1. Classificação de seleção
A ideia básica da ordenação por seleção é: cada passagem (como a i-ésima passagem) seleciona o elemento com a menor chave entre os próximos n-i+1 (i=1,2...,n-1) elementos a serem ordenados, como um elemento ordenado O i-ésimo elemento da subsequência, até que a n-1ª passagem seja concluída, há apenas um elemento a ser ordenado, portanto não há necessidade de escolher novamente. O algoritmo heap sort na classificação por seleção é o foco do exame ao longo dos anos.
2. Classificação de seleção simples
1. Pensamento algorítmico
De acordo com a ideia de ordenação por seleção acima, a ideia de algoritmo de ordenação por seleção simples pode ser derivada intuitivamente: supondo que a tabela de ordenação seja [L...n], a i-ésima ordenação é selecionar o elemento com a menor chave de Li.n] e I(i) Exchange, cada classificação pode determinar a posição final de um elemento, de modo que toda a tabela de classificação possa ser ordenada após a classificação n-1.
2. Implementação do algoritmo
//简单选择排序
void selectsort(SqList &L){
for(int i=0;i<L.length-1;i++){
//一共进行n-1趟
Elemtype min=L.data[i]; //记录最小的元素位置
int n=0;
for(int j=i+1;j<L.length;j++){
//从未排序部分开始遍历
if(L.data[j].grade<min.grade) {
min=L.data[j];
n=j;
}
}
if(min.grade!=L.data[i].grade){
Elemtype temp=L.data[i];
L.data[i]=L.data[n];
L.data[n]=temp;
}
}
}
3. Análise de eficiência
A análise de desempenho do algoritmo de classificação por seleção simples é a seguinte:
- Eficiência de espaço: Apenas um número constante de unidades auxiliares é usado, então a eficiência de espaço é 0(1). ,
- Eficiência de tempo: Não é difícil ver no pseudocódigo acima que, no processo de seleção e classificação simples, o número de operações de movimento do elemento é muito pequeno, não mais do que 3(n-1) vezes, e o melhor caso é mover 0 vezes. Neste momento, a lista correspondente já está ordenada, mas o número de comparações entre os elementos não tem nada a ver com o estado inicial da sequência, é sempre n(n- 1)/2 vezes , então a complexidade de tempo é sempre 0(n 2 ) .
- Estabilidade: Depois de encontrar o menor elemento na i-ésima passagem, trocar com o i-ésimo elemento pode fazer com que a posição relativa do i-ésimo elemento mude com o elemento que contém a mesma palavra-chave. Por exemplo, tabela L={2, 2,1 }, depois de classificar L={1, 2,2 }, a sequência de classificação final também é L={1,2,2}, obviamente, a ordem relativa de 2 e 2 mudou. Portanto, a classificação por seleção simples é um método de classificação instável .
3. Classificação da pilha
1. Pensamento algorítmico
A ideia de classificação de heap é muito simples: primeiro, os n elementos armazenados em L1...n] são construídos em um heap inicial. Devido às características do próprio heap (tome o heap grande como exemplo), o elemento superior da pilha é o valor máximo. Depois de gerar o elemento superior do heap, o elemento inferior do heap geralmente é enviado para o topo do heap. Nesse momento, o nó raiz não satisfaz a natureza do heap superior grande e o heap é destruído. Ajuste o elemento superior do heap para baixo para que possa continuar a manter a natureza do grande heap superior e, em seguida, gerar o elemento superior do heap. Repita isso até que haja apenas -um elemento restante na pilha. Pode-se ver que a ordenação do heap precisa resolver dois problemas: ①Como construir uma sequência desordenada em um heap inicial?
A chave para a classificação do heap é construir o heap inicial. Em uma árvore binária completa de n nós, o último nó é filho do nó Ln/2'th. Filtre a subárvore cuja raiz é o nó Ln/2'th (para um heap raiz grande, se a chave do nó raiz for menor que aquela com a chave maior entre os filhos esquerdo e direito, troque) e faça o subárvore um heap. Em seguida, filtre a subárvore com raiz em cada nó (Ln/2J-1~1) para ver se o valor do nó é maior que o valor de seus nós filho esquerdo e direito. Caso contrário, os nós filho esquerdo e direito O valor maior no nó é trocado com ele, e o heap do próximo nível pode ser destruído após a troca, então continue a usar o método acima para construir o heap do próximo nível até que a subárvore enraizada no nó forme um heap. Use repetidamente o método acima para ajustar o heap para construir o heap até o nó raiz.
2. Exemplo de ajuste
Ajuste inicialmente a subárvore L(4), 09 < 32, troca e atenda à definição do heap após a troca; continue a ajustar a subárvore L(3) para frente, 78<o maior dos filhos esquerdo e direito, 87, troca e satisfaz o heap após a troca Definição; ajusta a subárvore L(2) para frente, 17 < o maior dos filhos esquerdo e direito 45, e atende à definição do heap após a troca; ajusta para frente para o nó raiz L (1), 53 < o maior dos filhos esquerdo e direito 87. Troca. Após a troca, o heap da subárvore L(3) é destruído. Use o método acima para ajustar L(3). 53 <o maior de os filhos esquerdo e direito 78. Troca, até agora a árvore binária completa atende à definição de um heap.
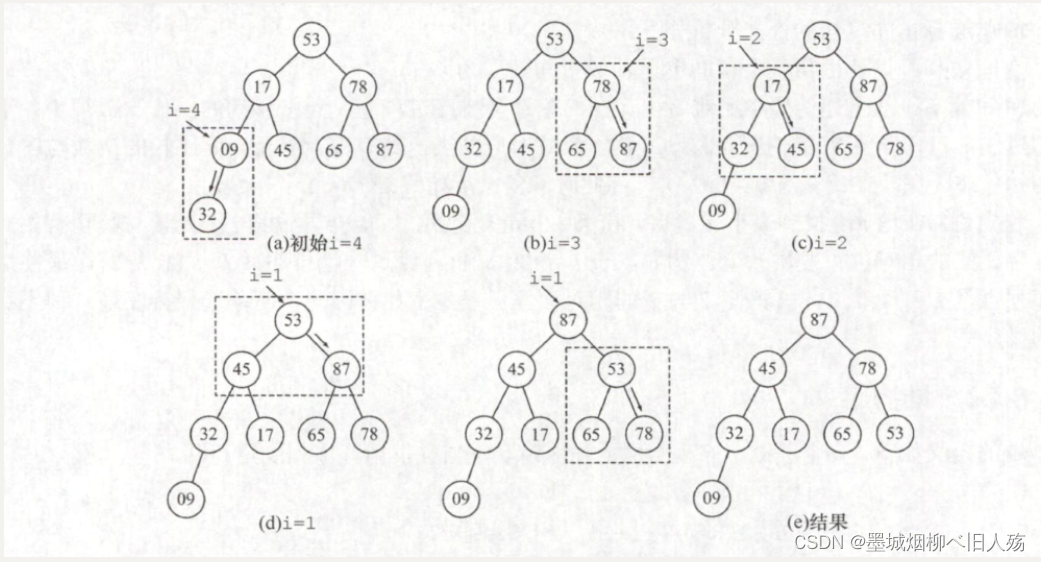
3. Implementação da linguagem C
void Heapsort(SqList &L){
buildMaxheap(L);
for(int i=L.length-1;i>0;i--){
Elemtype temp=L.data[i];
L.data[i]=L.data[0];
L.data[0]=temp;
HeadAdjust(L,0, i);
}
}
4. Análise de Eficiência
A análise de desempenho do algoritmo heap sort é a seguinte:
- Eficiência de espaço: Apenas um número constante de unidades auxiliares é usado, então a complexidade do espaço é 0(1).
- Eficiência de tempo: O tempo para construir um heap é O(n), e há n-1 operações de ajuste para baixo depois, e a complexidade de tempo de cada ajuste é O(h), portanto, nos melhores, piores e médios casos, heap classificação A complexidade de tempo é O(nlog2n).
- Estabilidade: durante a triagem, é possível ajustar os seguintes elementos com a mesma palavra-chave à frente, de modo que o algoritmo de classificação de heap é um método de classificação instável. Por exemplo, tabela L= {1, 2 , 2}, ao construir o heap inicial, 2 pode ser trocado para o topo do heap, neste momento L= { 2 , 1,2}, e a sequência de ordenação final é L={1,2, 2 } , obviamente, a ordem relativa de 2 e 2 mudou.
4. Um exemplo completo de implementação da linguagem C
/*我们今天的主角插入排序是基于查找算法来的,所以我们还是利用线性表来进行模拟*/
/*为了便于我们后面演示希尔排序,所以我们采用顺序存储结构*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MaxSize 50 //这里只是演示,我们假设这里最多存五十个学生信息
//定义学生结构
typedef struct {
char name[200]; //姓名
int grade; //分数,这个是排序关键字
} Elemtype;
//声明使用顺序表
typedef struct {
/*这里给数据分配内存,可以有静态和动态两种方式,这里采用动态分配*/
Elemtype *data; //存放线性表中的元素是Elemtype所指代的学生结构体
int length; //存放线性表的长度
} SqList; //给这个顺序表起个名字,接下来给这个结构体定义方法
//初始化线性表
void InitList(SqList &L){
/*动态分配内存的初始化*/
L.data = (Elemtype*)malloc(MaxSize * sizeof(Elemtype)); //为顺序表分配空间
L.length = 0; //初始化长度为0
}
//求表长函数
int Length(SqList &L){
return L.length;
}
//求某个数据元素值
bool GetElem(SqList &L, int i, Elemtype &e) {
if (i < 1 || i > L.length)
return false; //参数i错误时,返回false
e = L.data[i - 1]; //取元素值
return true;
}
//输出线性表
void DispList(SqList &L) {
if (L.length == 0)
printf("线性表为空");
//扫描顺序表,输出各元素
for (int i = 0; i < L.length; i++) {
printf("%s %d", L.data[i].name, L.data[i].grade);
printf("\n");
}
printf("\n");
}
//插入数据元素
bool ListInsert(SqList &L, int i, Elemtype e) {
/*在顺序表L的第i个位置上插入新元素e*/
int j;
//参数i不正确时,返回false
if (i < 1 || i > L.length + 1 || L.length == MaxSize)
return false;
i--; //将顺序表逻辑序号转化为物理序号
//参数i正确时,将data[i]及后面的元素后移一个位置
for (j = L.length; j > i; j--) {
L.data[j] = L.data[j - 1];
}
L.data[i] = e; //插入元素e
L.length++; //顺序表长度加1
return true;
/*平均时间复杂度为O(n)*/
}
//简单选择排序
void selectsort(SqList &L){
for(int i=0;i<L.length-1;i++){
//一共进行n-1趟
Elemtype min=L.data[i]; //记录最小的元素位置
int n=0;
for(int j=i+1;j<L.length;j++){
//从未排序部分开始遍历
if(L.data[j].grade<min.grade) {
min=L.data[j];
n=j;
}
}
if(min.grade!=L.data[i].grade){
Elemtype temp=L.data[i];
L.data[i]=L.data[n];
L.data[n]=temp;
}
}
}
void HeadAdjust(SqList &L,int k, int len){
Elemtype temp=L.data[k];
for(int i=2*k+1;i<len;i=2*i+1){
if(i<len-1 && L.data[i].grade<L.data[i+1].grade)
i++;
if(temp.grade>=L.data[i].grade)
break;
else{
L.data[k]=L.data[i];
k=i;
}
}
L.data[k]=temp;
}
void buildMaxheap(SqList &L){
for(int i=L.length/2-1;i>=0;i--)
HeadAdjust(L, i, L.length);
}
void Heapsort(SqList &L){
buildMaxheap(L);
for(int i=L.length-1;i>0;i--){
Elemtype temp=L.data[i];
L.data[i]=L.data[0];
L.data[0]=temp;
HeadAdjust(L,0, i);
}
}
int main(){
SqList L;
Elemtype stuents[10]={
{
"张三",649},{
"李四",638},{
"王五",665},{
"赵六",697},{
"冯七",676},
{
"读者",713},{
"阿强",627},{
"杨曦",649},{
"老六",655},{
"阿黄",604}};
//这一部分忘了的请回顾我的相关博客
printf("初始化顺序表并插入开始元素:\n");
InitList(L); //这时是一个空表,接下来通过插入元素函数完成初始化
for (int i = 0; i < 10; i++)
ListInsert(L, i + 1, stuents[i]);
DispList(L);
/*printf("根据分数进行简单选择排序后结果为:\n");
selectsort(L);
DispList(L); //到这一步我们的简单选择排序没什么问题的
*/
printf("根据分数进行堆排序后结果为:\n");
Heapsort(L);
DispList(L);
}
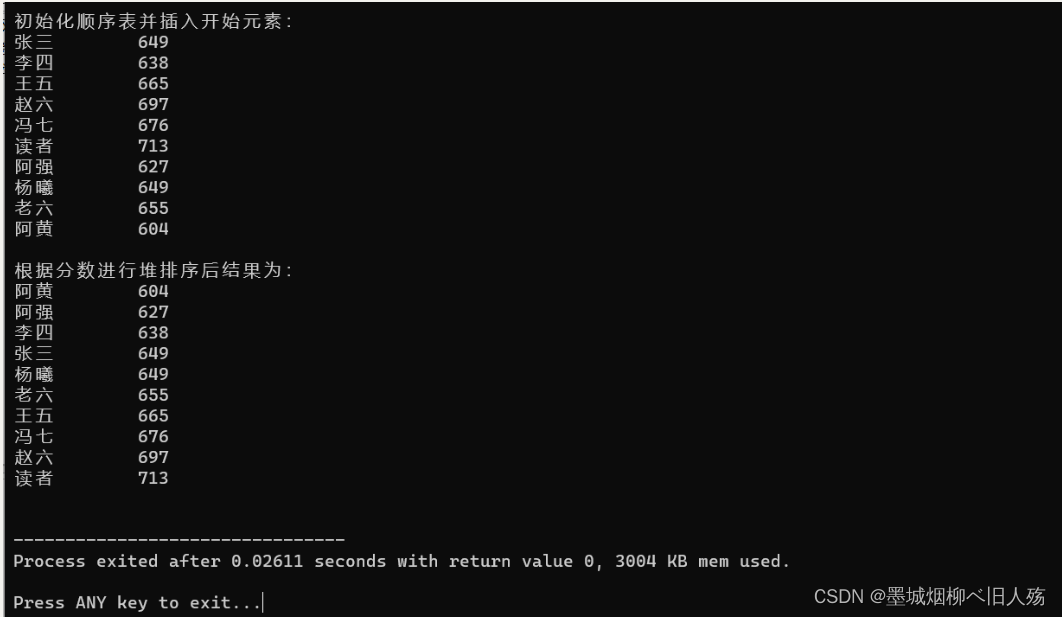
5. Resultados de execução
1. Classificação de seleção simples
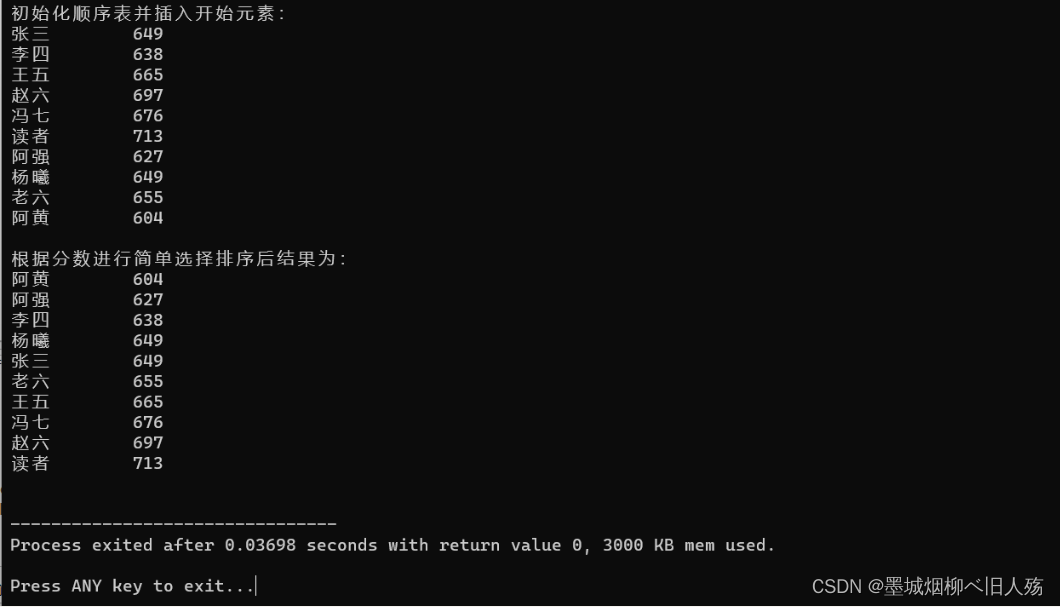
2. Classificação de heap