Índice
scrapy-framework
pipeline-itrm-shell
login simulado scrapy
imagem de download raspada
Baixar middleware
scrapy-framework
significado:
Composição: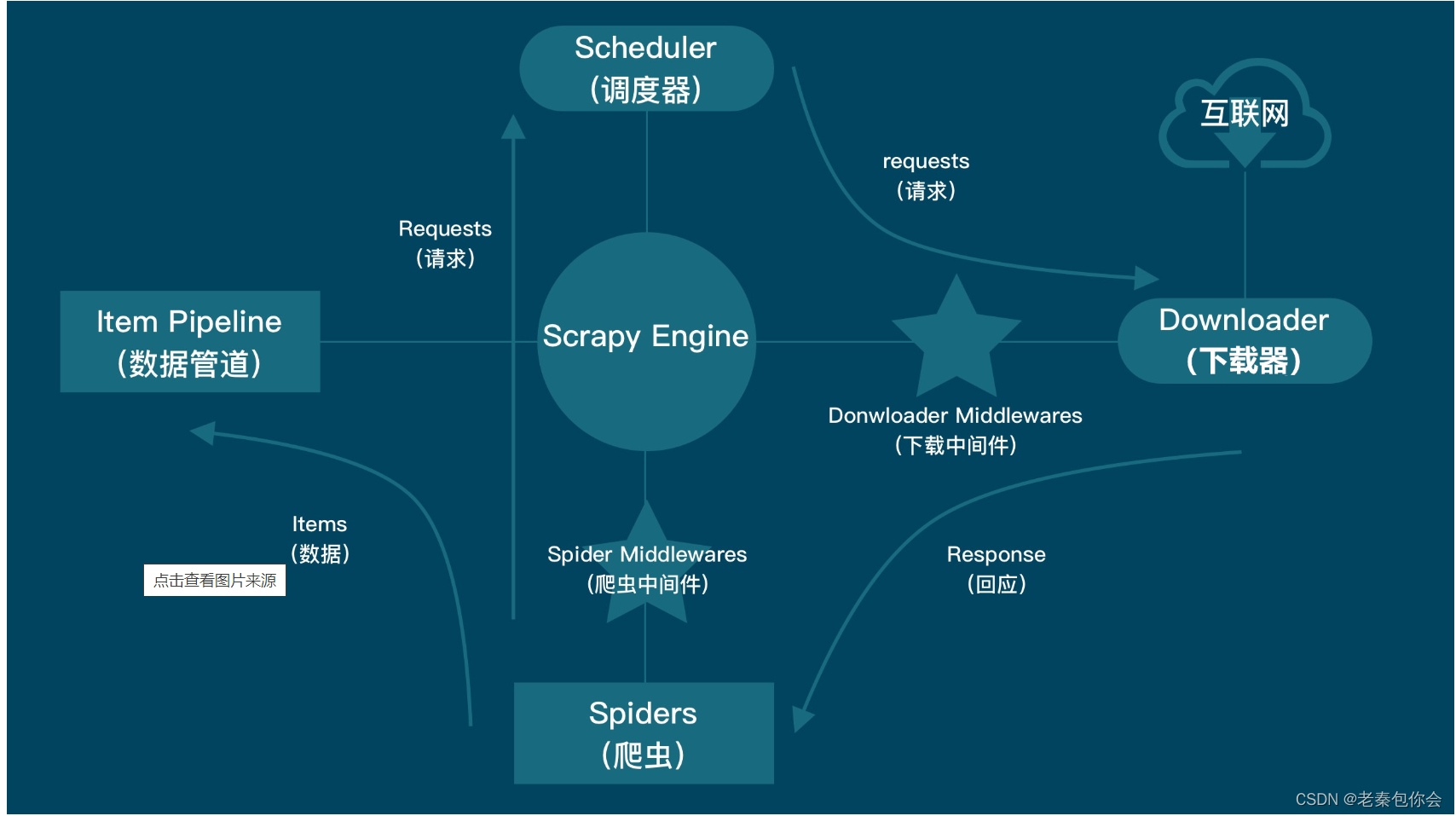

Processo em execução: 1. A estrutura scrapy obtém start_urls e constrói uma solicitação de solicitação
2. A solicitação é enviada ao mecanismo scrapy, passando pelo middleware do rastreador, e o mecanismo envia a solicitação ao agendador (uma fila armazena a solicitação)
3. O agendador envia a solicitação de solicitação ao mecanismo
4. O mecanismo então envia a solicitação de solicitação ao downloader, passando pelo middleware de download no meio
5. O downloader acessa a Internet e retorna uma resposta
6. O downloader envia a resposta obtida para o mecanismo e passa pelo middleware de download no meio
7. O mecanismo envia a resposta ao rastreador, passando pelo middleware do rastreador no caminho
8. O rastreador obtém dados através da resposta, (você pode obter url,....) Se você quiser enviar outra solicitação, construa uma solicitação de solicitação para enviar ao mecanismo e recicle-a uma vez. Se você não enviar uma solicitação , enviar os dados para o Engine, passando pelo middleware do rastreador
9. O mecanismo envia os dados para o pipeline
10. Pipeline para salvar
Vamos primeiro criar um projeto através da página cmd


c:/d:/e: --->Trocar disco de rede
nome do arquivo cd -----> alternar para o arquivo
scrapy startproject nome do projeto --------> criar projeto
scrapy genspider crawler nome do domínio nome do domínio -------> criar arquivo crawler
nome do arquivo do rastreador de rastreamento scrapy ------------> executar arquivo do rastreador
Também podemos criar um arquivo start.py para executar o arquivo crawler (para criar a primeira camada sob o projeto)
Onde o arquivo foi criado:

Código para executar o arquivo do rastreador:
from scrapy import cmdline
# cmdline.execute("scrapy crawl baidu".split())
# cmdline.execute("scrapy crawl novel".split())
cmdline.execute("scrapy crawl shiping".split())importar do cmdline de importação scrapy
cmdline.execute(['scrapy','crawl','crawler file name']): executa o arquivo crawler
Deixe-me analisar os arquivos dentro
Arquivo name.py do rastreador

Pode-se ver que o framework scrapy fornece alguns atributos de classe, e os valores desses atributos de classe podem ser alterados, mas def parse() não pode alterar o nome e passar parâmetros à vontade
arquivo settings.py

Encontre isso e abra, remova o comentário, quanto menor o valor, primeiro será executado, se você não abrir, não poderá transferir os dados para o arquivo pipelines.py
O parâmetro item em process_item() na classe MyScrapyPipeline
Deixe-me demonstrar,
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/review/best/']
def parse(self, response):
print(response.text)resultado:
Ao clicarmos na primeira URL, passaremos para a seguinte
É porque o arquivo do rastreador está em conformidade com uma regra. A solução é a seguinte: encontre o seguinte código no arquivo settings.py:

Altere True para False e execute
resultado:
Pode-se ver que um erro é reduzido
Mas ainda há um erro, vamos resolvê-lo abaixo:
A solução para 403 é adicionar UA (header request header)
Encontre-o aqui como mostrado:

Altere My_scrapy (+http://www.yourdomain.com) para um cabeçalho de solicitação:

resultado:
pode ser acessado normalmente
arquivo middlewares.py (para adicionar cabeçalhos de solicitação)
Mas alguns fofos acham que isso é muito problemático. Se o cabeçalho da solicitação de cabeçalho for alterado com frequência, será muito difícil de usar. Em relação a esse problema, podemos pensar sobre isso. Se adicionarmos um cabeçalho de solicitação durante o processo de envio da solicitação, não será tão problemático. Já, como adicioná-lo?
As gracinhas podem pensar se o middleware pode ser usado:
Em seguida, encontraremos o middleware, que é um arquivo middlewares.py no projeto scrapy

Ao abrirmos este arquivo veremos:
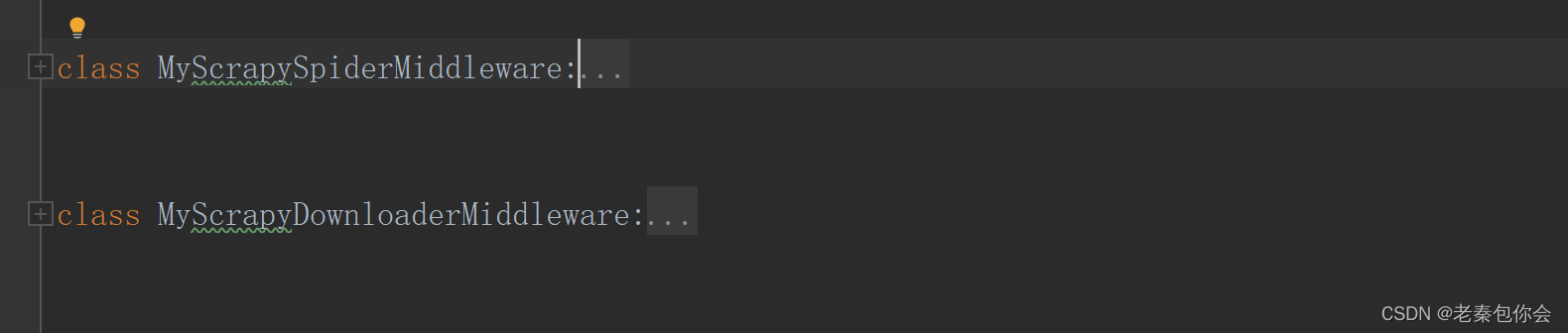
O principal motivo é que esse arquivo grava o middleware do rastreador e o middleware de download no arquivo middlewares.py
MyScrapyDownloaderMiddleware Este é o middleware de download
MyScrapySpiderMiddleware Este é o middleware do rastreador
Então deixe-me explicar MyScrapyDownloaderMiddleware

O principal é que esses dois são mais usados, vamos começar com process_crawler
Captura de tela do código:

Quando imprimirmos, descobriremos que não foi impresso, por que está assim? O motivo é que nosso middleware não foi aberto, então vamos encontrar as configurações e os arquivos py e remover seus comentários
Captura de tela do código:

Uma vez executado com sucesso:

Então vamos tentar process_response novamente
Captura de tela do código:

resultado:
 Pode-se ver que a solicitação está na frente da resposta
Pode-se ver que a solicitação está na frente da resposta
Talvez alguns fofos tenham pensado em algumas situações, você pode criar um pedido e uma resposta?
Vamos tentar
Captura de tela do código:


resultado:

A gracinha cuidadosa vai descobrir que não é o que ele esperava,
Abaixo intercepto o middleware de download:

este é o problema
Deixe-me explicar o seguinte:
process_request(solicitação, spider)
# - return None: continue processando esta requisição
será repassado quando return None, como o process_request() do duoban retornar return None irá executar o process_request() do middleware de download
# - ou retornar um objeto Request
quando retornar (um objeto Request ) não será repassado, como o process_request() do duoban retorna return (um objeto Request), ele não executará o process_request() do middleware de download, mas retornará ao mecanismo, e o mecanismo retornará ao agendador (retorno no mesmo way) # -
ou retornar um objeto Response
não será passado quando return (um objeto Response), como o process_request() do duoban retorna return (um objeto Response), ele não executará o process_request() do middleware de download, mas retornará para o mecanismo, e o mecanismo retorna ao arquivo Crawler (nível cruzado)
# - ou levanta IgnoreRequest: process_exception () métodos de Se este método lançar uma exceção, o método process_exception será chamado
# middleware de downloader instalado será chamado
process_response(solicitação, resposta, aranha)
# - retorna um objeto Response
# - retorna um objeto Request
Retorna o objeto Request: interrompe a chamada do intermediário e coloca-o no agendador para ser agendado para download;
# - ou levanta IgnoreRequest
Alguns fofos vão pensar, posso criar um middleware sozinho para adicionar cabeçalhos de solicitação: (no arquivo middlewares.py )
from scrapy import signals
import random
class UsertMiddleware:
User_Agent=["Mozilla/5.0 (compatible; MSIE 9.0; AOL 9.7; AOLBuild 4343.19; Windows NT 6.1; WOW64; Trident/5.0; FunWebProducts)",
"Mozilla/4.0 (compatible; MSIE 8.0; AOL 9.7; AOLBuild 4343.27; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"]
def process_request(self, request, spider):
# 添加请求头
print(dir(request))
request.headers["User-Agent"]=random.choice(self.User_Agent)
# 添加代理ip
# request.meta["proxies"]="代理ip"
return None
class UafgfMiddleware:
def process_response(self, request, response, spider):
# 检测请求头是否添加上
print(request.headers["User-Agent"])
return response
resultado
é executável
arquivo pipelines.py
process_item(self, item, spider)
item: Recebe os dados retornados pelo arquivo crawler, como um dicionário
Vamos rastejar para Douban
Pratique o rastreamento de imagens de filmes de Douban
Arquivo do rastreador.py:
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com','doubanio.com']
start_urls = ['https://movie.douban.com/review/best/']
a=1
def parse(self, response):
divs=response.xpath('//div[@id="content"]//div[@class="review-list chart "]//div[@class="main review-item"]')
for div in divs:
# print(div.extract)
title=div.xpath('./a/img/@title')
src=div.xpath('./a/img/@src')
# print(title.extract_first())
print(src.extract_first())
yield {
"title": title.extract_first(),
"src": src.extract_first(),
"type": "csv"
}
# 再发请求下载图片
yield scrapy.Request(
url=src.extract_first(),
callback=self.parse_url,
cb_kwargs={"imgg":title.extract_first()}
)
#第一种
# next1=response.xpath(f'//div[@class="paginator"]//a[1]/@href').extract_first()
# 第二种方法自己构建
next1="/review/best?start={}".format(20*self.a)
self.a+=1
url11='https://movie.douban.com'+next1
yield scrapy.Request(url=url11,callback=self.parse)
print(url11)
def parse_url(self,response,imgg):
# print(response.body)
yield {
"title":imgg,
"ts":response.body,
"type":"img"
}
arquivo pipelines.py:
import csv
class MyScrapyPipeline:
def open_spider(self,spider): # 当爬虫开启时调用
header = ["title", "src"]
self.f = open("move.csv", "a", encoding="utf-8")
self.wri_t=csv.DictWriter(self.f,header)
self.wri_t.writeheader()
def process_item(self, item, spider): # 每次传参都会调用一次
if item.get("type")=="csv":
item.pop("type")
self.wri_t.writerow(item)
if item.get("type")=="img":
item.pop("type")
with open("./图片/{}.png".format(item.get("title")),"wb")as f:
f.write(item.get("ts"))
print("{}.png下载完毕".format(item.get("title")))
return item
def close_spider(self,spider):
self.f.close()arquivo settings.py:


Isso só pode produzir o que você deseja produzir
_____________________________________



Todos os itens acima estão abertos
Lembre-se de que, se a solicitação de envio no arquivo do rastreador falhar, a função no arquivo pipelines.py não poderá ser chamada de volta
Maneiras de pausar e retomar o rastreador
Alguns fofos acham que existe uma maneira de pausar e retomar os rastreadores? Se sim, qual é?
Deixe-me falar sobre isso

scrapy crawl crawler file name -s JOBDIR=caminho do arquivo (basta definir)
Ctrl+c pausa o rastreador
Quando a gracinha quiser restaurar novamente, ela descobrirá que o download não pode ser executado,
Qual é o motivo, porque o método que escrevemos é diferente daquele fornecido pela estrutura,
O scrapy.Request é o seguinte:

dont_filte (não filtrar?) r é um filtro, se for False, será filtrado (a mesma url só é acessada uma vez), se for True, não será filtrado
A gracinha vai pensar porque parse() pode enviar, o resultado é o seguinte:

O resultado é bem claro, se não quiser filtrar tem que trocar

Se você deseja filtrar métodos substituídos:

login simulado scrapy
Existem dois métodos:
● 1 carrega cookies diretamente para solicitar a página (semi-automaticamente, use selenium para obter ou obter cookies manualmente)
https://www.1905.com/vod/list/c_178/o3u1p1.html para fazer um caso
O primeiro método é a página de solicitação obtida por login manual
Exemplo de código de arquivo rastreador 1 (adicionar cookie ao arquivo rastreador);
import scrapy
class A17kSpider(scrapy.Spider):
name = '17k'
allowed_domains = ['17k.com']
start_urls = ['https://www.17k.com/']
# 重写
def start_requests(self):
cook="GUID=f0f80f5e-fb00-443f-a6be-38c6ce3d4c61; __bid_n=1883d51d69d6577cf44207; BAIDU_SSP_lcr=https://www.baidu.com/link?url=v-ynoaTMtiyBil1uTWfIiCbXMGVZKqm4MOt5_xZD0q7&wd=&eqid=da8d6ae20003f26f00000006647c3209; Hm_lvt_9793f42b498361373512340937deb2a0=1684655954,1684929837,1685860878; dfxafjs=js/dfxaf3-ef0075bd.js; FPTOKEN=zLc3s/mq2pguVT/CfivS7tOMcBA63ZrOyecsnTPMLcC/fBEIx0PuIlU5HgkDa8ETJkZYoDJOSFkTHaz1w8sSFlmsRLKFG8s+GO+kqSXuTBgG98q9LQ+EJfeSHMvwMcXHd+EzQzhAxj1L9EnJuEV2pN0w7jUCYmfORSbIqRtu5kruBMV58TagSkmIywEluK5JC6FnxCXUO0ErYyN/7awzxZqyqrFaOaVWZZbYUrhCFq0N8OQ1NMPDvUNvXNDjDOLM6AU9f+eHsXFeAaE9QunHk6DLbxOb8xHIDot4Pau4MNllrBv8cHFtm2U3PHX4f6HFkEpfZXB0yVrzbX1+oGoscbt+195MLZu478g3IFYqkrB8b42ILL4iPHtj6M/MUbPcxoD25cMZiDI1R0TSYNmRIA==|U8iJ37fGc7sL3FohNPBpgau0+kHrBi2OlH2bHfhFOPQ=|10|87db5f81d4152bd8bebb5007a0f3dbc3; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F75%252F100257543.jpg-88x88%253Fv%253D1685860834000%26id%3D100257543%26nickname%3D%25E8%2580%2581%25E5%25A4%25A7%25E5%2592%258C%25E5%258F%258D%25E5%25AF%25B9%25E6%25B3%2595%25E7%259A%2584%25E5%258F%258D%26e%3D1701413546%26s%3Db67793dfa5cea859; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100257543%22%2C%22%24device_id%22%3A%221883d51d52d1790-08af8c489ac963-26031a51-1638720-1883d51d52eea0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f0f80f5e-fb00-443f-a6be-38c6ce3d4c61%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1685861547"
yield scrapy.Request(
url=self.start_urls[0],
callback=self.parse,
cookies={lis.split("=")[0]:lis.split("=")[1] for lis in cook.split(";")}
)
def parse(self, response):
# print(response.text)
yield scrapy.Request(url="https://user.17k.com/www/",callback=self.parse_url)
def parse_url(self,response):
print(response.text)
resultado:
Exemplo de código de arquivo rastreador 2 (adicionar cookie para baixar arquivo de middleware);
class MyaddcookieMiddleware:
def process_request(self, request, spider):
cook = "GUID=f0f80f5e-fb00-443f-a6be-38c6ce3d4c61; __bid_n=1883d51d69d6577cf44207; BAIDU_SSP_lcr=https://www.baidu.com/link?url=v-ynoaTMtiyBil1uTWfIiCbXMGVZKqm4MOt5_xZD0q7&wd=&eqid=da8d6ae20003f26f00000006647c3209; Hm_lvt_9793f42b498361373512340937deb2a0=1684655954,1684929837,1685860878; dfxafjs=js/dfxaf3-ef0075bd.js; FPTOKEN=zLc3s/mq2pguVT/CfivS7tOMcBA63ZrOyecsnTPMLcC/fBEIx0PuIlU5HgkDa8ETJkZYoDJOSFkTHaz1w8sSFlmsRLKFG8s+GO+kqSXuTBgG98q9LQ+EJfeSHMvwMcXHd+EzQzhAxj1L9EnJuEV2pN0w7jUCYmfORSbIqRtu5kruBMV58TagSkmIywEluK5JC6FnxCXUO0ErYyN/7awzxZqyqrFaOaVWZZbYUrhCFq0N8OQ1NMPDvUNvXNDjDOLM6AU9f+eHsXFeAaE9QunHk6DLbxOb8xHIDot4Pau4MNllrBv8cHFtm2U3PHX4f6HFkEpfZXB0yVrzbX1+oGoscbt+195MLZu478g3IFYqkrB8b42ILL4iPHtj6M/MUbPcxoD25cMZiDI1R0TSYNmRIA==|U8iJ37fGc7sL3FohNPBpgau0+kHrBi2OlH2bHfhFOPQ=|10|87db5f81d4152bd8bebb5007a0f3dbc3; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F75%252F100257543.jpg-88x88%253Fv%253D1685860834000%26id%3D100257543%26nickname%3D%25E8%2580%2581%25E5%25A4%25A7%25E5%2592%258C%25E5%258F%258D%25E5%25AF%25B9%25E6%25B3%2595%25E7%259A%2584%25E5%258F%258D%26e%3D1701413546%26s%3Db67793dfa5cea859; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100257543%22%2C%22%24device_id%22%3A%221883d51d52d1790-08af8c489ac963-26031a51-1638720-1883d51d52eea0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f0f80f5e-fb00-443f-a6be-38c6ce3d4c61%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1685861547"
cookies = {lis.split("=")[0]: lis.split("=")[1] for lis in cook.split(";")}
request.cookies=cookies
return NoneExemplo de código de arquivo de rastreador três (adicionar cookie para baixar o arquivo de middleware);
def sele():
#创建一个浏览器
driver=webdriver.Chrome()
#打开网页
driver.get("https://user.17k.com/www/bookshelf/")
print("你有15秒的时间登入")
time.sleep(15)
print(driver.get_cookies())
print({i.get("name"):i.get("value") for i in driver.get_cookies()})
class MyaddcookieMiddleware:
def process_request(self, request, spider):
sele()
return NoneEncontre uma interface para enviar uma solicitação de postagem para armazenar cookies
Código 1:
import scrapy
class A17kSpider(scrapy.Spider):
name = '17k'
allowed_domains = ['17k.com']
start_urls = ['https://www.17k.com/']
# # 重写
# def start_requests(self):
# cook="GUID=f0f80f5e-fb00-443f-a6be-38c6ce3d4c61; __bid_n=1883d51d69d6577cf44207; BAIDU_SSP_lcr=https://www.baidu.com/link?url=v-ynoaTMtiyBil1uTWfIiCbXMGVZKqm4MOt5_xZD0q7&wd=&eqid=da8d6ae20003f26f00000006647c3209; Hm_lvt_9793f42b498361373512340937deb2a0=1684655954,1684929837,1685860878; dfxafjs=js/dfxaf3-ef0075bd.js; FPTOKEN=zLc3s/mq2pguVT/CfivS7tOMcBA63ZrOyecsnTPMLcC/fBEIx0PuIlU5HgkDa8ETJkZYoDJOSFkTHaz1w8sSFlmsRLKFG8s+GO+kqSXuTBgG98q9LQ+EJfeSHMvwMcXHd+EzQzhAxj1L9EnJuEV2pN0w7jUCYmfORSbIqRtu5kruBMV58TagSkmIywEluK5JC6FnxCXUO0ErYyN/7awzxZqyqrFaOaVWZZbYUrhCFq0N8OQ1NMPDvUNvXNDjDOLM6AU9f+eHsXFeAaE9QunHk6DLbxOb8xHIDot4Pau4MNllrBv8cHFtm2U3PHX4f6HFkEpfZXB0yVrzbX1+oGoscbt+195MLZu478g3IFYqkrB8b42ILL4iPHtj6M/MUbPcxoD25cMZiDI1R0TSYNmRIA==|U8iJ37fGc7sL3FohNPBpgau0+kHrBi2OlH2bHfhFOPQ=|10|87db5f81d4152bd8bebb5007a0f3dbc3; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F75%252F100257543.jpg-88x88%253Fv%253D1685860834000%26id%3D100257543%26nickname%3D%25E8%2580%2581%25E5%25A4%25A7%25E5%2592%258C%25E5%258F%258D%25E5%25AF%25B9%25E6%25B3%2595%25E7%259A%2584%25E5%258F%258D%26e%3D1701413546%26s%3Db67793dfa5cea859; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100257543%22%2C%22%24device_id%22%3A%221883d51d52d1790-08af8c489ac963-26031a51-1638720-1883d51d52eea0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f0f80f5e-fb00-443f-a6be-38c6ce3d4c61%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1685861547"
# yield scrapy.Request(
# url=self.start_urls[0],
# callback=self.parse,
# cookies={lis.split("=")[0]:lis.split("=")[1] for lis in cook.split(";")}
# )
#
# def parse(self, response):
# # print(response.text)
# # yield scrapy.Request(url="https://user.17k.com/www/bookshelf/",callback=self.parse_url)
# pass
# def parse_url(self,response):
#
# # print(response.text)
# pass
#发送post请求
def parse(self, response):
data={
"loginName": "15278307585",
"password": "wasd1234"
}
yield scrapy.FormRequest(
url="https://passport.17k.com/ck/user/login",
callback=self.prase_url,
formdata=data
)
#适用于该页面有form表单
# yield scrapy.FormRequest.from_response(response,formdata=data,callback=self.start_urls)
def prase_url(self,response):
print(response.text)Além desses, você pode retornar o objeto de resposta baixando o middleware
from scrapy import signals
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
from scrapy.http.response.html import HtmlResponse
lass MyaaacookieMiddleware:
def process_request(self, request, spider):
# 创建一个浏览器
driver=webdriver.Chrome()
# 打开浏览器
driver.get("https://juejin.cn/")
driver.implicitly_wait(3)
# js语句下拉
for i in range(3):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(3)
html=driver.page_source
return HtmlResponse(url=driver.current_url,body=html,request=request,encoding="utf-8")Isso é tudo para o acima.
Resumir
A estrutura scrapy é para resolver a grande quantidade de reescrita de código causada pelo rastreamento de muitos dados e resolver o problema com uma pequena quantidade de código