Diretório de artigos
Introdução básica:
Os chatbots baseados no TensorFlow usam principalmente métodos de machine deep learning, e o modelo mais usado é o modelo seq2seq+Attention. Este modelo pode realizar a tradução ou geração automática da frase de origem para a frase de destino. No robô de bate-papo, a pergunta do usuário pode ser usada como frase de origem, a resposta gerada pelo robô pode ser usada como frase de destino e um robô de diálogo inteligente pode ser construído por meio de treinamento e aprendizado de modelos.
Em primeiro lugar, usar a estrutura de segmentação de palavras chinesas jieba para segmentar textos de caracteres chineses é segmentar sentenças em palavras gerenciáveis. Isso pode ajudar o modelo a entender melhor a semântica das sentenças, além de reduzir a dimensionalidade dos dados de entrada. Após a tokenização, cada palavra é codificada com um número de identificação para que o modelo possa processá-la.
Então, por meio do treinamento e aprendizado de uma grande quantidade de dados, o modelo pode aprender gradualmente as leis e os conceitos da linguagem. O modelo pode ser treinado usando um corpus de pares de perguntas e respostas para que o modelo aprenda a associar perguntas com respostas correspondentes. Durante o processo de treinamento, o algoritmo de retropropagação e o otimizador podem ser usados para ajustar os parâmetros do modelo para que o modelo possa gerar a resposta correta.
Após a conclusão do treinamento, o chatbot está pronto para conversas reais. Quando um usuário insere uma pergunta, o robô a torna tokenizada e a converte em um formulário codificado por ID, que é então inserido no modelo. O modelo é propagado para frente para calcular uma distribuição de probabilidade que representa respostas possíveis. Ao selecionar a resposta com maior probabilidade, o bot pode gerar uma resposta correspondente e devolvê-la ao usuário.
Entre eles, para melhorar o efeito do modelo, é muito importante introduzir o mecanismo de Atenção. O mecanismo de atenção pode ajudar o modelo a prestar mais atenção às informações contextuais relevantes ao gerar cada palavra, melhorando assim a compreensão semântica do modelo e a qualidade da resposta.
Além disso, para enriquecer o corpus e melhorar a capacidade de generalização do modelo, é possível usar não apenas pares de perguntas e respostas como dados de treinamento, mas também incluir outros tipos de diálogos, como conversa fiada, perguntas frequentes, etc. Isso pode fazer com que o robô tenha uma certa capacidade de responder a vários tipos de perguntas.
Em suma, o modelo de aprendizado profundo é usado para treinar e aprender a realizar correspondência automática e responder ao diálogo humano-computador. Por meio do pré-processamento adequado de dados, codificação de segmentação de palavras, construção e otimização de modelos e a introdução do mecanismo de atenção, os chatbots podem ser equipados com melhores recursos de diálogo e de compreensão semântica.
Ideia de implementação:
1. Pré-processamento de dados : Segmente as perguntas e respostas no corpus e use a ferramenta de segmentação de palavras chinesas jieba para processar o texto de caracteres chineses. Cada segmentação palavra após palavra será mapeada para um número de ID exclusivo para que o modelo possa lidar com isso.
2. Construção do modelo : use o framework TensorFlow para construir um modelo de robô de diálogo baseado em machine deep learning, usando o modelo seq2seq+Attention. O modelo Seq2seq consiste em um codificador (Encoder) e um decodificador (Decoder).O codificador converte a sequência de pergunta de entrada em uma representação vetorial de comprimento fixo e o decodificador usa esse vetor para gerar uma resposta.
3. Preparação de dados de treinamento : Use um grande número de dados de pares de perguntas e respostas como o conjunto de treinamento, no qual a pergunta é usada como a sequência de entrada e a resposta é usada como a sequência de destino. Os dados de treinamento podem ser obtidos rastreando comunidades de perguntas e respostas na Internet ou usando conjuntos de dados abertos existentes.
4. Treinamento do modelo : insira os dados de treinamento preparados no modelo para treinamento e use o algoritmo de retropropagação e o otimizador para ajustar os parâmetros do modelo para que o modelo possa gerar respostas corretas. Uma função de perda apropriada, como a função de perda de entropia cruzada, pode ser definida para avaliar a lacuna entre a saída do modelo e a resposta real e otimizar o modelo.
5. Corresponder e gerar respostas : Quando o usuário insere uma pergunta, a segmentação de palavras é realizada na frase de entrada e a sequência após a segmentação de palavras é inserida no modelo treinado. O modelo converte a sequência de perguntas em uma representação vetorial por meio do codificador e, em seguida, o decodificador usa esse vetor para gerar uma resposta. No processo do decodificador, o mecanismo de atenção pode ajudar o modelo a se concentrar em informações contextuais relevantes e melhorar a qualidade e a precisão da resposta.
6. Avaliação e melhoria do modelo : Avalie o modelo por meio de avaliação manual e avaliação do conjunto de teste e melhore e otimize o modelo com base nos resultados da avaliação. De acordo com as necessidades dos cenários reais de aplicação, os hiperparâmetros e as funções de perda do modelo podem ser ajustados para melhorar a capacidade de resposta e o nível de inteligência do robô.
introdução detalhada
1. A história do desenvolvimento dos chatbots:
-
Primeira geração: chatbots baseados em regras que geram respostas escrevendo regras predefinidas e correspondência de padrões. Essas regras são escritas manualmente, não podem abranger todas as situações de diálogo possíveis e são difíceis de lidar com linguagem natural complexa.
-
A segunda geração: chatbots com métodos estatísticos, que introduzem a tecnologia de aprendizado de máquina, modelam e treinam por meio de métodos estatísticos, como o uso de modelos n-gram para modelagem de linguagem e o uso de estimativa de probabilidade máxima para gerar respostas. Embora possa melhorar a fluência do diálogo até certo ponto, falta-lhe a capacidade de compreender a semântica e o contexto, e as respostas geradas podem ser imprecisas.
-
A terceira geração: Chatbots baseados em aprendizado profundo, usando modelos de rede neural para modelagem e treinamento. Entre eles, o modelo seq2seq (Sequence-to-Sequence) é uma estrutura de modelo comum, que consiste em um codificador (Encoder) e um decodificador (Decoder), mapeando a sequência de entrada em uma representação vetorial de comprimento fixo e, em seguida, o O vetor serve como estado inicial do decodificador para gerar a sequência de saída. Para focar a informação relevante na sequência de entrada e melhorar a qualidade da resposta, é introduzido o mecanismo de Atenção.
2. interface embedding_attention_seq2seq:
- embedding_attention_seq2seq é uma interface no TensorFlow para construir um modelo seq2seq+Attention.
- Os parâmetros da interface incluem principalmente encoder_inputs, decoder_inputs e Attention_states.
- encoder_inputs representa a sequência de entrada do codificador, decoder_inputs representa a sequência de entrada do decodificador e Attention_states representa a representação vetorial usada para calcular o peso Atenção.
- Outros parâmetros comumente usados incluem num_encoder_symbols, num_decoder_symbols, embedding_size, num_heads, etc., que são usados para especificar o tamanho do vocabulário, dimensão do vetor de palavras, número de cabeças de atenção, etc.
3. Treine o modelo:
(1) Segmentação de palavras chinesas : use a biblioteca jieba para executar o processamento de segmentação de palavras em textos chineses e divida as sentenças em sequências de palavras.
(2) Obtenção da função do conjunto de treinamento : de acordo com o cenário de aplicação, os dados de resposta à pergunta podem ser rastreados da Internet ou um conjunto de dados aberto existente pode ser usado como conjunto de treinamento. Converta os dados de resposta à pergunta no formato exigido pelo modelo e divida-os em conjuntos de treinamento e validação.
(3) Obtenha a função de identificação de sentença : use o vocabulário para converter a sentença após a segmentação de palavras em uma sequência de ID de sentença, o que é conveniente para o modelo processar.
(4) Função de previsão : define o estágio de inferência do modelo, executa a geração de sequência e gera respostas por meio do codificador e do decodificador.
(5) Parâmetros de otimização : Selecione uma função de perda apropriada (como função de perda de entropia cruzada), otimizador (como otimizador de Adam) e hiperparâmetros para treinar e otimizar o modelo.
4. Programação em Python para realizar um robô de bate-papo completo:
- Com base nas etapas descritas acima, um sistema de chatbot pode ser construído usando a linguagem de programação Python.
- Ao introduzir a biblioteca jieba para segmentação de palavras chinesas, crie um modelo seq2seq+Attention e use a interface fornecida pelo TensorFlow para treinamento e previsão do modelo.
- Durante o processo de codificação, o modelo pode ser otimizado e aprimorado adequadamente com base nas necessidades reais, como adicionar mais dados de treinamento, ajustar a estrutura do modelo e os hiperparâmetros, etc.
- Por fim, a depuração do sistema é realizada para garantir que o robô possa dar respostas precisas e razoáveis às questões levantadas pelos usuários e tenha um certo nível de inteligência.
para adicionar:
Para expandir e enriquecer a funcionalidade dos chatbots, alguns dos seguintes aspectos podem ser considerados:
- Reconhecimento de entidade : introduza a tecnologia de reconhecimento de entidade para extrair informações importantes de perguntas para responder às perguntas dos usuários com mais precisão.
- Reconhecimento de intenção : Classifique as perguntas do usuário por intenção, para entender melhor as necessidades do usuário e dar respostas correspondentes.
- Gerenciamento de diálogo : ao introduzir a tecnologia de gerenciamento de diálogo, os chatbots podem conduzir várias rodadas de diálogo, lembrar informações contextuais e se comunicar de forma coerente.
- Processamento multimodal : a combinação de vários métodos de entrada, como texto, imagens e voz, permite que os chatbots lidem com diversas entradas do usuário.
- Adaptação de domínio : de acordo com o cenário de aplicação específico, o robô de bate-papo é adaptado ao domínio para fornecer respostas mais profissionais e direcionadas.
- Mecanismo de feedback do usuário : adicione um mecanismo de feedback do usuário para coletar continuamente comentários e sugestões do usuário para otimizar e melhorar o desempenho dos chatbots.
Construção do ambiente e tecnologias-chave
Construção do ambiente
Use o interpretador python de python3.6, versão tensorflow = 1.14, embedding_attention_seq2seq de tensorflow, use rede neural LSTM, use o otimizador AdamOptimizer, segmentação de palavras chinesas jieba, etc. O processo de instalação e construção de cada item é o seguinte:
- Instale o Anaconda (gerenciador de pacotes e gerenciador de ambiente):
O Anaconda vem com uma grande coleção de pacotes de ciência de dados comumente usados, vem com conda, Python e mais de 150 pacotes científicos e suas dependências. Assim, você pode começar a processar os dados imediatamente. Na análise de dados, muitos pacotes de terceiros são usados, e o conda (gerenciador de pacotes) pode ajudá-lo a instalar e gerenciar esses pacotes em seu computador, incluindo instalação, desinstalação e atualização de pacotes.
(1) Etapas e instruções de instalação e configuração do Anaconda:
- a. Entre no site oficial e clique em Download;
- b. Escolha a versão apropriada do seu computador para baixar (escolha a versão de 64 bits de 2020.11);
- c. Encontre o instalador de acordo com seu próprio caminho de download e clique no instalador para instalar;
- d. Siga as instruções para instalar de acordo com as opções padrão e, finalmente, clique em Concluir para concluir a instalação;
- e. Abra "System Properties-Advanced-Environment Variables-User User Variables-Selecione Path-Edit para configurar o ambiente e adicione o caminho de sua própria instalação após o valor da variável da seguinte forma:

- f. Clique em OK para concluir a configuração do ambiente.
- g. Clique em Iniciar para abrir o prompt do Anaconda (Anaconda3) e insira um terminal como o Anaconda3 para alterar a fonte da imagem doméstica e insira o seguinte comando na linha de comando:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- h. Exibe o endereço do canal ao definir a pesquisa
conda config --set show_channel_urls yes
O Anaconda conclui a instalação.
1. Use o Anaconda3 para instalar o interpretador python3.6:
(1) Entre na interface cmd do sistema Windows: então digite: conda --version para verificar a versão do anaconda, o resultado é mostrado na figura (3)

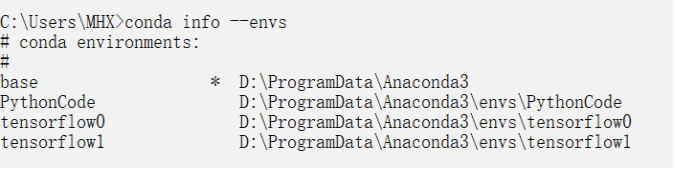
Instale o python e crie o ambiente tensorflow
(4) conda search --full --name pythonVerifique a versão do python suportada pelo anaconda
(5) Instale o interpretador Python e crie o ambiente tensorflow0 conda create --name tensorflow0 python=3.6; (
6) O comando para entrar no ambiente tensorflow0 é: activate tensorflow0
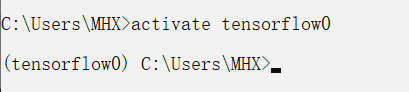
2. Instale o tensorflow1.14 no ambiente tensorflow0,
(1) O comando é pip install --upgrade --ignore-installed tensorflow, a instalação foi bem-sucedida tensorflow=1.14 versão;
(2) Verifique se a instalação do tensorflow foi bem-sucedida ou não, digite o seguinte código:
import tensorflow as tf
hello = tf.constant(‘hello,tf’)
sess = tf.Session()
print(sess.run(hello))
3. Instale e configure o ambiente tensorflow0 para o IDE Pycham que executa o código
(1) Baixe e instale o Pycham: Entre no site oficial do Pycham para baixar o pacote de instalação da versão da comunidade Pycham para o local, clique na opção padrão para instalar.
(2) Adicionar ambientetensorflow0到Pycham

tecnologia chave
Anaconda3 presta atenção à configuração correta do caminho na configuração da variável de ambiente após a instalação. Ao escolher a versão python, você deve prestar atenção ao escolher a versão python3.6. O motivo é que a versão mais recente não pode instalar a versão tensorflow1.14. A versão correta a escolha da versão do tensorflow é a chave para a operação bem-sucedida do programa. O fator chave do não, já que o aprendizado de máquina baseado em tensorflow se refere principalmente à empresa google, a maioria de suas estruturas e interfaces de algoritmo não são compatíveis com o tensorflow2, encontrei muitas dificuldades na seleção e download do tensorflow, o ambiente deve ser construído Com base nas versões python3.6 e Tensorflow1.14, outras bibliotecas necessárias jieba Chinese thesaurus, seq2seq e numpy são operações relativamente simples. Especificamente, insira os seguintes comandos no Terminal para instalá-los com sucesso.
O comando para instalar a biblioteca numpy: pip install numpy
o comando para instalar a biblioteca jieba: pip install jieba
o comando para instalar a biblioteca seq2seq:pip install seq2seq
Código
1. Pegue a palavra número:
# coding:utf-8
import sys
import jieba
from numpy import unicode
class WordToken(object):
def __init__(self):
# 最小起始id号, 保留的用于表示特殊标记
self.START_ID = 4
self.word2id_dict = {
}
self.id2word_dict = {
}
def load_file_list(self, file_list, min_freq):
"""
加载样本文件列表,全部切词后统计词频,按词频由高到低排序后顺次编号
并存到self.word2id_dict和self.id2word_dict中
"""
words_count = {
}
for file in file_list:
with open(file, 'r',encoding='utf-8') as file_object:
for line in file_object.readlines():
line = line.strip()
seg_list = jieba.cut(line)
for str in seg_list:
if str in words_count:
words_count[str] = words_count[str] + 1
else:
words_count[str] = 1
sorted_list = [[v[1], v[0]] for v in words_count.items()]
sorted_list.sort(reverse=True)
for index, item in enumerate(sorted_list):
word = item[1]
if item[0] < min_freq:
break
self.word2id_dict[word] = self.START_ID + index
self.id2word_dict[self.START_ID + index] = word
return index
def word2id(self, word):
if not isinstance(word, unicode):
print ("Exception: error word not unicode")
sys.exit(1)
if word in self.word2id_dict:
return self.word2id_dict[word]
else:
return None
def id2word(self, id):
id = int(id)
if id in self.id2word_dict:
return self.id2word_dict[id]
else:
return None
2. Treinamento:
# coding:utf-8
import sys
import jieba
from numpy import unicode
class WordToken(object):
def __init__(self):
# 最小起始id号, 保留的用于表示特殊标记
self.START_ID = 4
self.word2id_dict = {
}
self.id2word_dict = {
}
def load_file_list(self, file_list, min_freq):
"""
加载样本文件列表,全部切词后统计词频,按词频由高到低排序后顺次编号
并存到self.word2id_dict和self.id2word_dict中
"""
words_count = {
}
for file in file_list:
with open(file, 'r',encoding='utf-8') as file_object:
for line in file_object.readlines():
line = line.strip()
seg_list = jieba.cut(line)
for str in seg_list:
if str in words_count:
words_count[str] = words_count[str] + 1
else:
words_count[str] = 1
sorted_list = [[v[1], v[0]] for v in words_count.items()]
sorted_list.sort(reverse=True)
for index, item in enumerate(sorted_list):
word = item[1]
if item[0] < min_freq:
break
self.word2id_dict[word] = self.START_ID + index
self.id2word_dict[self.START_ID + index] = word
return index
def word2id(self, word):
if not isinstance(word, unicode):
print ("Exception: error word not unicode")
sys.exit(1)
if word in self.word2id_dict:
return self.word2id_dict[word]
else:
return None
def id2word(self, id):
id = int(id)
if id in self.id2word_dict:
return self.id2word_dict[id]
else:
return None
3. Teste:
# coding:utf-8
import sys
import numpy as np
import tensorflow as tf
from tensorflow.contrib.legacy_seq2seq.python.ops import seq2seq
import word_token
import jieba
import random
# 输入序列长度
input_seq_len = 5
# 输出序列长度
output_seq_len = 5
# 空值填充0
PAD_ID = 0
# 输出序列起始标记
GO_ID = 1
# 结尾标记
EOS_ID = 2
# LSTM神经元size
size = 8
# 初始学习率
init_learning_rate = 1
# 在样本中出现频率超过这个值才会进入词表
min_freq = 10
wordToken = word_token.WordToken()
# 放在全局的位置,为了动态算出num_encoder_symbols和num_decoder_symbols
max_token_id = wordToken.load_file_list(['./samples/question', './samples/answer'], min_freq)
num_encoder_symbols = max_token_id + 5
num_decoder_symbols = max_token_id + 5
def get_id_list_from(sentence):
sentence_id_list = []
seg_list = jieba.cut(sentence)
for str in seg_list:
id = wordToken.word2id(str)
if id:
sentence_id_list.append(wordToken.word2id(str))
return sentence_id_list
def get_train_set():
global num_encoder_symbols, num_decoder_symbols
train_set = []
with open('samples/question', 'r', encoding='utf-8') as question_file:
with open('samples/answer', 'r', encoding='utf-8') as answer_file:
while True:
question = question_file.readline()
answer = answer_file.readline()
if question and answer:
question = question.strip()
answer = answer.strip()
question_id_list = get_id_list_from(question)
answer_id_list = get_id_list_from(answer)
if len(question_id_list) > 0 and len(answer_id_list) > 0:
answer_id_list.append(EOS_ID)
train_set.append([question_id_list, answer_id_list])
else:
break
return train_set
def get_samples(train_set, batch_num):
raw_encoder_input = []
raw_decoder_input = []
if batch_num >= len(train_set):
batch_train_set = train_set
else:
random_start = random.randint(0, len(train_set)-batch_num)
batch_train_set = train_set[random_start:random_start+batch_num]
for sample in batch_train_set:
raw_encoder_input.append([PAD_ID] * (input_seq_len - len(sample[0])) + sample[0])
raw_decoder_input.append([GO_ID] + sample[1] + [PAD_ID] * (output_seq_len - len(sample[1]) - 1))
encoder_inputs = []
decoder_inputs = []
target_weights = []
for length_idx in range(input_seq_len):
encoder_inputs.append(np.array([encoder_input[length_idx] for encoder_input in raw_encoder_input], dtype=np.int32))
for length_idx in range(output_seq_len):
decoder_inputs.append(np.array([decoder_input[length_idx] for decoder_input in raw_decoder_input], dtype=np.int32))
target_weights.append(np.array([
0.0 if length_idx == output_seq_len - 1 or decoder_input[length_idx] == PAD_ID else 1.0 for decoder_input in raw_decoder_input
], dtype=np.float32))
return encoder_inputs, decoder_inputs, target_weights
def seq_to_encoder(input_seq):
"""从输入空格分隔的数字id串,转成预测用的encoder、decoder、target_weight等
"""
input_seq_array = [int(v) for v in input_seq.split()]
encoder_input = [PAD_ID] * (input_seq_len - len(input_seq_array)) + input_seq_array
decoder_input = [GO_ID] + [PAD_ID] * (output_seq_len - 1)
encoder_inputs = [np.array([v], dtype=np.int32) for v in encoder_input]
decoder_inputs = [np.array([v], dtype=np.int32) for v in decoder_input]
target_weights = [np.array([1.0], dtype=np.float32)] * output_seq_len
return encoder_inputs, decoder_inputs, target_weights
def get_model(feed_previous=False):
"""构造模型
"""
learning_rate = tf.Variable(float(init_learning_rate), trainable=False, dtype=tf.float32)
learning_rate_decay_op = learning_rate.assign(learning_rate * 0.9)
encoder_inputs = []
decoder_inputs = []
target_weights = []
for i in range(input_seq_len):
encoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="encoder{0}".format(i)))
for i in range(output_seq_len + 1):
decoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="decoder{0}".format(i)))
for i in range(output_seq_len):
target_weights.append(tf.placeholder(tf.float32, shape=[None], name="weight{0}".format(i)))
# decoder_inputs左移一个时序作为targets
targets = [decoder_inputs[i + 1] for i in range(output_seq_len)]
cell = tf.contrib.rnn.BasicLSTMCell(size)
# 这里输出的状态我们不需要
outputs, _ = seq2seq.embedding_attention_seq2seq(
encoder_inputs,
decoder_inputs[:output_seq_len],
cell,
num_encoder_symbols=num_encoder_symbols,
num_decoder_symbols=num_decoder_symbols,
embedding_size=size,
output_projection=None,
feed_previous=feed_previous,
dtype=tf.float32)
# 计算加权交叉熵损失
loss = seq2seq.sequence_loss(outputs, targets, target_weights)
# 梯度下降优化器
opt = tf.train.GradientDescentOptimizer(learning_rate)
# 优化目标:让loss最小化
update = opt.apply_gradients(opt.compute_gradients(loss))
# 模型持久化
saver = tf.train.Saver(tf.global_variables())
return encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate
def train():
"""
训练过程
"""
train_set = get_train_set()
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model()
# 全部变量初始化
sess.run(tf.global_variables_initializer())
# 训练很多次迭代,每隔10次打印一次loss,可以看情况直接ctrl+c停止
previous_losses = []
for step in range(50000):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = get_samples(train_set, 1000)
input_feed = {
}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([len(sample_decoder_inputs[0])], dtype=np.int32)
[loss_ret, _] = sess.run([loss, update], input_feed)
if step % 10 == 0:
print ('step=', step, 'loss=', loss_ret, 'learning_rate=', learning_rate.eval())
if len(previous_losses) > 5 and loss_ret > max(previous_losses[-5:]):
sess.run(learning_rate_decay_op)
previous_losses.append(loss_ret)
# 模型持久化
saver.save(sess, './model/demo')
def predict():
"""
预测过程
"""
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model(feed_previous=True)
saver.restore(sess, './model/demo')
sys.stdout.write("> ")
sys.stdout.flush()
input_seq = sys.stdin.readline()
while input_seq:
input_seq = input_seq.strip()
input_id_list = get_id_list_from(input_seq)
if (len(input_id_list)):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = seq_to_encoder(' '.join([str(v) for v in input_id_list]))
input_feed = {
}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([2], dtype=np.int32)
# 预测输出
outputs_seq = sess.run(outputs, input_feed)
# 因为输出数据每一个是num_decoder_symbols维的,因此找到数值最大的那个就是预测的id,就是这里的argmax函数的功能
outputs_seq = [int(np.argmax(logit[0], axis=0)) for logit in outputs_seq]
# 如果是结尾符,那么后面的语句就不输出了
if EOS_ID in outputs_seq:
outputs_seq = outputs_seq[:outputs_seq.index(EOS_ID)]
outputs_seq = [wordToken.id2word(v) for v in outputs_seq]
print (" ".join(outputs_seq))
else:
print ("你觉得呢")
sys.stdout.write("> ")
sys.stdout.flush()
input_seq = sys.stdin.readline()
if __name__ == "__main__":
#训练:
#train()
#测试对话:
predict()
Resumo e experiência
Com base na estrutura principal de aprendizado profundo de máquina do pacote de análise de ferramentas OneAPI TensorFlow, o robô de bate-papo usando o modelo seq2seq+Attention realiza a segmentação de palavras em frases de texto chinês por meio da estrutura de segmentação de palavras chinesas jieba e, em seguida, numera os resultados da segmentação de palavras. Então, por meio de uma grande quantidade de treinamento e aprendizado de dados, um modelo é gerado para que possa realizar a função básica de diálogo homem-máquina.
Esse chatbot pode reconhecer automaticamente a frase de entrada do chat e corresponder à resposta correspondente à pergunta. Ele é treinado em um grande corpus de vocabulário de texto para gerar respostas a perguntas de entrada.
A utilização de tal chatbot pode tirar algumas conclusões e novas experiências, tais como:
- Compreensão e geração de linguagem: com aprendizado profundo de máquina, os modelos podem entender a linguagem humana e gerar respostas correspondentes. Esta técnica tem amplas perspectivas de aplicação no campo do processamento de linguagem natural.
- Sensível ao contexto: o modelo seq2seq+Atenção pode lembrar as informações de contexto do diálogo, de modo a manter a coerência em várias rodadas de diálogo e fornecer respostas mais precisas.
- Processamento multimodal: ao usar o pacote de análise de ferramentas OneAPI TensorFlow, combinado com outras tecnologias, como processamento de imagem e processamento de voz, é possível realizar entradas e saídas multimodais e fornecer uma experiência de diálogo mais rica.
- Modelo de pré-treinamento: Através de muito treinamento e aprendizado, os chatbots podem ter um certo nível de inteligência, ser capazes de responder a vários tipos de perguntas e fazer ajustes adaptativos com base em corpora em diferentes campos.
- Expansão dos cenários de aplicação: os chatbots podem ser amplamente utilizados no atendimento ao cliente, assistentes inteligentes, sistemas de resposta a perguntas e outros campos para fornecer aos usuários uma experiência conveniente de interação humano-computador.
Resumindo, o robô de bate-papo baseado no pacote de análise de ferramentas OneAPI TensorFlow usa tecnologia de aprendizado profundo e modelo seq2seq+Attention e, após uma grande quantidade de treinamento e aprendizado de dados, ele realiza a função básica de diálogo homem-máquina. Ele pode reconhecer automaticamente a entrada do usuário e fornecer as respostas correspondentes. Esses robôs alcançaram resultados satisfatórios na compreensão e geração de linguagem, consciência de contexto, processamento multimodal e modelos pré-treinados, fornecendo ricas possibilidades para vários cenários de aplicação.