1. Estrutura de dados em redis
O Redis suporta cinco tipos de dados: string (string), hash (hash), list (lista), set (conjunto não ordenado) e zset (conjunto ordenado)
No projeto seckill, usei redis Set e estrutura Hash:
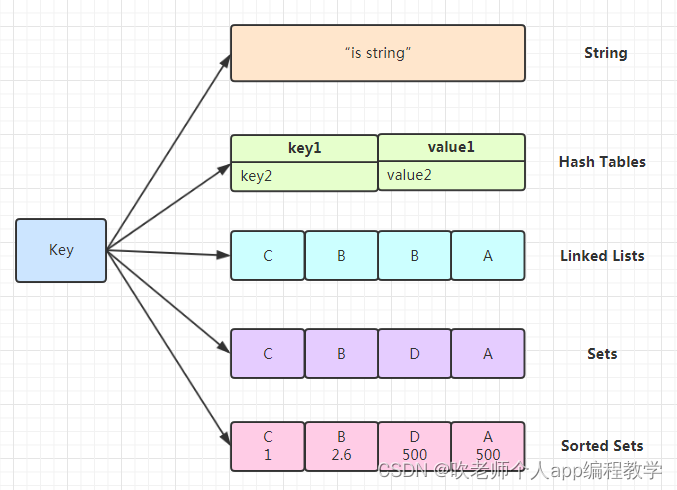
String: uma chave corresponde a uma string, e string é o tipo de dados mais básico do Redis. (O framework byte abase implementa apenas a estrutura de dados de string do redis, portanto, se quisermos armazenar estruturas de dados complexas, podemos apenas convertê-los em strings no formato json para armazenamento) lista: uma chave corresponde a uma lista de strings , O
subjacente A camada é implementada usando uma lista duplamente vinculada, que suporta muitas operações suportadas por uma lista duplamente vinculada.
Cerquilha:
Set: Por exemplo, uma instância de Set: A = {'a', 'b', 'c'}, A é a chave do conjunto, 'a', 'b' e 'c' são os membros do definir. Não ordenado, sem elementos repetidos.
SortedSet: Uma pontuação é adicionada ao conjunto e os dados no conjunto são ordenados.
3. A implementação subjacente da estrutura de dados redis
string
é implementado usando um tipo de dados chamado Simple Dynamic String (SDS).
/*
* 保存字符串对象的结构
*/
struct sdshdr {
int len; // buf 中已占用空间的长度
int free; // buf 中剩余可用空间的长度
char buf[]; // 数据空间
};
Vantagens do SDS sobre strings C:
SDS salva o comprimento da string, mas não salva o comprimento da string C. É necessário percorrer todo o array (até '\0' ser encontrado) para obter o comprimento da string.
Ao modificar o SDS, verifique se o espaço SDS fornecido é suficiente, caso contrário, expanda o espaço SDS primeiro para evitar o estouro do buffer. A string C não verifica se o espaço de string é suficiente e é fácil causar um estouro de buffer ao chamar algumas funções (como a função de concatenação de string strcat).
O mecanismo de pré-alocação de espaço do SDS pode reduzir o número de vezes para realocar espaço para strings.
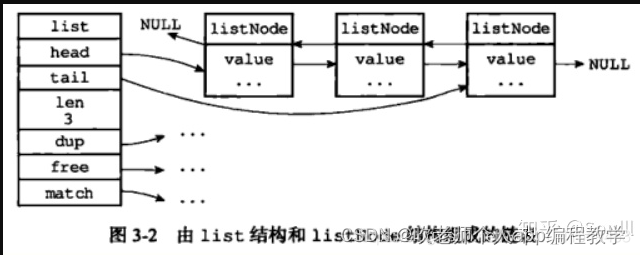
4, lista
Implementado usando uma lista duplamente encadeada.
5、hash
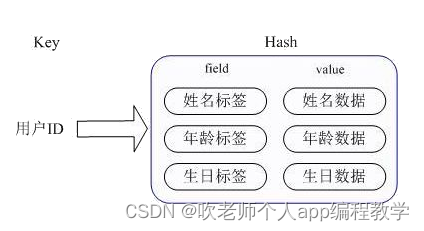
A estrutura hash é, na verdade, um dicionário com muitos pares chave-valor (semelhante ao tipo dict do python).
A tabela hash do Redis é uma estrutura dicttht:
typedef struct dicttht { dictEntry **table;//array da tabela hash unsigned long size;//tamanho da tabela hash unsigned long sizemask;//máscara de tamanho da tabela hash, use Para calcular o valor do índice unsigned long used;//O número de nós existentes na tabela hash }
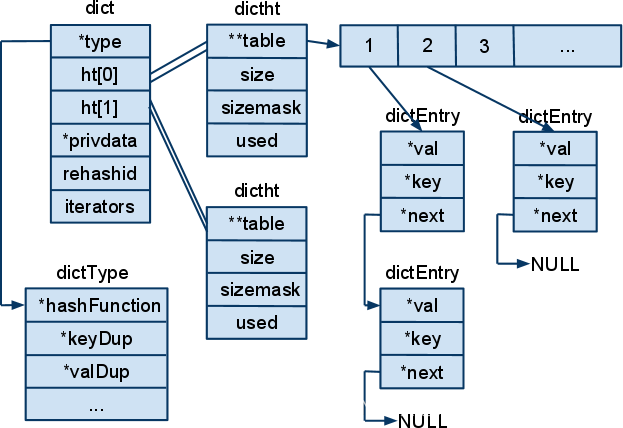
A estrutura do nó da tabela hash é a seguinte:
typeof struct dictEntry{ void *key;//key union{ //Os tipos de valores correspondentes a diferentes chaves podem ser diferentes, use union para lidar com esse problema void *val ; uint64_tu64; int64_ts64; } struct dictEntry *próximo; }
Um dos métodos para resolver conflitos de hash é o método zipper.
Para manter o fator de carregamento da tabela de hash dentro de uma faixa razoável, é necessário expandir ou diminuir o tamanho da tabela de hash, o que é chamado de rehash. Há um total de duas estruturas dictht de tabela de hash no dicionário, ht[0] é usado para armazenar pares chave-valor, ht[1] é usado para armazenar dados temporariamente durante o rehash, geralmente a tabela de hash para a qual aponta está vazia e precisa ser expandido ou contraído a tabela de hash de ht[0] tem espaço alocado para isso.
Por exemplo, expandir a tabela hash é alocar um espaço com o dobro do tamanho de ht[0] para ht[1], então migrar todos os dados de ht[0] para ht[1] por meio de rehash e finalmente liberar ht[0 ] ], transforme ht[1] em ht[0] e atribua uma tabela de hash vazia a ht[1]. Encolher hashtables é semelhante.
Rehash progressivo: o redis não encontra especificamente tempo para executar o rehash de uma só vez, mas gradualmente. Durante o rehash, não afeta o acesso externo a ht[0]. É necessário sincronizar os dados correspondentes a ht[1] ao modificar o dicionário , quando toda a transferência de dados estiver concluída, o rehash termina.
———————————————
6、conjunto
set pode ser implementado com intset ou dicionário.
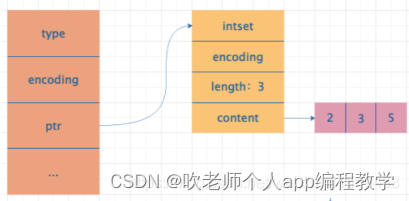
intset
só usa intset quando os dados são todos valores inteiros e o número é menor que 512. intset é um conjunto ordenado composto por inteiros, que pode ser usado para busca binária.
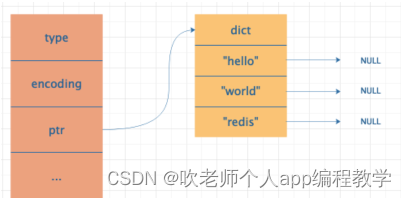
Dicionários
Use dicionários (método zipper) quando as condições de uso de intset não forem atendidas. Ao usar dicionários, defina o valor como nulo.
7、 verifique
Cada elemento em zset contém os próprios dados e uma pontuação (score) correspondente.
Exemplo clássico: a chave de um zset é "math", que representa as notas da aula de matemática, e então muitos dados podem ser inseridos nessa chave. Ao inserir dados, cada vez que você precisa inserir um nome e uma pontuação correspondente. Em seguida, o nome é o próprio dado e a pontuação é sua pontuação.
Os dados do próprio zset não permitem a duplicação, mas a pontuação permite a duplicação.
O princípio de implementação subjacente do zset:
Quando os dados são pequenos, use ziplist: ziplist ocupa memória contínua e cada elemento é armazenado continuamente na forma de (dados + pontuação), classificados por pontuação de pequeno a grande. Para economizar memória, o espaço ocupado por cada elemento da ziplist pode ser diferente. Para dados grandes (long long), mais bytes são usados para armazenamento, e para dados pequenos (short), menos bytes são usados para armazenamento. Portanto, é necessário percorrer em ordem ao pesquisar. Ziplist economiza memória, mas tem baixa eficiência de pesquisa.
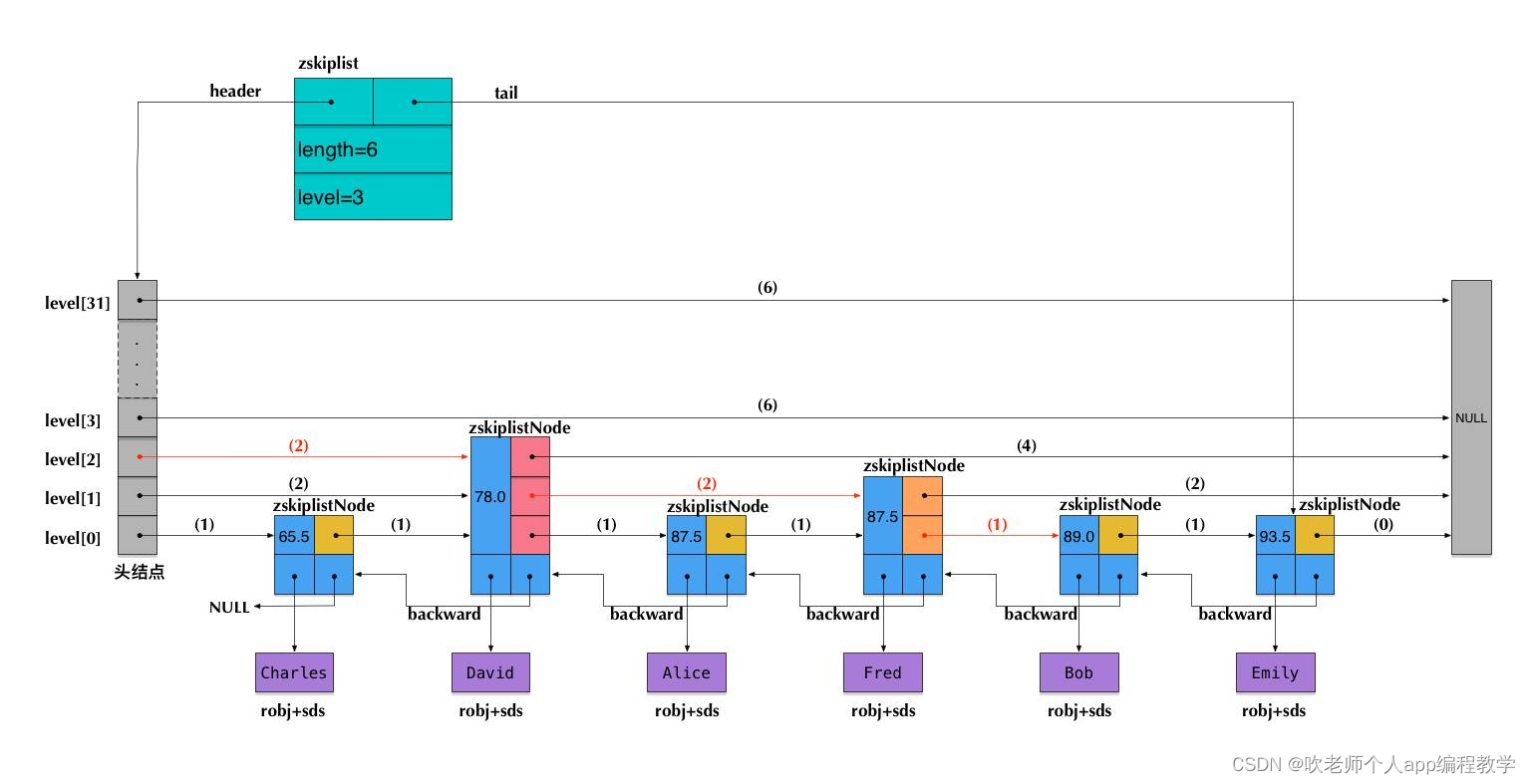
Quando houver muitos dados, use um dicionário + pule a tabela: