
Como romper o gargalo da inteligência artificial (IA) contemporânea? Estudiosos diferentes têm visões diferentes.
De um modo geral, pode ser resumido em duas categorias: uma é a dos alunos supervisionados, que defendem a melhoria da aprendizagem supervisionada melhorando a qualidade dos rótulos de dados. Os representantes incluem Wu Enda, que iniciou a revolução da "IA centrada em dados", e Rev Lebaredian, que defendeu o design de "dados sintéticos com todos os rótulos".
Em segundo lugar, estudiosos não supervisionados, como Yann LeCun, defendem que a próxima geração de sistemas de IA não dependerá mais de conjuntos de dados cuidadosamente rotulados.
Recentemente, Yann LeCun explicou em profundidade suas ideias de aprendizado autossupervisionado no blog oficial da meta AI (anteriormente Facebook) e em uma entrevista ao IEEE. Ele acredita que, se a IA quiser romper o gargalo atual, deve deixar a máquina aprender o modelo mundial para preencher as lacunas de informações, prever o que acontecerá e prever o impacto das ações.

Não foi uma ideia revolucionária, mas foi um ato revolucionário. Como LeCun mencionou em muitos discursos: Esta revolução não será supervisionada (A REVOLUÇÃO NÃO SERÁ SUPERVISIONADA). Especificamente, essa revolução se reflete no pensamento de duas questões:
Primeiro, que paradigma de aprendizado devemos usar para treinar o modelo mundial?
Em segundo lugar, qual arquitetura o modelo mundial deveria usar?
Ao mesmo tempo, ele também mencionou que as limitações do aprendizado supervisionado às vezes são confundidas com as limitações do aprendizado profundo, e essas limitações podem ser superadas pelo aprendizado autossupervisionado.
O seguinte é o pensamento de LeCun sobre auto-supervisão e design de modelo mundial. O conteúdo vem de meta AI e IEEE. A AI Technology Review foi compilada sem alterar o significado original.
AI pode aprender modelos do mundo
LeCun mencionou que humanos e animais podem aprender conhecimento de mundo por meio de observação, interação simples e de maneira não supervisionada, portanto, pode-se supor que as habilidades potenciais contidas nisso formam a base do senso comum. Esse bom senso permite que os humanos concluam tarefas em ambientes desconhecidos, como um jovem motorista que nunca dirigiu um carro na neve, mas sabe que, se o carro for muito forte, os pneus escorregarão.
Já décadas atrás, alguns estudiosos estudaram como humanos, animais e até mesmo sistemas inteligentes "aproveitam" o modelo mundial para aprender por si mesmos. Portanto, a IA atual também está enfrentando um redesenho de paradigmas e arquiteturas de aprendizado, permitindo que as máquinas aprendam modelos do mundo de maneira autossupervisionada e, em seguida, usem esses modelos para previsão, raciocínio e planejamento.
Os modelos mundiais precisam incorporar perspectivas de diferentes disciplinas, incluindo, entre outras, ciência cognitiva, neurociência de sistemas, controle ideal, aprendizado por reforço e inteligência artificial "tradicional". Eles devem ser combinados com novos conceitos em aprendizado de máquina, como aprendizado autossupervisionado e arquiteturas de incorporação conjunta.
Nova arquitetura de IA: arquitetura de inteligência autônoma
Com base na ideia do modelo de mundo acima mencionado, LeCun propõe uma agência inteligente autônoma, que consiste em seis módulos independentes, e assume que cada um é diferenciável: algumas funções objetivas podem ser facilmente calculadas e as estimativas de gradiente correspondentes e o gradiente informações Propagadas para módulos upstream.
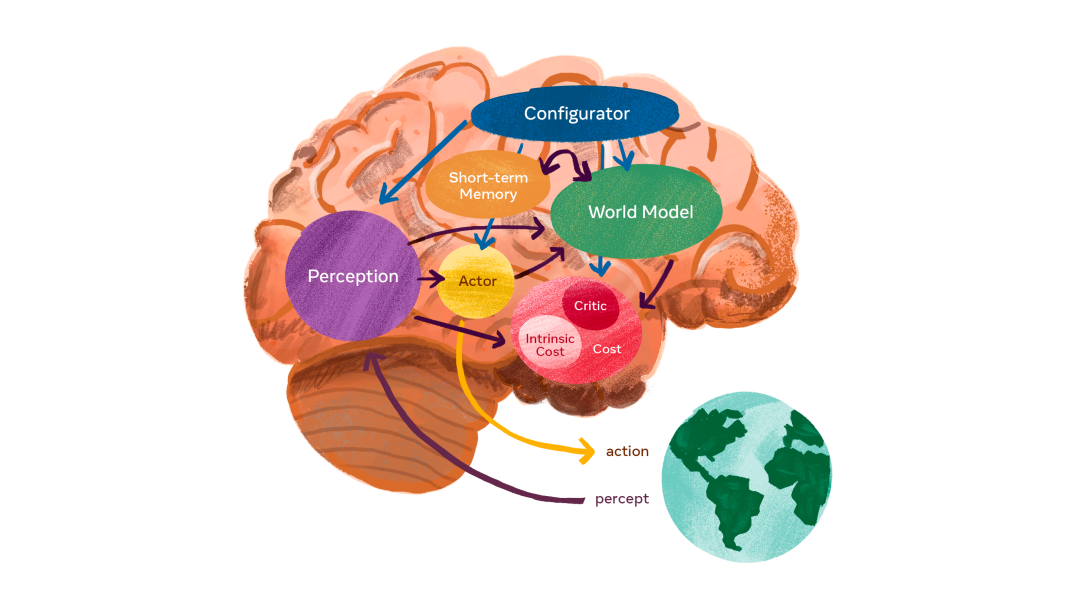
Arquitetura de sistema autônoma e inteligente: O configurador é o núcleo e recebe entrada de outros módulos.
-
A função do configurador é o controle. Dada uma tarefa a ser executada, ele pré-configura módulos de percepção, modela o mundo ajustando parâmetros, calcula custos e adiciona atores.
-
O módulo de percepção é capaz de receber informações e estimar o mundo real. Para uma tarefa específica, apenas uma pequena fração do estado do mundo percebido é relevante e útil. O configurador alimenta o módulo de percepção, que extrai informações relevantes para a tarefa da percepção.
-
O módulo de modelo mundial é a parte mais complexa e serve a um papel duplo. 1. Estimar a informação que falta que o módulo de percepção não consegue obter 2. Prever razoavelmente o estado futuro do mundo, incluindo a evolução natural do mundo e o impacto das ações dos participantes. Um modelo de mundo é um simulador do mundo real e, como o mundo é cheio de incertezas, o modelo deve ser capaz de lidar com várias previsões possíveis. Exemplo intuitivo: um motorista que se aproxima de um cruzamento pode diminuir a velocidade de seu carro para evitar que outro veículo que se aproxima do cruzamento não pare em um sinal de parada.
-
O módulo de custo é usado para calcular a inadequação do agente previsto. Consiste em duas partes: custo intrínseco, que não é treinável, mas pode calcular o "desconforto" em tempo real: dano do agente, violação de comportamento codificado etc.; crítico, que é um módulo treinável que prevê o valor futuro de o custo intrínseco.
LeCun disse: O módulo de custo é onde estão os direcionadores comportamentais básicos e as motivações intrínsecas. Assim, levará em consideração o custo intrínseco: não desperdiçar energia e o consumo específico da tarefa. O módulo de custo é separável e o gradiente do custo pode ser retropropagado por meio de outros módulos para planejamento, raciocínio ou aprendizado.
-
O módulo do participante fornece recomendações para ação. O módulo ator pode encontrar uma sequência ótima de ações que minimize o custo futuro estimado e produzir a primeira ação na sequência ótima, de maneira semelhante ao controle ótimo clássico.
-
O módulo de memória de curto prazo pode registrar a situação atual, prever o estado do mundo e o custo associado.
Arquitetura de modelo mundial e treinamento auto-supervisionado
No coração da arquitetura do modelo mundial está a previsão.
Um dos principais desafios na construção de um modelo mundial é como fazer com que o modelo represente várias previsões ambíguas. O mundo real não é totalmente previsível: uma determinada situação pode evoluir de várias maneiras, e muitos detalhes relevantes para a situação são irrelevantes para a tarefa em questão. Por exemplo, posso precisar prever o que os carros ao meu redor farão enquanto dirijo, mas não preciso prever a posição detalhada de folhas individuais em árvores próximas à estrada. Então, como o modelo de mundo aprende uma representação abstrata do mundo real, retém detalhes importantes, ignora detalhes irrelevantes e faz previsões no espaço de representações abstratas?
Um elemento chave da solução é a Joint Embedding Predictive Architecture (JEPA). JEPA captura as dependências entre duas entradas (x e y). Por exemplo, x pode ser um vídeo e y pode ser o próximo vídeo. As entradas x e y são alimentadas para codificadores treináveis que extraem suas representações abstratas, ou seja, sx e sy. O módulo preditor é treinado para prever sy a partir de sx. Um preditor pode usar a variável latente z para representar informações que estão presentes em sy, mas não em sx. O JEPA lida com a incerteza nas previsões de duas maneiras: (1) o codificador pode optar por descartar informações difíceis de prever sobre y; (2) quando a variável latente z varia em um conjunto, isso causará um conjunto de previsões plausíveis em mudar.
Então, como treinamos JEPA?
Até agora, o único método que os pesquisadores usaram é o "contraste", que envolve mostrar exemplos de x e y compatíveis e muitos exemplos de x e y incompatíveis. Mas isso é bastante impraticável quando a representação é um estado de alta dimensão.
Outra estratégia de formação surgiu nos últimos dois anos: os métodos de regularização. Quando aplicado ao treinamento JEPA, o método usa quatro critérios:
-
tornar a representação de x maximamente informativa sobre x
-
tornar a representação de y maximamente informativa sobre y
-
tornar a representação de y previsível ao máximo a partir da representação de x
-
Faça com que o preditor use o mínimo possível de informações de variáveis latentes para representar a incerteza na previsão
Esses critérios podem ser transformados em funções de custo diferenciáveis de várias maneiras. Um método é o método VICReg, ou seja, variância/variável (Variance), invariância (Invariância), regularização de covariância (Regularização de covariância). No VICReg, o conteúdo da informação representado por x e y é maximizado mantendo a variância de seus componentes acima de um limite e tornando esses componentes tão independentes quanto possível. Ao mesmo tempo, o modelo tenta tornar a representação de y previsível a partir da representação de x. Além disso, o conteúdo informacional das variáveis latentes é minimizado tornando-as discretas, de baixa dimensão, esparsas ou ruidosas.

A beleza do JEPA é que ele produz naturalmente uma representação abstrata das informações de entrada, elimina detalhes irrelevantes e pode realizar previsões. Isso permite que os JEPAs sejam empilhados uns sobre os outros para aprender representações com um maior nível de abstração, permitindo previsões de longo prazo.
Por exemplo, uma cena pode ser descrita em alto nível como "o chef está fazendo crepes". Ele prevê que o cozinheiro vai buscar a farinha, o leite e os ovos, misturar os ingredientes, colocar a massa na frigideira, fritar a massa, virar o crepe e repetir o processo várias vezes. Em um nível mais baixo de expressão, a cena pode ser derramar uma colher de massa e espalhá-la uniformemente pela frigideira. A trajetória precisa da mão do chef que dura cada milissegundo. Em trajetórias de mão de baixo nível, nosso modelo de mundo só pode fazer previsões precisas de curto prazo. Mas em um nível mais alto de abstração, ele pode fazer previsões de longo prazo.
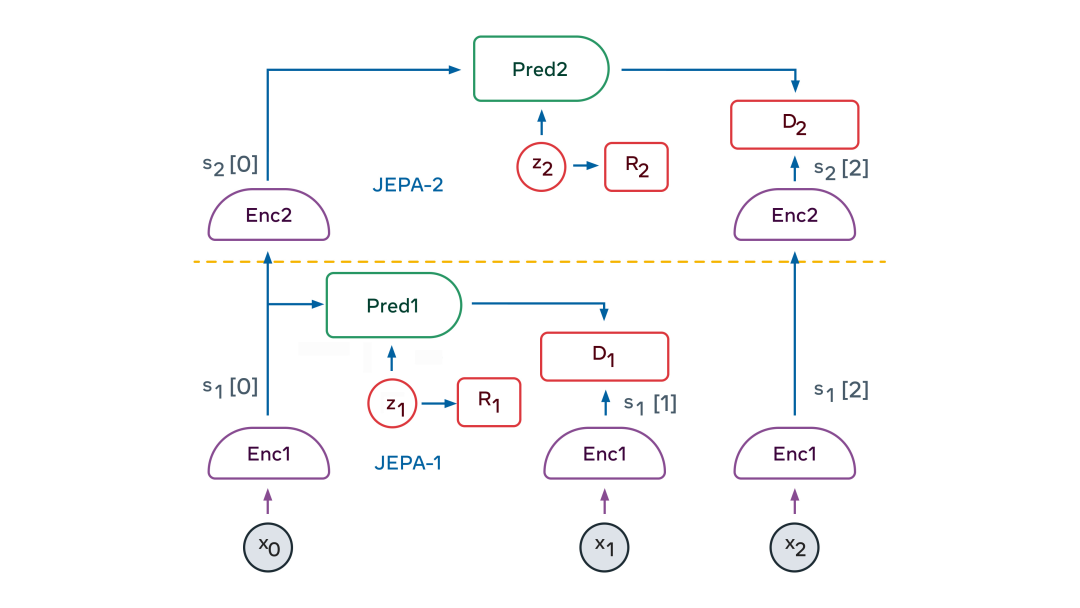
O JEPA hierárquico pode ser usado para realizar previsões em vários níveis de abstração e em várias escalas de tempo. O método de treinamento é principalmente através da observação passiva e raramente através da interação.
Nos primeiros meses de vida, os bebês aprendem como o mundo funciona principalmente pela observação. Ela aprendeu que o mundo é tridimensional, que alguns objetos serão colocados na frente de outros e que, quando um objeto é ocluído, ele ainda existe. Eventualmente, por volta dos 9 meses de idade, os bebês aprendem física intuitiva – por exemplo, que objetos sem suporte caem devido à gravidade.
A visão do JEPA em camadas é que ele pode aprender como o mundo funciona assistindo a vídeos e interagindo com o ambiente. Ao se treinar para prever o que vai acontecer em um vídeo, ele pode gerar uma representação hierárquica do mundo. Ao realizar ações no mundo e observar os resultados, o modelo mundial aprenderá a prever as consequências de suas ações e, assim, será capaz de raciocinar e planejar.
Trama "Sense-Act"
Ao treinar o JEPA hierárquico como um modelo de mundo, um agente (robô) pode realizar o planejamento hierárquico de ações complexas, decompondo tarefas complexas em uma série de subtarefas menos complexas e menos abstratas, até o efetor (efetor) ação de baixo nível.
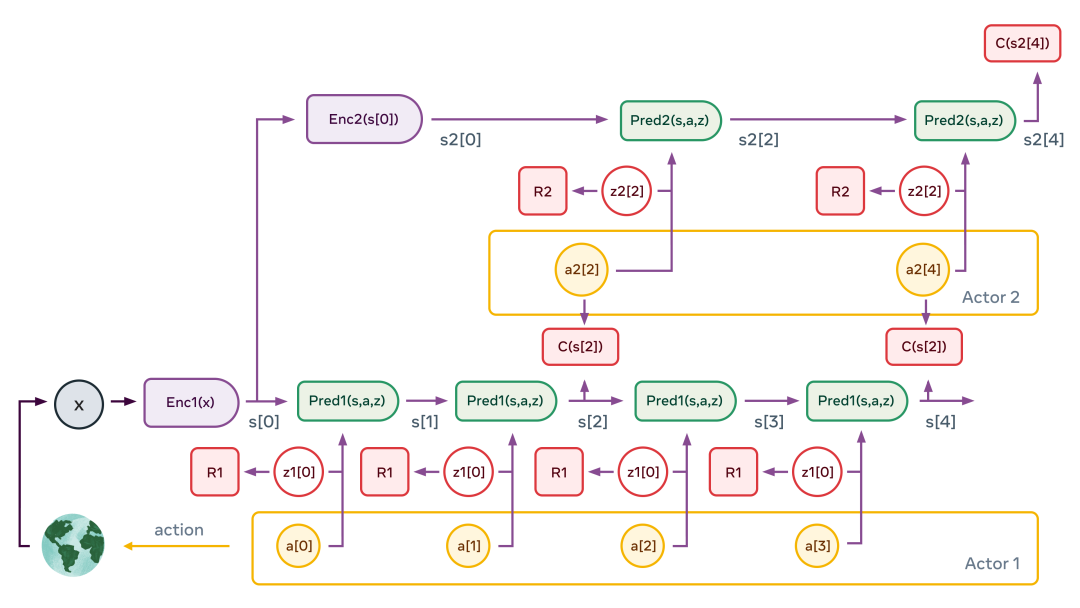
Um enredo típico de percepção-ação é o descrito acima. A figura ilustra o caso de uma hierarquia de dois níveis. O módulo de percepção extrai uma representação hierárquica do estado do mundo (s1[0]=Enc1(x) e s2[0]=Enc2(s[0]) na figura). Em seguida, o preditor secundário é aplicado várias vezes para prever o estado futuro dada a sequência de ações abstratas propostas pelo ator secundário. O ator otimiza a sequência de ação secundária para minimizar o custo total (C(s2[4]) na figura).
Este processo é semelhante ao modelo de controle preditivo no controle ótimo. Repita o processo para vários gráficos de variáveis latentes de segundo nível, que podem produzir diferentes cenários de alto nível. As ações de alto nível resultantes não constituem ações reais, mas apenas definem restrições que a sequência de estados de baixo nível deve satisfazer (por exemplo, os ingredientes estão misturados corretamente?). Eles formam submetas. Todo o processo é repetido nas camadas inferiores: execute os preditores da camada inferior, otimize as sequências de ação da camada inferior para minimizar o custo intermediário da camada superior e repita o processo para vários gráficos das variáveis latentes da camada inferior. Uma vez que o processo está completo, o agente envia a primeira ação de baixo nível para o efetor, e todo o episódio pode ser repetido.
Se conseguirmos construir tal modelo, então todos os módulos são diferenciáveis, então todo o processo de otimização de movimento pode ser executado usando métodos baseados em gradiente.
Aproximando a IA da inteligência de nível humano
A visão de LeCun precisa ser explorada mais profundamente e há muitos desafios assustadores pela frente. Um dos desafios mais interessantes e difíceis foi instanciar os detalhes de arquitetura e treinamento para o modelo mundial. Poderíamos até dizer que treinar um modelo do mundo é o principal desafio no qual a inteligência artificial pode realmente avançar nas próximas décadas.
Mas muitos outros aspectos da arquitetura ainda precisam ser definidos, incluindo como exatamente treinar um crítico (o papel de uma rede crítica é medir quão bom é um ator em um determinado estado), como construir e treinar um configurador e como usar a memória de curto prazo para acompanhar o estado do mundo e armazenar o histórico do estado e das ações do mundo e usar o custo intrínseco para ajustar o crítico.
LeCun e outros pesquisadores da Meta AI estão ansiosos para explorá-los nos próximos meses e anos, trocando ideias e aprendizados com outros no campo. Criar máquinas que possam aprender e entender tão eficientemente quanto os humanos é um empreendimento científico de longo prazo - e o sucesso não é garantido. Mas acreditamos que a pesquisa fundamental continuará a aprofundar nossa compreensão de mentes e máquinas e levará a muitos outros avanços da IA que beneficiarão a humanidade.
Yann LeCun: IA não precisa de supervisão humana
IEEE Spectrum: Você disse que as limitações do aprendizado supervisionado às vezes são confundidas com limitações intrínsecas do aprendizado profundo, então quais limitações podem ser superadas com o aprendizado autossupervisionado?
Yann LeCun : O aprendizado supervisionado funciona bem em alguns campos estruturalmente estáveis. Nesses domínios, você pode coletar muitos dados rotulados e pode ver durante a implantação que esses tipos de entrada não são muito diferentes dos tipos de entrada usados durante o treinamento. É difícil coletar grandes quantidades de dados rotulados que sejam relativamente imparciais. Não estou falando necessariamente de viés social, estou dizendo que correlações nos dados não devem ser usadas pelo sistema. Um exemplo muito famoso é quando você está treinando um sistema que reconhece vacas, e você está treinando com vacas no pasto, o sistema usará a grama como pano de fundo para as vacas. Dada outra vaca na praia, pode ser mais difícil de detectar.
O aprendizado auto-supervisionado (SSL) nos permite treinar sistemas para aprender boas representações de entrada de maneira independente da tarefa. Como o treinamento SSL usa dados não rotulados, podemos usar conjuntos de treinamento muito grandes e permitir que o sistema aprenda representações mais robustas e completas das entradas. Então, requer apenas uma pequena quantidade de dados rotulados para obter um bom desempenho em tarefas supervisionadas. Isso reduz bastante a quantidade de dados rotulados típicos do aprendizado puramente supervisionado e torna o sistema mais robusto para entradas que diferem das amostras de treinamento rotuladas. Às vezes, também reduz a sensibilidade do sistema ao viés de dados - uma melhoria que compartilharemos com mais informações da pesquisa nas próximas semanas.
O que está acontecendo agora em sistemas reais de IA é que estamos migrando para arquiteturas maiores que usam SSL para pré-treinar grandes quantidades de dados não rotulados. Estes podem ser usados para várias tarefas. Por exemplo, a Meta AI agora possui um sistema de tradução de idiomas que pode lidar com centenas de idiomas. Isso é uma única rede neural! Também temos um sistema de reconhecimento de fala multilíngue. Esses sistemas podem lidar com idiomas com poucos dados, muito menos dados anotados.
IEEE Spectrum: Outros pioneiros da indústria dizem que o caminho a seguir para a IA é melhorar o aprendizado supervisionado por meio de uma melhor rotulagem de dados. Andrew Ng recentemente falou comigo sobre IA centrada em dados , e o Rev Lebaredian da NVIDIA falou comigo sobre dados sintéticos com todos os rótulos. Existem divergências no campo sobre o caminho a seguir?
LeCun : Não acho que haja uma divisão filosófica. O pré-treinamento SSL é uma prática bastante comum em PNL. Ele apresentou grandes melhorias de desempenho no reconhecimento de fala e começou a se tornar cada vez mais útil para a visão. No entanto, ainda existem muitas aplicações inexploradas de aprendizado supervisionado "clássico", portanto, é claro que deve-se usar dados sintéticos e aprendizado supervisionado sempre que possível. A Nvidia também está desenvolvendo SSL ativamente.
Em meados dos anos 2000, Geoff Hinton, Yoshua Bengio e eu estávamos convencidos de que a única maneira de treinar redes neurais muito grandes e profundas era por meio do aprendizado autossupervisionado (ou não supervisionado). Foi também quando Andrew Ng se interessou pelo aprendizado profundo. Seu trabalho na época também estava centrado no que hoje chamamos de autossupervisão.
IEEE Spectrum: Como o aprendizado auto-supervisionado leva a sistemas de IA de senso comum? Até que ponto o bom senso pode levar os sistemas de IA à inteligência de nível humano?
LeCun : Acho que a IA fará grandes avanços assim que descobrirmos como fazer as máquinas aprenderem como o mundo funciona da mesma forma que os humanos e os animais: principalmente observando e agindo com base nessa observação. Entendemos como o mundo funciona porque aprendemos um modelo interno do mundo que nos permite preencher as informações que faltam, prever o que acontecerá e prever o impacto de nossas ações. Nossos modelos de mundo nos permitem perceber, interpretar, raciocinar, planejar com antecedência e agir.
Mas como uma máquina aprende um modelo do mundo? Isso se resume a duas questões: qual paradigma de aprendizagem devemos usar para treinar o modelo mundial? Que arquitetura o modelo mundial deve usar?
Para a primeira pergunta, minha resposta é SSL (aprendizagem autossupervisionada). Um exemplo seria fazer com que uma máquina assistisse a um vídeo, pausasse o vídeo e, em seguida, fizesse com que a máquina aprendesse uma representação do que acontecerá a seguir no vídeo. Ao fazer isso, as máquinas podem aprender uma riqueza de conhecimento básico sobre como o mundo funciona, talvez semelhante à forma como bebês e animais aprendem durante as primeiras semanas e meses de vida.
Para a segunda pergunta, minha resposta é um novo tipo de macroarquitetura profunda, que chamo de Arquitetura de previsão de incorporação conjunta hierárquica (H-JEPA). Resumidamente explicado, em vez de prever quadros futuros de um videoclipe, JEPA aprende uma representação abstrata do videoclipe e o futuro do clipe para que o último possa ser facilmente previsto com base na compreensão do primeiro. Isso pode ser alcançado usando alguns desenvolvimentos recentes em métodos SSL não contrastantes, em particular um recentemente proposto por mim e por meus colegas chamado "VICReg".
IEEE Spectrum: Algumas semanas atrás, você respondeu a um tweet de Ilya Sutskever na OpenAI no qual ele especulava que as grandes redes neurais de hoje podem ser conscientes. Sua resposta é um sonoro "não". Na sua opinião, o que é preciso para construir uma rede neural consciente? Como seria esse sistema?
LeCun : Em primeiro lugar, a consciência é um conceito muito vago. Alguns filósofos, neurocientistas e cientistas cognitivos acham que é apenas uma ilusão, e estou bem perto disso.
Mas tenho um palpite sobre o que causa a ilusão de consciência. Minha hipótese é que temos um único "motor" modelo mundial em nosso córtex pré-frontal. O modelo mundial pode ser configurado de acordo com a situação atual. Somos o timoneiro do veleiro, nosso modelo de mundo simula as correntes de ar e água ao redor do nosso barco. Construímos uma mesa de madeira; nosso modelo do mundo imaginou os resultados do corte e montagem da madeira, e assim por diante.
Precisamos de um módulo em nosso cérebro, que chamo de "configurador", que estabeleça metas e submetas para nós, configure nosso modelo de mundo para simular a situação atual e ative nosso sistema de percepção para extrair informações relevantes e descartar informações redundantes. . A existência de um configurador supervisor pode ser responsável por nossa ilusão de consciência. Mas aqui está o engraçado: precisamos desse configurador porque só temos um motor de modelo mundial. Se nossos cérebros fossem grandes o suficiente para acomodar muitos modelos do mundo, não precisaríamos de consciência. Então, nesse sentido, a consciência é resultado das limitações do nosso cérebro!
IEEE Spectrum: Que papel o aprendizado autossupervisionado pode desempenhar na construção do Metaverso?
LeCun : O aprendizado profundo tem muitas aplicações específicas no mundo virtual, como rastreamento de movimento para óculos VR e óculos AR, captura e ressintetização de movimentos corporais e expressões faciais e muito mais.
Existem muitas oportunidades para novas ferramentas criativas orientadas por IA no metaverso, permitindo que todos criem coisas novas nos mundos virtual e real. Mas o Metaverse também possui um aplicativo de "IA pura": assistentes virtuais de IA. Devemos ter assistentes virtuais de IA que possam nos ajudar em nossas vidas diárias, responder a quaisquer perguntas que tenhamos e nos ajudar a lidar com o dilúvio de informações que nos bombardeiam todos os dias. Para fazer isso, precisamos que nossos sistemas de IA tenham alguma compreensão de como o mundo funciona (seja físico ou virtual), alguma capacidade de raciocinar e planejar e algum nível de bom senso. Resumindo, precisamos descobrir como construir sistemas de IA autônomos que possam aprender como humanos. Leva tempo. Mas a Meta está nessa trilha há muito tempo.
Link de referência:
1. https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research
2.https://spectrum.ieee.org/yann-lecun-ai
O editor compilou informações sobre inteligência artificial, incluindo bibliotecas de recursos, como processamento de imagens opencv\processamento de linguagem natural, fundamentos matemáticos de aprendizado de máquina, livros eletrônicos de leitura obrigatória e coleções de artigos. Estudantes universitários que desejam aprender inteligência artificial ou mudar para indústrias de alta remuneração também estão muito interessadas. Prático, gratuito e sem rotina,
Adicione minha saia [ 966367816 ] para fazer o download ou escaneie o código + vx para receber recursos internos, banco de perguntas sobre inteligência artificial, esboço de estudo de perguntas de entrevista de Dachang, esboço de curso de autoestudo e farra de dados de inteligência artificial de 500G gratuitamente ~
