
prefácio
Há mais de três anos, no artigo "Falando sobre compreensão de vídeo" [1], o autor resumiu brevemente sua compreensão da compreensão de vídeo. Felizmente, ele foi reconhecido por seus amigos. Ser reconhecido pelos leitores é a conquista de maior orgulho do autor. . Agora, parece que há muitas falhas e pontos de vista limitados no artigo, especialmente a popularidade dos modelos multimodais nos últimos anos, o que tornou muitas tecnologias revolucionárias na direção da compreensão do vídeo. Por que você precisa da fusão multimodal? [ 2] Tentei corrigir [1], mas limitado ao tempo do autor e ao nível de entendimento da época, nenhuma discussão foi realizada. Este artigo espera resumir brevemente os modelos multimodais nos últimos anos e discutir brevemente as possibilidades de aplicação desses modelos em cenários de recuperação de mídia avançada, como pesquisa de imagem e pesquisa de vídeo. O autor não é profundo na indústria e o conhecimento é superficial. Se houver algum erro, por favor, perdoe-me e entre em contato comigo. Este artigo está em conformidade com o contrato de direitos autorais CC 4.0 BY-SA . Para reimpressão, entre em contato com o autor e indique a fonte, obrigado .
Introdução: A Estrutura Organizacional do Papel
O tamanho deste artigo é longo. Para se adaptar a leitores com diferentes experiências de conhecimento, o autor fornece um guia para este artigo. Leitores com experiências de conhecimento relevantes são convidados a pular para os capítulos de que precisam.
- "0x01 Video and Picture: Information Dispersed in Time and Space" apresenta principalmente os símbolos visuais de imagens e vídeos e apresenta brevemente a aplicação do alinhamento semântico texto-visual e fusão semântica na recuperação de informações.
- "0x02 Single-modal video/picture feature expression" apresenta principalmente o método de aprendizagem de representação monomodal de imagens e vídeos e, finalmente, fornece uma breve visão geral dos métodos de representação de texto. A modelagem unimodal é a base da modelagem multimodal.Muitos métodos de modelagem cross-modal e multimodal foram profundamente influenciados pela modelagem unimodal, então o autor acha necessário introduzir este capítulo.
- "0x03 Use of Semantic Labels: Towards Multimodality" é usado principalmente como uma introdução para introduzir algumas correlações e diferenças entre multimodalidade e modalidade única. Este capítulo serve como uma ponte entre a modelagem unimodal mencionada acima e a seguinte multimodal modelagem. .
- "0x04 Antes do CLIP: Modelagem de Fusão de Informações Multimodais" Esta parte começa oficialmente a apresentar o modelo multimodal Este capítulo apresenta o modelo de fusão semântica antes do CLIP.
- "0x05 Depois do CLIP: Contraste de Informação Multimodal e Modelagem de Fusão" Esta parte apresenta o alinhamento semântico e os modelos de fusão semântica depois do CLIP. A maioria desses modelos são algumas melhorias para os defeitos do CLIP.
- "0x06 End of Journey" é um resumo deste artigo.
0x01 Vídeos e fotos: informações dispersas no tempo e no espaço
Os seres humanos são animais visuais, e o que você vê é o que obtém é sempre o desejo mais primitivo dos seres humanos. Em comparação com informações de texto que exigem que as pessoas entendam, pensem profundamente e usem a imaginação, as informações de mídia avançada, como vídeos e fotos, têm uma vantagem absoluta na eficiência da transmissão de informações. Se a informação do texto vem dos significados abstratos do consenso da comunidade humana carregados por cada símbolo , e as infinitas mudanças produzidas pela livre combinação de significados abstratos, então que "símbolos visuais" carregam a informação de vídeos e fotos?
elementos visuais da imagem
Os elementos básicos da maioria das imagens são pixels (Pixel) 2 , e os pixels formam um bloco de imagem (Patch) em pedaços. O assunto envolvido em fotos é amplamente distribuído em todas as esferas da vida. Conforme mostrado na Fig. 1.1, imagens biológicas, fotos de sensoriamento remoto, emoticons de rede, fotos naturais carregadas por usuários, selfies, imagens infravermelhas etc. podem ser consideradas como certos tipos de imagem. Este artigo se concentra mais nas imagens naturais carregadas pelos usuários, que serão doravante referidas como imagens gerais.

自然图片含有复杂的视觉语义,在文章[6]中,作者认为常见的具有区分度(Distinguished)的视觉语义元素有:实体(Entity),属性(Attribution),关系(Relation)等,如Fig 1.2 (a-c) 所示,这些视觉元素偏具象,且是局部语义,比如实体中的大金毛,大橘猫,属性里面的紫色,蓝色,黑色,关系里面的骑着,修理,倒立等等。有些场景中需要表示整个图片的全局视觉语义,需要组合这些局部语义形成全局语义,比如Fig 1.2中的(d),为了识别出图片中所带有的“抑郁,悲伤”的抽象语义,需要提取出图片整体色调,女生趴着,蜡烛熄灭等元素,为了简便,笔者将这种全局语义简称为视觉氛围(Vision Atmosphere),这种抽象语义的建模,笔者认为会类似于后文提到的弱视觉语义数据建模,且按下不表。


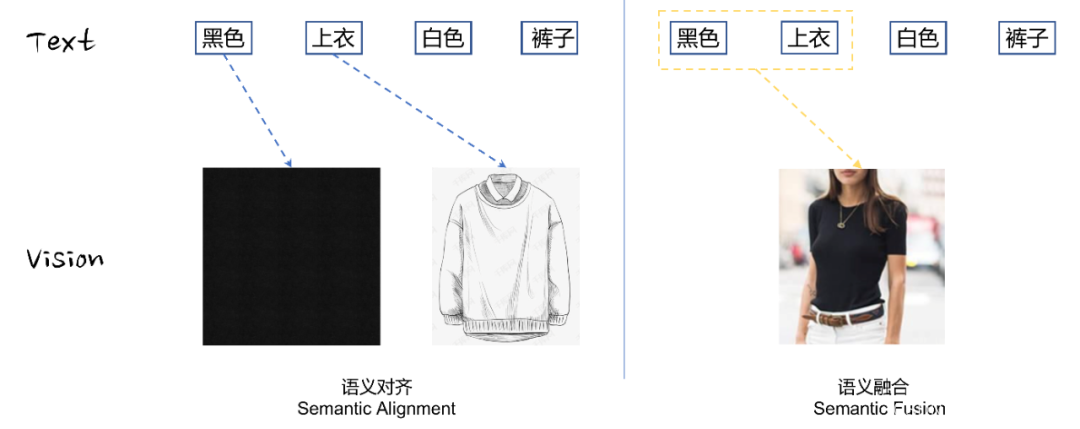
É claro que esses elementos visuais podem ser apenas a ponta do iceberg. Os pintores podem descrever emoções com pinceladas, e os fotógrafos ainda podem contar histórias com luz e sombra. A semântica concreta das imagens costuma ser a semântica subjacente, e a semântica abstrata é difícil de entender modelo, portanto, não será o foco especial deste artigo (Mesmo semântica visual fraca pode estar relacionada à semântica abstrata). Portanto, neste artigo, o autor acredita que a semântica concreta da maioria das imagens é transmitida por meio de símbolos visuais, como entidades, atributos e relacionamentos, e esses símbolos visuais podem ser mais ou menos associados a informações de texto. Essa ponte semântica estabelecida entre texto e visão geralmente pode ser dividida em dois estágios, alinhamento semântico e fusão semântica , conforme mostrado na Figura 1.4.
- Alinhamento semântico: refere-se ao mapeamento de entidades visuais e descrições de atributos em texto para elementos visuais correspondentes. A relação de mapeamento gráfico-texto aqui pode ser chamada de semântica visual básica.
- Fusão semântica: com base no alinhamento semântico, a semântica visual básica é fundida e combinada para formar uma semântica visual composta complexa. A semântica visual composta inclui relações visuais, atmosferas visuais mais abstratas, etc.
Não é difícil constatar que o texto tem semântica compacta e alta densidade de informação, enquanto as imagens costumam ter muita redundância de informação e baixa densidade de informação sob semântica semelhante. Portanto, muitos estudos estão pensando em como comprimir a quantidade de informação da imagem e efetivamente extrair e codificar suas informações ocultas. Semântica, continuaremos a discutir isso mais tarde.
Elementos visuais do vídeo
O vídeo não é uma simples expansão de imagens na dimensão do tempo. A correlação temporal dos elementos visuais das imagens entre diferentes quadros traz símbolos visuais mais complexos e mutáveis. Mesmo que todos os símbolos visuais dos quadros de vídeo sejam reconhecidos, seu tempo A simples conexão em o vídeo não pode representar totalmente os símbolos visuais do vídeo.
视频的视觉符号最典型的比如动作,如Fig 1.5 (a)所示,动作序列通常是同个实体特定模式的行为,比如弯腰、捡起、起身,在以视频片段为单位的时候就能视为一整个视觉符号。动作通常是一个连续的线性符号,而视频的多帧特性意味着其存在非线性的帧间关联,如[9,10]中所介绍的通过组织视频非线性流进行动作理解的工作。非线性视频的特性在互联网视频中更为常见,如Fig 1.5 (b,c) 所示,互联网视频受到视频创作者的剪辑,视频通常都会出现镜头、场景的切换,事件的因果关系因此作为视觉符号存在于视频的非线性关系中。通常来说,视频的组成可以层次化地分为以下四部分[10],帧、镜头、事件乃至整个视频都可以视为视频的视觉元素。
帧(Frame) --> 镜头(Shot) --> 事件(Event) --> 视频(Video)
因此,对于视频的视觉元素挖掘,会比图片的视觉元素挖掘复杂很多,有些挖掘方法甚至和视觉本身无关,比如识别视频的OCR信息。在实际应用中,我们暂时不期望能对视频的视觉符号进行深入挖掘,认为其只需要挖掘出其中实体、属性、关系等基础视觉概念,顶多能延伸出一些简单的动作、场景视觉概念、简单事件的视觉概念等。

语义对齐/融合与信息检索
正如笔者在之前文章[25-27]中所谈到的,信息检索中最重要的一块就是相关性(Relevance),可以说相关性决定了整个搜索系统的基础体验好坏与否。在典型的搜索系统中,相关性由文本相关性进行建模,经典的有BM25、TF-IDF等基于词频的描述,在深度学习流行后,渐渐落地了各种端到端的语义相关性建模,如BERT、ERNIE等。这类型模型对相关性的建模是基于字词文本的语义匹配,如Fig 1.6(a)所示,苹果有两种常见语义,分别是电子产品和食物,Fig 1.6(b)展示了其他文本相关性的例子。
0x02 Expressão de recurso de vídeo/imagem de modo único
正如前言所说,笔者曾在[1]中对视频理解进行过讨论,彼时认为动作理解是视频理解的核心任务,而这两年的工作经验告诉我,这个结论是有所偏颇的。首先,采用动作理解的前提是以人为中心的视频内容理解,利用动作理解学习出的视频视觉符号大多集中在人体动作,而对视频中出现的视觉实体、属性、关系等感知能力很弱。我们之前的讨论告诉我们,互联网视频为代表的通用视频视觉信息复杂多变,视频内容不可能都以人为中心,事实上我们线上遇到的视频大多都不可能以人为中心。其次,即便遇到类似直播,知识盘点类,解说类的以人为中心视频,其视频的主要语义也不可能是出镜人物的动作,而是人物的解说内容,此时反而OCR、ASR等信息更为关键。动作理解类的应用主要还是集中在toB类的厂商中,比如摄像头监控,无人机监控,机器人应用等,对于互联网视频而言,采用动作理解技术去理解整个视频的视觉信息是远远不够的,我们更希望能对视频中的视觉实体、属性、关系等视觉符号进行识别。
之前我们在[1]中也谈到过,在传统的动作识别中需要利用大量的动作标签进行视频表征学习,而动作标签往往需要人工标注,这是昂贵且耗时的,因此在[1]的末尾也引出了一些自监督学习的方式去学习动作视频表征。这些自监督方法需要人工去设计各种类型的pretext任务,比如jigsaw puzzle [30],colorization [31],image rotation [32]等,这些pretext任务通常是启发式的,很难保证其跨数据集的泛化性,换句话说就是不够通用。对于一般的通用视频/图片来说,则有其他更高效的自监督学习方法。
图片表征
SimCLR
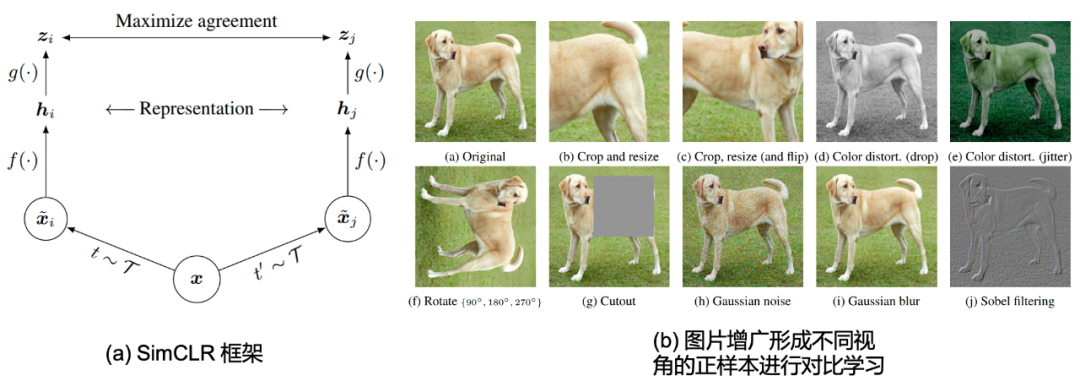
O que introduzimos no início é o famoso SimCLR [28] do Sr. Hinton. Esse método usa aumento de imagem (aumento de imagem) para construir pares de pares de imagens positivas e, ao mesmo tempo, trata outras imagens como amostras negativas. Esse método pode ser usado em Sob a premissa de não usar rótulos de imagem, a aprendizagem auto-supervisionada da representação da imagem é realizada. Conforme mostrado na Figura 2.1(a), onde f ( ⋅ ) f(\cdot)f ( ⋅ ) é um codificador de imagem, por exemplo, ResNet-50 é usado neste trabalho. g ( ⋅ ) g(\cdot)g ( ⋅ ) representa a função de mapeamento que mapeia a representação (representation) para o espaço semântico (Semantic Space), que normalmente pode ser representado pelo módulo MLP. Por exemplo, este trabalho usa zi = g ( hi ) = W 2 σ (W 1 hi ) z_i = g(\mathbf{h}_i) = W_2 \sigma(W_1\mathbf{h}_i)zeu=g ( heu)=C2s ( W1heu) , ondeσ ( ⋅ ) \sigma(\cdot)σ ( ⋅ ) é a função de ativação ReLU. Et ∼ T t\sim \mathcal{T}t∼T和t ′ ∼ T t^{\prime} \sim \mathcal{T}t′∼T significa usar o mesmo método de transformação de imagemT \mathcal{T}As duas amostrasgeradas por T , sob a transformação de imagem apropriada, as imagens têm invariância de rótulo (invariância de rótulo de instância), podemos considerá-las como perspectivas diferentes da imagem original, portanto, essas duas amostras de imagem podem ser consideradas como uma amostra positiva par. No tamanho do lote fornecido éNNNo caso de N , 2 N 2Npode ser gerado por aumento de imagem2 N imagens, onde cada amostra tem uma amostra positiva,2 ( N − 1 ) 2(N-1)2 ( N−1 ) Amostras negativas. A transformação da imagem neste artigo é mostrada na Fig. 2.1 (b), principalmente corte, inversão, processamento de espaço de pixel, etc.
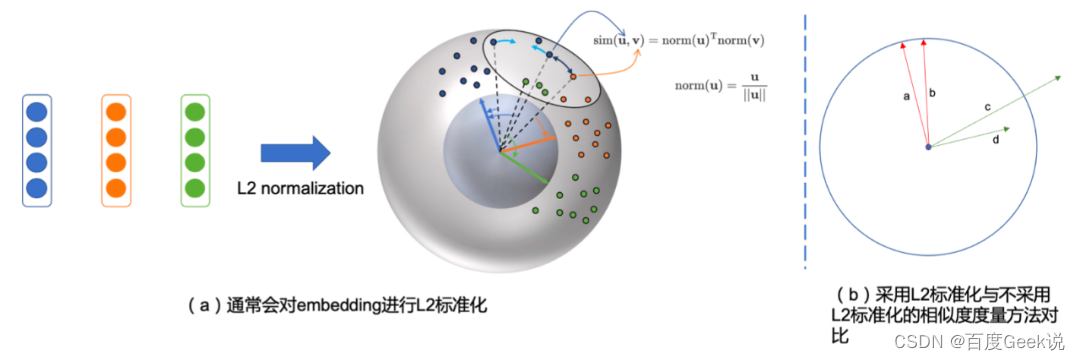
通过采用带温度系数的交叉熵损失作为对比损失进行建模(该损失函数被称之为NT-Xent loss4),如公式(2-1)所示,其中的 s i m ( u , v ) = u T v / ∣ ∣ u ∣ ∣ ∣ ∣ v ∣ ∣ \mathrm{sim}(\mathbf{u}, \mathbf{v})=\mathbf{u}^{\mathrm{T}} \mathbf{v} / ||\mathbf{u}|| ||\mathbf{v}|| sim(u,v)=uTv/∣∣u∣∣∣∣v∣∣表示了余弦相似度度量。不妨将余弦相似度拆开,视为对 u , v \mathbf{u}, \mathbf{v} u,v进行L2标准化(L2 normalization)后进行点乘进行相似度度量,在这个视角中,我们会发现得到的表征都在一个高维球面上,如Fig 2.2所示。公式(2-1)的 τ \tau τ是温度系数,而 1 [ k ≠ i ] \mathbb{1}_{[k \neq i]} 1[k=i]是指示函数,表示仅在 k ≠ i k \neq i k=i的情况下为1,而 < i , j > <i,j> <i,j>是一对正样本对。可以看出公式(2-1)的分母部分是正样本打分加上所有的负样本打分,而分子部分则是正样本打分。从这个角度上看,当batch size越大的时候,产生的负样本数量就越多,正负样本的对比会更为充分,更能学习出具有区分度的特征。
L ( i , j ) = − log exp ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( s i m ( z i , z k ) / τ ) (2-1) \mathcal{L}(i,j) = -\log \dfrac{\exp(\mathrm{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]}\exp(\mathrm{sim}(z_i, z_k)/\tau)} \tag{2-1} L(i,j)=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)(2-1)
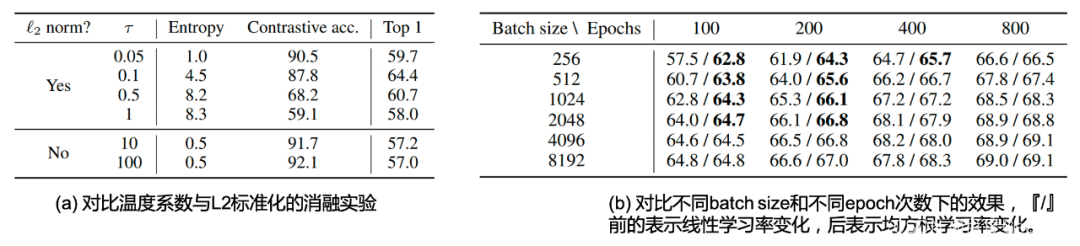
该工作的消融实验对图片变换的组合,温度系数,batch size大小,训练epoch数量,特征表达位置的效果等进行了充分的探索,其试验部分值得诸位读者翻阅原文细看,本博文仅作抛砖引玉之功用,简单对其中笔者认为重要的结论和实验进行介绍。温度系数对于对比学习实在重要,正如笔者在[29]中讨论的,温度系数的大小控制着整个任务的学习难度。在本文也有着对应的消融实验,如Table 2.1 (a)所示,我们发现在采用了L2标准化的情况下,温度系数分别选取{0.05, 0.1, 0.5, 1}情况下,其训练的对比准确率(Contrastive acc.)依次下降,意味着温度系数越大,其对比学习任务难度越大。然而其泛化性能如最后一列所示,在 τ = 0.1 \tau = 0.1 τ=0.1的情况下取得最优,这意味着为了取得最好的表征效果,需要细致地调整对比损失的温度系数。此处对于温度系数的结论和博文[29]的是一致的,即是
加大温度系数将增大对比任务的难度,会尝试将其中的难样本也区分正确;而减小温度系数将减小对比任务的难度,让任务收敛得更好。
区别仅在于在CLIP等工作中,温度系数通常是可学习的(Learnable temperature),而在SimCLR中是固定的温度系数,这并不是本章的重点。同时,我们能看到,采用L2标准化和不采用L2标准化同样会带来明显的性能差距,不采用L2标准化会带来更高的对比训练表现,然而其表征能力都不及采用了L2标准化的结果。这一点也比较容易理解,如Fig 2.2 (b)所示,采用了L2标准化后,如a和b,每个embedding的模都是1,也就是说在模这个维度不存在任何区分度,只能通过embedding的其他更具有区分度的信息进行判断语义。而不采用L2标准化,如c和d,则在训练中不同embedding的模都可能不同,模型会尝试通过模大小这个维度进行区分正负样本,而忽略了embedding本身的语义信息。这很容易导致在训练时期易于收敛,但学习出的表征较差。
Voltando à nossa discussão sobre o experimento de ablação, o autor também explorou o impacto do tamanho do lote durante o treinamento. Intuitivamente, usar um tamanho de lote maior pode gerar mais amostras negativas na mesma iteração, o que pode ser mais adequado. Aprenda por comparação. E aumentar o tempo de treinamento, ou seja, aumentar a época de treinamento também pode ver mais amostras negativas em mais tempo; portanto, o efeito deve ser semelhante ao aumento do tamanho do lote. Conforme mostrado na Tabela 2.1 (b), no caso de uma época fixa, o efeito de usar um tamanho de lote maior é melhor do que o menor. No caso do mesmo tamanho de lote, quanto maior a época, melhor o efeito. Observe que antes do "/" é o escalonamento da taxa de aprendizado linear e depois do "/" é o resultado do uso do escalonamento da taxa de aprendizado do quadrado médio da raiz. O uso do escalonamento da taxa de aprendizagem quadrática média é benéfico para o treinamento com tamanho de lote pequeno e poucas épocas. Não é difícil descobrir que a desvantagem de treinamento causada por lotes muito pequenos pode ser compensada por um período de treinamento mais longo. O autor também tentou usar um tamanho de lote maior e um período de treinamento mais longo. ainda fornecem melhoria contínua de desempenho.
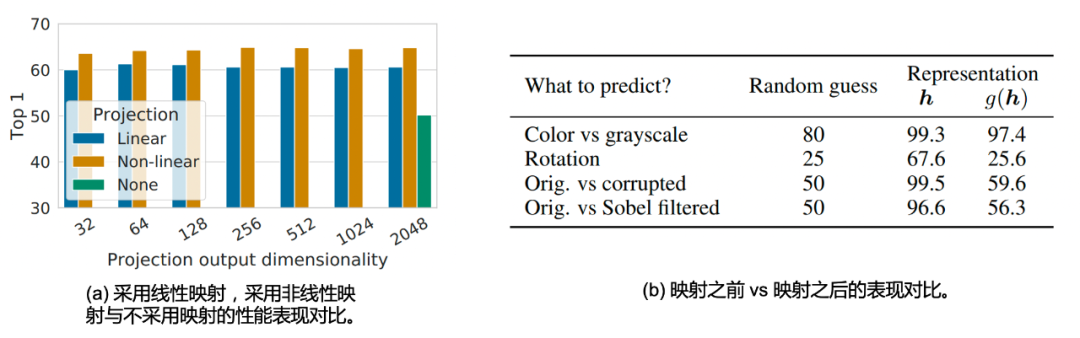
Os autores também estudam diferentes mapeamentos g ( ⋅ ) g(\cdot)A comparação do método g ( ⋅ ) para o desempenho da representação, conforme mostrado na Fig. 2.4 (a), não importa em qual dimensão de saída (32,64,...,1024,2048), o mapeamento não linear ( ou seja, função ReLU)g ( ⋅ ) g(\cdot)g ( ⋅ ) sempre supera mapeamentos lineares (3,0%) e não usar nenhuma função de mapeamento sempre tem desempenho pior do que usar mapeamentos (10,0%). Ao mesmo tempo, o autor também chegou a uma conclusão interessante, usando a representaçãohhh e a representação g após usar o mapeamento( h ) g(h)A comparação de g ( h ) é que o primeiro é melhor do que o segundo. Essa discussão específica não é muito relevante para o tópico deste artigo, portanto, os leitores interessados devem ir para o artigo.
O trabalho de abertura - SimCLR demorou muito para ser apresentado, pois tem significado norteador para a modelagem e projeto do modelo multimodal baseado em aprendizado contrastivo. Em suma, a partir da discussão acima, podemos ver que a atual modelagem de representação auto-supervisionada baseada na aprendizagem contrastiva tem os seguintes pontos para prestar atenção:
- Modelos grandes são importantes para o aprendizado contrastivo auto-supervisionado
- Tamanho de lote grande e período de treinamento mais longo são importantes
- É importante usar um cabeçote de mapeamento não linear
- O coeficiente de temperatura adequado é importante
- É importante adotar a normalização L2
Descobriremos que os seguintes modelos, sejam eles representações unimodais ou intermodais, têm mais ou menos a sombra dessas ideias.
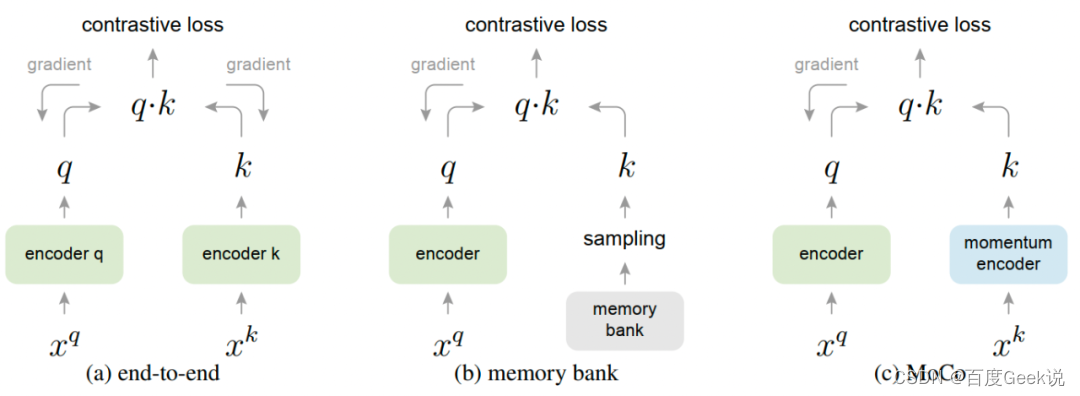
Banco de Memória e MoCo
A partir dos experimentos do SimCLR, aumentar o tamanho do lote pode alcançar melhores resultados em menos ciclos de treinamento, mas aumentar o tamanho do lote geralmente requer mais recursos de GPU. Considerando que a essência de aumentar o tamanho do lote é aumentar o número de amostras negativas que podem ser vistas em uma iteração, pode-se considerar manter uma fila virtual de amostras negativas e usar amostras negativas históricas para aprendizado comparativo para atingir o tamanho do lote. de desacoplar o tamanho e número de amostras negativas, e banco de memória [34] é um trabalho que adota uma fila de amostras negativas.
Antes de começar a discutir o trabalho do banco de memória em si, vamos tentar olhar para o aprendizado comparativo de outro ângulo. consulta, enquanto correspondência de amostra positiva Significa que a consulta corresponde à chave correta e a correspondência de amostra negativa significa que a chave errada é correspondida. Os codificadores podem ser divididos em codificadores de consulta e codificadores de chave. Os codificadores QK podem ser os mesmos na modelagem do mesmo modal, mas geralmente diferentes na modelagem cross-modal. Não é difícil ver que, para que a Consulta corresponda corretamente à Chave no dicionário, os estados do codificador da Consulta e do codificador da Chave precisam ser consistentes. Por que o estado é consistente? De um modo geral, o codificador de consulta e o codificador de chave recebem atualizações influenciadas pelo gradiente de forma síncrona durante o treinamento. Sempre que o codificador de consulta atualiza uma etapa, o codificador de chave atualiza uma etapa. É fácil descobrir que o codificador de consulta e o codificador de chave modelados dessa maneira pelo SimCLR são os mesmos; portanto, o codificador QK deve ser consistente no estado.
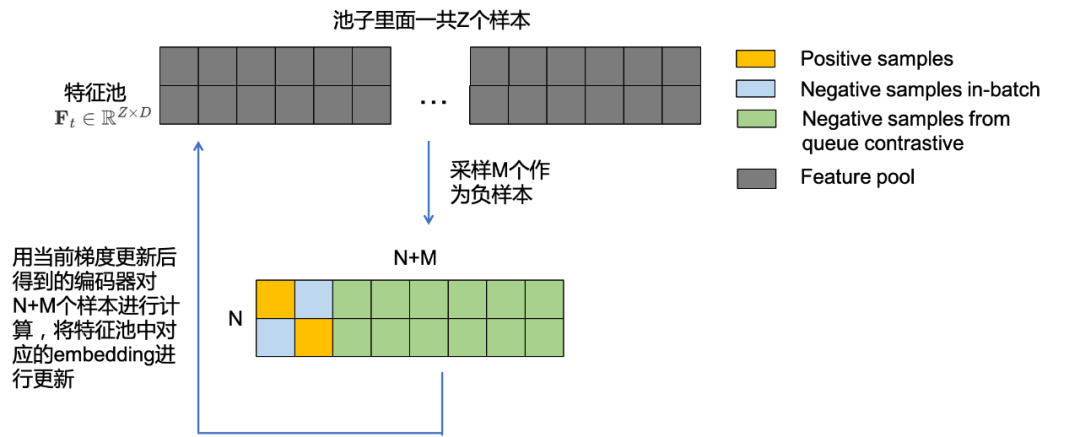
Início do Algoritmo do Banco de Memória
- Primeiro, use o codificador de consulta atual ft ( ⋅ ) f_{t}(\cdot)ft( ⋅ ) para todosos ZZAs amostras Z são calculadas para obterZZIncorporação Z , chame dettConjunto de recursosF t ∈ RZ × D \mathbf{F}_{t} \in \mathbb{R}^{Z \times D} no tempo tFt∈RZ × D. _
- Extraia MM do pool de recursosM amostras são usadas como amostras negativas, registradas comoM ∈ RM × D \mathbf{M} \in \mathbb{R}^{M \times D}M∈RM × D , NNcom o tamanho do lote atualN amostras são comparadas para obterR ( N + M ) × D \mathbb{R}^{(N+M) \times D}R( N + M ) × D pontuação de amostra negativa e combinada com a pontuação de comparação da amostra de tamanho de lote atual, conforme mostrado na Fig. 2.7, formandoRN × ( N + M ) \mathbb{R}^{N \times ( N +M)}RN × ( N + M ) pontuações, das quaisNNN amostras positivas são pontuadas e o restante são amostras negativas. De acordo com esta matriz de pontuação, a perda de comparação é modelada e o gradiente é gerado para atualizar o codificador de consulta e é registrado como t + 1 t+1t+Codificador de consulta no tempo 1 ft + 1 ( ⋅ ) f_{t+1}(\cdot)ft + 1( ⋅ )。
- usar t + 1 t+1t+Codificador de consulta no tempo 1 ft + 1 ( ⋅ ) f_{t+1}(\cdot)ft + 1( ⋅ ) Depois de calcular a incorporação de N+M amostras, atualize as feições no pool de feições correspondente para obterF t + 1 ∈ RZ × D \mathbf{F}_{t+1} \in \mathbb{ R}^ {Z \vezes D}Ft + 1∈RZ × D. _
- Volte para a etapa 1 para a próxima rodada de treinamento.
Algoritmo de Fim do Banco de Memória
Da perspectiva deste processo, podemos descobrir que não há codificador de chave neste processo, e o papel da codificação de chave é substituído pela unidade de armazenamento de amostra semi-offline do banco de memória. Como o banco de memória é amostrado na amostra global para obter uma amostra negativa, e t + 1 t+1t+O resultado do Query encoder no momento 1 atualizará apenas N + M N+Mem todo o poolN+Incorporação de M amostras, emt + 2 t+2t+Amostras negativas ainda serão amostradas aleatoriamente em 2 momentos, então t + 1 t+1t+A incorporação atualizada no tempo 1 é amostrada como uma amostra negativa parat + 2 t+2t+2 rodadas de treino. Não é difícil ver que o estado do codificador de consulta e o estado do codificador de chave (ou seja, o banco de memória) são inconsistentes neste momento, e o número de etapas que o codificador de chave fica atrás do codificador de consulta é imprevisível (porque está no pool de amostra total Amostras negativas são amostradas aleatoriamente dentro). Isso também é resumido na Tabela 2.2.
| 提高batch size的方式 | 提高负样本数量的方式 | batch size和负样本数量是否耦合 | Query-Key编码器状态一致性 | 正样本对中QK编码器是否状态一致 | 是否会遇到BN层统计参数泄露 | |
|---|---|---|---|---|---|---|
| 端到端 | all_gather |
通过提高batch size | 是 | 一致更新 | 一致更新 | 是 |
| MoCo | 一般无需提高batch size | 通过维护负样本队列 | 否 | 一致更新,或者Key编码器以固定步数落后于Query编码器 | 一致更新 | 否 |
| Memory Bank | 一般无需提高batch size | 通过维护负样本队列 | 否 | 不一致,Key永远落后于Query,且落后步数不可预期 | 不一致, | 否 |
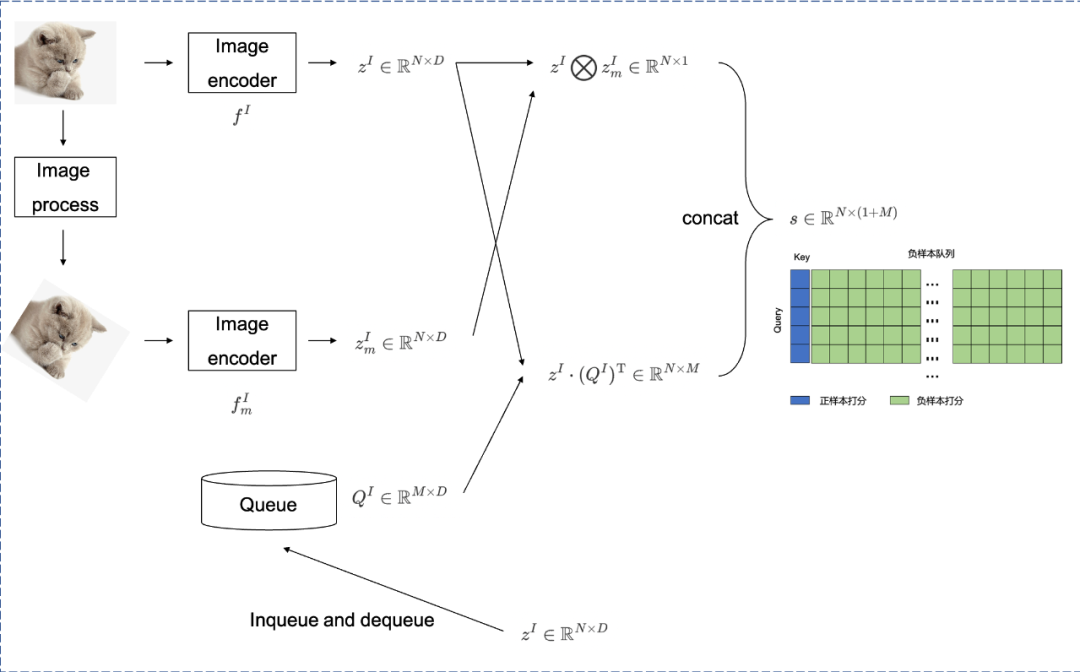
MoCo和memory bank不同在于,MoCo在采用负样本队列进行负样本扩充的前提下,同样采用了Key编码器5。如Fig 2.8所示,其中的 f I f^{I} fI为Query编码器,而 F m I F^{I}_{m} FmI为Key编码器,前者输出的embedding矩阵为 z I ∈ R N × D z^{I} \in \mathbb{R}^{N \times D} zI∈RN×D,后者输出的embedding矩阵则为 z m I ∈ R N × D z^{I}_{m} \in \mathbb{R}^{N \times D} zmI∈RN×D,负样本队列样本数量为固定的 M M M个, Q I ∈ R M × D Q^{I} \in \mathbb{R}^{M \times D} QI∈RM×D。MoCo的整个流程描述如下:
Begin of MoCo Algorithm
- 计算正样本打分,即是计算当前Query编码器和Key编码器的打分,得到 z I ⨂ z m I ∈ R N × 1 z^{I} \bigotimes z^{I}_{m} \in \mathbb{R}^{N \times 1} zI⨂zmI∈RN×1。
- 计算负样本打分,即是计算当前Query编码器和负样本队列的打分,得到 z I ⋅ ( Q I ) T ∈ R N × M z^{I} \cdot (Q^{I})^{\mathrm{T}} \in \mathbb{R}^{N \times M} zI⋅(QI)T∈RN×M。
- Concatene amostras positivas e amostras negativas para pontuar, obtenha s ∈ RN × ( 1 + M ) s \in \mathbb{R}^{N \times (1+M)}s∈RN × ( 1 + M ) , onde a primeira coluna é sempre amostras positivas.
- Atualize a fila de amostra negativa e defina o ponteiro z do codificador de consulta atual para z I z^{I}zEu enfileiro a fila de amostra negativaQIQ^{I}QI , e remova a amostra mais antiga da fila de amostras negativas.
- Os parâmetros do codificador de chave são atualizados por meio da atualização de momento para acompanhar o estado do codificador de consulta.
- Repita a etapa 1.
Fim do Algoritmo MoCo
A atualização de momento do codificador de chave na etapa 5 é muito importante, o que garante que o codificador de chave possa rastrear o estado do codificador de consulta. O método de atualização de momento é mostrado na fórmula (2-2), onde θ K t + 1 , θ K t \theta_{K}^{t+1},\theta_{K}^{t}eukt + 1,euktRespectivamente t + 1 t+1t+1 ettParâmetros chave do modelo do codificador no tempo t , e θ Q t \theta_{Q}^{t}euQtpara ttt时刻的Query编码器模型参数, m ∈ [ 0 , 1 ) m \in [0,1) m∈[0,1)表示动量系数(本文默认设为 m = 0.999 m=0.999 m=0.999)。通过动量更新的方式,不难看出Key编码器和Query编码器可以保持状态一致,因此正样本打分是状态一致的Query-Key打分。我们继续考察负样本打分,负样本打分来自于Query编码器embedding与负样本队列的打分,负样本队列由过去 T T T个时刻中的Query编码器embedding所填充,此时负样本队列中最老的状态总是落后于当前Query编码器 T T T个时刻,这个落后步数是可以预期的,因此近似可以认为负样本打分也是状态一致的。
θ K t + 1 ← m θ K t + ( 1 − m ) θ Q t (2-2) \theta_{K}^{t+1} \leftarrow m\theta_{K}^{t} + (1-m)\theta_{Q}^{t} \tag{2-2} θKt+1←mθKt+(1−m)θQt(2-2)
在MoCo的训练过程中,可能会遇到Batch Norm层的信息泄露问题,这个不是本文重点,具体见博文[35]。
MAE
Masked AutoEncoder (MAE) [36] 同样也是凯明大佬的代表作之一。考虑到在NLP任务中有Mask Language Model(MLM),其对输入的文本进行掩膜然后尝试通过模型进行缺失令牌的预测,从而让模型学习到令牌的语义(从缺失令牌的上下文中)。正如上文所说,文字是一种信息密度极高的信息媒介,而图片则是一种信息冗余度极高的媒介,既然文字可以通过掩膜文本令牌的方式进行语义建模,图片这种信息密度更低的数据类型没道理不能这样处理。
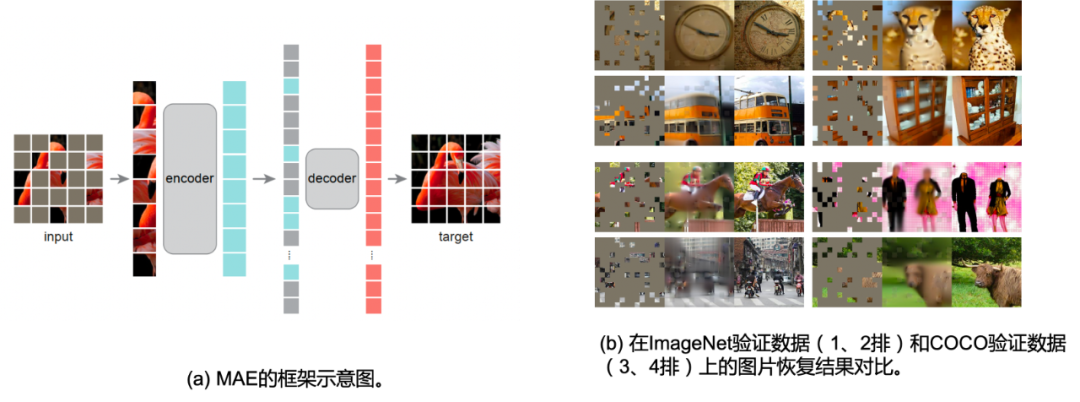
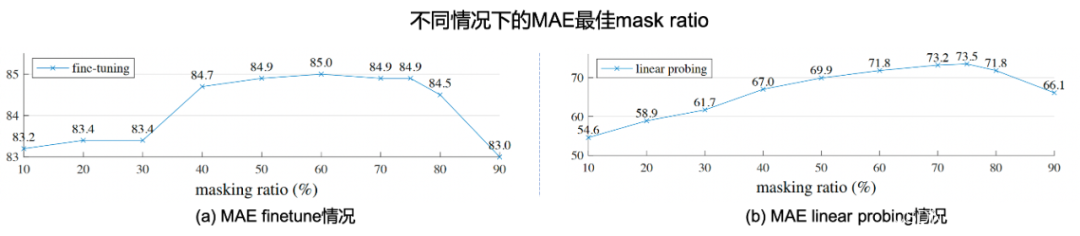
No trabalho do MAE, conforme mostrado na Fig. 2.9 (a), o autor primeiro divide a imagem em grades e divide uniformemente a imagem em múltiplos 16 × 16 16 \ times 1616×Um bloco de imagem com um tamanho de 16 pixels é gravado como um total deNNN blocos de imagem. Então, de acordo com a proporção de máscara dada (relação de máscara)ppp , remova aleatoriamente o bloco de imagem na granularidade do bloco e remova o bloco de imagem restante visível (visível)x ∈ RM × W × H × C \mathbf{x} \in \mathbb{R}^{M \times W \vezes H \vezes C}x∈RM × W × H × C é usado como entrada do codificador ViT, e a incorporação de saída ér ∈ RM × D \mathbf{r} \in \mathbb{R}^{M \times D}r∈RM × D , ondeDDD为embedding维度。此时,将缺失的embedding用mask token进行代替(类似于NLP中的[MASK]),将其余的图片块按照原先图片块的位置关系进行排序,通过ViT decoder进行像素级别的重建,即完成了MAE的建模。作者通过finetune任务和linear probe任务,在多个下游数据上进行了测试,证明了MAE对于图片表征学习的有效性,这些实验读者有兴趣可自行翻阅,本文主要对其重建的图片可视化结果进行展示,如Fig 2.9 (b)所示,其第一列表示mask后的图片,第二列表示恢复后的图片,第三列表示ground truth的愿图片,采用mask概率为80%,可以发现其重建图片效果在语义上都是没问题的。特别关注的是,第3排的右边结果,我们发现尽管重建图片和真实图片存在一定的差别(真实图片的人体是没头的,但是重建图片则是含有头的),但是重建图片在语义上更为正确(这个应该是人体的模型,大部分真实的人体都应该有头吧…),由此可知MAE的重建并不是基于记忆,而是基于语义。作者在原文还进行了不少消融实验,本文就列举其中一个对最佳掩膜比例的实验,如Fig 2.10所示,作者在MAE finetune和MAE linear probing的情况下,分别尝试了不同的掩膜比例,其中发现两种情况下的MAE最佳掩膜比例都在75%,而在BERT中,典型的掩膜比例是15%左右,这也一定程度上验证了图片的信息密度的确比文本的高。MAE这种对图片进行掩膜的思想,也直接影响到了跨模态模型的建模,如FLIP [24]。
BEiT
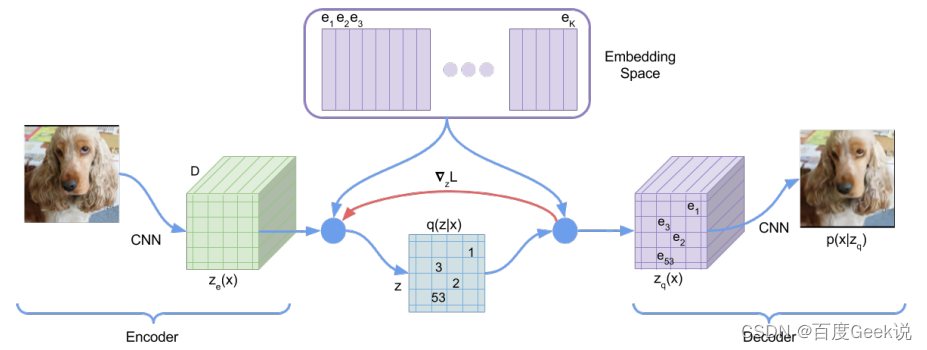
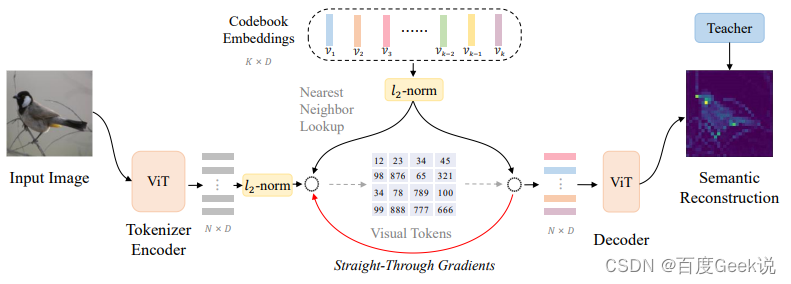
除了MAE这种尝试对图片像素进行重建的工作外,还有一些工作尝试对图片的稀疏视觉令牌进行重建。在此之前,我们可以了解下什么叫做稀疏视觉令牌(sparse visual token),将图片进行分块后,通过模型将图片块映射到某个整型的ID,我们称之为图片块的视觉令牌化,对比稠密的浮点向量,它由于是一个整型的值,因此是稀疏的。图片的信息冗余性是能够对图片块进行视觉令牌化的重要前提,通过令牌化另一方面也可以提取图片的关键语义信息。VQ-VAE [45]就是一种尝试对图片进行稀疏视觉令牌化的工作,如Fig 2.11所示,作者通过图片的像素重建着手,将视觉的稀疏编码看成是中间的隐变量 z z z。通过维护一个向量字典(Embedding space),对图片块编码后的稠密向量在字典中进行最近邻查找,将查找得到后的索引视为是其稀疏编码(也既是稀疏视觉令牌)。整个过程的具体介绍请见博文 [46],此处不累述。
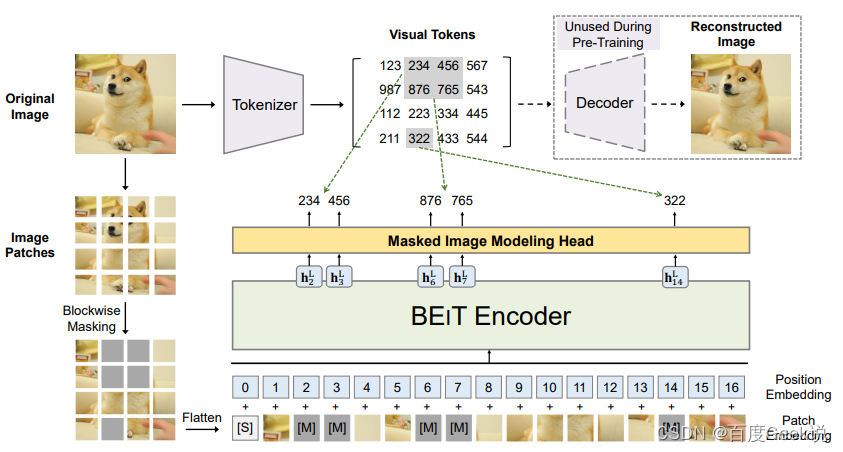
而在BEiT [47]就是尝试对这种视觉令牌进行重建,而不是对像素本身进行重建的工作。像素本身是一种最底层的视觉元素,而若干像素组成的小图片块具有的语义也较为底层,如果对像素作为粒度进行重建,容易导致模型过多关注到像素重建这个底层任务,从而忽视了高层的一些视觉元素和视觉语义。具体来说,在BEiT中,作者引入了所谓Masked Image Modeling(MIM)的任务,一听这个名字我们就想到了BERT的Masked Language Modeling(MLM),没错这个工作就是效仿BERT的思想对图片进行自监督建模。顾名思义,如Vision Transformer一样,MIM这个任务会首先对图片进行分块(Patching),然后通过dVAE [48]对图片块进行视觉令牌化6。如Fig 2.12所示,类似MAE的做法,首先会随机对图片进行掩膜,而不同的点在于掩膜掉的图片块并不会被抛弃,而是用一个特殊的mask向量[M] e [ M ] ∈ R D e_{[M]} \in \mathbb{R}^{D} e[M]∈RD进行替代,多个图片块(包括[M])拉平到序列,表示为 x M x^{\mathcal{M}} xM,将其输入BEiT编码器,对产出的向量 { h i L } \{h_{i}^{L}\} {
hiL}进行视觉令牌的预测。这里面的 i i i是第 i i i个token输出,而 L L L表示了编码器的最后一层层数。通过多类分类器建模这块的视觉令牌预测,如式子(2-3)所示。
p M I M ( z ′ ∣ x M ) = s o f t m a x ( W c h i L + b c ) (2-3) p_{MIM}(z^{\prime}|x^{\mathcal{M}}) = \mathrm{softmax}(\mathbf{W}_c h^{L}_{i}+b_c) \tag{2-3} pMIM(z′∣xM)=softmax(WchiL+bc)(2-3)
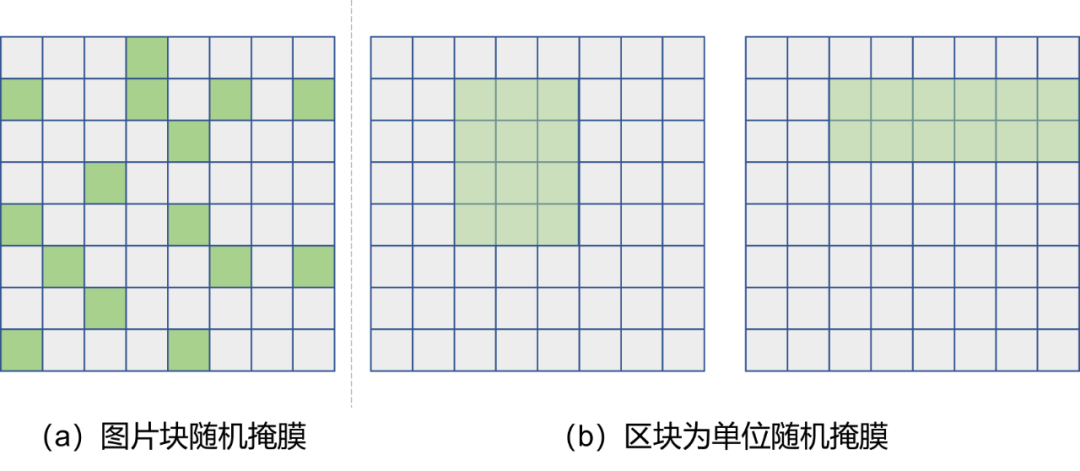
当然,这个对图片块的掩膜并不是随机选取图片块进行的,而是以“区块”(Block)为单位进行选取的,这俩的区别可见Fig 2.13所示,以区块为单位的随机掩膜在固定掩膜图片块数量一致的情况下,可以随机选取区块的长和宽,以及区块在图片中的位置,具体的细节请移步原论文。
BEiT对图片进行稀疏编码,并且通过稀疏编码后的图片块的重建,进而提高图像自监督任务的语义建模能力,这一点非常有创新性。然而遗憾的是BEiT里采用的dVAE的重建目标仍然是像素级的重建,因此其视觉令牌化后的稀疏编码高层语义能力仍可以优化。启发与此,在BEiT v2 [49]中,作者在BEiT的MIM任务基础上,尝试对稀疏令牌化这个过程也进行更为合理的建模。如Fig 2.14所示,在BEiT v2中,作者大部分参考了VQ-VAE的方法,而区别在于最后的重建目标并不是恢复图片的像素,而是对齐Teacher模型的产出。此处的Teacher模型是大型的视觉语义模型,比如CLIP [15] 或者DINO [50],其最后pooling层前的feature map可视为是具有语义特性的特征,表示为 t i \mathbf{t}_i ti,而模型输出则表示为 { o i } i = 1 N \{\mathbf{o}_i\}_{i=1}^{N} {
oi}i=1N。相较于对像素恢复通过MSE建模,此处会采用最大化 t i \mathbf{t}_i ti和 o i \mathbf{o}_i oi的余弦相似度 cos ( o i , t i ) \cos(\mathbf{o}_i, \mathbf{t}_i) cos(oi,ti)进行建模。此处的稀疏令牌是由最近邻查找字典得到的,可用公式(2-4)进行表示,而这个字典会通过梯度进行更新。作者把整个稀疏令牌的学习过程称之为vector-quantized knowledge distillation(VQ-KD),其最终的损失函数如公式(2-5)所示。不难知道,由于最近邻查找是没有梯度的,在实现的时候采用了所谓的“梯度拷贝”的方式复制了梯度,这个具体解释可见博客 [46],而公式(2-5)中的 s g [ ⋅ ] \mathrm{sg}[\cdot] sg[⋅]表示的就是stop gradient,即是停止梯度的意思。我们很容易发现VQ-KD的loss和VQ-VAE的loss其实是一模一样的,因此VQ-KD和VQ-VAE的区别,以笔者的角度来看就是引入了Teacher模型进行了语义知识的蒸馏,这也和它的取名可谓贴切了。
z i = arg min j ∣ ∣ l 2 ( h i ) − l 2 ( v i ) ∣ ∣ 2 (2-4) z_i = \arg \min_{j} ||l_2(\mathbf{h_i})-l_2(\mathbf{v}_i)||_2 \tag{2-4} zi=argjmin∣∣l2(hi)−l2(vi)∣∣2(2-4)
LVQ − KD = min ∑ x ∈ D ∑ i = 1 N − cos ( oi , ti ) + ∣ ∣ sg [ l 2 ( hi ) ] − l 2 ( vzi ) ∣ ∣ 2 2 + ∣ ∣ l 2 ( hi ) − sg [ l 2 ( vzi ) ] ∣ ∣ 2 2 (2-5) \begin{align} \mathcal{L}_{VQ-KD} &= \min \sum_{x\in \mathcal{D }} \sum_{i=1}^{N} -\cos(\mathbf{o}_i, \mathbf{t}_i)+ \\ & ||\mathrm{sg}[l_2(\mathbf{h_i} )]-l_2(\mathbf{v}_{z_i})||_2^2 + ||l_2(\mathbf{h_i})-\mathrm{sg}[l_2(\mathbf{v}_{z_i}) ]||_2^2 \end{align} \tag{2-5}euVQ − KD _=minx ∈ D∑eu = 1∑n−cos(oeu,teu) +∣∣ sg [ l2( heu)]−eu2( vzeu) ∣ ∣22+∣∣ eu2( heu)−sg [ eu2( vzeu)] ∣ ∣22( 2-5 )
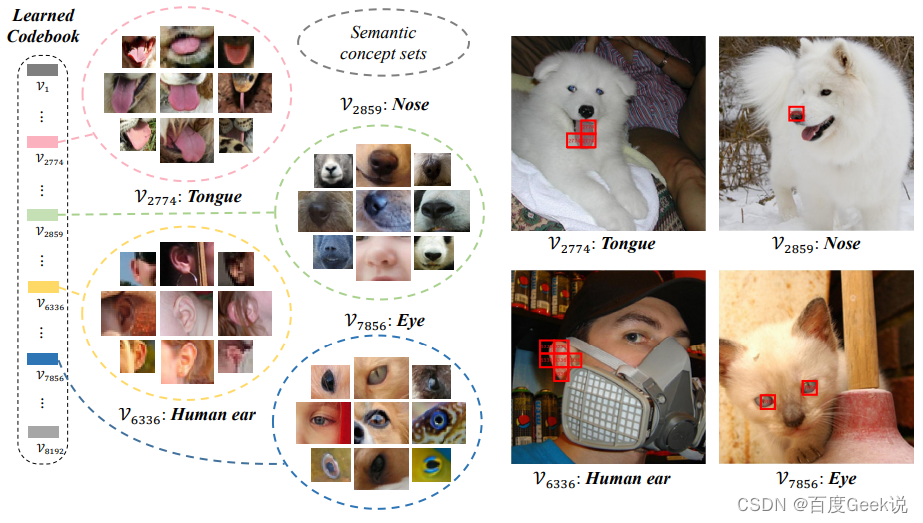
Então, o dicionário erudito atende às expectativas e possui características semânticas significativas? O autor realizou uma análise visual do dicionário.Como mostrado na Fig. 2.15, os blocos de imagens podem ser agrupados realizando a recuperação do vizinho mais próximo no conjunto de imagens válidas ImageNet e cada palavra no dicionário treinado. Não é difícil descobrir que esse método pode de fato agrupar conceitos visuais do mesmo tipo de semântica em um determinado vetor de palavras, o que significa que as palavras aprendidas têm conceitos semânticos visuais significativos.
No BEiT v2, também é proposto usar a estratégia de agregação de patch para reduzir a diferença entre a representação da granularidade da imagem e a representação do bloco da imagem, ou seja, [CLS]a diferença entre a representação correspondente e a representação correspondente de outros tokens, mas isso não é o foco deste artigo, então não vou entrar em detalhes.
representação de vídeo
O autor mencionou uma vez a modelagem auto-supervisionada de vídeo em "Wanzi Changwen Talking about Video Understanding" [1], que mencionou alguns métodos auto-supervisionados de modelagem de vídeo, como previsão baseada na ordem da sequência de quadros, rastreamento baseado, vídeo baseado método de coloração. O atual método popular de modelagem auto-supervisionada de vídeo geral foi muito inspirado pela modelagem de imagem, que produziu um método baseado na reconstrução de vídeo. Esta seção apresenta principalmente esse tipo de método.
videoMAE
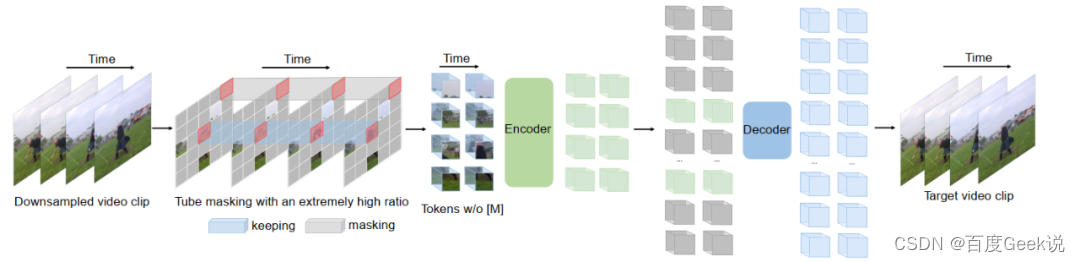
Como uma imagem estática desdobrada no domínio do tempo, a modelagem auto-supervisionada de vídeo é inspirada em muitas modelagens de imagem, e VideoMAE [51] é um trabalho influenciado pela modelagem MAE de imagem, conforme mostrado na Fig. 2.16, videoMAE's O processo e a imagem MAE são muito semelhantes em comparação. A modelagem MAE de imagens considera o mascaramento aleatório de blocos de imagens, e os vídeos também podem usar diretamente esse método? Conforme mostrado na Figura 2.17, existem vários esquemas de mascaramento possíveis em vídeo: mascaramento de quadro aleatório, mascaramento aleatório e mascaramento de tubo. Como discutido anteriormente, tanto os vídeos quanto as imagens são mídias com redundância de informações muito rica.Comparado às imagens, o vídeo não possui apenas redundância de informações espaciais, mas também redundância temporal7, o que não é difícil de entender, o vídeo geralmente muda lentamente em quadros adjacentes . Se a estratégia de mascaramento de bloco de imagem aleatório for usada como a imagem MAE, então pode haver "vazamento na dimensão do tempo" de informação durante o processo de treinamento, e isso levará ao objetivo de prever o bloco de imagem atual, que tenderá a passar através do correspondente É realizado preenchendo as informações dos quadros adjacentes, em vez de preencher depois de aprender sua semântica. Obviamente, isso não é propício para o modelo aprender a semântica dos vídeos. Portanto, este trabalho adota o chamado tube masking (mascaramento de tubo), conforme mostrado na Fig. 2.17 (d), que também mascara os picture blocks correspondentes aos frames adjacentes do mesmo picture block, reduzindo assim o modelo através de “time "Atalho" para preencher a possibilidade de blocos de imagem ausentes, para que o modelo possa primeiro aprender a semântica do vídeo.

BEVT
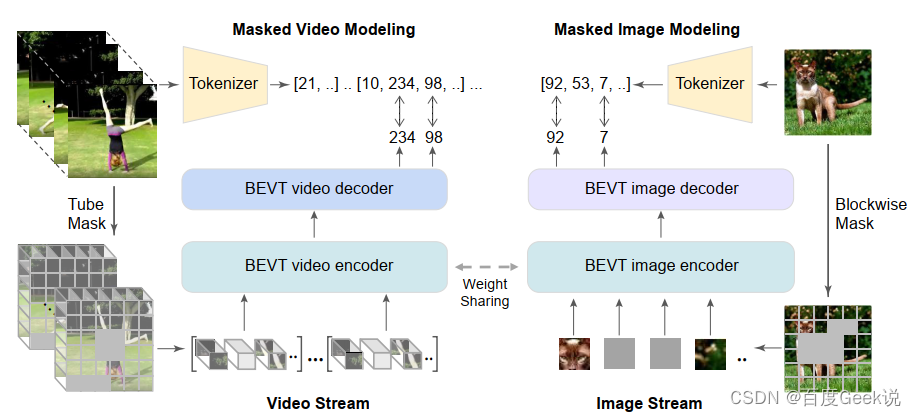
我们在上文提到过,对图片像素的重建任务容易学习出低级视觉特征,而忽略高层语义特征,因此在BEiT和BEiT v2中尝试对视觉稀疏令牌化后的视觉令牌进行重建,从而保证视觉高层语义的建模。对于视频建模而言,同样存在这个问题,因此在BEVT [55]中,作者基于BEiT系列工作的启发,尝试采用对视频块稀疏化后的令牌进行重建,而不是视频像素本身。同时,由于视频固有的时间-空间语义特性,为了更好地对视频的视觉空间特性进行建模,作者采用了视频流(Video Stream)和图片流(Image Stream)同时训练的方式进行,并且其视频编码器和图片编码器是采用权值共享(weight sharing)的。整个模型框架如Fig 2.18所示,本文不对具体技术进行介绍,有兴趣的读者请移步原论文。
文本表征
文本表征不是本文的重点,在此不进行介绍,感兴趣的同学请自行查阅文献。(其实是因为笔者太懒:P,而且笔者自知在文本建模上没有特别系统化的认识,就不班门弄斧了。)
0x03 语义标签的使用:走向多模态
以上我们分别对视觉单模态和文本单模态的自监督表征方法进行了简单介绍,相信大家对自监督建模或多或少也有所了解了。而自本章开始,终于我们将正式地踏入跨模态的地界。欢迎你,我的旅客,至此欢迎来到多模态的世界~
人类语义表达与理解过程
Sem dúvida, antes de entrarmos no mundo multimodal, precisamos entender o que é multimodal (modalidade múltipla). No ponto de vista do autor, seja texto ou visão, ou voz, ou mesmo linguagem corporal humana, etc., todos os meios que podem ser usados pelos membros e órgãos humanos para expressar a semântica e as emoções no pensamento humano podem ser. pode ser considerada como uma modalidade, e a combinação dessas modalidades e a interação da informação modal pode ser considerada como multimodal. Como mostrado na Fig. 3.1, a expressão e a compreensão semântica humana podem ser expressas como codificação e decodificação de informações e a parte mais importante do pensamento humano.Consideremos o pensamento humano como uma caixa preta, que expressa a racionalidade e o pensamento humanos. A codificação e a decodificação da informação são meios para os seres humanos expressarem seus pensamentos e entenderem os pensamentos dos outros por meio de órgãos externos, como olhos, boca, nariz, orelhas e membros. No entanto, na interação de informações (incluindo codificação e decodificação de informações) de grupos humanos, certos conceitos concretos e abstratos8 irão convergir até certo ponto, e o resultado da convergência de conceitos será armazenado na biblioteca de conceitos de consenso de humanos na forma de consenso conceitos tornam-se um conceito universal.
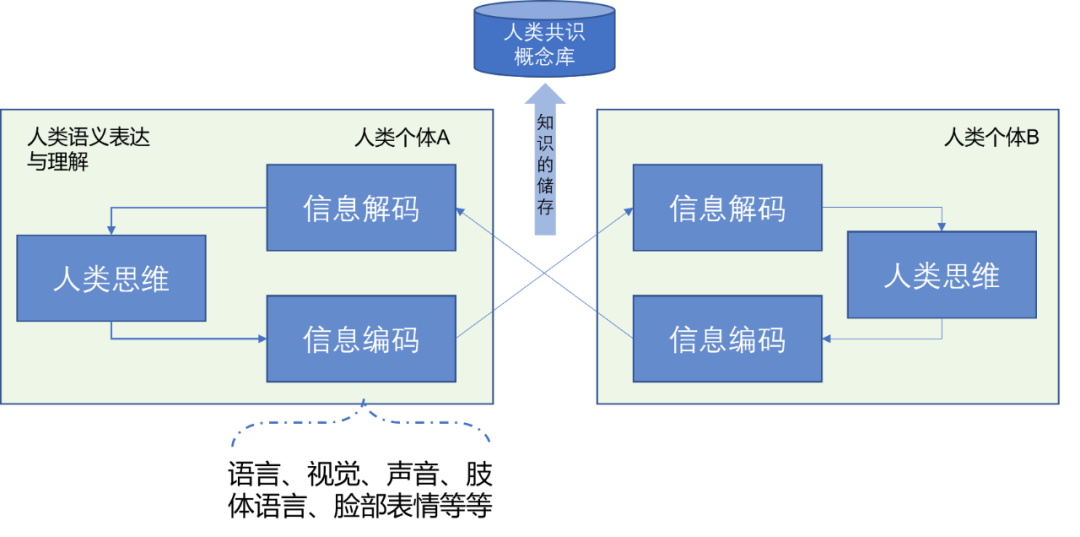
A partir disso, podemos entender que, seja linguagem, imagens, vídeos, sons, movimentos corporais ou expressões faciais, todos esses são meios para os humanos expressarem seus pensamentos internos. Atualmente, não podemos entender o nível mais baixo do pensamento humano, portanto, considerá-lo como uma variável oculta xxx , e a expressão desses modos pode ser considerada como a variável explícitazzz , a codificação da informação é expressa como uma funçãof ( ⋅ ) f(\cdot)f ( ⋅ ) , então com codificação visual e codificação de texto, temos a fórmula (3-1). ondeztexto, zvisão z_{texto}, z_{visão}zt e x t,zv i s i o nPode ser considerado como uma certa representação numérica (representação numérica) de expressão textual e expressão visual. O que usamos atualmente é a expressão incorporada (Embedding), ou chamada representação distribuída (Representação Distribuída), que geralmente é uma representação flutuante densa. representação de ponto , como ztext ∈ RD z_{text} \in \mathbb{R}^{D}zt e x t∈RD , é claro, essa expressão não é necessariamente a mais precisa.
ztext = ftext ( x ) zvision = fvision ( x ) (3-1) \begin{align} z_{text} &= f_{text}(x) \\ z_{vision} &= f_{vision}(x) \end{align} \tag{3-1}zt e x tzv i s i o n=ft e x t( x )=fv i s i o n( x )( 3-1 )
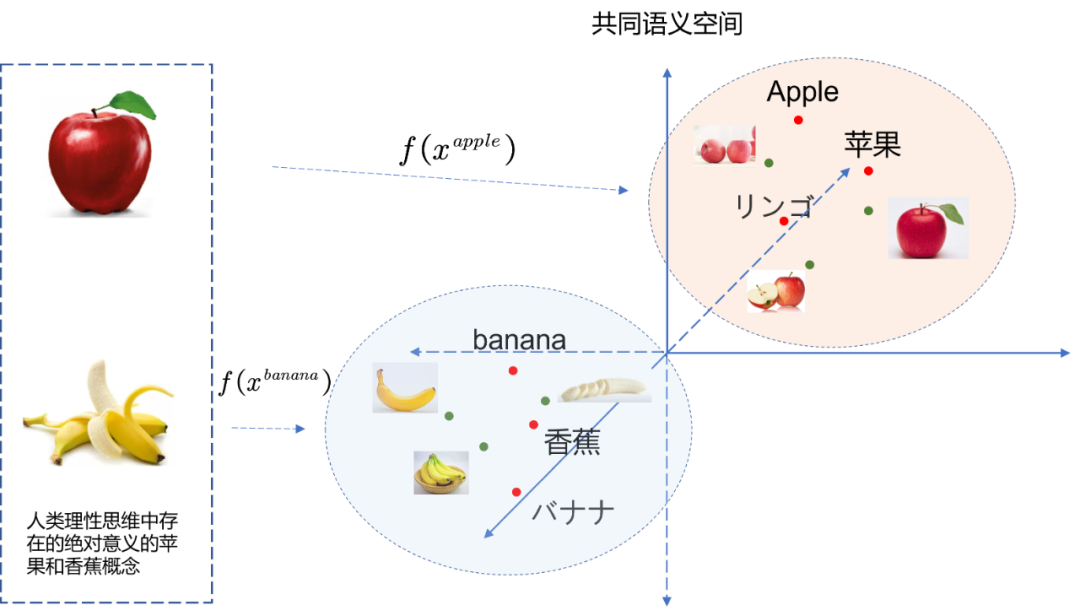
Se no consenso humano, temos um certo conceitox A x_AxAO texto e a expressão visual de , então é concebível que ftexto ( x A ) = fvisão ( x A ) f_{texto}(x_A)=f_{visão}(x_A)ft e x t( xA)=fv i s i o n( xA),也就有ztexto A = zvisão A z_{texto}^{A}=z_{visão}^{A}zt e x tA=zvisão _ _ _ _ _A, conforme mostrado na Fig. 3.2, uma vez determinado que dois conceitos cross-modais podem ser equacionados, eles podem ser mapeados para um espaço semântico comum.Este processo é exatamente o alinhamento semântico que discutimos anteriormente. Esse alinhamento semântico se aplica não apenas a textos e imagens, mas também a sons, linguagem corporal, expressões, etc.
rótulo semântico
在分类任务中,我们的标签通常是“硬标签(hard label)”,指的是对于某个样本,要不是类别A,那么就是类别B,或者类别C等等,可以简单用one-hot编码表示,比如[0,1,0], [1,0,0]等,相信做过分类任务的朋友都不陌生。以ImageNet图片分类为例子,人工进行图片类别标注的过程并不是完全准确的,人也会犯错,而且犯错几率不小。那么很可能某些图片会被标注错误,而且图片信息量巨大,其中可能出现多个物体。此时one-hot编码的类别表示就难以进行完整的样本描述。我们这个时候就会认识到,原来标注是对样本进行描述,而描述存在粒度的粗细问题。one-hot编码的标签可以认为是粒度最为粗糙的一种,如果图片中出现多个物体,而我们都对其进行标注,形成multi-hot编码的标签,如[0,1,1]等,那么此时粒度无疑更为精细了,如果我们对物体在图片中的位置进行标注,形成包围盒(bounding box,bbox),那么无疑粒度又进一步精细了。
也就是说,对于标注,我们会考虑两个维度:1)标注信息量是否足够,2)标注粒度是否足够精细。然而,对于一般的xxx-hot标签而言,除了标注其类别,是不具有其他语义(semantic)信息的,也就是说,我们很难知道类别A和类别B之间的区别,类别C与类别B之间的区别。因为人类压根没有告诉他,如Fig 3.3 (a) 所示,基于one-hot标签的类别分类任务,每个标签可以视为是笛卡尔坐标系中彼此正交的轴上的基底,这意味着每个类别之间的欧式距离是一致的,也就是说,模型认为猫,狗,香蕉都是等价的类别,但是显然,猫和狗都属于动物,而香蕉属于植物。基于one-hot标注,模型无法告诉我们这一点。
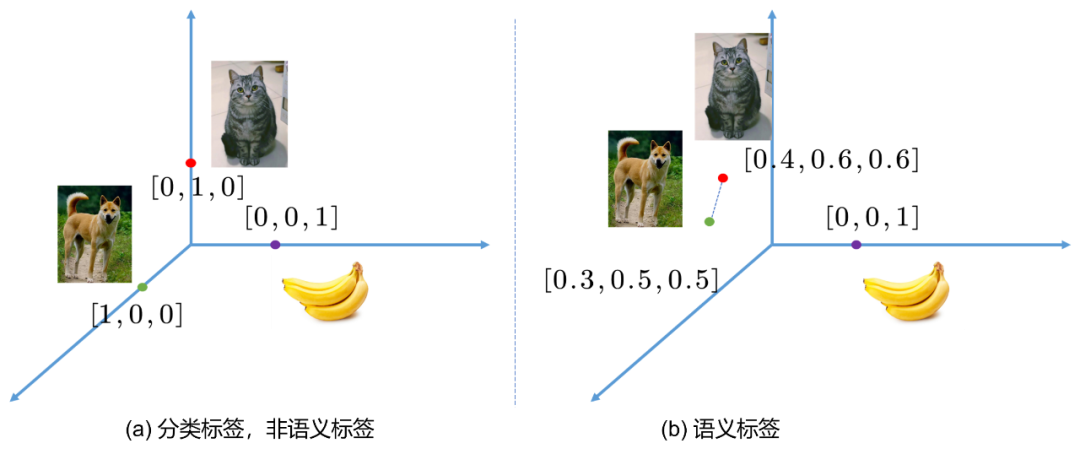
Em outras palavras, cães e gatos têm semântica mais próxima do que bananas, e talvez a Fig. 3.3 (b) seja uma escolha melhor. Se nosso rótulo não é mais one-hot, mas o chamado rótulo semântico, ou no campo da PNL chamado rótulo distribuído (rótulo de distribuição, vetor de distribuição) ou rótulo incorporado (rótulo de incorporação, vetor de incorporação), então o rótulo de categoria O A distância euclidiana entre as categorias pode descrever a semelhança entre as categorias, que pode ser considerada como uma informação semântica simples, mas muitas informações semânticas de alto nível dependem disso.
É difícil confiar na anotação manual para obter tags semânticas, porque a anotação semântica humana tem os seguintes defeitos inerentes:
- Os seres humanos não podem descrever objetivamente o grau de semelhança entre cada semântica visual.
- Existem inúmeros conceitos semânticos visuais e é difícil para os humanos rotular todos os conceitos.
- A semântica é um consenso de grupo de seres humanos, e anotações individuais podem facilmente introduzir vieses individuais.
Portanto, uma abordagem mais viável é usar um método auto-supervisionado para aprender a estrutura inerente dentro/entre as modalidades. Sabemos que uma categoria é chamada de "cachorro", outra categoria é chamada de "gato" e outra A categoria é "banana ", e podemos obter o vetor de palavras descrito por cada categoria através do método de incorporação de palavras, porque o vetor de palavras é obtido com base na matriz de co-ocorrência ou no princípio da localidade de contexto, portanto, há uma grande probabilidade de categorias semanticamente relacionadas possuem vetores Word semelhantes, de modo a realizar a geração de tags semânticas.
É claro que esses rótulos semânticos podem expressar apenas informações semânticas aproximadas e de baixo nível, como o grau de similaridade entre as categorias. E quanto à semântica de nível superior? Por exemplo, no cenário de controle de qualidade de vídeo, dada uma imagem, fazemos uma pergunta com base na imagem e, em seguida, esperamos que o modelo responda à pergunta; como legenda da imagem, dada uma imagem, o modelo precisa tentar descrever o imagem na linguagem. Essas tarefas requerem anotações semânticas de alto nível para serem realizadas. De um modo geral, o que a anotação manual pode fazer neste momento é fornecer uma imagem, permitir que várias pessoas a descrevam com padrões semelhantes e, em seguida, formar um par imagem-texto <image, text#1, text#2...text#n>para o modelo aprender. Claro, esse tipo de carga de trabalho que requer muita mão de obra para rotular é surpreendente. Portanto, uma maneira melhor é explorar informações massivas e ruidosas na Internet. Por exemplo, o contexto de imagens em páginas da Web pode ser considerado relevante, como círculos de amigos e fotos no Weibo, comentários de artigos, etc.
Claro, a informação semântica de alto nível também depende da confiabilidade da semântica subjacente. Por exemplo, muitos transformadores são usados atualmente em aplicações multimodais, como ViLBERT [53], ERNIE-ViL [54], etc., todos dependem sobre a confiabilidade dos vetores de palavras, e então podemos falar sobre isso. Semântica confiável de nível superior. Deste ponto de vista, de fato, há uma lógica da mesma origem da semântica subjacente, das tarefas CV&NLP subjacentes às tarefas multimodais semânticas de alto nível.
Modelos multimodais requerem dados rotulados semanticamente
O que é multimodal? Já falamos sobre isso antes. Nada mais é do que descrever o mesmo conceito e a mesma coisa através de diferentes modalidades. As mais comuns são descrever uma determinada cena com fotos, vídeos, linguagens e vozes. Isso é multimodal. um exemplo . A multimodalidade é atualmente uma direção de pesquisa muito quente.No momento, a semântica de vídeo é complexa, especialmente em sistemas de busca e recomendação, que podem conter vários tipos de vídeos, e é difícil descrevê-los do ponto de vista da semântica de ação. Se for estendido para outra semântica mais ampla, serão necessárias anotações mais refinadas para alcançá-lo. De um modo geral, a rotulagem da categoria de classificação de ação é muito grosseira.
Considerando o fenômeno generalizado de cauda longa no sistema de recomendação de busca, obviamente não é aconselhável realizar um trabalho detalhado de rotulagem de amostras. como projetar a rotulagem apropriada da amostra também é uma questão complicada . Para uma imagem (ou um vídeo), simplesmente dar um rótulo de ação não é suficiente para descrever a semântica de toda a amostra, além de rotular a posição e o tipo de cada objeto na amostra e fornecer uma descrição de texto do que aconteceu em cada amostra , para descrever a cena e o ambiente da amostra, esses são outros métodos de rotulagem que podem ser usados.
Que tipo de tags semânticas são apropriadas? Por enquanto, tanto quanto o autor entende, na fase de pré-treinamento, a fim de garantir que os resultados do pré-treinamento possam ser efetivamente generalizados em tarefas a jusante, a semântica do pré-treinamento não pode ser restrita. Por exemplo, usar apenas a semântica da categoria de ação para restringir é uma restrição estreita. Para fazer com que as anotações tenham informações semânticas mais gerais, muitos métodos atualmente usam fusão multimodal.
No método de fusão multimodal, tomando uma imagem como exemplo, você pode considerar o uso de uma frase para descrever os elementos e o conteúdo de uma imagem (a descrição aqui pode ser marcada manualmente ou pode ser coletada automaticamente dos recursos massivos da rede . Por exemplo, comentários dos usuários sobre suas imagens carregadas, contexto da imagem da página da web, descrição e até barragem, etc.), como o conjunto de dados de legendas conceituais (CC) pré-treinamento [6] usado em ERNIE-VIL [16] , sua anotação A amostra final é mostrada na Fig 3.2. O quadro pontilhado foi adicionado pelo autor. Percebemos que a amostra no canto superior esquerdo está marcada com "Árvores em uma tempestade de neve de inverno". Através deste texto simples e imagens emparelhadas, podemos saber muitas informações:
- Sob uma nevasca, o clima é dominado pelo branco.
- A forma e a aparência da árvore são geralmente verticais no chão.
- Durante uma tempestade de neve, a visibilidade é ruim.
Se houver alguns textos descritivos sobre árvores no conjunto de dados, como "Dois meninos brincam na árvore", é provável que o modelo combine essas amostras e aprenda o conceito de "árvore", mesmo sem o envolvimento de rótulos humanos. os rótulos da caixa delimitadora podem ser aprendidos.Além disso, devido à versatilidade dos rótulos semânticos, também oferece a possibilidade de aprender outros conceitos sobre tempestades de neve. Através deste método, a pressão de rotulagem causada pelo problema da cauda longa pode ser aliviada até certo ponto. E como os recursos incorporados ao texto possuem atributos semânticos, isso significa que as tags de texto podem ser compatíveis com expressões de semântica semelhante (sinônimos, sinônimos etc.), o que melhora ainda mais a versatilidade do modelo. Essas são as características do modelo. modelo de fusão multimodal.
Em resumo, o autor acredita que o modelo de fusão multimodal apresenta as seguintes vantagens:
- A precisão da anotação é menor e pode ser anotada pela maneira intuitiva dos seres humanos de ver imagens e falar.
- Uma grande quantidade de dados de descrição de imagens fracamente rotulados pode ser coletada através da Internet, como comentários de imagens, barragem e autodescrições de usuários.
- A semântica é mais geral e pode ser usada como um modelo pré-treinado para uma variedade de tarefas downstream.
- Ele pode aliviar o problema de cauda longa e é mais amigável para cenas com semântica semelhante.
Portanto, o autor acredita que na era atual de dados maciços fracamente rotulados na Internet e na era do poder de computação altamente aprimorado, é imperativo adotar um método de fusão multimodal em aplicativos como vídeo cross-modal e pesquisa de imagem e recomendação. , é a direção presente e futura. Nossa próxima série de artigos apresentará brevemente esses métodos.

0x04 Antes do CLIP: modelagem de fusão de informações multimodais
O artigo anterior do autor levou os leitores a entender alguns pré-conhecimentos, como modelagem monomodal e coleta de dados multimodais.Este artigo o levará a entrar em contato formalmente com modelos multimodais. O autor acredita que o modelo comparativo de pré-treinamento imagem-texto (CLIP) publicado no ICML 2021 pode ser usado como uma linha divisória. O trabalho de pesquisa multimodal antes e depois disso tem paradigmas de pesquisa completamente diferentes. A capacidade de tiro aumenta ainda mais o entusiasmo dos pesquisadores pela pesquisa multimodal.
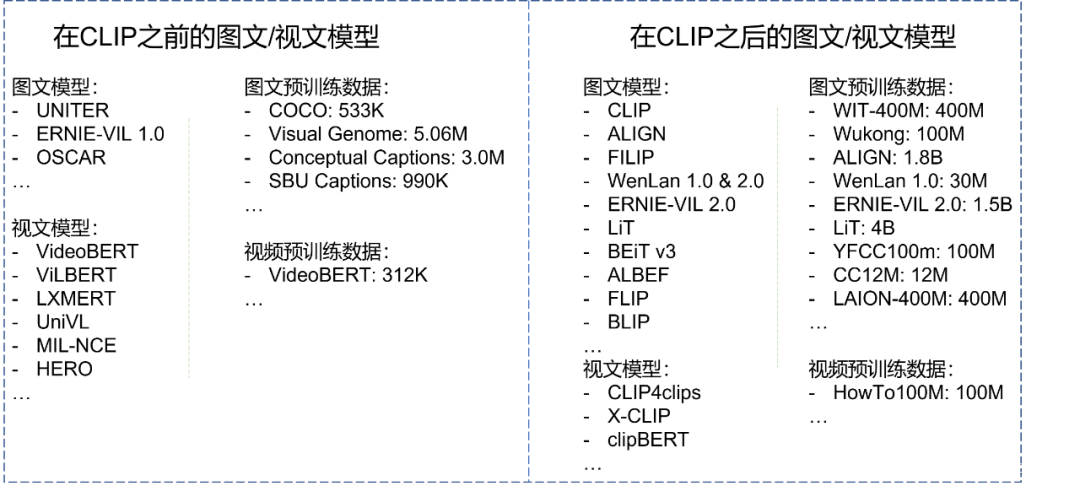
Este capítulo não dará uma introdução detalhada ao CLIP, mas deixará essa glória no Capítulo 0x05, quando o CLIP fará sua estreia. Além dos detalhes do CLIP, primeiro comparamos os principais modelos multimodais antes e depois do CLIP com os conjuntos de dados pré-treinamento usados. Conforme mostrado na Fig. 5.1, descobrimos que os dados pré-treinamento antes do CLIP eram todos pequenos, com ordens de magnitude na ordem de "centenas". Após o CLIP, o tamanho dos dados pré-treinamento se expande diretamente para "bilhões, bilhões" como a unidade. Por que existe uma diferença tão grande de ordem de magnitude? Vamos revelar a resposta mais tarde. Obviamente, o modelo multimodal após o CLIP é a principal prioridade do nosso artigo, mas, por favor, seja paciente, apresentaremos um ou dois modelos multimodais antes do CLIP neste capítulo, porque eles podem nos dar algumas revelações muito valiosas. Então, senhores e meninas, por aqui, por favor~
modelo gráfico
UNIR
Aprendizagem de representação universal de imagem-texto (UNITER) [57], a razão pela qual o autor apresenta este trabalho é que este trabalho apresenta várias perdas de fusão semântica imagem-texto, e as vantagens e desvantagens dessas perdas nos inspirarão. A estrutura do modelo do UNITER é mostrada na Fig. 5.2. Os dados de entrada são um par de pares imagem-texto. O modelo primeiro usa a rede Faster RCNN para detectar objetos na imagem, extrai os recursos do objeto (proposta de recurso) e usa eles como a camada superior A entrada do modelo de fusão semântica. Para o lado do texto, a tokenização de texto (Tokenização de texto) é usada para converter o texto em incorporação de palavras, que também é usada como entrada do Transformer. Neste momento, a entrada do Transformer é dividida em duas categorias, informações de imagem e informações de texto.
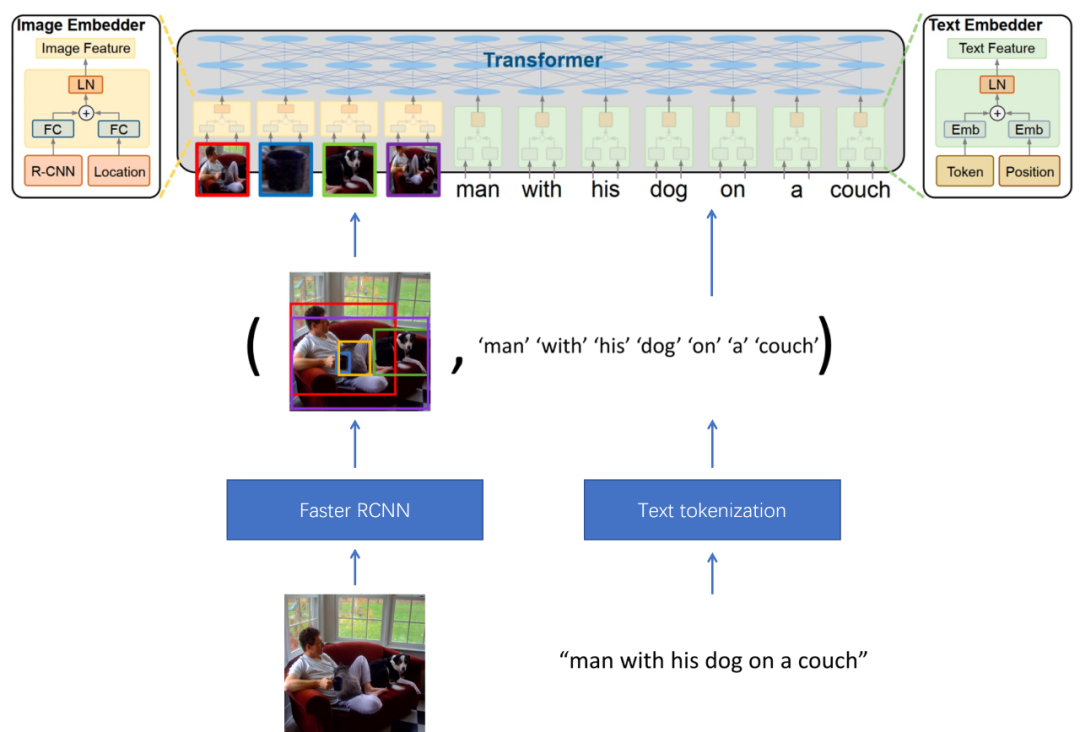
Como o autor acredita que o mais importante no UNITER é o método de modelagem de fusão semântica multimodal, então introduza principalmente a perda usada neste artigo. Conforme mostra a Figura 5.3, as principais perdas utilizadas pelo UNITER são:
E vamos expressar em uma forma matemática unificada, usando v = { v 1 , ⋯ , v K } \mathbf{v}=\{v_1,\cdots,v_K\}v={ v1,⋯,vK} significaKKCaracterísticas das regiões da imagem K , w = { w 1 , ⋯ , w T } \mathbf{w}=\{w_1,\cdots,w_T\}c={ w1,⋯,cT} significaTTT tokens de texto, comm ∈ NM \mathbf{m}\in \mathbb{N}^{M}m∈NM representa o índice mascarado.
-
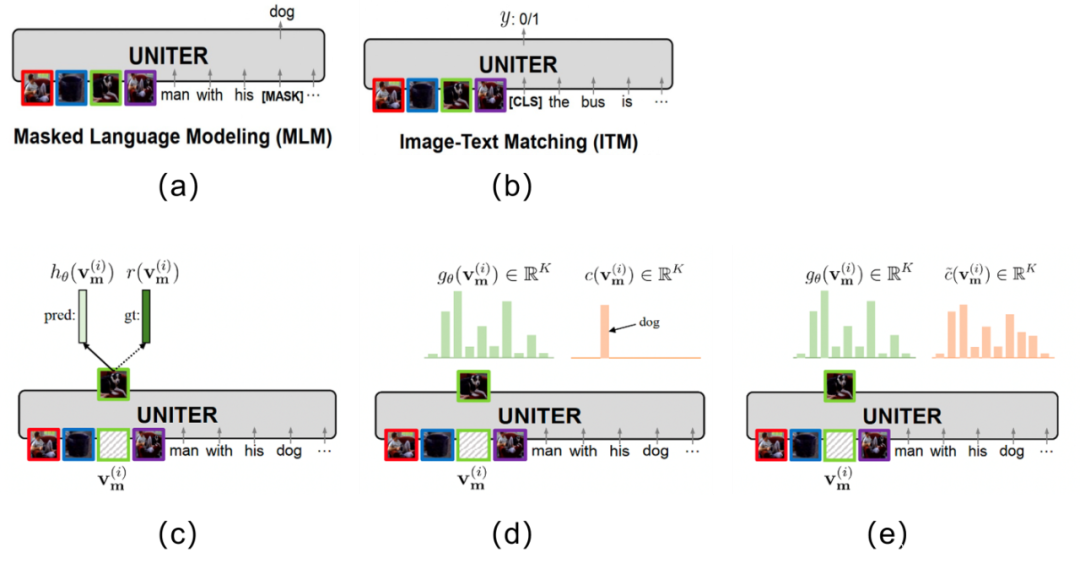
Masked Language Modeling (MLM): Essa perda é mostrada na Figura 5.3 (a) A ideia é mascarar aleatoriamente os tokens de texto e tentar prever o texto mascarado por meio das informações da imagem e das demais informações do texto. A perda é mostrada em (5-1), onde w / m \mathbf{w}_{/ \mathbf{m}}c/ mIndica que o m \mathbf{m} foi removidoOs tokens de texto restantes após o texto no índice representado por m .
LMLM ( θ ) = − E ( w , v ) ∼ D log P θ ( wm ∣ w / m , v ) (5-1) \mathcal{L}_{MLM}(\theta) = -E_{( \mathbf{w}, \mathbf{v}) \sim D} \log P_{\theta}(\mathbf{w}_{\mathbf{m}}|\mathbf{w}_{/ \mathbf{m }},\mathbf{v}) \tag{5-1}euM L M( eu )=− E( w , v ) ∼ Dpouco tempoPeu( wm∣ w/ m,v )( 5-1 ) -
Correspondência de imagem-texto (ITM): essa perda é mostrada na Fig. 5.3 (b). A ideia é projetar uma tarefa de correspondência 0/1 para fusão semântica construindo amostras positivas de correspondência de imagem e amostras negativas de correspondência de imagem-texto. , a perda é mostrada em (5-2).
LITM ( θ ) = − E ( w , v ) ∼ D [ y log s θ ( w , v ) + ( 1 − y ) log ( 1 − s θ ( w , v ) ) ] (5-2) \mathcal{L}_{ITM}(\theta) = -E_{(\mathbf{w}, \mathbf{v})\sim D}[y\log s_{\theta}(\mathbf{w}, \mathbf{v})+(1-y)\log(1-s_{\theta}(\mathbf{w}, \mathbf{v})) ] \tag{5-2}eueu TM( eu )=− E( w , v ) ∼ D[ vocêpouco temposeu( w ,v )+( 1−y )log g ( 1−seu( w ,v ))](5-2) -
Masked Region Modeling—Masked Region Feature Regression (MRFR): 该损失如Fig 5.3 ©所示,公式如(5-3)所示,其思想是随机对图片块进行掩膜,通过尚未掩膜的图片和文本尝试对其进行预测,其中的ground truth为 r ( v m ( i ) ) r(\mathbf{v}_{\mathbf{m}}^{(i)}) r(vm(i)) ,是该掩膜掉的图片块的Faster RCNN对应的输出特征。
f θ ( v m ∣ v / m , w ) = ∑ i = 1 M ∣ ∣ h θ ( v m ( i ) ) − r ( v m ( i ) ) ∣ ∣ 2 2 (5-3) f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{/ \mathbf{m}}, \mathbf{w}) = \sum_{i=1}^{M} ||h_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}) - r(\mathbf{v}_{\mathbf{m}}^{(i)})||_{2}^{2} \tag{5-3} fθ(vm∣v/m,w)=eu = 1∑m∣∣ heu( vm( eu ))−r ( vm( eu )) ∣ ∣22( 5-3 ) -
Masked Region Modeling-Masked Region Classification (MRC): Essa perda é semelhante a 3, e também é modelagem MRM, mas seu destino de recuperação não é mais um recurso, mas uma categoria de destino de máscara, como a Fig 5.3 (d) e fórmula (5 -4), assim modelado por uma perda de entropia cruzada.
f θ ( vm ∣ v / m , w ) = ∑ i = 1 MCE ( c ( vm ( i ) ) , g θ ( vm ( i ) ) ) (5-4) f_{\theta}(\mathbf{v }_{\mathbf{m}}|\mathbf{v}_{/ \mathbf{m}}, \mathbf{w}) = \sum_{i=1}^{M} \mathrm{CE}(c (\mathbf{v}_{\mathbf{m}}^{(i)}), g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)})) \ etiqueta{5-4}feu( vm∣ v/ m,w )=eu = 1∑mCE ( c ( vm( eu )) ,geu( vm( eu )))( 5-4 )
- Masked Region Modeling - Masked Region Classification - KL Divergence (MRC-kl): Essa perda é semelhante a 4, mas o objetivo da classificação não é mais a categoria, mas sim a distribuição de probabilidade de sua categoria, então a modelagem da perda é realizada através da divergência KL .
f θ ( vm ∣ v / m , w ) = ∑ i = 1 MDKL ( c ~ ( vm ( i ) ) ∣ ∣ g θ ( vm ( i ) ) ) (5-5) f_{\theta}(\mathbf {v}_{\mathbf{m}}|\mathbf{v}_{/ \mathbf{m}}, \mathbf{w}) = \sum_{i=1}^{M} D_{KL} ( \tilde{c}(\mathbf{v}_{\mathbf{m}}^{(i)})||g_{\theta}(\mathbf{v}_{\mathbf{m}}^{( i)})) \tag{5-5}feu( vm∣ v/ m,w )=eu = 1∑mDK L(c~ (vm( eu )) ∣∣ geu( vm( eu )))( 5-5 )
Para o ITM, a situação pode ser melhor, porque o ITM julga se o texto da imagem corresponde à granularidade da imagem; portanto, em circunstâncias ideais, ele pode alinhar todos os conceitos visuais que apareceram na imagem ao mesmo tempo. Mas, mesmo assim, também não é eficiente o suficiente.Apresentaremos a perda contrastiva no próximo capítulo, e a perda contrastiva fornece um método de modelagem de alinhamento semântico muito mais eficiente sob outra perspectiva. Mas ITM e MLM não têm absolutamente nenhuma vantagem? Isso não é necessariamente o caso.Os métodos de modelagem de ITM e MLM têm as características de "combinação", o que permite interação de informações suficientes entre gráficos e texto, por isso é um método de modelagem mais adequado para fusão semântica. Observamos os resultados do teste de ablação do UNITER através da Fig. 5.4. Prestamos atenção apenas aos resultados do teste relacionados ao MLM e ITM (ou seja, a parte emoldurada pela linha vermelha pontilhada). Notamos que os resultados do teste do ITM são melhores do que o MLM, e o método de ITM+MLM é melhor do que os resultados dos dois primeiros sozinhos. Como acabamos de analisar, não é difícil de entender. O ITM usa imagens como granularidade para modelar o alinhamento semântico, o que é mais eficiente que o MLM. O ITM+MLM pode obter melhores recursos de alinhamento semântico e, ao mesmo tempo, ter recursos de fusão semântica. .
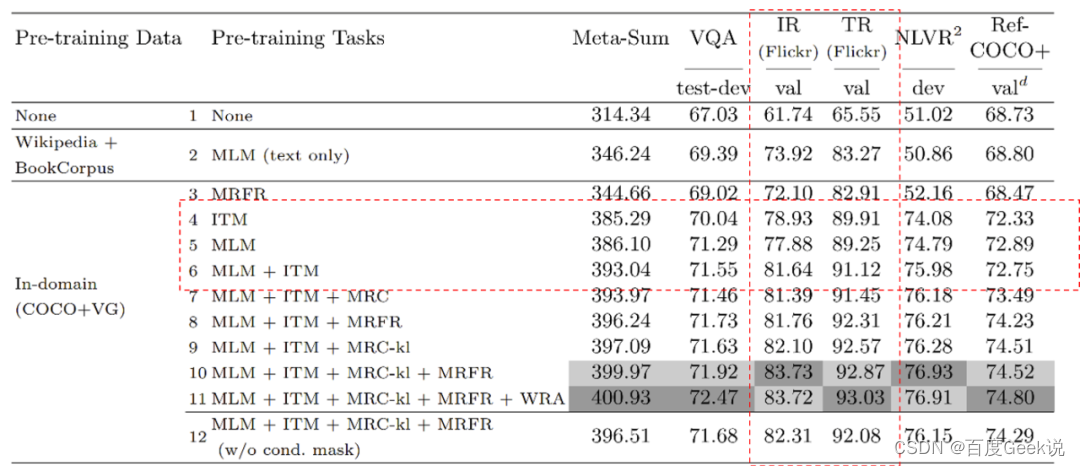
Que conclusões valiosas podemos obter da modelagem e dos experimentos do UNITER? Em primeiro lugar, nem o ITM nem o MLM são um método de modelagem de alinhamento semântico ideal e, como analisamos no Capítulo 0x00, o alinhamento semântico eficaz é a premissa da fusão semântica, pular diretamente o alinhamento semântico para modelar a fusão semântica não é razoável. Em segundo lugar, o uso de MLM e ITM é fortemente dependente da "limpeza" dos dados. Porque os métodos de modelagem de ITM e MLM assumem fortemente que o conteúdo mascarado na imagem ou texto pode ser restaurado por meio de informação cross-modal, o gráfico os dados devem ser compatíveis e complementares! Isso significa que nossos dados devem estar limpos o suficiente e não podemos usar dados ruidosos da Internet em grande escala, o que explica porque os dados pré-treinamento que podem ser usados no trabalho antes do CLIP são de apenas um milhão de níveis, isso porque Dados rotulados limpos são muito caros e requerem rotulagem manual ou confirmação. Esses defeitos podem ser mais ou menos amenizados no trabalho após o CLIP, o que é realmente empolgante~
modelo visual
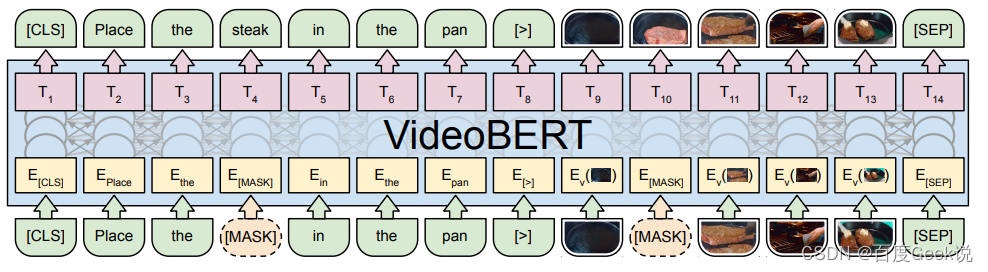
VideoBERT
Este artigo não apresentará muito trabalho de modelo multimodal anterior ao CLIP. Para o modelo de texto visual, o autor adicionará um videoBERT [42]. O videoBERT também usa o modelo Transformer para modelar texto e informações visuais, mas aqui a entrada visual não é um vetor denso, mas tenta tokenizar informações visuais. Como uma tentativa inicial de tokenização visual, os tokens visuais usados aqui são os centros de cluster obtidos pelo agrupamento hierárquico K-means. Comparado com o método da série BEiT ou o método VQ-VAE que mencionamos, esse método de obtenção de tokens visuais por meio de clustering é muito simples e difícil de aumentar. A maneira ideal deve ser manter a tabela de palavras visuais esparsas, obter tokens esparsos através da pesquisa de tabela vizinha mais próxima, assim como VQ-VAE.
A principal inspiração do videoBERT é que as informações de vídeo são um formulário de dados com alta redundância de informações. A tokenização semântica pode não apenas economizar muito os requisitos de recursos do modelo, mas também focar na semântica de modelagem. Ao mesmo tempo, conforme mencionado no BEiT v3 que apresentaremos posteriormente, a modelagem multimodal na forma de tokenização visual esparsa tornará muitos pré-treinamentos multimodais que eram difíceis de fazer antes viáveis.
0x05 Após CLIP: comparação de informações multimodais, modelagem de fusão
Depois de muito esperar saiu, ainda segurando a pipa meio escondida, enfim, finalmente nosso CLIP apareceu nesse capítulo! No Capítulo 0x04, conhecemos o modelo antes do CLIP e também percebemos alguns de seus defeitos inerentes, e esses defeitos foram mais ou menos atenuados após o lançamento do CLIP, então vamos direto ao assunto.
modelo gráfico
GRAMPO
Contrastive Language-Image Pretraining (CLIP) [15] é um trabalho que marcou época. Após o lançamento do CLIP, o paradigma de pesquisa multimodal sofreu grandes mudanças. Portanto, as pistas deste artigo consideram o CLIP como um ponto de demarcação, e este capítulo é uma introdução ao trabalho após o CLIP. Como é necessário apresentar a obra depois do CLIP, é inevitável que o próprio CLIP tenha um livro especial, vamos apresentar o CLIP nesta seção.
CLIP的模型结构本身并没有特别多值得注意的地方,其采用的是经典的双塔结构,对于图片域和文本域有着不同的图片编码器(Image Encoder)和文本编码器(Text Encoder)。其中文本编码器采用了经典的Transformer结构,而图片编码器则采用了两种:第一种是改进后的ResNet,作者选择用基于注意力的池化层去替代ResNet的全局池化层,此处的注意力机制同样是与Transformer类似的多头QKV注意力;作者同样采用ViT结构作为第二种图片编码器进行实验。本文用 f T e x t ( ⋅ ) f_{\mathrm{Text}}(\cdot) fText(⋅)表示文本编码器, f I m g ( ⋅ ) f_{\mathrm{Img}}(\cdot) fImg(⋅)表示图片编码器, x I m g ∈ R N × H × W × C \mathbf{x}_{Img} \in \mathbb{R}^{N \times H \times W \times C} xImg∈RN × H × W × C representa um lote de imagens, ex T ext ∈ RN × S \mathbf{x}_{\mathrm{Text}} \in \mathbb{R}^{N \times S}xTexto∈RN × S表示个batch的文本,那么有:
fimg = f I mg ( x I mg ) ∈ RN × D iftext = f T ext ( x T ext ) ∈ RN × D t (6-1) \begin{aligned } \mathbf{f}_{\mathrm{img}} &= f_{\mathrm{Img}}(\mathbf{x}_{Img}) \in \mathbb{R}^{N \times D_{i }} \\ \mathbf{f}_{\mathrm{texto}} &= f_{\mathrm{Texto}}(\mathbf{x}_{Texto}) \in \mathbb{R}^{N \times D_{t}} \end{aligned} \tag{6-1}fimagemftexto=fimg( xeu sou g)∈RN × Deu=fTexto( xText)∈RN×Dt(6-1)
通过线性映射层将图片特征 f i m g \mathbf{f}_{\mathrm{img}} fimg和文本特征 f t e x t \mathbf{f}_{\mathrm{text}} ftext都映射到相同的嵌入特征维度 D e D_{e} De,那么有:
f i m g e = f i m g W i m g ∈ R N × D e f t e x t e = f t e x t W t e x t ∈ R N × D e (6-2) \begin{aligned} \mathbf{f}_{\mathrm{img}}^{e} &= \mathbf{f}_{\mathrm{img}} \mathbf{W}_{\mathrm{img}} \in \mathbb{R}^{N \times D_{e}} \\ \mathbf{f}_{\mathrm{text}}^{e} &= \mathbf{f}_{\mathrm{text}} \mathbf{W}_{\mathrm{text}} \in \mathbb{R}^{N \times D_{e}} \end{aligned} \tag{6-2} fimgeftexte=fimgWimg∈RN×De=ftextWtext∈RN×De( 6-2 )
A fim de garantir a consistência das escalas numéricas dos dois modos de gráficos e texto, a padronização L2 é realizada sobre eles, conforme mostrado em (6-3), que também apresentamos acima.
GL 2 ( x ) = xi ∑ i D xi 2 (6-3) G_{L2}(\mathbf{x}) = \dfrac{\mathbf{x}_i}{\sqrt{\sum_{i}^{ D}\mathbf{x}_i^2}} \tag{6-3}GL2_ _( x )=∑euDxeu2xeu( 6-3 )
Especifica, padrão
fimgnorm = GL 2 ( fimg ) ftextnorm = GL 2 ( ftext ) (6-4) \begin{aligned} \mathbf{f}^{\mathrm{norm}}_{ \mathrm{ img}} &= G_{L2}(\mathbf{f}_{\mathrm{img}}) \\ \mathbf{f}^{\mathrm{norma}}_{\mathrm{texto}} &= G_ {L2}(\mathbf{f}_{\mathrm{texto}}) \end{alinhado} \tag{6-4}fimgnormaftextonorma=GL2_ _( fimagem)=GL2_ _( ftexto)( 6-4 )
Neste momento, conforme mostrado na Fig. 6.1, a multiplicação de matrizes é realizada nos recursos de incorporação de imagem e recursos de incorporação de texto. Então, na matriz de pontuação formada, as amostras positivas pareadas são pontuadas na diagonal, e os demais elementos da matriz são amostras negativas compostas por figuras e textos não pareados (e vice-versa) no mesmo lote. Esta estratégia pode formarN 2 − NN^2-NN2−N amostras negativas. Todo o processo pode ser descrito pela fórmula (6-5).
M = ( fimgnorm ) ( ftextnorm ) T ∈ RN × N (6-5) \mathbf{M} = (\mathbf{f}^{\mathrm{norma}}_{\mathrm{img}}) (\mathbf {f}^{\mathrm{norma}}_{\mathrm{texto}})^{\mathrm{T}} \in \mathbb{R}^{N \vezes N} \tag{6-5}M=( fimgnorma) ( ftextonorma)T∈RN × N( 6-5 )
Então só precisaM \mathbf{M}Cada linha e coluna de M calcula a perda de entropia cruzada (respectivamente registrada comoI2T losssomaT2I loss) e soma para formar a perda total. Conforme mostrado na fórmula (6-6), a perda de entropia cruzada aqui tem um coeficiente de temperaturaτ \tauτ , que pode efetivamente aliviar o problema de aprendizagem de convergência no caso de super largeq ⋅ k + q \cdot k_{+}batch sizena fórmulaq⋅k+Representa pontuação de amostra positiva e q ⋅ kiq \cdot k_{i}q⋅keuIndica batcha pontuação de todas as amostras atualmente abaixo. Cada linha pode ser considerada como a perda do par de amostras negativas formado pela combinação da mesma imagem com o texto de todos os outros pares de amostras no mesmo lote, e cada coluna é naturalmente o mesmo texto, que é formado pela combinação de cada imagem perdida. Todo o processo é mostrado no pseudocódigo abaixo.
L q = − log exp ( q ⋅ k + / τ ) ∑ i = 0 N exp ( q ⋅ ki / τ ) (6-6) \mathcal{L}_{q} = -\log \dfrac {\exp(q \cdot k_{+} /\tau)}{\sum_{i=0}^{N} \exp(q \cdot k_{i} / \tau)} \tag{6-6}euq=−pouco tempo∑eu = 0nexp ( q⋅keu/ t )exp ( q⋅k+/ t ).( 6-6 )
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
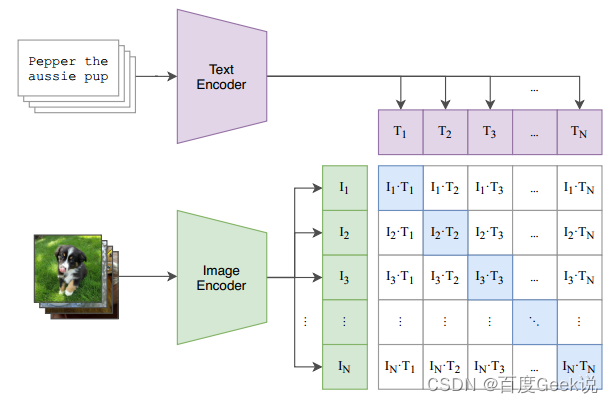
A estrutura do modelo do CLIP e a estratégia de composição de amostras positivas e negativas não são complicadas. Seu método de composição de amostras negativas é o método clássico de lote negativo, ou seja, amostras negativas são formadas de dentro do lote. A contribuição do CLIP é que ele pode usar dados massivos da Internet. Os dados do par imagem-texto (cerca de 400 milhões de pares imagem-texto) e o tamanho super grande do lote (cerca de 32.000) são pré-treinados e, para poder aprender completamente, um estrutura de modelo de grande capacidade é adotada. Por que esse método de aprendizado "simples" do CLIP pode efetivamente realizar o alinhamento semântico? Conforme mostrado na Fig. 6.2, em uma comparação, uma amostra positiva pode ser comparada com um grande número de amostras negativas. Essa comparação tem duas dimensões:
- Comparação figura-texto : uma imagem corresponde a um texto correspondente (amostra positiva), e N − 1 N-1N−1 texto incompatível (amostra negativa), neste momento, uma comparação de amostras positivas e negativas pode esclarecer totalmente o alinhamento semântico visual em diferentes textos. Conforme mostrado na Fig. 6.2, se a primeira linha for considerada uma amostra positiva, então os "cachorrinhos, filhotes e cachorrinhos" no texto são todos consistentes com as imagens da amostra positiva, enquanto o texto da amostra negativa "gatinho" é consistente com a amostra positiva As imagens de amostra não são negativas. Portanto, a diferença semântica entre "cachorrinhos, cachorrinhos" e "gatinhos" é esclarecida de uma só vez. Se nossas amostras negativas forem grandes o suficiente, podemos esclarecer os conceitos visuais em muitos textos em um processo de iteração, e isso é algo MLM e ITM não podem fazer.
- Comparação texto-imagem : semelhante à comparação imagem-texto, um texto corresponde a uma imagem correspondente (amostra positiva) e N − 1 N-1N−Uma imagem incomparável (amostra negativa) e a mesma comparação de amostras positivas e negativas podem esclarecer o alinhamento semântico visual entre diferentes imagens. Considere também a primeira linha como uma amostra positiva, então as palavras "filhotes, cachorrinhos, cachorrinhos" no texto correspondem apenas à primeira linha de imagens e não podem corresponder efetivamente a outras imagens, portanto, podem ser esclarecidas em muitas imagens em uma vez conceito visual.
A partir desta análise, não é difícil saber que o método de modelagem de aprendizado comparativo do CLIP é essencialmente diferente dos métodos ITM e MLM apresentados acima. No CLIP, ao expandir o número de amostras negativas, a capacidade de alinhamento semântico pode ser melhorada em uma eficiência muito alta. E por causa da estrutura de torre dupla, o modelo só precisaN fotos eNNN textos são usados para o cálculo do autovetor e, finalmente, são reunidos para calcular a matriz de pontuação. Conforme mostrado na Fig 6.1, a complexidade computacional desse modelo éO ( N ) \mathcal{O}(N)O ( N ) , e se uma comparação semelhante precisar ser alcançada de maneira semelhante ao ITM, devido à limitação do modelo de interação de torre única, a complexidade computacional do modelo aumentará para O ( N 2 ) \mathcal{ O}(N^2)O ( N2 ), o que não é aceitável. Além disso, a perda de ITM para alinhamento semântico na granularidade das imagens não é comparável à sua eficiência, sem falar no MLM modelado na granularidade dos blocos visuais.

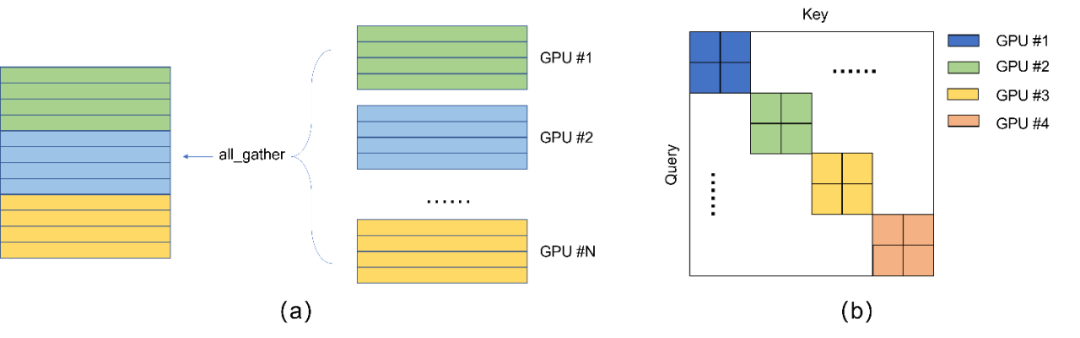
A partir da análise acima, não é difícil saber que a capacidade de alinhamento semântico eficiente do CLIP depende do grande número de amostras negativas, e o número de amostras negativas é associado ao tamanho das amostras negativas. No CLIP, isso batch sizeé all_gatherrealizado através da capacidade de comunicação distribuída do framework. Nós a apresentamos brevemente neste artigo. all_gatherÉ possível agregar vetores de diferentes GPUs. Consulte torch.distributed.all_gather[58] para obter detalhes. Observe que este processo não propagará gradientes em diferentes GPUs. Os gradientes só podem vir da máquina local. Consulte [59] para obter detalhes. Todo o processo, conforme mostrado na Fig. 6.3 (a), all_gatherreunirá vetores de diferentes GPUs, assumindo que batch sizeo tamanho de cada GPU é NNN , um total deKKK GPUs, então obatch sizetamanho agregado pode ser considerado comoKN KNK N . Mas observe que comoall_gathero mecanismo em si não passa pelo gradiente, além doNNN amostras têm gradientes, outros( K − 1 ) N (K-1)N( K−1 ) N amostras só podem ser consideradas como constantes para participar da comparação, conforme mostrado na Fig. 6.3 (b), apenas as amostras dos blocos na diagonal possuem gradientes, e essas amostras são todas vetores nativos em cada GPU.
CLIP的贡献点除了超大batch size的应用外,另外是采用了海量的互联网带噪图文数据,而不是人工精心标注的数据,我们得了解其是如何进行数据采集的。作者在英语维基百科上采集了50万个基础词,这些词都是出现过起码100次的高频词汇,同时在互联网尽可能地采集了大量的图文对数据,通过判断文本中的词汇是否在这50万基础词中进行数据的筛选,同时进行了数据的平衡,使得每个基础词上大概有2万个图文对。最终收集得到了4亿个图文对。我们不难发现这个过程由于对基础词的频次进行了筛选,因此都是一些高频的视觉概念才得以收集。
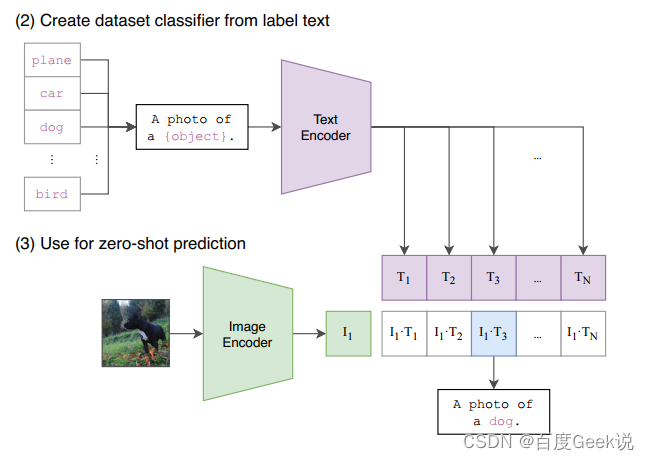
对于笔者而言,CLIP最为震撼的是其zero-shot能力和few-shot能力,其zero-shot性能甚至在某些场景能超越监督训练后的resnet50,真是让人震惊。而且,对于搜索场景而言,本身就容易受到长尾分布的影响,海量样本无法通过人工进行细致标注,强大的zero-shot和few-shot能力在搜索场景中将发挥重要的作用。我们进一步观察CLIP是如何去进行zero-shot任务的。如Fig 6.4所示,考虑到大部分的数据集的标签都是以单词的形式存在的,比如“bird”,“cat”等等,然而在预训练阶段的文本描述大多都是某个短句,为了填补这种数据分布上的差别,作者考虑用“指示上下文”(guide context)对标签进行扩展9。以Fig 6.4为例子,可以用a photo of a <LABEL>.作为文本端的输入,其中的<LABEL>恰恰是需要预测的zero-shot标签。在预测阶段,以分类任务为例子,对所有可能的分类类别文本对<LABEL>进行替代,得到一个CLIP的图文打分,然后将其中最高打分作为最终的预测类别。
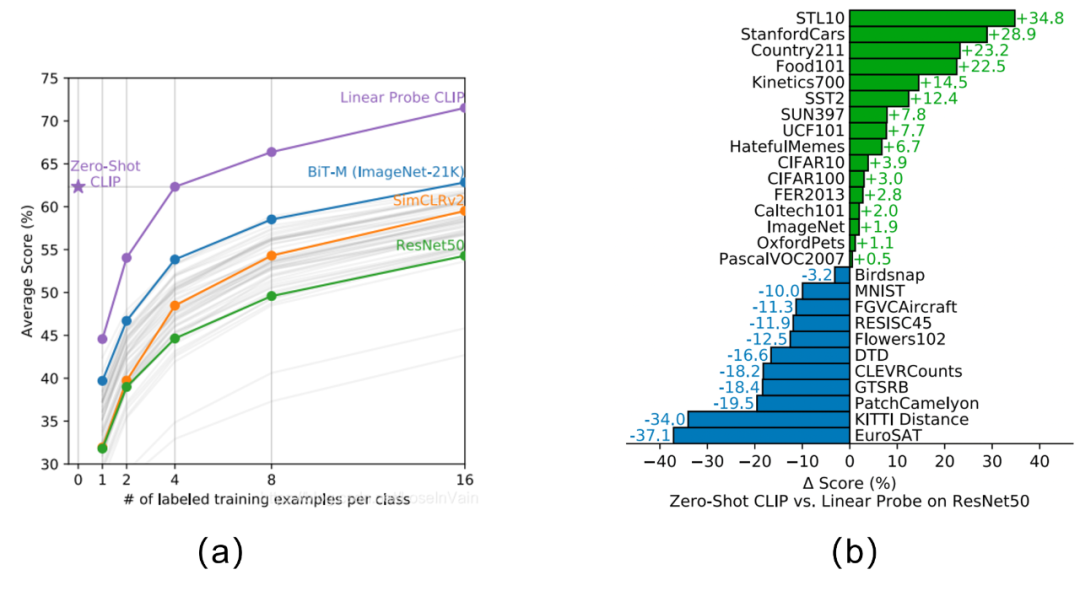
基于这种评估方式,以分类任务为例子,其zero-shot与强监督模型的对比结果见Fig 6.5 (b),对比的模型是强监督的resnet50(在linear probe的评估下[60]),我们发现其在一些数据集上其zero-shot能力甚至能比肩/超过强监督模型。CLIP的zero-shot和few-shot与其他模型的zero-shot/few-shot对比见Fig 6.5 (a),我们发现几个结论:
- zero-shot CLIP已经能够比肩16 shot的BiT-M了。
- few-shot CLIP性能远超其他few-shot模型。
- zero-shot CLIP能够比肩4 shot CLIP,这说明了提供了少量的样本(<4)就对CLIP模型进行finetune可能并不是一个好的做法,有可能会打乱模型在预训练阶段的语义对齐结果,从而影响其泛化性能。
当然,CLIP的论文原文是一个长达40多页的超长论文,里面有着非常详尽的试验分析,在此就不展开了,有兴趣的读者不妨去原文一睹CLIP的风采。总结来看,我们以下归结下CLIP的优点和缺陷,是的,CLIP即便有着革命性的成就,同样也是有缺陷的,而对这些缺陷的改进则引出了后续的一系列工作。
CLIP为什么惊艳?
- 在zero-shot和few-shot任务中的极致性能。
- 能够利用互联网中的海量带噪声数据,避免了对人工标注数据的依赖。
- 大规模对比学习能够实现良好的跨模态语义对齐。
CLIP的缺陷?
- 粗粒度的图片与文本打分,无法建模细粒度的视觉信息:在CLIP中是采用图片粒度与文本粒度进行匹配,形成图文粒度的打分的,在这种粒度下,理论上我们无法对文本和图片中的细粒度语义进行建模。
- Difícil de conseguir a fusão semântica : O método de aprendizagem do CLIP se concentra principalmente no alinhamento semântico, mas é difícil realizar a fusão semântica. Por exemplo, pode haver imagens de "gato no sofá", "gato no chão" e "gato no tapete" em nosso conjunto de dados, mas raramente vemos imagens de "gato na cabeça". só pode ser resolvido por fusão semântica, enquanto CLIP tem dificuldade em modelar semânticas composicionais esparsas.
- Concentre-se em conceitos semânticos visuais de alta frequência : uma vez que o vocabulário alvo foi rastreado em alta frequência no CLIP, é concebível que os conceitos visuais obtidos sejam alguns conceitos semânticos de alta frequência.
- Concentre-se no corpus em inglês : como os dados são rastreados principalmente da comunidade inglesa, faltam multilíngues, especialmente as expectativas chinesas.
- Requer muitos recursos de GPU para treinamento : o CLIP aumenta o número de amostras negativas aumentando o tamanho do lote, e aumentar o tamanho do lote requer um mecanismo no treinamento distribuído
all_gather, portanto, uma grande quantidade de recursos de GPU é necessária para aumentar o tamanho do lote e então Para aumentar o número de amostras negativas, as restrições de recursos obviamente limitam a possibilidade de aumentar ainda mais o número de amostras negativas.
Essas vantagens e desvantagens do CLIP inspiraram uma série de maravilhosos trabalhos multimodais no acompanhamento, vamos fazer uma pausa primeiro e depois continuar a jornada multimodal.
ALINHAR
ALIGN: A Large-scale ImaGe and Noisy-text embedding feature (ALIGN: A Large-scale ImaGe and Noisy-text embedding) [17] Com base no CLIP, este trabalho coloca restrições mais relaxadas nos dados pré-treinamento usados, de modo que o pré-treinamento A escala dos dados de treinamento atingiu impressionantes 1,8 bilhões de níveis. No ALIGN, o autor não restringe mais a condição da semântica de alta frequência, mas rastreia os dados do par imagem-texto o máximo possível da Internet e usa apenas um método de filtragem de dados muito simples. Esse tipo de filtragem de dados inclui:
- Filtre imagens com tamanho muito pequeno, que geralmente são imagens sem sentido.
- Filtra o texto muito curto, que geralmente não tem sentido.
- Exclua algum texto gerado automaticamente, como tempo de filmagem e assim por diante.
Neste trabalho, os indicadores do conjunto de dados natural são melhores do que o CLIP (senão o artigo não será publicado, certo :P), mas o autor acha que deveria ser dada mais atenção à parte de análise de resultados, e o autor realizou vários experimentos para visualizar seus resultados de alinhamento semântico. Conforme mostrado na Figura 6.6, a configuração experimental de (ab) é assim, dado um gráfico x \mathbf{x}x , a feição da torre de imagem f ( x ) ∈ RD f(\mathbf{x}) \in \mathbb{R}^{D} deseu modelo ALIGNf ( x )∈RD , dado um pedaço de textot \mathbf{t}t (como "azul", "roxo"...), o recurso de torre de texto g ( t ) ∈ RD g(\mathbf{t}) \in \mathbb{R}^{D} deseu modelo ALIGN pode também ser obtidog ( t )∈RD. _ Então, para uma determinada imagem e texto alvo, seus atributos podem ser "editados". A edição aqui se reflete na adição ("+") ou remoção ("-") dos atributos na imagem através da descrição do texto. O método específico é usar o recurso de torre de imagem para subtrair/adicionar o recurso de torre de texto10,ou seja,f ( x ) − g ( t ) ∈ RD , f ( x ) + g ( t ) ∈ RD f(\mathbf{x } )-g(\mathbf{t})\in \mathbb{R}^{D}, f(\mathbf{x})+g(\mathbf{t})\in \mathbb{R}^{D }f ( x )−g ( t )∈RD ,f ( x )+g(t)∈RD,然后在图片库里用增减后的特征去进行最近邻检索,得到最终的图片。如Fig 6.6 (a)所示,其能对玫瑰的颜色进行改变,回想到我们第0x00章所介绍的基础视觉元素,我们就能发现这其实是“属性”(Attribution)的对齐能力。不仅如此,Fig 6.6(a)的第三个例子能对“from distance”这种“关系”(Relation)概念进行感知,证明了其对“关系”建模的语义对齐能力。我们再看到Fig 6.6(b)的例子,我们会发现其不仅能对视觉属性、视觉关系进行对齐,而且还能对“视觉实体”概念进行对齐,否则其不能对图片中去掉“flowers”、添加“rose”等编辑产生响应。因此,Fig 6.6 (a)(b)实验其实直观地展示了大规模对比学习模型的强大语义对齐能力。
不仅如此,我们再看到Fig 6.6 ©(d)试验,这俩试验是通过固定文本加上一些属性,比如“detail”、“on a canvas”去检索图片,这个实验设置比前者简单些。我们不难发现,ALIGN模型除了能对视觉实体、属性、关系进行对齐外,似乎还有建模更复杂的视觉语义的能力,比如画风(“in black and white”),细粒度的视角(“view from bottom”、“view from top”…),这种能力可能是基础语义概念的组合,比如黑白画风多少可以拆分为“黑色+白色”的基础视觉属性组合,但是笔者仍然觉得对细粒度的视角关系有着如此好的感知能力,真的是非常神奇,也许基础视觉概念的组合真的是对复杂视觉语义的感知基础?!

FILIP
Depois de nos maravilharmos com a poderosa capacidade de alinhamento semântico do modelo de aprendizado contrastivo em grande escala, vamos olhar novamente para a capacidade de modelagem refinada (fine-grained) que falta ao CLIP. O autor já analisou por que o CLIP não tem essa capacidade. Sem ela, o CLIP comprime diretamente texto e imagens em um vetor ao calcular a semelhança entre imagens e textos. E se não for compactado em um vetor, mas em vários vetores? De fato, esta é a maneira mais direta de aliviar a modelagem grosseira do CLIP, e esta é exatamente a ideia do FILIP (Fine-grain interativo language-image pretraining) [39].
Discutimos na postagem do blog [61] antes que na correspondência de torre de imagem-texto, alguns objetos com caudas longas e formas pequenas podem ser ignorados durante o processo de treinamento devido à necessidade de atualizar o vetor da torre de imagem com antecedência. , resultando na falta de recursos de correspondência refinada ao combinar imagens e textos. Para resolver este problema, precisamos fornecer ao modelo a capacidade de interagir online com imagens e textos e extrair as informações de cada região das imagens de alguma forma (o Detector ROI detecta cada região ROI ou simplesmente divide o patch , como o ViT faz) e, em seguida, interagir com cada área do texto e da imagem, para que o modelo tenha a capacidade de explorar algumas informações refinadas na imagem. Tomando o primeiro método como exemplo, conforme mostrado na Fig. 6.7, se o Detector ROI for usado para extrair primeiro a área ROI da imagem, conforme mostrado na caixa vermelha, a correspondência online do texto "o homenzinho amarelo na mesa amarela" é executada, ou seja, pode ser alcançada uma combinação refinada de lacaios na cena.
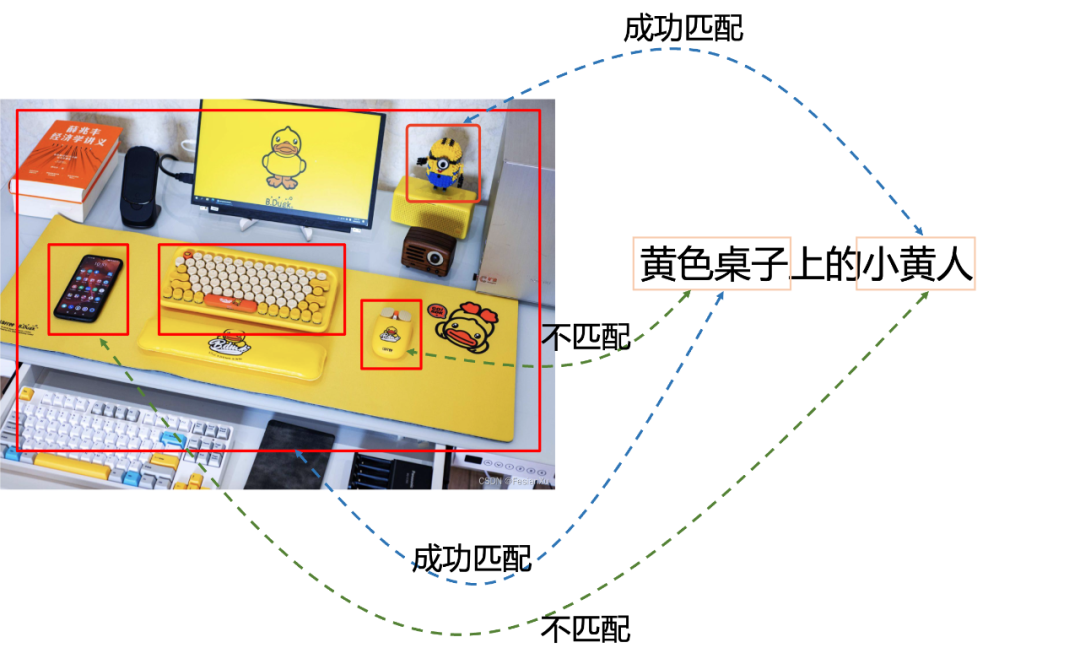
Obviamente, essa premissa é que existe um detector de ROI bom o suficiente e sua complexidade computacional também é muito cara, o que é um fardo relativamente grande para aplicativos on-line, como pesquisa de imagens. A FILIP usa um método mais direto e inteligente para alcançar a interação online. O método é "Late Interaction (Late Interaction)", tentando mover a operação interativa o mais longe possível, para que os resultados do front-end do pipeline possam ser atualizados • Reduza o custo das interações online.
Conforme mostrado na Fig. 6.8, o codificador de imagem do FILIP é o ViT. Após a imagem de entrada ser simplesmente dividida em blocos, ela é mapeada linearmente e inserida no Transformer. A saída é o vetor de incorporação correspondente a cada Patch de imagem. O lado do texto também usa Transformer.A saída é a incorporação de cada token. Se x eu x^ euxI representa a amostra da imagem,x T x^TxT representa uma amostra de texto, entãoxi I x_i^IxeueuIndica o segundo ii da imagem no lotei amostras,xi T x_i^TxeuTRepresenta o ii do texto no lotei amostras, pares de amostras com o mesmo subscrito{ xi I , xi T } \{x_i^I, x_i^T\}{
xeueu,xeuT} Achamos que é um par de amostras positivas, e os pares de amostras com subscritos diferentes{ xi I , xj T } \{x_i^I, x_j^T\}{
xeueu,xjT} consideramos como um par de amostras negativas. Comf θ ( ⋅ ) f_{\theta}(\cdot)feu( ⋅ ) representa o codificador da imagem,g ϕ ( ⋅ ) g_{\phi}(\cdot)gϕ(⋅)表示文本编码器,在不存在交互的双塔匹配模型中,如CLIP和ALIGN中,第 i i i个和第 j j j个样本间的相似度定义为:
s i , j I = s i , j T = f θ ( x i I ) T g ϕ ( x j T ) (6-7) s_{i,j}^I = s_{i,j}^T = f_{\theta}(x_i^I)^{\mathrm{T}} g_{\phi}(x_j^{T}) \tag{6-7} si,jI=si,jT=fθ(xiI)Tgϕ(xjT)(6-7)
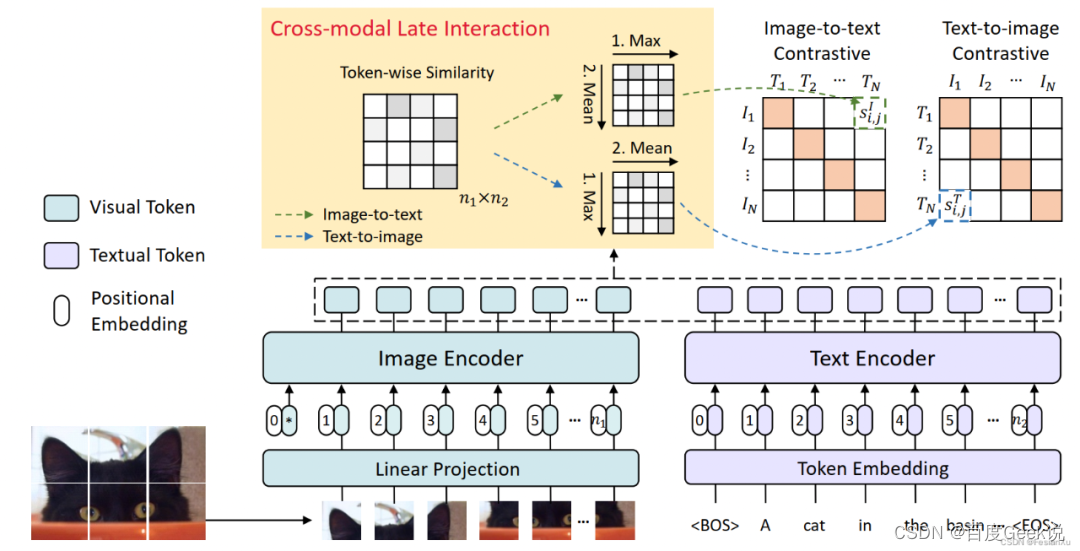
其中 f θ ( x i I ) ∈ R d , g ϕ ( x j T ) ∈ R d f_{\theta}(x_i^I) \in \mathbb{R}^{d}, g_{\phi}(x_j^{T}) \in \mathbb{R}^{d} fθ(xiI)∈Rd,gϕ(xjT)∈Rd , seja um codificador de imagem ou um codificador de texto, apenas um vetor de recurso é produzido para a mesma imagem/texto e sua similaridade gráfica é calculada calculando a similaridade do cosseno, que obviamente é um Cálculo de similaridade global (Global). No FILIP, o ViT e o Text Transformer podem ser usados para gerar embeddings "exclusivos" para cada token de imagem e token de texto (que podem ser considerados como informações locais refinadas para cada modalidade), assumindo n 1n_1n1e n 2 n_2n2são os iiA amostra de imagem i e o jjthO número de tokens de j amostras de texto, entãof θ ( xi I ) ∈ R n 1 × d , g ϕ ( xj T ) ∈ R n 2 × d f_{\theta}(x_i^I) \in \mathbb{ R}^{n_1 \times d}, g_{\phi}(x_j^{T}) \in \mathbb{R}^{n_2 \times d}feu( xeueu)∈Rn1× d ,gϕ( xjT)∈Rn2× d . Como calculamos oiieu ejjj个样本间的相似度呢?此时就体现了迟交互的作用,对于第 i i i个图片的第 k k k个token而言,分别计算其和第 j j j个文本样本的所有 n 2 n_2 n2个token间的相似程度,并且挑选其中相似度最大的打分,作为第 i i i个图片第 k k k个token的打分代表,这个方式作者称之为『逐令牌最大相似度(token-wise maximum similarity)』。
max 0 ≤ r < n 2 [ f θ ( x i I ) ] k T [ g ϕ ( x i T ) ] r (6-8) \max_{0 \leq r \lt n_2} [f_{\theta}(x_i^I)]_k^{\mathrm{T}} [g_{\phi}(x_i^T)]_r \tag{6-8} 0≤r<n2max[fθ(xiI)]kT[ gϕ( xeuT) ]r( 6-8 )
Claro, para amostras de imagens iiTanto quanto eu estou preocupado, este é apenas okkthA pontuação máxima de similaridade de k tokens, e temosn 1 n_1n1token de imagem, então este n 1 n_1n1Calcule a média das pontuações máximas de similaridade.
si , j I (xi I , xj T ) = 1 n 1 ∑ k = 1 n 1 [ f θ ( xi I ) ] k T [ g ϕ ( xi T ) ] mk I (6-9) s_{i, j}^I(x_i^I,x_j^T) = \dfrac{1}{n_1} \sum_{k=1}^{n_1} [f_{\theta}(x_i^I)]_k^{\mathrm {T}} [g_{\phi}(x_i^T)]_{m_{k}^{I}} \tag{6-9}seu , jeu( xeueu,xjT)=n11k = 1∑n1[ feu( xeueu) ]kT[ gϕ( xeuT) ]mkeu( 6-9 )
ondemk I m_{k}^ImkeuIdentifica o índice de sua máxima similaridade, ou seja, mk I = arg max 0 ≤ r < n 2 [ f θ ( xi I ) ] k T [ g ϕ ( xi T ) ] r m_k^I = \arg\ max_{0\leq r \lt n_2} [f_{\theta}(x_i^I)]_k^{\mathrm{T}} [g_{\phi}(x_i^T)]_rmkeu=ar gmáximo0 ≤ r < n2[ feu( xeueu) ]kT[ gϕ( xeuT) ]r, a fórmula (6-9) é a medida de similaridade do lado imagem-texto, da mesma forma, também podemos definir a medida de similaridade si , j T ( xi T , xj I ) s_{i,j }^T(x_i^ T,x_j^I)seu , jT( xeuT,xjeu)。 注意到si , j I ( xi I , xj T ) s_{i,j}^I(x_i^I,x_j^T)seu , jeu( xeueu,xjT)不一定等于si , j T ( xi T , xj I ) s_{i,j}^T(x_i^T,x_j^I)seu , jT( xeuT,xjeu) , ou seja, para interações baseadas em similaridade máxima, a similaridade cross-modal não é necessariamente simétrica, o que é diferente do CLIP.
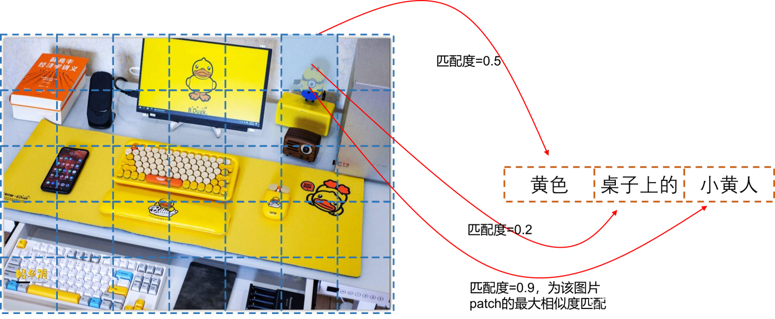
Em seguida, observamos visualmente os resultados refinados do FILIP. O autor adotou o método Prompt Learning e otimizou o modelo Prompt para o conjunto de dados. Este artigo não será expandido. No artigo, o autor visualizou os resultados da correspondência refinada de imagens e textos, conforme mostrado na Fig 6.10, onde os rótulos são "Balloon", "Lifeboat", "Small white butterfly" )", "Electric Iocomotive (electric locomotiva)", e o número atrás da etiqueta indica a posição de uma determinada palavra da etiqueta no modelo de etiqueta. Por exemplo, o modelo aqui é
Modelo de etiqueta: uma foto de um {label}
Quando o rótulo é "Pequena borboleta branca", o modelo de rótulo é "uma foto de uma pequena borboleta branca", pequeno é o 5º no modelo, branco é o 6º e borboleta é o 7º. De acordo com o método de interação descrito acima, encontramos o ID de posição do modelo com a correspondência máxima de similaridade entre cada patch de imagem e a palavra do modelo de rótulo e, em seguida, destacamos o ID de posição da posição do rótulo entre esses IDs de posição, desenhando assim Os resultados são mostrado na Fig. 6.10. Podemos descobrir que alguns desses objetos de rótulo são muito refinados. Por exemplo, a proporção visual de balões na imagem original é muito pequena. Os resultados do CLIP são consistentes com nossas expectativas e não há resposta a essa precisão objetos granulados. O resultado do FILIP pode responder à parte do balão no remendo da figura. O FILIP pode não apenas responder a objetos de granulação fina, mas também tem um bom efeito em objetos grandes. Conforme mostrado na Fig. 6.10 ©, a borboleta ocupa mais da metade da imagem. Neste momento, o efeito de correspondência do FILIP também pode exceda a do CLIP.

Wen Lan
我们在介绍CLIP的一节中,已经知道了通过增大负样本数量可以有效地提高对比学习的效率。然而CLIP也好,ALIGN也罢,这些方法都属于是Table 2.2中所提到的端到端方法,其负样本数量和batch size是耦合在一起的,而提高batch size的代价就是珍贵的硬件资源,有什么方法能够将batch size和负样本数量进行解耦呢?我们在第0x01章其实介绍过类似的情况,MoCo就是一种通过维护负样本队列和动量更新编码器,从而实现batch size和负样本数量解耦的方法,只不过MoCo是应用在图片单模态的自监督建模的,这个思想是否能够迁移到多模态呢?
WenLan [18]就是这样的一种方法,可以视为是MoCo在图文多模态上的延伸,由于图文多模态模型具有图片和文本两个模态,两个模态都需要独立维护一个负样本队列,因此有两个负样本队列。并且,由于在MoCo中,只有Query编码器是进行梯度更新的,而Key编码器是进行动量更新的,那么在多模态模型中,我们现在有Image Encoder和Text Encoder两种模态的编码器,让谁充当Query编码器进行梯度更新,让谁充当Key编码器进行动量更新呢?答案就是在WenLan中同时存在两套Query-Key编码器,在第一套编码器中,由Image编码器充当Query编码器,Text编码器充当Key编码器;在第二套编码器中,由Text编码器充当Query编码器,由Image编码器充当Key编码器。
我们用框图详细解释下整个流程,我们以其中一套编码器 f I , f m T f^{I}, f^{T}_m fI,fmTComo exemplo, conforme mostrado na parte superior da Fig 6.11, supondo que o tamanho do lote da imagem e do texto seja MMM_ _ ondeQT ∈ RD × KQ^T\in\mathbb{R}^{D \times K}QT∈RD × K é a fila de amostra negativa,KKK é o tamanho da fila,DDD é a dimensão do recurso. z I ∈ RM × D z^{I}\in\mathbb{R}^{M\vezes D}zEU∈RM × D é a imagem depois def I f^IfI A saída do recurso após o codificador (Codificador de consulta),z T ∈ RM × D z^T\in\mathbb{R}^{M \times D}zT∈RM × D é o texto correspondente apósfm T f^T_{m}fmTSaída de recurso após o codificador (aqui Codificador de chave). Defina o operador ⨂ \bigotimes⨂为:
a ⨂ b = ∑ j ( a ⋅ b ) ij ∈ RM × 1 a ∈ RM × D , b ∈ RM × D (6.10) a \bigotimes b = \sum_{j} (a \cdot b)_{ij} \in\mathbb{R}^{M\vezes 1}\\ a \in\mathbb{R}^{M\vezes D}, b\in\mathbb{R}^{M\ vezes D} \tag{6.10}a⨂b=j∑( um⋅b )eu∈RM × 1a∈RM × D ,b∈RM × D( 6.10 )
Pode-se descobrir que z I ⨂ z T z^I \bigotimes z^TzEU⨂zT está marcando amostras positivas, ondea ⋅ b ∈ RM × D a \cdot b \in \mathbb{R}^{M \times D}a⋅b∈RM × D éelement-wisea multiplicação e, finalmente, a entrada atualMMM amostras são pontuadas como amostras positivas e o código de cálculo é mostrado no Código 6.1; ez I ⋅ QT z^I \cdot Q^TzEU⋅QT é usar a fila de amostra negativaQTQ^TQT executa a pontuação da amostra negativa. Finalmente,axisapós unir o último, as pontuações de amostra positiva e negativaSI 2 T ∈ RM × ( 1 + K ) \mathbf{S}_{I2T}\in\mathbb{R}^{M \times (1+K )}Seu 2 T∈RM × ( 1 + K ) , onde a primeira dimensão é a pontuação positiva da amostra e o restanteKKA dimensão K classifica as amostras negativas. Então a perda pode ser calculada através da perda de entropia cruzada para obterLI 2 T \mathcal{L}_{I2T}eueu 2 T. Após a conclusão do cálculo de perda, os recursos calculados pelo codificador de chave são enfileirados na fila de amostra negativa para atingir o objetivo de atualizar a fila de amostra negativa. Observe que no processo de implementação específico aqui, z T z^T em todas as GPUs precisa serzT realiza todas as coletas, e o código pode se referir à implementação de MoCo [63].
l_pos = torch.einsum('nc,nc->n', [zI, zT]).unsqueeze(-1) # 一个batch中的M个正样本打分计算,大小为M x 1
l_neg = torch.einsum('nc,ck->nk', [zI, QT.clone().detach()]) # 一个batch中的所有样本和负样本队列进行负样本打分,大小为M x K
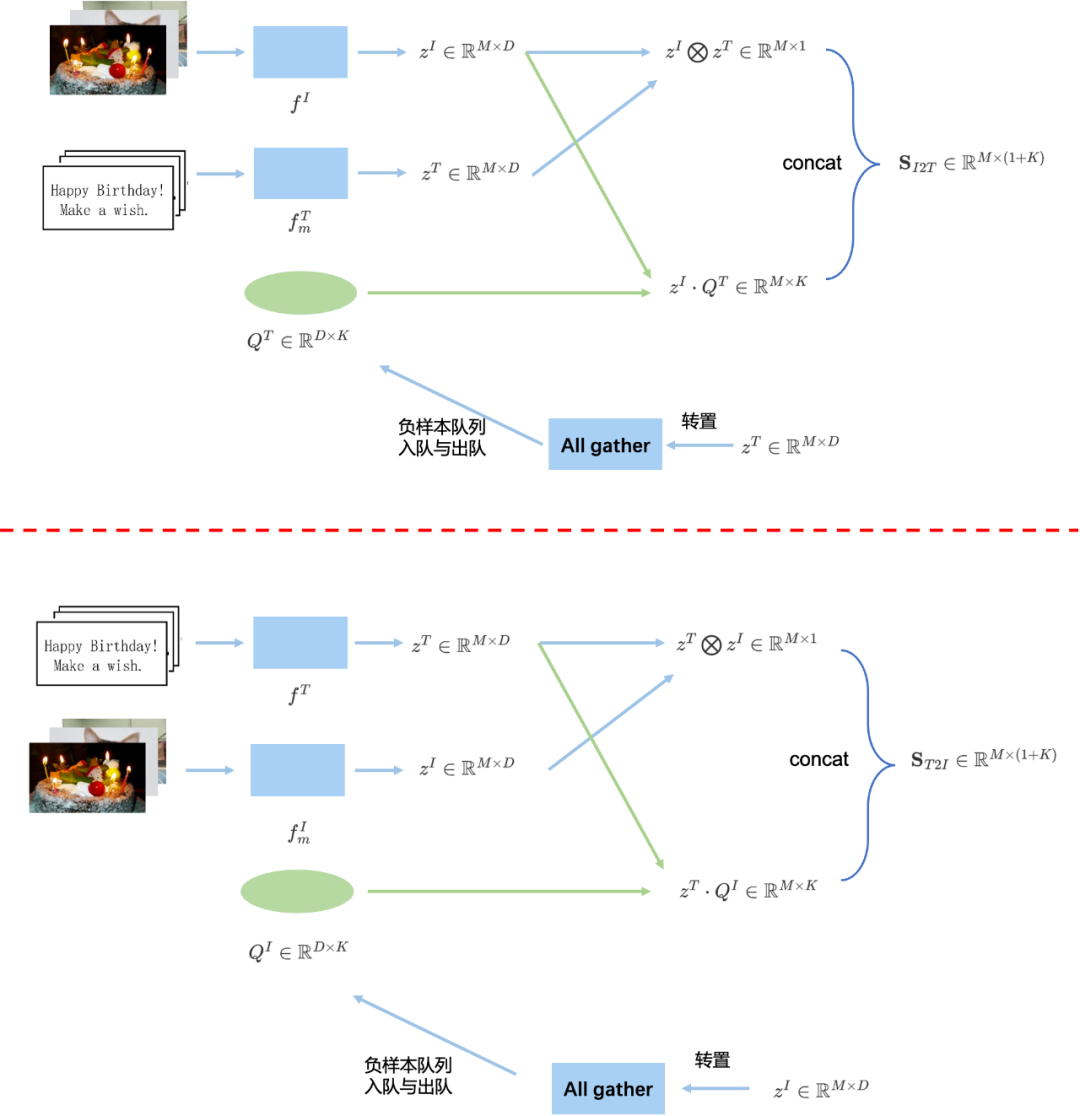
Claro, este é apenas um conjunto de codificadores. Se outro conjunto de codificadores for considerado, o diagrama de blocos geral é mostrado na Fig. 6.11. Por meio de outro conjunto de codificadores, podemos obter a perda LT 2 I \mathcal{L}_ { T2I}euT2 I_ _, adicione as perdas dos dois codificadores para obter a perda final:
L = LI 2 T + LT 2 I (6.11) \mathcal{L} = \mathcal{L}_{I2T}+\mathcal{L}_{ T2I } \tag{6.11}eu=eueu 2 T+euT2 I_ _( 6.11 )
com subscritojjj significa indexar o vetor, então essas duas partes da perda podem ser refinadas e expressas como:
LI 2 T = − ∑ j log exp ( zj I ⋅ zj T / τ ) exp ( zj I ⋅ zj T / τ ) + ∑ n T ∈ QT exp ( zj I ⋅ n T / τ ) LT 2 I = − ∑ j log exp ( zj T ⋅ zj I / τ ) exp ( zj T ⋅ zj I / τ ) + ∑ n I ∈ QI exp ( zj T ⋅ n I / τ ) (6.12) \begin{aligned} \mathcal{L}_{I2T} &= -\sum_{j} \log\dfrac{\exp( z^{ I}_{j} \cdot z^{T}_j / \tau)}{\exp(z^{I}_{j} \cdot z^{T}_j / \tau)+\sum_ {n^ T\em Q^T} \exp(z^{I}_{j} \cdot n^T / \tau)} \\ \mathcal{L}_{T2I} &= -\sum_{j } \log \dfrac{\exp(z^{T}_{j} \cdot z^{I}_j / \tau)}{\exp(z^{T}_{j} \cdot z^{I }_j / \tau)+\sum_{n^I \in Q^I} \exp(z^{T}_{j} \cdot n^I / \tau)} \end{alinhado} \tag{6.12 }eueu 2 TeuT2 I_ _=−j∑pouco tempoexp ( zjeu⋅zjT/ t )+∑nT ∈QTexp ( zjeu⋅nt /t)exp ( zjeu⋅zjT/ t ).=−j∑pouco tempoexp ( zjT⋅zjeu/ t )+∑neu ∈Qeuexp ( zjT⋅neu /t)exp ( zjT⋅zjeu/ t ).( 6.12 )
Do diagrama de blocos Fig 6.11, para uma entrada em lote{ BT , BI } \{B^{T}, B^I\}{
BT ,BI }, ele precisa ser alimentado em dois conjuntos de codificadores para cálculo, portanto, a quantidade de cálculo e a memória da GPU são relativamente altas. Além disso, o tamanho da camada oculta de 2560 é usado em WenLan, o que leva ao fato que mesmo no A100 só pode ser aberto na medida em que o tamanho do lote de cada cartão = 16. Ao mesmo tempo, isso também restringe o tamanho da fila de amostras negativas, o que pode ser um ponto que pode ser melhorado no futuro.
Vamos falar sobre sua estratégia de atualização para a fila de amostras negativas. Para cada modalidade, mantemos manualmente uma matriz de fila Q ∈ RD × KQ\in \mathbb{R}^{D \times K} na GPUQ∈RD × K e um ponteiro de filaqueue_ptrpara indicar onde atualizar a fila. Conforme mostrado na Fig. 6.12 (tomando um conjunto de codificadores como exemplo), assumindo que agora temos duas GPUs realizando computação paralela de dados [63] ao mesmo tempo, então o recurso z ∈ RM × D z \ in \mathbb{ R}^{M \vezes D}z∈RM × D precisa entrar na fila de amostra negativaQQQ , neste momento, para atualizar a fila de amostras negativas mais rapidamente, vamos agregar (gather) as features em todas as GPUs, e calcular as agregadasbatch size=G*M, onde G é o número de placas. Neste momento, de acordo comqueue_ptr,Q[:, queue_ptr:queue_ptr+batch_size]os recursos agregados são atribuídos em . Todo o processo também pode ser visto no Código 6.2.
feature_z_gathered = concat_all_gather(feature_z) # 此处汇聚所有GPU上的相同张量。
batch_size = feature_z_gathered.shape[0]
Q[:, queue_ptr:queue_ptr + batch_size] = feature_z_gathered.transpose()
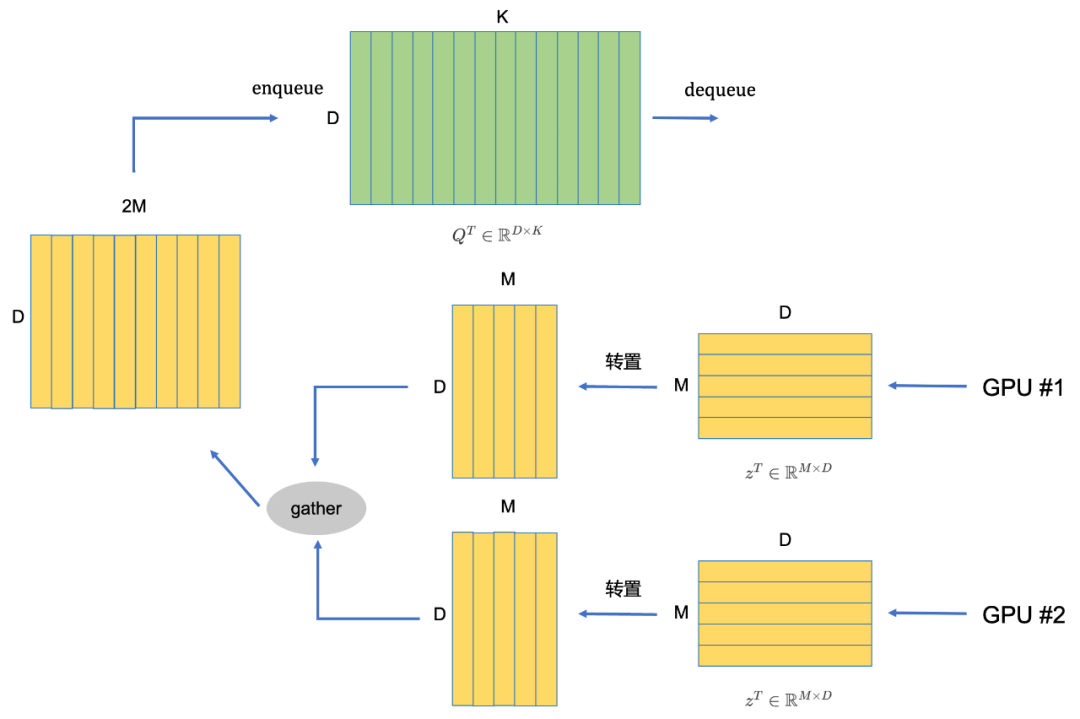
O modelo multimodal não pode resolver muito bem esse tipo de problema. O modelo multimodal pode atingir o objetivo do design desenterrando o conceito visual da imagem. Quanto a aprofundar o fundo humano mais profundo da imagem, a relação entre personagens, obras, etc., você precisa usar o Knowledge Graph (Gráfico de conhecimento) para conectar conceitos. Por exemplo, o terceiro caso da Fig. 6.13, todos nós sabemos que esta é uma cena famosa do filme "A Chinese Journey to the West", mas pelo modelo visual, podemos apenas saber que é "um homem fantasiado e uma garota fantasiada Juntos", obviamente nenhum usuário usará uma frase que não esteja de acordo com o hábito de pesquisa para pesquisar, e a pesquisa mais provável é "Uma jornada chinesa para o oeste se Deus me der outra chance", " Cenas famosas de uma jornada chinesa para o oeste" e similares. Obviamente, esses conceitos não podem ser capturados pelo modelo multimodal, o que pode ser a limitação do modelo multimodal.

WenLan V2 [64] fez algumas otimizações com base no WenLan, principalmente nos seguintes pontos:
-
WenLan v2 usa um conjunto de dados de texto e gráfico de Internet maior para pré-treinamento, com um tamanho de dados de até 650 milhões de pares de gráficos e texto e, como os dados vêm de rastreadores da Internet sem rotulagem manual, os dados estão mais próximos dos dados da vida real, ou seja, dados semânticos visuais fracos. Comparado com os 30 milhões de pares semânticos fracos de imagem-texto usados no WenLan 1.0, esse conjunto de dados é obviamente uma ordem de magnitude maior.
-
Do ponto de vista técnico, este trabalho remove o Detector de Objetos no WenLan, sendo assim um modelo de correspondência gráfico-texto que não depende dos resultados da detecção de objetos. Esta característica torna este trabalho mais adequado para aplicações na indústria atual, pois envolve a detecção de objetos, o que requer mais consumo computacional.
-
O método de cálculo de pontuações de amostras positivas está alinhado com o CLIP e as diferenças específicas são mostradas na Fig. 6.14.
Os detalhes do WenLan v2 não são o foco deste artigo, então não vou apresentá-los mais. Os leitores interessados podem consultar a postagem anterior do blog do autor [65].
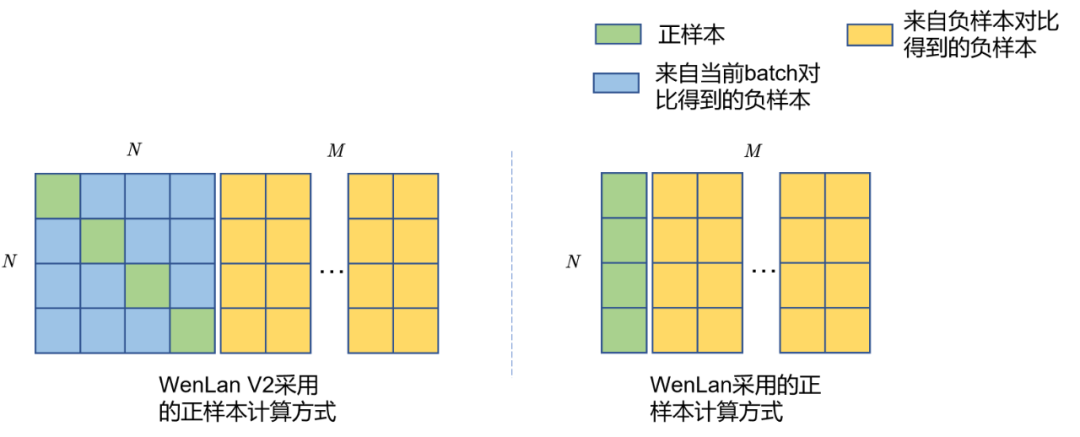
Aceso
Recordando os dados do par gráfico-texto de que falamos antes, idealmente, deve ser como mostrado na figura à esquerda da Fig 6.15. O texto descreve os elementos visuais na imagem objetivamente, para que o modelo possa aprender o alinhamento semântico entre texto e visão. Chamamos esse par de dados de imagem-texto Correlação Forte. No entanto, em dados reais da Internet, texto e gráficos não são tão ideais para os dados. Em muitos casos, a descrição do texto não descreve os elementos visuais da imagem, mas o significado abstrato de toda a imagem, conforme mostrado na Fig. 6.15, como uma descrição de toda a imagem. Uma descrição visual, idealmente deve ser
Existem várias velas acesas em um bolo de frutas (as em negrito são conceitos visuais).
Mas nos dados reais da Internet, muitos são descrições abstratas de toda a cena, como
Feliz aniversário! faça um desejo.
这种抽象描述没有任何视觉元素(实体、属性、关系等),因此我们称之为弱视觉关联(weak correlation)。单纯依靠弱视角关联数据,显然模型无法将没有任何视觉语义的文本对齐到图片中的视觉元素中,这其实也在拷问我们:我们在上文分析中,已经知道了如何对强视觉关联样本建立语义对齐,这种强视觉关联数据都是对具象视觉概念的描述,那么我们如何对抽象的概念进行视觉对齐呢?比如自由、和平、指引、积极向上等等,其实这些抽象概念大多也会有具象的某些视觉联系,比如破碎的枷锁意味着自由,橄榄枝和鸽子象征着和平,灯塔隐含着指引之意,显然抽象概念和对应的隐含视觉概念并不是强视觉关联的,因此也是属于弱视觉关联数据的一种。那么其实又回到了我们一开始的问题,如何对弱视觉关联数据进行跨模态建模呢?问得更基础些,我们如何对弱视觉关联数据进行语义对齐?不回答这个问题,我们将难以对抽象概念进行语义对齐。

一种可能的回答是,通过大量视觉语义相似数据的对比,从中找出文本抽象概念与文本具象概念的对应关系。具体些,如Fig 6.16所示,假如我们想要学习出“生日快乐”与“生日蛋糕”有着强烈的相关性,那么一种可能的做法,在数据量足够多的时候,我们会有很多与蛋糕图片能够配对的文本,这些文本里面可能有抽象概念,如“生日快乐”,也可能有具象概念,比如“生日蛋糕”,而此时生日蛋糕的图片显然都是视觉语义相似的。通过相同的视觉概念作为桥梁,从而可以学习出抽象概念和具象概念的某些关联,正如Fig 6.16的例子所示,这种方法提供了模型学习出“生日蛋糕和生日快乐是相关”的能力。
A premissa do esquema acima é dupla: primeiro, uma grande quantidade de dados é necessária e a Internet é suficiente para fornecê-los; segundo, um grande número de amostras precisa ser comparado ao mesmo tempo. O primeiro ponto é fácil de entender, mas e o segundo ponto? A razão é que apenas comparando um grande número de amostras de uma só vez, a probabilidade de amostrar imagens com conceitos visuais semelhantes pode ser melhorada. Isso significa que precisamos melhorar batch size, e isso é limitado pelo hardware, temos que pensar de outra forma. Não falamos sobre o fato de que a chave é encontrar conceitos semânticos visuais semelhantes? Se nosso aprendizado semântico visual for melhor, podemos corrigir o modelo de torre visual? Uma vez corrigidas as características da torre visual, apenas a torre de texto precisa ser pré-treinada. Nesse momento, o consumo de memória pode ser bastante reduzido e podemos melhorá-lo batch sizepara uma nova altura.
Lock-Image Tuning (LiT) [20] Mesmo que o ponto de partida deste trabalho não seja este, o autor ainda sente que seu método é de grande ajuda para o aprendizado de semântica visual fraca. No LiT, o autor usa alguns conjuntos de dados de imagens de alta qualidade (como JFT-300M, ImageNet-21K, JFT-8B...) para pré-treinar a torre visual. são fixos. Somente o modelo de texto é pré-treinado para o aprendizado comparativo. Como o modelo visual que ocupa mais memória de vídeo não está envolvido neste momento, ele pode ser bastante batch sizeaprimorado. Conforme mostrado na Fig. 6.17, no método CLIP tradicional, os recursos visuais e textuais estão próximos do chamado espaço semântico comum, mas no método LiT, os recursos visuais são fixos e apenas os textuais se moverão em direção os recursos visuais. A direção está mais próxima.
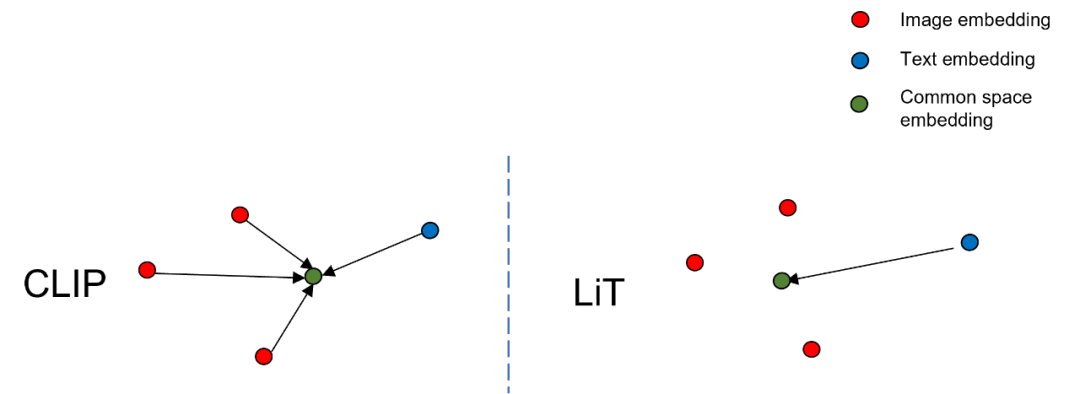
Claro, o autor não tentou apenas consertar o lado visual, mas também tentou consertar o modelo do lado do texto, ou nenhum dos dois. Ao mesmo tempo, sem fixar o modelo do lado visual/texto, o autor também tentou diferentes configurações de aquecimento do modelo e treinamento completo a partir do zero, conforme mostrado na Fig 6.18, onde Lock significa que os parâmetros do modelo são fixos, o Lque Usignifica Os parâmetros do modelo não são fixos e o hot start pré-treinamento é realizado, uo que significa que os parâmetros do modelo não são fixos e o treinamento é realizado do zero (treinar do zero). O autor conduziu uma variedade de experimentos no artigo e finalmente descobriu que, para a classificação zero-shot, a configuração Lu (ou seja, o lado da imagem é fixo, o lado do texto não é fixo e treinado do zero) é a mais eficaz, como o ImageNet da Fig. 6.18 (b) são mostrados os resultados do teste 0-shot.
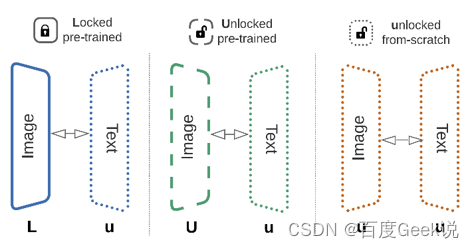
ALBEF
从上文的讨论中我们发现,高效的语义对齐都是利用双塔模型,利用大规模对比学习进行预训练得到的,而双塔模型天然适合在检索、推荐场景等工业场景适用。比如在图文信息检索场景中,我们要衡量用户Query和图片之间的图文相关性。假如图片编码器是 y v = f v ( I ) , y v ∈ R D y_v =f_v(I), y_v \in \mathbb{R}^{D} yv=fv(I),yv∈RD,文本编码器是 y w = f w ( T ) , y w ∈ R D y_w = f_w(T), y_w \in \mathbb{R}^{D} yw=fw(T),yw∈RD , e o conjunto de todas as imagens na biblioteca a serem recuperadas é registrado comoD = { I i ∣ i = 1 , ⋯ , M } \mathcal{D}=\{I_i|i=1,\cdots,M\ }D={ eueu∣ eu=1 ,⋯,M } , a extração de recursos pode ser realizada em todas as imagens com antecedência para formar o recurso de índice de avanço da imagem e construir um banco de dados, que é registrado comoDFI = { fv ( I i ) , i = 1 , ⋯ , N } \ mathcal{D }_{FI}=\{f_v(I_i),i=1,\cdots,N\}DF eu={ fv( eueu) ,eu=1 ,⋯,N } , quando o usuário digita o termo de buscaQQPara Q , você só precisa realizar o cálculo online do codificador de texto na Consulta para obter o recurso de textofw = fw ( Q ) f_w=f_w(Q)fw=fw(Q),然后对待排序的样本进行图片正排库取特征,进行相关性计算(在线计算余弦距离)就可以判断候选图片与Query之间的图文相关程度了。利用双塔模型可以预先建库并且在线计算相关性的特性,可以很大程度上用空间换时间节省很多计算资源,而这也是双塔模型在搜索系统(不仅仅是图文搜索)中被广泛应用的原因之一。
这个世界没有银弹,双塔模型中的图片和文本信息不能在线交互的特性决定了其对一些细致的图文匹配需求无法满足。举个例子,比如去搜索『黑色上衣白色裤子』,那么百度返回的结果如图Fig 6.20 (a) 所示,除去开始三个广告不计,用红色框框出来的Top3结果中有俩结果都是『白色上衣黑色裤子』,显然搜索结果并没有理解到『黑色上衣』和『白色裤子』这两个概念,而是单独对『黑色』『白色』和『上衣』『裤子』这两个属性进行了组合,因此才会得到『白色上衣黑色裤子』被排到Top20结果的情况。而类似的结果同样在谷歌上也会出现,如Fig 6.20 (b)所示。
![![fig-albef-badcase][fig-albef-badcase]](https://img-blog.csdnimg.cn/2ecb8409268c4d23ae23a920f582a9cb.png)
这种多模态匹配细粒度结果不尽人意的原因,很大程度上是双塔模型中的图片编码器和文本编码器无法在线进行交互导致的。可以想象到,我们的图片编码器由于是预先对所有图片提特征进行建库的,那么就无法对所有属性的组合都进行考虑,必然的就会对一些稀疏的组合进行忽略,而倾向于高频的属性组合,因此长尾的属性组合就无法很好地建模。双塔模型这种特点,不仅仅会使得多属性的Query的检索结果倾向于高频组合,而且还会倾向于图片中的一些大尺寸物体,比如Fig 6.21中的小黄人尺寸较小,在进行特征提取的时候,其在整张图片中的重要性就有可能被其他大尺寸物体(比如键盘和显示屏等)掩盖。

Em essência, esses defeitos se devem ao fato de que o aprendizado comparativo do modelo das Torres Gêmeas apenas modela o alinhamento semântico, e já sabemos na discussão do Capítulo 0x00 que o alinhamento semântico é modelar conceitos visuais longos e frios, como combinação. nenhuma vantagem no conceito complexo de , para modelar esses conceitos visuais combinados, temos que introduzir a fusão semântica ao mesmo tempo. Fusão semântica? Quando introduzimos o UNITER, já sabíamos que a maioria das funções de perda do modelo de interação de torre única pode modelar a fusão semântica, como perdas de ITM e MLM, etc. Por que não combinamos o alinhamento semântico e a fusão semântica? Teoricamente, uma das maneiras mais apropriadas é primeiro conduzir um treinamento de alinhamento semântico suficiente para aprender conceitos visuais básicos e, em seguida, usar a fusão semântica para aprender conceitos visuais complexos combinados.
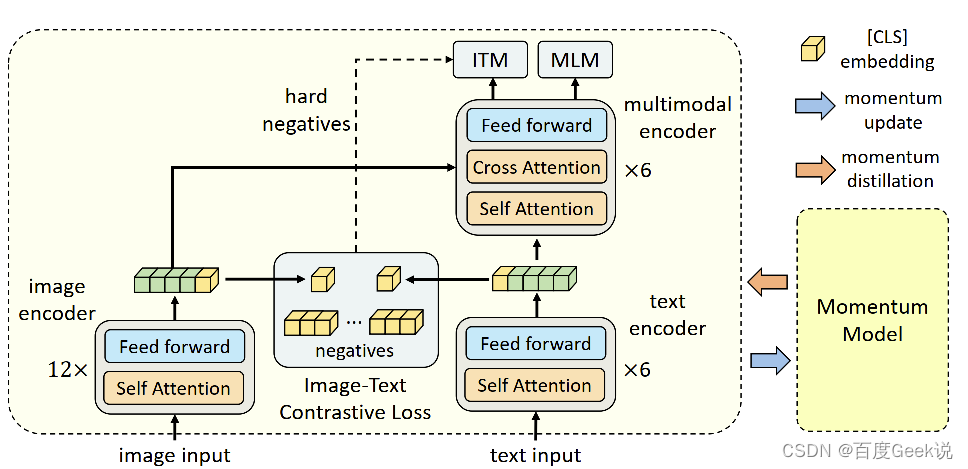
Podemos também formalizar este processo matematicamente, usamos { v CLS , v 1 , ⋯ , v N } \{\mathbf{v}_{CLS},\mathbf{v}_1,\cdots,\mathbf{ v} _N\}{ vC L S,v1,⋯,vn} significa entrada de imagemI \mathbf{I}O resultado da codificação do codificador de imagem de I , também para a entrada de texto I \mathbf{I}Também posso representar o resultado da codificação após seu codificador de texto{ w CLS , w 1 , ⋯ , w N } \{\mathbf{w}_{CLS},\mathbf{w}_1,\cdots,\mathbf{w } _N\}{ wC L S,c1,⋯,cn} . Existem dois tipos de objetivos pré-treinamento:
- Alinhamento Semântico : Aprendizagem Contrastiva Imagem-Texto (ITC) para alinhamento semântico imagem-texto por meio de um codificador modal único (na verdade, um modelo de torre gêmea)
- Fusão Semântica : Os recursos de imagem/texto alinhados semanticamente são interagidos de forma cruzada no codificador multimodal, e a fusão semântica de imagem-texto é realizada por meio das tarefas Masked Language Model (MLM) e Image-Text Matching (ICM).
语义对齐可以通过双塔模型的大规模对比学习进行,其目标是让图片-文本对的相似度尽可能的高,也就是 s = g v ( v c l s ) T g w ( w c l s ) s=g_v(\mathbf{v}_{cls})^{\mathrm{T}}g_w(\mathbf{w}_{cls}) s=gv(vcls)Tgw(wcls),其中的 g v ( ⋅ ) g_v(\cdot) gv(⋅)和 g w ( ⋅ ) g_w(\cdot) gw(⋅)是对[CLS]的线性映射,其将[CLS]特征维度映射到了多模态共同特征子空间。类似于WenLan,在ALBEF模型中,作者同样采用了两个图片/文本样本队列和动量图片/文本编码器,这两个队列维护了最近的动量编码器的 M M M个表征,这些来自于动量编码器的特征表示为 g v ′ ( v c l s ′ ) g_{v}^{\prime}(\mathbf{v}^{\prime}_{cls}) gv′(vcls′) egw ′ ( wcls ′ ) g_{w}^{\prime}(\mathbf{w}^{\prime}_{cls})gc′( wc l s′) . Realize a pontuação de correspondência modal cruzada, conforme mostrado na fórmula (6-13)
s ( I , T ) = gv ( vcls ) T gw ′ ( wcls ′ ) s ( T , I ) = gw ( wcls ) T gv ′ ( vcls ′ ) (6-13) \begin{aligned} s(I,T) &= g_v(\mathbf{v}_{cls})^{\mathrm{T}}g_{w}^{\prime} ( \mathbf{w}^{\prime}_{cls}) \\ s(T,I) &= g_w(\mathbf{w}_{cls})^{\mathrm{T}}g_{v} ^ {\prime}(\mathbf{v}^{\prime}_{cls}) \end{aligned} \tag{6-13}s ( eu ,T )s ( T ,eu )=gv( vc l s)T gc′( wc l s′)=gw( wc l s)T gv′( vc l s′)( 6-13 )
Então pode-se definir a correlação gráfico-texto/texto-gráfico, conforme a fórmula (6-14), ondeNNN ébatch size(este ponto é a implementação do código, alguns desvios do artigo [67])
pmi 2 t ( I ) = exp ( s ( I , T m ) / τ ) ∑ m = 1 M + N exp ( s ( I , T m ) τ ) pmt 2 i ( T ) = exp ( s ( T , I m ) / τ ) ∑ m = 1 M + N exp ( s ( T , I m ) τ ) (6- 14) \begin{aligned} p^{i2t}_{m}(I) &= \dfrac{\exp(s(I, T_m)/\tau)}{\sum_{m=1}^{M+ N} \exp(s(I,T_m)\tau)} \\ p^{t2i}_{m}(T) &= \dfrac{\exp(s(T, I_m)/\tau)}{\ sum_{ m=1}^{M+N}\exp(s(T, I_m)\tau)} \end{alinhado} \tag{6-14}pmeu 2 t( eu )pmt 2 eu( T )=∑m = 1M + Nexp ( s ( eu ,Tm) t )exp ( s ( eu ,Tm) / t )=∑m = 1M + Nexp ( s ( T ,EUm) t )exp ( s ( T ,EUm) / t )( 6-14 )
令yi 2 t ( I ) \mathbf{y}^{i2t}(I)yi 2 t (I)eyt 2 i ( T ) \mathbf{y}^{t2i}(T)yt 2 i (T)representa o rótulo real, e a perda contrastiva imagem-texto (Image-Text Contrastive Loss, ITC) é definida pela perda de entropia cruzada:
L itc = 1 2 E ( I , T ) ∼ D [ H ( yi 2 t ( I ) , pi 2 t ( I ) ) + H ( yt 2 i ( T ) , pt 2 i ( T ) ) ] (6-15) \mathcal{L}_{itc} = \dfrac {1}{ 2} \mathbb{E}_{(I,T) \sim D} [H(\mathbf{y}^{i2t}(I), \mathbf{p}^{i2t}(I) )+H( \mathbf{y}^{t2i}(T), \mathbf{p}^{t2i}(T))] \tag{6-15}eueu sou _=21E( I , T ) ∼ D[ H ( yi 2 t (eu),pi 2 t (eu))+H ( yt 2 i (T),pt 2 i (T))]( 6-15 )
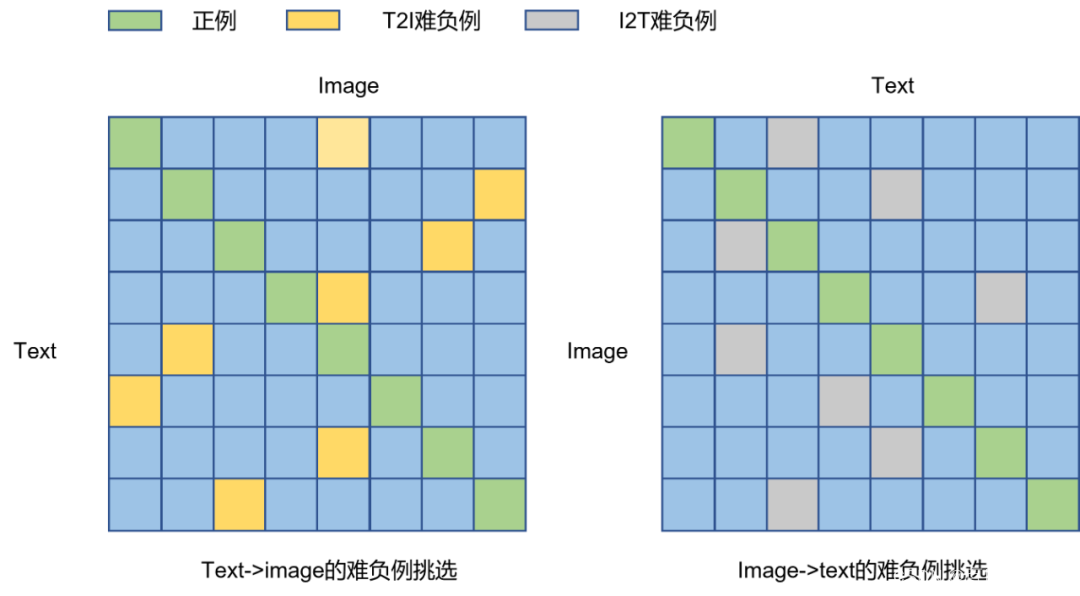
A camada inferior do modelo ALBEF é o alinhamento semântico de torre gêmea, e sua camada superior é a fusão semântica de torre única . A fim de alcançar a fusão semântica, o artigo usa a perda do Masked Language Model (MLM) para modelar pares de amostras positivas . O autor leva 15% 15\%15% de probabilidade de substituir o Token de entrada por um token especial[MASK], sejaT ^ \hat{T}T^ indica o texto mascarado,pmsk ( I , T ^ ) \mathbf{p}^{msk}(I,\hat{T})pm s k (eu,T^ )representa o resultado da previsão do token mascarado eymsk \mathbf{y}^{msk}ym s k representa o rótulo real do token mascarado, então o objetivo do MLM é minimizar a seguinte perda de entropia cruzada:
L mlm = E ( I , T ^ ) ∼ DH ( ymsk , pmsk ( I , T ^ ) ) (6- 16) \mathcal{L}_{mlm} = \mathbb{E}_{(I, \hat{T})\sim D} H(\mathbf{y}^{msk}, \mathbf{ p}^ {msk}(I,\hat{T})) \tag{6-16}eum eu m=E( eu ,T^ )∼DH ( ym s k ,pm s k (eu,T^ ))( 6-16 )
Por meio da modelagem de perda MLM, não apenas o alinhamento semântico entre entidades multimodais pode ser encontrado, mas também a relação semântica composta entre cada entidade. modelo para fundir diferentes entidades. Mineração do relacionamento multimodal entre eles para fazer previsões sobre as entidades mascaradas.
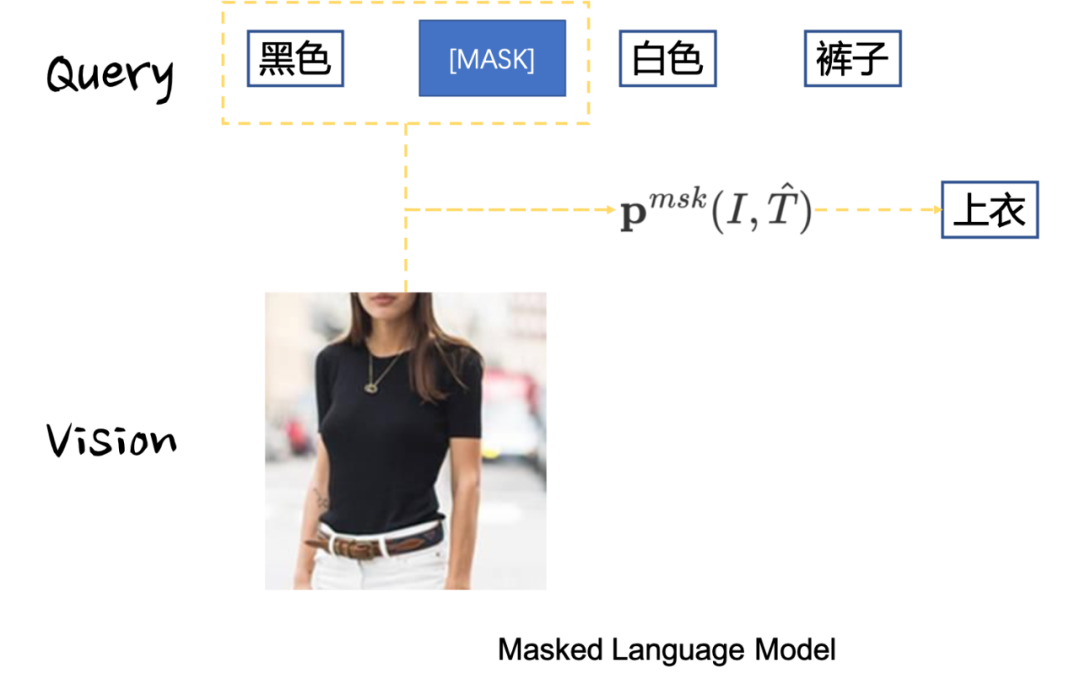
Além da perda de MLM, o artigo também usa correspondência de imagem-texto (ITM) para combinar e aprender amostras negativas difíceis, de modo que se espera que o modelo tenha uma melhor capacidade de distinguir amostras negativas difíceis, de modo a compensar o incapacidade do modelo de torre única.As deficiências da difícil seleção de amostra negativa para melhorar o alinhamento semântico e as capacidades de fusão semântica de modelos multimodais. A base para o autor selecionar amostras negativas difíceis é baseada na pontuação do modelo de torre gêmea. Conforme mostrado na Fig. 6.23, a imagem mais difícil na mesma consulta (com a pontuação mais alta, mas previsão errada) pode ser selecionada, ou a mesma imagem pode ser selecionada A consulta mais difícil em Imagem (no artigo, é obtida por amostragem de acordo com a probabilidade de definir o tamanho da pontuação). A partir disso, podemos obter NNN exemplos positivos e2 N 2N2 N exemplos negativos concretos constituem a entrada da tarefa ITM e sua perda é mostrada na fórmula (6-17).
L itm = E ( I , T ) ∼ DH ( yitm , pitm ( I , T ) ) (6-17) \mathcal{L}_{itm} = \mathbb{E}_{(I,T)\sim D} H(\mathbf{y}^{itm}, \mathbf{p}^{itm}(I,T)) \tag{6-17}eueu sou _=E( I , T ) ∼ DH ( yeu sou , _peu sou (eu, _T ))( 6-17 )
A perda final da etapa pré-treinamento é composta pelas três perdas acima, conforme demonstrado na fórmula (6-18):
L = L itc + L mlm + L itm (6-18) \mathcal{L } = \mathcal{L}_{itc}+\mathcal{L}_{mlm}+\mathcal{L}_{itm} \tag{6-18}eu=eueu sou _+eum eu m+eueu sou _( 6-18 )
A maior parte dos dados gráficos utilizados para o pré-treinamento vem da Internet, geralmente o chamado conjunto de dados semânticos visuais fracos, pode haver algumas palavras no texto que nada têm a ver com a semântica visual do imagem, e a imagem também pode conter Algo não mencionado no texto. Para a perda de ITC, o texto de amostra negativo de uma imagem também pode corresponder à imagem (especialmente se os dados do par imagem-texto vierem de dados de clique do usuário); para a perda de MLM, o token mascarado pode ser outras alternativas de token podem também descrevem a imagem (e podem até ser mais apropriados). O autor acredita que o uso de rótulos para treinamento em tarefas de ITC e MLMone-hotsuprimirá todos os exemplos negativos, independentemente de esses exemplos negativos serem realmente "exemplos negativos". Para resolver este problema, o autor propõe que o codificador de momento pode ser considerado como uma versão de média móvel exponencial (média móvel exponencial) do codificador de modo único/multimodal, e o codificador de momento pode ser usado para gerar tarefas ITC e MLM "Pseudo-rótulo". Pelo codificador de momento, temos a pontuação do codificador de momento:
s′ (I, T) = gv′ ( vcls ′ ) T gw ′ ( wcls ′ ) s′ ( T , I ) = gw ′ ( wcls ′ ) T gv ′ ( vcls ′ ) (6-19) \begin{aligned} s^{\prime}(I,T) &= g^{\prime}_{v}(\mathbf{v}_{cls}^{\ prime} )^{\mathrm{T}} g^{\prime}_{w}(\mathbf{w}_{cls}^{\prime}) \\ s^{\prime}(T,I) &= g^{\prime}_{w}(\mathbf{w}_{cls}^{\prime})^{\mathrm{T}} g^{\prime}_{v}(\mathbf{ v} _{cls}^{\prime}) \end{aligned} \tag{6-19}s’ (eu,T )s’ (T,eu )=gv′( vc l s′)T gc′( wc l s′)=gc′( wc l s′)T gv′( vc l s′)( 6-19 ) o s ′ s^{\prime}
em (6-19)s' substituindo ssna fórmula (6-14)s , obtemos pseudo rótulosqi 2 t , qt 2 i \mathbf{q}^{i2t}, \mathbf{q}^{t2i}qeu 2 t ,qt 2 i , entãoITCM o D ITC_{MoD}I T CM oDDetermine:
L itcmod = ( 1 − α ) L itc + α 2 E ( I , T ) ∼ D [ KL ( qi 2 t ( I ) ∣ ∣ pi 2 t ( I ) ) + KL ( qt 2 i ( T ) ∣ ∣ pt 2 i ( T ) ) ] (6-20) \mathcal{L}_{itc}^{mod} = (1-\alpha)\mathcal{L}_{itc}+\dfrac{ \alpha }{2}\mathbb{E}_{(I,T) \sim D} [KL(\mathbf{q}^{i2t}(I) || \mathbf{p}^{i2t}(I). )) + KL(\mathbf{q}^{t2i}(T) || \mathbf{p}^{t2i}(T))] \tag{6-20}eueu tc _modo _ _=( 1−a ) Leu sou _+2aE( I , T ) ∼ D[ K L ( qi 2 t (I)∣∣pi 2 t (eu))+K L ( qt 2 i (T)∣∣pt 2 i (T))]( 6-20 )
Da mesma forma,MLMM o D MLM_{MoD}M L MM oDA perda pode ser definida como:
L mlmmod = ( 1 − α ) L mlm + α E ( I , T ^ ) ∼ DKL ( qmsk ( I , T ^ ) ∣ ∣ pmsk ( I , T ^ ) ) (6-21 ) \ mathcal{L}_{mlm}^{mod} = (1-\alpha)\mathcal{L}_{mlm} + \alpha\mathbb{E}_{(I,\hat{T}) \ sim D } KL(\mathbf{q}^{msk}(I, \hat{T}) ||\mathbf{p}^{msk}(I, \hat{T})) \tag{6-21 }eum eu mmodo _ _=( 1−a ) Lm eu m+um E( eu ,T^ )∼DK L ( qm s k (eu,T^ )∣∣pm s k (eu,T^ ))( 6-21 )
Por que o codificador de momento pode gerar o chamado "pseudo-rótulo"? Quando a quantidade de dados é relativamente grande, o codificador pode ver pares de dados do mesmo texto e diferentes tipos de imagens em diferentes etapas. Considere uma situação em que há duas entidades patos e laranjas na descrição do texto, em um par de dados{text,image A}a imagem A tem patos e a imagem B com apenas laranjas pode ser considerada um exemplo negativo; em um par de dados{text,image B}Há laranjas em e imagem A com apenas patos pode ser considerado um exemplo negativo. A atualização do codificador por meio do momento pode ser vista como um coeficiente de suavização de tempo γ \gammano processo de atualização do momentoγ{text,image A}, {text, image B} , considera as informações do rótulo das amostrasencontradas em diferentes etapas
ERNIE-WIL 2.0
A maior parte do trabalho anterior coletava apenas informações de legenda para formar pares imagem-texto para pré-treinamento, o que inevitavelmente desperdiça as informações de rich text em imagens da Internet. Conforme mostrado na Fig. 6.25, existem muitos tipos diferentes de informações de texto anexadas às imagens na página da Web, como o título da imagem, as informações de categoria da imagem (que podem ser selecionadas pelo usuário), o contexto informações correspondentes à imagem, etc. Essas informações de texto ou estão mais ou menos relacionadas a imagens e podem ajudar mais ou menos no pré-treinamento. Além disso, você pode até usar o Object Detector para identificar entidades em imagens, marcar imagens e gerar uma série de textos. Ao mesmo tempo, no sistema comercial, o par de amostra de consulta e imagem do usuário também pode ser extraído por meio do sinal de clique <query, image>.
Em ERNIE VIL 2.0 [19], o autor adotou o modelo de duas torres e adotou o método CLIP para all_gatheraumentar o tamanho total do lote para 7168 usando 112 GPUs A100 e operações. E, o mais importante, neste artigo, o autor propôs a "aprendizagem contrastiva multivisão", na qual multivisão se refere à expressão de diferentes perspectivas na mesma modalidade (imagem, texto). . Por exemplo, para imagens, o aumento de imagem (aumento de imagem) pode ser executado em imagens, como agitação de imagem, corte aleatório, etc. Através deste método, imagens de duas perspectivas podem ser geradas, representando a imagem original e a imagem após o aprimoramento da imagem. Para o modo de texto, o autor acredita que, além da legenda, outras informações de texto disponíveis da imagem podem ser consideradas como informações de texto multivisualização. Por exemplo, neste artigo, o autor acredita que as tags da imagem são suas texto multivisualização. Depois, para a legenda da foto, para as tags da foto (que podem ser selecionadas pelo usuário ou geradas por modelos como o Object Detector). Conforme mostrado na Fig. 6.26, em comparação com o aprendizado contrastivo de visão única, as perdas contrastivas podem ser construídas tanto dentro da mesma modalidade quanto entre as modalidades. Conforme mostrado na fórmula (6-22), onde é a combinação de pares de amostras positivas e é a combinação de pares de amostras negativas, onde representa o número da amostra. Conforme mostrado na fórmula (6-23), a modelagem de perda é realizada em cada tipo de par em (6-22) por meio da perda de infoNCE. A estrutura do modelo de todo o ERNIE-VIL 2.0 é mostrada na Fig. 6.26©.
S + = { ( I v 1 i , I v 2 i ) , ( T v 1 i , T v 2 i ) , ( I v 1 i , T v 1 i ) , ( T v 1 i , I v 1 i ) } S − = { ( I v 1 i , I v 2 j ) , ( T v 1 i , T v 2 j ) , ( I v 1 i , T v 1 j ) , ( T v 1 i , I v 1 j ) } , i ≠ j (6-22) \begin{align} S^{+} &= \{(I_{v1}^{i}, I_{v2}^{i}), (T_{v1}^{i}, T_{v2}^{i}), (I_{v1}^{i}, T_{v1}^{i}), (T_{v1}^{i}, I_{v1}^{i})\} \\ S^{-} &= \{(I_{v1}^{i}, I_{v2}^{j}), (T_{v1}^{i}, T_{v2}^{j}), (I_{v1}^{i}, T_{v1}^{j}), (T_{v1}^{i}, I_{v1}^{j})\}, i \neq j \end{align} \tag{6-22} S+S−={(Iv1i,Iv2i),(Tv1i,Tv2i),(Iv1i,Tv1i),(Tv1i,Iv1i)}={(Iv1i,Iv2j),(Tv1i,Tv2j),(Iv1i,Tv1j),(Tv1i,Iv1j)},i=j(6-22)
L ( x , y ) = − 1 N ∑ i N log exp ( ( hxi ) Thyi / τ ) ∑ j = 1 N exp ( ( hxi ) Thyj / τ ) (6-23) L(x , y) = -\dfrac{1}{N} \sum_{i}^N \log\dfrac{\exp((h_{x}^i)^{\mathrm{T}} h_{y}^i /\tau)}{\sum_{j=1}^N \exp((h_{x}^i)^{\mathrm{T}} h_{y}^j/\tau)} \tag{6- 23}L ( x ,y )=−N1eu∑npouco tempo∑j = 1nexp (( hxeu)T hyj/ t )exp (( hxeu)T hyeu/ t ).( 6-23 )
实验结果就不贴出来了,笔者感觉这种方法比较有意思的是,它可以通过多视角文本样本扩充一些抽象实体的语义。如Fig 6.27 所示,对于(a)中的caption提到的“Dinner”,“晚餐”本质上是一个抽象的实体,没有具象化到某一类型具体的食物,而通过Object Detector得到的tag,我们能知道图片中存在西红柿,洋葱,食物等等实体,通过建立caption和tag的关联,可以让模型学习到Dinner的具象化语义。对于Fig 6.27 (b)和©而言,BMW E90是宝马的其中一个型号,而Gatos Manx应该是主人给猫取的爱称。汽车型号这种语义非常稀疏,而猫的姓名更是稀疏无比,在训练样本中甚至可能没有其他共现的文本出现了,这种语义很难学习出来。而通过建立caption和tag的关联,可以让模型学习到BWM E90是一种白色汽车,而Gatos Manx是一只猫(当然这个有风险,也许有人也叫这个名字呢,emm,但是如同“旺财”“福贵”在猫狗上取名的概率更大一样,这样学习出来的bias似乎也并不是没有可取之处呢?)。因此通过多视角文本的多模态预训练方式,可以扩充抽象语义,学习出稀疏语义。这是ERNIE VIL 2.0一文给予笔者最大的启发。

FLIP
Quando discutimos a modelagem auto-supervisionada de modo único antes, mencionamos os modelos MAE e VideoMAE. Não é difícil encontrar na Fig. 2.9 (b), mesmo que a maior parte da área da imagem (80%) esteja mascarada, o pixel Os resultados da reconstrução em nível de suas imagens ainda possuem informações semânticas visuais suficientes. Isso é fácil de entender. A imagem em si é um meio de informação com uma grande quantidade de redundância de informações. Mascarar a maior parte ainda tem informações suficientes para vazar sua informação semântica visual. Portanto, não falta tokenização esparsa em trabalhos anteriores. negócio com. Mencionamos o modelo LiT que corrige completamente os recursos do visual final, então existe um compromisso que pode reduzir o consumo de recursos do modelo visual final e também aprender o modelo visual final ao mesmo tempo? Combinando os fatos e requisitos acima, alguns estudiosos propuseram imitar o MAE, mascarar a imagem de entrada em uma grande área com base no CLIP e usar o bloco de imagem não mascarado como entrada do modelo visual final, reduzindo assim bastante o consumo de recursos Ocupação, essa é a ideia de modelagem do Fast Language-Image Pretraining (FLIP) [24].
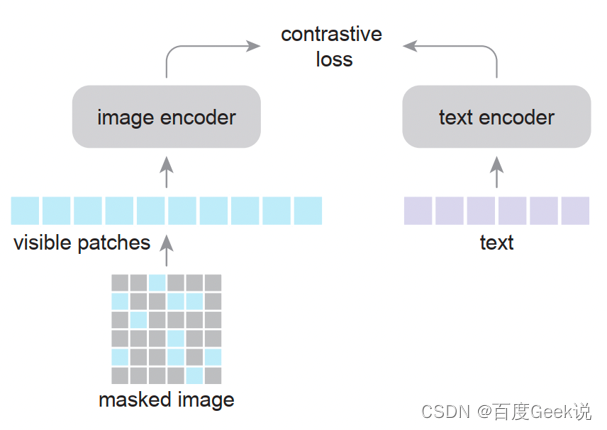
Conforme mostrado na Fig. 6.28, no FLIP, o autor divide uniformemente a imagem em blocos e, após executar o mascaramento aleatório (50%) na maioria deles, as partes não mascaradas são organizadas de acordo com a entrada do codificador de imagem e aprendendo por comparação Através deste método, a memória de vídeo e os requisitos de recursos de computação do modelo do lado da imagem são bastante reduzidos, de modo que pode ser alcançado:
- use um maior
batch size - Adote um modelo final visual maior
- Capacidade de usar conjuntos de dados maiores para pré-treinamento
Como mostrado na Fig. 6.29, após adotar o método FLIP (máscara 50% ou 75%), o mesmo efeito do modelo CLIP original pode ser alcançado em um tempo menor, e melhores resultados podem ser alcançados no mesmo tempo de treinamento. a aceleração é de quase 3,7 vezes.
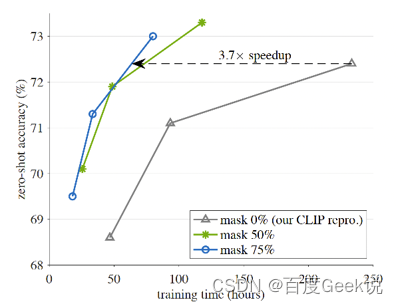
O método do FLIP é muito direto e simples. Sempre manteve o estilo do Sr. Kaiming, e realizou experimentos extremamente detalhados no papel. Aqui apenas extraímos alguns experimentos para análise. Conforme mostrado na Fig 6.30, este é o resultado do teste de ablação zero-shot do FLIP no ImageNet-1K, que explora:
- Efeito da proporção de máscara: Máscaras com proporção de 50% alcançam os melhores resultados e a maioria dos patches de imagem parece ser redundante para o alinhamento semântico do aprendizado contrastivo.
- O impacto do tamanho do lote: FLIP permite que o tamanho do lote seja aberto para 64 K. Descobrimos que, seja a proporção da máscara de 50% ou 75%, quanto maior o tamanho do lote, melhor o efeito.
- Se deve mascarar o texto: O texto é um meio com densidade de informação extremamente alta. Intuitivamente, mascará-lo causará uma grande perda. Pelo experimento (c), isso também é verdade. O efeito de não mascará-lo é o melhor.
- Se deve executar o antimascaramento no estágio de inferência: Para garantir a integridade das informações da imagem no estágio de inferência, a maneira intuitiva é reverter o processo de mascaramento e usar a imagem completa para inferência. Pelo teste (d), o efeito de inferência é o melhor com o método anti-máscara.
- Se deve executar o ajuste fino do antimascaramento: como a operação antimascaramento é usada durante a inferência, para a consistência do pré-treinamento e da distribuição da tarefa de inferência, intuitivamente, uma pequena quantidade de ajuste fino da mesma distribuição deve ser executada após o FLIP o pré-treinamento está concluído. No experimento (e), os autores ajustaram os resultados após o pré-treinamento FLIP com uma pequena quantidade de mascaramento inverso, e os resultados foram realmente melhores do que a linha de base.
- Se deve introduzir tarefas de reconstrução visual: se deve também introduzir perda de reconstrução MAE no processo de aprendizagem contrastiva? O experimento (f) nos diz que não é necessário.Talvez a tarefa de reconstrução do MAE seja tendenciosa para a reconstrução em nível de pixel, e o alinhamento semântico aprendido pelo aprendizado contrastivo não dependa dessa semântica visual de baixo nível.
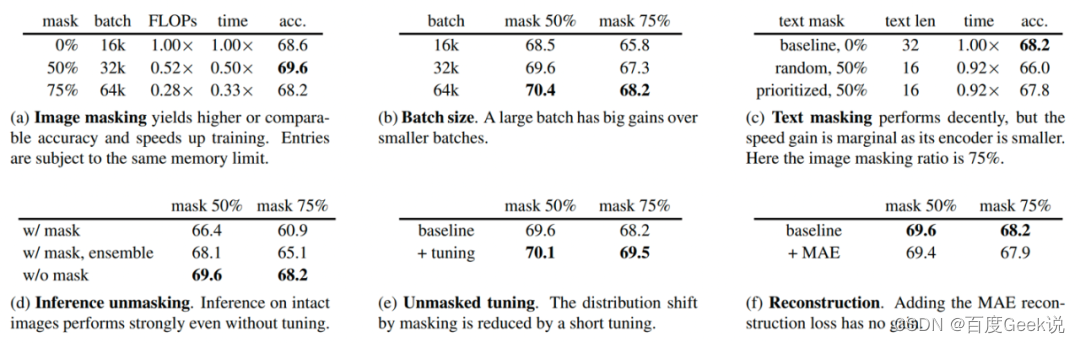
Vejamos a comparação experimental entre FLIP e CLIP, conforme mostrado na Fig 6.31, o autor reproduziu o CLIP e também usou os resultados do OpenCLIP para comparação. Depois de usar o FLIP, ele pode superar os resultados do CLIP e openCLIP nas mesmas L/14configurações L/16. . Parece que o FLIP também é um método que vale a pena explorar.

BEiT v3
Anteriormente, introduzimos o incrível efeito da perda de aprendizagem contrastiva em tarefas de alinhamento semântico e também discutimos por que as perdas de ITM e MLM apresentam desvantagens em tarefas de alinhamento semântico, mas se as perdas de ITM e MLM realmente não podem modelar o alinhamento semântico Pano de lã? Em outras palavras, essas duas perdas estão destinadas a serem ineficientes em tarefas de alinhamento semântico? Curiosamente, o modelo BEiT v3 [68] parece nos dar uma resposta surpresa diferente. Como mostrado na Fig. 6.32, o modelo BEiT v3 que usa apenas a perda MLM para modelagem pode ser descrito como um guerreiro hexagonal. superaram seus predecessores e atingiram o estado da arte. Por que um efeito de alinhamento semântico tão bom pode ser alcançado sem aprendizado contrastivo em larga escala? Então, o que discutimos acima está errado? E ouça o autor devagar.
Como o nome BEiT indica, BEiT v3 é o trabalho de continuação dos modelos BEiT e BEiT v2. Uma das características desta série é o uso de tokenização visual esparsa para representar recursos visuais. Deep depende de recursos visualmente esparsos. No BEiT v3, o autor considera a informação visual como uma "língua estrangeira" (Imglish), por isso é visualmente tokenizada. é adotado o método usado no BEiT v2. Para detalhes, consulte o Capítulo 0x01. Por meio da tokenização visual esparsa, o texto e as imagens são convertidos em uma série de tokens discretos e, em seguida, os pares imagem, texto e imagem-texto são modelados por meio do Multiway Transformer, conforme mostrado na Fig. 6.33.
Especificamente, conforme mostrado na Fig. 6.30, a frente ( L − F ) x (LF)x de BEiT v3( L−F ) A camada x consiste em especialistas visuais11V-FFNeespecialistas em textoL-FFN, no topoxxA camada x é especialista em fusão multimodalVL-FFN, ondex = 3 x=3x=3 . Independentemente deV-FFN,L-FFNouVL-FFN, na verdade, a essência é uma sóFeed-Forward Network, mas a entrada para diferentes modalidades será controlada por treinamento eencaminhadapara diferentes módulos FFN, daí o nome. Podemos também formalizar todo o processo de entrada matematicamente, se nosso token de texto for registrado comoT ∈ RM × 1 T\in \mathbb{R}^{M \times 1}T∈RM × 1 , o token visual é expresso comoV ∈ RNV \in \mathbb{R}^{N}V∈RN , ondeMMM eNNN é o número de fichas. Depois de consultar a tabela separadamente, obtêm-se os vetores de incorporação de texto e visão, que são expressos comoT e ∈ RM × d T_{e} \in \mathbb{R}^{M \times d}Te∈RM × d和V e ∈ RN × d V_{e} \in \mathbb{R}^{N \times d}Ve∈RN × d , o vetor de incorporação do par imagem-texto pode ser expresso como a junção dos dois, ou seja,VL e = [ V e ; T e ] ∈ R ( M + N ) × d VL_{e} = [V_{e };T_{e}] \in \mathbb{R}^{(M+N) \times d}V Le=[ Ve;Te]∈R( M + N ) × d。
A função do módulo na Fig. 6.33 Shared Multi-Head Self-Attentioné processar o mecanismo de auto-atenção multicabeças, independentemente de ser um modo de texto, imagem ou par imagem-texto, daí o nome, que é XX na fórmula ( shared6- 24 )X pode serT e T_{e}Te、V e V_{e}Veou VL e VL_{e}V Le。
O = s o f t m a x ( Q K T d k + a t t n ) V Q = X W Q ∈ R N × D K = X W K ∈ R N × D V = X W V ∈ R N × D O = X W Q ∈ R N × D (6-24) \begin{align} O &= \mathrm{softmax}(\dfrac{QK^{\mathrm{T}}}{\sqrt{d_k}}+attn)V \\ Q &= XW_{Q}\in \mathbb{R}^{N \times D} \\ K &= XW_{K}\in \mathbb{R}^{N \times D} \\ V &= XW_{V}\in \mathbb{R}^{N \times D} \\ O &= XW_{Q}\in \mathbb{R}^{N \times D} \\ \end{align} \tag{6-24} OQKVO=softmax(dkQKT+attn)V=XWQ∈RN×D=XWK∈RN×D=XWV∈RN×D=XWQ∈RN×D( 6-24 )
Durante o pré-treinamento, apenas Masked Data Modeling é usado para modelagem, e essa essência é a mesma do MLM. Especificamente, independentemente da entrada modal única (texto ou imagem) ou entrada multimodal (par gráfico-texto), apenas o texto/imagem nele é mascarado e o modelo de treinamento tenta mascarar a reconstrução do token. O autor executa 15 % 15\%na entrada de texto unimodalMáscara aleatória com 15% de probabilidade, 50% 50\%para entrada de texto multimodal50% de probabilidade de mascaramento aleatório, para a estratégia de mascaramento da imagem, consulte o esquema de BEiT v2, então não vou entrar em detalhes aqui. No BEiT v3, o autor irábatch sizeconfigurá-lo para 6144, ou seja, 2048 textos unimodais, 2048 imagens unimodais e 2048 pares imagem-texto multimodais. Isso é muito menor do que o aprendizado contrastivo típico12batch size,a partir dos resultados de uma série de experimentos no artigo, conforme mostrado na Fig. 6.35 e na Fig. 6.32, o desempenho do BEiT v3 superou seus predecessores em muitas tarefas visuais e multimodais, incluindo o uso do CLIP com aprendizado contrastivo em larga escala, como mostrado na Fig. 6.35 (b), mesmo no cenário experimental zero-shot do qual o CLIP se orgulha, o BEiT v3 tem uma vantagem absoluta.
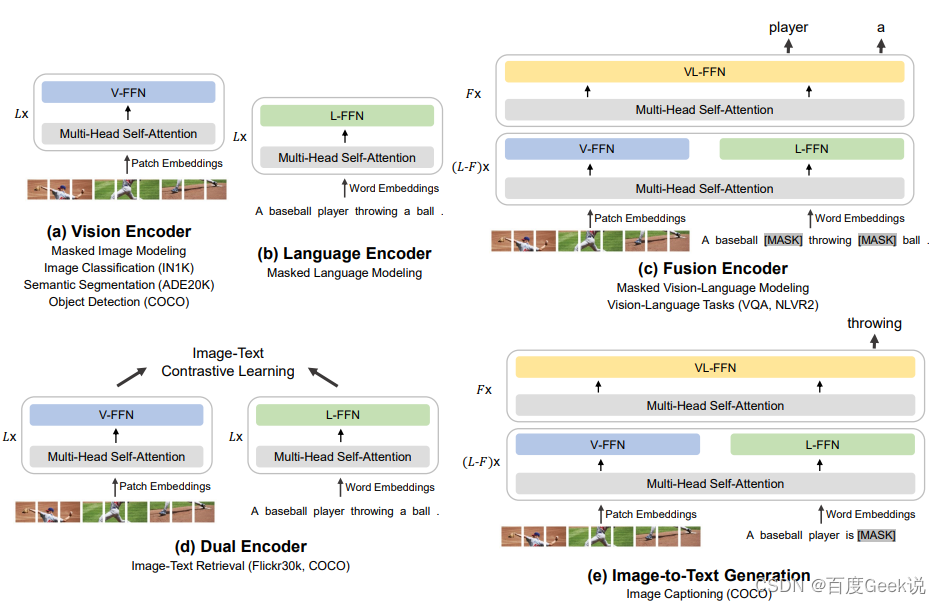
A partir da discussão acima, o BEiT v3 pode ser descrito como simples e simples. Ele usa apenas a perda de MLM para modelagem, não apenas modelando a representação modal única, mas também modelando o alinhamento semântico ao mesmo tempo. Conforme mostrado na Fig. 6.35, o BEiT v3 pode atingir o nível SOTA em tarefas de recuperação, sejam os resultados após o ajuste fino ou os resultados zero-shot. Por que existe uma diferença tão grande entre o desempenho do BEiT v3 e o UNITER que discutimos antes, que também adota a modelagem MLM? Será que nosso julgamento anterior sobre o MLM foi tendencioso? O autor acredita que a principal diferença é que o BEiT v3 usa recursos esparsos de semântica visual suficientemente bons para converter blocos de imagem em tokens esparsos para modelagem MLM, o que tem várias vantagens:
- Não há diferença essencial entre tokens esparsos visuais e tokens de texto e podem ser considerados como entrada homogênea. A modelagem MLM neles é semelhante ao treinamento auto-supervisionado de texto. Como todos sabemos, a tarefa auto-supervisionada de texto MLM é atualmente uma das os paradigmas convencionais para o pré-treinamento de texto.
- A unidade de entrada mudou de um bloco de imagem para um único token, e a eficiência do treinamento é maior. Sob o mesmo consumo de recursos, mais treinamento pode ser realizado.
- As previsões baseadas em tokens visuais são mais informativas semanticamente do que as previsões em nível de pixel.
Da perspectiva do BEiT v3, descobrimos que, mesmo que o MLM seja um método de modelagem de fusão semântica, não é impossível modelar o alinhamento semântico. e relacionamento de fusão semântica entre tokens visuais e tokens de texto13 . Deste ponto de vista, a perda da fusão semântica não significa que a fusão semântica não possa ser modelada com eficiência, então nossa compreensão da fusão semântica e modelagem do alinhamento semântico foi além. Os dois não são claramente distintos um do outro, mas intimamente relacionados .
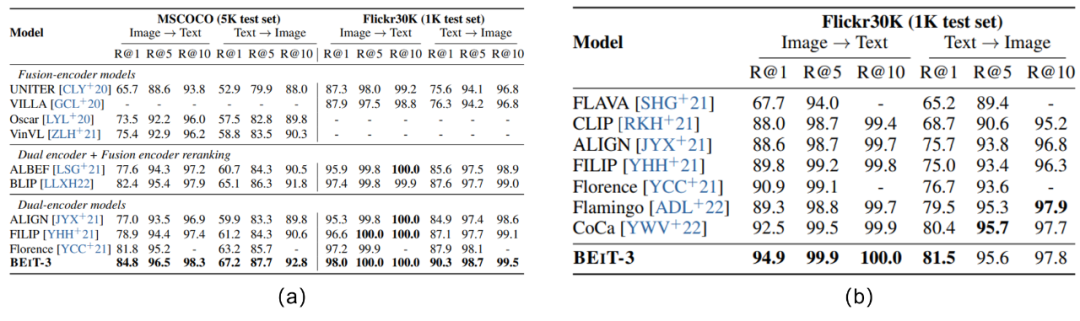
modelo visual
CLIP4clips
我们在之前介绍了很多CLIP之后的图文匹配模型,在大量图文数据的大规模对比学习预训练下,CLIP的图片语义对齐能力已经很强了,是否能将图片CLIP的能力迁移到视频上呢?如果将视频看成是图片在时间轴上的展开,那么将图片CLIP迁移到视频上的做法是自然而然的,在CLIP4clips [41] 中对这个做法进行了探索。如Fig 6.28所示,作者将图片CLIP预训练好的图片ViT模型参数,直接加载到视频ViT模型中,而此处的视频ViT模型,其实也是单独对视频中的每一帧进行特征提取罢了。让我们进行形式化表达,用 x ∈ R T × W × H × 3 \mathbf{x} \in \mathbb{R}^{T \times W \times H \times 3} x∈RT×W×H×3表示当前输入的视频,其有 T T T帧,对其进行划分patch,每个patch的大小则为 x i ∈ R T × K W × K H × 3 , i = 0 , ⋯ , M \mathbf{x}_{i} \in \mathbb{R}^{T \times K_{W} \times K_{H} \times 3}, i=0,\cdots,M xi∈RT×KW×KH×3,i=0 ,⋯,M , tome-o como a entrada de ViT (claro, o endireitamento e o mapeamento linear são necessários antes disso), tomamos o vetor do modelo[CLS]como a saída do recurso do vídeo, expressa comoy ∈ RT × D \mathbf{y} \in \ mathbb{R}^{T \vezes D}y∈RT × D , ondeDDD é a dimensão de incorporação. Portanto, cada quadro do vídeo equivale a passar pelo modelo ViT para extração de características. Com base nisso, o autor explora principalmente dois pontos neste trabalho:
- Como modelamos as informações de tempo do vídeo quando o CLIP da imagem é pré-treinado?
- A fim de aliviar a diferença de distribuição entre dados de imagem e vídeo, o CLIP de imagem precisa realizar pós-treinamento nos dados de vídeo?
Em seguida, exploramos duas questões.
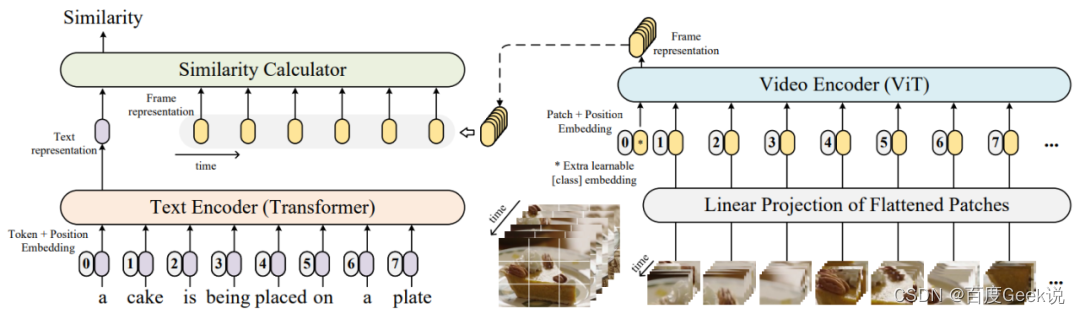

- Em conjuntos de dados diferentes,
meanPooleseqLSTM/seqTransfcada um tem seu próprio cerco, em conjuntos de dados menores, não hámeanPoolvantagem em introduzir parâmetros adicionais (por exemplo, o conjunto de dados MSVD tem menos de 2.000 vídeos e cada vídeo tem cerca de 60 segundos de duração). Quando a quantidade de dados é grande, como o conjunto de dados LSMDC (contém cerca de 120.000 vídeos, cada vídeo tem entre 2 a 30 segundos de duração), conjunto de dados ActivityNet (contém cerca de 20.000 vídeos do youtube), conjunto de dados DiDeMo (contém 10.000 vídeos), podemos veja que o efeito deseqLSTMeseqTransfé melhor. Comparando com os resultados do CLIP-straight, podemos constatar que embora seja a mesma informação visual, a diferença entre fotos e vídeos é muito grande , por isso é necessário introduzir módulos adicionais para modelar o vídeo informações de tempo. - Em todos os quatro conjuntos de teste, o efeito do método com o maior número de parâmetros
tightTransfé o pior. Como este modelo introduz muitos parâmetros que não foram pré-treinados, seu treinamento precisa de mais suporte de dados . Em um bom modelo, novos parâmetros deve ser introduzido com o mínimo de cuidado possível .
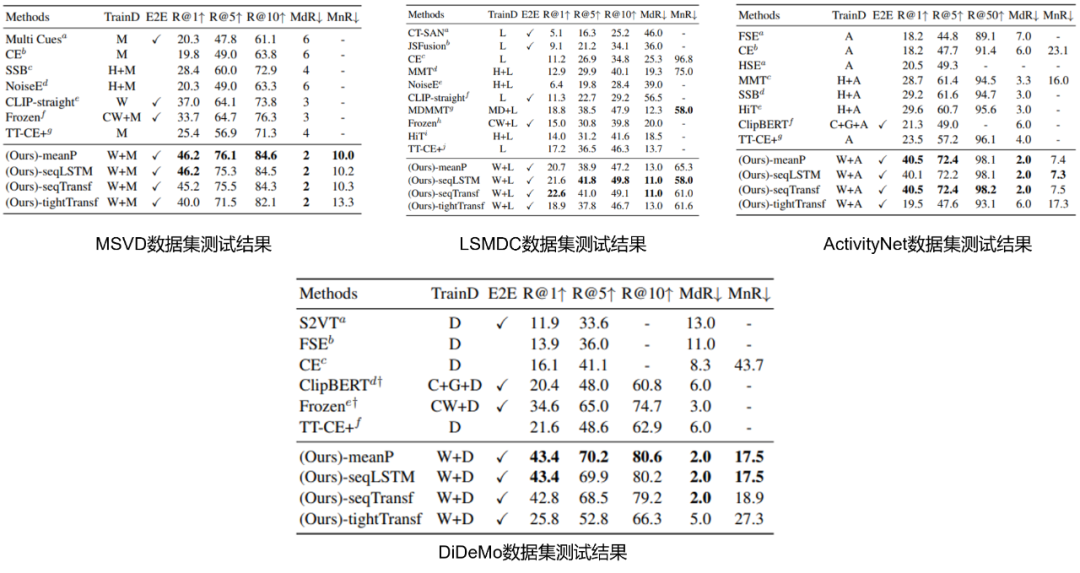
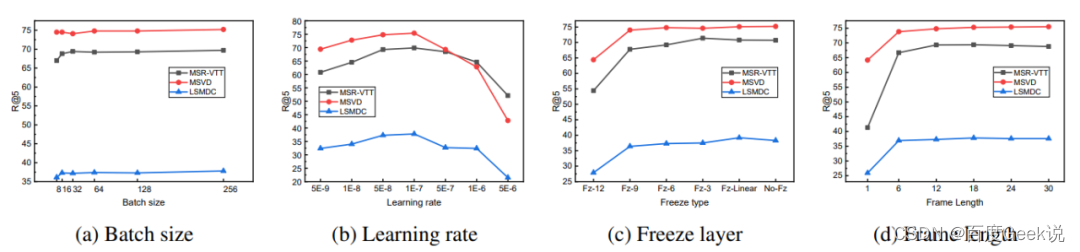
X-CLIP
Introduzimos o método de modelagem de interação fine-grained entre imagens e texto no trabalho do FILIP, e há trabalho semelhante ao estender para vídeo-texto. X-CLIP [38] é uma modelagem multi-grained de texto e vídeo. . Conforme mostrado na Fig. 6.33, ao combinar frases/palavras no lado do texto e vídeo/quadros no lado visual, podem ser formados quatro tipos diferentes de pares, que contêm três granularidades diferentes.

Conforme mostrado na Fig. 6.34, do ponto de vista do método de modelagem do modelo, tanto o final visual quanto o final do texto são modelados usando o Transformer, e o final visual é o modelo ViT. [CLS]Para obter informações refinadas de texto e vídeo, não apenas os recursos de saída do texto são usados como a representação da granularidade da frase , mas também os recursos de saída do token de cada posição são usados como a representação da granularidade da palavra . Para fins visuais, a saída do recurso Transformer em diferentes posições de quadro é considerada uma representação de granularidade de quadro , e mean poolo resultado dessas representações é considerado uma representação de granularidade de vídeo . E vamos formalizar, usamos v ′ ∈ RD v^{\prime} \in \mathbb{R}^{D}v′∈RD representa a representação da granularidade do vídeo,t ′ ∈ RD t^{\prime} \in \mathbb{R}^{D}t′∈RD representa a representação da granularidade da sentença,F ∈ R n × DF \in \mathbb{R}^{n \times D}F∈Rn × D representa a representação da granularidade do quadro,T ∈ R m × DT \in \mathbb{R}^{m \times D}T∈Rm × D representa a representação da granularidade da palavra, então a representação da espessura das duas modalidades pode ser comparada entre si, conforme mostrado abaixo
SV − S = ( ( v ′ ) T ( t ′ ) ) ∈ R 1 SV − W = ( T v ′ ) T ∈ R 1 × m SF − S = F t ′ ∈ R n × 1 SF − W = FTT ∈ R n × m (6-25) \begin{align} S_{VS} &= (( v^{\prime})^{\mathrm {T}}(t^{\prime})) \in \mathbb{R}^{1} \\ S_{VW} &= (Tv^{\prime} )^{\mathrm{T}} \in \mathbb{R}^{1 \times m} \\ S_{FS} &= Ft^{\prime} \in \mathbb{R}^{n \times 1 } \\ S_{FW} &= FT^{\mathrm{T}} \in \mathbb{R}^{n \times m} \end{align} \tag{6-25}SV - SSV - WSF - SSF − W=(( v’ )T (t′ ))∈R1=( Tv _’ )T∈R1 × m=F t′∈Rn × 1=F TT∈Rn × m( 6-25 )
Além da pontuação comparativa de granulação grossaSV − S S_{VS}SV - SExceto para uma pontuação numérica, outras pontuações refinadas e granuladas são matrizes ou vetores, que precisam ser agregadas em pontuações numéricas de uma certa maneira antes que possam ser adicionadas para formar a pontuação de similaridade de comparação multi-granular final (Multi -grained Contrastive Similarity), então esse processo de agregação é chamado de Matriz de Atenção Sobre Similaridade (AOSM), conforme mostrado na fórmula (6-26).
SV − S ′ = ( ( v ′ ) T ( t ′ ) ) ∈ R 1 SV − W ′ = ∑ i = 1 m exp ( SV − W ( 1 , i ) / τ ) ∑ j = 1 m exp ( SV − W ( 1 , j ) / τ ) SV − W ( 1 , i ) ∈ R 1 SF − S ′ = ∑ i = 1 n exp ( SF − S ( i , 1 ) / τ ) ∑ j = 1 n exp ( SF − S ( j , 1 ) / τ ) SF − S ( i , 1 ) ∈ R 1 (6-26) \begin{align} S^{\prime}_{VS} &= ( (v^{\prime})^{\mathrm {T}}(t^{\prime})) \in \mathbb{R}^{1} \\ S^{\prime}_{VW} &= \sum_{i=1}^{m} \dfrac{\exp(S_{VW}(1,i)/\tau)}{\sum_{j=1}^{m} \exp(S_{VW} (1,j)/\tau)} S_{VW}(1, i) \in \mathbb{R}^{1} \\ S^{\prime}_{FS} &= \sum_{i=1 }^{n} \dfrac{\exp(S_{FS}(i,1)/\tau)}{\sum_{j=1}^{n}\exp(S_{FS}(j,1)/ \tau)} S_{FS}(i,1) \in \mathbb{R}^{1} \end{align} \tag{6-26}SV - S′SV − W′SF − S′=((v′)T(t′))∈R1=i=1∑m∑j=1mexp(SV−W(1,j)/τ)exp(SV−W(1,i)/τ)SV−W(1,i)∈R1=i=1∑n∑j=1nexp(SF−S(j,1)/τ)exp(SF−S(i,1)/τ)SF−S(i,1)∈R1(6-26)
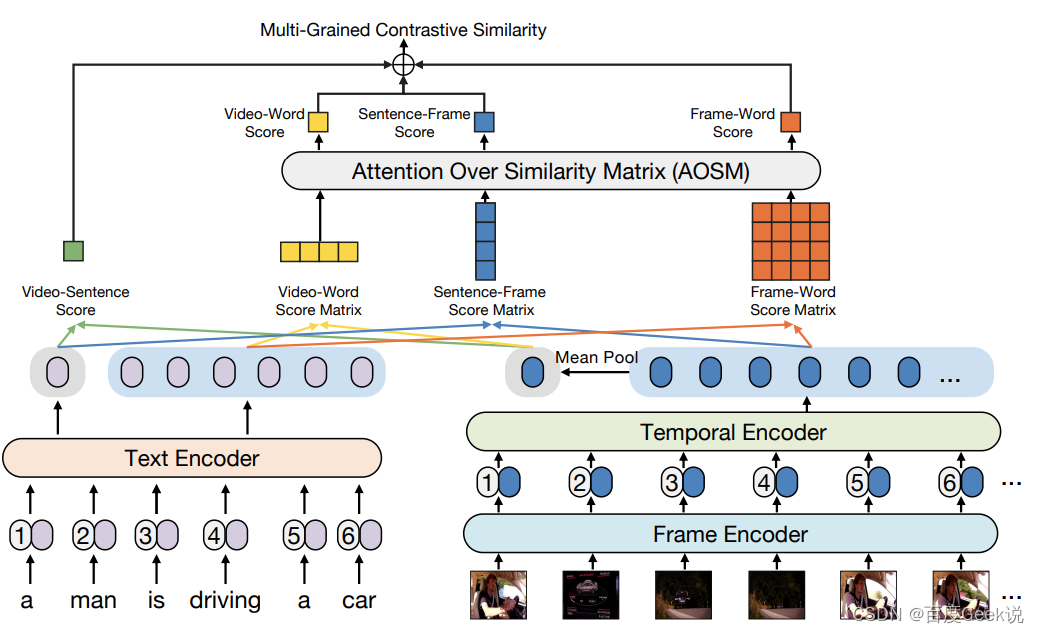
Vamos terminar este capítulo com um experimento comparativo.Como mostrado na Fig. 6.35, o autor compara os experimentos de ablação no conjunto de dados MSR-VTT combinando as pontuações dessas quatro granularidades. Entre eles estão várias observações:
- Observando Exp1 - Exp4, descobrimos que o resultado da comparação Word-Frame refinada não é necessariamente melhor do que a comparação Sent-Video granulada. comparação granulada. , pode não ser uma boa coisa para a recuperação.
- Observando Exp4, Exp1 e Exp7, descobrimos que uma vez que a comparação Word-Frame fine-grained mais a comparação Sent-Frame cross-grained, seu desempenho pode exceder o desempenho grosseiro, o que significa que não é necessário apenas modelar informações refinadas, mas também informações grosseiras também precisam ser consideradas (por exemplo, o texto está na granularidade da frase neste momento). A mesma conclusão também pode ser obtida comparando os experimentos Exp1, Exp4 e Exp6, ou Exp1, Exp4 e Exp10.
- Depois de adicionar resultados de grão grosso, grão fino e grão cruzado, é o melhor em todas as configurações, o que nos dá uma inspiração. Mesmo que o modelo de grão fino seja modelado, a aplicação de grão grosso e grão cruzado pode não deve ser descartado, caso contrário, pode haver aprendizado insuficiente, levando a resultados abaixo do ideal.
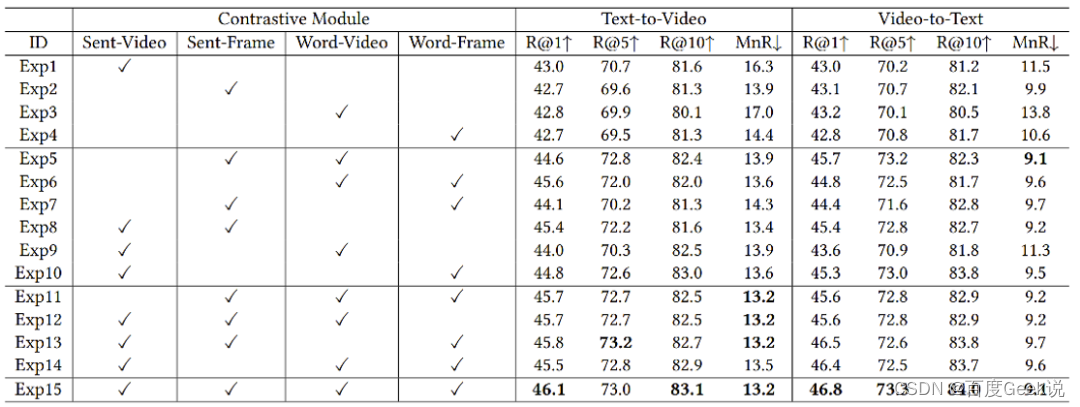
0x06 Fim da Jornada
Esta é uma longa jornada multimodal. Graças a você e a mim como leitores e autores, podemos chegar aqui juntos. Nosso artigo chegou ao fim. Apresentamos alguns trabalhos inspiradores neste artigo. Devido a limitações de espaço, é impossível para o autor classificar a vasta literatura multimodal. Como resumo, os pontos de otimização dos atuais modelos de correspondência multimodal comuns podem ser resumidos. Estes são as várias direções mostradas na Tabela 7.1, e as em negrito indicam que foram introduzidas neste artigo.
| Direção de otimização do modelo de correspondência multimodal | Exemplos de trabalho representativo |
|---|---|
| Modelagem de granulação fina/multigranular | FILIP [39], X-CLIP [38]… |
| Desacoplar a relação entre amostras negativas e tamanho do lote / acelerar o pré-treinamento | WenLan 1.0 [18], WenLan 2.0, FLIP [24]… |
| Usar dados de várias exibições | ERNIE-VIL 2.0 [19]… |
| Dimensionamento | CLIPE [15], FLIP , ALINHE [17]… |
| Reordenação do Alinhamento Semântico + Fusão Semântica | ALBEF [40], BLIP… |
| Estrutura multimodal unificada | Florença, FLAVA, BEiT v3 , Coca… |
| CLIP de imagem migrado para CLIP de vídeo | CLIP4clipes [41]… |
| Tokenização visual esparsa | VideoBERT [42], BEiT , BEiT v2 , BEiT v3 , VQ-VAE [45], BEVT , VIMPAC, dVAE… |
| Modelo de fusão semântica | UNITER [43], OSCAR, UniVL… |
| Um modelo de alinhamento semântico melhor | LiT [44]… |
| modelo multilíngue | Wukong, CLIP Chinês, WenLan … |
| Otimização da função de perda | CLIP-Lite [70] |
| … | … |
A percepção humana é obtida com base na interação de informações multimodais no ambiente externo.As informações multimodais podem ser descritas como o modo de entrada mais natural para os humanos, e também podem ser um caminho para um nível mais profundo de inteligência artificial. O autor está bem ciente da complexidade do modelo multimodal, então este artigo é apenas um breve resumo do modelo de correspondência semântica multimodal. Existem muitos trabalhos excelentes que não foram lidos com atenção devido à energia e habilidade limitadas do autor. , se em algum lugar pode ser útil para os leitores, então o propósito do autor ao escrever este artigo foi alcançado.
Quando se trata da aplicação real dessas tarefas, o autor acredita que, para aplicações industriais, a maioria desses trabalhos acadêmicos não pode ser transferida diretamente. A razão é muito simples: existem muitas lacunas entre os cenários de negócios e os cenários acadêmicos. Tomando o cenário de pesquisa como exemplo, vamos dar alguns exemplos:
-
A maior parte do nosso lado do texto não é como o texto da legenda no trabalho acadêmico, mas a consulta do usuário. Há uma grande lacuna entre a consulta e a legenda, e a consulta do usuário entre diferentes empresas também apresenta diferenças significativas. Um modelo e método que pode funcionar em um negócio não significa que pode funcionar em outro negócio, então os leitores descobrirão que este artigo não dá atenção especial aos indicadores de trabalhos acadêmicos sobre benchmarks, mas tenta desenterrar as possibilidades. as inspirações são benéficas para nossa compreensão da diferença entre negócios e acadêmicos e podem nos ajudar a promover melhor a otimização do modelo de negócios depois de combinar o conhecimento de negócios.
-
Não só há uma lacuna óbvia no lado do texto, mas também há uma grande diferença entre dados acadêmicos e dados comerciais em vídeos/imagens. Nos negócios, há mais dados semânticos visuais fracos, então encontraremos alguns bons Métodos granulares e multigranulados Vale muito a pena tentar.
-
A grande escala de dados de negócios também torna muitos métodos impossíveis de serem promovidos a um custo razoável e é limitado pela maneira de ir online. Muitas explorações acadêmicas de prefácio precisam ser implementadas e muitas otimizações de arquitetura e simplificações de métodos precisam ser consideradas.
Isso está longe do fim. Espero que tenhamos a oportunidade de continuar nossa jornada multimodal no novo capítulo. A estrada é longa e vou procurá-la de cima a baixo.
Apêndice A. Organização do conjunto de dados
Conjuntos de dados rotulados manualmente
| conjunto de dados | A quantidade de dados |
|---|---|
| Legenda COCO [11] | 533K |
| Legendas densas do genoma visual (Legenda VG) [12] | 5,06M |
| Legendas conceituais (CC) [13] | 3,0M |
| Legenda SBU [14] | 990K |
| … |
conjunto de dados pré-treinamento
| conjunto de dados | A quantidade de dados | aberto ou não | tipo de dados |
|---|---|---|---|
| WIT-400M [15] | 400M | privado | imagem-texto |
| Wu-Kong [16] | 100M | público disponível & chinês | imagem-texto |
| ALINHAR [17] | 1.8B | privado | imagem-texto |
| Wen Lan [18] | 30M | privado | imagem-texto |
| ERNIE-VIL 2.0 [19] | 1.5B | privado | imagem-texto |
| LiT [20] | 4B | privado | imagem-texto |
| YFCC100M [21] | 100M | público disponível | imagem-texto |
| CC12M [22] | 12M | público disponível | imagem-texto |
| HowTo100M [23] | 100M | público disponível | vídeo-texto |
| LAION-400M [24] | 400M | privado | imagem-texto |
| LAION-2B [24] | 2b | privado | imagem-texto |
| … |
Referência
[1]. https://fesianxu.github.io/2022/12/24/video-understanding-20221223/, https://blog.csdn.net/LoseInVain/article/details/105545703, texto longo de 4.000 palavras falar video entender
[2]. https://fesianxu.github.io/2022/12/24/general-video-analysis-1-20221224/, um de análise de vídeo e fusão multimodal, por que a fusão multimodal é necessária
[3]. https://github.com/basveeling/pcam, PatchCamelyon (PCam)
[4]. https://github.com/phelber/EuroSAT, EuroSAT: Classificação de Uso e Cobertura do Solo com Sentinel-2
[5]. https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set/, Hateful Memes Challenge and dataset for research on harmful multimodal content
[6]. Yu, F., Tang, J., Yin, W., Sun, Y., Tian, H., Wu, H., & Wang, H. (2021, May). Ernie-vil: Knowledge enhanced vision-language representations through scene graphs. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 4, pp. 3208-3216). Short for ERNIE-VIL 1.0
[7]. https://www.bilibili.com/video/BV1644y1S7H3, 我想,这以后便是在农村扎根了吧
[8]. https://www.bilibili.com/video/BV1Mg411J7kp, 自制钓鱼佬智能快乐竿
[9]. https://fesianxu.github.io/2022/12/24/nonlinear-struct-video-20221224/, https://blog.csdn.net/LoseInVain/article/details/108212429, 基于图结构的视频理解——组织视频序列的非线性流
[10]. Mao, Feng, et al. “Hierarchical video frame sequence representation with deep convolutional graph network.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[11]. Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll´ar, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
[12]. Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV (2017)
[13]. Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: ACL (2018)
[14]. Ordonez, V., Kulkarni, G., Berg, T.L.: Im2text: Describing images using 1 million captioned photographs. In: NeurIPS (2011)
[15]. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR. Short for CLIP
[16]. Gu, J., Meng, X., Lu, G., Hou, L., Niu, M., Xu, H., … & Xu, C. (2022). Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework. arXiv preprint arXiv:2202.06767. short for WuKong
[17]. Jia, C., Yang, Y., Xia, Y., Chen, Y. T., Parekh, Z., Pham, H., … & Duerig, T. (2021, July). Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning (pp. 4904-4916). PMLR. Short for ALIGN
[18]. Huo, Y., Zhang, M., Liu, G., Lu, H., Gao, Y., Yang, G., … & Wen, J. R. (2021). WenLan: Bridging vision and language by large-scale multi-modal pre-training. arXiv preprint arXiv:2103.06561. short for WenLan 1.0
[19]. Shan, B., Yin, W., Sun, Y., Tian, H., Wu, H., & Wang, H. (2022). ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training. arXiv preprint arXiv:2209.15270. short for ERNIE-VIL 2.0
[20]. Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., & Beyer, L. (2022). Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18123-18133). Short for LiT
[21]. Thomee, B., Shamma, D. A., Friedland, G., Elizalde, B., Ni, K., Poland, D., … & Li, L. J. (2016). YFCC100M: The new data in multimedia research. Communications of the ACM, 59(2), 64-73.
[22]. Changpinyo, S., Sharma, P., Ding, N., & Soricut, R. (2021). Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3558-3568).
[23]. Miech, A., Zhukov, D., Alayrac, J. B., Tapaswi, M., Laptev, I., & Sivic, J. (2019). Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 2630-2640).
[24]. Li, Y., Fan, H., Hu, R., Feichtenhofer, C., & He, K. (2022). Scaling Language-Image Pre-training via Masking. arXiv preprint arXiv:2212.00794. Short for FLIP
[25]. https://blog.csdn.net/LoseInVain/article/details/116377189, 从零开始的搜索系统学习笔记
[26]. https://blog.csdn.net/LoseInVain/article/details/126214410, 【见闻录系列】我所理解的搜索业务二三事
[27]. https://blog.csdn.net/LoseInVain/article/details/125078683, 【见闻录系列】我所理解的“业务”
[28]. Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR. short for SimCLR
[29]. https://blog.csdn.net/LoseInVain/article/details/125194144, 混合精度训练场景中,对比学习损失函数的一个注意点
[30]. Noroozi, M. and Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision, pp. 69–84. Springer, 2016. short fot jigsaw puzzles
[31]. Zhang, R., Isola, P., and Efros, A. A. Colorful image colorization. In European conference on computer vision, pp. 649–666.
Springer, 2016. short for colorization
[32]. Gidaris, S., Singh, P., & Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728. short for rotations
[33]. He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9729-9738). short for MoCo
[34]. Wu, Z., Xiong, Y., Yu, S. X., & Lin, D. (2018). Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3733-3742). short for Memory Bank
[35]. https://blog.csdn.net/LoseInVain/article/details/120039316, Batch Norm层在大尺度对比学习中的过拟合现象及其统计参数信息泄露问题
[36]. He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000-16009). short for MAE
[37]. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021. short for ViT
[38]. Ma, Y., Xu, G., Sun, X., Yan, M., Zhang, J., & Ji, R. (2022, October). X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. In Proceedings of the 30th ACM International Conference on Multimedia (pp. 638-647). Short for X-CLIP
[39]. Yao, L., Huang, R., Hou, L., Lu, G., Niu, M., Xu, H., … & Xu, C. (2021). Filip: Fine-grained interactive languageimage pre-training. arXiv preprint arXiv:2111.07783. short for FILIP
[40]. Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., & Hoi, S. C. H. (2021). Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems, 34, 9694-9705.
[41]. Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., & Li, T. (2022). CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing, 508, 293-304. short for CLIP4clips
[42]. Sun, C., Myers, A., Vondrick, C., Murphy, K., & Schmid, C. (2019). Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 7464-7473). Short for VideoBERT
[43]. Chen, Y. C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., … & Liu, J. (2020, August). Uniter: Universal imagetext representation learning. In European conference on computer vision (pp. 104-120). Springer, Cham. Short for UNITER
[44]. Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., & Beyer, L. (2022). Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18123-18133). Short for LiT
[45]. Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017). short for VQ-VAE
[46]. https://fesianxu.github.io/2022/12/24/discrete-latent-representation-20221223/, 【论文极速读】VQ-VAE:一种稀疏表征学习方法
[47]. Bao, Hangbo, Li Dong, Songhao Piao, and Furu Wei. “Beit: Bert pre-training of image transformers.” arXiv preprint arXiv:2106.08254 (2021). short for BEiT
[48]. Vahdat, Arash, Evgeny Andriyash, and William Macready. “Dvae#: Discrete variational autoencoders with relaxed boltzmann priors.” Advances in Neural Information Processing Systems 31 (2018). short for dVAE
[49]. Peng, Zhiliang, Li Dong, Hangbo Bao, Qixiang Ye, and Furu Wei. “Beit v2: Masked image modeling with vector-quantized visual tokenizers.” arXiv preprint arXiv:2208.06366 (2022). short for BEiT v2
[50]. Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9650-9660). short for DINO
[51]. Tong, Zhan, Yibing Song, Jue Wang, and Limin Wang. “Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.” arXiv preprint arXiv:2203.12602 (2022). short for VideoMAE
[52]. https://fesianxu.github.io/2023/01/20/semantic-label-20230120/, 语义标签(Semantic label)与多模态模型的一些关系
[53]. Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.” arXiv preprint arXiv:1908.02265 (2019). short for ViLBERT
[54]. Yu, Fei, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. “Ernie-vil: Knowledge enhanced vision-language representations through scene graph.” arXiv preprint arXiv:2006.16934 (2020). short for ERNIE-VIL 1.0
[55]. Wang, R., Chen, D., Wu, Z., Chen, Y., Dai, X., Liu, M., … & Yuan, L. (2022). Bevt: Bert pretraining of video transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14733-14743). short for BEVT
[56]. https://blog.csdn.net/LoseInVain/article/details/114958239, 语义标签(Semantic label)与多模态模型的一些关系
[57]. Chen, Y. C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., … & Liu, J. (2020, September). Uniter: Universal image-text representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX (pp. 104-120). Cham: Springer International Publishing. short for UNITER
[58]. https://pytorch.org/docs/stable/distributed.html, DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED
[59]. https://amsword.medium.com/gradient-backpropagation-with-torch-distributed-all-gather-9f3941a381f8, Gradient backpropagation with torch.distributed.all_gather
[60]. https://blog.csdn.net/LoseInVain/article/details/103870157, 一些深度学习中的英文术语的纪录
[61]. https://blog.csdn.net/LoseInVain/article/details/122735603, 图文多模态语义融合前的语义对齐——一种单双混合塔多模态模型
[62]. https://github.com/facebookresearch/moco/blob/78b69cafae80bc74cd1a89ac3fb365dc20d157d3/moco/builder.py#L53
[63]. https://blog.csdn.net/LoseInVain/article/details/105808818, 数据并行和模型并行的区别
[64]. Fei, Nanyi, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu et al. “WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model.” arXiv preprint arXiv:2110.14378 (2021). short for WenLan v2
[65]. https://blog.csdn.net/LoseInVain/article/details/121699533, WenLan 2.0:一种不依赖Object Detection的大规模图文匹配预训练模型 & 数据+算力=大力出奇迹
[66]. Li, Junnan, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. “Align before fuse: Vision and language representation learning with momentum distillation.” Advances in Neural Information Processing Systems 34 (2021). short for ALBEF
[67]. https://github.com/salesforce/ALBEF/issues/22
[68]. Wang, Wenhui, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal et al. “Image as a foreign language: Beit pretraining for all vision and vision-language tasks.” arXiv preprint arXiv:2208.10442 (2022). short for BEiT v3
[69]. Bao, H., Wang, W., Dong, L., Liu, Q., Mohammed, O. K., Aggarwal, K., … & Wei, F. (2021). Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. arXiv preprint arXiv:2111.02358.
[70]. Shrivastava, A., Selvaraju, R. R., Naik, N., & Ordonez, V. (2021). CLIP-Lite: information efficient visual representation learning from textual annotations. arXiv preprint arXiv:2112.07133. short for CLIP-Lite
相同的文本符号所代表的抽象含义并不是一成不变的,而是会随着人类社会的地域,事件,时间等发生变化,也就是说文本的语义是变化着的。举个例子,苹果在过去只是指的食物苹果,在现在又多出了苹果(产品,公司)的语义,黄色在过去只是颜色代表,现在在国内有着情色的含义,而在日本,这个黄色则由桃色,粉色(ピンク)替代了。 ↩︎
光栅化的图片的基础组成部分是像素,而矢量图则可以通过公式进行表达。 ↩︎
有两种方法可供使用:一、原图 t t t与原图的变换 t ′ ∼ T t^{\prime} \sim \mathcal{T} t′∼T作为一对正样本对 < t , t ′ > <t, t^{\prime}> <t,t′>;二、原图 t t t在同一个图片变换 T \mathcal{T} T下产生两个衍生图片 t ′ ∼ T t^{\prime} \sim \mathcal{T} t′∼T , t ′ ′ ∼ T t^{\prime \prime} \sim \mathcal{T} t′′∼T,将这两个衍生图片视为一对正样本对 < t ′ , t ′ ′ > <t^{\prime}, t^{\prime \prime}> <t′,t′′>。前者称之为非对称处理,由于会影响性能而仅在消融实验中采用,SimCLR采用的是后者,也称之为对称性处理。 ↩︎
全称是Normalized Temperature-scaled Cross Entropy,标准化温度系数放缩交叉熵损失。 ↩︎
由于此处的key编码器采用动量更新,因此也被称之为动量编码器。 ↩︎
笔者认为采用VQ-VAE应该也是可以的,未曾试验过。 ↩︎
正因为视频同时有着空间和时间上的冗余度,在视频压缩中同时也有时间和空间维度的信息压缩。 ↩︎
具象概念:现实生活中存在的物体的概念,如苹果,老虎,电脑等。 抽象概念:非现实生活中真实存在的物体概念,如自由、和平、爱情等。 ↩︎
上下文提示词,在其他文献也被称之为prompt,我们本文不区分这两个术语。 ↩︎
这种做法在NLP里面也是一种经典做法,比如 f ( k i n g ) − f ( m a l e ) ≈ f ( q u e u e ) f(king)-f(male) \approx f(queue) f(king)−f(male)≈f(queue),这一定程度代表了embedding的语义对齐能力。 ↩︎
在Multiway Transformer原论文 [69] 中,
V-FFN和L-FFN被称之为“视觉专家”和“文本专家”,采用的是Mixture of Multiple Experts (MMoE) 的思想。 ↩︎CLIP的
batch size高达32k,ALIGN的batch size大概是16k。 ↩︎Por precaução, a descrição aqui é "alinhamento de tokens visuais e tokens textuais" em vez de "alinhamento de conceitos visuais e textuais". O autor considera principalmente que a semântica implícita por tokens visuais esparsos deve ser visual Um subconjunto de conceitos , o alinhamento de tokens visuais para tokens textuais não infere o alinhamento semântico das duas modalidades. ↩︎