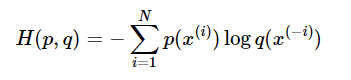Diretório da coluna: pytorch (segmentação de imagem UNet) introdução rápida e combate real - zero, prefácio
pytorch introdução rápida e combate real - 1, preparação de conhecimento (introdução aos elementos)
pytorch introdução rápida e combate real - 2, aprendizado profundo clássico desenvolvimento de rede
pytorch rápido introdução E combate real - três, Unet realiza
introdução rápida de pytorch e combate real - quatro, treinamento e teste de rede
Aprendendo profundamente alguns conceitos
Entropia cruzada, regularização, mapeamento de identidade e degradação. Também sou fã, não tenha medo, tudo bem se funcionar mesmo assim.
O que é gradiente descendente, o que é algoritmo de BP, o que é o gráfico de cálculo, o que é a rede contínua completa, rede convolucional... emmm ok, eu ainda entendo a rede convolucional, então estou indo para o aprendizado profundo.
Se você não entende de convolução, veja isto: O caminho para o aprendizado de máquina três: Rede neural convolucional
Esforce- se para obter a velocidade mais rápida para começar a trabalhar no código, portanto, os seguintes conceitos que ficarei muito confortável depois de entender, um por cerca de cinco minutos, para entender: DL e este site Espere pelo chefe,
se você gosta dos mais detalhados, pode encontrar @刘二大人 em uma determinada estação
0 Machine Learning e Deep Learning
Desenvolvimento de aprendizado de máquina: classificação linear -> perceptron -> descida de gradiente -> rede neural -> algoritmo BP -> rede totalmente conectada de três camadas -> CNN como vetor de suporte SVM
perceptron, árvore de decisão, algoritmo EM, mapa de probabilidade, Naive Bay Estes são todos aprendizado de máquina especial.
Obviamente, o aprendizado profundo também pertence ao aprendizado de máquina. Onde está a diferença?
Redes Neurais Convolucionais!
Em 2012, a AlexNet integrou a classificação e a engenharia de recursos e usou redes neurais convolucionais para esmagar os métodos tradicionais de aprendizado de máquina no campo CV. Como um marco, abriu o prelúdio para o domínio da visão computacional por redes neurais convolucionais e acelerou a aplicação de visão.
1 Conceitos em pré-processamento de dados
1.1 Características dos dados
O exemplo clássico de livro de melancia, a melancia tem várias características que podem ser inseridas na rede (ou cérebro humano) para julgamento.
Eu não sei muito sobre melancia, então mudei.
Se um grupo de cães e um grupo de gatos forem cães amarelos e gatos brancos, selecionar o recurso de cor pode resolver muito bem essa tarefa de classificação, mas é difícil resolver esse problema se você escolher o número de olhos e o número de caudas.
Portanto, bons recursos podem explicar bem o problema.
Temos que selecionar bons recursos e filtrar os ruins.
O exemplo concreto é muito mais complexo.
Referência: Como distinguir recursos úteis
1.2 Padronização de recursos
Há uma série de recursos que não são padrão em instâncias concretas:
Os preços das casas variam de acordo com vários parâmetros (por exemplo centro da cidade, andar, zona, cidade, etc.).
Tome dois parâmetros como exemplo, a distância em km e a área em m2
são cerca de 10 km, e a área é 0 ~ 200, o vão é diferente, a influência é diferente, ou seja, o peso é diferente (mas não refletem a importância), mas após a normalização, o peso pode refletir melhor a importância.
Duas maneiras:

e! Algumas feições são quantificadas, como distância e área.
Mas ainda existem alguns recursos como "a cidade onde você está localizado" que não são quantificados, então você pode encontrar uma maneira de quantificar os recursos para resolver o problema: como classificar cidades.
Referência: Por que padronizar recursos
1.3 Processamento de dados não balanceados
Exemplo típico: 99 " fotos " "exemplos" de gatos ("fotos" podem levar a problemas de reconhecimento, substituídos por "exemplos" aqui) e um exemplo de foto de um cachorro como conjunto de treinamento. (Esses exemplos são descrições de recursos, que podem ser o peso da altura da cor ou a distribuição de valores de pixel na imagem) Contanto
que a máquina adivinhe todos os gatos, a taxa de precisão pode chegar a 99%.
problema de classificação de cães e gatos, a classificação desta máquina A taxa de precisão de classificação do método é de 100% para gatos, mas 0% para cães. Portanto,
na verdade, esta máquina não pode resolver o problema de classificação de cães e gatos
[simples classificação, não reconhecimento]
• 也就是说这个数据集不能解决这个问题,那么就要对数据集进行处理。
1. Encontre um conjunto de dados melhor
2. Duplique o exemplo do cachorro, torne-o igual
3. Reduza o exemplo do gato, torne-o igual
Para outros métodos, consulte o seguinte artigo: Lidando com dados não balanceados
2 Conceitos em design de rede
2.1 Função de excitação
Não sei muito sobre isso, então vamos falar brevemente sobre minha opinião:
em primeiro lugar, nem todo recurso comprimido pode durar para sempre. No processo de trabalho da rede neural, existem muitas combinações de recursos que precisam ser eliminadas. A eliminação mecanismo é a função de ativação. Portanto, a função de ativação retransforma o resultado para determinar se ele atende ao padrão de ativação.
Em termos leigos, se esta estrada pode ir, se for 0, não pode ir (matar neurônios), se não for 0, pode ir (ativar neurônios).
Observações anteriores:
将线性函数变成非线性来解决非线性问题。也就是对y再进行一次变换。
但这些激励函数必须可微分。因为多层网络的梯度传导中,需要对微分计算梯度下降方向。
对于浅层网络,激励函数选择没有那么大要求。
但是当网络层数比较深的时候,激励函数选择不甚会导致梯度消失以及梯度下降问题。
也和梯度传导过程中的微分有关。
浅层的CNN可以用relu,浅层循环网络可以用relu或者tanh
Emmm é apenas o meu sentimento, referência específica:
Por que você precisa de uma função de incentivo
Funções de incentivo comumente usadas
2.2 Optimizer O otimizador acelera o treinamento da rede neural (como SGD)
Referência: Otimizadores aceleram o treinamento de rede neural
2,3 camada BN
Esta seção apresenta brevemente, seguida de uma introdução detalhada no GoogleNet-V2
Batch normalization (BN: Batch Normalization: resolva o problema de que a distribuição de dados da camada intermediária muda durante o processo de treinamento, de modo a evitar que o gradiente desapareça ou exploda e acelere a velocidade de treinamento). Tomando a função de ativação tanh como exemplo , apenas os dados de treinamento na
parte intermediária do tempo são dados relativamente mais eficazes e, quando distribuídos em ambos os lados, a influência no processo de treinamento será comparada. . . "Fixo" (não muda muito com as mudanças)
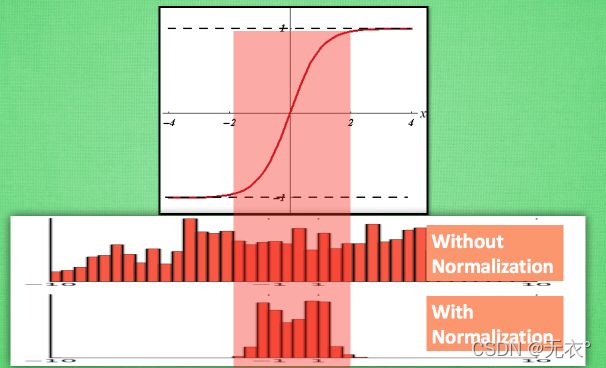
, então podemos migrá-lo sem afetar a distribuição geral dos dados, ou seja, padronizar e transformar os dados em um bom intervalo mantendo relativamente a distribuição, para melhor " influenciar" o treinamento.
Referência: Por que explicação detalhada da camada BN
de normalização em lote
2.4 Desenvolvimento e seleção de redes clássicas
Porque se a rede for dividida em módulos, a estrutura de quatro níveis é muito grande e o comprimento em si é muito longo, por isso é inconveniente escrever e ler. Aqui eu escolho diretamente a rede Unet para processamento de imagens médicas.
Abra um único artigo para apresentar: introdução rápida ao pytorch e combate real - 2. Desenvolvimento de rede clássica de aprendizado profundo
3. Conceitos na função Perda
Não fique muito preso nisso, apenas olhe para ele casualmente, ou não olhe para ele. Nessa fase, é bom simplesmente entender, de qualquer forma, é um erro.
Funções de perda comuns
3.1 Regularização L1 L2
3.2 Erro Quadrático Médio
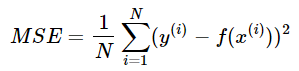
3.3 Função Custo de Entropia Cruzada (Entrada Cruzada)