Fonte: 2023CVPR
Link original: https://arxiv.org/abs/2206.02066
源码:GitHub - XuJiacong/PIDNet: Este é o repositório oficial do nosso trabalho recente: PIDNet
0. Resumo
A estrutura de rede de ramificação dupla mostrou sua eficácia e eficácia em tarefas de segmentação semântica em tempo real . No entanto, a desvantagem de fundir diretamente detalhes de alta resolução e contexto de baixa frequência é que os recursos detalhados são facilmente sobrecarregados pelas informações contextuais circundantes. Esse fenômeno de overshooting limita a melhoria da precisão de segmentação dos modelos de ramificação dupla existentes. Neste artigo, vinculamos redes neurais convolucionais (CNNs) e controladores PID (proporcional-integral-derivativo) , revelando que as redes de ramificação dupla são equivalentes aos controladores proporcional-integral (PI), que têm problemas de superajuste semelhantes. Para resolver este problema, propomos uma nova estrutura de rede de três ramificações: PIDNet, que consiste em três ramificações para resolver ramificação de detalhe, ramificação de contexto e informações de limite, respectivamente, e usa atenção de limite para guiar a fusão de ramificação de detalhe e ramificação de contexto. Nossa família de PIDNets atinge um compromisso ideal entre velocidade de inferência e precisão, e sua precisão excede todos os modelos existentes com velocidade de inferência semelhante na paisagem urbana e conjuntos de dados CamVid . Entre eles, a velocidade de inferência do PIDNet-S na paisagem urbana é de 78,6% e a velocidade de inferência é de 93,2 FPS; a velocidade de inferência no CamVid é de 80,1% e a velocidade de inferência é de 153,7 FPS.
1. Introdução
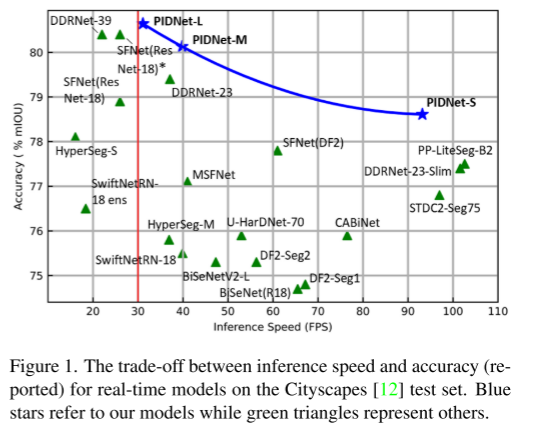
O controlador proporcional-integral-derivativo (PID) é um conceito clássico que tem sido amplamente utilizado em sistemas e processos dinâmicos modernos, como manipulação robótica [3], processos químicos [24] e sistemas de energia [25]. Embora muitas estratégias avançadas de controle com melhor desempenho de controle tenham sido desenvolvidas nos últimos anos, os controladores PID ainda são a primeira escolha para a maioria das aplicações industriais devido à sua simplicidade e robustez. Além disso, a ideia do controlador PID foi estendida a muitos outros campos. Por exemplo, os pesquisadores introduziram o conceito de PID na redução de ruído de imagem [32], afundamento de gradiente estocástico [1] e otimização numérica [50] para melhor desempenho do algoritmo. Neste artigo, projetamos uma nova arquitetura de tarefa de segmentação semântica em tempo real, utilizando o conceito básico de controlador PID, e demonstramos por meio de extensos experimentos que nosso modelo supera todos os trabalhos anteriores, alcançando velocidade e precisão de inferência. mostrado na Figura 1.
A segmentação semântica é uma tarefa fundamental na análise de cenas visuais, onde o objetivo é atribuir um rótulo de classe específico para cada pixel em uma imagem de entrada. Com a crescente demanda por inteligência, a segmentação semântica tornou-se um componente básico de percepção para aplicações como direção autônoma [16], diagnóstico de imagens médicas [2] e imagens de sensoriamento remoto [54]. A partir de FCN [31], a convolução em profundidade melhorou muito em relação aos métodos tradicionais e gradualmente dominou o campo da segmentação semântica, propondo muitos modelos representativos [4, 6, 40, 48, 59, 60]. Para obter um melhor desempenho, introduzimos várias estratégias para equipar esses modelos para aprender a correlação contextual entre pixels em escala sem perder detalhes importantes. Embora a precisão de segmentação desses modelos seja encorajadora, o custo computacional proibitivo dificulta severamente sua aplicação em cenários de tempo real, como carros autônomos [16] e cirurgia robótica [44].
A fim de atender às necessidades de tempo real ou mobilidade, os pesquisadores propuseram muitos modelos eficientes de segmentação semântica de palavras. Especificamente, o ENet [36] emprega um decodificador leve para reduzir a amostragem de mapas de recursos em um estágio inicial. ICNet [58] codifica pequenas entradas em caminhos profundos complexos para analisar a semântica de alto nível. MobileNet [21, 42] substitui convoluções tradicionais por convoluções separáveis em profundidade. Esses primeiros trabalhos reduziram a latência e o uso de memória dos modelos de segmentação, mas a baixa precisão limitou severamente suas aplicações no mundo real. Recentemente, muitos modelos novos e promissores baseados na arquitetura Two-Branch Network (TBN) foram propostos na literatura, alcançando um compromisso SOTA entre velocidade e precisão [15, 20, 38, 39, 52].
Neste artigo, analisamos a arquitetura do TBN da perspectiva do controlador PID e apontamos que o TBN é equivalente ao controlador PI, que tem o problema de overshoot conforme mostrado na Fig. 2. Para resolver este problema, projetamos uma nova estrutura de rede de três ramificações, PIDNet, e demonstramos sua superioridade nos conjuntos de dados de paisagem urbana [12], CamVid [5] e Contexto PASCAL [33]. Também fornecemos estudos de ablação e visualizações de recursos para entender melhor a função de cada módulo no PIDNet. O código fonte pode ser acessado através de https://github.com/XuJiacong/PIDNet
As principais contribuições deste artigo estão em três aspectos:
- Ligando CNNs profundas com controladores PID e propondo uma rede de três ramificações baseada na arquitetura do controlador PID
- Propor módulos eficientes, como o módulo Bag fusion que equilibra detalhes e recursos contextuais, para melhorar o desempenho de PIDNets
- O PIDNet alcança o melhor compromisso entre velocidade de inferência e precisão entre todos os modelos existentes. Entre eles, sem ferramentas de aceleração, o PIDNet-S alcançou 78,6% mIOU no conjunto de teste cityapes e a velocidade atingiu 93,2 FPS, enquanto o PIDNet-L alcançou a maior precisão (80,6% mIOU).
2. Trabalho relacionado
Nesta seção, métodos representativos para atingir alta precisão e requisitos de tempo real são discutidos, respectivamente.
2.1 Segmentação semântica de alta precisão
Abordagens iniciais para segmentação semântica foram baseadas em arquiteturas de codificador-decodificador [4, 31, 40], onde o codificador gradualmente amplia seu campo receptivo por meio de convolução strided ou operações de agrupamento, e o decodificador usa deconvolução ou upsampling de detalhes de recuperação semântica avançada. No entanto, os detalhes espaciais são facilmente ignorados durante o downsampling da rede do codec. Para aliviar este problema, convoluções dilatadas [53] são propostas para ampliar o campo de visão sem reduzir a resolução espacial. Com base nisso, a série DeepLab [7-9] usa convoluções dilatadas com diferentes taxas de expansão na rede, o que melhorou muito em comparação com trabalhos anteriores. Observe que a convolução dilatada não é adequada para implementação de hardware devido ao seu acesso não sequencial à memória. PSPNet [59] introduz um Pyramid Pooling Module (PPM) para resolver informações contextuais multi-escala, enquanto HRNet [48] utiliza multi-caminho e conexões bilaterais para aprender e fundir representações em diferentes escalas. Inspiradas pelas capacidades de análise de dependência de longo prazo do mecanismo de atenção [47] em máquinas de linguagem, as operações não locais [49] são introduzidas na visão computacional, levando a muitos modelos precisos [17, 23, 55].
2.2 Segmentação semântica em tempo real
Muitas arquiteturas de rede foram propostas para alcançar um equilíbrio ideal entre velocidade de inferência e precisão, que pode ser resumida da seguinte forma.
Codificadores e Decodificadores Leves
SwiftNet [35] usa uma entrada de baixa resolução para semântica de alto nível e outra entrada de alta resolução para fornecer detalhes suficientes para seu decodificador leve. O DFANet [27] introduz um backbone leve modificando a estrutura do Xception [11], que é baseado em convoluções separáveis em profundidade e reduz o tamanho da entrada para melhorar a velocidade de inferência. ShuffleSeg [18] usa ShuffleNet [57] integrando transformação de canal e convolução de grupo como backbone para reduzir a quantidade de computação. No entanto, a maioria dessas redes ainda emprega uma arquitetura de codificador-decodificador, exigindo que as informações fluam por um codificador profundo e voltem por um decodificador, o que introduz muita latência. Além disso, como a otimização de convoluções separáveis em profundidade na GPU é imatura, as convoluções convencionais são mais rápidas com mais FLOPs e parâmetros [35]. Portanto, buscamos modelos mais eficientes que evitem decomposições convolucionais e arquiteturas codificador-decodificador.
Arquitetura de rede de ramificação dupla
Um grande campo receptivo pode extrair relevância contextual, e detalhes espaciais são cruciais para delineamento de limites e reconhecimento de objetos em pequena escala. Para equilibrar esses dois aspectos, os autores do BiSeNet [52] propõem uma arquitetura de rede de dois ramos (TBN), que consiste em dois ramos com diferentes profundidades para incorporação de contexto e análise de detalhes, e um O módulo de fusão de recursos (FFM) é usado para fundir contexto e informações detalhadas. A fim de melhorar a capacidade de representação desta arquitetura ou reduzir a complexidade do seu modelo, alguns trabalhos de acompanhamento baseados nesta arquitetura foram propostos [38, 39, 51]. Especificamente, DDRNet [20] introduz conexões bilaterais para melhorar a troca de informações entre ramificações contextuais e detalhadas, alcançando resultados de segmentação semântica em tempo real de última geração. No entanto, fundindo diretamente a semântica detalhada original e as informações contextuais de baixa frequência, existe o risco de os limites do objeto serem superados pelos pixels circundantes e objetos pequenos serem sobrecarregados por objetos grandes adjacentes (como mostrado nas Figuras 2 e 3). 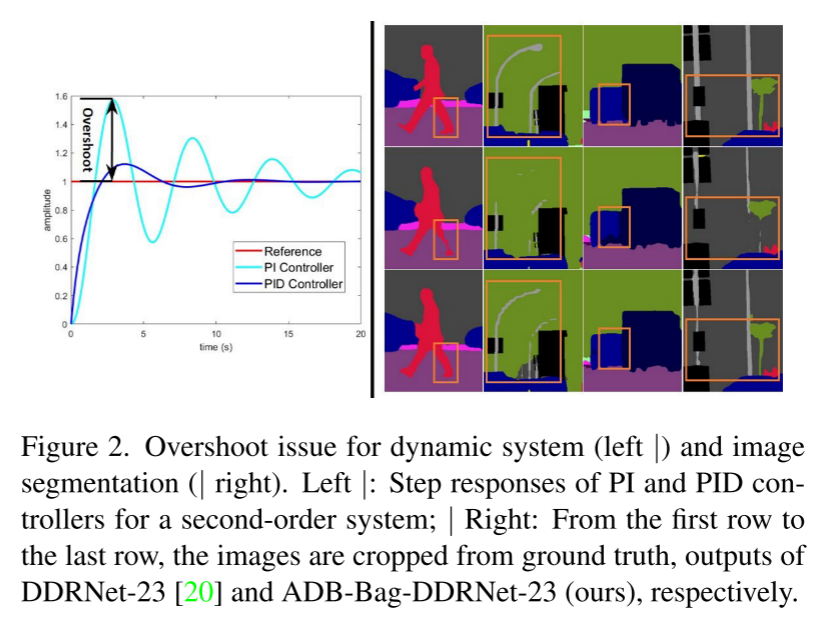
3. Método
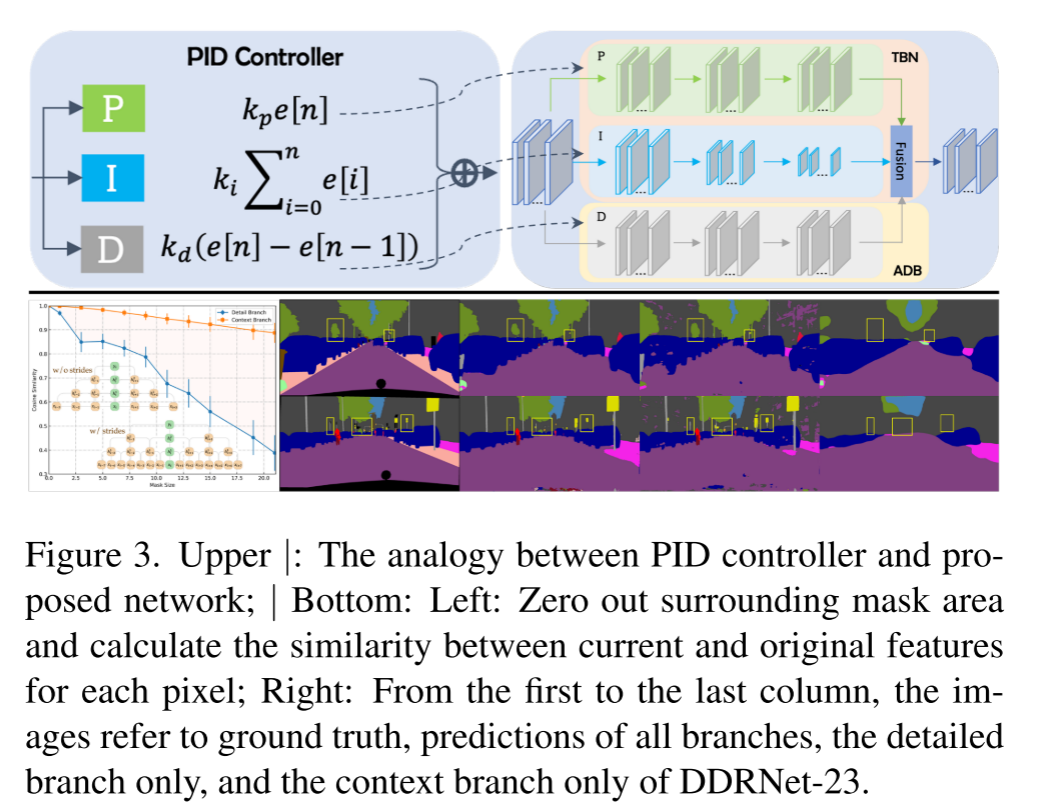
O controlador PID consiste em três partes: controlador Proporcional (P), controlador Integral (I) e controlador Derivativo (D), conforme mostrado na Fig. 3-acima. A implementação do controlador PI pode ser escrita como:

O controlador P concentra-se no sinal atual, enquanto o controlador I acumula todos os sinais passados. Devido aos efeitos inerciais acumulados, a saída de um controlador PI simples ultrapassa quando o sinal muda em direções opostas. Em seguida, introduza o controlador D, quando o sinal fica menor, o componente D se torna um valor negativo, que atua como um amortecedor para reduzir o overshoot. Da mesma forma, o TNS resolve o contexto e os detalhes separadamente por meio de várias camadas convolucionais. Considere um exemplo 1D simples em que a ramificação de detalhe e a ramificação de contexto consistem em 3 camadas sem bn e ReLUs. Então, o mapa de saída pode ser calculado como:

Entre eles, kmn é o enésimo valor do núcleo da camada m. Como |kmn| é distribuído principalmente em (0,0,01) (DDRNet-23 é 92%), com 1 como limite, o coeficiente de cada item diminui exponencialmente à medida que o número de camadas aumenta. Portanto, para cada vetor de entrada, quanto maior o número de itens, maior a contribuição para o produto final. Para o ramo de detalhe, I[I−1], I[I] e I[I+1] respondem por mais de 70% do total de entradas, indicando que o ramo de detalhe presta mais atenção às informações locais .
No entanto, I[I−1], I[I] e I[I+1] representam apenas menos de 26% do total de entradas da ramificação de contexto, portanto, a ramificação de contexto enfatiza as informações ao redor .
Conforme mostrado na Figura 3-Inferior, a ramificação de contexto é menos sensível a alterações de informações locais do que a ramificação de detalhes. A ramificação de detalhes e a ramificação de contexto do domínio espacial se comportam de maneira semelhante aos controladores P (atual) e I (anterior) do domínio do tempo.
Substitua z−1 na transformada z do controlador PID por e−jω, expresso como:

Quando a frequência de entrada ω aumenta, os ganhos dos controladores I e D tornam-se menores e maiores, respectivamente, de modo que os controladores P, I e D funcionam como filtros passa-tudo, passa-baixa e passa-alta, respectivamente. Como o controlador PI presta mais atenção à parte de baixa frequência do sinal de entrada, ele não pode responder imediatamente às mudanças rápidas do sinal, portanto, ele próprio tem o problema de ultrapassar. Os controladores D reduzem o overshoot tornando a saída de controle sensível a mudanças no sinal de entrada. Figura 3 — A parte inferior mostra que a ramificação de detalhes analisa várias informações semânticas, embora de forma imprecisa, enquanto a ramificação de contexto agrega informações contextuais de baixa frequência e, da mesma forma, usa um grande filtro de média semanticamente. A fusão direta de informações detalhadas e informações de contexto leva à perda de alguns recursos de detalhes. Portanto, concluímos que o TBN é equivalente a um controlador PI no domínio de Fourier .
3.1. PIDNet: Uma nova rede de três ramificações
Para aliviar o problema de overshooting, anexamos um ramo diferencial auxiliar (ADB) ao TBN para simular um controlador PID e destacar espacialmente as informações semânticas de alta frequência. Como a semântica dos pixels dentro de cada objeto é consistente, as inconsistências ocorrem apenas nos limites dos objetos adjacentes, portanto, apenas nos limites dos objetos, a diferença na semântica é diferente de zero, o ADB visa a detecção de limites. Assim, construímos uma nova arquitetura de segmentação semântica em tempo real com três ramificações, a Rede Proporcional-Integral-Derivativa (PIDNet), conforme mostrado na Figura 4.

PIDNet tem três ramificações com funções complementares: a ramificação proporcional (P) analisa e preserva informações detalhadas em mapas de recursos de alta resolução; a ramificação integral (I) agrega informações contextuais locais e globais para resolver dependências de longo prazo; a derivada (D) branch extrai recursos de alta frequência e prevê regiões de fronteira. Como em [20], também empregamos os blocos residuais em cascata [19] como a espinha dorsal para compatibilidade de hardware. Além disso, a profundidade das ramificações P, I e D é definida como Moderada, Profunda e Rasa para alta eficiência. Assim, aprofundando e expandindo o modelo, foram geradas as séries pidnet (PIDNet-S, M e L).
Seguindo [20, 28, 51], colocamos uma cabeça semântica na saída do primeiro módulo Pag, gerando uma perda semântica adicional l0 para otimizar melhor toda a rede. Uma perda de entropia cruzada binária ponderada l1 é adotada para resolver o problema de desbalanceamento de detecção de limite em vez de perda de dados [13]. Porque é mais inclinado a limites irregulares para destacar a área de limite e aprimorar as características de pequenos alvos. l2 e l3 denotam perda de CE, enquanto l3 utiliza a saída de perda de CE com reconhecimento de limite [46] pelo cabeçote de limite para coordenar tarefas de segmentação semântica e detecção de limite e aprimorar a função do módulo Bag. O cálculo de BAS-Loss pode ser escrito como:
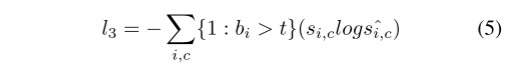
onde t é um limite predefinido, bi, si,c e ˆsi,c são respectivamente o cabeçalho de limite do i-ésimo pixel da classe c, a verdade de referência da segmentação e a saída do resultado da predição. Portanto, a perda final do PIDNet é:
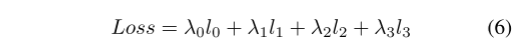
De acordo com a experiência, definimos os parâmetros de perda de treinamento do PIDNet como: λ0 = 0,4, λ1 = 20, λ2 = 1, λ3 = 1, t = 0,8.
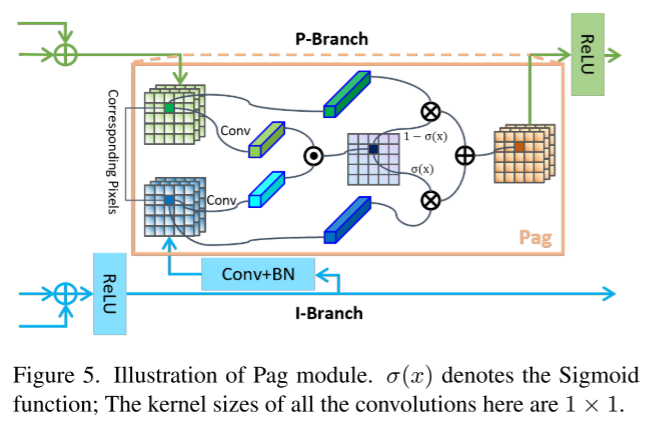
3.2 Pag: Aprendizado Seletivo de Semântica Avançada
As conexões laterais usadas em [20, 35, 48] aumentam a transferência de informações entre mapas de características de diferentes escalas e melhoram a expressividade dos modelos de mapas de características. No PIDNet, as informações semânticas ricas e precisas fornecidas pelo ramo I são cruciais para a análise detalhada e detecção de limites dos ramos P e D, que contêm relativamente poucas camadas e canais. Portanto, tratamos o ramo I como um backup dos outros dois e permitimos que ele forneça as informações necessárias. Diferente do mapa de recursos fornecido pela adição direta do ramo D, introduzimos o módulo de fusão guiado por atenção de pixel (Pixel-attention-guided fusion module, Pag) conforme mostrado na Figura 5, para que o ramo P possa ser seletivamente fundidas do ramo I para aprender características semânticas úteis. O conceito básico de Pag é emprestado do mecanismo de atenção [47]. Defina os vetores dos pixels correspondentes nos mapas de recursos do ramo P e do ramo I como vp e vi respectivamente, então a saída da função Sigmoide pode ser expressa como:

σ representa a probabilidade de que esses dois pixels pertençam ao mesmo objeto. Se σ for alto, confiamos mais em vi porque o ramo I é semanticamente rico e preciso, e vice-versa. Portanto, a saída de Pag pode ser escrita como:

(Verde e azul correspondem à parte superior de P e I na Figura 4. O desenho é mais complicado. Na verdade, isso é muito comum. A função é fundir dois recursos. A taxa de fusão σ é calculada com base nos vetores de recursos dos dois.)
3.3. PAPPM: Agregação rápida de contexto
Para melhor construir a cena global, PSPNet [59] introduz um Pyramid Pooling Module (PPM), que concatena mapas de pooling multi-escala antes de camadas convolucionais para formar representações contextuais locais e globais. O Deep Aggregation PPM (DAPPM) proposto por [20] melhora ainda mais a capacidade de incorporação de contexto do PPM e mostra um desempenho superior. No entanto, o processo de cálculo do DAPPM não pode ser paralelizado em profundidade e leva muito tempo, e o DAPPM contém muitos canais em cada escala, o que pode exceder a capacidade de representação do modelo leve. Portanto, modificamos as conexões em DAPPM para serem paralelizáveis, conforme mostra a Figura 6, e reduzimos o número de canais por escala de 128 para 96. Este novo módulo de coleta de contexto é chamado de Parallel Aggregation PPM (PAPPM) e é aplicado ao PIDNet-M e ao PIDNet-S para garantir sua velocidade. Para nosso modelo profundo: PIDNet-L, considerando a profundidade do DAPPM, ainda escolhemos o DAPPM, mas reduzimos seu número de canais, para que o cálculo seja menor e a velocidade seja mais rápida.

3.4 Bolsa: detalhes de balanceamento e contexto
Considerando as características de contorno extraídas pelo ADB, utilizamos atenção de contorno para guiar a fusão das representações de detalhe (P) e contexto (I). Especificamente, projetamos um módulo de fusão guiado por atenção de limite (Bag), conforme mostrado na Fig. 7, que preenche regiões de alta frequência e baixa frequência com recursos de detalhe e recursos contextuais, respectivamente. Observe que a ramificação de contexto é semanticamente precisa, mas perde muitos detalhes espaciais e geométricos, especialmente para regiões limítrofes e objetos pequenos. Como a ramificação de detalhes preserva melhor os detalhes espaciais, forçamos o modelo a confiar na ramificação de detalhes ao longo das regiões de borda e preencher outras regiões com recursos contextuais. Defina os vetores de pixels correspondentes aos mapas de recursos P, I e D como vp, vi e vd, respectivamente, então as saídas de Sigmoid, Bag e Light-Bag podem ser expressas como:

onde f é uma combinação de convolução, normalização de lote e ReLUs. Apesar de substituirmos a convolução 3 × 3 em Bag por duas convoluções 1 × 1 em Light-Bag, as funções de Bag e Light-Bag são semelhantes, ou seja, quando σ > 0,5, o modelo confia mais nas características detalhadas, ao invés de Informação contextual.

(Na verdade, é PDI de cima para baixo, D é usado como o peso σ e Light-Bag usa 1 * 1 pequena convolução para ser mais leve, que é semelhante a Pag)
4. Experimente
Nesta seção, nossos modelos são treinados e testados nos benchmarks Cityscape, CamVid e PASCAL Context.
4.1. Conjuntos de dados
paisagem urbana . Cityscape [12] é um dos mais famosos conjuntos de dados de análise de cenas urbanas, que contém 5.000 imagens coletadas da perspectiva de carros em diferentes cidades. Essas imagens são divididas em 2975, 500 e 1525 grupos para treinamento, validação e teste. A resolução da imagem é de 2048×1024, o que é um desafio para modelos em tempo real. Somente conjuntos de dados anotados são usados aqui.
CamVid . O CamVid [5] fornece 701 imagens de cenas de direção, divididas em 367, 101 e 233 imagens, para treinamento, verificação e teste. A resolução da imagem é de 960×720, e existem 32 categorias rotuladas, 11 das quais são comparadas com trabalhos anteriores.
PASCAL Context fornece anotação semântica de toda a cena em PASCAL Context [33], que contém 4998 imagens para treinamento e 5105 imagens para validação. Embora este conjunto de dados seja usado principalmente para modelos de referência de alta precisão, nós o usamos aqui para demonstrar a capacidade de generalização de PIDNets. Ambos os cenários de nível 59 e nível 60 foram avaliados.
4.2. Detalhes da Implementação
Pré-treinamento Antes de ajustar nossos modelos, nós os pré-treinamos via ImageNet [41], como na maioria dos trabalhos anteriores [20, 34, 35]. Removemos o ramo D no estágio final e mesclamos recursos diretamente para construir um modelo de classificação. O número total de épocas de treinamento é 90, e a taxa de aprendizado é inicialmente definida como 0,1 e multiplicada por 0,1 nas épocas 30 e 60. As imagens são cortadas aleatoriamente para 224 × 224 e invertidas horizontalmente para aumento de dados.
Treinamento Nosso esquema de treinamento é quase o mesmo dos trabalhos anteriores [15, 20, 52]. Especificamente, atualizamos a taxa de aprendizado com uma estratégia multicluster, recorte aleatório, inversão horizontal aleatória e escala aleatória no intervalo [0,5, 2,0] para aumento de dados. O número de períodos de treinamento, taxa de aprendizado inicial, queda de peso, tamanho da colheita e tamanho do lote da paisagem urbana, Contexto CamVid e PASCAL são [484, 1e−2, 5e−4, 1024 × 1024, 12], [200,1e− 3 ,5e−4,960×720,12] e [200,1e−3,1e−4,520×520,16]. Seguindo [20, 51], ajustamos o modelo CamVid pré-treinado da paisagem urbana e paramos o processo de treinamento quando lr < 5e−4 para evitar overfitting
Inferência Antes do teste, nossos modelos são treinados e val-set em Cityscape e CamVid. Medimos a velocidade de inferência em uma plataforma que consiste em RTX 3090, PyTorch 1.8, CUDA 11.2, cuDNN 8.0 e um ambiente Windows Conda. Aproveitando os protocolos métricos propostos em [10] e subsequentemente [20, 35, 45], integramos a normalização de lote em camadas convolucionais e definimos o tamanho do lote como 1 para medir a velocidade de inferência.
4.3. Estudo de ablação
ADB para redes de duas filiais
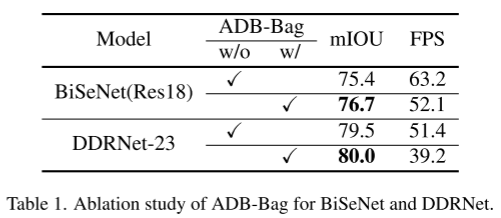
Para demonstrar a eficácia da abordagem PID, combinamos ADB e Bag com modelos existentes. Aqui, implementamos duas redes representativas de ramificação dupla: BiSeNet [52] e DDRNet [20] equipadas com ADB e Bag, que atingem uma precisão muito maior do que o modelo original no conjunto cityscape val, como mostra a Tabela 1. No entanto, a computação extra diminui significativamente sua velocidade de inferência, o que nos levou a construir o PIDNet.
Colaboração de Pag e Bag
Antes do estágio de fusão, o ramo P usa o módulo Pag para obter informações úteis do ramo I sem ficar sobrecarregado e introduz o módulo Bag para guiar a fusão de recursos detalhados e recursos contextuais. Conforme mostrado na Tabela 2, a conexão lateral pode melhorar significativamente a precisão do modelo e o pré-treinamento pode melhorar ainda mais o desempenho do modelo. Em nosso esquema, a combinação de adicionar conexões laterais e módulos de fusão Bag ou conexões laterais Pag e adicionar módulos de fusão não faz sentido, pois os detalhes devem ser mantidos consistentes em toda a rede. Portanto, precisamos apenas comparar o desempenho de Add + Add e Pag + Bag. Os resultados experimentais na Tabela 2 e Tabela 3 ilustram a superioridade da sinergia Pag e Bag (ou Light-Bag). A visualização do mapa de características na Figura 8 mostra que no mapa sigmóide do segundo Pag, objetos pequenos ficam muito mais escuros do que objetos grandes, e meu ramo perde mais detalhes. Além disso, na saída do módulo Bag, as características das regiões de contorno e de pequenos objetos também são bastante aprimoradas, conforme mostrado na Figura 9, e é por isso que escolhemos a detecção de limite grosseiro.

Eficiência do PAPPM.
Para modelos em tempo real, um módulo de agregação de contexto pesado pode retardar significativamente a inferência e pode exceder a capacidade de representação da rede. Portanto, propomos PAPPM que consiste em uma estrutura paralela e um pequeno número de parâmetros. Os resultados experimentais na Tabela 3 mostram que em nosso modelo leve, o PAPPM atinge a mesma precisão que o DAPPM [20], mas com uma aceleração de 9,5 FPS.

Efetividade das perdas Extra.
O PIDNet introduz três perdas adicionais para facilitar a otimização de toda a rede e enfatizar a função de cada componente. A partir da Tabela 4, pode-se ver que para um melhor desempenho, a perda de limite l1 e a perda de limite l3 são necessárias, especialmente a perda de limite (+1,1% mIOU), o que prova fortemente a necessidade de ramificação d, enquanto a mineração de exemplo difícil online ( OHEM) [43] melhora ainda mais a precisão.
4.4. Comparação
CamVid.
Para o conjunto de dados CamVid [5], apenas a precisão do DDRNet pode ser comparada com nosso modelo, então testamos sua velocidade em nossa plataforma, que é mais avançada que a deles para uma comparação justa. Os resultados experimentais na Tabela 5 mostram que a precisão de todos os nossos modelos excede 80% mIOU, o PIDNet-S-Wider simplesmente dobra o número de canais do pidnet, obtém a maior precisão e é muito melhor do que os modelos anteriores. grande vantagem. Além disso, o PIDNet-S atinge uma melhoria de precisão de 1,5% mIOU em relação ao modelo de última geração DDRNet-23-S anterior, com apenas ~1 ms de latência adicionada.

Paisagens urbanas.
Trabalhos anteriores em tempo real usam a paisagem urbana [12] como referência padrão, considerando sua interpretação de alta qualidade. Conforme mostrado na Tabela 6, para uma comparação justa, testamos a velocidade de inferência de modelos lançados nos últimos dois anos na mesma plataforma sem nenhuma ferramenta de aceleração. Resultados experimentais mostram que PIDNets alcançam o melhor equilíbrio entre velocidade de inferência e precisão de inferência. Entre eles, o PIDNet-L superou o SFNet (ResNet18)† e o DDRNet-39 em termos de velocidade e precisão, e a precisão do teste aumentou de 80,4% mIOU para 80,64% mIOU, tornando-se o modelo mais preciso no campo de tempo real. O PIDNet-M e o PIDNet-S também fornecem maior precisão em comparação com outros modelos com velocidade de inferência semelhante. Ao remover os módulos Pag e Bag do PIDNet-S, fornecemos uma alternativa mais rápida: o PIDNet-S-simple, que generaliza menos bem, mas ainda atinge a maior precisão em modelos com latência < 10 ms .
Contexto PASCAL.
O caminho Avg(17,8) no PAPPM é removido porque o tamanho da imagem é muito pequeno no Contexto PASCAL [33]. Diferente dos outros dois conjuntos de dados, este artigo emprega inferência multiescala e invertida para comparação com modelos anteriores. Apesar das anotações menos detalhadas no Contexto PASCAL em comparação com os dois conjuntos de dados anteriores, nosso modelo ainda alcança desempenho competitivo em redes pesadas existentes, conforme mostrado na Tabela 7.
5. Conclusão
Uma nova estrutura de rede de três ramos é proposta: rede de segmentação semântica em tempo real PIDNet. O PIDNet alcança um equilíbrio ideal entre tempo de inferência e precisão. Mas como o PIDNet utiliza previsão de limite para equilibrar informações detalhadas e informações contextuais, é necessária uma anotação precisa perto dos limites para um melhor desempenho, o que geralmente requer muito tempo.
(A ideia é um pouco como bmaskrcnn, adicionando informações de borda, mas está realmente relacionado ao PID, ou está apenas pegando emprestado este formulário, que não tem nada a ver com a sensação real de integral e diferencial, mas devo dizer que o efeito Precisa ser bom)