Este artigo será escrito em modo de pesquisa técnica, e alunos não técnicos podem ignorá-lo.
Diretório de artigos
fundo
Na implementação do serviço de entrada baseado no design e construção do modelo de componente (plug-in), ao usar o plug-in do pacote nativo Go, haverá defeitos funcionais, que não são suficientes para suportar os recursos esperados; ao usar o pacote de código aberto go-plugin, embora os defeitos funcionais tenham sido corrigidos, mas perdeu parte do desempenho (custos de comunicação entre os componentes e o programa principal).
Para obter detalhes, consulte o design da estrutura das dezenas de milhões de serviços de entrada [Gateway] (1)
Para obter detalhes, consulte o design da estrutura de dezenas de milhões de serviços de entrada [Gateway] acima (1)
Este artigo apresentará outro padrão de arquitetura baseado em "camadas" e "pipeline".
em camadas
A ideia de camadas foi vista desde que você começou a aprender computadores. Arquitetura de computador modelo "von Neumann", arquitetura de banco de dados/kernel Linux, etc. Pode-se dizer que "camadas" é a maneira principal e eficaz de desmontar problemas complexos e simplificá-los.
A lógica de negócios é abstraída no nível superior e dividida em várias camadas, e os níveis superior e inferior dependem um do outro. No entanto, deve-se notar que quanto mais fina a granularidade do controle de abstração de negócios, maior o custo de implementação; e se o relacionamento de chamada do negócio for dinâmico, mais camadas de abstração levarão a um aumento na complexidade geral e maior magnitude; negócios subsequentes comunicação Na ausência de um entendimento completo da estrutura abstrata em camadas, a qualidade da implementação da função é cara, adicionando uma camada de neblina à manutenção e expansão dos serviços subseqüentes.
Relacionamento de chamada dinâmico: Aparece em cenários de negócios complexos, ou seja, existem vários serviços de downstream, o serviço de chamada real é determinado pelo campo de resposta do serviço de upstream e toda a rota apresenta uma topologia de relacionamento dinâmico.
A névoa da manutenção e expansão: Refere-se ao desenvolvimento iterativo sem entender completamente o design do framework, o que não pode garantir que as funções entregues farão uso total dos recursos do framework, tornando a qualidade de saída um tanto especulativa.
O seguinte é dividido em três maneiras de diferentes granularidades de divisão.
Distribuição + Handle
Na base atual, o tamanho da partícula é aumentado, então
- A realização do negócio é mais gratuita.
- A estrutura é retirada do negócio e o custo de manutenção é menor.
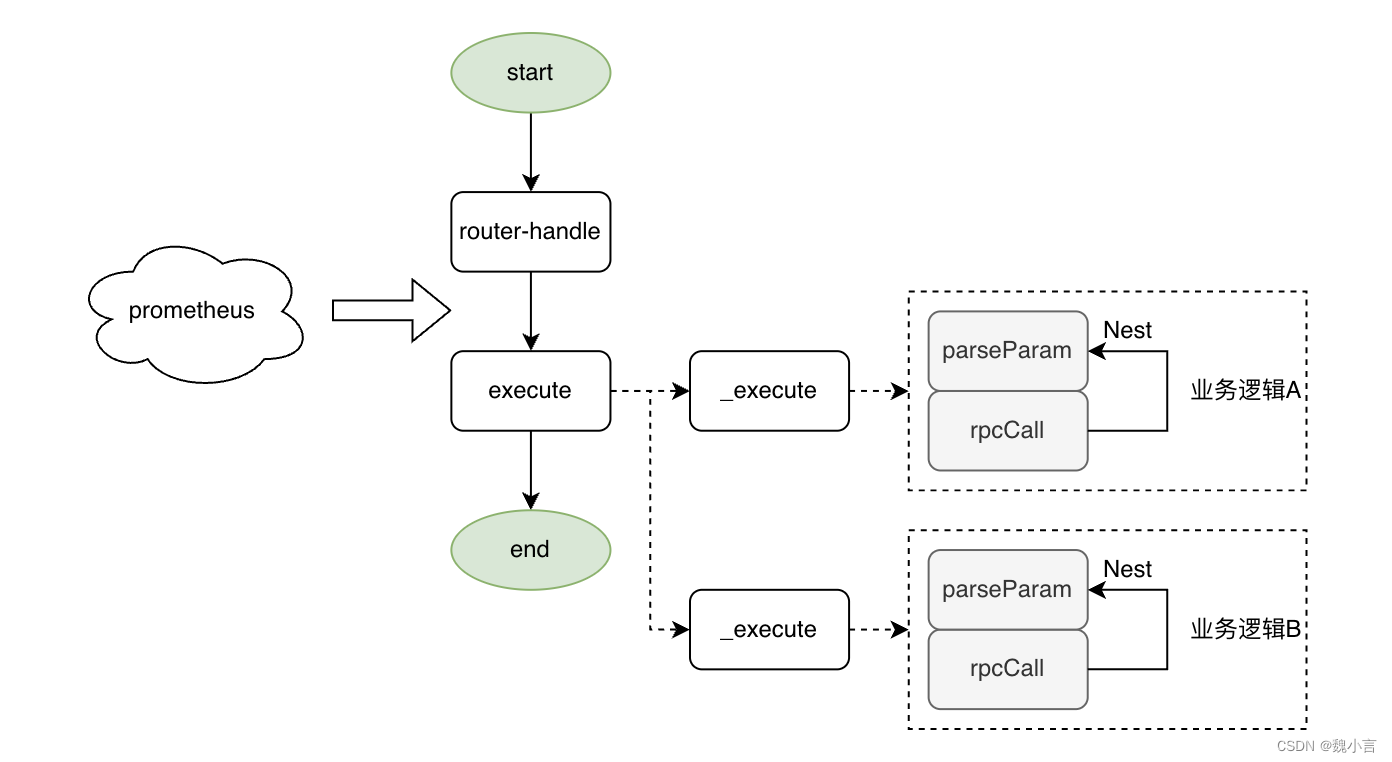
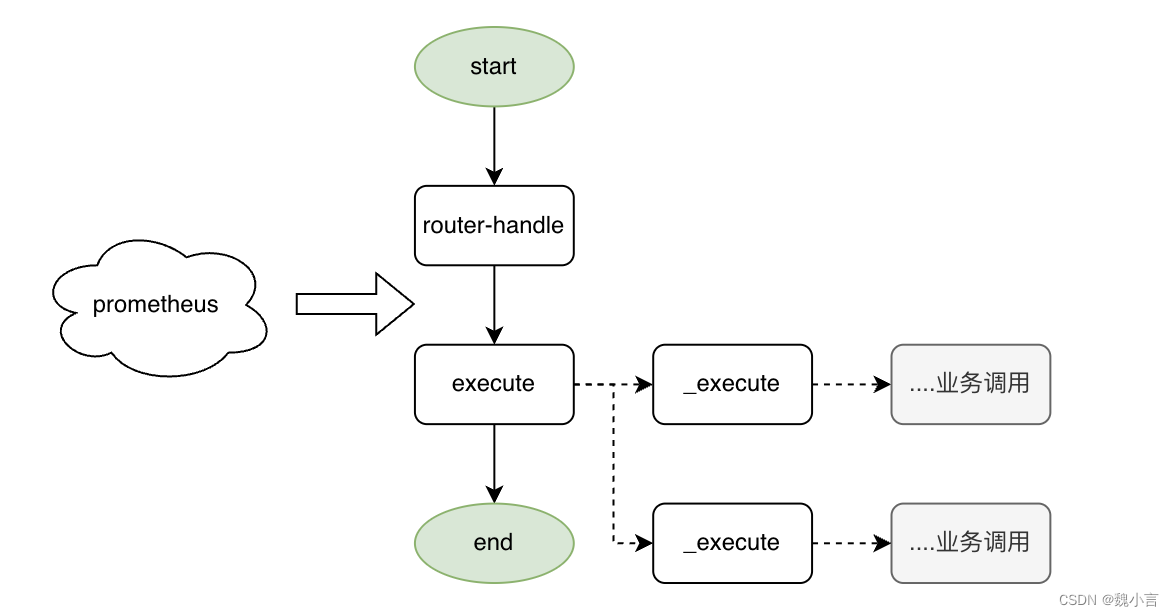 No modo Web, o processo existente é dividido em duas partes: roteador + executar.
No modo Web, o processo existente é dividido em duas partes: roteador + executar.
- roteador
- Distribua o tráfego para o identificador correspondente.
- executar
- O processamento de negócios específico não é dividido em camadas de estrutura, e o design e a implementação específicos são realizados por estudantes de desenvolvimento de negócios.
distribuição+gancho
Com base no identificador, adicione restrições de gancho, então
- A granularidade da restrição é muito pequena e a complexidade é muito alta para cenários sem requisitos de gancho.
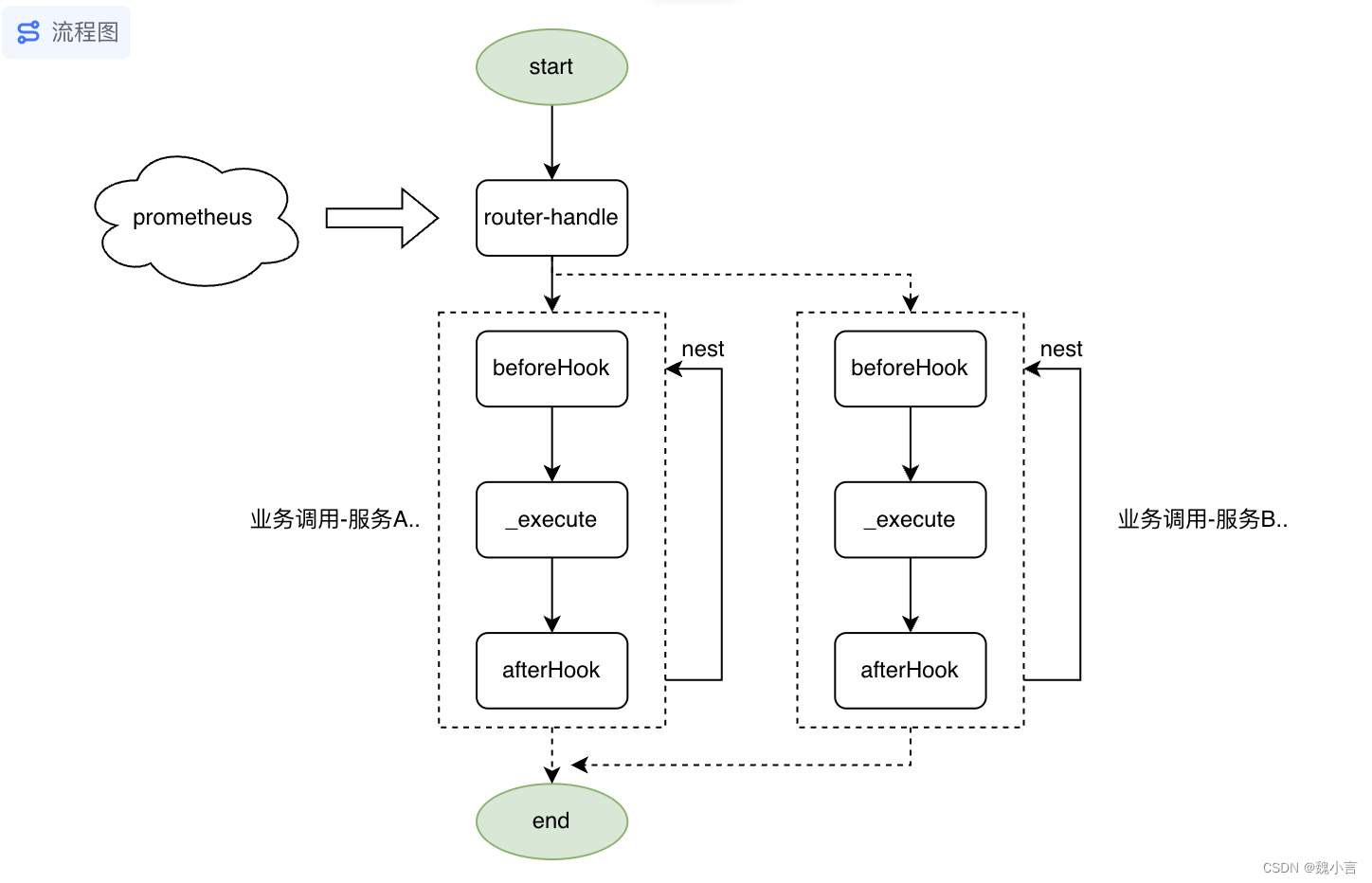
No modo Web, divida o processo existente em roteador + afterhook\execute\beforehook\assert logic.
-
roteador
- Distribua o tráfego para o identificador correspondente.
-
afterhook\execute\beforehook\assert
- Entre processos de negócios específicos, controle o tamanho da granularidade, pré-execução, execução e pós-execução.
Distribuição + camadas simultâneas
É necessário organizar o negócio atual, redividir a ordem de chamada dos subserviços e chamar simultaneamente em camadas, de modo
- Existem cenários em que o roteamento de subserviços downstream é alterado dinamicamente, o que não pode ser previsto e colocado em camadas com antecedência, e roteamento adicional precisa ser projetado.
- A maioria das chamadas de serviço pode ser alterada de serial para paralelo e o desempenho será melhorado.
- Se houver um problema de roteamento dinâmico, processamento adicional precisa ser feito para esse problema e a complexidade do projeto e da implementação é alta.
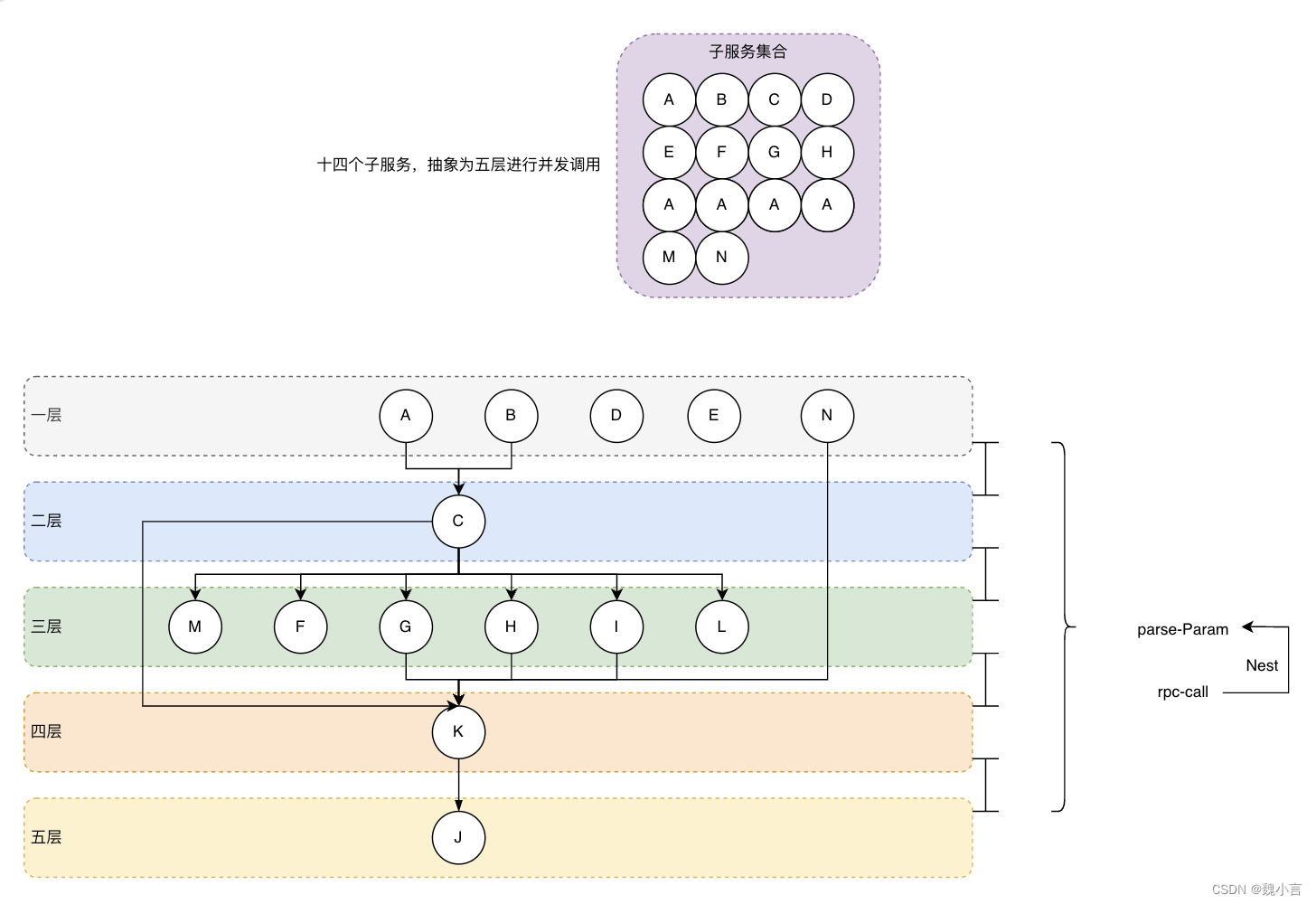
A premissa de uso é que existe um mapa estático de topologia de subserviços, e o relacionamento da chamada de serviço é colorido dinamicamente e dividido em diferentes níveis, e as chamadas concorrentes são feitas de acordo com o nível de serviços.
- Duas partes são abstraídas: construção de parâmetros + emenda de resposta e invocação simultânea de serviço.
gasoduto
A ideia de pipelines pode ser raramente vista em linguagens tradicionais. É mais comum em novos estilos como Goland e Ruby, especialmente em designs que suportam simultaneidade no nível da linguagem e são nativos da nuvem. O foco está na busca final de desempenho e processamento de stream de alto desempenho de dados, como big data e modelos grandes.
Observação: para saber mais sobre o nativo da nuvem, acesse: Migração da arquitetura de aplicativo nativo da nuvem 1: Paradigma de migração incremental
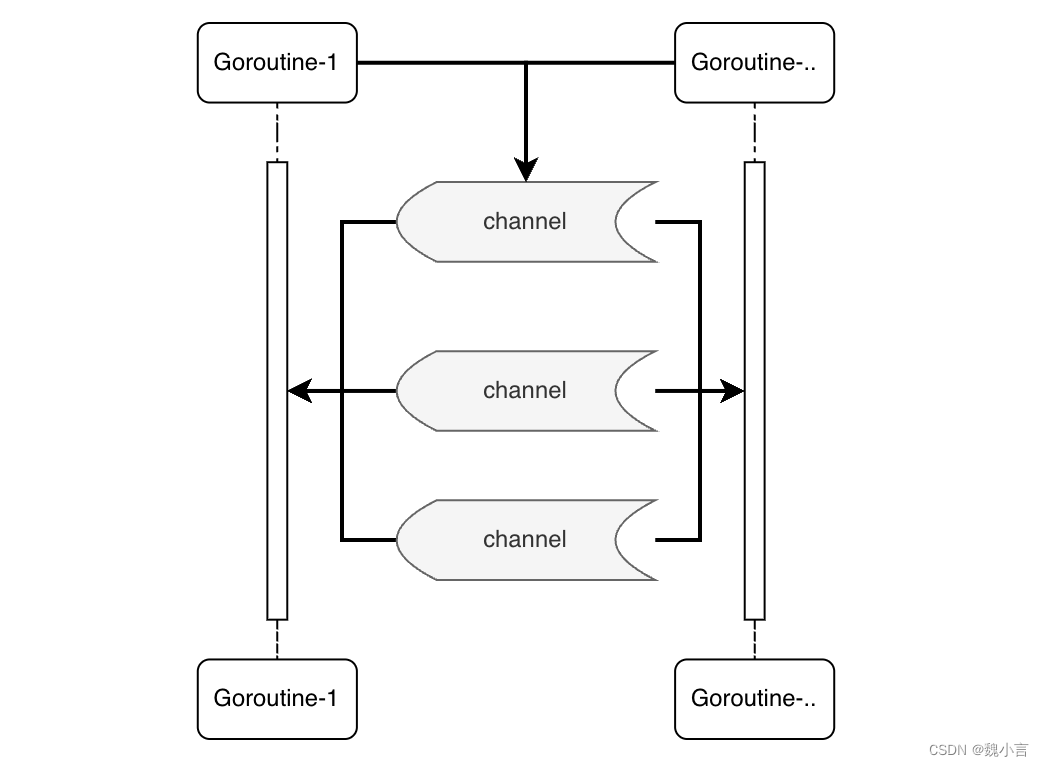
Mas não importa, você pode simplesmente transplantar o conceito de middleware para o pipeline primeiro e depois aprender mais. O design aqui é baseado no Canal em Goland.
Nota: Se você quiser saber mais sobre a Goland, acesse: Design Reflection of Go Language
Canal
Nos vários esquemas e implementações mencionados acima, todos eles são alterações de string e fusões dentro da solicitação e até mesmo deixam o nível da linguagem "operando com base no PHP existente".
Aqui falamos sobre um design de padrão baseado em pipeline que realiza o paralelismo no nível de serviço, que é especialmente adequado para cenários de simultaneidade extremamente grandes e está em conformidade com as características da linguagem Go.
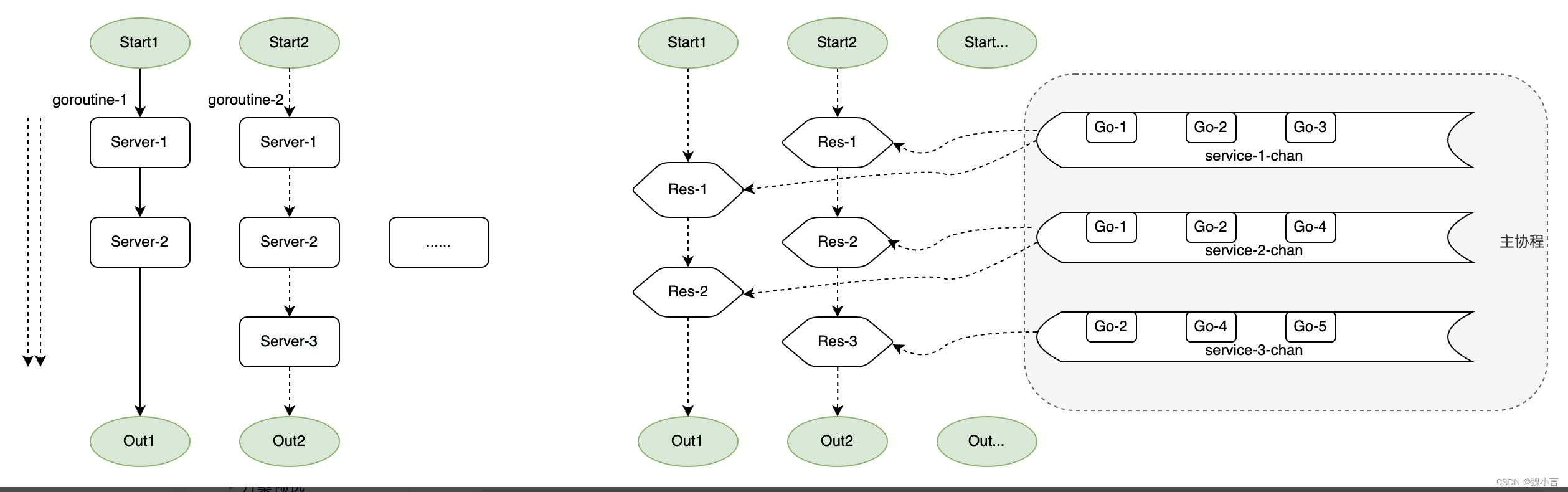
A co-rotina principal será responsável pelo monitoramento e chamadas concorrentes de cada autoatendimento, sendo que a cor-rotina de negócios é utilizada apenas para iniciação do serviço e recebimento de resposta. Agregue diferentes solicitações na dimensão de subserviço e chame-as em paralelo.
Aqui está uma breve visão geral do programa:
- Montando "apenas orquestrar parâmetros de serviço"
- Do projeto de processo linear ao simplificado e altamente montado.
- acelerar
- Converta vários serviços em um único pv de serial para paralelo.
- Converta chamadas pv únicas em simultâneas.
- expandir
- Modularização do serviço, chamadas multi-rotas são 100% reutilizáveis.
- A estrutura é forte, protege o uso do negócio e possui altos requisitos para a realização da função de chamada básica "funções completas, suporte à configuração personalizada".
Mas deve-se notar que,
- Envolve o modelo Go Channel, e o custo de implementação é relativamente alto.
- É necessária a consideração de problemas/esquemas, como cobertura rigorosa e científica e impasses simultâneos.
implementação de demonstração
package main
import (
"fmt"
"sync"
)
type FInput struct{
callback chan FInput
param string
res string
}
func main () {
fmt.Println("hello https://tool.lu/")
c := make(chan FInput,3)
defer close(c)
var wg sync.WaitGroup
wg.Add(3)
go F(c,wg) //服务开启监听
go A(c,wg) //发起服务请求
go B(c,wg) //发起服务请求
wg.Wait()
fmt.Println("X https://tool.lu/ is finish")
}
func F (c chan FInput,wg sync.WaitGroup){
fmt.Println("F https://tool.lu/ len:",len(c))
for{
i, ok := <-c
fmt.Println("F https://tool.lu/ ok:",ok)
fmt.Println("F https://tool.lu/ param:",i.param)
if ok{
i.res = i.param + " is executed "
i.callback <- i
}
}
fmt.Println("F https://tool.lu/ is finish")
wg.Done()
}
func A (c chan FInput,wg sync.WaitGroup){
cb:=make(chan FInput)
defer close(cb)
var p FInput
p.callback = cb
p.param = "A"
c<-p
i, ok := <-cb
if ok{
fmt.Println("A https://tool.lu/ res ok:",ok)
fmt.Println("A https://tool.lu/ res param:",i.param)
fmt.Println("A https://tool.lu/ res value:",i.res)
}
fmt.Println("A https://tool.lu/ is finish")
wg.Done()
}
func B (c chan FInput,wg sync.WaitGroup){
cb:=make(chan FInput)
defer close(cb)
var p FInput
p.callback = cb
p.param = "B"
c<-p
i, ok := <-cb
if ok{
fmt.Println("B https://tool.lu/ res ok:",ok)
fmt.Println("B https://tool.lu/ res param:",i.param)
fmt.Println("B https://tool.lu/ res value:",i.res)
}
fmt.Println("B https://tool.lu/ is finish")
wg.Done()
}
resumo
Na verdade, comparando os vários projetos de padrões arquitetônicos mencionados acima, cada um tem suas próprias características e suas vantagens e desvantagens são combinadas. Na hora de escolher uma arquitetura, pensar em diferentes modelos é apenas o primeiro passo. Somente sob esta premissa pode ser feita uma seleção adicional.
À medida que o chatGPT entra no campo de visão do público, o "canal modelo grande" se populariza, e seu processo de evolução singular é ainda mais marcante. Para ser franco, vários aplicativos no futuro serão modelos mais inteligentes e maiores...
O próximo capítulo apresentará como o "serviço de entrada" é combinado com o "grande modelo" para projetar um modelo de arquitetura orientado para o futuro, portanto, fique atento!