1. Modelo de linguagem grande
Large Language Model refere-se a um modelo de linguagem com um grande número de parâmetros e capacidades de processamento. Esses modelos são treinados com técnicas de aprendizado profundo para processar e gerar texto em linguagem natural.
Os modelos de linguagem em larga escala desempenham um papel importante no campo do processamento de linguagem natural, pois podem entender e gerar texto e executar tarefas relacionadas à linguagem, como tradução automática, resumo de texto, análise de sentimento, sistemas de diálogo, etc. Esses modelos são treinados em conjuntos de dados de texto massivos, permitindo que aprendam a estrutura, a sintaxe, a semântica e a relevância contextual da linguagem.
Nos últimos anos, com o desenvolvimento da tecnologia e o aumento dos recursos computacionais, os grandes modelos de linguagem tornaram-se cada vez mais poderosos. O exemplo mais famoso são os modelos da série GPT (Transformador Pré-treinado Generativo) da OpenAI, como GPT-3, GPT-4, etc. Esses modelos têm bilhões a centenas de bilhões de parâmetros, são capazes de gerar texto de alta qualidade e funcionam bem em uma variedade de tarefas de linguagem.
O surgimento de modelos de linguagem em larga escala teve um enorme impacto nos campos de processamento de linguagem natural e inteligência artificial. Eles fornecem soluções de alto nível para problemas relacionados à linguagem e criam diálogos e experiências de interação mais naturais e inteligentes para as pessoas.
Existem também alguns recursos e aplicativos importantes quando se trata de modelos de linguagem grandes:
- Pré-treinamento: modelos de linguagem grandes geralmente passam por uma fase de pré-treinamento para aprender dados de texto em grande escala. Nesta fase, o modelo aprende as leis estatísticas e as representações semânticas da linguagem a partir de textos massivos sem rótulos. Dessa forma, o modelo pode adquirir um rico conhecimento de linguagem para melhorar seu desempenho em tarefas específicas subsequentes.
- Ajuste fino: após o pré-treinamento, modelos de linguagem grandes geralmente precisam ser ajustados para tarefas e conjuntos de dados específicos. O ajuste fino refere-se ao treinamento adicional do modelo em dados rotulados para melhor adaptá-lo a tarefas específicas, como classificação de sentimento, reconhecimento de entidade nomeada, etc.
- Geração de texto: modelos de linguagem grandes são ótimos para gerar texto. Eles podem gerar texto coerente e gramaticalmente correto a partir de um determinado contexto, variando de frases simples a textos longos. Essa capacidade generativa os torna amplamente aplicáveis em chatbots, escrita automatizada, assistentes virtuais e muito mais.
- Sistemas de diálogo: Grandes modelos de linguagem também são amplamente utilizados no desenvolvimento de sistemas de diálogo. Ao interagir com os usuários, esses modelos podem entender a intenção do usuário e fornecer respostas significativas. Eles são capazes de conduzir diálogos, tirar dúvidas, dar sugestões, etc., tornando o sistema de diálogo mais inteligente e natural.
O contínuo desenvolvimento e avanço de grandes modelos de linguagem trouxe novas oportunidades e desafios para o campo do processamento de linguagem natural. Eles não apenas melhoram o desempenho das tarefas de processamento de texto, mas também fornecem às pessoas formas de aplicação mais criativas e interativas. - Domínios de aplicativos: os modelos de linguagem em larga escala desempenham um papel importante em vários domínios de aplicativos. São utilizados na sumarização e geração automática de artigos, atendimento inteligente e assistentes virtuais, sistemas de recuperação e recomendação de informações, programação inteligente e geração de códigos, etc. Esses modelos são capazes de lidar com vários tipos de dados de texto e fornecer soluções para diferentes tarefas.
- Requisitos de dados: O treinamento de grandes modelos de linguagem requer uma grande quantidade de dados para capturar o conhecimento e os padrões da linguagem. Normalmente, esses modelos são pré-treinados usando corpora de texto em grande escala disponíveis na Internet. No entanto, para o ajuste fino de tarefas específicas, conjuntos de dados relativamente poucos, mas bem rotulados, são necessários. A qualidade e a diversidade dos dados são críticas para o desempenho e capacidade de generalização do modelo.
- Recursos computacionais: Devido ao grande número de parâmetros e estrutura complexa de grandes modelos de linguagem, treinamento e inferência requerem muitos recursos computacionais. O treinamento desses modelos pode exigir o uso de clusters massivos de computação distribuída e unidades de processamento gráfico (GPUs). Portanto, a disponibilidade de recursos de computação e infraestrutura é uma consideração importante para desenvolver e implantar grandes modelos de linguagem.
- Qualidade e viés: modelos de linguagem grandes podem ter problemas de qualidade e viés ao gerar texto. Eles podem conter informações imprecisas, conteúdo repetitivo ou linguagem tendenciosa. Portanto, garantir a qualidade de saída de grandes modelos de linguagem e corrigir possíveis vieses são direções importantes de pesquisa e desenvolvimento.
- Privacidade e Ética: Modelos de linguagem em grande escala podem ter questões éticas e de privacidade ao lidar com grandes quantidades de dados de texto. Proteger os dados pessoais e confidenciais dos usuários e garantir o uso transparente e justo desses modelos são considerações importantes.
Em conclusão, os modelos de linguagem de grande escala têm amplas perspectivas de aplicação nas áreas de processamento de linguagem natural e inteligência artificial. Eles podem entender e gerar texto em linguagem natural, proporcionando às pessoas uma melhor experiência interativa e soluções inteligentes. No entanto, ainda existem muitos desafios e questões que precisam ser abordadas para melhorar ainda mais o desempenho, a qualidade e a usabilidade desses modelos.
2. O pré-treinamento é uma tecnologia chave em grandes modelos de linguagem
O pré-treinamento é uma técnica chave em grandes modelos de linguagem. Refere-se ao treinamento inicial em dados de texto não rotulados em grande escala, para que o modelo possa aprender as leis estatísticas e a representação semântica da linguagem. O objetivo do pré-treinamento é permitir que o modelo capture um rico conhecimento linguístico dos dados e construa uma compreensão do mundo linguístico.
O processo de pré-treinamento geralmente adota o método de aprendizagem auto-supervisionada. O aprendizado autossupervisionado é um método de aprendizado que não requer rotulagem manual de dados e usa alvos gerados automaticamente nos dados para treinamento. No pré-treinamento, o modelo cria uma tarefa a partir de grandes quantidades de dados de texto que exige que o modelo preveja a palavra que falta ou a próxima frase com base no contexto. Os modelos tentam resolver essas tarefas preditivas aprendendo a relação entre o contexto e a estrutura da linguagem.
Durante o processo de pré-treinamento, o modelo ajusta gradualmente seus parâmetros internos para permitir a codificação de padrões, sintaxe, semântica e informações contextuais na linguagem. Esse processo de aprendizado permite que o modelo capture as associações entre palavras, frases e sentenças, construindo assim sua capacidade de representar a linguagem.
Depois de pré-treinado, o modelo pode ser usado para várias tarefas específicas de downstream. Nessas tarefas, o modelo geralmente precisa ser ajustado para se adaptar às necessidades da tarefa específica e às características do conjunto de dados. Por meio do ajuste fino, um modelo pode ser treinado em um conjunto de dados rotulado para adaptá-lo aos objetivos e requisitos de uma tarefa específica.
A vantagem do pré-treinamento é que ele pode utilizar uma grande quantidade de dados não rotulados e aprender uma ampla gama de conhecimentos de idiomas a partir deles. Isso faz com que o modelo tenha certa versatilidade e capacidade de generalização, podendo apresentar melhor desempenho em diversas tarefas e conjuntos de dados. O pré-treinamento também permite que o modelo tenha uma certa compreensão de fenômenos e contextos de linguagem invisíveis, para que possa lidar melhor com a diversidade e a complexidade nas tarefas posteriores.
Deve-se notar que o pré-treinamento não é um processo definitivo. Com o passar do tempo e a adição de novos dados, o modelo pode melhorar ainda mais o desempenho e se adaptar a novos ambientes de linguagem por meio de um novo pré-treinamento. Portanto, o pré-treinamento é uma parte importante da melhoria contínua e do desenvolvimento de grandes modelos de linguagem.
No processo de pré-treinamento, geralmente são usados conjuntos de dados de texto não rotulados em grande escala. Esses conjuntos de dados podem ser grandes quantidades de texto extraídos da Internet, como Wikipedia, conteúdo da Web, livros, artigos de notícias, etc. Esses dados de texto não são explicitamente rotulados ou anotados, mas contêm informações e estrutura linguísticas ricas.
A arquitetura do modelo pré-treinado geralmente é baseada no modelo Transformer em aprendizado profundo, como a série GPT (Generative Pre-trained Transformer). Essa arquitetura de modelo é capaz de lidar com dependências de longa distância e capturar informações contextuais do texto de entrada por meio da autoatenção.
Durante o pré-treinamento, os dados são divididos em segmentos de texto de comprimento fixo (por exemplo, sentenças de comprimento fixo ou número fixo de palavras). O modelo então prevê um dos segmentos com base no contexto. Por exemplo, dada a parte anterior de uma frase, o modelo precisa prever a parte posterior dessa frase. Essa tarefa é chamada de Masked Language Modeling (MLM).
Em um modelo de linguagem mascarada, o modelo aprende relacionamentos de palavras, estrutura gramatical e informações semânticas no contexto para prever palavras mascaradas. Ao resolver essas tarefas, o modelo pode aprender representações distribuídas de palavras (embeddings de palavras) e informações de contexto.
O número de parâmetros de um modelo pré-treinado costuma ser muito grande, chegando a bilhões ou centenas de bilhões. Esse grande número de parâmetros permite que o modelo capture melhor a complexidade e a diversidade do texto.
Depois de pré-treinado, o modelo pode ser ajustado para tarefas e conjuntos de dados específicos. O estágio de ajuste fino geralmente usa dados rotulados para fazer com que o modelo se adapte melhor aos objetivos e requisitos da tarefa treinando em uma tarefa específica.
A vantagem do pré-treinamento é que ele pode aprender com dados não rotulados em grande escala, o que fornece uma gama mais ampla de conhecimento de idioma e compreensão contextual. Essa generalidade permite que modelos pré-treinados se adaptem a várias tarefas e domínios e tenham um bom desempenho em diferentes tarefas de processamento de linguagem natural.
No processo de pré-treinamento, algumas técnicas e estratégias também podem ser aplicadas para melhorar ainda mais o desempenho e o efeito do modelo:
- Pré-treinamento multitarefa: além de uma única tarefa de modelagem de linguagem mascarada, o pré-treinamento multitarefa também pode ser usado para aumentar a diversidade e a capacidade de aprendizado do modelo. Isso significa que, durante o pré-treinamento, o modelo pode aprender simultaneamente a lidar com várias tarefas de previsão diferentes, como modelagem de linguagem mascarada, previsão da próxima frase, classificação de texto etc. Esse pré-treinamento multitarefa ajuda o modelo a obter uma compreensão de linguagem e recursos de raciocínio mais abrangentes.
- Bootstrapping: Bootstrapping refere-se ao uso do texto gerado pelo próprio modelo como parte dos dados de treinamento durante o processo de pré-treinamento. O modelo primeiro gera algumas amostras de texto falso e, em seguida, mistura essas amostras com dados reais não rotulados para treinamento. Por meio do bootstrap, o modelo pode aprender mais estruturas e padrões de linguagem das amostras que ele mesmo gera.
- Mascaramento dinâmico: a tarefa tradicional de modelagem de linguagem mascarada geralmente é mascarar aleatoriamente algumas palavras no texto de entrada e, em seguida, o modelo precisa prever essas palavras mascaradas. Para melhorar ainda mais a capacidade de generalização do modelo, uma estratégia de mascaramento dinâmico pode ser adotada. O mascaramento dinâmico refere-se à seleção de palavras a serem mascaradas com base na importância ou probabilidade de cada palavra, em vez de mascaramento aleatório. Essa estratégia ajuda o modelo a entender melhor a semântica e o contexto.
- Pré-treinamento incremental: O pré-treinamento não é necessariamente concluído de uma só vez, mas o modelo pode ser continuamente aprimorado e expandido por meio do pré-treinamento incremental. No pré-treinamento incremental, o modelo pré-treinado pode ser estendido ainda mais com novos dados e tarefas para melhorar seu desempenho e adaptabilidade.
O pré-treinamento é uma das etapas fundamentais para o sucesso de grandes modelos de linguagem. Ele permite que o modelo aprenda a estrutura e a representação da linguagem a partir de dados não rotulados em grande escala, possuindo assim uma ampla gama de recursos de compreensão e geração de linguagem. Modelos pré-treinados podem fornecer resultados de geração e processamento de texto de maior qualidade e precisão, ajustando-os para tarefas específicas.
3. Word embeddings (embedding de palavras) é um método de representação que mapeia palavras em um espaço vetorial contínuo
Embeddings de palavras são uma representação que mapeia palavras em um espaço vetorial contínuo. É uma técnica para converter símbolos discretos (palavras) em vetores numéricos contínuos. As incorporações de palavras são amplamente utilizadas no campo do processamento de linguagem natural para representar as informações semânticas e contextuais das palavras.
Os métodos tradicionais de processamento de texto geralmente representam palavras como vetores codificados one-hot, onde cada palavra corresponde a uma posição de índice única, apenas um elemento no vetor é 1 e o restante dos elementos é 0. No entanto, essa representação falha em capturar a relação semântica e a semelhança entre as palavras.
As incorporações de palavras mapeiam palavras em um espaço vetorial de valor real de baixa dimensão, tornando as palavras com semântica semelhante mais próximas no espaço vetorial. Este método de representação permite que a informação semântica das palavras seja representada por distância e direção no espaço vetorial.
As incorporações de palavras podem ser geradas por diferentes algoritmos e modelos. Um dos métodos comumente usados é o Word2Vec, que é baseado em um modelo de rede neural que gera vetores de palavras aprendendo os padrões de distribuição de palavras no contexto. O método Word2Vec possui dois modelos: modelos Continuous Bag-of-Words (CBOW) e Skip-Gram. O modelo CBOW prevê a palavra atual com base na palavra contextual, enquanto o modelo Skip-Gram faz o oposto e prevê a palavra contextual com base na palavra atual.
Outro método comumente usado é o GloVe (Global Vectors for Word Representation), que combina estatísticas globais e informações de contexto local. O GloVe gera vetores de palavras analisando as estatísticas de co-ocorrência de palavras em um corpus de texto em larga escala.
A vantagem de usar incorporações de palavras é que elas podem representar palavras como vetores contínuos de valor real, de modo que a relação semântica entre palavras possa ser representada por distância e direção no espaço vetorial. Essa representação pode capturar melhor as informações semânticas e contextuais das palavras e é útil para muitas tarefas de processamento de linguagem natural, como cálculo de similaridade de sentido de palavra, classificação de texto, reconhecimento de entidade nomeada, etc. Além disso, as incorporações de palavras também podem ser usadas como entrada de modelos de aprendizado profundo para fornecer informações semânticas mais ricas, melhorando assim o desempenho do modelo.
Além de Word2Vec e GloVe, existem outros métodos de incorporação de palavras comumente usados, como:
- FastText: FastText é um método de incorporação de palavras baseado em subpalavras. Ele representa uma palavra como a média dos vetores de suas subpalavras (n-gramas), capturando assim informações semânticas mais refinadas dentro das palavras. O FastText tem melhor desempenho ao lidar com idiomas morfologicamente ricos e fora do vocabulário.
- ELMo (Embeddings from Language Models): ELMo é um método de incorporação de palavras baseado em contexto. Ele usa um modelo de linguagem bidirecional para gerar representações vetoriais de palavras, levando em consideração a polissemia e as mudanças semânticas das palavras em diferentes contextos. O ELMo pode fornecer vários níveis diferentes de representações de recursos para cada palavra, de modo a capturar melhor as informações semânticas e contextuais das palavras.
- BERT (Representações de Codificador Bidirecional de Transformers): BERT é um modelo de linguagem pré-treinado baseado no modelo Transformer. Ele é pré-treinado com modelagem de linguagem mascarada e tarefas de previsão da próxima frase, gerando incorporações de palavras com representações semânticas ricas. A característica do BERT é que ele pode entender o relacionamento bidirecional no contexto e tem boa adaptabilidade a uma variedade de tarefas downstream.
Esses métodos levam em consideração as informações de contexto ao gerar incorporações de palavras, para que os vetores de palavras possam capturar melhor a semântica e o contexto das palavras. Tais incorporações de palavras podem ser aplicadas a várias tarefas de processamento de linguagem natural, como classificação de texto, reconhecimento de entidade nomeada, tradução automática, etc., para melhorar o desempenho e a eficácia do modelo.
Vale ressaltar que os embeddings de palavras gerados são uma representação estática, ou seja, cada palavra corresponde a um vetor fixo. Nos últimos anos, alguns métodos propuseram representações dinâmicas de incorporação de palavras, como Contextualized Word Embeddings (ELMo e BERT mencionados acima), que consideram o contexto de toda a frase ao gerar vetores de palavras e fornecem a cada palavra uma representação vetorial diferente. Essa representação dinâmica pode capturar melhor as informações contextuais e semânticas das palavras.
Além dos métodos comuns de incorporação de palavras mencionados acima, existem outros modelos e técnicas de incorporação de palavras, como:
- WordRank: WordRank é um método de incorporação de palavras baseado em gráfico. Ele usa as informações de coocorrência entre as palavras para construir uma estrutura gráfica e calcula a similaridade entre as palavras por meio de um algoritmo de passeio aleatório para gerar vetores de palavras.
- Vetores de parágrafo (Doc2Vec): Vetores de parágrafo é um método capaz de gerar representações incorporadas em nível de parágrafo ou documento. Funciona alimentando parágrafos ou documentos como um todo no modelo e aprendendo os vetores de incorporação correspondentes.
- Embeddings baseados em Transformer: Além do Transformer usado no modelo de linguagem pré-treinado, o modelo Transformer também pode ser usado diretamente para gerar incorporações de palavras. Embeddings baseados em Transformer usam um modelo Transformer para codificar uma sequência de entrada, mapeando cada palavra para uma representação vetorial de dimensão fixa.
- ConceptNet Numberbatch: ConceptNet Numberbatch é um método de incorporação de palavras baseado no gráfico de conhecimento. Ele combina uma grande quantidade de conhecimento semântico e associações para mapear palavras em um espaço vetorial de alta dimensão.
Esses métodos têm suas próprias características e escopo de aplicação, e o modelo de incorporação de palavras apropriado pode ser selecionado de acordo com as características da tarefa e dos dados. O desenvolvimento da tecnologia de incorporação de palavras promoveu continuamente o progresso no campo do processamento de linguagem natural, permitindo que os modelos entendam e processem melhor os dados de texto.
4. Como as incorporações de palavras e os tokens estão relacionados
Em tarefas de processamento de linguagem natural, o texto geralmente é processado por segmentação de palavras ou segmentação de palavras e é dividido em unidades discretas, ou seja, tokens. Um token pode ser uma palavra, um caractere ou outras unidades menores, dependendo da estratégia específica de segmentação de palavras.
Um vocabulário é uma coleção de todos os tokens possíveis envolvidos em uma tarefa. Cada token terá um índice exclusivo no vocabulário. A construção do vocabulário geralmente é baseada em conjuntos de dados de tarefas, incluindo conjuntos de treinamento e teste.
A geração de incorporações do Word é baseada no vocabulário. Uma vez que o vocabulário esteja no lugar, cada token pode ser associado à incorporação de palavra correspondente por meio de um índice.
Como exemplo, suponha que você tenha um vocabulário simples como este:
词汇表:['I', 'like', 'apples', 'and', 'oranges']
O índice correspondente é o seguinte:
索引:[0, 1, 2, 3, 4]
Se você usar o método Word2Vec para gerar incorporações de palavras, poderá obter a representação vetorial de cada palavra da seguinte maneira:
I 的词向量:[0.2, 0.3, -0.1]
like 的词向量:[0.5, -0.2, 0.4]
apples 的词向量:[0.1, 0.6, -0.3]
and 的词向量:[-0.2, 0.1, 0.5]
oranges 的词向量:[-0.4, -0.5, 0.2]
Por meio do índice do vocabulário, cada token pode ser mapeado para a incorporação de palavra correspondente. Por exemplo, a frase "Eu gosto de maçãs" pode ser representada como uma sequência de palavras incorporadas da forma:
[ [0.2, 0.3, -0.1], [0.5, -0.2, 0.4], [0.1, 0.6, -0.3] ]
Neste exemplo, cada token está associado a um vetor de incorporação de palavras correspondente. Essa representação de incorporação de palavras permite que as palavras no texto participem do treinamento do modelo subsequente e do processo de inferência na forma de vetores.
Por meio da incorporação de palavras, o modelo pode entender melhor a semântica e as informações de contexto das palavras e desempenhar um papel em várias tarefas de processamento de linguagem natural, como classificação de texto, reconhecimento de entidade nomeada, tradução automática, etc.
Ele pode ser usado em tarefas subsequentes de processamento de linguagem natural, como classificação de texto ou reconhecimento de entidade nomeada.
Para tarefas de classificação de texto, a sequência de palavras incorporadas para cada texto pode ser alimentada em um modelo de classificação, como o uso de uma rede neural recorrente (RNN) ou uma rede neural convolucional (CNN), etc. O modelo pode aprender a relação entre vetores de incorporação de palavras e informações contextuais para classificar o texto.
Para tarefas de reconhecimento de entidade nomeada, as incorporações de palavras podem ser usadas como recursos de entrada combinados com outros recursos (como tags de parte da fala, recursos de nível de caractere, etc.) para identificar entidades nomeadas no texto. Os vetores de incorporação de palavras podem ajudar o modelo a entender a semântica e o relacionamento contextual das palavras, de modo a identificar entidades nomeadas com mais precisão.
Em resumo, ao associar a incorporação de palavras a tokens, os dados de texto em tarefas de processamento de linguagem natural podem ser convertidos em sequências de incorporação de palavras, permitindo que o modelo aprenda informações semânticas e contextuais a partir delas. Essa representação ajuda a melhorar o desempenho e a eficácia do modelo em várias tarefas.
5. A emergência de grandes modelos de linguagem
"Emergence" (emergência) refere-se à geração de complexos e novos comportamentos, estruturas ou propriedades em um sistema, que são o resultado da interação e sinergia entre os vários componentes do sistema.
No contexto de grandes modelos de linguagem, "emergência" refere-se à capacidade do modelo de gerar novo conteúdo textual que seja semântico, lógico e criativo quando aprende a partir de dados textuais. Esse tipo de conteúdo de texto não é observado diretamente pelo modelo nos dados de treinamento, mas é gerado por meio do aprendizado e da captura de padrões de uma grande quantidade de dados de treinamento.
O modelo de linguagem grande aprende as regras e estruturas da linguagem natural por meio do processo de pré-treinamento e ajuste fino. Na fase de pré-treinamento, o modelo usa dados de texto massivos para aprender conhecimento sobre vocabulário, sintaxe, semântica, etc., e gera representações de linguagem ricas. No estágio de ajuste fino, o modelo é ainda mais ajustado e otimizado por meio de dados de treinamento específicos da tarefa para se adaptar a tarefas específicas de processamento de linguagem natural.
Quando um grande modelo de linguagem é aplicado a tarefas como geração de texto, resposta a perguntas, condução de diálogos, etc., ele pode mostrar criatividade e capacidade de linguagem surpreendentes. Os modelos podem gerar artigos coerentes, lógicos e semanticamente precisos, histórias, respostas e muito mais, às vezes até imitando um estilo ou voz diferente. Esse conteúdo textual gerado demonstra a capacidade do modelo de entender a linguagem e ser criativo, e é considerado uma "emergência" no processo de aprendizado do modelo.
Vale ressaltar que embora grandes modelos de linguagem possam gerar textos com criatividade e fluência, pode haver certas incertezas e erros no conteúdo gerado pelo modelo. Isso ocorre porque a saída do modelo é baseada nos padrões e regularidades estatísticas que ele observa nos dados de treinamento, e o modelo não tem compreensão real e capacidade de raciocínio. Portanto, ao usar um grande modelo de linguagem para gerar texto, ele precisa ser tratado com cautela, e sua saída deve ser verificada e filtrada para garantir a precisão e a racionalidade do conteúdo gerado.
Em grandes modelos de linguagem, "emergência" (emergência) também pode se referir a um modelo que exibe comportamentos ou capacidades além das expectativas que não foram explicitamente especificadas ou orientadas nos estágios iniciais de design e treinamento do modelo. O surgimento dessas características é o desenvolvimento gradual e a exibição do próprio modelo por meio do processo de aprendizado e iteração.
Quando um modelo de linguagem grande é grande o suficiente e totalmente treinado, ele pode exibir uma variedade de capacidades e comportamentos surpreendentes, incluindo, entre outros:
- Criação de Texto: Grandes modelos de linguagem podem gerar conteúdo de texto coerente, lógico e criativo, incluindo histórias, poemas, artigos, etc.
- Diálogo e perguntas e respostas: os modelos podem responder a perguntas feitas por usuários, fornecer respostas significativas e relevantes e até mesmo demonstrar um grau de raciocínio e bom senso.
- Tradução de idiomas: O modelo pode realizar tradução automática, convertendo texto em um idioma para texto em outro idioma, mantendo a maior precisão semântica e gramatical possível.
- Resumo e geração de texto: O modelo pode gerar um resumo ou visão geral correspondente com base em uma determinada entrada de texto, extraindo as informações principais e expressando-as.
- Compreensão e inferência semântica: modelos de linguagem grandes podem entender o significado de sentenças, inferir contexto e informações implícitas e exibir fortes recursos de compreensão semântica em tarefas de processamento de texto.
Esse comportamento e capacidade emergentes são o resultado do aprendizado do modelo a partir de grandes quantidades de dados de texto e da auto-otimização. Durante o processo de treinamento do modelo, o modelo forma gradualmente a capacidade de compreender e gerar linguagem, capturando as leis estatísticas da linguagem, informações contextuais e relações semânticas, exibindo assim propriedades emergentes surpreendentes.
No entanto, deve-se notar que, embora grandes modelos de linguagem possam exibir recursos impressionantes, eles ainda apresentam algumas limitações, como exemplos de ataques adversários, problemas de proteção de privacidade, etc. Portanto, ao usar modelos de linguagem grandes, validação e controles adequados são necessários para garantir a precisão, confiabilidade e adequação de suas saídas.
6. Ajuste fino
O ajuste fino refere-se ao processo de ajuste e otimização do modelo para se adaptar a tarefas específicas com base no estágio de pré-treinamento.
No processamento de linguagem natural, o ajuste fino geralmente se refere a ajustes feitos em modelos de linguagem de grande escala pré-treinados (como BERT, GPT, etc.). Esses modelos são pré-treinados em dados de texto em grande escala, aprendendo representação de linguagem avançada e recursos de compreensão de linguagem. Em seguida, ajuste as tarefas específicas para adaptar o modelo aos requisitos e dados específicos da tarefa.
O processo de ajuste fino geralmente inclui as seguintes etapas:
- Congelar os parâmetros do modelo pré-treinado: Primeiro, os parâmetros do modelo pré-treinado são fixos e não serão atualizados. Isso é feito para preservar o conhecimento e as representações que o modelo pré-treinado já aprendeu.
- Adicionando camadas específicas da tarefa: dependendo da tarefa, algumas camadas ou estruturas específicas da tarefa são adicionadas para conectar o modelo a uma tarefa específica. Essas camadas geralmente incluem camadas totalmente conectadas, camadas convolucionais, camadas de pool, etc., para corresponder à saída do modelo com rótulos ou destinos relacionados à tarefa.
- Treinamento em camadas específicas de tarefas: atualize os parâmetros das camadas específicas de tarefas adicionadas treinando em conjuntos de dados específicos de tarefas. Durante esse processo, os parâmetros do modelo pré-treinado permanecem inalterados.
- Ajuste fino global: se o conjunto de dados da tarefa for relativamente pequeno ou tiver uma grande diferença em relação ao conjunto de dados pré-treinamento, você poderá optar por ajustar todo o modelo. Neste caso, além das camadas específicas da tarefa, outros parâmetros do modelo pré-treinado também são treinados e atualizados de acordo com os dados da tarefa.
Através do ajuste fino, o modelo pode combinar o conhecimento geral e a capacidade de representação de modelos pré-treinados com os requisitos de tarefas específicas, de modo a melhor se adaptar e resolver tarefas específicas. O processo de ajuste fino aproveita as ricas representações de linguagem aprendidas por modelos pré-treinados em dados de grande escala para obter melhor desempenho em conjuntos de dados de tarefas relativamente pequenos.
Vale a pena notar que o sucesso do ajuste fino depende de fatores como tamanho, qualidade e similaridade de domínio do conjunto de dados da tarefa. Ao mesmo tempo, escolher uma taxa de aprendizado apropriada, algoritmo de otimização e estratégia de ajuste também é um fator chave que precisa ser observado durante o processo de ajuste fino.
No processo de ajuste fino, além de adicionar camadas específicas de tarefas e atualizar parâmetros, os seguintes aspectos precisam ser considerados:
- Partição do conjunto de dados: Divida o conjunto de dados disponível em conjuntos de pré-treinamento, ajuste fino e avaliação. O conjunto de pré-treinamento é usado na fase de pré-treinamento, o conjunto de ajuste fino é usado para ajustar os parâmetros do modelo e o conjunto de avaliação é usado para avaliar o desempenho do modelo. Certifique-se de que os conjuntos de ajuste fino e avaliação sejam representativos das características e distribuição de dados da tarefa de destino.
- Inicialização de parâmetros: No estágio de ajuste fino, os parâmetros do modelo pré-treinado geralmente são congelados e apenas os parâmetros das camadas específicas da tarefa precisam ser inicializados. A inicialização de parâmetro pode ser feita usando inicialização aleatória, inicialização de parâmetro de modelo pré-treinado ou outras heurísticas.
- Ajuste da taxa de aprendizado: No processo de ajuste fino, a configuração da taxa de aprendizado é crucial para o desempenho do modelo. Uma estratégia de decaimento da taxa de aprendizado pode ser adotada, como reduzir gradualmente a taxa de aprendizado ou ajustar a taxa de aprendizado de acordo com o desempenho do conjunto de validação, para equilibrar a velocidade de convergência e o desempenho do modelo durante o processo de ajuste fino.
- Atualização de gradiente: algoritmos de otimização comuns, como descida de gradiente estocástico (SGD) ou algoritmos de otimização adaptáveis (como Adam), podem ser usados para ajuste fino. O algoritmo de otimização apropriado pode ser selecionado de acordo com as características da tarefa e a escala do conjunto de dados.
- Tratamento de ajuste excessivo: quando o conjunto de dados de ajuste fino é pequeno ou a complexidade do modelo é alta, ele pode enfrentar o problema de ajuste excessivo. Técnicas de regularização, como decaimento ou abandono de peso, podem ser empregadas para aliviar o overfitting e melhorar a capacidade de generalização do modelo.
- Número de iterações: o número de iterações para ajuste fino depende da complexidade da tarefa, do tamanho do conjunto de dados e da disponibilidade de recursos de computação. Várias rodadas de ajuste fino podem ser executadas, observando o desempenho do modelo no conjunto de validação e escolhendo as condições de parada apropriadas.
- Seleção de modelo: Durante o processo de ajuste fino, diferentes arquiteturas de modelo, camadas e configurações de hiperparâmetros podem ser experimentadas, e a seleção pode ser feita por meio do desempenho do conjunto de validação. Às vezes, técnicas como ajuste de modelo e integração de modelo podem ser necessárias para melhorar ainda mais os resultados do ajuste fino.
O objetivo do ajuste fino é fazer com que o modelo pré-treinado se adapte melhor à tarefa alvo e melhorar o desempenho do modelo e a capacidade de generalização por meio de ajustes e treinamento em tarefas específicas. O ajuste fino utiliza o conhecimento geral e a capacidade de representação aprendida pelo modelo pré-treinado em dados de grande escala e, ao mesmo tempo, ajusta o modelo para um estado adequado para uma tarefa específica por meio do treinamento em conjuntos de dados específicos da tarefa. Dessa forma, o modelo pode funcionar bem em conjuntos de dados relativamente pequenos e fornecer previsões e resultados úteis.
7. Aprendizagem por Reforço de Feedback Humano (Aprendizado por Reforço de Feedback Humano, RLHF)
É um método de aprendizado por reforço no qual humanos fornecem feedback sobre o comportamento do agente para acelerar o processo de aprendizado ou orientar o agente a obter melhor desempenho em uma tarefa específica.
No aprendizado por reforço tradicional, o agente aprende interagindo com o ambiente e ajusta sua estratégia de comportamento por meio de tentativa e erro e feedback de sinais de recompensa. No entanto, esse aprendizado interativo pode exigir um grande número de amostras de treinamento e tempo para atingir um nível de desempenho desejado.
No aprendizado de reforço por feedback humano, os humanos fornecem informações adicionais para guiar o aprendizado do agente. Esse feedback pode ser variado, como:
- Sinais de recompensa: os humanos podem fornecer sinais de recompensa ou punição para diferentes comportamentos de um agente para orientar suas escolhas de comportamento.
- Amostras de demonstração: humanos podem mostrar ou demonstrar amostras de comportamento plausíveis para o agente observar e aprender para ajudar a acelerar o processo de aprendizado.
- Feedback de otimização: os humanos podem fornecer sugestões ou instruções de otimização específicas sobre o comportamento do agente para influenciar diretamente a tomada de decisão do agente.
Por meio do feedback humano, o agente pode aprender estratégias de comportamento eficazes mais rapidamente, evitar tentativas e erros desnecessários e se adaptar melhor aos requisitos da tarefa. O aprendizado por reforço com feedback humano pode ser altamente útil em aplicações práticas, especialmente quando as tarefas são complexas ou as amostras são escassas.
Os métodos específicos de implementação do aprendizado por reforço de feedback humano incluem aprendizado por imitação (Aprendizado por Imitação), aprendizado por reforço inverso (Aprendizado por Reforço Inverso) e aprendizado interativo (Aprendizado Interativo). Dependendo da tarefa, esses métodos combinam feedback humano e aprendizado autônomo do agente de diferentes maneiras para obter melhor desempenho e resultados.
No aprendizado por reforço de feedback humano, existem alguns conceitos e técnicas-chave que merecem uma exploração mais aprofundada:
- Aprendizagem interativa: em alguns casos, o feedback humano pode interagir com o processo de aprendizagem do agente. As decisões do agente podem afetar como o feedback humano é fornecido, criando um processo de aprendizado interativo cíclico. Essa interação pode levar o agente a fazer ajustes mais direcionados e aprender com base no feedback.
- Interpretação de estado e aprendizado de recursos: o feedback humano pode ajudar os agentes a entender diferentes estados e recursos do ambiente. A interpretação e a orientação fornecidas por humanos podem ajudar os agentes a entender melhor o ambiente e os requisitos da tarefa durante o processo de aprendizado, melhorando assim a eficiência e o desempenho do aprendizado.
- Combinado com conhecimento especializado: O feedback humano pode ser combinado com o conhecimento especializado do domínio. Os especialistas podem fornecer regras, orientação heurística ou conhecimento específico do domínio sobre tarefas para auxiliar no processo de aprendizado do agente. Essa combinação pode permitir que o agente alcance um desempenho de nível de especialista mais rapidamente.
- Feedback Contínuo: O feedback humano pode ser não apenas recompensas ou instruções discretas, mas também sinais contínuos. Por exemplo, por meio de manipulação manual ou orientação humana, os humanos podem intervir diretamente no comportamento do agente, fornecendo sinais de feedback contínuo para ajustar a estratégia do agente.
- Métodos de otimização: o aprendizado por reforço de feedback humano pode usar diferentes métodos e algoritmos de otimização. Por exemplo, o aprendizado por reforço inverso pode ser usado para aprender funções de recompensa de amostras de demonstração humana; ou o aprendizado de imitação pode ser usado para aprender diretamente as políticas comportamentais de amostras de demonstração humana.
O aprendizado por reforço de feedback humano é uma tarefa complexa que envolve a interação de agentes com humanos, o design de algoritmos de aprendizado e o uso criterioso do feedback humano. A pesquisa nesta área ainda está evoluindo e visa melhorar a eficiência de aprendizagem, desempenho e confiabilidade dos agentes para que eles possam cooperar e interagir melhor com os seres humanos.
8. Alerta de poucos tiros
O prompt de poucos disparos refere-se à tarefa de processamento de linguagem natural (NLP), dado um número muito pequeno de exemplos ou amostras para orientar o modelo a gerar uma saída relevante. Essa abordagem é útil para modelos que generalizam bem para pequenas quantidades de dados.
Ao usar o prompt de poucos disparos, a capacidade de generalização do modelo pode ser aprimorada fornecendo mais exemplos. Esses exemplos podem ser pares de frases relacionadas ou pares de perguntas e respostas para que o modelo aprenda informações semânticas e contextuais mais amplas.
Por exemplo, suponha que queremos treinar um modelo para uma tarefa de resposta a perguntas, mas temos apenas algumas amostras de respostas a perguntas. Podemos alimentar o modelo com alguns exemplos por meio de um prompt de poucas fotos, que contém perguntas e respostas correspondentes. O modelo usa esses exemplos para aprender a conexão entre perguntas e respostas para que possa fornecer respostas precisas quando confrontado com novas perguntas.
Por exemplo, podemos fornecer o seguinte exemplo de prompt de poucos tiros:
Pergunta: "Quem foi o primeiro presidente dos Estados Unidos?"
Resposta: "George Washington".
Com base neste exemplo, o modelo pode aprender a responder "George Washington" corretamente em perguntas semelhantes. Então, ao se deparar com uma nova pergunta, como "Quem foi o segundo presidente dos Estados Unidos?", o modelo pode tentar inferir que a resposta correta é "John Adams".
Ao fornecer exemplos rápidos, o modelo pode aprender padrões e conhecimentos gerais a partir de dados limitados e realizar raciocínio e generalização ao enfrentar novas tarefas ou situações. Essa abordagem é útil para resolver problemas de escassez de dados ou para se adaptar rapidamente a novas tarefas em domínios específicos.
8.1 Exemplo de geração de etiqueta
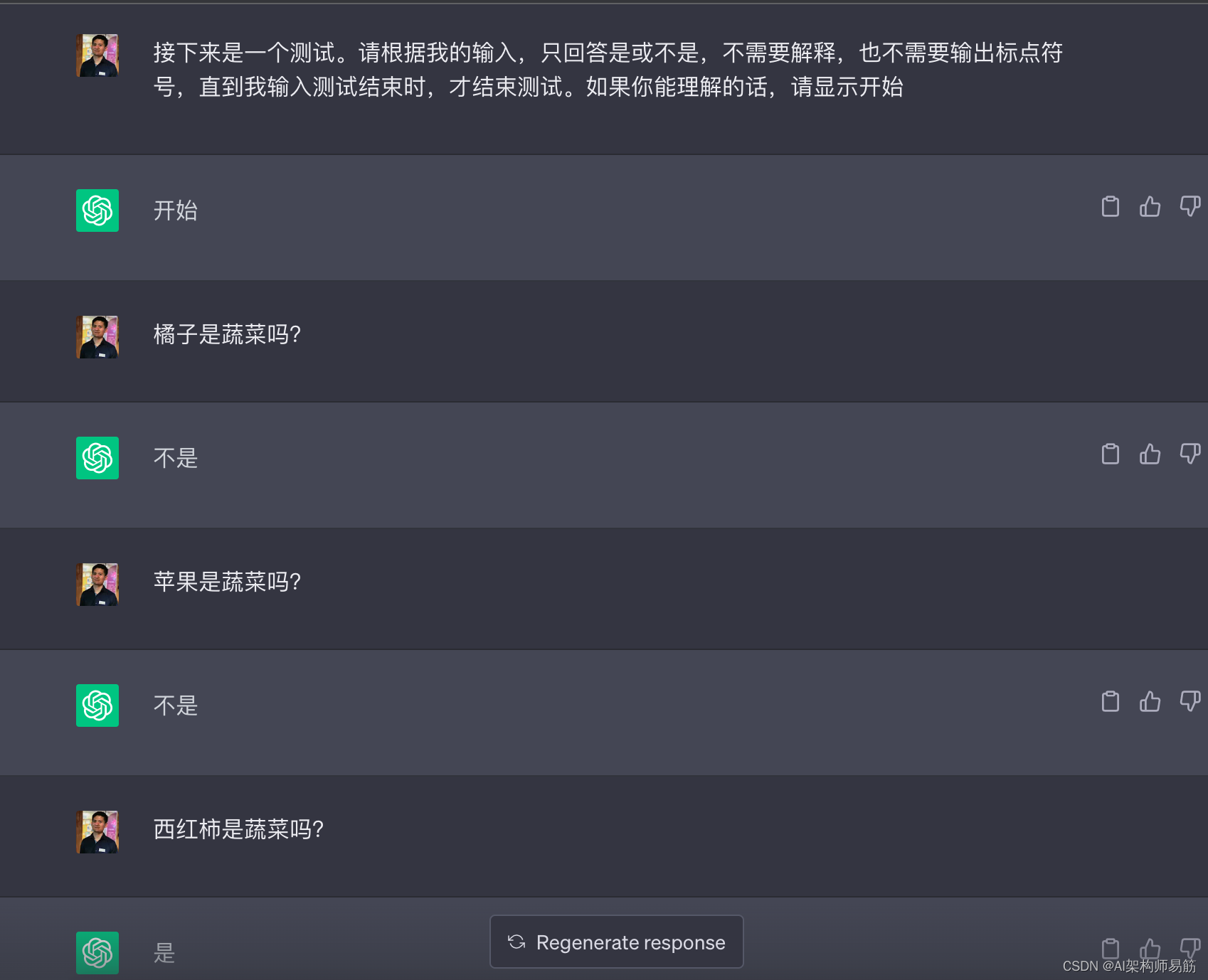
Em seguida é um teste. Responda apenas sim ou não de acordo com minha entrada, nenhuma explicação é necessária e nenhuma pontuação é necessária, e o teste não terminará até o final do meu teste de entrada. Se você pode entender, por favor, mostre o início
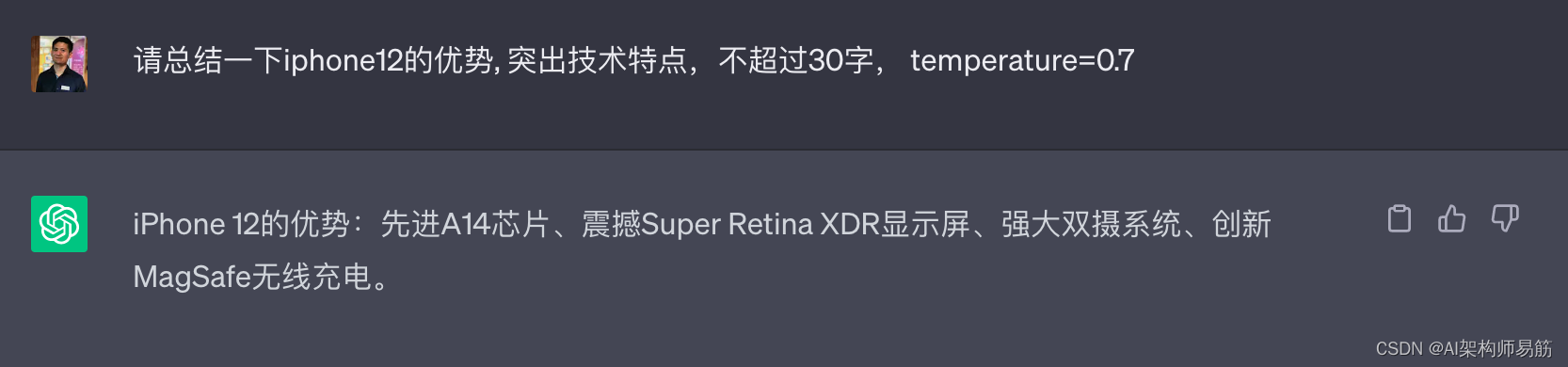
9. Temperatura = 0,7 (recomenda-se que 0~0,7 seja mais preciso, 0 seja preciso, quanto maior, mais criativo)
Resuma as vantagens do iphone12, destaque os recursos técnicos, não mais que 30 palavras, temperatura = 0,7