A conversão de voz AI é realmente tão complicada quanto possível? Este artigo propõe um modelo de conversão de linguagem simples, mas igualmente poderoso, que é tão natural e claro quanto o método de linha de base, e a similaridade é bastante aprimorada.
O mundo da voz do qual a IA participa é realmente incrível. Ela pode trocar a voz de uma pessoa pela voz de qualquer outra pessoa, e também pode trocar vozes com animais.
Sabemos que o objetivo da conversão de voz é converter a voz de origem na voz de destino, mantendo o conteúdo inalterado. Os métodos recentes de conversão de fala de qualquer para qualquer melhoraram a naturalidade e a similaridade do locutor, mas à custa de uma complexidade substancialmente aumentada. Isso significa que o treinamento e a inferência se tornam mais caros, dificultando a avaliação e o estabelecimento de melhorias.
A questão é: a conversão de voz de alta qualidade requer complexidade? Em um artigo recente da Universidade de Stellenbosch, na África do Sul, vários pesquisadores exploraram essa questão.

Endereço do artigo: https://arxiv.org/pdf/2305.18975.pdf
Endereço GitHub: https://bshall.github.io/knn-vc/
O destaque da pesquisa é que eles apresentam a Conversão de Voz K-Nearest Neighbor (kNN-VC), um método simples e poderoso para conversão de voz de qualquer para qualquer . Nenhum modelo de transformação explícito é treinado no processo, mas a regressão K-Nearest Neighbors é simplesmente usada.
Especificamente, os pesquisadores primeiro usam um modelo de representação de fala auto-supervisionado para extrair as sequências de recursos do enunciado de origem e do enunciado de referência, depois convertem cada quadro da representação de origem no falante-alvo, substituindo seu vizinho mais próximo na referência e, finalmente, usam um vocoder neural para sintetizar os recursos transformados para obter a fala transformada.
A partir dos resultados, apesar de sua simplicidade, o KNN-VC iguala ou até melhora a inteligibilidade e a similaridade do falante em avaliações subjetivas e objetivas em comparação com vários sistemas de conversão de fala de linha de base.
Vamos apreciar o efeito da conversão de voz KNN-VC. Vejamos primeiro a conversão vocal, aplicando KNN-VC a alto-falantes de origem e destino não vistos no conjunto de dados LibriSpeech.
Voz da fonte : me cutuque para ouvir o áudio
Voz Sintética 1 : Me cutuque para ouvir o áudio
Synthetic Speech 2 : Cutuque-me para ouvir o áudio
O KNN-VC também oferece suporte à conversão de fala em vários idiomas, como espanhol para alemão, alemão para japonês e chinês para espanhol.
Fonte Chinês : Me cutuque para ouvir o áudio
Target Spanish : Me cutuque para ouvir o áudio
Synthetic Speech 3 : Cutuque-me para ouvir o áudio
O que é ainda mais surpreendente é que o KNN-VC também pode trocar vozes humanas por latidos de cachorro.
Cachorro de origem latindo : me cutuque para ouvir o áudio
Vocal de origem : Me cutuque para ouvir o áudio
Synthetic Speech 4 : Cutuque-me para ouvir o áudio
Synthetic Speech 5 : Cutuque-me para ouvir o áudio
Em seguida, veremos como o KNN-VC funciona e comparamos os resultados com outros métodos jixianos.
Visão geral do método e resultados experimentais
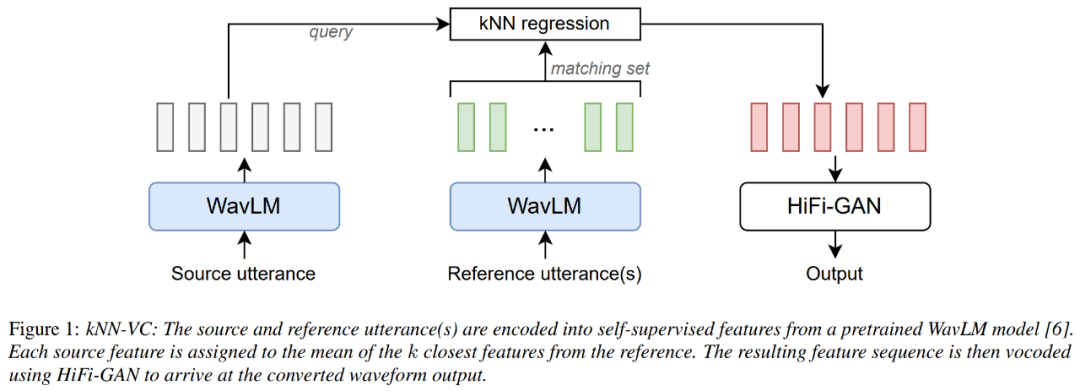
O diagrama de arquitetura do kNN-VC é mostrado abaixo, que segue a estrutura codificador-conversor-vocodificador. Primeiro, um codificador extrai representações auto-supervisionadas da fonte e da fala de referência, depois um transformador mapeia cada quadro de origem para seus vizinhos mais próximos na referência e, finalmente, um vocoder gera formas de onda de áudio com base nos recursos transformados.
O codificador usa WavLM, o conversor usa a regressão K do vizinho mais próximo e o vocoder usa HiFiGAN. O único componente que precisa ser treinado é o vocoder.
Para o codificador WavLM, usamos apenas o modelo WavLM-Large pré-treinado e não o treinamos neste artigo. Para o modelo de conversão kNN, o kNN é não paramétrico e não requer nenhum treinamento. Para o vocoder HiFiGAN, os recursos WavLM foram codificados usando o repositório original do autor HiFiGAN, tornando-se a única parte que exigia treinamento.
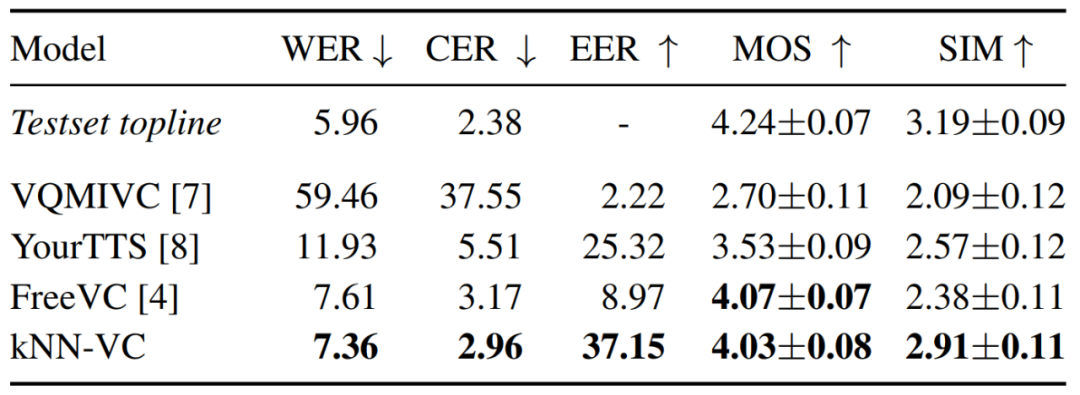
Em experimentos, os pesquisadores primeiro compararam o KNN-VC com outros métodos de linha de base, usando os maiores dados de alvo disponíveis (aproximadamente 8 minutos de áudio por alto-falante) para testar o sistema de conversão de fala.
Para KNN-VC, os pesquisadores usam todos os dados do alvo como o conjunto correspondente. Para o método de linha de base, eles calculam a média das incorporações do locutor para cada enunciado de destino.
A Tabela 1 abaixo relata os resultados de inteligibilidade, naturalidade e similaridade de alto-falante para cada modelo. Como pode ser visto, o kNN-VC alcança naturalidade e inteligibilidade semelhantes ao melhor FreeVC de linha de base, mas com similaridade de alto-falante significativamente maior. Isso também confirma a tese deste artigo: a conversão de fala de alta qualidade não precisa aumentar a complexidade.
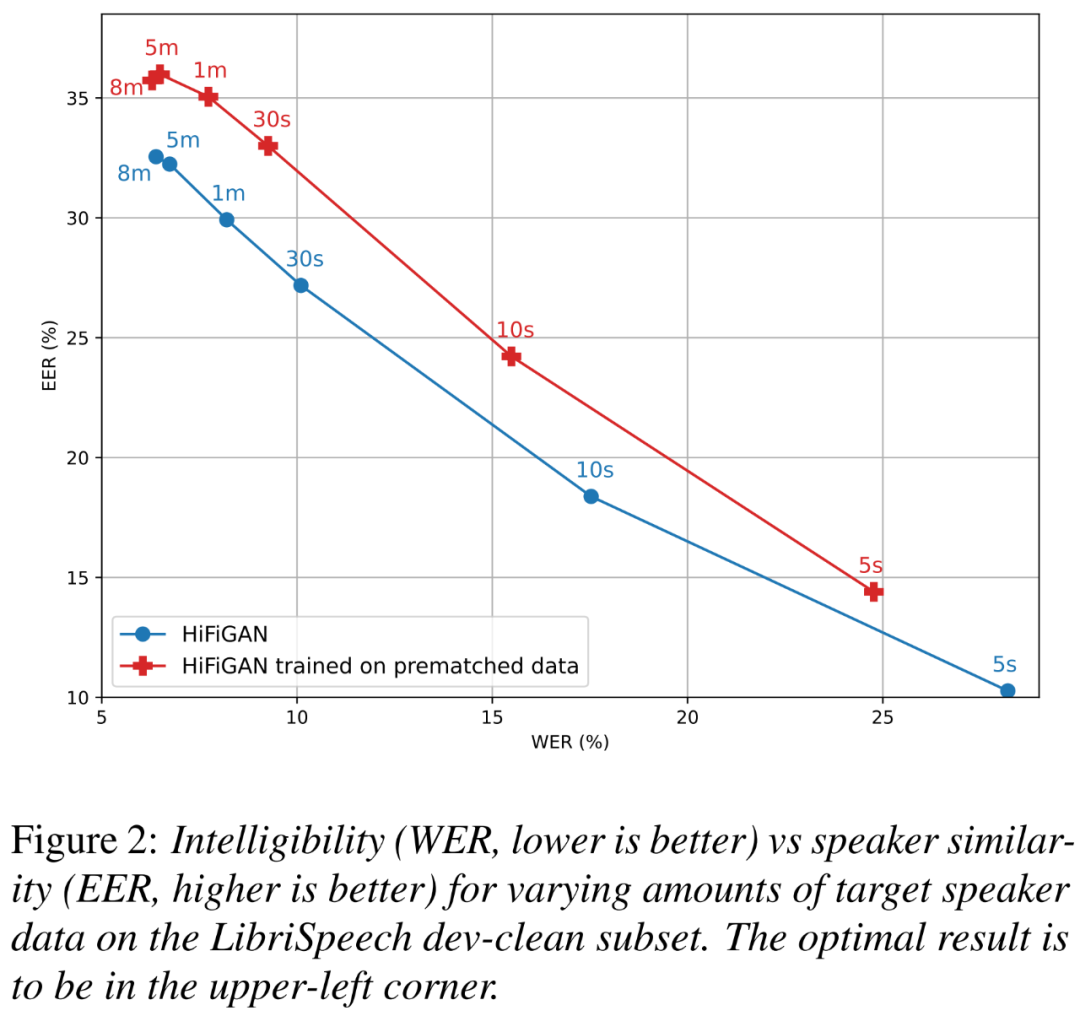
Além disso, os pesquisadores queriam entender quanta melhoria é devida ao HiFi-GAN treinado em dados pré-correspondidos e quanto o tamanho dos dados do alto-falante alvo afeta a inteligibilidade e a similaridade do alto-falante.
A Figura 2 abaixo mostra os gráficos WER (quanto menor, melhor) e EER (maior, melhor) para duas variantes HiFi-GAN em diferentes tamanhos de alto-falantes-alvo.
Comentários quentes de internautas
Para este novo método de conversão de voz kNN-VC que "usa apenas o vizinho mais próximo", algumas pessoas pensam que o modelo de voz pré-treinado é usado no artigo, portanto, não é correto usar "apenas". Mas é inegável que o kNN-VC ainda é mais simples que outros modelos.
Os resultados também demonstram que o kNN-VC é tão eficaz, se não o melhor, em comparação com os métodos de conversão de fala qualquer para qualquer muito complexos.

Outros disseram que o exemplo da voz humana trocando com o latido do cachorro é muito interessante.