OCR é uma inovação tecnológica que ajuda os usuários a extrair texto de imagens ou documentos digitalizados e convertê-los em um formato legível por computador, automatizando o processo de reduzir consideravelmente a entrada manual. Esta função é particularmente útil em muitos cenários que requerem processamento adicional de dados, como verificação de identidade, gerenciamento de despesas, reembolso automático, processamento de negócios, etc. Hoje, as soluções de OCR combinam as tecnologias AI (Inteligência Artificial) e ML (Machine Learning) para automatizar o processo e melhorar a precisão da extração de dados. Este artigo apresentará o passado e o presente dessa tecnologia e dará uma olhada no desenvolvimento gradual dessa tecnologia: o passado dominado pela tecnologia OCR tradicional, o presente chamativo da tecnologia OCR de aprendizado profundo e o futuro iminente do OCR pré-treinado modelos grandes!
1. A vida passada do OCR: o passado governado pela tecnologia OCR tradicional
Como funciona a tecnologia OCR tradicional
A maneira como o OCR funciona pode ser comparada à capacidade humana de ler texto e reconhecer padrões. A tecnologia OCR tradicional reconhece e extrai automaticamente caracteres em imagens ou documentos por meio de visão computacional e tecnologia de reconhecimento de padrões. A tecnologia OCR tradicional precisa passar pelas seguintes etapas:
1. Pré-processamento de imagem
Este estágio é para aprimorar a qualidade da imagem, incluindo remoção de ruído, binarização (ou seja, conversão da imagem em preto e branco) e correção automática da distorção e inclinação da imagem.
* Aplicação de Pré-processamento de Imagem
No fluxo de trabalho de reconhecimento óptico de caracteres (OCR), o pré-processamento da imagem é a primeira etapa, que estabelece as bases para a precisão e robustez de todo o sistema. Portanto, é fundamental entender as técnicas utilizadas no pré-processamento de imagens e as etapas em que são executadas.
* Definição do pré-processamento da imagem
O pré-processamento de imagem é uma técnica para melhorar os dados da imagem (removendo informações inúteis, aprimorando informações úteis ou aumentando a velocidade computacional) antes que a análise da imagem principal seja realizada. Ele pode melhorar a qualidade da imagem, fazer com que o mecanismo de OCR separe melhor o texto e o plano de fundo e melhorar a precisão do reconhecimento do texto.
* As principais etapas e técnicas de pré-processamento de imagens
1. Denoising : Nesta etapa, vários filtros (por exemplo, filtro mediano, filtro gaussiano, etc.) são usados para reduzir o ruído na imagem, como poeira, arranhões, etc.

2. Escala de cinza : converte uma imagem colorida em uma imagem em escala de cinza. Porque na maioria dos casos, precisamos prestar atenção apenas no contraste entre texto e fundo, não em suas cores. A escala de cinza pode reduzir bastante a complexidade computacional enquanto retém as informações principais.

3. Binarização : Esta etapa converte a imagem em uma imagem contendo apenas preto e branco. O processo de binarização pode ser implementado definindo um limite, todos os pixels abaixo desse limite serão marcados como pretos e os pixels acima do limite serão marcados como brancos. Isso pode aumentar ainda mais o contraste entre o texto e o plano de fundo.

4. Enquadramento e correção : Os sistemas de OCR precisam corrigir automaticamente a distorção e a distorção nas imagens para garantir o reconhecimento correto do texto. Este processo envolve detectar o ângulo de inclinação das linhas de texto na imagem e corrigi-los de acordo.

5. Delineação de área : Também conhecida como análise de layout, esta etapa é usada para identificar áreas de texto, áreas não textuais e informações estruturais de texto na imagem, como colunas, linhas, blocos, cabeçalhos, parágrafos, tabelas, etc. Através desta etapa, uma base pode ser fornecida para as etapas subsequentes de extração de texto.
*Importância do pré-processamento de imagens*
Um bom pré-processamento de imagem pode melhorar significativamente a eficiência e a precisão das etapas subsequentes. Ele melhora a qualidade da imagem, separa melhor o texto do plano de fundo, remove o ruído das imagens, corrige distorções e distorções nas imagens, reconhece informações estruturais no texto e muito mais. Esses são os principais fatores para garantir que o sistema OCR possa reconhecer e extrair texto com precisão. Portanto, uma compreensão aprofundada e o domínio das etapas e técnicas de pré-processamento de imagens são cruciais para a construção de um sistema de OCR eficiente e preciso.
2. Segmentação de caracteres
A segmentação de caracteres é uma etapa importante no processo de OCR. O objetivo desta etapa é segmentar a área de texto na imagem em caracteres independentes para reconhecimento de caracteres nas etapas subsequentes. A seguir estão os principais passos e algumas técnicas comuns usadas para segmentação de caracteres.

*As principais etapas da segmentação de caracteres *
1. Segmentação de linha : o objetivo desta etapa é segmentar regiões de texto na imagem em linhas individuais. Normalmente, a segmentação de linha pode ser obtida analisando o histograma de projeção horizontal da imagem. O histograma de projeção horizontal é obtido acumulando o valor de cinza de cada pixel da imagem na direção horizontal. Entre linhas de texto, o valor acumulado geralmente cai significativamente, e os locais onde essas quedas são onde ocorrem as divisões de linha.
2. Segmentação de caracteres : após a segmentação de linha, a próxima etapa é segmentar ainda mais cada linha de texto em caracteres individuais. Isso geralmente pode ser obtido analisando histogramas de projeção vertical. Semelhante ao histograma de projeção horizontal, o histograma de projeção vertical é obtido acumulando o valor de cinza de cada pixel na direção vertical. Entre os personagens, o valor acumulado também costuma cair significativamente, e os locais dessas quedas são onde ocorrem as divisões dos personagens.
* Problemas comuns e soluções de segmentação de caracteres*
No processo de segmentação de caracteres, existem alguns problemas comuns, como aderência e desconexão de caracteres. Esses problemas podem fazer com que os caracteres não sejam segmentados corretamente, afetando a precisão do OCR.
1. Colagem de caracteres : Às vezes, dois ou mais caracteres em uma imagem podem estar intimamente conectados para formar uma forma que se parece com um único caractere. Para resolver esse problema, um método comum é separar caracteres coesos por meio de operações morfológicas. Por exemplo, você pode usar técnicas de afinamento ou esqueletização para extrair as linhas centrais dos caracteres e, a seguir, separar os caracteres colados com base nessas linhas centrais.
2. Desconexão do personagem : Às vezes, um personagem em uma imagem pode ser desconectado em duas ou mais partes devido a ruídos ou outros motivos. Para resolver esse problema, um método comum é conectar caracteres desconexos por meio de operações morfológicas. Por exemplo, você pode usar técnicas de dilatação ou fechamento para preencher buracos em caracteres e, em seguida, conectar caracteres desconectados com base nessas formas preenchidas.
No geral, a segmentação de caracteres é uma etapa fundamental no OCR. Somente quando os caracteres da imagem são segmentados com precisão, o sistema OCR pode identificar e extrair corretamente esses caracteres. Portanto, uma compreensão aprofundada e o domínio das etapas e técnicas de segmentação de caracteres são cruciais para a construção de um sistema de OCR eficiente e preciso.
3. Reconhecimento de caracteres
Nesta etapa, a imagem ou documento é dividido em partes ou regiões e os caracteres nelas contidos são reconhecidos. Esse processo envolve correspondência de matriz (ou seja, cada caractere é comparado a uma biblioteca de matrizes de caracteres) e reconhecimento de recursos (ou seja, identificação de padrões de texto e recursos de caracteres de imagens).

* Tecnologia de reconhecimento de caracteres *
O reconhecimento de caracteres é uma etapa crítica no fluxo de trabalho de reconhecimento óptico de caracteres (OCR). Nesta etapa, o sistema precisa reconhecer cada caractere individual obtido pela segmentação. A seguir estão as principais técnicas e etapas na etapa de reconhecimento de caracteres, principalmente em sistemas tradicionais de OCR.
* extração de recursos*
A extração de recursos é o primeiro passo no reconhecimento de caracteres e seu objetivo é extrair recursos que possam refletir sua forma e estrutura principais de cada imagem de personagem. Essas características podem ajudar a distinguir diferentes caracteres. Nos sistemas tradicionais de OCR, os métodos comuns de extração de recursos incluem:
- *Matriz de Coocorrência de Nível de Cinza (GLCM)* GLCM é um método estatístico para extrair recursos de textura de imagens. Esses recursos incluem contraste, correlação, energia e homomorfismo, entre outros.
- *Momentos invariantes Hu* Os momentos invariantes Hu são um conjunto de recursos que podem resistir a mudanças na translação, escala e rotação da imagem.
- *Fourier Descriptor * Fourier Descriptor pode extrair recursos da forma dos caracteres, especialmente os limites dos caracteres.
* classificação *
Depois que os recursos são extraídos, o próximo passo é usar esses recursos para classificar os caracteres. Nos sistemas tradicionais de OCR, o classificador mais comum é uma Support Vector Machine (SVM).
- *Support Vector Machine (SVM)* SVM é um modelo de aprendizado supervisionado que realiza a classificação encontrando o limite de decisão que maximiza a distância entre as classes.
Ao treinar um classificador, é necessário um conjunto de caracteres rotulados com rótulos de classes reais. Ao realizar o reconhecimento de caracteres, o classificador produzirá um rótulo de categoria de acordo com os recursos de entrada, e esse rótulo é o resultado do reconhecimento.
*Avaliação de Desempenho *
Após a conclusão do reconhecimento de caracteres, o desempenho do sistema precisa ser avaliado. Métricas de desempenho comumente usadas incluem exatidão, precisão, recall e pontuação F1. Essas métricas podem nos ajudar a entender como um classificador funciona em diferentes condições para que ele possa ser otimizado e aprimorado.
Limitações do OCR tradicional
Embora a tecnologia tradicional de reconhecimento óptico de caracteres (OCR) funcione muito bem em muitos cenários, ela apresenta algumas limitações, especialmente em situações complexas ou desafiadoras. Aqui estão algumas das principais limitações:
1. Altos requisitos de clareza e qualidade : A tecnologia OCR tradicional é altamente dependente da qualidade da imagem. Se a imagem de entrada for de baixa qualidade (por exemplo, imagem borrada, baixo contraste, iluminação irregular, presença de ruído, etc.), a precisão do OCR pode ser bastante reduzida.
2. Dependência de fontes e layouts : As técnicas tradicionais de OCR geralmente são treinadas com base em fontes e layouts específicos. Portanto, se o texto de entrada usar uma fonte não incluída nos dados de treinamento ou tiver um layout diferente, a precisão do reconhecimento poderá ser afetada.
3. O desafio de lidar com : Se os caracteres de texto estiverem intimamente ligados ao fundo ou o texto estiver em um fundo complexo, os sistemas OCR tradicionais podem ter dificuldade em segmentar e reconhecer os caracteres com precisão. Da mesma forma, os sistemas OCR tradicionais podem não ser capazes de reconhecer com precisão os caracteres se eles forem decorados ou renderizados em WordArt.
4. Reconhecimento de manuscrito difícil : Para o reconhecimento de texto manuscrito, os sistemas OCR tradicionais geralmente encontram maiores desafios, porque a forma, o tamanho e a inclinação do texto manuscrito variam muito e muitas vezes não possuem limites claros.
5. Incapaz de lidar com vários idiomas e caracteres especiais : os sistemas OCR tradicionais geralmente são otimizados para um ou alguns idiomas e podem não fornecer resultados de reconhecimento satisfatórios para outros idiomas ou caracteres especiais, como símbolos matemáticos e símbolos musicais.
6. Falta de compreensão do contexto : As tecnologias tradicionais de OCR geralmente tratam o reconhecimento de caracteres como uma tarefa independente, sem considerar as informações de contexto dos caracteres. Portanto, se um caractere estiver desfocado na imagem, o sistema OCR pode não ser capaz de reconhecer esse caractere com precisão.
Em geral, embora a tecnologia OCR tradicional funcione muito bem em alguns cenários, ao lidar com tarefas complexas ou desafiadoras, as limitações dessa tecnologia serão expostas. É por isso que mais e mais pesquisadores começaram a explorar o uso de técnicas mais avançadas, como o aprendizado profundo, para melhorar os sistemas de OCR.
2. A vida atual do OCR: o presente da tecnologia OCR de aprendizagem profunda
A tecnologia OCR tradicional não é ideal ao lidar com imagens complexas e texto de formato irregular. Na era do aprendizado profundo, as máquinas podem "aprender" a lidar com tarefas complexas e ter boa adaptabilidade aos dados. Ao combinar o aprendizado profundo para criar um modelo de OCR mais poderoso e flexível, ele pode processar vários tipos de texto e melhorar a precisão do reconhecimento de caracteres.
A tecnologia OCR de aprendizado profundo é dividida em duas etapas: detecção de texto e reconhecimento de texto.
Detecção de texto de aprendizado profundo
Proposta baseada na caixa de candidatos: um exemplo de FastRCNN
FastRCNN (Fast Regional Convolutional Neural Network) é um modelo de aprendizado profundo para detecção de alvos. Ele usa a Region Proposal Network (RPN) para descobrir a área onde o alvo pode existir na imagem e, em seguida, passa por uma convolução A rede executa a extração de recursos e classificação dessas regiões. Ele pode alcançar maior velocidade de computação e detecção de alvo mais precisa ao processar dados de imagem.
No cenário OCR (reconhecimento óptico de caracteres, reconhecimento óptico de caracteres), o FastRCNN pode ser usado para localizar e reconhecer conteúdo de texto em imagens. Ele pode reconhecer todas as formas de texto, incluindo texto impresso, manuscrito e até mesmo não estruturado. Como o FastRCNN é um modelo de tarefa de dois níveis, ele primeiro localiza a área de texto e depois executa o reconhecimento de texto, o que torna o modelo altamente eficiente e preciso ao lidar com tarefas de reconhecimento de texto em cenas complexas.

https://arxiv.org/pdf/1506.01497.pdf
Descrição técnica
Para detecção de região de texto, o FastRCNN gera possíveis propostas de região de texto via RPN. RPN é uma rede totalmente convolucional que pode gerar potenciais regiões de texto em qualquer lugar da imagem, o que desempenha um papel importante no processamento de várias imagens complexas, especialmente imagens contendo várias regiões de texto de tamanhos diferentes e layouts complexos.
passos técnicos
** Proposta de região :** Utiliza a rede RPN para gerar propostas de região de texto latente em imagens pré-processadas.
** Extração e classificação de recursos :** Use FastRCNN para extração e classificação de recursos para cada região proposta. Como o FastRCNN pode executar o compartilhamento de recursos em diferentes regiões, ele pode melhorar muito a eficiência computacional sem sacrificar a precisão.
**Pós- processamento : **Processe a saída do modelo, incluindo fusão, desduplicação e classificação das regiões de texto detectadas e, finalmente, retorne os resultados da detecção e reconhecimento ao usuário.
** Aprendizado e otimização contínuos :** De acordo com o desempenho do modelo em aplicações práticas, colete dados de feedback, otimize e treine continuamente o modelo e melhore seu desempenho em cenários complexos.
Baseado em segmentação: um exemplo de MaskRCNN
O Mask-RCNN é um modelo de detecção de objetos baseado em deep learning, cuja principal característica é a detecção simultânea de objetos e a segmentação de imagens em nível de pixel. O modelo adiciona uma tarefa de segmentação paralela com base no FastRCNN, que pode gerar informações como classificação, localização e formato do alvo.
No cenário OCR (reconhecimento óptico de caracteres, reconhecimento óptico de caracteres), o Mask-RCNN pode ser usado para detectar e segmentar com precisão o texto. Como o Mask-RCNN pode não apenas reconhecer o texto na imagem, mas também fornecer com precisão a forma e a posição do texto, isso o torna especialmente adequado para processar imagens de texto com layouts e formas complexas.

Descrição técnica
A aplicação de Mask-RCNN em cenários de OCR envolve principalmente detecção de região de texto e segmentação de forma.
Primeiro, como o FastRCNN, o Mask-RCNN gera possíveis propostas de região de texto via RPN. Então, para cada região proposta, Mask-RCNN não apenas executa as tarefas de classificação e regressão do FastRCNN, mas também executa uma tarefa adicional de segmentação paralela em nível de pixel.
No OCR, essa tarefa de segmentação pode ser usada para gerar informações precisas de forma e posição do texto, que tem valor de aplicação importante para processar imagens de texto com layout e forma complexos, como texto de formato livre, texto organizado vertical ou obliquamente.
passos técnicos
**Proposta de região :** Utiliza a rede RPN para gerar propostas de região de texto latente em imagens pré-processadas.
**Extração , classificação e segmentação de recursos :** Para cada região proposta, o Mask-RCNN realiza simultaneamente extração, classificação e segmentação em nível de pixel. Por meio dessas tarefas, pode-se obter a categoria, a posição e a forma precisa de cada personagem.
**Pós- processamento : **Saída do modelo de processo, incluindo fusão, desduplicação e classificação de regiões de texto detectadas e geração de informações precisas de forma e posição do texto com base nos resultados da segmentação.
**Aprendizado e otimização contínuos: **De acordo com o desempenho do modelo em aplicações práticas, colete dados de feedback, otimize e treine continuamente o modelo e melhore seu desempenho em cenários complexos.
Reconhecimento de Texto de Aprendizado Profundo
Quando falamos sobre a rota técnica de reconhecimento de texto OCR de aprendizado profundo, existem três direções principais: método de decodificação baseado em CTC, método de decodificação baseado em atenção e método baseado em segmentação de caracteres.
Método de decodificação baseado em CTC:
Imagine que você está ouvindo um trecho de áudio e precisa converter o diálogo em texto. Isso requer um sistema capaz de traduzir sons em caracteres em ordem cronológica. Esse é o conceito da CTC (Classificação Temporal Conexionista). O que o CTC resolve é como converter áudio (ou imagens) com duração fixa em texto de duração não fixa.
CTC (Conexionist Temporal Classification) é um método de decodificação especial para problemas sequenciais. Na tarefa de OCR, pode nos ajudar a estabelecer uma relação de mapeamento entre recursos de série temporal de dimensão fixa e saídas de dimensão não fixa (por exemplo: sequências de texto). Então, como exatamente isso funciona?
Descrição técnica
A principal inovação do CTC é a introdução de um símbolo especial, geralmente chamado de caractere "espaço" ou caractere "em branco". Esse caractere não tem significado semântico real, mas desempenha um papel fundamental no treinamento do modelo.
Especificamente, quando treinamos um modelo, precisamos de uma entrada de comprimento fixo (como uma imagem) para corresponder a uma saída de comprimento fixo (como uma sequência de caracteres). Mas no problema de OCR, a largura da imagem de entrada (ou o comprimento do tempo do recurso) geralmente é fixa, enquanto o número de caracteres de saída varia, o que leva a um problema de "desalinhamento" entre a entrada e a saída.
O CTC efetivamente resolve esse problema introduzindo o caractere "espaço". No momento do treinamento, podemos prever uma probabilidade para cada caractere possível, ao mesmo tempo em que prevemos a probabilidade de um caractere "espaço". Podemos então gerar a sequência final de caracteres a partir dessas probabilidades previstas por meio de um processo chamado "decodificação".
passos técnicos
Quando usamos o método de decodificação baseado em CTC para lidar com o problema de OCR, geralmente são adotados os seguintes passos técnicos:
1. Extração de recursos : Primeiro, precisamos extrair recursos úteis da imagem de entrada. Isso geralmente é feito com modelos de aprendizado profundo, como CNNs. A largura de cada imagem é dividida em pequenos blocos ("passos de tempo") e um vetor de características é gerado para cada pequeno bloco.
2. Previsão de Sequência : Em seguida, alimentamos esses vetores de recursos em uma Rede Neural Recorrente (RNN) que prevê um caractere para cada intervalo de tempo e simultaneamente prevê um caractere de "espaço".
3. Decodificação CT C : Finalmente, usamos o algoritmo de decodificação CTC para gerar a sequência final de caracteres a partir das probabilidades previstas. Nesse processo, o caractere "espaço" tem um papel importante: pode ser usado para indicar o limite entre os caracteres, e também pode ser usado para indicar uma etapa de tempo onde não há caracteres.
Neste método de decodificação, o modelo CRNN+CTC é um representante muito típico. A CRNN (Convolutional Recurrent Neural Network) combina os recursos da Convolutional Neural Network (CNN) e da Recurrent Neural Network (RNN) para extrair recursos de imagens com eficiência e realizar a previsão de sequência.
Vale a pena notar que, embora o método de decodificação baseado em CTC tenha vantagens significativas em lidar com entrada de comprimento fixo e saída de comprimento variável, ele não faz uso total das informações de contexto ao prever cada caractere, por isso é difícil lidar com caracteres irregulares. formas. Pode haver alguma degradação no texto, como texto curvo ou manuscrito.
Método de decodificação baseado em atenção: análise técnica de profundidade
Quando lemos, sempre prestamos atenção em algumas partes específicas e ignoramos outras informações menos importantes. Nesse processo, sempre buscamos informações importantes no contexto, que é o mecanismo de Atenção.
A decodificação baseada em atenção é um método muito utilizado em deep learning, principalmente quando se trata de problemas sequenciais, como tradução automática e OCR, apresenta bom desempenho. Chama-se "Atenção" porque imita a tendência humana de se concentrar em partes-chave da informação.
Descrição técnica
A ideia básica do mecanismo de atenção é que, ao fazer previsões, o modelo deve "focar" na parte mais relevante da entrada. No contexto do OCR, isso significa que, ao prever um personagem, o modelo deve se concentrar nas regiões da imagem que são mais relevantes para esse personagem.
O modelo Seq2Seq+Atenção é um modelo típico baseado em Atenção. Este modelo geralmente consiste em duas partes: um codificador (Encoder) e um decodificador (Decoder). A tarefa do codificador é converter a imagem de entrada em um conjunto de vetores de características. A tarefa do decodificador é converter esses vetores de recursos em sequências de caracteres.
Diferente do modelo Seq2Seq tradicional, o decodificador aqui irá selecionar e prestar atenção em quais vetores de características através do mecanismo de Atenção ao gerar cada caractere. Em outras palavras, o modelo "foca" nos recursos que são mais úteis para a previsão atual.
passos técnicos
O uso do método de decodificação baseado em atenção para lidar com o problema de OCR geralmente adota as seguintes etapas técnicas:
1. Extração de recursos : primeiro, precisamos de um codificador (geralmente uma rede neural profunda, como CNN) para converter a imagem de entrada em um conjunto de vetores de recursos.
2. Previsão de sequência : Então, precisamos de um decodificador (geralmente uma rede neural recorrente, como RNN ou LSTM) para converter esses vetores de recursos em sequências de caracteres. Ao gerar cada caractere, o decodificador usa o mecanismo de atenção para selecionar e focar em quais vetores de recursos.
3. Decodificação de Atenção : Através do processo de decodificação de Atenção, o modelo pode gerar uma série de caracteres, que juntos formam o resultado final do texto. Vale a pena notar que, como cada etapa da predição depende da informação de contexto de todas as etapas anteriores, esse método geralmente pode obter melhores resultados ao lidar com texto complexo e irregular.
Embora o método de decodificação baseado em atenção funcione melhor ao lidar com texto de formato irregular, como texto curvo ou manuscrito, deve-se observar que, quando o texto processado é muito longo ou muito curto, esse método pode ser eficaz. Além disso, como o modelo precisa considerar todas as informações de contexto, a complexidade computacional é relativamente alta, o que também é um ponto que precisa ser observado no método de decodificação baseada em atenção.
Métodos de segmentação baseados em caracteres
Quando lemos palavras, nós as lemos letra por letra. Esse método é muito eficaz para lidar com texto curvo e texto irregular, mas a premissa é que precisamos rotular com precisão cada caractere, que é o método baseado na segmentação de caracteres.
Na área de OCR, o método baseado na segmentação de caracteres é uma solução mais tradicional, cuja ideia central é decompor o problema de OCR em dois subproblemas: detecção de caracteres e reconhecimento de caracteres. Este método tem certas vantagens em lidar com texto curvo e texto irregular, mas tem requisitos mais elevados para rotulagem de caracteres.

Descrição técnica
O método baseado na segmentação de caracteres primeiro usa tecnologia de processamento de imagem para segmentar cada caractere na imagem e, em seguida, reconhece cada caractere individualmente. A vantagem dessa abordagem é que ela pode manipular textos de várias formas e tamanhos, especialmente textos curvos e irregulares. E, como cada caractere é tratado individualmente, ele também lida bem com o espaçamento de caracteres inconsistente.
No entanto, esta abordagem também tem suas limitações. Como requer posicionamento e segmentação precisos de cada caractere, possui altos requisitos para rotulagem de caracteres. Em aplicações práticas, devido a vários fatores de interferência (como iluminação, ruído de fundo, estilo de fonte, etc.), é difícil obter uma segmentação de caracteres totalmente precisa.
passos técnicos
A utilização do método baseado na segmentação de caracteres para lidar com o problema de OCR geralmente adota as seguintes etapas técnicas:
1. Detecção de caracteres : Primeiro, precisamos usar um algoritmo de detecção de caracteres (como janela deslizante ou método baseado em região) para localizar e segmentar cada caractere na imagem. Isso geralmente requer extensas técnicas de processamento de imagem, como detecção de bordas, operações morfológicas, etc.
2. Reconhecimento de caracteres : Então, precisamos reconhecer cada caractere segmentado. Isso pode ser feito com um classificador como SVM ou rede neural profunda. Cada caractere é reconhecido individualmente e depois combinado para formar o texto final.
3. Classificação de caracteres : Depois de identificar todos os caracteres, também precisamos classificá-los para obter a ordem correta de leitura. Isso geralmente pode ser feito com relações espaciais (por exemplo, da esquerda para a direita, de cima para baixo) ou modelos sequenciais (por exemplo, HMMs).
Nesse processo, o posicionamento, segmentação e reconhecimento de caracteres são etapas fundamentais, e os resultados de cada etapa afetarão diretamente o desempenho final do OCR. Portanto, embora o método baseado na segmentação de caracteres tenha suas vantagens em lidar com alguns textos complexos, ele também precisa pesar sua complexidade e precisão em aplicações práticas.
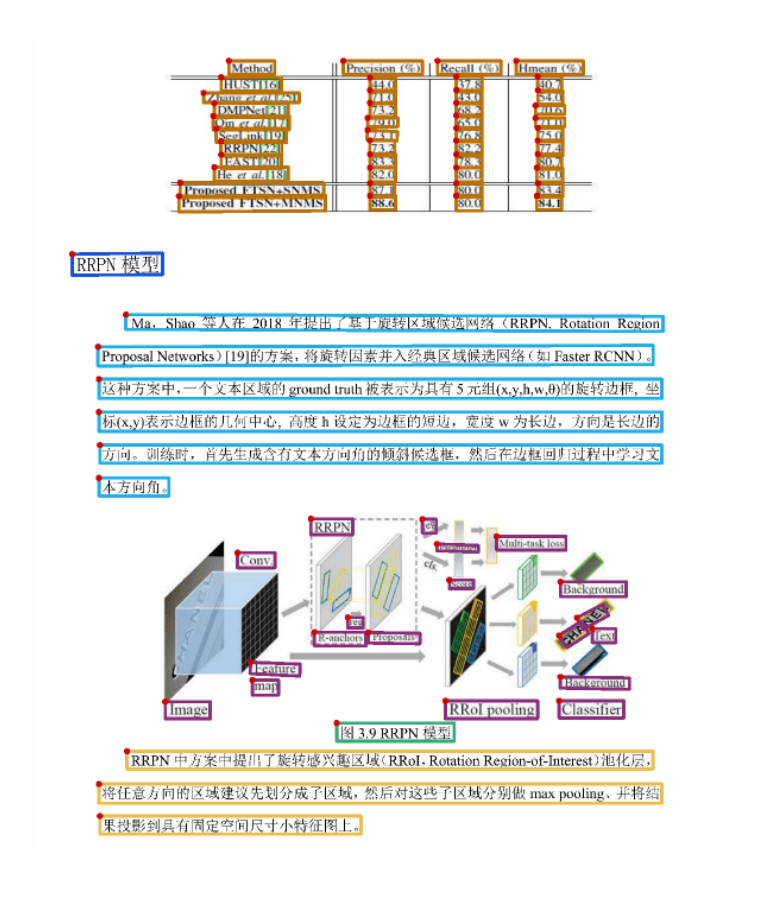
Método baseado em transformador
O modelo Transformer mostrou grande potencial no campo NLP nos últimos anos, e seu excelente desempenho também atraiu a atenção do campo OCR. O método baseado em Transformer fornece uma nova maneira de lidar com o problema de OCR, que pode resolver as limitações das CNNs em lidar com dependências de longo prazo.
Descrição técnica
O núcleo do modelo do Transformer é o mecanismo de auto-atenção (Self-Attention), que permite ao modelo ter uma perspectiva global de cada elemento ao processar os dados da sequência. Em problemas de OCR, isso significa que o modelo pode considerar simultaneamente todas as regiões da imagem ao prever um personagem, não apenas regiões locais.
O modelo Transformer geralmente consiste em duas partes: um codificador (Encoder) e um decodificador (Decoder). A tarefa do codificador é converter a imagem de entrada em um conjunto de vetores de características. A tarefa do decodificador é converter esses vetores de recursos em sequências de caracteres. Vale a pena notar que, devido ao mecanismo de auto-atenção, o codificador e o decodificador podem considerar todos os vetores ou caracteres de recursos ao processar cada vetor ou caractere de recursos.
passos técnicos
O uso de métodos baseados no Transformer para lidar com problemas de OCR geralmente adota as seguintes etapas técnicas:
1. Extração de recursos : primeiro, precisamos de um codificador (geralmente uma rede neural profunda, como CNN) para converter a imagem de entrada em um conjunto de vetores de recursos.
2. Previsão de sequência : Então, precisamos de um decodificador baseado em Transformer para converter esses vetores de recursos em sequências de caracteres. Ao gerar cada caractere, o decodificador usa um mecanismo de auto-atenção para selecionar e focar em quais vetores de recursos.
3. Combinação de caracteres : Finalmente, o decodificador combina as sequências de caracteres geradas no resultado final do texto. Como o modelo Transformer considera todos os vetores de recursos para cada vetor de recursos, esse método geralmente obtém melhores resultados ao lidar com textos complexos e irregulares.
No geral, a abordagem baseada no Transformer é uma maneira muito promissora de lidar com o problema de OCR. Ele não apenas pode superar a limitação da CNN em lidar com problemas de dependência de longo prazo, mas também pode ter um bom desempenho em textos complexos devido à existência do mecanismo de auto-atenção. No entanto, devido à carga computacional relativamente grande do modelo Transformer, em aplicações práticas, deve-se atentar para o equilíbrio entre os recursos computacionais e o desempenho do modelo.
3. O futuro do OCR: o futuro iminente dos modelos grandes de OCR pré-treinamento
Atualmente, modelos grandes de pré-treinamento de NLP e CV (OpenAI GPT, Meta SAM) têm mostrado forte desempenho. Ao pré-treinar uma grande quantidade de dados não rotulados, modelos grandes podem aprender um grande número de recursos visuais e recursos de linguagem, o que melhorará muito o desempenho do modelo em tarefas posteriores. Atualmente, a pesquisa nesta área está em um estágio de desenvolvimento rápido, e alguns estudos mostraram que o grande modelo pré-treinado de aprimoramento de recursos multimodais em nível de caractere conjunto e texto em nível de campo tem grande potencial em tarefas de OCR.

Olhando para o futuro, esperamos que o modelo grande pré-treinado possa melhorar ainda mais o desempenho do OCR, especialmente ao lidar com cenas multilíngues e complexas, textos longos e outros problemas. Ao mesmo tempo, também é necessário estudar como reduzir o consumo de recursos computacionais do modelo e garantir o desempenho, para que esses modelos possam ser aplicados em uma gama mais ampla de dispositivos e cenários.
Hehe TextIn.com tem se concentrado no campo de texto inteligente por 15 anos
