O mecanismo de persistência Redis pertence aos pontos de conhecimento de entrevista de alta frequência das entrevistas de back-end. É um clichê e leva tempo para dominá-lo. Mesmo que você não esteja se preparando para uma entrevista, o desenvolvimento diário precisa ser usado com frequência.
Recentemente, dediquei um tempo para melhorar bastante o mecanismo de persistência do Redis que escrevi antes, com imagens e textos claros e fáceis de entender. Compartilhe, espero que te ajude!
Visão geral do conteúdo:

Ao usar o cache, muitas vezes precisamos persistir os dados na memória, ou seja, gravar os dados da memória no disco rígido. A maioria dos motivos é reutilizar dados posteriormente (como reiniciar a máquina, recuperar dados após uma falha da máquina) ou para sincronização de dados (como os nós mestre e escravo do cluster Redis sincronizam dados por meio de arquivos RDB).
Um ponto importante que diferencia o Redis do Memcached é que o Redis suporta persistência e suporta três métodos de persistência:
- Instantâneo (instantâneo, RDB)
- Anexar apenas arquivo (arquivo somente anexar, AOF)
- Persistência híbrida de RDB e AOF (novo no Redis 4.0)
Endereço oficial do documento: redis.io/topics/pers… .

persistência RDB
O que é persistência RDB?
O Redis pode obter uma cópia dos dados armazenados na memória em um determinado momento criando um instantâneo . Depois que o Redis cria um instantâneo, o instantâneo pode ser copiado, o instantâneo pode ser copiado para outros servidores para criar uma cópia do servidor com os mesmos dados (estrutura mestre-escravo do Redis, usada principalmente para melhorar o desempenho do Redis) e o instantâneo pode ser deixado no local para reiniciar o servidor quando usado.
A persistência de instantâneo é o método de persistência padrão adotado pelo Redis, que é redis.confconfigurado por padrão no arquivo de configuração:
clojure
copiar código
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。 save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。 save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
O RDB bloqueará o thread principal ao criar um instantâneo?
O Redis fornece dois comandos para gerar arquivos de instantâneo RDB:
save: A operação de salvamento síncrona bloqueará o thread principal do Redis;bgsave: Bifurca um processo filho, o processo filho será executado sem bloquear o thread principal do Redis, a opção padrão.
O principal motivo para dizer o thread principal do Redis em vez do processo principal aqui é que, após o início do Redis, ele conclui principalmente o trabalho principal de uma maneira de thread único. Se você quiser descrevê-lo como o processo mestre do Redis, tudo bem.
persistência AOF
O que é persistência AOF?
Comparado com a persistência de instantâneo, a persistência AOF tem melhor desempenho em tempo real. Por padrão, o Redis não habilita a persistência AOF (append only file) (foi habilitada por padrão após o Redis 6.0), que pode ser appendonlyhabilitada pelos parâmetros:
bash
copiar código
appendonly yes
Após a ativação da persistência AOF, toda vez que um comando que alterará os dados no Redis for executado, o Redis gravará o comando no buffer AOF server.aof_bufe, em seguida, gravará no arquivo AOF (neste momento, o buffer do kernel do sistema não está sincronizado para o disco) e finalmente fsyncdecidir quando sincronizar os dados no cache do kernel do sistema para o disco rígido de acordo com a configuração do método de persistência ( estratégia).
Somente quando sincronizado com o disco pode ser considerado como armazenamento persistente, caso contrário, ainda há risco de perda de dados. Por exemplo, se os dados na área de buffer do kernel do sistema não tiverem sido sincronizados e a máquina de disco cair, então esta parte dos dados será perdida.
O local de salvamento do arquivo AOF é o mesmo do arquivo RDB, ambos definidos dirpor parâmetros, e o nome do arquivo padrão é appendonly.aof.
Qual é o processo básico do trabalho AOF?
A implementação da função de persistência AOF pode ser simplesmente dividida em 5 etapas:
- Anexar comando (acrescentar) : Todos os comandos de gravação serão anexados ao buffer AOF.
- Gravação de arquivo (gravação) : grava os dados no buffer AOF no arquivo AOF. Esta etapa precisa chamar
writeuma função (chamada do sistema) ewriteretornar diretamente após a gravação dos dados no buffer do kernel do sistema (gravação atrasada). Perceber! ! ! Não há sincronização com o disco neste momento. - Sincronização de arquivos (fsync)
fsync: O buffer AOF é sincronizado com o disco rígido de acordo com o método de persistência correspondente ( estratégia). Esta etapa precisa chamarfsynca função (chamada do sistema)fsyncpara executar a sincronização forçada do disco rígido para uma única operação de arquivo efsyncficará bloqueada até que a gravação no disco seja concluída e retorne, garantindo a persistência dos dados. - Regravação de arquivo (reescrita) : À medida que o arquivo AOF se torna cada vez maior, é necessário reescrever o arquivo AOF periodicamente para atingir o objetivo da compactação.
- Reinicie o carregamento (carga) : Quando o Redis é reiniciado, o arquivo AOF pode ser carregado para recuperação de dados.
O sistema Linux fornece diretamente algumas funções para acessar e controlar arquivos e dispositivos, e essas funções são chamadas de chamadas de sistema (syscall) .
Aqui está outra explicação de algumas das chamadas do sistema Linux mencionadas acima:
write: Retorna diretamente após gravar no buffer do kernel do sistema (basta gravar no buffer) e não será sincronizado com o disco rígido imediatamente. Ao melhorar a eficiência, também traz o risco de perda de dados. A operação síncrona do disco rígido geralmente depende do mecanismo de agendamento do sistema, o kernel do Linux geralmente sincroniza a cada 30 segundos e o valor específico depende da quantidade de dados gravados e do estado do buffer de E/S.fsync:fsyncÉ usado para forçar a atualização do buffer do kernel do sistema (sincronizado com o disco), para garantir que a operação de gravação do disco seja concluída antes de retornar.
O fluxograma do fluxo de trabalho AOF é o seguinte:

Quais são os métodos de persistência AOF?
Existem três métodos ( fsyncestratégias) de persistência AOF diferentes no arquivo de configuração do Redis, que são:
appendfsync always: Depois que o thread principal chamarwritea operação de gravação, o thread de segundo plano (aof_fsyncthread) chamará imediatamentefsynca função para sincronizar o arquivo AOF (deslize o disco) efsynco thread retornará após a conclusão, o que reduzirá seriamente o desempenho do Redis (write+fsync).appendfsync everysec: O thread principal chama ewriteretorna imediatamente após executar a operação de gravação, e o thread de segundo plano (aof_fsyncthread) chamafsynca função (chamada do sistema) a cada segundo para sincronizar o arquivo AOF (write+fsync,fsynco intervalo é de 1 segundo)appendfsync no: Chamado pelo thread principalwriteRetorne imediatamente após executar a operação de gravação, deixe o sistema operacional decidir quando sincronizar, geralmente a cada 30 segundos no Linux (writemas nãofsync,fsynco tempo é determinado pelo sistema operacional).
Pode-se ver que a principal diferença entre esses três métodos de persistência está no fsynctempo de sincronização dos arquivos AOF (disco brushing) .
Para equilibrar os dados e o desempenho de gravação, você pode considerar appendfsync everyseca opção de permitir que o Redis sincronize arquivos AOF uma vez por segundo, e o desempenho do Redis será menos afetado. E desta forma, mesmo que o sistema falhe, o usuário só perderá os dados gerados em no máximo um segundo. Quando o disco rígido está ocupado executando operações de gravação, o Redis também diminui graciosamente sua velocidade para se adaptar à velocidade máxima de gravação do disco rígido.
A partir do Redis 7.0.0, o Redis usa o mecanismo Multi Part AOF . Como o nome indica, Multi Part AOF é para dividir o arquivo AOF único original em vários arquivos AOF. No Multi Part AOF, os arquivos AOF são divididos em três tipos, a saber:
- BASE: Indica o arquivo AOF básico, que geralmente é gerado por subprocessos através de reescrita, e possui no máximo um arquivo.
- INCR: Indica o arquivo AOF incremental, que geralmente é criado quando o AOFRW começa a ser executado, podendo haver vários arquivos.
- HISTORY: Indica o arquivo AOF histórico, que é alterado de BASE e INCR AOF. Toda vez que o AOFRW for concluído com sucesso, o BASE e o INCR AOF correspondentes antes deste AOFRW se tornarão HISTORY, e o AOF do tipo HISTORY será excluído automaticamente pelo Redis.
Multi Part AOF não é o ponto chave, apenas entenda. Para uma introdução detalhada, você pode ler o artigo sobre o design e implementação do Redis 7.0 Multi Part AOF por desenvolvedores do Alibaba .
Problema relacionado : Método Redis AOF #783 .
Por que o AOF registra o log após a execução do comando?
Bancos de dados relacionais (como o MySQL) geralmente registram logs antes de executar comandos (para facilitar a recuperação de falhas), enquanto o mecanismo de persistência Redis AOF registra logs após a execução de comandos.
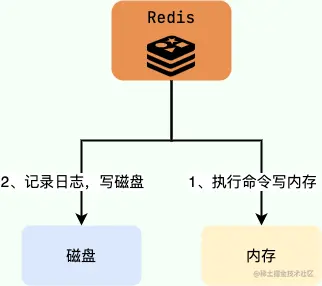
Por que o log é gravado após a execução do comando?
- Para evitar sobrecarga de verificação adicional, o log AOF não executará a verificação de sintaxe nos comandos;
- A gravação após a execução do comando não bloqueará a execução do comando atual.
Isso também traz riscos (também mencionei isso quando introduzi a persistência AOF):
- Se o Redis travar logo após a execução do comando, a modificação correspondente será perdida;
- Ele pode bloquear a execução de outros comandos subsequentes (o log AOF é executado no thread principal do Redis).
Você entende a reescrita AOF?
Quando o AOF fica muito grande, o Redis pode reescrever automaticamente o AOF em segundo plano para gerar um novo arquivo AOF. Esse novo arquivo AOF é o mesmo que o estado do banco de dados salvo pelo arquivo AOF original, mas menor em tamanho.

AOF rewrite (reescrita) é um nome ambíguo. Esta função é realizada lendo os pares chave-valor no banco de dados. O programa não precisa executar nenhuma operação de leitura, análise ou gravação nos arquivos AOF existentes.
Como a reescrita AOF executará um grande número de operações de gravação, para evitar afetar o processamento normal de solicitações de comando do Redis, o Redis coloca o programa de reescrita AOF em um subprocesso para execução.
Durante a regravação do arquivo AOF, o Redis também mantém um buffer de regravação AOF , que registra todos os comandos de gravação executados pelo servidor durante o processo filho que cria um novo arquivo AOF. Quando o processo filho concluir o trabalho de criação de um novo arquivo AOF, o servidor anexará todo o conteúdo no buffer de reescrita ao final do novo arquivo AOF, para que o estado do banco de dados salvo no novo arquivo AOF seja consistente com o existente estado do banco de dados. Por fim, o servidor substitui o arquivo AOF antigo pelo novo arquivo AOF para concluir a operação de regravação do arquivo AOF.
Para habilitar a função de reescrita AOF, você pode chamar BGREWRITEAOFo comando para executá-lo manualmente ou pode definir os dois itens de configuração a seguir para permitir que o programa determine automaticamente o tempo de disparo:
auto-aof-rewrite-min-size: Se o tamanho do arquivo AOF for menor que este valor, a regravação AOF não será acionada. O valor padrão é 64 MB;auto-aof-rewrite-percentage: Ao executar a reescrita AOF, a proporção do tamanho AOF atual (aof_current_size) para o tamanho AOF anterior (aof_base_size) ao reescrever. Se o tamanho do arquivo AOF atual aumentar nesse valor percentual, a reescrita AOF será acionada. Definir esse valor como 0 desativará a regravação automática de AOF. O valor padrão é 100.
Antes da versão 7.0 do Redis, se houver comandos de gravação durante a reescrita, o AOF pode usar muita memória e todos os comandos de gravação que chegarem durante a reescrita serão gravados no disco duas vezes.
Após a versão 7.0 do Redis, o mecanismo de reescrita AOF foi otimizado e aprimorado. O parágrafo a seguir foi extraído do artigo Seeing the past and future of Redis from the release of Redis7.0 by Alibaba developers .
Como lidar com dados incrementais durante a reescrita AOF sempre foi um problema. No passado, os dados incrementais durante a gravação precisavam ser mantidos na memória. Após a gravação, essa parte dos dados incrementais deveria ser gravada em um novo arquivo AOF para garantir a integridade dos dados . Pode-se ver que a gravação AOF consumirá memória adicional e E/S de disco, que também é o ponto problemático da gravação Redis AOF. Embora muitas melhorias tenham sido feitas antes, o problema essencial do consumo de recursos não foi resolvido.
O Redis Enterprise Edition do Alibaba Cloud também encontrou esse problema no início. Após várias iterações de desenvolvimento interno, implementou o mecanismo AOF de várias partes para resolvê-lo. Ao mesmo tempo, também contribuiu para a comunidade e o lançou com esta versão 7.0 . O método específico é usar o método de armazenamento de arquivo independente base (dados completos) + inc (dados incrementais) para resolver completamente o desperdício de memória e recursos de E/S, além de oferecer suporte à preservação e gerenciamento de arquivos AOF históricos. Combinado com as informações de tempo em arquivos AOF, o PITR pode ser restaurado por ponto no tempo (já suportado pelo Alibaba Cloud Enterprise Edition Tair), o que aumenta ainda mais a confiabilidade dos dados do Redis e atende às necessidades dos usuários para reversão de dados.
Problema relacionado : a descrição de reescrita do Redis AOF é #1439 imprecisa .
Você entende o mecanismo de verificação AOF?
O mecanismo de verificação AOF é que o Redis verifica o arquivo AOF na inicialização para determinar se o arquivo está completo e se há dados danificados ou perdidos. O princípio desse mecanismo é realmente muito simples, é verificar o arquivo AOF usando um número chamado checksum (checksum) . Essa soma de verificação é um número calculado pelo algoritmo CRC64 em todo o conteúdo do arquivo AOF. Se o conteúdo do arquivo for alterado, a soma de verificação também será alterada. Portanto, quando o Redis iniciar, ele irá comparar a soma de verificação calculada com a soma de verificação salva no final do arquivo (o conteúdo da última linha salvando a soma de verificação será ignorado no cálculo), para julgar se o arquivo AOF está completo. Se encontrar um problema com o arquivo, o Redis se recusará a iniciar e fornecerá uma mensagem de erro apropriada. O mecanismo de verificação AOF é muito simples e eficaz, o que pode melhorar a confiabilidade dos dados do Redis.
Da mesma forma, o arquivo RDB também possui um mecanismo de verificação semelhante para garantir a exatidão do arquivo RDB, que não será repetido aqui.
Quais otimizações o Redis 4.0 fez para o mecanismo de persistência?
Como RDB e AOF têm vantagens próprias, o Redis 4.0 passou a oferecer suporte à persistência híbrida de RDB e AOF (fechada por padrão e pode ser aof-use-rdb-preamblehabilitada por meio de itens de configuração).
Se a persistência híbrida estiver ativada, quando o AOF for reescrito, o conteúdo do RDB será gravado diretamente no início do arquivo AOF. A vantagem disso é que ele pode combinar as vantagens de RDB e AOF, carregamento rápido e evitar a perda de muitos dados. Claro, também existem desvantagens: a parte RDB em AOF está no formato compactado e não está mais no formato AOF, portanto, a legibilidade é ruim.
Endereço oficial do documento: redis.io/topics/pers…

Como escolher RDB e AOF?
Com relação às vantagens e desvantagens de RDB e AOF, o site oficial também fornece uma descrição mais detalhada da persistência do Redis . Aqui está um breve resumo com base no meu próprio entendimento.
RDB é melhor que AOF :
- O conteúdo armazenado no arquivo RDB são dados binários compactados, que salvam um conjunto de dados em um determinado momento. O arquivo é pequeno e adequado para backup de dados e recuperação de desastres. O arquivo AOF armazena cada comando de gravação, semelhante ao log binário do MySQL, e geralmente é muito maior que o arquivo RDB. Quando o AOF fica muito grande, o Redis pode reescrever automaticamente o AOF em segundo plano. O novo arquivo AOF salva o mesmo estado do banco de dados do arquivo AOF original, mas o tamanho é menor. No entanto, antes da versão 7.0 do Redis, se houver comandos de gravação durante a reescrita, o AOF pode usar muita memória e todos os comandos de gravação que chegarem durante a reescrita serão gravados no disco duas vezes.
- Use arquivos RDB para restaurar dados, apenas analise e restaure os dados diretamente, sem executar comandos um por um, a velocidade é muito rápida. No entanto, o AOF precisa executar cada comando de gravação por vez, o que é muito lento. Ou seja, em comparação com o AOF, o RDB é mais rápido ao restaurar grandes conjuntos de dados.
AOF é melhor que RDB :
- A segurança dos dados do RDB não é tão boa quanto a do AOF e não há como persistir os dados em tempo real ou no segundo nível. O processo de geração do arquivo RDB é relativamente pesado. Embora o trabalho do processo filho BGSAVE escrevendo o arquivo RDB não bloqueie o thread principal, ele terá um impacto nos recursos da CPU e nos recursos de memória da máquina. AOF suporta perda de dados de segundo nível (dependendo da estratégia fsync, se for a cada segundo, os dados serão perdidos por no máximo 1 segundo), é apenas para anexar comandos ao arquivo AOF e a operação é leve.
- Os arquivos RDB são salvos em um formato binário específico e existem várias versões do RDB na evolução das versões do Redis, portanto, há um problema de que a versão antiga do serviço Redis não é compatível com a nova versão do formato RDB.
- AOF contém logs de todas as operações em um formato fácil de entender e analisar. Você pode exportar facilmente arquivos AOF para análise e também pode manipular arquivos AOF diretamente para resolver alguns problemas. Por exemplo, se o
FLUSHALLcomando de execução atualizar acidentalmente todo o conteúdo, desde que o arquivo AOF não tenha sido reescrito, exclua o comando mais recente e reinicie para restaurar o estado anterior.
Resumindo :
- Se os dados salvos pelo Redis forem perdidos e não importa, você pode optar por usar o RDB.
- O AOF sozinho não é recomendado, pois criar um instantâneo RDB de tempos em tempos permite backups de banco de dados, reinicializações mais rápidas e resolve erros do mecanismo AOF.
- Se os dados salvos exigirem alta segurança, é recomendável habilitar a persistência RDB e AOF ao mesmo tempo ou habilitar a persistência híbrida RDB e AOF.