Índice
Diretório de artigos
O histórico de desenvolvimento da virtualização do sistema operacional (tecnologia de contêiner)
Em 1979, a versão 7 do UNIX introduziu o recurso Chroot. O Chroot agora é considerado o protótipo da primeira tecnologia de virtualização no nível do sistema operacional (Virtualização no nível do sistema operacional), que é essencialmente uma tecnologia de isolamento para a camada do sistema de arquivos do sistema operacional.
Em 2006, o Google lançou a tecnologia Process Container (contêiner de processo) rodando no Linux. Seu objetivo é fornecer uma limitação e prioridade de recursos no nível do sistema operacional semelhante ao Virtual Mahine (tecnologia de virtualização de computadores), mas principalmente para controle de processo, capacidade de auditoria de recursos e capacidade de controle de processo.
Em 2007, o Google promoveu a integração do código do Process Container no Kernel do Linux. Ao mesmo tempo, como o nome Container tem muitos significados diferentes no Kernel, para evitar a confusão de nomenclatura de código, o Process Container foi renomeado como Grupos de Controle, referidos como: Cgroups.
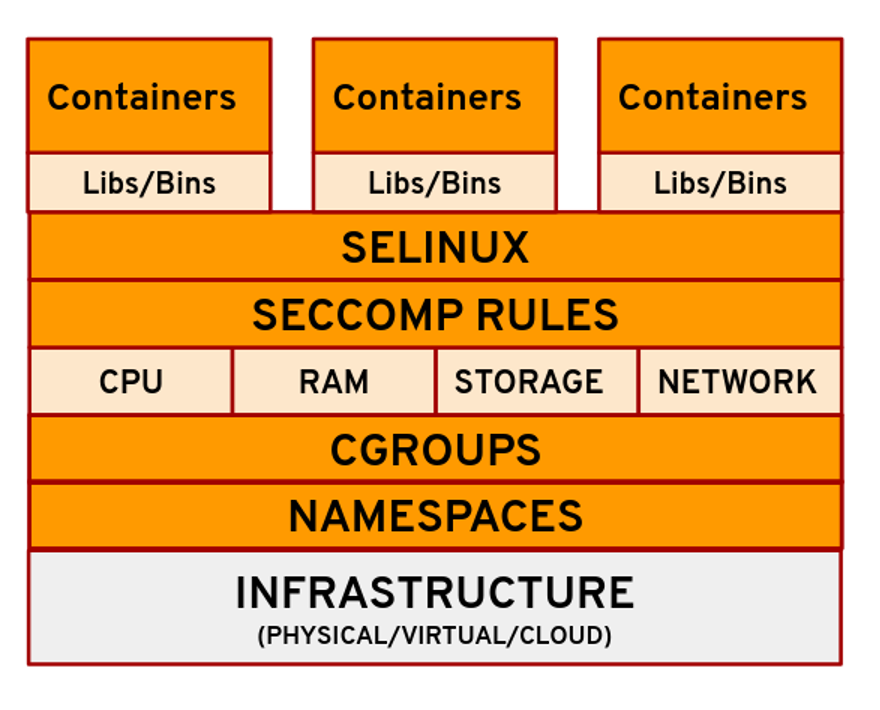
Em 2008, a comunidade Linux integrou Chroot, Cgroups, Namespaces, SELinux, Seccomp e outras tecnologias e lançou a versão LXC (Linux Container) v0.1.0. O LXC realiza a virtualização completa e leve do sistema operacional, combinando a capacidade de gerenciamento de cota de recursos do Cgroups e a capacidade de isolamento de visualização de recursos do Namespace.
Em 15 de março de 2013, na Python Developers Conference realizada em Santa Clara, Califórnia, Solomon Hvkes, fundador e CEO da DotCloud, lançou pela primeira vez o Docker baseado no pacote LXC em um mini-speak de apenas 5 minutos. seu código-fonte e hospede-o no Github após a reunião.
chroot
Chroot é uma interface de chamada do sistema que pode ser chamada pelo processo do usuário, que permite que um processo use o diretório especificado como o diretório raiz (diretório raiz) e, em seguida, todas as operações do sistema de arquivos do processo só podem ser executadas neste diretório especificado. Por isso é chamado de Change Root.
O protótipo da função chroot() é muito simples:
- Autoridade de invocação : usuário raiz.
- Lista formal de parâmetros :
- caminho: Um ponteiro para uma cadeia de caracteres, que é um caminho absoluto, indicando o caminho do diretório para o qual mudar o diretório raiz do Processo.
- A função retorna :
- sucesso: retorna 0;
- Falha: retorne -1.
#include <unistd.h>
int chroot(const char *path);
Deve-se observar que após alterar o diretório raiz do Processo, o Processo só pode acessar os arquivos e recursos no novo diretório raiz e seus subdiretórios. Portanto, após chamar chroot(), certifique-se de que todos os arquivos e recursos que o processo precisa acessar existem no novo diretório raiz.
chroot() é atualmente usado principalmente para:
- Cenário de isolamento de segurança : Limite o alcance de acesso do Processo para melhorar a segurança do sistema.
- Cenário do ambiente de depuração : crie um ambiente isolado do sistema principal para depuração, teste e execução do processo.
- Cenário de resgate do sistema : quando o sistema operacional Linux é danificado ou atacado, você pode usar chroot para alternar o processo para o diretório raiz do sistema danificado para operações de reparo e resgate.
Pode-se ver que chroot() fornece isolamento para Processo no nível do sistema de arquivos Linux (sistema de arquivos), mas não fornece isolamento de segurança completo e não pode impedir outros ataques. Portanto, para alcançar o isolamento de segurança entre os Processos, outras medidas de segurança precisam ser tomadas.
Cgroups
Cgroups (Control Groups) é uma cota de recursos do sistema operacional e tecnologia de gerenciamento para User Process ou Kernel Thread fornecida pelo Linux Kernel. Ele inclui principalmente os quatro aspectos a seguir:
- Cota de recurso : limita a cota de uso de um recurso do sistema por um processo.
- Prioridade : Quando ocorre a competição por recursos, quais processos devem priorizar o uso de recursos.
- Auditoria : monitore e relate os limites de recursos e o uso por processos.
- Controle : Controle o estado do processo, por exemplo: em execução, suspenso, retomado.
Os principais conceitos de design e implementação do Cgroups são mostrados na figura abaixo, incluindo:
- libcgroups : Fornece um conjunto de aplicativos e bibliotecas de interface de programação.
- Tarefas : Abstração unificada do processo do usuário e thread do kernel. Como o processo do usuário ou o thread do kernel no kernel são realmente diferenciados apenas pelos parâmetros passados pelo clone() SCI, todos eles usam a descrição task_struct.
- Subsistemas : definições de tipo para recursos controláveis.
- Grupo de Controle (cgroup) : É a descrição do grupo de controle de recursos utilizado para associar diversas Tarefas e Subsistemas. O cgroup minúsculo é usado abaixo para descrever um grupo de controle específico.
- Cgroup Filesystem : Fornece entrada de configuração cgroup para o Userspace através da interface de arquivo unificado VFS (Virtual File System).
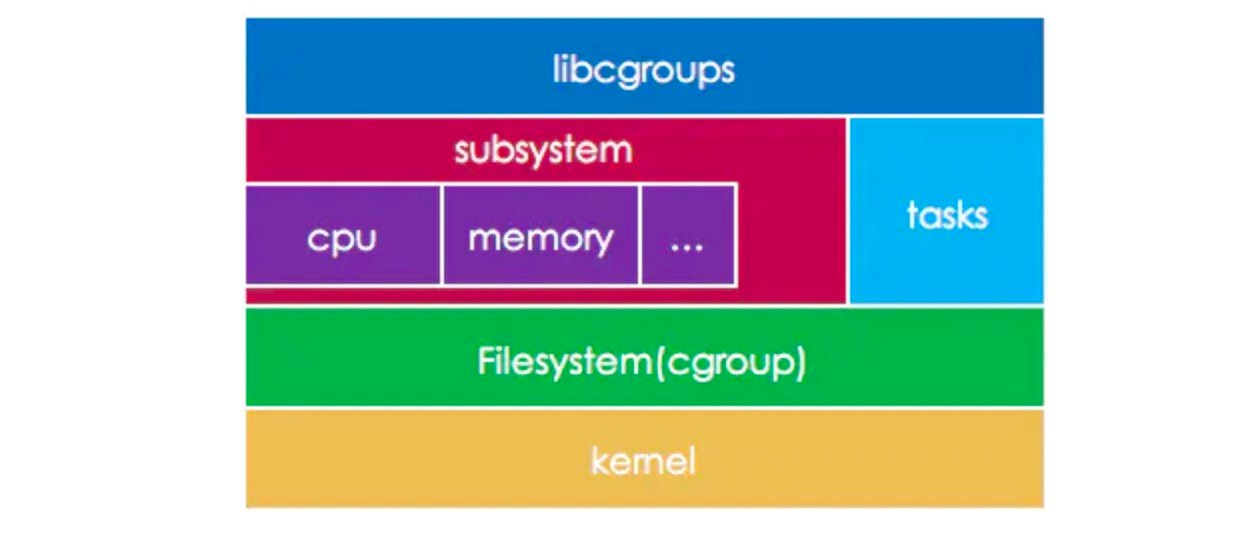
Subsistemas Cgroup
Cgroups define vários tipos de recursos do sistema que podem ser controlados como subsistemas (subsistemas), incluindo:
- cpu : limita a taxa de uso de um único núcleo de CPU de uma tarefa.
- cpuset : limita o conjunto de núcleos de CPU usados pela tarefa.
- cpuacct : Relatório de uso da CPU da tarefa de estatísticas (Contabilidade).
- memory : limita a capacidade de memória usada pela tarefa.
- enormetlb : Limite a enorme capacidade de memória de página de Task.
- devices : Limita os dispositivos que a Tarefa pode acessar.
- blkio : Limita o uso de Block I/O de Task.
- net_cls : Limite o tipo de pacote de rede da tarefa (Classificador de rede) e o uso de Net I/O.
- net_prio : Defina a prioridade de processamento do tráfego de rede (Network Traffic) da tarefa.
- namespace : Restringir tarefas para usar diferentes namespaces.
- freezer : Suspenda ou retome a tarefa especificada.
- perf_event : Permite o monitoramento com a ferramenta perf.
- pids : Limita o número de Tarefas associadas a um cgroup.
- etc.
A definição desses subsistemas é principalmente fornecer entradas de configuração correspondentes, e a implementação de restrições específicas de recursos do sistema é reutilizar totalmente vários módulos funcionais do próprio Kernel, por exemplo:
- O subsistema cpu depende da implementação do Kernel Process Scheduler.
- O Subsistema de memória depende da implementação do Kernel Memory Manager.
- O subsistema net_cls depende da implementação do Kerne Traffic Control.
- etc.
Você pode visualizar os subsistemas Cgroup suportados no sistema através da CLI:
$ sudo yum install libcgroup-tools
$ lssubsys -a
cpuset
cpu,cpuacct
blkio
memory
devices
freezer
net_cls,net_prio
perf_event
hugetlb
pids
rdma
Sistema de Arquivos Cgroup
Cgroups fornece uma entrada de configuração cgroup unificada para Userspace através da interface de arquivo Kernel VFS (Virtual File System, sistema de arquivo virtual).
Você pode visualizar o caminho de montagem e o conteúdo do sistema de arquivos Cgroup atual por meio da CLI:
$ df -h
Filesystem Size Used Avail Use% Mounted on
...
tmpfs 16G 0 16G 0% /sys/fs/cgroup
$ ll /sys/fs/cgroup/
总用量 0
drwxr-xr-x. 4 root root 0 6月 1 16:22 blkio
lrwxrwxrwx. 1 root root 11 6月 1 16:22 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 6月 1 16:22 cpuacct -> cpu,cpuacct
drwxr-xr-x. 4 root root 0 6月 1 16:22 cpu,cpuacct
drwxr-xr-x. 2 root root 0 6月 1 16:22 cpuset
drwxr-xr-x. 4 root root 0 6月 1 16:22 devices
drwxr-xr-x. 2 root root 0 6月 1 16:22 freezer
drwxr-xr-x. 2 root root 0 6月 1 16:22 hugetlb
drwxr-xr-x. 4 root root 0 6月 1 16:22 memory
lrwxrwxrwx. 1 root root 16 6月 1 16:22 net_cls -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 6月 1 16:22 net_cls,net_prio
lrwxrwxrwx. 1 root root 16 6月 1 16:22 net_prio -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 6月 1 16:22 perf_event
drwxr-xr-x. 4 root root 0 6月 1 16:22 pids
drwxr-xr-x. 4 root root 0 6月 1 16:22 systemd
Pode-se ver que, por padrão, os Cgroups criarão seu próprio sistema de arquivos Cgroup para subsistemas, que contém os arquivos necessários para definir cotas de recursos e associar-se a várias tarefas. Do seguinte modo.
$ ll /sys/fs/cgroup/memory/
总用量 0
-rw-r--r--. 1 root root 0 6月 1 16:22 cgroup.clone_children
--w--w--w-. 1 root root 0 6月 1 16:22 cgroup.event_control
-rw-r--r--. 1 root root 0 6月 1 16:22 cgroup.procs
-r--r--r--. 1 root root 0 6月 1 16:22 cgroup.sane_behavior
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.failcnt
--w-------. 1 root root 0 6月 1 16:22 memory.force_empty
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.failcnt
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.max_usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.kmem.slabinfo
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.failcnt
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.max_usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.kmem.usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.max_usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.memsw.failcnt
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.memsw.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.memsw.max_usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.memsw.usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.move_charge_at_immigrate
-r--r--r--. 1 root root 0 6月 1 16:22 memory.numa_stat
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.oom_control
----------. 1 root root 0 6月 1 16:22 memory.pressure_level
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.soft_limit_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.stat
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.swappiness
-r--r--r--. 1 root root 0 6月 1 16:22 memory.usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.use_hierarchy
-rw-r--r--. 1 root root 0 6月 1 16:22 notify_on_release
-rw-r--r--. 1 root root 0 6月 1 16:22 release_agent
drwxr-xr-x. 55 root root 0 6月 1 16:23 system.slice
-rw-r--r--. 1 root root 0 6月 1 16:22 tasks
drwxr-xr-x. 2 root root 0 6月 1 16:23 user.slice
Entre eles, o arquivo de interface principal do cgroup é prefixado com cgroup:
- cgroup.clone_children : Identifica se o cgroup filho herdará o cgroup pai. O valor padrão é 0, o que significa nenhuma herança.
- cgroup.procs : Quando for Root cgroup, todos os PIDs na Hierarquia serão registrados.
- etc.
Aquele prefixado com memória é o arquivo de interface do Controlador, que é o controlador projetado pelo modelo de alocação de recursos Cgroups, incluindo:
- Peso : aloca recursos de acordo com a proporção de peso.
- limit(max) : limita o uso excessivo de recursos.
- Proteção : Pode ser proteção rígida ou proteção flexível.
- Alocação : Parâmetros de alocação de recursos.
O restante também possui um arquivo de interface de gerenciamento, por exemplo:
- notify_on_release : Indica se deve executar release_agent quando a última Tarefa deste cgroup for encerrada.
- release_agent : É um caminho, que é usado para limpar automaticamente os cgroups não utilizados depois que a Tarefa é encerrada.
- tarefas : Registra a lista de tarefas associadas a este cgroup.
Hierarquia Cgroup
Cgroups usam o método Filesystem para fornecer entrada de operação, e outra vantagem trazida por ele é que ele suporta a forma organizacional Cgroup Hierarchy (hierárquica), que é representada como uma estrutura de árvore.
Quando o usuário cria um cgroup filho no cgroup pai, o cgroup filho também criará automaticamente os arquivos de configuração necessários e pode configurar se deseja herdar a configuração relevante do cgroup pai. Como mostrado abaixo.
$ mkdir /sys/fs/cgroup/memory/cgrp1/
$ ls /sys/fs/cgroup/memory/cgrp1/
cgroup.clone_children memory.kmem.limit_in_bytes memory.kmem.tcp.usage_in_bytes memory.memsw.max_usage_in_bytes memory.soft_limit_in_bytes tasks
cgroup.event_control memory.kmem.max_usage_in_bytes memory.kmem.usage_in_bytes memory.memsw.usage_in_bytes memory.stat
cgroup.procs memory.kmem.slabinfo memory.limit_in_bytes memory.move_charge_at_immigrate memory.swappiness
memory.failcnt memory.kmem.tcp.failcnt memory.max_usage_in_bytes memory.numa_stat memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.limit_in_bytes memory.memsw.failcnt memory.oom_control memory.use_hierarchy
memory.kmem.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.limit_in_bytes memory.pressure_level notify_on_release

Finalmente, um arquivo de tarefas é incluído no sistema de arquivos de cada cgroup, que é usado para salvar a lista de tarefas associadas ao cgroup atual. Se quisermos adicionar um processo de usuário a um cgroup, podemos escrever seu PID no arquivo de tarefas. do seguinte modo:
$ cd /sys/fs/cgroup/memory/cgrp1 # 进入 cgrp1
$ echo 1029 > tasks # 将 PID 1029 的 Process 添加到 cgrp1 的 tasks 列表
Regras Operacionais para Cgroups
Ao usar Cgroups, os usuários devem seguir certas regras operacionais, caso contrário, ocorrerão erros. O objetivo das regras de operação é evitar conflitos na configuração de cotas de recursos.
-
Uma Hierarquia pode anexar vários Subsistemas, conforme mostrado na figura abaixo, os Subsistemas de cpu e memória são anexados à mesma Hierarquia.
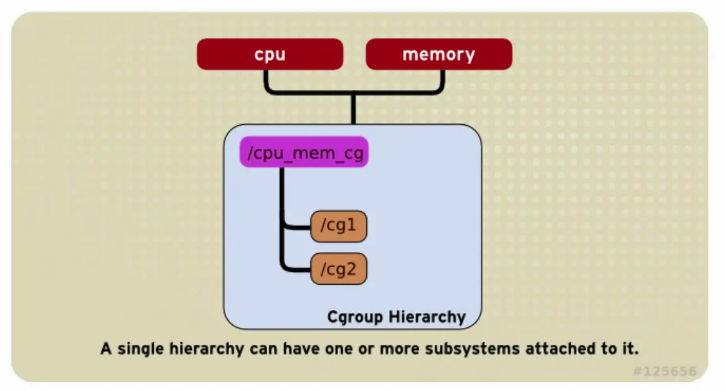
-
Um Subsistema que foi Anexado só pode ser Anexado a uma Hierarquia vazia novamente e não pode ser Anexado a uma Hierarquia que foi Anexada a outros Subsistemas. Conforme mostrado na figura abaixo, o Subsistema cpu foi Anexado à Hierarquia A, e o O subsistema de memória foi anexado à Hierarquia B. Portanto, o Subsistema cpu não pode mais ser Anexado à Hierarquia B, mas apenas pode ser Anexado a outra Hierarquia C vazia.
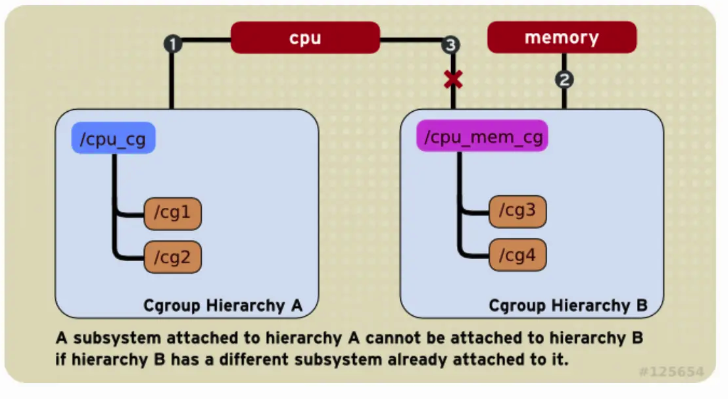
-
Cada Tarefa só pode estar nas únicas tarefas cgroup da mesma Hierarquia, e pode estar em múltiplas tarefas cgroup de diferentes Hierarquias. Conforme mostrado na figura abaixo, isso garante que a mesma cota de cgroup para uma tarefa seja exclusiva.
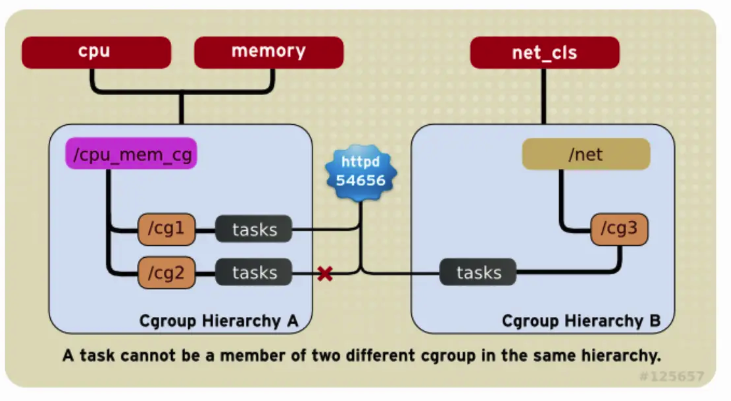
-
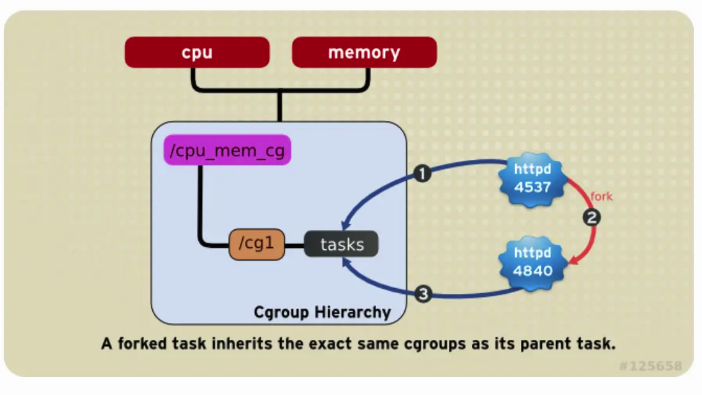
Quando o processo filho é bifurcado, ele herda automaticamente os cgroups do processo pai, mas após o fork, pode ser ajustado para outros cgroups conforme necessário, conforme mostrado na figura a seguir:
Implementação de Código de Cgroups
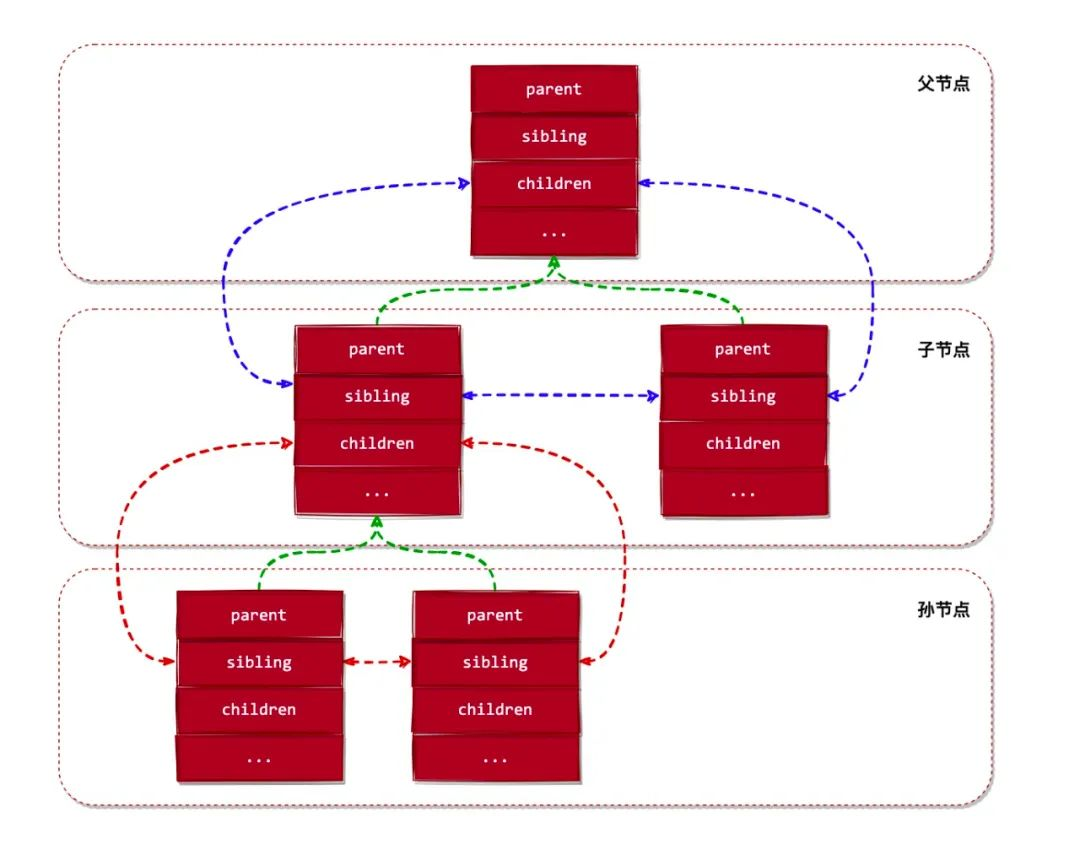
Agora olhe novamente para a declaração e definição do cgroup no Kernel, que é projetado como uma estrutura de dados em árvore:
struct cgroup {
...
// 下面 3 个字段把 cgroup 设计成了一个树数据结构
struct list_head sibling; // 兄弟节点
struct list_head children; // 子节点
struct cgroup *parent; // 父节点
struct dentry *dentry; // cgroup 对应的目录对象
// cgroup 关联的 subsystems 对象
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
...
};
Por padrão, durante a inicialização do Kernel, um rootnode (nó raiz) é automaticamente instanciado e todos os FSs do cgroup do Subsistema são associados a este rootnode.
static struct cgroupfs_root rootnode;
struct cgroupfs_root {
struct super_block *sb; // Root cgroup FS 的挂载点(VFS 使用)
...
struct list_head subsys_list; // Root cgroup 绑定的 Subsystems 列表
struct cgroup top_cgroup; // Root cgroup 对象
int number_of_cgroups; // Root cgroup 拥有的 cgroups 的数量
...
};
Se os usuários quiserem montar subsistemas manualmente em outro cgroup FS, eles também podem usar o comando mount para montar, conforme mostrado no seguinte comando:
$ mount -t cgroup -o memory memory /sys/fs/cgroup/memory1
Além disso, o campo cgroup_subsys_state em cgroup é usado para associar a uma lista de estado de subsistemas (estrutura de estatísticas de recursos de subsistema) e, em seguida, associar a vários subsistemas específicos.
struct cgroup_subsys_state {
struct cgroup *cgroup; // 指向 cgroup 对象
atomic_t refcnt; // 引用计数器
unsigned long flags; // 标志位
};
struct mem_cgroup {
// 资源统计对象通用部分
struct cgroup_subsys_state css;
// 资源统计对象私有部分
struct res_counter res; // 用于统计 tasks 的内存使用情况
struct mem_cgroup_lru_info info;
int prev_priority;
struct mem_cgroup_stat stat;
};
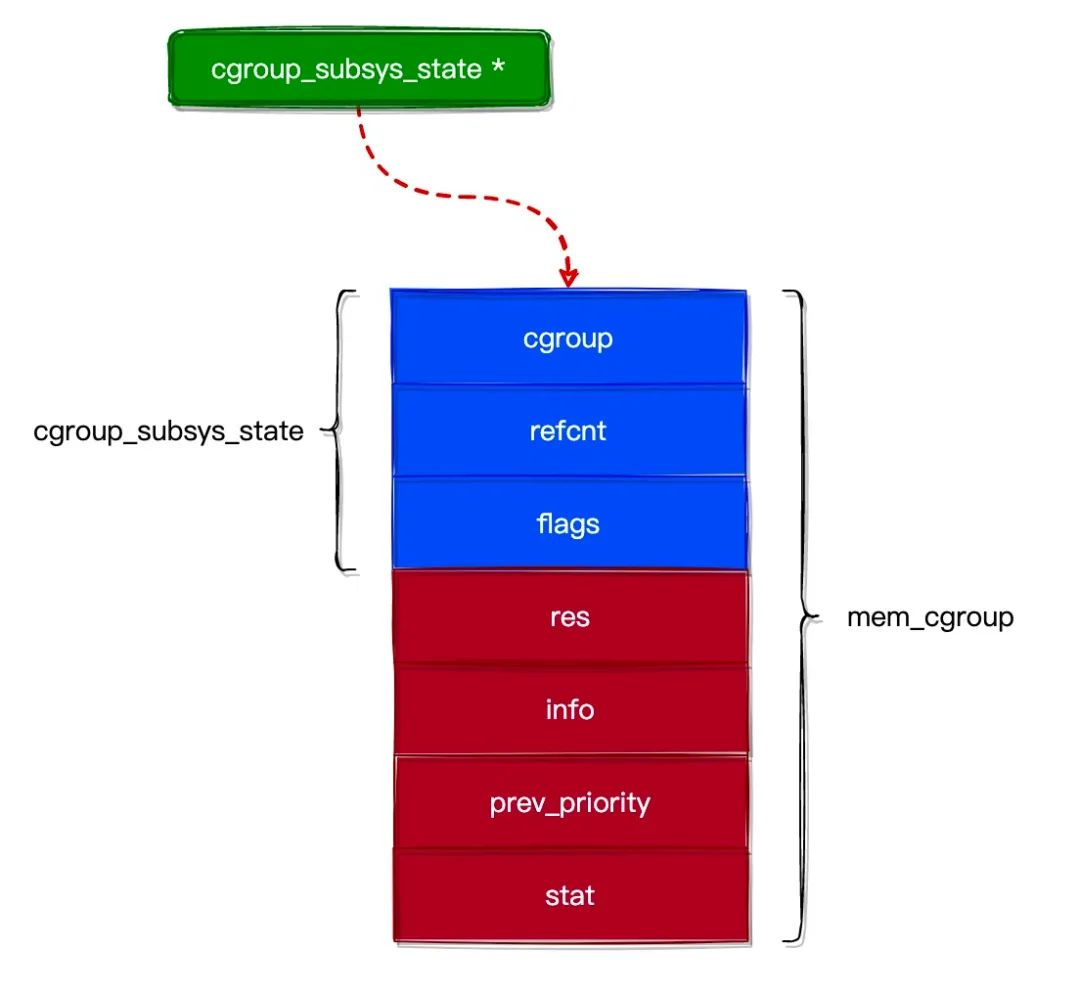
Pode-se ver que o cgroup e os subsistemas têm um relacionamento um-para-muitos, conforme mostrado na figura abaixo.
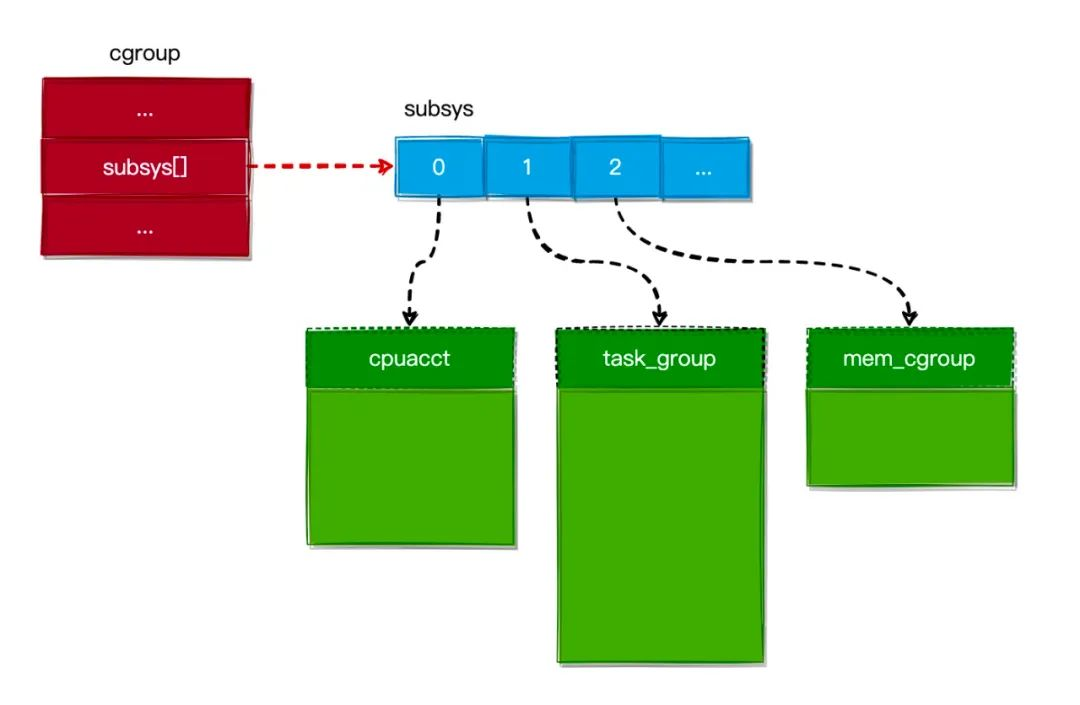
Ao mesmo tempo, porque uma Tarefa pode ser associada a vários cgroups, o relacionamento muitos-para-muitos entre Tarefas e Subsistemas é finalmente realizado. Como mostrado abaixo:
- ProcessA pertence a /sys/fs/cgroup/memory/cgrp1/cgrp3 e /sys/fs/cgroup/cpu/cgrp2/cgrp3, portanto, ProcessA está associado a dois estados de subsistemas Cgroup, mem_groupA e task_groupA.
- O ProcessoB pertence a /sys/fs/cgroup/memory/cgrp1/cgrp4 e /sys/fs/cgroup/cpu/cgrp2/cgrp3, portanto, o ProcessoB está associado aos dois estados dos subsistemas Cgroup mem_groupB e task_groupA.
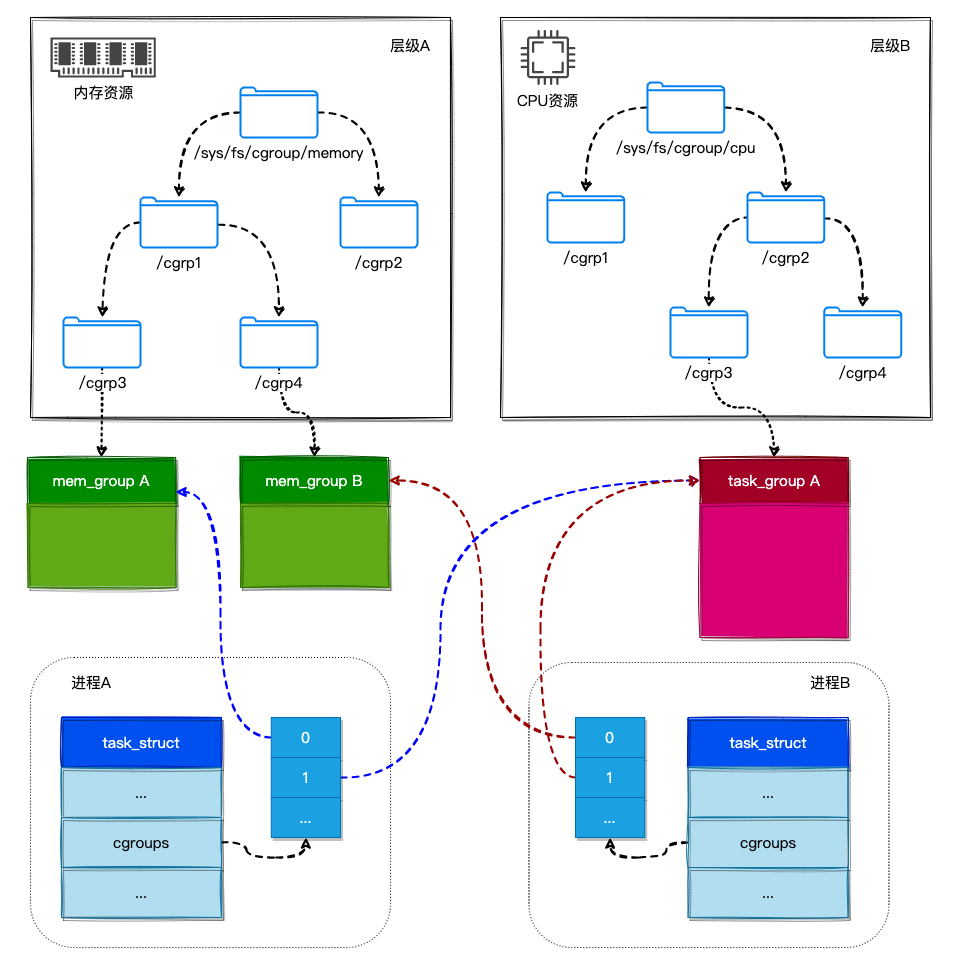
Na task_struct de Task, registre a lista Cgroup Subsystems State associada a ela por meio do campo css_set, conforme a seguir:
struct task_struct {
...
struct css_set *cgroups;
...
};
struct css_set {
...
// 用于收集不同 cgroup 的资源统计对象
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
};
Finalmente, uma estrutura de relacionamento de mapeamento de M×N Linkage é formada entre User Process e Cgroups. Como mostrado abaixo.

Namespaces
Linux Namespaces (namespace) é uma tecnologia de isolamento de visualização de recursos no nível do sistema operacional, que pode dividir os recursos globais do Linux em recursos visíveis dentro do escopo do Namespace.
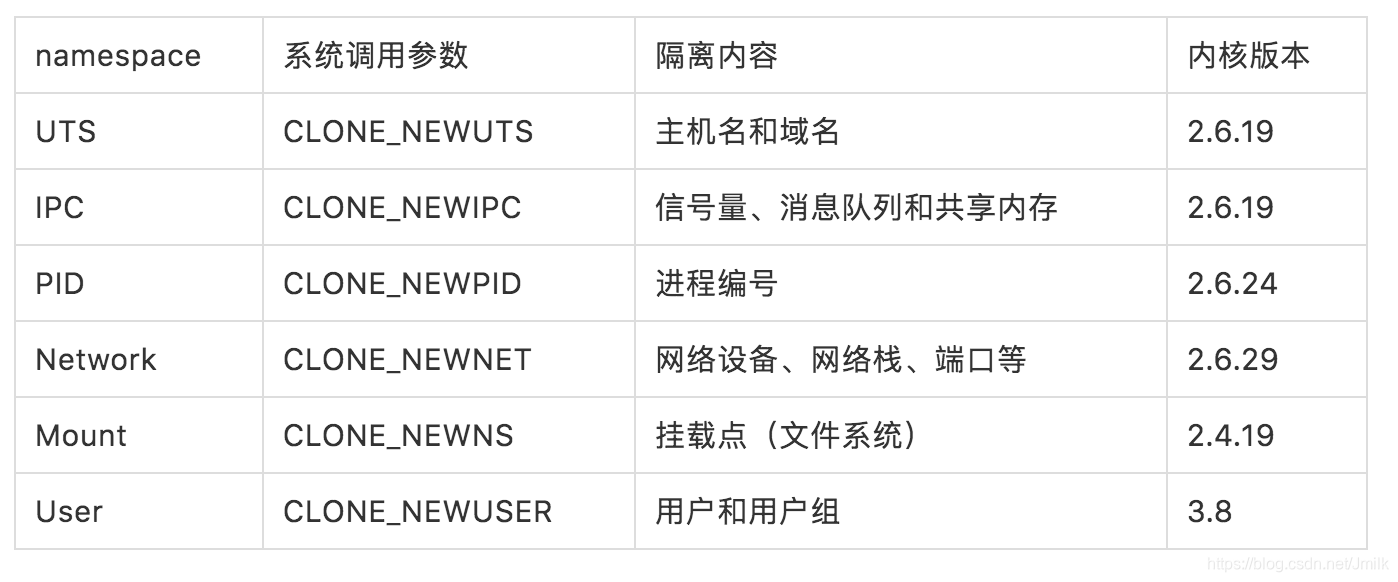
Existem muitos tipos de Namespaces, que cobrem basicamente os elementos básicos necessários para formar um sistema operacional:
- Namespace UTS (nome do host do sistema)
- Time namespace (hora do sistema)
- Espaço de nomes PID (número do processo do sistema)
- Namespace IPC (comunicação entre processos do sistema)
- Mount namespace (sistema de arquivos do sistema)
- Espaço de nomes de rede (rede do sistema)
- Namespace do usuário (permissões de usuário do sistema)
- Espaço de nomes Cgroup (sistema Cgroup)
User Process é o principal objeto de serviço do Namespace, e existem três principais SCIs relacionados a ele:
- clone() : Crie um processo e defina o parâmetro de tipo da instância do namespace ao mesmo tempo.
- setns() : adiciona um processo à instância de namespace especificada.
- unshare() : Tira um Processo da Instância de Namespace especificada.
Conforme mostrado na figura abaixo, cada Namespace possui seu próprio parâmetro de tipo clone:
Por meio do arquivo /proc/{pid}/ns, você pode visualizar em quais instâncias de namespaces o processo especificado é executado e cada instância de namespace possui um identificador exclusivo.
$ ls -l --time-style='+' /proc/$$/ns
总用量 0
lrwxrwxrwx. 1 root root 0 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 uts -> uts:[4026531838]
No final, os usuários podem criar uma variedade de tipos diferentes de instâncias de namespaces para fornecer isolamento de recursos do sistema operacional, combinados com a criação de vários tipos diferentes de cgroups para fornecer cotas de recursos do sistema operacional, constituindo um contêiner básico do sistema operacional. Contêiner de Processo.
espaço de nomes UTS
O namespace UTS fornece o isolamento de nome de host e nome de domínio para contêiner.
O Processo no Container pode ser configurado chamando os comandos sethostname e setdomainname conforme necessário, para que cada Container possa ser considerado como um nó independente na rede.
espaço de nomes PID
O namespace PID fornece o isolamento do ID do processo para o Container.
Cada contêiner tem seu próprio ambiente de processo, e o processo init do contêiner é o processo PID nº 1, que atua como o processo pai de todos os processos filhos. Para obter o isolamento do processo, primeiro você precisa criar um processo com PID 1, que possui as seguintes características:
- Se um processo filho deixar o processo pai (o processo pai não espera por isso), o processo init será responsável por recuperar recursos e encerrar o processo filho.
- Se o processo init for encerrado, o Kernel chamará SIGKILL para encerrar todos os processos neste namespace PID.
espaço de nomes IPC
O namespace IPC fornece o isolamento de mecanismos de comunicação IPC (entre processos) para contêineres, incluindo mecanismos como semáforos, filas de mensagens e memória compartilhada.
Cada Container tem a seguinte interface de arquivo /proc:
- /proc/sys/fs/mqueue : tipo de interface POSIX Message Queues;
- /proc/sys/kernel : tipo de interface System V IPC;
- /proc/sysvipc : tipo de interface System V IPC.
Montar namespace
O namespace Mount fornece o isolamento do ponto de montagem do sistema de arquivos para o contêiner e, em seguida, realiza o isolamento do VFS.
Cada Container possui a seguinte interface de arquivo /proc, que pode formar um rootfs independente (sistema de arquivos raiz):
- /proc/[pid]/mounts
- /proc/[pid]/mountinfo
- /proc/[pid]/mountstats
Na verdade, o namespace Mount é desenvolvido com base na melhoria contínua do Chroot. O rootfs criado para o Container é apenas os arquivos, diretórios e configurações contidos em uma distribuição do sistema operacional, e não inclui os arquivos do Kernel.
Espaço de nomes de rede
Network namespace fornece o isolamento de recursos de rede para Container, incluindo:
- Dispositivos de rede
- Pilhas de protocolo IPv4 e IPv6 (pilha de protocolo IPv4, IPv6)
- tabelas de roteamento IP
- Regras de firewall
- tomadas
- /proc/[pid]/net
- /sys/classe/net
- /proc/sys/net
Deve-se observar que o mesmo dispositivo de rede só pode existir em uma instância de namespace, por isso é frequentemente usado em combinação com dispositivos de rede virtual.

Espaço de nomes de usuário
O namespace do usuário fornece ao Container isolamento relacionado a permissões de usuário e atributos de segurança, incluindo: ID do usuário, ID do grupo de usuários, diretório raiz e permissões especiais.
Cada Container tem a seguinte interface de arquivo /proc:
- /proc/[pid]/uid_map
- /proc/[pid]/gid_map
Aplicação do Docker para Cgroups e Namespaces
Quando criamos um Docker Container, podemos visualizar os cgroups e namespaces do Container.
- Verifique a configuração do ID do contêiner (cfca1212d140) e do PID (2240).
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cfca1212d140 centos:centos7.9.2009 "bash" 18 months ago Up 2 hours vim-ide
$ docker inspect --format='{
{.State.Pid}}' cfca1212d140
2240
- Verifique a configuração dos cgroups do Container.
$ ll /sys/fs/cgroup/memory/docker/
总用量 0
drwxr-xr-x. 2 root root 0 6月 2 03:40 cfca1212d1407a89632a439e974e246d1f6edd0bbef9079f06addf2613e1d46f
$ cat /sys/fs/cgroup/memory/docker/cfca1212d1407a89632a439e974e246d1f6edd0bbef9079f06addf2613e1d46f/cgroup.procs
2240
$ cat /sys/fs/cgroup/memory/docker/cfca1212d1407a89632a439e974e246d1f6edd0bbef9079f06addf2613e1d46f/memory.limit_in_bytes
9223372036854771712
- Confira a configuração dos namespaces do Container.
$ ls -l --time-style='+' /proc/2240/ns
总用量 0
lrwxrwxrwx. 1 root root 0 ipc -> ipc:[4026532433]
lrwxrwxrwx. 1 root root 0 mnt -> mnt:[4026532431]
lrwxrwxrwx. 1 root root 0 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 pid -> pid:[4026532434]
lrwxrwxrwx. 1 root root 0 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 uts -> uts:[4026532432]
documentos de referência
- https://mp.weixin.qq.com/s/EdRVEJ0i5j9eHwd8QK-cDg
- https://juejin.cn/post/6921299245685276686
- https://zhuanlan.zhihu.com/p/388101355