
Autor | Yuan Gungun
Editor a cargo | Tang Xiaoyin
Producido | Campamento base de tecnología de IA de CSDN
El profesor Aravind Joshi (Aravind Joshi), quien definió la gramática de adyacencia de árboles (TAG), propuso una vez que "si no hay un punto de referencia para evaluar el modelo, es como un astrónomo que no construye un telescopio y quiere ver las estrellas ."
Hasta ahora, se han lanzado cientos de modelos a gran escala en el país y en el extranjero, pero no importa qué tipo de modelo a gran escala, en la etapa de debut, sin excepción, enfatizan sus propios parámetros y puntajes en varios puntos de referencia de evaluación.
Por ejemplo, no hace mucho, Meta acaba de anunciar el código abierto y el soporte para el comercial Llama2, y utiliza explícitamente MMLU, TriviaQA, Natural Questions, GSM8K, HumanEval, BoolQ, HellaSwag, OpenBookQA, QuAC, Winogrande y otros conjuntos de datos para la evaluación. En el Informe técnico GPT-4 , OpenAI muestra en detalle los resultados en varios tipos de exámenes, así como el desempeño en puntos de referencia académicos como MMLU, HellaSwag, ARC, WinoGrande, HumanEval y DROP.
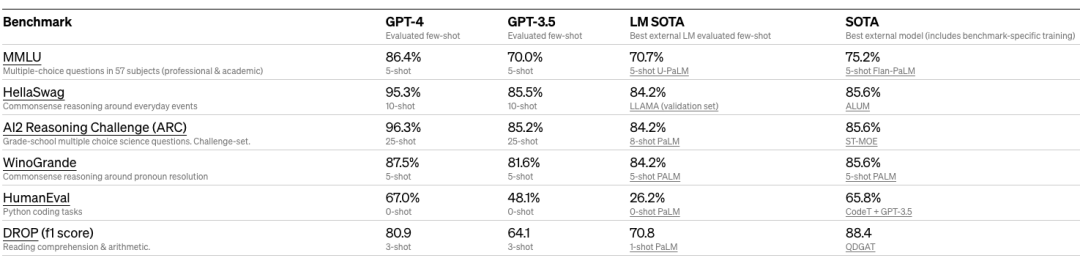
Comparación de varios puntos de referencia de GPT-4 (fuente: Informe técnico de GPT-4 )
Debido a que las bases y caminos técnicos de cada modelo son diferentes, los dos tipos de indicadores, la cantidad de parámetros y la puntuación del benchmark de evaluación, son relativamente intuitivos, lo que también convierte al benchmark de evaluación del modelo en una herramienta para medir el desempeño de varios aspectos. del modelo en la industria.

Evolución de los puntos de referencia de evaluación de modelos grandes
Antes de la aparición de los puntos de referencia de evaluación de modelos estandarizados, la mayoría de los modelos usaban conjuntos de datos de preguntas y respuestas como SQuAD y Natural Questions para probar el efecto del modelo, y luego derivaban puntos de referencia de evaluación de múltiples tareas y tareas en serie para una evaluación más compleja y completa. .
Dado que GLUE se lanzó como el primer punto de referencia de evaluación de modelo de lenguaje grande claro y estandarizado, en el tema de los puntos de referencia de evaluación de modelo de lenguaje grande, se divide principalmente en varias rutas de evaluación:
Uno está representado por GLUE, mediante la evaluación del rendimiento del modelo en tareas estáticas de NLU (comprensión del lenguaje natural), como la inferencia del lenguaje natural, la implicación del texto, el análisis de sentimientos y la similitud semántica.
El segundo está representado por MMLU y AGIEval, a través de la colección de libros, exámenes y otros materiales del mundo real para formar preguntas de opción múltiple, cuestionarios y otras tareas. Por ejemplo, MMLU propone una tarea de respuesta a preguntas de opción múltiple para el modelo grande, que cubre 57 dominios de conocimiento, incluidos STEM, humanidades y ciencias sociales y otras disciplinas, con el propósito de examinar el desempeño de la capacidad de razonamiento del modelo grande en diversos y avanzados. tareas de conocimiento.
El tercero está representado por HELM.Este tipo de punto de referencia se centra en la división de escenas y evalúa el rendimiento del modelo en varios escenarios. Por ejemplo, HELM propone 16 escenarios y combina 7 indicadores para una medición detallada, lo que fortalece aún más la transparencia de los grandes modelos de lenguaje. Además de los puntos de referencia de evaluación, en los últimos años también han surgido puntos de referencia de evaluación en múltiples áreas verticales de conocimiento.
Además, existen otras rutas de evaluación, como tareas de texto, puntos de referencia de evaluación multilingüe y puntos de referencia de evaluación de seguridad. También existen herramientas basadas en el sistema de puntuación de Elo, como Chatbot Arena, para mostrar de manera intuitiva el efecto del modelo y permitir que los humanos participen en la evaluación.En China, también está SuperClue Langya Bang para brindar servicios similares.
En el documento reciente A Survey on Evaluation of Large Language Models ( https://arxiv.org/abs/2307.03109 ) publicado por la Universidad de Jilin, el Instituto de Investigación de Microsoft, el Instituto de Automatización, la Academia de Ciencias de China y otras instituciones , los principales grandes se enumeran los puntos de referencia de evaluación del modelo.
 来源:Una encuesta sobre la evaluación de modelos de lenguaje extenso
来源:Una encuesta sobre la evaluación de modelos de lenguaje extenso
El mundo chino también necesita un modelo grande de referencia que se adapte al tipo de idioma chino. Por lo tanto, recientemente han surgido en China varios puntos de referencia de evaluación de modelos grandes chinos. Estos puntos de referencia de modelo se basan básicamente en la ruta tecnológica de referencia de modelo tradicional. Mejoras y optimizaciones .
Muchos modelos chinos a gran escala se han sometido a iteraciones de múltiples versiones y se ha derivado una matriz de evaluación completa.Algunos planean lanzar productos más abundantes para formar una plataforma de evaluación integral.
CSDN incluye productos de referencia de modelos grandes chinos (parte)
| nombre del proyecto |
equipo |
características |
Evaluación C |
Universidad Jiaotong de Shanghái Universidad de Tsinghua Universidad de Edimburgo, etc. |
Cubriendo las cuatro direcciones principales de humanidades, ciencias sociales, ciencia e ingeniería, y otras especializaciones, una prueba de conocimiento y razonamiento chino con 13,948 preguntas en 52 disciplinas. |
CMMLU |
MBZUAI Universidad Jiaotong de Shanghái Microsoft Research Asia, etc. |
Cubre 67 temas desde temas básicos hasta nivel profesional avanzado, cada tema tiene al menos 105 preguntas, 11528 preguntas |
CLAVE |
equipo CLUE |
Proporciona varios tipos de modelos de referencia de evaluación, conjuntos de datos, tablas de clasificación, herramientas de puntuación Elo, etc. |
MarcarEval |
Zhiyuán |
Más de 20 conjuntos de datos de evaluación subjetiva y objetiva, que cubren los conjuntos de datos públicos HellaSwag, MMLU, C-Eval y el conjunto de datos de evaluación subjetiva CCLC creado por Zhiyuan |
brújula abierta |
OpenMMlab |
Una plataforma integral para la evaluación de modelos a gran escala, que proporciona soluciones de evaluación de modelos para más de 50 conjuntos de datos con alrededor de 300 000 preguntas |
Kola |
Equipo de la Universidad de Tsinghua |
Con base en Wikipedia y casi 90 días de noticias y novelas como conjunto de datos, se diseñaron un total de 119 tareas a partir de cuatro dimensiones de memoria del conocimiento, comprensión del conocimiento, aplicación del conocimiento y creación del conocimiento. |
PandaLM |
Universidad de Westlake Universidad de Pekín, etc. |
El modelo de puntuación automatizado de PandaLM se basa en tres anotadores profesionales que puntúan de forma independiente la salida de diferentes modelos grandes y construyen un conjunto de pruebas diverso que contiene 50 campos y 1000 muestras. |
GAOKAO |
OpenLMLab |
Se recopilaron las preguntas del examen de ingreso a la universidad nacional de 2010 a 2022, incluidas 1781 preguntas objetivas y 1030 preguntas subjetivas. La evaluación se divide en dos partes, la parte objetiva de la evaluación automatizada y la parte subjetiva que se basa en la calificación de expertos para formar la calificación final. |
Xiezhi Xiezhi |
Universidad de Fudan El equipo del profesor Xiao Yanghua |
Consta de 249 587 preguntas de opción múltiple que cubren 516 temas diferentes y cuatro niveles de dificultad |
Una lista completa de puntos de referencia de clasificación y evaluación de modelos nacionales a gran escala (actualización continua)
¿Puede la puntuación de los puntos de referencia del modelo demostrar completa y objetivamente las capacidades de los modelos, y la tabla de clasificación demuestra los pros y los contras de los modelos?
CSDN aprendió que la mayoría de los equipos de modelos grandes prestan más atención a los puntos de referencia de evaluación. Algunos entrevistados dijeron a CSDN que los puntos de referencia de evaluación proporcionan una referencia para la dirección de ajuste del modelo. El equipo puede optimizar el modelo a través del rendimiento del modelo en los puntos de referencia de evaluación. Al mismo tiempo, puede entender las brechas y diferencias entre sí mismo y otros modelos tiene cierta importancia de referencia.
También hay equipos de modelos a gran escala que aún no han realizado evaluaciones comparativas. Entre ellos, los equipos entrevistados mencionaron que los actuales puntos de referencia de evaluación de modelos chinos a gran escala son principalmente el camino MMLU, que se centra en probar el conocimiento y la capacidad del modelo, pero todavía existen ciertas limitaciones a la hora de medir el rendimiento del modelo.sexo. Al mismo tiempo, estos conjuntos de datos basados en exámenes y conocimientos académicos son relativamente transparentes y fáciles de obtener, lo que también afectará la objetividad de las puntuaciones y clasificaciones.
Por lo tanto, aunque los puntos de referencia de evaluación de modelos son actualmente una herramienta eficaz para medir el rendimiento del modelo, si pueden convertirse en árbitros justos en la competencia de modelos chinos a gran escala requiere que el punto de referencia en sí continúe trabajando en una dirección integral, objetiva y precisa. De acuerdo con la tendencia empresarial actual del modelo ardiente, podemos predecir con optimismo que tanto el modelo chino a gran escala como el punto de referencia de evaluación del modelo chino a gran escala mantendrán una tendencia de progreso de recuperación continua y un impulso de innovación en el futuro.

Ya apareció el patrón de 100 modelos, ¿cómo hacer esfuerzos en el futuro?
El modelo grande sigue moviéndose, pero ¿va en la dirección correcta?
Según las últimas estadísticas de CSDN, hay más de cien modelos a gran escala de uso general que han surgido en China. En la competencia, el modelo grande de uso general continúa acumulando recursos, centrándose en la mejora de la cantidad de parámetros y la capacidad de razonamiento, y cada equipo de modelo también está trabajando arduamente para explorar un camino de evolución tecnológica adecuado.
Mapa conceptual de tecnología y aplicación de modelos grandes (v20230428)
Wang Yonggang Fundador/CEO de SeedV Lab
ChatGLM desarrollado por Zhipu AI y Baichuan dirigido por Wang Xiaochuan han anunciado modelos grandes de código abierto y los han hecho gratuitos para uso comercial. Esperan vincular más escenarios para aprovechar el valor y construir rápidamente un ecosistema. El modelo de la industria está explorando escenarios comerciales tanto como sea posible. Wang Jianshuo, el fundador de People AI, dijo en un programa de podcast que han aclarado los escenarios de prueba para los servicios de conferencias después de la investigación.
Jia Yangqing mencionó una vez el concepto de vida útil del modelo en un podcast. Él cree que desde el lanzamiento de AlexNet en 2012 hasta el presente, después del lanzamiento de cada modelo a gran escala con un rendimiento sólido, tomará solo entre seis meses y un año. Aparece un modelo con rendimiento cercano. A medida que más modelos grandes de propósito general de alta calidad se abren gradualmente, se espera que las barreras técnicas entre los modelos se eliminen aún más.
Algunos expertos de la industria también creen que aunque el entusiasmo por los modelos a gran escala ha sido extremadamente alto recientemente, el desarrollo de modelos a gran escala y sus aplicaciones depende de la medición de la empresa de los costos de implementación del modelo y el valor real.
A menudo decimos que las nuevas tecnologías siempre se sobrestiman a corto plazo y se subestiman a largo plazo. La popularidad de los modelos grandes ha continuado desde el año pasado, y las innovaciones tecnológicas que han atraído la atención de toda la sociedad se actualizan constantemente. Con el avance del tiempo y la tecnología, los modelos grandes dejarán de ser términos técnicos inescrutables.
En el proceso de desencanto de los grandes modelos, los puntos de referencia de evaluación deben ser una parte importante. Establecer un sistema de evaluación más completo, objetivo y preciso y formar una interacción benigna con la investigación de modelos a gran escala también será la dirección para que los profesionales y los equipos de referencia de evaluación continúen explorando.

