O que é aprendizagem contrastiva?
A aprendizagem contrastiva parece estar em um estado de "nenhuma definição clara e princípios orientadores"
O que é aprendizagem contrastiva ? (Este é um link do WeChat ) O texto completo é relativamente longo, mas a estrutura lógica ainda é boa.
Se você quiser entender mais rapidamente o que é aprendizado contrastivo ou como o aprendizado contrastivo é feito, você pode ler o artigo do modelo SimCLR, que pode ser considerado uma introdução a um modelo de aprendizado contrastivo relativamente "padrão". Este artigo ilustra o SimCLR , muito bem dito .
Então, qual é a representação unificada da aprendizagem contrastiva, ou qual é a estrutura unificada da aprendizagem contrastiva? Este artigo explica muito bem.
Por enquanto, a estrutura da aprendizagem contrastiva pode ser resumida em três tipos:
-
Com base em exemplos negativos:
- É representado principalmente pelo SimCLR . Embora muitos modelos de aprendizado comparativo tenham sido propostos antes do SimCLR (2020), como o Moco V1, o efeito deste SimCLR é óbvio em comparação com o modelo anterior e adota uma estrutura simétrica. A comparação geral Clara e fácil de articular.
-
Baseado em rede assimétrica
-
Com base na decorrelação de recursos (ou método de função de perda de remoção de redundância)
prefácio
Primeiro remova a fonte do papel:
【文章一】ICML'20 Entendendo a Representação Contrastiva Aprendendo por Alinhamento e Uniformidade na Hiperesfera
【文章二】CVPR'21 Entendendo o Comportamento da Perda Contrastiva
Deixe-me falar sobre por que você deve ler esses dois artigos? Na verdade, veio de uma oportunidade acidental. Eu vi a aprendizagem contrastiva (Contrastive Learning) e entrei no poço do artigo ConSERT: A Contrastive Framework for Self-Supervisioned Sentence Representation Transfer (é claro, como uma introdução ao aprendizado contrastivo, ainda sinto que o artigo SimCLR é direto). Então eu queria saber por que o aprendizado contrastivo era um pouco metafísico. Parecia assim, mas senti que faltava prova, então descobri acidentalmente esses dois artigos.
Eu sinto que o 【Artigo 2】 segue o trabalho do 【Artigo 1】 até certo ponto. Ambos os artigos provam do ponto de vista matemático porque o Aprendizado Contrastivo pode funcionar.
fundo
A ideia de aprendizado comparativo é muito simples de dizer, ou seja, aproximar amostras semelhantes e afastar amostras diferentes. Uma perda de comparação comumente usada é baseada na perda de entropia cruzada de amostras negativas no lote. Suponha que tenhamos um conjunto de dados D = { ( xi , xi + ) } i = 1 m D = \{(x_i,x_i^+)\}^m_{i=1}D={( xeu,xeu+) }eu = 1m, entre os quais xi x_ixeuSoma xi + x_i^+xeu+está semanticamente relacionado, então em um mini lote de tamanho N, ( xi , xi + ) (x_i, x_i^+)( xeu,xeu+)的训练目标为
ι i = logesim ( hi , hi + ) / τ ∑ j = 1 N esim ( hi , hj + ) / τ \iota_i = log\frac{e^{sim(h_i,h_i^+)/ \tau}}{\sum^N_{j=1}e^{sim(h_i,h_j^+)/\tau}}eueu=l o g∑j = 1nesim ( h _eu, hj+) / tesim ( h _eu, heu+) / t
Mas na aprendizagem contrastiva, o mais importante é construir instâncias Positivas ( xi , xi + ) (x_i,x_i^+)( xeu,xeu+) , uma das razões pelas quais o aprendizado contrastivo se originou no campo CV é que as imagens podem ser giradas, cortadas, distorcidas etc. para construir amostras positivas que não afetam a compreensão semântica das imagens xi + x_i^+xeu+. Recentemente, muitos métodos de aprimoramento de dados no campo de NLP foram aplicados a métodos para gerar amostras positivas.
Perda contrastiva
Conforme mencionado no [artigo 1º], a perda contrastiva comum é mostrada na figura a seguir:
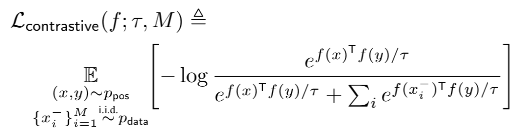
em:
- pos(x,y) pos(x,y)p os ( x ,y ) representa um par de amostra positivo;
- xi − x_i^-xeu−significa xi x_ixeuA amostra negativa;
- f (x) f(x)f ( x ) é um codificador treinado (pelo meu entendimento atual, acho que é uma rede neural);
É um pouco abstrato, então vamos olhar para a perda usada nos dois artigos de SimCLR e CoonSERT para comparação, que é fácil de entender:
Quanto à forma de cálculo, este blog , SimCLR, apresenta todo o processo como ponto de entrada. Na minha opinião, o numerador é o par positivo, ou seja, apenas a distância entre o par positivo é considerada, mas o denominador é tudo as distâncias, incluindo o par positivo, pares de amostras e pares de amostras negativas.
Claro, existem outras perdas usadas no aprendizado comparativo:
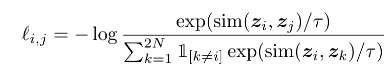

Texto (Artigo 1)
duas propriedades
Primeiro, [Artigo 1] identificou dois atributos relacionados à perda contrastiva:
AlignmentÉ usado para medir a similaridade (compacidade ou alinhamento) entre exemplos positivos e amostras, ou seja, amostras semelhantes possuem características semelhantes.UniformityAvalia quão uniformemente os vetores de todos os dados são distribuídos, quanto mais uniforme, mais informações são retidas .
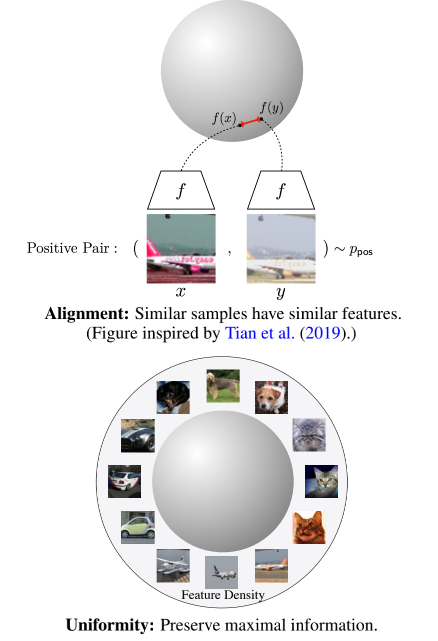
Quais são os benefícios de distribuir recursos na hiperesfera da unidade?
-
Os vetores de norma fixa melhoram a estabilidade do treinamento;
-
Se as características de uma categoria podem ser melhor agrupadas, então esta categoria é mais fácil de ser linearmente separável em todo o espaço de características .
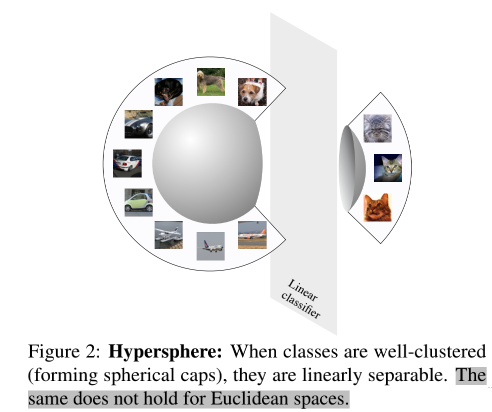
Para esta separabilidade linear, um experimento foi feito neste artigo: usando AlexNet como framework modelo, no CIFAR-10, três métodos experimentais foram comparados: inicialização aleatória, aprendizado de classificação supervisionado e aprendizado comparativo não supervisionado, e o efeito de representação foi visualizado (I sinto que no artigo É também porque o bidimensional pode ser melhor exibido e expresso, então o método do círculo bidimensional é adotado. Embora o conceito de hiperesfera tenha sido mencionado no artigo, a dimensão m desta hiperesfera é geralmente maior que 2):
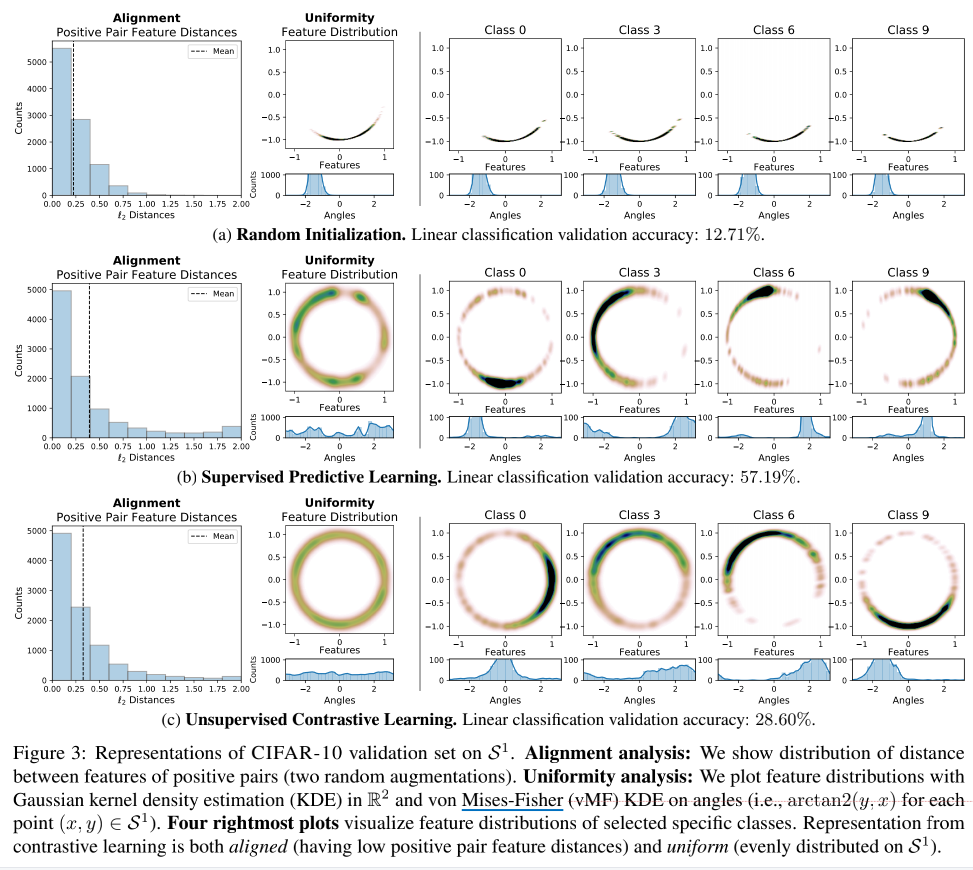
Vamos analisar brevemente a imagem acima:
- O primeiro é o histograma de Alinhamento.Pode-se ver que os pares de amostras positivas são muito semelhantes, e o efeito não é ruim;
- Olhando para a imagem da Uniformidade novamente, o pior dos três métodos é obviamente a inicialização aleatória, o que também reflete porque os pares de amostras positivas são muito próximos - porque todas as amostras são empilhadas juntas, então de acordo com a Uniformidade. definição de que tais informações características não podem ser distribuídas uniformemente na hiperesférica, portanto, a oportunidade de informação não pode ser preservada.
- Vamos olhar para as quatro imagens na extrema direita novamente, e podemos descobrir que as representações de diferentes categorias de aprendizagem comparativa estão distribuídas em diferentes posições do círculo (veja a imagem de distribuição de ângulos abaixo da imagem do círculo).
- Comparado com o aprendizado supervisionado, a distribuição do aprendizado contrastivo é mais uniforme e não haverá fenômeno de agregação - embora o efeito da segmentação linear, o aprendizado contrastivo (28,60%) seja muito pior do que o aprendizado supervisionado (58,19%), mas mais informações são retido para aprender.
Medir duas propriedades
Vamos voltar e olhar para a perda mencionada no artigo:
文中将L contrastive L_{contrastive}eucon t r a s t i v e _Foi dividido e dividido em duas partes (ou seja, simplificação):

Para medir as duas propriedades de Alinhamento e Uniformidade, serão definidas duas perdas ( L align e L uniform L_{align} e L_{uniform}eua l i g ne Lu ni f ou m) correspondem respectivamente a esses dois atributos, como segue (do ponto de vista formal, significa f ( xi − ) T f ( x ) f(x_i^-)^Tf(x)f ( xeu−)T f(x)torna-se∣ ∣ f ( x ) − f ( y ) ∣ ∣ ||f(x)-f(y)||∣∣ f ( x )−f ( y ) ∣∣ ):
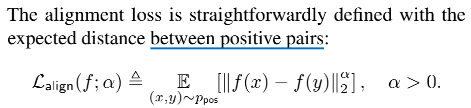

Eu sinto que o propósito de fazer isso é: provar que o mecanismo de aprendizado comparativo ou a razão para o bom efeito é por causa dos dois atributos de Alinhamento e Uniformidade, então o artigo simplesmente constrói duas Perdas com base nas definições desses dois atributos e otimiza diretamente esses dois A Loss pode ser concluído se o efeito é melhor do que L contrastive L_{contrastive}eucon t r a s t i v e _melhorar. Se for bom, então prova que o aprendizado comparativo é de fato devido a esses dois atributos que tornam o efeito melhor.
Por que você escreve assim? O artigo fornece um raciocínio detalhado da fórmula. Intercetei um pouco aqui para ilustrar a relação da equação:

Prova experimental
Pode ser visto claramente na figura abaixo que a Perda diretamente otimizada (o pequeno ponto na figura abaixo) tem uma acc maior
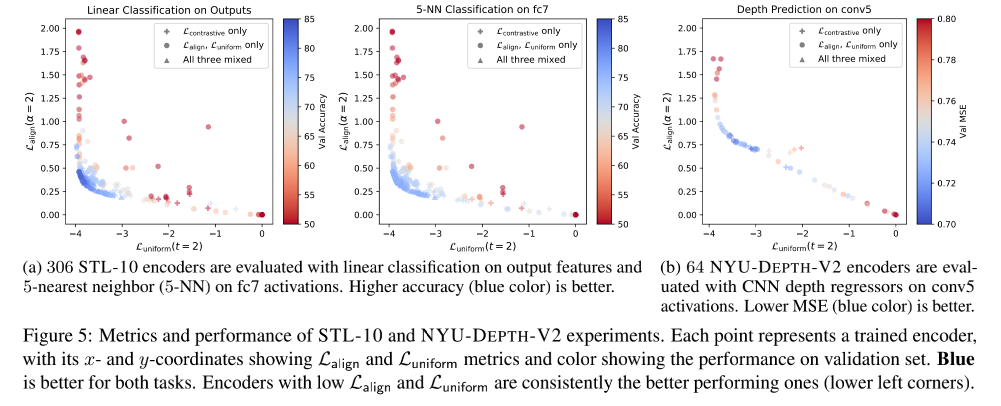
A figura abaixo também reflete L align e L uniform L_{align} e L_{uniform}eua l i g ne Lu ni f ou mA importância da combinação, não importa qual seja usada sozinha, o efeito não é bom (acho que a ordenada na figura abaixo representa apenas o valor, não uma medida certa, ou seja, L alinha e L uniforme L_{alinha} e L_{uniforme}eua l i g ne Lu ni f ou mdeve ser o menor possível).
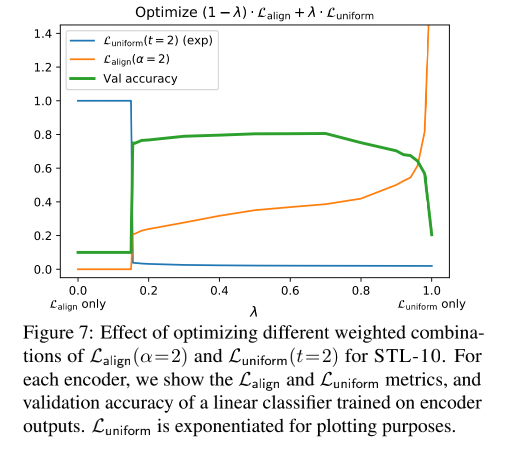
Texto (Artigo 2)
Em primeiro lugar, a amostra negativa no aprendizado comparativo deve ser relativa à âncora simples, ou seja, para a amostra xi x_ixeuPois, além dos dados aumentando xi + x_i^+xeu+O resto são amostras negativas.
Isso também explica por que quanto mais você empurra a amostra negativa, pior é o efeito semântico potencial, porque a amostra negativa contém amostras semelhantes do mesmo tipo . Isso leva a afastar a distância do gato do gradiente de prata, que também destrói o latente semântica de amostras semelhantes. Isso ocorre porque a perda contrastiva busca apenas distinguir diferentes instâncias (ou amostras) sem prestar atenção às relações semânticas.
Resumo
Este artigo discute principalmente a função Perda do aprendizado comparativo e acredita que a Perda do aprendizado comparativo é uma função de perda com reconhecimento de dureza , e o parâmetro de temperatura τ \tauτ pode controlar o grau de punição para amostras negativas duras (quanto menor a penalidade, mais fácil é separar amostras negativas semelhantes e torná-las uniformes, ou seja, uniformidade). No entanto, a busca excessiva de indicadores de uniformidade destruirá a distribuição espacial de amostras semelhantes (as chamadas amostras semelhantes referem-se aaltamente semelhantes a amostras positivas e muitas vezes provavelmente são amostras positivas em potencial), o que afetará ainda mais as tarefas a jusante. Os autores chamam esse fenômenode dificuldade de tolerância à uniformidade, mas escolhendo umbom coeficiente de temperaturaτ \tauτ pode encontrar um bom equilíbrio entre separar amostras negativas e tolerar amostras semelhantes.
introduzir
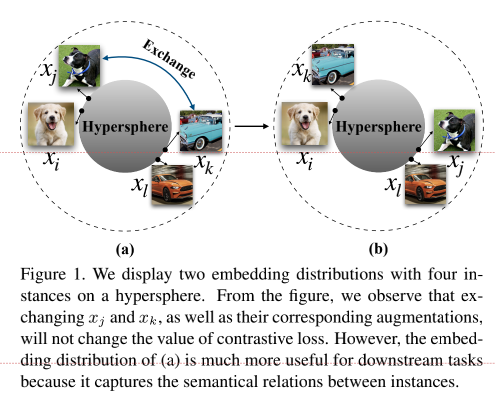
Para entender melhor o impacto da estrutura semântica proposta pelo autor, o autor usa a figura a seguir para explicar. Para (a) (b) duas distribuições de incorporação, iremos xj e xk x_j e x_kxje xkA troca de incorporação, embora não altere a perda de aprendizado comparativo, mas a distribuição de (a) funciona melhor em tarefas downstream do que a distribuição de (b), porque pode refletir a estrutura semântica latente entre as amostras.
Na verdade, esta figura também mostra as características de tolerância à uniformidade do lado. (a) a figura mostra que a distância de amostras semelhantes não é muito grande, mas (b) a distância de amostras semelhantes na figura é relativamente grande ( embora para xj x_jxje xk x_kxkOu seja, a distância entre as amostras é a mesma, então a perda é a mesma.Nas tarefas downstream, os resultados mostram que a distribuição em (a) é melhor, o que significa que a semântica latente entre amostras semelhantes pode ser preservada.
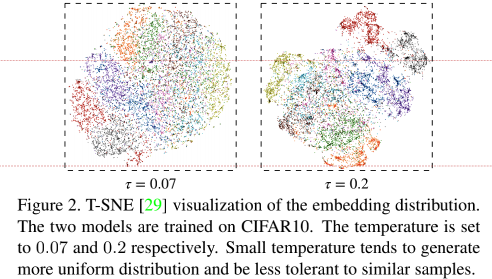
Ao mesmo tempo, o artigo também discute a influência da temperatura na perda de contraste. Verifica-se que para temperaturas mais baixas , a perda de contraste irá punir mais a amostra negativa mais próxima , embora a distribuição seja mais uniforme (mais próxima da distância entre a amostra positiva pares e ampliar a distância entre pares de amostras negativas. Distância, tal método não contém informações semânticas), mas também levará à separação de amostras semelhantes. O autor usa T-SNE para visualizar a distribuição de imersão em diferentes temperaturas:
Todo o artigo realizou três tarefas:
- Analisou que a perda contrastiva é um tipo de perda sensível à dureza, e esse atributo é de grande importância para a perda contrastiva;
- Do ponto de vista da análise de gradiente, o parâmetro de temperatura é um parâmetro importante para punir amostras negativas duras;
- Isso mostra que existe de fato um limite de uniformidade-tolerância no aprendizado contrastivo, e uma boa escolha de temperatura pode equilibrar os dois atributos de uniformidade (para garantir distribuição uniforme de amostras) e tolerância (para manter a distância entre amostras semelhantes).
Analisando propriedades sensíveis à dureza
Primeiro, dê a forma da perda contrastiva (perda InfoNCE) amplamente usada no aprendizado autossupervisionado:

Por conveniência, o autor usa P i , j P_{i,j}Peu , jExpresso (significando xi x_ixeuconsiderado xj x_jxjA probabilidade):

Do ponto de vista da aprendizagem comparativa Perda (requer a similaridade si entre a i-ésima amostra e sua cópia de outro aumento (ou seja, amostra positiva) , i s_{i,i}seu , euTão grande quanto possível, e a similaridade com outras instâncias (amostras negativas) si , k s_{i,k}seu , kTão pequena quanto possível), o autor define uma perda simples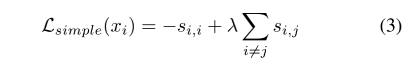
No entanto, o processo de treinamento real, usando L simples L_{simples}eué simples _ _O efeito do método não é tão bom quanto a perda contrastiva baseada em softmax.
Isso ocorre porque a perda contrastiva baseada em softmax é uma função de perda com reconhecimento de dureza , que pode se concentrar automaticamente em amostras negativas para obter um efeito de distribuição uniforme.
análise de gradiente
Vamos dar uma olhada na derivação da fórmula (1) da seguinte forma (resultados de derivadas parciais para similaridade positiva e não similaridade):
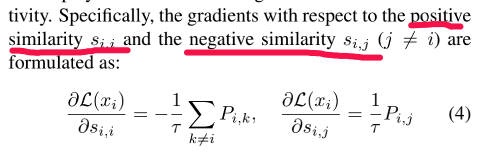
De acordo com a fórmula acima, as seguintes conclusões podem ser tiradas:
- Para a amostra negativa, seu gradiente é proporcional a exp ( si , j / τ ) exp(s_{i,j}/\tau)e x p ( seu , j/ τ ) , o que mostra que a perda contrastiva é uma função de perda sensível à dureza, que é diferente de∂ L simples ∂ si , j = λ \frac{\partial L_{simples}}{\partial s_{i,j} } =\lambda∂ seu , j∂ Lé simples _ _=λ é umarazão constante(ou seja, para todas as amostras negativas, o gradiente é o mesmo);
- Pensando melhor, para todas as proporções amostrais negativas, P i , j P_{i,j}Peu , jOs termos do denominador são os mesmos, então diga si , j s_{i,j}seu , jQuanto maior, então P i , j P_{i,j}Peu , jQuanto maior o item do numerador, maior o gradiente-------> Ou seja, a perda de aprendizado comparativo é dar uma amostra negativa mais semelhante (amostra negativa dura) com um gradiente maior, então quanto mais longe de amostras positivas .
- A observação cuidadosa também pode encontrar um local interessante, ou seja, o gradiente da amostra positiva é igual à soma dos gradientes de todas as amostras negativas
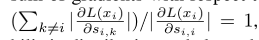
O efeito da temperatura
Autor para xj x_jxjEsta amostra negativa define um valor chamado Força Relativa da Penalidade:
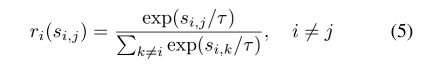
A fórmula (5) satisfaz a distribuição de Boltzmann, e a entropia da distribuição aumenta estritamente com o aumento do coeficiente de temperatura (a prova será dada no experimento complementar do artigo, que não será elaborado aqui).
A figura abaixo mostra a relação entre a penalidade relativa de amostras negativas e a temperatura e similaridade. Pode-se verificar que quando a temperatura é pequena , como 0,07, quanto mais próxima estiver a amostra negativa, maior será a penalidade e maior será a gradiente, portanto, o mais capaz Inversamente , à medida que a temperatura aumenta, a punição de todas as amostras negativas é uniforme (ou seja, apresenta uma sensação de igualdade de tratamento).
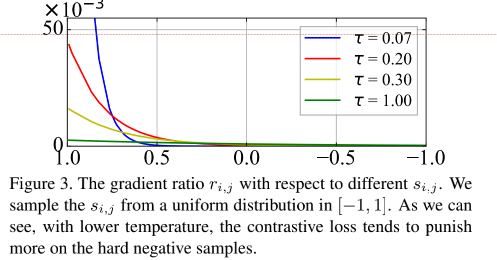
Mas, desta forma, surgem os problemas mencionados acima, muita busca por uma temperatura pequena só punirá a uma ou duas amostras negativas mais próximas. Por isso, o autor considera dois exemplos extremos do ponto de vista da fórmula, ou seja, o a temperatura tende a 0 e ao infinito Duas situações.
- Quando o coeficiente de temperatura tende a 0, a perda contrastiva degenera em uma função de perda que se concentra apenas nas amostras negativas mais difíceis

-
Quando o coeficiente de temperatura tende ao infinito, a perda de contraste tem o mesmo peso para todas as amostras negativas, e a perda de contraste perde as características de amostras difíceis.

Curiosamente, quando o coeficiente de temperatura tende ao infinito, a perda torna-se a perda simples L simples L_{simples} introduzida anteriormenteeué simples _ _(Fórmula (3))
Amostragem Negativa Forte Explícita
No artigo, o autor cita o trabalho do predecessor Zhuang et al.- LocalAggregation . Ao calcular o gradiente de amostras negativas, refere-se à seleção de amostras negativas maiores que um determinado limite para calcular a perda (como selecionar a amostra negativa mais próxima do Top K).
Nesse caso, é equivalente a amplificar o efeito de amostras negativas, de modo que, quando a temperatura aumentar, a distribuição de imersão final do modelo será mais uniforme e não se tornará conforme a temperatura aumenta conforme a temperatura aumenta, conforme mostrado na Figura 4 (abaixo). Mais desigual, mas igual à imagem da Figura 6.
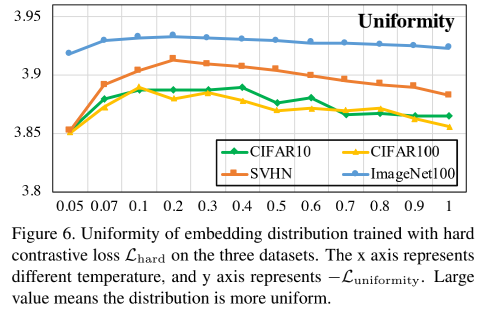
Desta forma, a influência do ajuste de temperatura nas mudanças de uniformidade no Dilema Uniformidade-Tolerância é aliviada.
A Perda Contrastiva Forte é definida da seguinte forma:
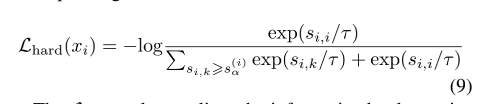
onde, s α ( i ) s_{\alpha}^{(i)}sa( eu )É uma amostra negativa e âncora xi x_{i}xeuUm ponto de corte de similaridade, para a similaridade em [ s α ( i ) s_{\alpha}^{(i)}sa( eu ),1.0] As amostras negativas deste intervalo (intervalo informativo) são consideradas como amostras duras informativas negativas são mais semelhantes à âncora, e é mais difícil separá-las), e pela similaridade em [-1.0 , s α ( i ) s_ { \alpha}^{(i)}sa( eu )] Este intervalo é chamado de intervalo não informativo.
Ao calcular a perda, si , j < s α ( i ) s_{i,j}<s_{\alpha}^{(i)}seu , j<sa( eu )Essas amostras negativas tais que ri ( si , j ) = 0 r_i(s_{i,j})=0reu( seu , j)=0 . É equivalente a comprimir a distribuição de proporção gradiente das amostras negativas originais (como a Figura 3) para o intervalo do intervalo informativo, aumentando assim a "punição" do modelo para amostras negativas neste intervalo e focando na relação entre xix_ixeuAmostras negativas semelhantes são empurradas para mais longe.
Dilema de Uniformidade-Tolerância
Incorporando Uniformidade
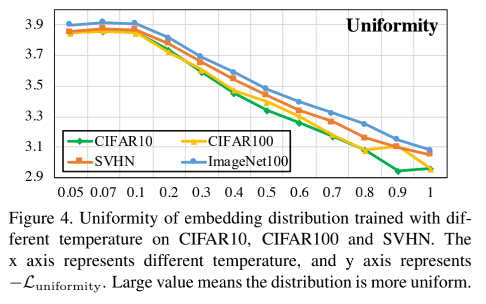
O autor analisou a relação entre Uniformidade e temperatura, conforme a figura abaixo:
Pode-se constatar que quando a temperatura é menor, a perda contrastiva tende a separar as amostras positivas de forma semelhante à amostra âncora, o que levará a uma distribuição local mais esparsa .
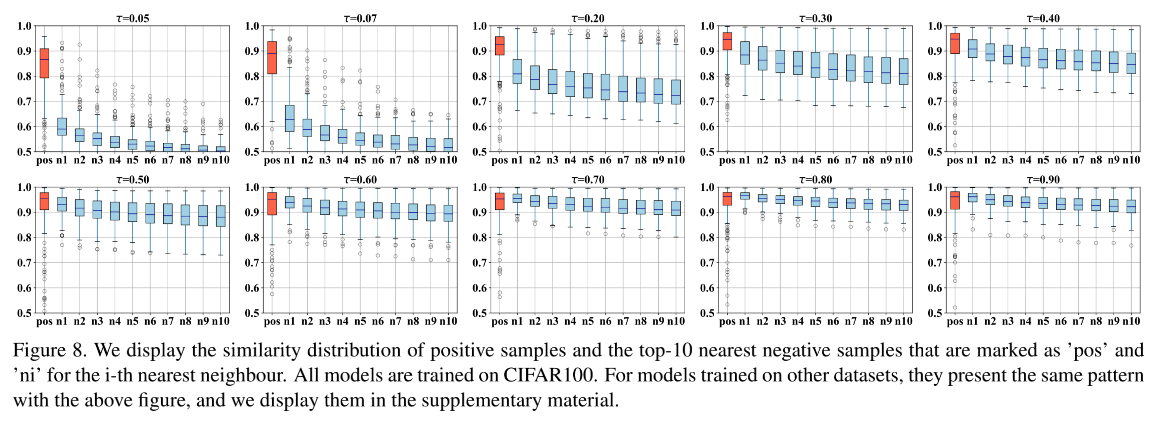
Vamos dar uma olhada na imagem de perda de contraste Hard:
Pode-se ver que a perda de contraste Hard não é tão sensível à temperatura, e o efeito é mantido em um nível alto.
Tolerância a potenciais amostras positivas
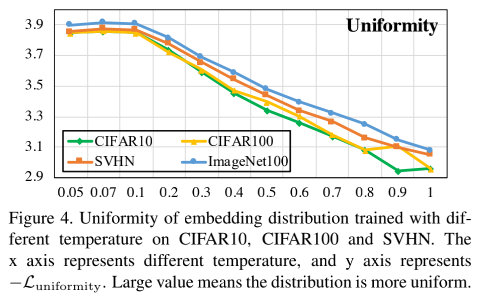
O efeito após o aprendizado comparativo pode ser representado pela Fig1(a), mas sabemos que à medida que a temperatura diminui, amostras negativas semelhantes ficarão distantes das amostras âncora, portanto, para medir esse fenômeno, o atributo Tolerância é proposto .
O autor usa a seguinte fórmula para medir a tolerância pertencente à mesma classe :

A chamada mesma categoria significa que os cães são da mesma categoria, mas não importa a raça, os carros são da mesma categoria, independentemente da marca.
A figura abaixo mostra o efeito da temperatura na tolerância:
Da mesma forma, vamos dar uma olhada em L hard L_{hard}euha r dO efeito da tolerância:
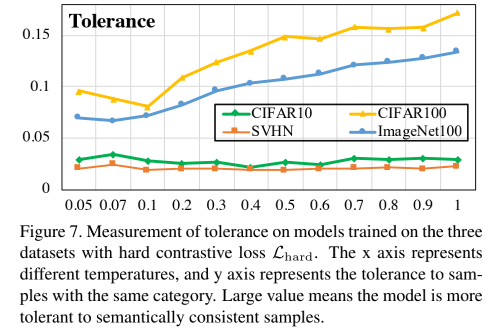
Pode-se ver que o efeito não é tão bom quanto a perda de contraste comum, o que é certo, porque H hard H_{hard}Hha r dA uniformidade é alta, resultando em uma diminuição na similaridade.
No entanto, comparando a Figura 6 e a Figura 4, pode-se verificar que, à medida que a temperatura aumenta neste momento, a Uniformidade permanece relativamente estável. Neste momento, o aumento da temperatura pode aumentar a Tolerância sem aumentar a uniformidade, ou seja, o embedding obtido pelo modelo pode ser mantido uniforme e pode ser agregado localmente, mantendo assim uma certa estrutura semântica potencial e quebrando a Uniformidade mencionada no item anterior Seção. -Questões de dilema de tolerância.
Verificação experimental
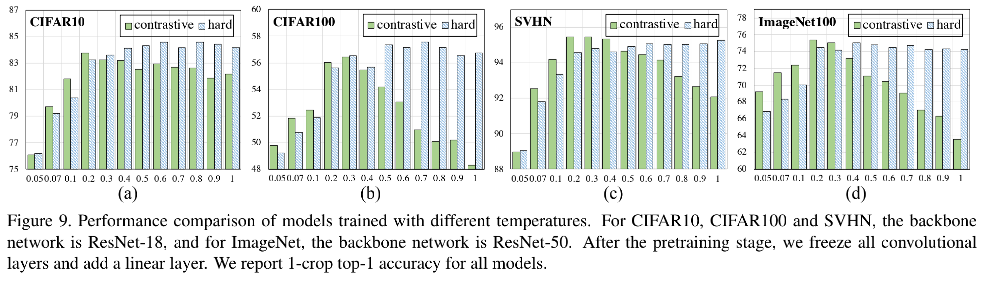
A figura a seguir mostra o efeito no CIFAR100. Os resultados provam que é realmente difícil separar as amostras positivas e negativas à medida que a temperatura aumenta (o eixo vertical representa a distância):
Por outro lado, o autor também verificou o coeficiente ótimo de temperatura de diferentes conjuntos de dados.A coluna verde na figura abaixo mostra o desempenho da comparação da perda com o coeficiente de temperatura. Além disso, o autor também verificou a perda comparativa encontrada tomando amostras difíceis explícitas. Depois de adotar o algoritmo de mineração de amostra difícil exibido, a correlação entre desempenho e coeficiente de temperatura é enfraquecida. Quando o coeficiente de temperatura é maior que um valor apropriado, a perda produzida O desempenho do modelo permaneceu amplamente estável.
Resumir
O artigo estuda o coeficiente de temperatura na perda contrastiva (Contrastive Loss) , explica o papel específico do coeficiente de temperatura e explora o mecanismo de aprendizado do aprendizado contrastivo.
Para resumir as conclusões deste artigo:
- A função de perda contrastiva é uma função de perda que tem a propriedade de autodescoberta de amostras negativas difíceis, o que é crucial para aprender representações auto-supervisionadas de alta qualidade, e as funções de perda que não possuem essa propriedade deterioram muito o desempenho de auto -aprendizagem supervisionada . O papel de focar em amostras difíceis é: para aquelas amostras que já estão distantes, não há necessidade de continuar a fazê-las distantes, mas principalmente focar em como fazer as amostras que não estão distantes, para que o resultado obtido o espaço de representação é mais uniforme (uniformidade).
- O papel do coeficiente de temperatura é ajustar o grau de atenção a amostras difíceis: quanto menor o coeficiente de temperatura, mais atenção é dada para separar esta amostra das outras amostras mais semelhantes) . Os autores conduzem análises e experimentos aprofundados sobre coeficientes de temperatura e os usam para explicar como o aprendizado contrastivo pode aprender representações úteis.
- Existe um Dilema de Uniformidade-Tolerância (Dilema de Uniformidade-Tolerância) para perda de contraste. Um coeficiente de temperatura pequeno se concentra mais na separação de amostras difíceis que são semelhantes a esta amostra e, portanto, tende a resultar em uma representação mais uniforme. No entanto, as amostras difíceis geralmente são muito semelhantes a esta amostra, como diferentes instâncias da mesma categoria, ou seja, muitas amostras negativas difíceis são, na verdade, amostras positivas em potencial. Forçar excessivamente a separação de amostras sólidas destrói a estrutura semântica latente aprendida.
referência:
https://zhuanlan.zhihu.com/p/357071960
https://zhuanlan.zhihu.com/p/406628964