Olá a todos, sou Wei Xue AI. Hoje apresentarei a prática de aprendizado de máquina 9 triagem e análise preditiva do autismo com base em vários modelos. barreiras e comportamentos estereotipados repetitivos. A triagem e análise precoces são cruciais para o diagnóstico e intervenção de crianças com autismo.
Conteúdo
1. Histórico do projeto
2. Significado da pesquisa
3. Prática de código e análise de dados
3.1 Pré-processamento de dados
3.2 Análise de gráficos de dados 4.
Análise do modelo de aprendizado de máquina
4.1 Codificação one-hot de dados
4.2 Classificação de dados
4.3 Modelo de regressão logística
4.4 Modelo de floresta aleatória
4,5 K vizinho mais próximo modelo
4.6 Resultados de execução
5. Resumo
1. Plano de fundo do projeto
O autismo recebeu ampla atenção nas últimas décadas, e sua alta prevalência e impacto de longo prazo nos pacientes e suas famílias são agora reconhecidos. No entanto, devido aos diversos sintomas do autismo e à falta de biomarcadores específicos, seu diagnóstico e tratamento enfrentam grandes desafios. Portanto, a realização de projetos de triagem e análise do autismo pode ajudar a melhorar a precisão do diagnóstico precoce e o efeito da intervenção.
2. Significado da pesquisa
Intervenção Precoce: A intervenção precoce para o autismo é fundamental para o desenvolvimento da criança. Por meio de programas de triagem e análise, os pacientes podem ser detectados precocemente e receber intervenção em tempo hábil, antes que as crianças apresentem sintomas óbvios. Isso ajuda a melhorar as interações sociais do paciente, habilidades de linguagem e desenvolvimento comportamental.
Melhorar a precisão do diagnóstico: o diagnóstico de autismo depende da avaliação clínica de médicos profissionais, mas esse método apresenta o risco de subjetividade e diagnósticos incorretos. Por meio do projeto de triagem e análise, tecnologia científica avançada e métodos de análise de dados podem ser usados para melhorar a precisão do diagnóstico do autismo e reduzir casos perdidos e diagnosticados incorretamente.
Otimizando a alocação de recursos: O diagnóstico e o tratamento do autismo requerem tempo, recursos financeiros e humanos significativos. Por meio de projetos de triagem e análise, podemos entender melhor as características epidemiológicas e o impacto social do autismo, de modo a otimizar a alocação de recursos e fornecer suporte e serviços mais eficazes.
Promova a pesquisa e o acúmulo de conhecimento: os projetos de triagem e análise podem coletar uma grande quantidade de dados, fornecendo recursos e informações valiosas para a pesquisa do autismo. Isso ajudará a obter informações sobre a patogênese, fatores genéticos e possíveis tratamentos do autismo, além de promover o progresso científico no campo do autismo.
3. Combate de código e análise de dados
3.1 Pré-processamento de dados
Antes de tudo, você precisa carregar o conjunto de dados, o endereço de download do conjunto de dados:
Link: https://pan.baidu.com/s/1sfb3_w2o5X7ya7Z0R51Npw?pwd=94we
Código de extração: 94we
# 第三方库导入
import numpy as np # 导入numpy库用于进行线性代数计算
import pandas as pd # 导入pandas库用于数据处理
import matplotlib.pyplot as plt # 导入matplotlib库用于数据可视化
import seaborn as sns # 导入seaborn库用于数据可视化
# 读取数据集1和数据集2
df1 = pd.read_csv('Autism_Data.arff', na_values='?')
df2 = pd.read_csv('Toddler Autism dataset July 2018.csv', na_values='?')
sns.set_style('whitegrid') # 设置seaborn风格为白色网格
# 提取ASD类别为YES的数据(成年人)
data1 = df1[df1['Class/ASD'] == 'YES']
# 提取ASD Traits为Yes的数据(幼儿)
data2 = df2[df2['Class/ASD Traits '] == 'Yes']
# 计算ASD阳性成年人的比例
print("成年人: ", len(data1) / len(df1) * 100)
# 计算ASD阳性幼儿的比例
print("幼儿:", len(data2) / len(df2) * 100)
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
3.2 Análise gráfica de dados
Mapa de calor de valores ausentes para um conjunto de dados adulto
sns.heatmap(data1.isnull(), yticklabels=False, cbar=False, cmap='viridis', ax=ax[0])
ax[0].set_title('成年人数据集')
ax[0].set_ylabel('样本索引')
Valores ausentes do mapa de calor para um conjunto de dados infantil
sns.heatmap(data2.isnull(), yticklabels=False, cbar=False, cmap='viridis', ax=ax[1])
ax[1].set_title('幼儿数据集')
ax[1].set_ylabel('样本索引')
plt.show() # 显示图形
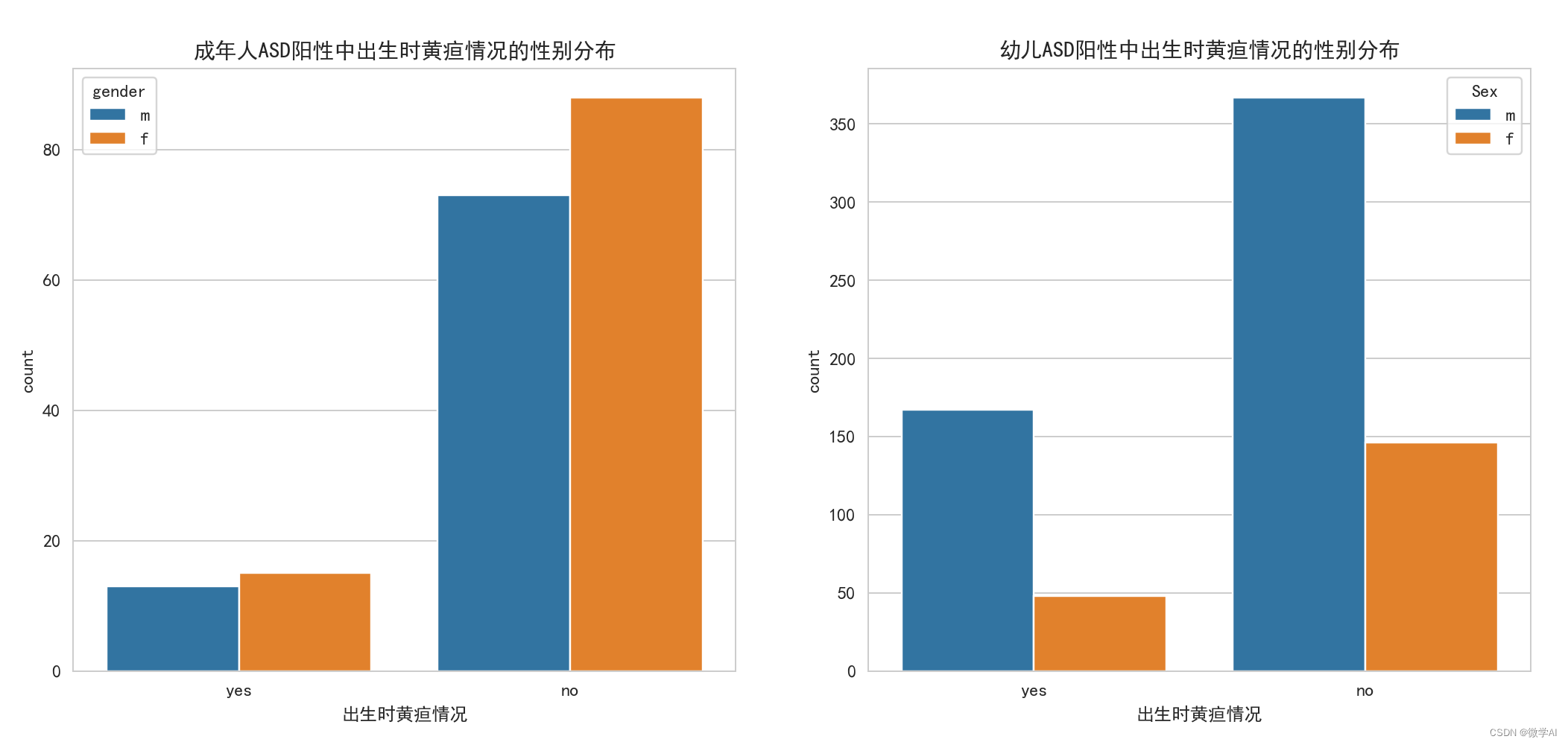
Desenhe um histograma de contagem de icterícia ao nascer em adultos e crianças com TEA positivo
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
# 绘制成年人ASD阳性中出生时黄疸情况的计数柱状图
sns.countplot(x='jundice', data=data1, hue='gender', ax=ax[0])
ax[0].set_title('成年人ASD阳性中出生时黄疸情况的性别分布')
ax[0].set_xlabel('出生时黄疸情况')
# 绘制幼儿ASD阳性中出生时黄疸情况的计数柱状图
sns.countplot(x='Jaundice', data=data2, hue='Sex', ax=ax[1])
ax[1].set_title('幼儿ASD阳性中出生时黄疸情况的性别分布')
ax[1].set_xlabel('出生时黄疸情况')
plt.show() # 显示图形
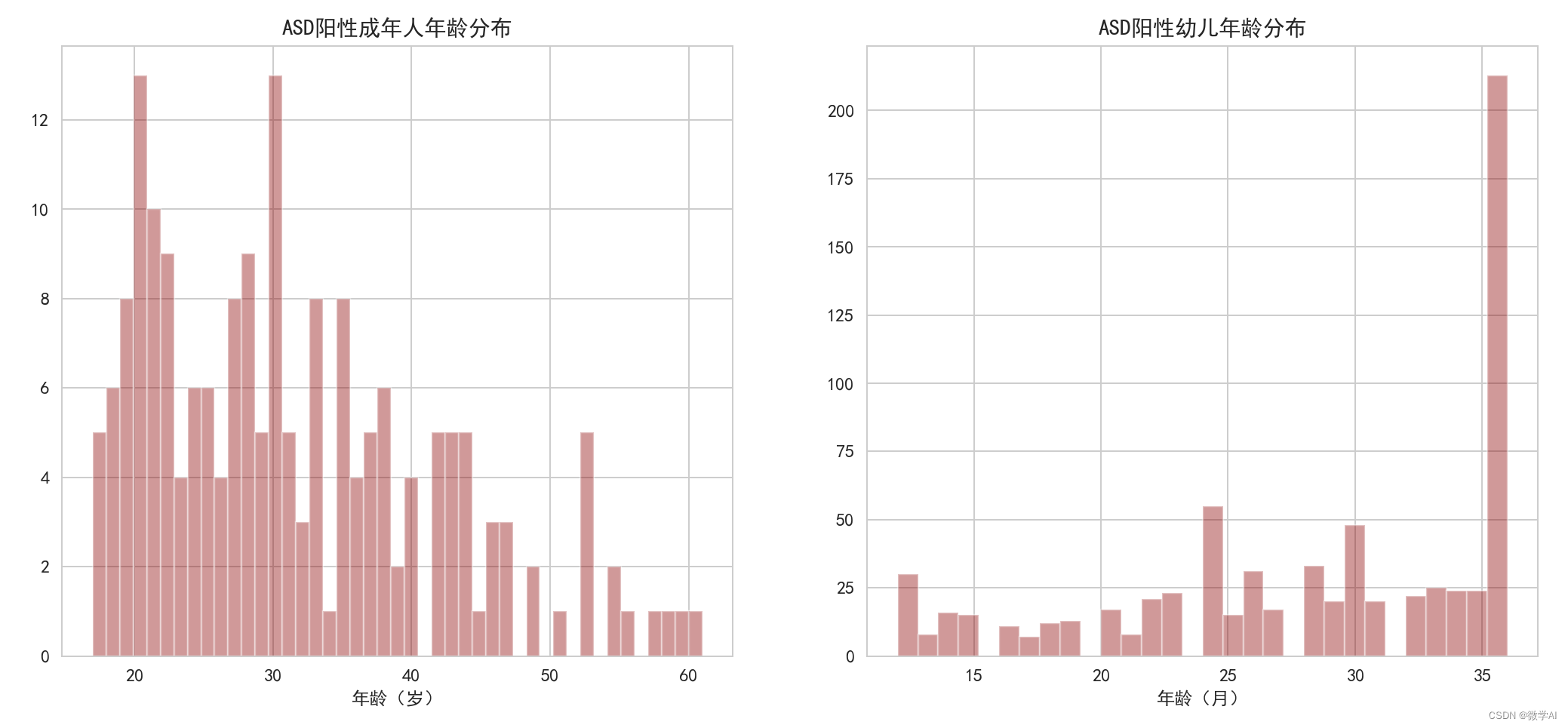
Trace um histograma da distribuição etária da positividade do TEA em adultos, crianças pequenas
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
# 绘制成年人ASD阳性年龄分布的直方图
sns.distplot(data1['age'], kde=False, bins=45, color='darkred', ax=ax[0])
ax[0].set_xlabel('年龄(岁)')
ax[0].set_title('ASD阳性成年人年龄分布')
# 绘制幼儿ASD阳性年龄分布的直方图
sns.distplot(data2['Age_Mons'], kde=False, bins=30, color='darkred', ax=ax[1])
ax[1].set_xlabel('年龄(月)')
ax[1].set_title('ASD阳性幼儿年龄分布')
plt.show() # 显示图形
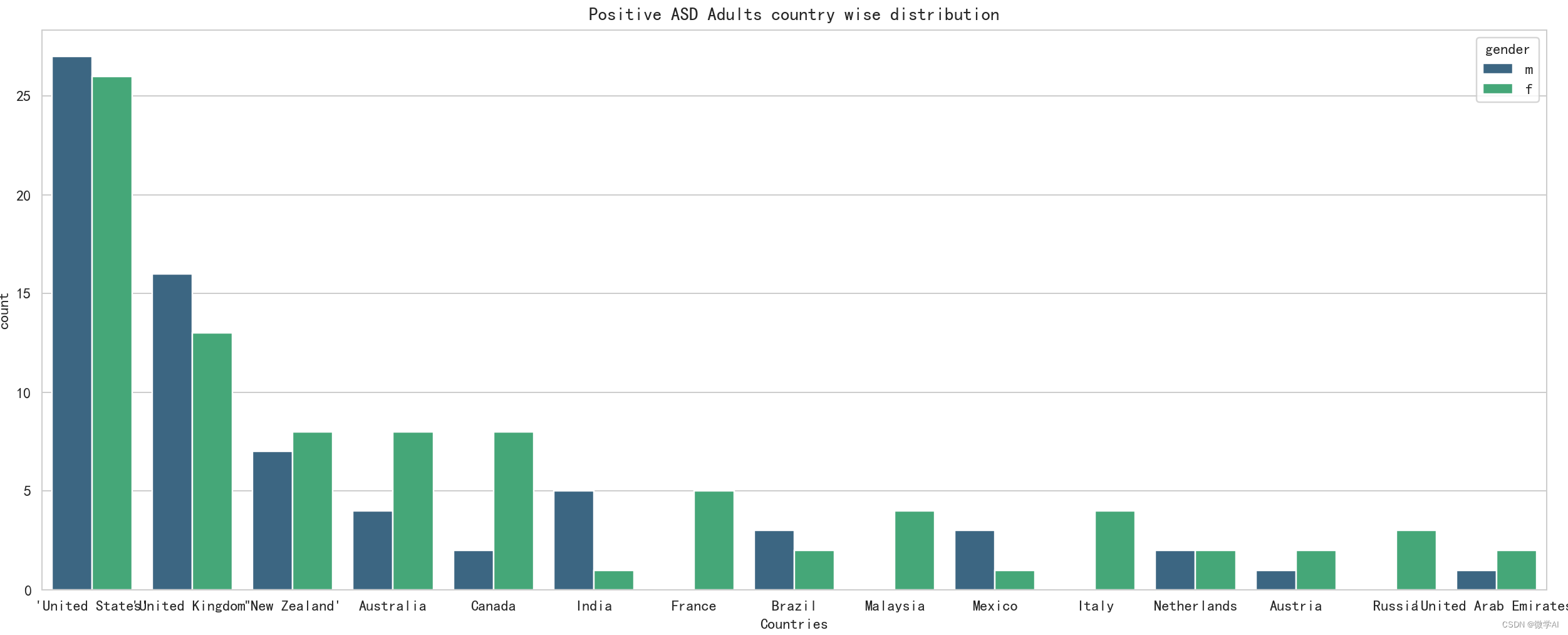
Análise do mapeamento da distribuição por país de adultos com TEA positivo
plt.figure(figsize=(20,6))
sns.countplot(x='contry_of_res',data=data1,order= data1['contry_of_res'].value_counts().index[:15],hue='gender',palette='viridis')
plt.title('Positive ASD Adults country wise distribution')
plt.xlabel('Countries')
plt.tight_layout()
plt.show() # 显示图形
# 输出种族的计数值
print(data1['ethnicity'].value_counts())
data2['Ethnicity'].value_counts()
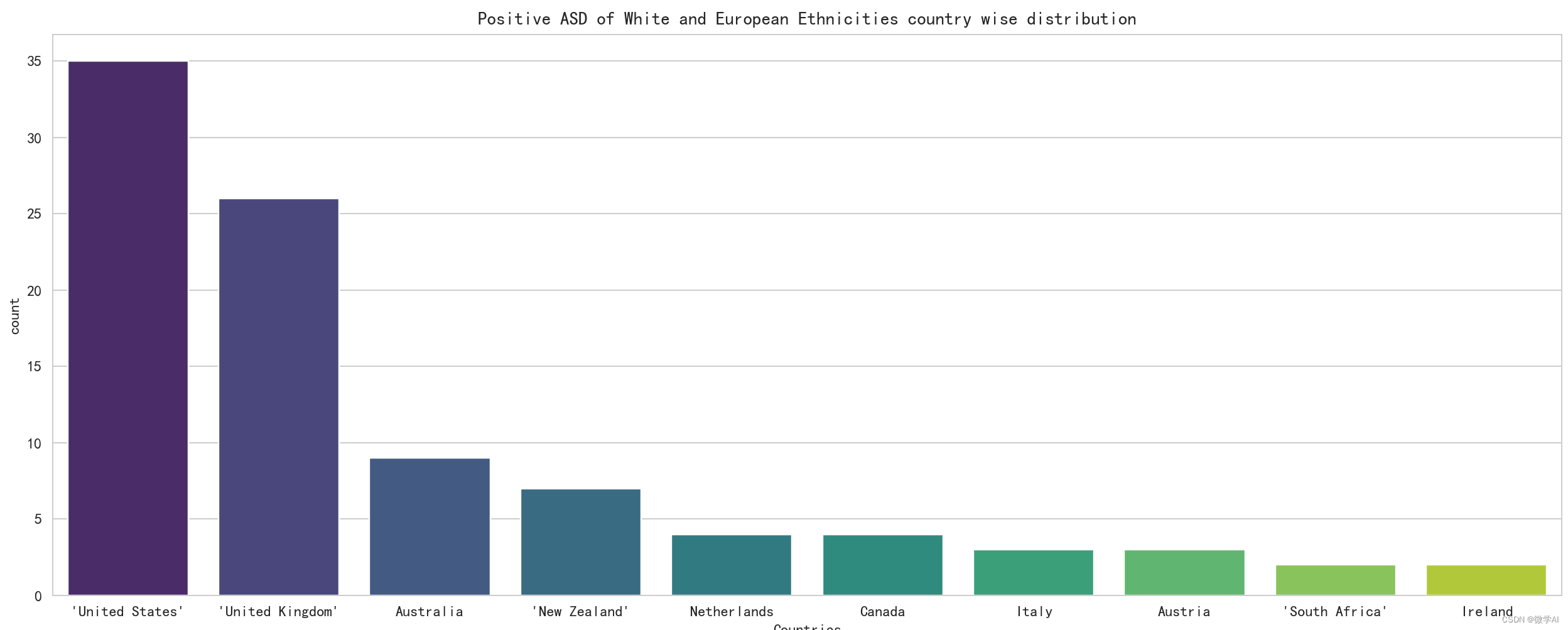
# 绘制白人和欧洲人种族在各个国家的分布图
plt.figure(figsize=(15,6))
sns.countplot(x='contry_of_res',data=data1[data1['ethnicity']=='White-European'],order=data1[data1['ethnicity']=='White-European']['contry_of_res'].value_counts().index[:10],palette='viridis')
plt.title('Positive ASD of White and European Ethnicities country wise distribution')
plt.xlabel('Countries')
plt.tight_layout()
plt.show() # 显示图形
# 绘制不同种族的 ASD 成人亲属中有无自闭症分布和不同种族的 ASD 儿童亲属中有无自闭症分布
fig, ax = plt.subplots(1,2,figsize=(20,6))
sns.countplot(x='austim',data=data1,hue='ethnicity',palette='rainbow',ax=ax[0])
ax[0].set_title('Positive ASD Adult relatives with Autism distribution for different ethnicities')
ax[0].set_xlabel('Adult Relatives with ASD')
sns.countplot(x='Family_mem_with_ASD',data=data2,hue='Ethnicity',palette='rainbow',ax=ax[1])
ax[1].set_title('Positive ASD Toddler relatives with Autism distribution for different ethnicities')
ax[1].set_xlabel('Toddler Relatives with ASD')
plt.tight_layout()
4. Análise do modelo de aprendizado de máquina
4.1 Codificação one-hot de dados
within24_36= pd.get_dummies(df2['Age_Mons']>24,drop_first=True) # 大于24个月的为1,否则为0
within0_12 = pd.get_dummies(df2['Age_Mons']<13,drop_first=True) # 小于13个月的为1,否则为0
male=pd.get_dummies(df2['Sex'],drop_first=True) # 性别为男性的为1,否则为0
ethnics=pd.get_dummies(df2['Ethnicity'],drop_first=True) # 使用独热编码表示种族
jaundice=pd.get_dummies(df2['Jaundice'],drop_first=True) # 是否有黄疸,有黄疸为1,否则为0
ASD_genes=pd.get_dummies(df2['Family_mem_with_ASD'],drop_first=True) # 亲属中是否有自闭症,有自闭症为1,否则为0
ASD_traits=pd.get_dummies(df2['Class/ASD Traits '],drop_first=True) # ASD 特征,有特征为1,否则为0
4.2 Coleta de dados
import pandas as pd
# 将多个数据集按列合并
final_data = pd.concat([within0_12, within24_36, male, ethnics, jaundice, ASD_genes, ASD_traits], axis=1)
# 设置列名
final_data.columns = ['within0_12', 'within24_36', 'male', 'Latino', 'Native Indian', 'Others', 'Pacifica', 'White European', 'asian', 'black', 'middle eastern', 'mixed', 'south asian', 'jaundice', 'ASD_genes', 'ASD_traits']
# 显示合并后的数据的前几行
final_data.head()
from sklearn.model_selection import train_test_split
# 划分特征和标签
X = final_data.iloc[:, :-1]
y = final_data.iloc[:, -1]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
4.3 Modelo de regressão logística
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型
logmodel = LogisticRegression()
# 在训练集上训练逻辑回归模型
logmodel.fit(X_train, y_train)
from sklearn.model_selection import GridSearchCV
# 设置网格搜索的参数
param_grid = {
'C': [0.01, 0.1, 1, 10, 100, 1000]}
# 创建逻辑回归模型的网格搜索对象
grid_log = GridSearchCV(LogisticRegression(), param_grid, refit=True)
# 在训练集上进行网格搜索
grid_log.fit(X_train, y_train)
print('GridSearchCV')
# 输出网格搜索得到的最佳模型参数
print(grid_log.best_estimator_)
# 使用网格搜索得到的最佳模型在测试集上进行预测
pred_log = grid_log.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
# 输出逻辑回归模型在测试集上的混淆矩阵和分类报告
print(confusion_matrix(y_test, pred_log))
print(classification_report(y_test, pred_log))
4.4 Modelo de Floresta Aleatória
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rfc = RandomForestClassifier(n_estimators=100)
# 在训练集上训练随机森林分类器
rfc.fit(X_train, y_train)
# 使用随机森林分类器在测试集上进行预测
pred_rfc = rfc.predict(X_test)
print('RandomForestClassifier')
# 输出随机森林分类器在测试集上的混淆矩阵和分类报告
print(confusion_matrix(y_test, pred_rfc))
print(classification_report(y_test, pred_rfc))
Modelo de vizinho mais próximo de 4,5 K
from sklearn.preprocessing import StandardScaler
# 对特征进行标准化处理
scaler = StandardScaler()
scaler.fit(X)
scaled_features = scaler.transform(X)
X_scaled = pd.DataFrame(scaled_features, columns=X.columns)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=101)
from sklearn.neighbors import KNeighborsClassifier
# 计算不同的K值下的分类错误率
error_rate = []
for i in range(1, 50):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
# 绘制K值和错误率的关系图
plt.figure(figsize=(10, 6))
plt.plot(range(1, 50), error_rate, color='blue', linestyle='dashed', marker='o', markerfacecolor='red', markersize=10)
plt.title('Error rate vs K-value')
plt.xlabel('K')
plt.ylabel('Error Rate')
# 根据错误率最低的K值创建K近邻分类器
knn = KNeighborsClassifier(n_neighbors=13)
knn.fit(X_train, y_train)
# 使用K近邻分类器在测试集上进行预测
pred_knn = knn.predict(X_test)
print(confusion_matrix(y_test, pred_knn))
print(classification_report(y_test, pred_knn))
4.6 Resultados de Corrida
Modelo de regressão logística:
precision recall f1-score support
0 0.00 0.00 0.00 78
1 0.63 1.00 0.77 133
accuracy 0.63 211
macro avg 0.32 0.50 0.39 211
weighted avg 0.40 0.63 0.49 211
Modelo de floresta aleatório:
precision recall f1-score support
0 0.71 0.37 0.49 78
1 0.71 0.91 0.80 133
accuracy 0.71 211
macro avg 0.71 0.64 0.64 211
weighted avg 0.71 0.71 0.68 211
K modelo de classificação do vizinho mais próximo:
precision recall f1-score support
0 0.68 0.32 0.43 78
1 0.70 0.91 0.79 133
accuracy 0.69 211
macro avg 0.69 0.62 0.61 211
weighted avg 0.69 0.69 0.66 211
5. Resumo
Este artigo analisa a situação do autismo por meio do conjunto de dados Toddler Autism July 2018.csv e realiza uma análise visual por meio de código e gráficos, nos quais as funções são usadas para combinar vários pd.concat()conjuntos de dados em um final_dataconjunto de dados por coluna. Em seguida, separe os recursos e rótulos e use train_test_split()uma função para dividir os dados em conjuntos de treinamento e teste.
Neste artigo, o modelo de regressão logística de busca em grade, o modelo de floresta aleatória e o classificador K-vizinho mais próximo são usados para treinar o conjunto de treinamento e fazer previsões sobre o conjunto de teste. Finalmente, produza a matriz de confusão e o relatório de classificação do modelo para avaliar o desempenho do modelo.
Entre eles, depois que as características são padronizadas, o valor K é usado para pesquisar no intervalo de 1 a 49, e o valor K com a menor taxa de erro é encontrado, e o classificador final K-vizinho mais próximo é criado para previsão e avaliação .