
Para mais informações, preste atenção à conta oficial acima!
Diretório de artigos
Este artigo, como o mais recente resultado da pesquisa da Shangjian Intelligence , foi publicado no principal jornal de pesquisa operacional "INFORMS JOURNAL ON APPLIED ANALYTICS". É a primeira vez que o aprendizado por reforço profundo foi aplicado a cenários de programação de manufatura em larga escala . Isso projeto de programação avançada foi selecionado pela autoridade internacional em pesquisa operacional O Prêmio Franz Edelman, o maior prêmio pela aplicação da pesquisa operacional INFORMS , foi amplamente divulgado pelo People's Daily e outros meios de comunicação como um caso típico de transformação tecnológica de empresas de manufatura.

O primeiro autor, Liang Yi, CEO e CTO da Shangjian Intelligent, especialista em inteligência artificial e algoritmos de otimização operacional, é bacharel em física pela Zhu Kezhen College, Zhejiang University, mestre em física teórica pela McMaster e doutorado em física de alta energia pela University of Alberta e pós-doutorado na University of Chinese Academy of Sciences. Ele publicou mais de dez artigos nas áreas de física de alta energia e inteligência artificial, com uma taxa média de citação de > 15. Ele costumava ser o principal pesquisador de algoritmos do laboratório de IA do Lenovo Research Institute, com foco na aplicação de inteligência artificial na fabricação.

Resumo
O Lenovo Research Institute cooperou com membros do grupo de operação da Lianbao Technology LCFC, a maior fábrica de fabricação de computadores da Lenovo, para substituir o agendamento de produção manual tradicional por uma plataforma de suporte à decisão baseada em arquitetura de aprendizado de reforço profundo. O sistema pode agendar as ordens de produção de todas as 43 linhas de montagem e manufatura da fábrica, equilibrar a prioridade relativa de produção, custo de troca e taxa de entrega de pedidos e usar o modelo de aprendizagem por reforço profundo para resolver o problema de programação multiobjetivo. O método combina alta eficiência computacional com um novo mecanismo de mascaramento para garantir restrições operacionais, evitando assim que os modelos de aprendizado de máquina percam tempo explorando soluções inviáveis. Ao utilizar este novo modelo, o processo original de gerenciamento da produção foi alterado, a carteira de pedidos de produção foi reduzida em 20% e a taxa de entrega aumentou em 23% . Ele também encurtou todo o processo de programação de 6 horas para 30 minutos , mantendo a flexibilidade de metas múltiplas, permitindo que a fábrica se ajuste rapidamente às mudanças de metas. O trabalho de pesquisa aumentou a receita da fábrica em US$ 1,91 bilhão em 2019 e US$ 2,69 bilhões em 2022.
introdução de fundo
A fábrica LCFC da Lenovo em Hefei é a maior fábrica de computadores da Lenovo. Possui 4 fábricas e 43 linhas de montagem. Em média, recebe cerca de 5.000 pedidos de computadores todos os dias , respondendo por mais da metade da produção de computadores da Lenovo e pelo menos um oitavo do computadores do mundo. Esses computadores contêm mais de 20 séries de produtos e 550 modelos de produtos . Antes da produção, esses pedidos são divididos em ordens de serviço de produção (MOs), em que um pedido pode conter milhares de computadores, cada um com o mesmo número de modelo e data de envio semelhante prometida.
O processo de produção de computadores pode ser dividido em três etapas:
- A primeira etapa: a produção da placa principal está a cargo da oficina de tecnologia de montagem de superfície. Nesta fase, a produção assenta sobretudo na execução automática, com elevada estabilidade e sem necessidade de intervenção humana;
- A oficina de componentes completa a segunda etapa da produção, com os operários prendendo a carcaça do laptop ao monitor e ao teclado;
- A terceira etapa, a etapa de montagem, monta os componentes internos do laptop. Essa etapa é a mais demorada e instável, exigindo muita intervenção manual, por isso a eficiência dessa etapa costuma ser o gargalo de todo o processo de fabricação .
Na terceira etapa, os produtos semi-acabados e peças de reposição são alocados em 43 linhas de produção de acordo com as ordens de serviço. pedido é montado. A eficiência de montagem de um determinado modelo de computador pode variar dependendo da linha de produção designada. A matriz de produção horária (Unidade por hora, UPH) expressa a eficiência correspondente de produtos e linhas de produção. A UPH é suscetível a flutuações na frequência dos funcionários, status da máquina na linha de produção e disponibilidade de ferramentas e materiais. Cada ordem de serviço corresponde a uma peça de trabalho. Conforme mostrado na Figura 1, a ordem de serviço 4 passa da linha de produção B para a linha de produção A. Como o UPH aumenta, o tempo de produção diminui. Além disso, o sequenciamento das ordens de serviço em cada linha de produção pode afetar significativamente o tempo total de produção.
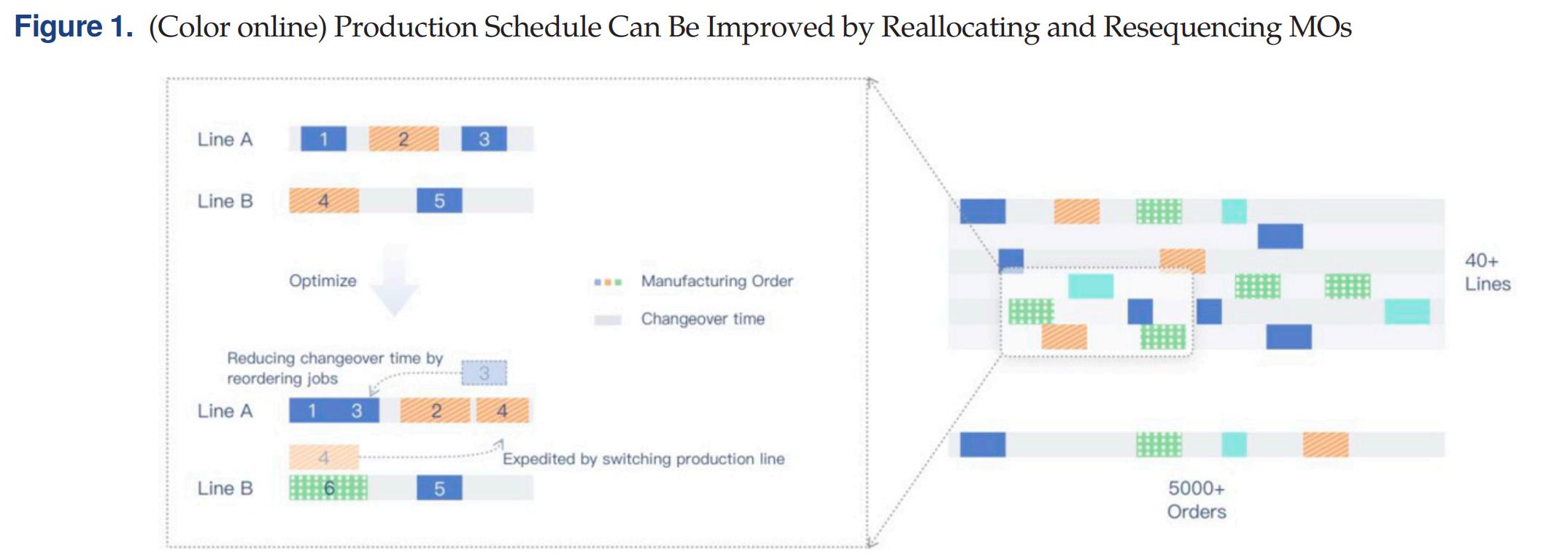
Quando a linha de produção é trocada para produzir modelos diferentes, isso levará ao custo de mudança de modelos, e o desempenho do cronograma pode ser melhorado por meio de uma atribuição de ordem de serviço razoável. O problema de otimização é computacionalmente intratável considerando o número de linhas de produção e a quantidade de pedidos despachados. Portanto, o gerenciamento da seção de montagem no terceiro estágio é o foco e a parte mais desafiadora do gerenciamento de produção de todas as fábricas da Lenovo.
Abordagens tradicionais não podem enfrentar os desafios existentes
Na Lenovo, a programação da produção baseada na experiência e julgamento humanos exigia horas de trabalho. As empresas manufatureiras modernas de hoje estão sob enorme pressão devido à oferta flutuante de recursos de produção. Portanto, a Lenovo precisa de um sistema de gerenciamento de produção com as seguintes características:
- Ele pode resolver problemas de agendamento em larga escala . Para uma empresa como a Lenovo com produção cada vez mais complexa, uma fábrica deve ser capaz de processar até dezenas de milhares de pedidos todos os dias;
- Capacidade de resposta rápida . A volatilidade do lado da oferta exige que o sistema de programação da produção responda rapidamente às mudanças na oferta de componentes. O processo de agendamento anterior da Lenovo baseava-se na experiência e no julgamento dos planejadores, que não podiam responder às mudanças no lado da oferta de maneira oportuna e adequada;
- Melhor desempenho de KPI . Ele pode otimizar simultaneamente a produção total, a taxa de entrega de pedidos, o custo de troca, etc.;
- Recursos de configuração flexíveis para destinos de otimização multicritério . Livres do trabalho mecânico, os planejadores têm mais tempo para o trabalho estratégico. Eles podem participar ativamente do processo de tomada de decisão interagindo com o sistema; por exemplo, podem configurar limites de KPI e definir prioridades relativas (pesos) para metas de otimização. Isso é fundamental para aumentar a confiança dos planejadores no sistema, aumentar sua satisfação no trabalho por meio desse fluxo de trabalho e aumentar a eficiência do processo de agendamento.
Os métodos tradicionais são difíceis de atender a tais demandas. Os métodos tradicionais são divididos em métodos exatos e métodos aproximados . Métodos exatos, como métodos de plano de corte e ramificação, que buscam soluções ótimas globais, são limitados à resolução de problemas de pequena escala. Para resolver problemas de grande escala, os desenvolvedores de soluções tradicionais buscam soluções ótimas aproximadas por meio de abordagens baseadas em regras ou heurísticas. No entanto, alguns métodos de aproximação, como pesquisa tabu/religação de caminho, funcionam bem em conjuntos de problemas pequenos e médios, mas geralmente são muito lentos para problemas de grande escala atenderem às necessidades de tempos de resposta rápidos. Outros métodos de aproximação que podem resolver problemas de grande e pequena escala em um período de tempo razoável geralmente não funcionam bem em termos de otimização de KPI. O conflito entre a velocidade de resposta e a qualidade da solução é mais pronunciado ao lidar com problemas de otimização multiobjetivo do que ao usar métodos tradicionais. Resumindo, essas deficiências dos métodos tradicionais trouxeram desafios consideráveis para o gerenciamento da cadeia de suprimentos da Lenovo.
solução
Para enfrentar esses desafios, o problema do **problema de planejamento da linha de produção (PLPP)** é modelado como um processo de decisão de Markov (MDP).
Suponha que uma fábrica tenha KKK linhas de produção eNNN ordens de serviço, o MDP correspondente ao problema de programação da produção pode ser expresso como{ X t , A , P , R } \left\{\mathbf{X}_{\mathbf{t}}, \mathbf{A}, \ mathbf{P}, \mathbf{R}\direita\}{ Xt,A ,P ,R }。
em:
X t \mathbf{X}_{\mathbf{t}}xt: cada evento ttO conjunto de estados de t é composto por uma série de vetoresX t = { xti } \boldsymbol{X}_t=\left\{\boldsymbol{x}_t^i\right\}xt={ xteu} ,xti \boldsymbol{x}_t^ixteué um conjunto de descrição de entrada iiCaracterísticas do estado i . Em PLPP,xti \boldsymbol{x}_t^ixteuIndica ordem de serviço iiUm instantâneo da série i , modelo, quantidade, UPH e capacidade restante para cada linha.
A \mathbf{A}A : coleção de ações. Um \mathbf{A}pode ser diretamenteA é equivalente à função de política P em MDP( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x})P ( e∣x ), ondex \boldsymbol{x}x ey \boldsymbol{y}y representa os estados do codificador e do decodificador, respectivamente. P ( . ∣ . ) P(. \mid .)P ( .∣. ) é a probabilidade condicional. De acordo com a regra da cadeia, dado o estado inicialx 0 \boldsymbol{x_0}x0, o processo de obtenção de uma solução completa com base no modelo de tomada de decisão sequencial é o seguinte:
P ( y ∣ x 0 ) = ∏ t = 0 NP ( yt + 1 ∣ yt , xt ) P\left(\boldsymbol{y } \mid \boldsymbol{x} _0\right)=\prod_{t=0}^NP\left(\boldsymbol{y}_{t+1} \mid \boldsymbol{y}_{t}, \boldsymbol {x}_t\direita)P( y∣x0)=t = 0∏nP( yt + 1∣yt,xt)
P \mathbf{P}P : Função de probabilidade de transição de estado. Para este problema, a transição de estadoP ( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x})P ( e∣x )é determinístico, portanto não há transições de estado aleatórias.
R\mathbf{R}R : coleção de funções de recompensa. r ( y ) ∈ R r(\boldsymbol{y}) \in \mathbf{R}r ( s )∈R é a transição do sistema para o estadoy \boldsymbol{y}Valor da função de recompensa para y . Para problemas de otimização multiobjetivo,r ( y ) r(\boldsymbol{y})r ( y ) pode ser definido como um vetor contendo valores ponderados de múltiplos indicadores de produção.
Na expressão MDP, uma solução é a sequência de ordens de serviço atribuídas a cada linha de produção. Uma solução quase ótima para um problema é obtida usando um modelo de aprendizado de máquina que aprende a aumentar a probabilidade de gerar a sequência desejada por meio de uma estrutura de aprendizado por reforço (RL).
A tarefa de programação da produção pode ser vista como aprender a organizar a ordem do pedido, ou seja, dado um pedido inicial, produzir um novo resultado de classificação, de modo que o modelo sequência a sequência (sequência a sequência, S2S) possa ser considerado .
Como todos sabemos, um modelo S2S típico inclui um codificador e um decodificador , o codificador aprende como codificar uma sequência de entrada em um vetor de tamanho fixo e o envia para o decodificador, e o decodificador aprende a converter esse vetor de volta em uma saída seqüência. Em nosso problema, a entrada para o codificador é uma sequência inicial de tickets e o decodificador gera uma sequência otimizada de tickets. A sequência de saída é a disposição do índice de ordem de serviço e a marca de separação . A marca de índice da primeira posição à primeira marca corresponde à ordem de serviço atribuída à linha de produção 1, e o índice entre a primeira marca e a segunda marca indica a ordem de serviço correspondente Atribuída à segunda linha de produção, e assim sucessivamente, conforme a figura abaixo.

A rede do codificador converte iterativamente a sequência de entrada em um tensor de alta dimensão. A rede decodificadora gera uma distribuição de probabilidade para selecionar cada MO por meio de um mecanismo de atenção.
Uma vez bem treinado, o modelo mantém seus parâmetros aprendidos e gera rapidamente sequências otimizadas. Isso fornece uma vantagem de tempo computacional sobre os métodos OR tradicionais. Em nosso modelo, o tempo de execução não aumenta exponencialmente com o tamanho do problema, o que permite que o modelo seja treinado em problemas relativamente pequenos e aplicado em problemas maiores.
A entrada do modelo inclui informações relacionadas ao pedido e relacionadas à fábrica. As informações relacionadas ao pedido incluem a quantidade necessária do produto, série do produto e ID do produto de cada pedido no plano . Aspectos relevantes da fábrica incluem o número de linhas de produção, a eficiência de produção de cada modelo em cada linha de produção, os custos de troca entre cada par de modelos de produção e as regras de fabricação .
As informações do pedido e as informações de produção correspondentes, incluindo o status de disponibilidade da máquina (por exemplo, se uma máquina está disponível para produção, manutenção ou reparo), UPH e calendário de produção são combinados na unidade MO no sistema.
Chamamos o modelo acima de Encoder Enhanced Pointer Network (EEPN) . Este modelo é treinado por aprendizado por reforço para otimizar o plano, reordenando as sequências MO de entrada e inserindo marcadores (cubos brancos) para indicar as posições de duas linhas adjacentes.
Melhore a capacidade de expressão do modelo
Muitos processos-chave para otimizar a programação da produção (por exemplo, cálculo do custo de troca, seleção da linha de produção) são difíceis de aprender para modelos que usam métodos anteriores de aprendizado por reforço profundo. Essas operações são altamente não lineares. Portanto, estruturas de rede simples não podem ser bem modeladas. Ao atualizar o codificador tradicional para uma rede neural convolucional não linear de duas camadas . Com a capacidade aprimorada de abstração de informações, o EEPN utiliza a estrutura do problema capturado para obter soluções de programação de produção de alta qualidade imediatamente após o treinamento.
Mecanismo de mascaramento para restrições complexas
Considerando a escala de programação da produção LCFC, é um desafio gerar um bom plano de produção em um sistema de produção tão grande e complexo. Ao mesmo tempo, o agendamento deve seguir regras complexas como restrições. Abaixo listamos as quatro restrições mais importantes:
- Tempo de produção : O tempo de produção de cada pedido não pode exceder sua janela de tempo predefinida, que é a interseção do horário de início mais cedo e o tempo disponível para todos os turnos. Cada turno tem um tempo total configurado, que inclui intervalos de trabalho e tempos de passagem de turno;
- Quantidade de produção : Quando um modelo de produto requer equipamentos especiais, sua quantidade total de produção dentro de um tempo especificado pode ser limitada (por exemplo, até 200 unidades por duas horas). Atingido o limite, o modelo deixará de ser produzido até o final da duração especificada, o que facilita o controle de qualidade;
- Linhas de produção alocadas : Cada pedido só pode ser alocado a uma linha de produção que tenha capacidade e capacidade para processar o modelo correspondente. Além disso, alguns modelos só podem ser produzidos em um número fixo de linhas em um determinado turno devido a limitações no número de acessórios (ou seja, equipamentos dedicados a restringir PCs durante a produção).
- Relacionados : alguns pedidos são marcados como relacionados, indicando que esses pedidos devem ser atendidos na mesma fábrica dentro do prazo especificado.
Essas restrições estão associadas ao pedido, linha de produção, tempo e quantidade, e o número de restrições pode exceder 1 0 6 10^61 06 .
Na EEPN, essas restrições são resolvidas com a introdução de um novo mecanismo de mascaramento . A tecnologia central do mecanismo de mascaramento é o tensor de mascaramento controlável (ou seja, matriz multidimensional). Cada elemento no tensor da máscara pode ser pensado como uma porta que controla se a colocação de um pedido em um local específico em uma linha específica é viável. A cada etapa de tempo de otimização em que o modelo processa um pedido, se colocar o pedido na linha não viola nenhuma restrição, a porta é aberta; caso contrário, a porta é fechada.
Portanto, a EEPN seleciona apenas os pedidos que abrem a porta e coloca alguns deles na linha de produção de acordo com o intervalo de tempo .

Conforme mostrado na figura acima, uma máscara combinada consiste em várias submáscaras combinadas por adição lógica, cada submáscara representando uma restrição. O mecanismo de mascaramento considera várias restrições simultaneamente durante a geração da solução e exclui soluções inviáveis, o que reduz bastante o tempo de computação para treinamento do modelo.
treinamento de modelo rápido
Durante a fase de teste do algoritmo, foi avaliado o impacto no tempo de execução do agendamento de benchmark de IA com e sem mascaramento e incluindo vários tamanhos de problema.
Os resultados mostram um leve aumento no tempo de execução dos testes que utilizam o mecanismo de mascaramento em relação aos testes que não utilizam esse mecanismo. À medida que o tamanho do problema aumenta, a taxa de crescimento do tempo de execução para ambos os testes é aproximadamente a mesma, resultando em um aumento linear no tempo de execução para o problema maior . Embora o mecanismo de mascaramento leve a um aumento no tempo de computação na solução de otimização, ele reduz significativamente o tempo de treinamento por meio da aplicação efetiva de restrições. Além disso, para problemas maiores, o mecanismo de mascaramento não leva a um aumento significativo no tempo de execução do modelo.
Configurar a otimização de agendamento multiobjetivo
Em cada execução de escalonamento, o EEPN deve gerar simultaneamente um conjunto de soluções sob diferentes alvos prioritários.Ao receber um conjunto de alvos prioritários, o tomador de decisão deve ser capaz de configurar de forma flexível o peso preferencial de cada alvo e escolher intuitivamente a solução ótima desejada .
Portanto, uma ideia é atualizar o EEPN para poder aprender políticas de escalonamento ótimas para diferentes conjuntos de prioridades em cenários multiobjetivos.
Isso pode ser feito usando vários pesos de preferência de destino como dados de entrada adicionais para modelos de aprendizado de máquina.

De acordo com pesquisas anteriores, este objetivo requer o projeto de múltiplas instâncias EEPN, cada uma das quais é responsável por completar a otimização sob um conjunto específico de prioridades de função objetivo. No entanto, esse método é muito demorado e requer muitos recursos de computação.
Em vez disso, a equipe de pesquisa da Lenovo decidiu usar um único EEPN para atingir esse objetivo. A versão multiobjetivo do EEPN toma como entrada as prioridades do critério da função objetivo (ou seja, pesos de preferência). Portanto, o EEPN aprende continuamente várias combinações de prioridades de objetos e dados de agendamento em um ambiente variável no tempo.
Usando os mesmos dados de agendamento, o EEPN pode gerar rapidamente resultados de agendamento ideais em cada caso, se as prioridades de destino configuradas forem diferentes. Usando essa abordagem baseada em aprendizado, o algoritmo resolve com sucesso o problema de otimização multiobjetivo.
para concluir
Resumindo, a estrutura EEPN desenvolvida pela Lenovo e testada pela LCFC para agendamento inteligente por meio de OR e AI provou melhorar a eficiência, aumentar a receita, economizar capital humano e proteger o meio ambiente. Essas soluções têm um enorme potencial para resolver alguns dos problemas mais complexos enfrentados pelas empresas e pela sociedade.
A solução não só foi implementada na fábrica de Lianbao, como também foi migrada e testada nos cenários de produção de outras fábricas internas da Lenovo como as fábricas de Shenzhen e Huiyang.Os resultados da etapa POC mostraram que os KPIs das duas fábricas melhoraram substancialmente. Além da indústria de PCs , esta solução também é aplicável à indústria de telefonia móvel, indústria de semicondutores e indústria de usinagem discreta , embora do ponto de vista de OR, o problema de programação de produção dessas indústrias possa ser diferente do PLPP da fábrica de Lianbao , porque cada fábrica tem seu próprio conjunto de processos de produção e preferências de KPI, mas pode se adaptar facilmente a essas diferenças modificando o mecanismo de mascaramento e definindo a função objetivo.