O mito do LLaMA de código aberto reaparece! A primeira solução de pré-treinamento de alto desempenho de modelo grande de 65 bilhões de parâmetros de código aberto, a velocidade de treinamento é acelerada em 38% e o modelo grande feito sob medida é criado a baixo custo.
A "Guerra dos Cem Modelos" está no auge, e o financiamento e as fusões e aquisições das empresas relacionadas à AIGC atingiram repetidamente novos recordes, e as empresas globais de tecnologia estão competindo para entrar no jogo.
No entanto, por trás da grande beleza dos grandes modelos de IA está o custo extremamente alto, e o custo de um único pré-treinamento pode chegar a dezenas de milhões de yuans. Com base no ajuste fino dos grandes modelos de código aberto existentes, como o LLaMA, também é difícil atender às necessidades das empresas para criar competitividade central e diversificar o uso comercial.
Portanto, como criar um grande modelo básico pré-treinado a baixo custo tornou-se um gargalo importante na onda de grandes modelos de IA.
A Colossal-AI é a maior e mais ativa ferramenta e comunidade de desenvolvimento de modelos em grande escala do mundo. Tomando o LLaMA, que atualmente é o mais usado, como exemplo, ele fornece uma solução de pré-treinamento de 65 bilhões de parâmetros pronta para uso, que pode aumentar a velocidade de treinamento em 38% e economizar muitos custos para empresas de modelos em grande escala.

Endereço de código aberto: https://github.com/hpcaitech/ColossalAI
LLaMA inflama o entusiasmo pelo código aberto
O grande modelo LLaMA 7B~65B de código aberto da Meta estimulou ainda mais o entusiasmo pela criação de um modelo semelhante ao ChatGPT e derivou projetos de ajuste fino como Alpaca, Vicuna e ColossalChat.
No entanto, o LLaMA apenas pesa o modelo de código aberto e restringe o uso comercial, e o conhecimento e os recursos que o ajuste fino pode melhorar e injetar são relativamente limitados. Para as empresas que realmente aderiram à onda de modelos grandes, elas ainda devem pré-treinar seus próprios modelos grandes principais.
Para esse fim, a comunidade de código aberto também fez muitos esforços:
-
RedPajama: conjunto de dados LLaMA de código aberto comercialmente disponível, sem código de treinamento e modelo
-
OpenLLaMA: modelo LLaMA 7B, 13B de código aberto comercialmente disponível, usando EasyLM baseado em treinamento JAX e TPU
-
Falcon: LLaMA comercial de código aberto 7B, modelo 40B, sem código de treinamento
No entanto, para o ecossistema PyTorch + GPU mais comum, ainda há uma falta de soluções de pré-treinamento de modelos básicos de grande escala eficientes, confiáveis e fáceis de usar.
A melhor solução de pré-treinamento para modelos grandes acelera em 38%
Em resposta às lacunas e necessidades acima, a Colossal-AI é a primeira a abrir o código-fonte da solução de pré-treinamento de baixo custo LLaMA de 65 bilhões de parâmetros.
Em comparação com outras opções convencionais do setor, esta solução pode aumentar a velocidade do pré-treinamento em 38%, precisa apenas de 32 A100/A800 para usar e não limita o uso comercial.
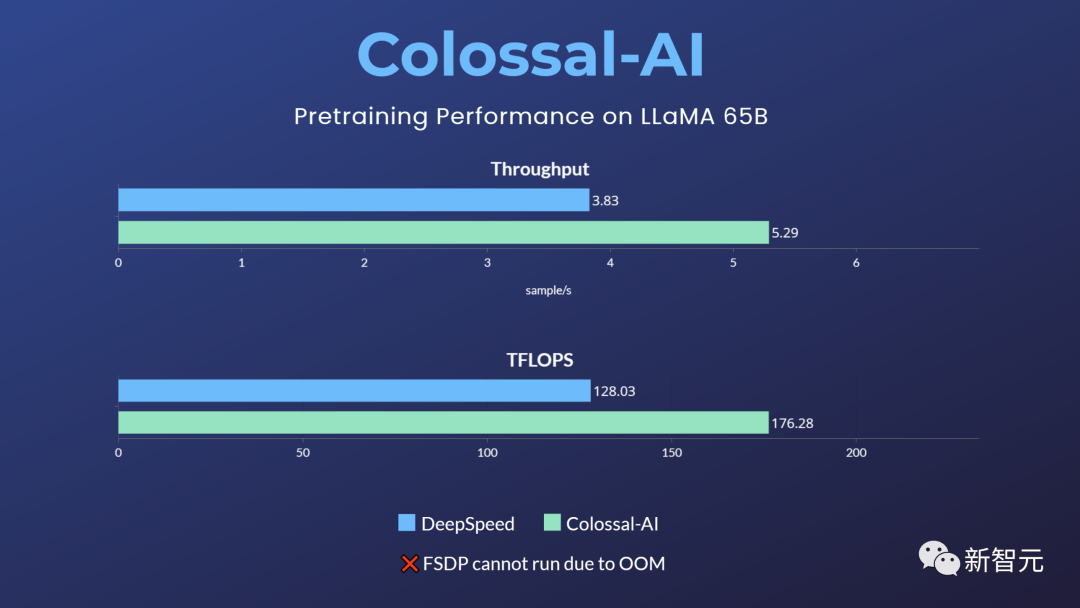
No entanto, PyTorch nativo, FSDP, etc. não podem executar esta tarefa devido ao estouro de memória. Hugging Face acelera, DeepSpeed e Megatron-LM não ofereceram suporte oficial ao pré-treinamento LLaMA.
sai da caixa
1. Instale o Colossal-AI
git clone -b example/llama https://github.com/hpcaitech/ColossalAI.gitcd ColossalAI# install and enable CUDA kernel fusionCUDA_EXT=1 pip install .
2. Instale outras dependências
cd examples/language/llama# install other dependenciespip install -r requirements.txt# use flash attentionpip install xformers
3. Conjuntos de dados
O conjunto de dados padrão togethercomputer/RedPajama-Data-1T-Sample será baixado automaticamente na primeira execução, e um conjunto de dados personalizado também pode ser especificado via -d ou --dataset.
4. Execute o comando
Os scripts de teste de velocidade 7B e 65B foram fornecidos e você só precisa definir o nome do host do nó múltiplo usado de acordo com o ambiente de hardware real para executar o teste de desempenho.
cd benchmark_65B/gemini_autobash batch12_seq2048_flash_attn.sh
Para a tarefa de pré-treinamento real, use o mesmo comando do teste de velocidade, basta iniciar o comando correspondente, como usar 4 nós * 8 cartões para treinar um modelo 65B.
colossalai run --nproc_per_node 8 --hostfile YOUR_HOST_FILE --master_addr YOUR_MASTER_ADDR pretrain.py -c '65b' --plugin "gemini" -l 2048 -g -b 8 -aPor exemplo, usar a estratégia paralela Colossal-AI gemini_auto pode facilmente implementar o treinamento paralelo de várias máquinas e vários cartões, reduzir o consumo de memória enquanto mantém o treinamento de alta velocidade. De acordo com o ambiente de hardware ou necessidades reais, combinações complexas de estratégias paralelas, como paralelismo de pipeline + paralelismo de tensor + ZeRO1, podem ser selecionadas.
Entre eles, por meio dos plug-ins Booster da Colossal-AI, os usuários podem personalizar facilmente o treinamento paralelo, como escolher estratégias paralelas como Low Level ZeRO, Gemini e DDP.
O ponto de verificação de gradiente reduz o uso de memória recalculando as ativações do modelo durante a retropropagação. Acelere o cálculo e economize memória de vídeo introduzindo o mecanismo de atenção do Flash.
Os usuários podem controlar convenientemente dezenas de parâmetros personalizados semelhantes por meio de parâmetros de linha de comando, o que mantém a flexibilidade para o desenvolvimento personalizado enquanto mantém o alto desempenho.
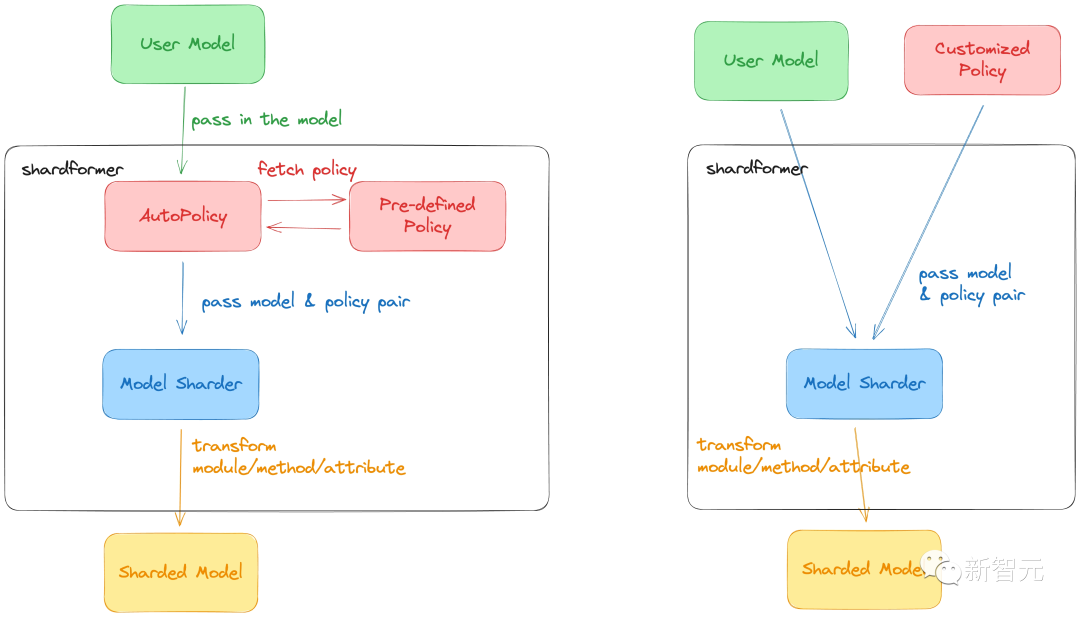
O mais recente ShardFormer da ColossalAI reduz consideravelmente o custo do uso do LLM de treinamento paralelo multidimensional.
Agora ele suporta uma variedade de modelos convencionais, incluindo LLaMA, e suporta nativamente a biblioteca de modelos Huggingface/transformers.
Ele pode suportar várias combinações de configuração de paralelismo multidimensional (pipeline, tensor, ZeRO, DDP, etc.) sem modificar o modelo e pode exercer excelente desempenho em várias configurações de hardware.
AI Large Model System Infrastructure Colossal-AI
O Colossal-AI fornece otimização do sistema central e suporte à capacidade de aceleração para o programa. Ele foi desenvolvido sob a liderança de James Demmel, Distinguished Professor da University of California, Berkeley, e You Yang, Presidential Youth Professor da National University of Singapore.
Com base no PyTorch, o Colossal-AI pode reduzir os custos de desenvolvimento e aplicação de treinamento/ajuste fino/raciocínio de modelos grandes de IA e reduzir os requisitos de GPU por meio de paralelismo multidimensional eficiente e memória heterogênea.
A solução Colossal-AI acima mencionada foi aplicada em uma empresa Fortune 500. Tem excelente desempenho no cluster de quilocalorias e leva apenas algumas semanas para concluir o pré-treinamento de um modelo privado de grande escala com centenas de bilhões de parâmetros. O InternLM lançado recentemente, como o Shanghai AI Lab e o Shangtang, também é baseado no Colossal-AI para obter um pré-treinamento eficiente em Kcal.
Desde o seu código aberto, o Colossal-AI ficou em primeiro lugar no mundo na GitHub Hot List por muitas vezes e obteve mais de 30.000 GitHub Stars. Ele também foi selecionado com sucesso como o tutorial oficial das principais conferências internacionais de IA e HPC, como SC, AAAI, PPoPP, CVPR e ISC. Centenas de empresas participaram da construção do ecossistema Colossal-AI.
A Luchen Technology, que está por trás disso, recebeu recentemente centenas de milhões de yuans em financiamento da Série A e concluiu rapidamente três rodadas de financiamento em 18 meses após seu estabelecimento.
Endereço de código aberto:
https://github.com/hpcaitech/ColossalAI
Link de referência:
https://www.hpc-ai.tech/blog/large-model-pretraining