fundo
Até agora, vimos os recursos do ChatGPT e os excelentes recursos que ele oferece. No entanto, para aplicativos corporativos, um modelo de código fechado como o ChatGPT pode representar riscos, pois as próprias empresas não têm controle sobre seus dados. Embora a OpenAI afirme que os dados do usuário não serão armazenados ou usados para treinar modelos, isso não garante que os dados não vazem de alguma forma.
Para resolver alguns dos problemas associados aos modelos de código fechado, os pesquisadores estão correndo para construir modelos de linguagem ampla (LLMs) de código aberto que competem com modelos como o ChatGPT. Com modelos de código aberto, as empresas podem hospedar modelos em um ambiente de nuvem seguro, reduzindo o risco de violações de dados. Mais importante ainda, você obtém total transparência sobre o funcionamento interno do modelo, o que ajuda os usuários a construir relacionamentos mais confiáveis com os sistemas de IA.
Com os recentes avanços no LLM de código aberto, é tentador experimentar novos modelos e ver como eles se comparam a modelos de código fechado como o ChatGPT.
No entanto, existem enormes barreiras para executar um modelo de código aberto hoje. Por exemplo, é muito mais fácil chamar a API ChatGPT do que entender como executar um LLM de código aberto.
Neste post, pretendo superar as dificuldades mencionadas, mostrando como um modelo de código aberto como o modelo Falcon-7B pode ser executado na nuvem em um ambiente de produção. Eventualmente, poderemos acessar esses modelos por meio de endpoints de API semelhantes ao ChatGPT.
desafio
Um desafio significativo na execução de modelos de código aberto é a falta de recursos de computação. Mesmo um modelo "pequeno" como o Falcon-7B requer uma GPU para funcionar.
Para resolver esse problema, podemos utilizar GPUs na nuvem. No entanto, isso apresenta outro desafio. Como conteinerizamos o LLM? Como ativamos o suporte a GPU? A ativação do suporte a GPU pode ser complicada, pois requer conhecimento de CUDA. Usar CUDA pode ser uma dor porque você precisa descobrir como instalar as dependências CUDA corretas e quais versões são compatíveis.
[Nota do tradutor] CUDA (Compute Unified Device Architecture) é uma plataforma de computação lançada pelo fabricante de placas gráficas NVIDIA. CUDA™ é uma arquitetura de computação paralela de uso geral lançada pela NVIDIA, que inclui a arquitetura do conjunto de instruções CUDA (ISA) e o mecanismo de computação paralela dentro da GPU. Os desenvolvedores podem usar C, C++ e FORTRAN para escrever programas para a arquitetura CUDA™.
Portanto, para evitar a armadilha mortal do CUDA, muitas empresas criaram soluções que podem facilmente contentorizar modelos enquanto oferecem suporte a GPUs. Nesta postagem do blog, usaremos uma ferramenta de código aberto chamada Truss para nos ajudar a conter o LLM facilmente sem muito trabalho.
O Truss permite que os desenvolvedores conteinerizem facilmente os modelos criados com qualquer estrutura.
Por que usar o Truss?
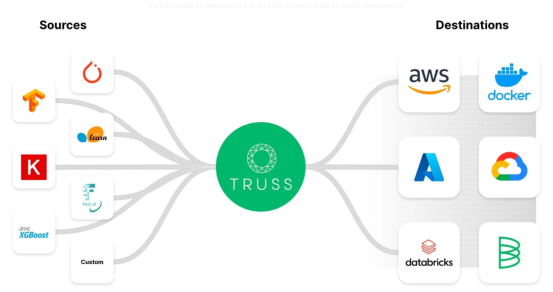
Truss — https://truss.baseten.co/e2e。
O Truss tem muitas funções úteis prontas para uso, como:
- Converta modelos Python em microsserviços com endpoints de API prontos para produção
- Congelar dependências via Docker
- Suporte para inferência de GPU
- Pré-processamento e pós-processamento simples do modelo
- Gerenciamento fácil e seguro de segredos
Já usei o Truss antes para implantar modelos de aprendizado de máquina e o processo foi tranquilo e fácil. O Truss cria automaticamente dockerfiles e gerencia as dependências do Python. Tudo o que precisamos fazer é fornecer o código para o nosso modelo.
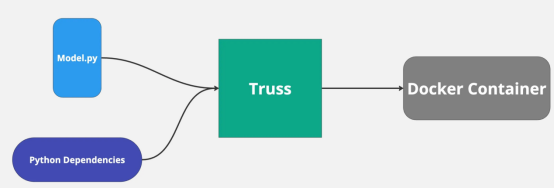
Na verdade, a principal razão pela qual queremos usar uma ferramenta como o Truss é que ela facilita a implantação de nossos modelos com suporte a GPU.
plano
Aqui estão os principais que abordarei neste post do blog:
- Configurando o Falcon 7B localmente com Truss
- Se você tiver uma GPU (tenho uma RTX 3080), execute o modelo localmente
- Conteinerize o modelo e execute-o com o Docker
- Crie um cluster Kubernetes habilitado para GPU no Google Cloud para executar nosso modelo
No entanto, não se preocupe, se a etapa 2 não tiver uma GPU, você ainda poderá executar o modelo na nuvem.
A seguir está o endereço do depósito de código do Github, que contém todo o código relevante descrito posteriormente neste artigo (se você quiser continuar lendo):
https://github.com/htrivedi99/falcon-7b-truss
vamos começar!
Etapa 1: configuração local do Falcon 7B usando treliça
Primeiro, precisamos criar um projeto com Python versão ≥ 3.8.
Em seguida, baixaremos o modelo do site oficial do HuggingFace e usaremos o Truss para embalagem. Aqui estão as dependências que precisamos instalar:
pip install trussEm seguida, crie um script chamado main.py em seu projeto Python. Este é um script temporário que usaremos para processar o Truss.
Em seguida, vamos configurar o pacote Truss executando o seguinte comando no terminal:
truss init falcon_7b_trussPressione 'y' se solicitado a criar uma nova Treliça. Depois de concluído, você deverá ver um novo diretório chamado falcon_7b_truss. Nesse diretório, haverá alguns arquivos e pastas gerados automaticamente. Precisamos preencher os seguintes itens: model.py, que está localizado na pasta model e também é referenciado pelo arquivo config.yaml.

Como mencionei antes, o Truss só precisa do código do nosso modelo, ele cuida de todo o resto automaticamente. Escreveremos o código em model.py, mas deve ser escrito em um formato específico.
A Truss espera que cada modelo suporte pelo menos três funções: __init__, carregar e prever.
- __init__ é usado principalmente para criar variáveis de classe
- load é onde baixamos o modelo do site oficial do HuggingFace
- prever é onde chamamos o modelo Aqui está o código completo de model.py:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from typing import Dict
MODEL_NAME = "tiiuae/falcon-7b-instruct"
DEFAULT_MAX_LENGTH = 128
class Model:
def __init__(self, data_dir: str, config: Dict, **kwargs) -> None:
self._data_dir = data_dir
self._config = config
self.device = "cuda" if torch.cuda.is_available() else "cpu"
print("THE DEVICE INFERENCE IS RUNNING ON IS: ", self.device)
self.tokenizer = None
self.pipeline = None
def load(self):
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model_8bit = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
load_in_8bit=True,
trust_remote_code=True)
self.pipeline = pipeline(
"text-generation",
model=model_8bit,
tokenizer=self.tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
def predict(self, request: Dict) -> Dict:
with torch.no_grad():
try:
prompt = request.pop("prompt")
data = self.pipeline(
prompt,
eos_token_id=self.tokenizer.eos_token_id,
max_length=DEFAULT_MAX_LENGTH,
**request
)[0]
return {"data": data}
except Exception as exc:
return {"status": "error", "data": None, "message": str(exc)}Aqui está o que está acontecendo:
- MODEL_NAME é o modelo que vamos usar, no nosso caso o modelo falcon-7b-instruct
- Dentro da carga, baixamos o modelo de 8 bits do site oficial do HuggingFace. A razão pela qual queremos 8 bits é que o modelo usa significativamente menos memória na GPU quando quantizado.
- Além disso, se você quiser executar o modelo nativamente em uma GPU com menos de 13 GB de VRAM, será necessário carregar o modelo em 8 bits.
- A função de previsão aceita uma solicitação JSON como argumento e invoca o modelo usando self.pipeline. arch.no_grad informa ao Pytorch que estamos no modo de inferência, não no modo de treinamento. É legal! Isso é tudo que precisamos para configurar nosso modelo.
Etapa 2: execute o modelo localmente (opcional)
Se você tiver uma GPU Nvidia com mais de 8 GB de VRAM, poderá executar o modelo localmente.
Se não, prossiga para a próxima etapa.
Precisamos baixar mais dependências para executar o modelo localmente. Antes de baixar as dependências, você precisa ter certeza de ter CUDA e o driver CUDA correto instalado.
Como estávamos tentando executar o modelo localmente, a Truss não pôde nos ajudar a gerenciar o poder do CUDA.
pip install transformers
pip install torch
pip install peft
pip install bitsandbytes
pip install einops
pip install scipy Em seguida, no script main.py criado fora do diretório falcon_7b_truss, precisamos carregar nosso arquivo Truss.
O seguinte é o código de main.py:
import truss
from pathlib import Path
import requests
tr = truss.load("./falcon_7b_truss")
output = tr.predict({"prompt": "Hi there how are you?"})
print(output)Aqui está o que está acontecendo:
- Se você se lembra, o diretório falcon_7b_truss foi criado automaticamente por Truss. Podemos carregar todo o pacote incluindo modelos e dependências usando truss.load
- Depois de carregar nosso pacote, podemos simplesmente chamar o método predict para obter a saída do modelo e executar main.py para obter a saída do modelo. O tamanho deste arquivo de modelo é de aproximadamente 15 GB, portanto, pode levar de 5 a 10 minutos para fazer o download do modelo. Depois de executar o script, você deve ver uma saída como esta:
• {'data': {'generated_text': "Hi there how are you?\nI'm doing well. I'm in the middle of a move, so I'm a bit tired. I'm also a bit overwhelmed. I'm not sure how to get started. I'm not sure what I'm doing. I'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I'm not sure if I'm doing it at all.\nI'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I"}}Etapa 3: empacotar o modelo com o Docker
Normalmente, quando as pessoas colocam um modelo em contêiner, elas pegam o binário do modelo e as dependências do Python e o empacotam com Flask ou um servidor Fast API.
Muito disso é clichê e não precisamos nos preocupar. Truss lida com essas tarefas automaticamente. Fornecemos o modelo e a Truss criará o servidor, então só falta fornecer as dependências do Python.
config.yaml contém a configuração do nosso modelo. É aqui que podemos adicionar dependências aos nossos modelos. O arquivo de configuração já fornece a maior parte do que precisamos, mas ainda precisamos adicionar algumas coisas.
Aqui está o que você precisa adicionar ao seu config.yaml:
apply_library_patches: true
bundled_packages_dir: packages
data_dir: data
description: null
environment_variables: {}
examples_filename: examples.yaml
external_package_dirs: []
input_type: Any
live_reload: false
model_class_filename: model.py
model_class_name: Model
model_framework: custom
model_metadata: {}
model_module_dir: model
model_name: Falcon-7B
model_type: custom
python_version: py39
requirements:
- torch
- peft
- sentencepiece
- accelerate
- bitsandbytes
- einops
- scipy
- git+https://github.com/huggingface/transformers.git
resources:
use_gpu: true
cpu: "3"
memory: 14Gi
secrets: {}
spec_version: '2.0'
system_packages: []Portanto, as principais coisas que adicionamos são sobre requisitos. Todas as dependências listadas são necessárias para baixar e executar o modelo.
Outra coisa importante que adicionamos foram os recursos. use_gpu:true é muito importante porque diz a Truss para criar um Dockerfile para nós com suporte a GPU ativado. Isso é para tarefas de configuração.
Em seguida, vamos conteinerizar nosso modelo. Se você não sabe como empacotar seu modelo com o Docker, não se preocupe, a Truss pode ajudá-lo.
No arquivo main.py, diremos a Truss para empacotar tudo junto. Aqui está o código que você precisa:
import truss
from pathlib import Path
import requests
tr = truss.load("./falcon_7b_truss")
command = tr.docker_build_setup(build_dir=Path("./falcon_7b_truss"))
print(command)o que aconteceu:
- Primeiro, carregamos falcon_7b_truss.
- Em seguida, a função docker_build_setup lida com todas as coisas complicadas, como criar o Dockerfile e configurar o servidor Fast API.
- Se você olhar em seu diretório falcon_7b_truss, verá mais arquivos gerados. Não precisamos nos preocupar com o funcionamento desses arquivos, pois todos serão gerenciados nos bastidores.
- No final da execução, obtemos um comando do Docker para criar nossa imagem do Docker:
docker build falcon_7b_truss -t falcon-7b-model:latest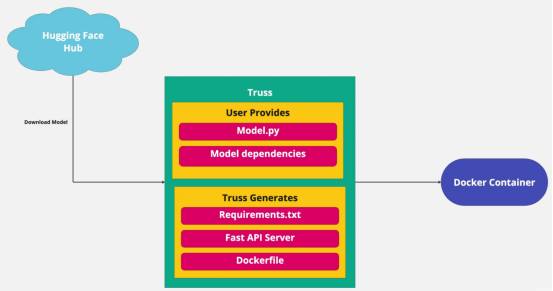
Se você deseja criar uma imagem do Docker, vá em frente e execute o comando build. A imagem tem cerca de 9 GB de tamanho, portanto, pode demorar um pouco para ser criada. Se você não quiser construí-lo, mas quiser continuar lendo, pode dar uma olhada nas fotos que forneci:
htrivedi05/truss-falcon-7b:latest .Se você mesmo criar a imagem, precisará marcá-la e enviá-la para o dockerhub para que nossos contêineres na nuvem possam extrair a imagem. Aqui estão os comandos que precisam ser executados após a criação da imagem:
docker tag falcon-7b-model <docker_user_id>/falcon-7b-model
docker push <docker_user_id>/falcon-7b-modelSurpreendentemente, neste ponto estamos prontos para executar nosso modelo na nuvem!
[Descrição] As seguintes etapas opcionais (antes da etapa 4) são usadas para executar a imagem localmente usando a GPU.
Se você tiver uma GPU Nvidia e quiser executar um modelo em contêiner localmente com suporte a GPU, verifique se o Docker está configurado para usar sua GPU.
Para fazer isso, tudo que você precisa é abrir um terminal e executar o seguinte comando:
distributinotallow=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get update
apt-get install -y nvidia-docker2
sudo systemctl restart dockerAgora que seu Docker está configurado para acessar a GPU, veja como executar o contêiner:
docker run --gpus all -d -p 8080:8080 falcon-7b-modelNovamente, vai demorar um pouco para baixar o modelo. Para ter certeza de que tudo está funcionando, você pode verificar os logs do contêiner e deverá ver "A INFERÊNCIA DO DISPOSITIVO ESTÁ EM EXECUÇÃO NO IS: cuda".
Você pode fazer chamadas para o modelo por meio do ponto de extremidade da API da seguinte maneira:
import requests
data = {"prompt": "Hi there, how's it going?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", jsnotallow=data)
print(res.json())Etapa 4: implantar o modelo na produção
Estou usando a palavra "produção" de forma bem vaga aqui. Executaremos nosso modelo no Kubernetes porque ele pode facilmente escalar e lidar com quantidades variáveis de tráfego nesse ambiente.
Dito isto, o Kubernetes fornece muitas configurações, como políticas de rede, armazenamento, mapas de configuração, balanceamento de carga, gerenciamento de segredos, etc.
Embora o Kubernetes tenha sido criado para "dimensionar" e executar cargas de trabalho de "produção", muitas das configurações de nível de produção necessárias não estão disponíveis prontas para uso. Uma discussão que cobre esses tópicos avançados do Kubernetes está além do escopo deste artigo e é uma distração do que estamos tentando alcançar aqui. Portanto, para esta postagem de blog, criaremos um cluster mínimo do tipo básico.
Sem mais delongas, vamos começar a criar nosso cluster!
pré-requisitos:
- Ter uma conta correspondente do Google Cloud que criou um projeto
- CLI da gcloud instalada com sucesso no seu computador
- Certifique-se de ter cota suficiente para executar seu computador habilitado para GPU. Você pode verificar suas cotas no grupo de comando "IAM & Admin".
Crie nosso cluster do GKE
Usaremos o Kubernetes Engine do Google para criar e gerenciar nosso cluster. Saiba algumas informações importantes abaixo:
O Kubernetes Engine do Google não é gratuito. O Google não nos permite usar uma GPU poderosa de graça. Dito isso, estamos criando um cluster de nó único com GPUs menos potentes. Este experimento não deve custar mais de US$ 1 a US$ 2.
Aqui está a configuração do cluster Kubernetes em que estaremos executando:
- 1 nó, cluster Kubernetes padrão
- 1 GPU Nvidia T4
- máquina n1-standard-4 (4 vCPU, 15 GB de memória)
- Tudo isso será executado em uma Instância Spot
Observação: se você estiver em outra região e não tiver acesso exatamente ao mesmo recurso, sinta-se à vontade para editá-lo.
Etapas para criar um cluster:
1. Acesse o Console do Google Cloud e procure um serviço chamado Kubernetes Engine:
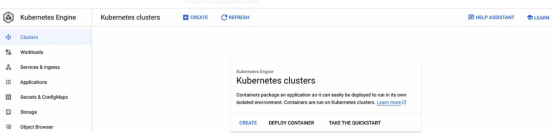
2. Clique no botão "CRIAR":
- Certifique-se de criar um cluster padrão, não um cluster de piloto automático. Deve dizer "Create a kubernetes cluster" na parte superior da página.
3. Fundação do cluster:
- Na guia "Cluster basics", não queremos fazer muitas alterações. Basta dar um nome ao cluster. Você não precisa alterar regiões ou planos de controle.
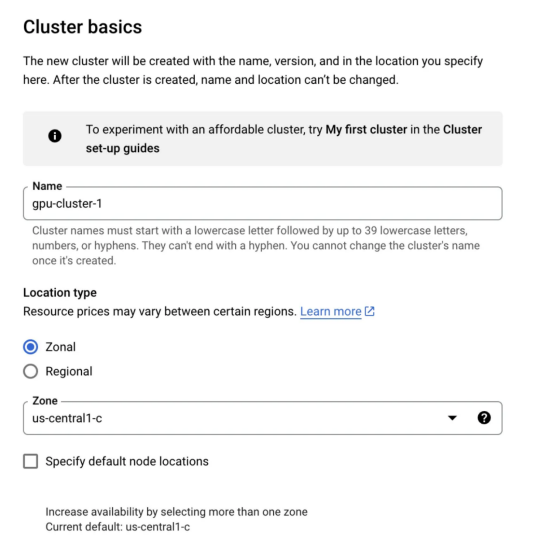
4. Clique na guia pool padrão e altere o número de nós para 1.

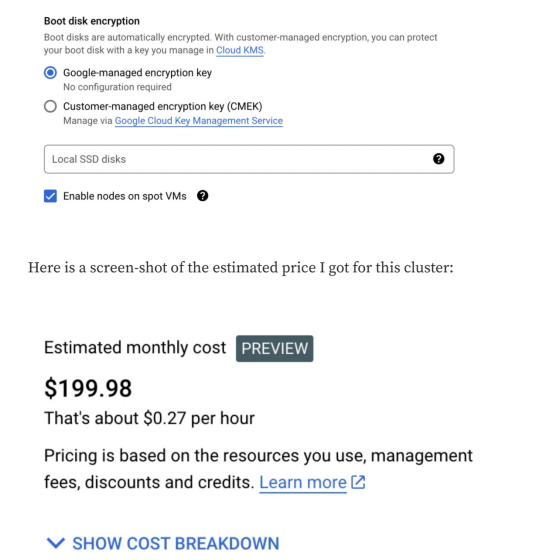
5. Na guia "pool padrão", clique na guia "Nós" na barra lateral esquerda:
- Altere a configuração da máquina (uso geral) de uso geral para GPU
- Selecione Nvidia T4 como o tipo de GPU e defina a quantidade como 1
- Habilite o compartilhamento de tempo da GPU (mesmo que não usemos esse recurso)
- Defina o número máximo de clientes compartilhados por GPU para 8
- Para o tipo de máquina, escolha n1-standard-4 (4 vCPU, 15 GB de memória)
- Altere o tamanho do disco de inicialização para 50
- Role para baixo até o final e marque a caixa que diz: Habilitar nós em VMs pontuais


Após a configuração do cluster, vá em frente e crie o cluster.
O Google leva alguns minutos para configurar tudo. Depois que seu cluster estiver funcionando, precisamos nos conectar a ele. Para fazer isso, abra seu terminal e execute o seguinte comando:
gcloud config set compute/zone us-central1-c
gcloud container clusters get-credentials gpu-cluster-1Se você usou zonas de nome de cluster diferentes, atualize essas zonas de acordo. Para verificar se estamos conectados, execute o seguinte comando:
kubectl get nodesVocê deve ver 1 nó aparecer no seu terminal. Embora nosso cluster tenha uma GPU, faltam alguns drivers Nvidia que precisamos instalar. Felizmente, instalá-los é um piscar de olhos. Execute o seguinte comando para instalar o driver:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yamlVamos comemorar, finalmente estamos prontos para implantar nosso modelo.
modelo de implantação
Para implantar nosso modelo em um cluster, precisamos criar uma implantação do Kubernetes. As implantações do Kubernetes nos permitem gerenciar instâncias do modelo conteinerizado. Aqui, não discutirei o Kubernetes ou como escrever arquivos yaml em profundidade, porque isso está além do escopo do tópico deste artigo.
Você precisa criar um arquivo chamado truss-falcon-deployment.yaml. Abra esse arquivo e cole o seguinte:
apiVersion: apps/v1
kind: Deployment
metadata:
name: truss-falcon-7b
namespace: default
spec:
replicas: 1
selector:
matchLabels:
component: truss-falcon-7b-layer
template:
metadata:
labels:
component: truss-falcon-7b-layer
spec:
containers:
- name: truss-falcon-7b-container
image: <your_docker_id>/falcon-7b-model:latest
ports:
- containerPort: 8080
resources:
limits:
nvidia.com/gpu: 1
---
apiVersion: v1
kind: Service
metadata:
name: truss-falcon-7b-service
namespace: default
spec:
type: ClusterIP
selector:
component: truss-falcon-7b-layer
ports:
- port: 8080
protocol: TCP
targetPort: 8080o que aconteceu:
- Dizemos ao Kubernetes que queremos criar pods com nossa imagem falcon-7b-model. Certifique-se de substituir <your_docker_id> pelo seu id real. Se você não criou sua própria imagem do Docker e deseja usar a minha, substitua-a pelo seguinte: htrivedi05/truss-falcon-7b:latest.
- Habilitamos o acesso à GPU para contêineres definindo um limite de recursos nvidia.com/GPU:1. Isso diz ao Kubernetes para solicitar apenas uma GPU para nosso contêiner.
- Para interagir com nosso modelo, precisamos criar um serviço Kubernetes que será executado na porta 8080.
Crie uma implantação executando o seguinte comando em um terminal:
kubectl create -f truss-falcon-deployment.yamlSe você executar este comando:
kubectl get deploymentsVocê deve ver uma exibição semelhante à seguinte:
NAME READY UP-TO-DATE AVAILABLE AGE
truss-falcon-7b 0/1 1 0 8sLevará alguns minutos para que a implantação mude para o estado pronto. Lembre-se de que o modelo deve ser baixado da página HuggingFace toda vez que o contêiner for reiniciado. Você pode verificar o progresso do contêiner executando:
kubectl get pods
kubectl logs truss-falcon-7b-8fbb476f4-bggtsAltere o nome do pod de acordo.
Você precisa procurar o seguinte nos logs:
- Procure a instrução de impressão THE DEVICE INFERENCE IS RUNNING ON IS: cuda. Isso confirma que nosso contêiner está conectado corretamente à GPU.
Em seguida, você deve ver algumas instruções de impressão sobre o arquivo de modelo que está sendo baixado.
Downloading (…)model.bin.index.json: 100%|██████████| 16.9k/16.9k [00:00<00:00, 1.92MB/s]
Downloading (…)l-00001-of-00002.bin: 100%|██████████| 9.95G/9.95G [02:37<00:00, 63.1MB/s]
Downloading (…)l-00002-of-00002.bin: 100%|██████████| 4.48G/4.48G [01:04<00:00, 69.2MB/s]
Downloading shards: 100%|██████████| 2/2 [03:42<00:00, 111.31s/it][01:04<00:00, 71.3MB/s]Depois de baixar o modelo e criar o microsserviço, você deverá ver a seguinte saída no final do log:
{"asctime": "2023-06-29 21:40:40,646", "levelname": "INFO", "message": "Completed model.load() execution in 330588 ms"}A partir desta mensagem, podemos confirmar que o modelo está carregado e pronto para tarefas de inferência.
modelo de raciocínio
Não podemos chamar o modelo diretamente; em vez disso, devemos chamar o serviço do modelo.
Você pode obter o nome do serviço executando o seguinte comando:
kubectl get svcA saída é a seguinte:
AME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.80.0.1 <none> 443/TCP 46m
truss-falcon-7b-service ClusterIP 10.80.1.96 <none> 8080/TCP 6m19sO que queremos chamar é o serviço truss-falcon-7b. Para tornar o serviço acessível, precisamos encaminhá-lo com o seguinte comando:
kubectl port-forward svc/truss-falcon-7b-service 8080A saída é a seguinte:
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080Lindo, nosso modelo é servido como um endpoint da API REST em 127.0.0.1:8080. Abra qualquer script Python, como main.py, e execute o seguinte código:
import requests
data = {"prompt": "Whats the most interesting thing about a falcon?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", jsnotallow=data)
print(res.json())A saída é a seguinte:
{'data': {'generated_text': 'Whats the most interesting thing about a falcon?\nFalcons are known for their incredible speed and agility in the air, as well as their impressive hunting skills. They are also known for their distinctive feathering, which can vary greatly depending on the species.'}}Uau! Nós conteinerizamos com sucesso o modelo Falcon 7B e o implantamos com sucesso como um microsserviço em produção!
Sinta-se à vontade para usar dicas diferentes para ver o que o modelo retorna.
Desligue o cluster
Quando estiver satisfeito com seu Falcon 7B, você pode excluir sua implantação executando:
kubectl delete -f truss-falcon-deployment.yamlEm seguida, acesse o Kubernetes Engine no Google Cloud e exclua o cluster do Kubernetes.
Nota: Salvo indicação em contrário; caso contrário, todas as imagens neste artigo são fornecidas pelo próprio autor.
para concluir
Embora não seja fácil executar e gerenciar um modelo de nível de produção como o ChatGPT, os desenvolvedores podem implantar melhor seus próprios modelos na nuvem ao longo do tempo.
Nesta postagem do blog, abordamos tudo o que é necessário para implantar o LLM na produção em um nível básico. Para resumir, primeiro precisamos empacotar o modelo usando o Truss, depois conteinerizá-lo usando o Docker e, finalmente, implantá-lo na nuvem usando o Kubernetes. Eu sei que é muito para fazer em detalhes e, embora não tenha sido a coisa mais fácil do mundo, fizemos mesmo assim.
Em conclusão, espero que você tenha aprendido algo interessante com esta postagem no blog. Obrigado por ler!
Veja mais ótimas ferramentas
Elevadores espaciais, MOSS, ChatGPT, etc. indicam que 2023 não está destinado a ser um ano comum. Qualquer nova tecnologia é digna de escrutínio e devemos ter essa sensibilidade.
Nos últimos anos, encontrei vagamente o código baixo, e é relativamente popular no momento, e muitos fabricantes importantes se juntaram um após o outro.
Conceito de plataforma Low-code: Através da geração automática de código e programação visual, apenas uma pequena quantidade de código é necessária para construir rapidamente vários aplicativos.
O que é low-code, na minha opinião, é arrastar, zumbir e operação de uma passagem para criar um sistema que pode executar, front-end, back-end e banco de dados, tudo de uma vez. Claro que este pode ser o objetivo final.
Link: www.jnpfsoft.com/?csdn, caso tenha interesse, experimente também.
A vantagem do JNPF é que ele pode gerar códigos front-end e back-end, o que proporciona grande flexibilidade e pode criar aplicações mais complexas e customizadas. Seu design arquitetônico também permite que os desenvolvedores se concentrem no desenvolvimento da lógica do aplicativo e na experiência do usuário sem se preocupar com os detalhes técnicos subjacentes.