Índice
1. Prefácio e conjunto de dados
2. Divida os conjuntos de dados e modifique os arquivos de configuração
1. Coloque as imagens e os arquivos de anotação .txt na pasta VOCData correspondente
arquivo 2..txt para arquivo .xml
3. Crie o programa split_train_val.py no diretório VOCData e execute-o
4. Converta o formato xml para o formato yolo_txt
5. Configure os arquivos de teste
3. Agrupamento para obter um quadro a priori
2. Modifique o arquivo de configuração do modelo
2. Teste a taxa de quadros do vídeo
1. Arquivo de peso .pt para .pth
2. Formato do arquivo.xml para .json
1. Prefácio e conjunto de dados
Este meu tutorial ganhou o apoio de muitos amigos. Sou muito grato a todos aqui. Vou postar um artigo um pouco mais alto hoje.
O artigo acima é para ensiná-lo a criar um modelo de peso DIY para detecção de alvos do zero. Para alunos de graduação em projetos de água (como eu), a maior parte do tempo é gasto em encontrar e rotular conjuntos de dados.
Muitos amigos me perguntaram onde encontrar o conjunto de dados. Este tutorial é minha ideia, mas muitos deles também são conjuntos de imagens, sem arquivos de anotação. Como encontrar o conjunto de dados YOLOv5 de detecção de alvo? _O Blog do Niu Da 2023-CSDN Blog
No entanto, algumas competições e projetos de código aberto fornecerão imagens + conjuntos de dados de anotações para os concorrentes. Por exemplo, esta pequena competição fornece conjuntos de dados prontos com imagens explicativas
Conjunto de treinamento: 28773 imagens endoscópicas de pólipos colorretais (imagens brutas, rótulos e arquivos Readme).O link do disco de rede é o seguinte:Link: https://pan.baidu.com/s/1n08y04DokW5LyF0t7tMIogExtrair código: tmkn



Finalmente, ensine todos a chamar val.py para testar e obter dados relevantes.
2. Divida os conjuntos de dados e modifique os arquivos de configuração
A estrutura geral ainda é como este documento, Xiaobai YOLOv5 todo o processo de treinamento + reconhecimento digital_Crie um script no diretório raiz de yolov5, crie um arquivo split_train_val.py_Niu Da 2023 Blog-CSDN Blog
1. Coloque as imagens e os arquivos de anotação .txt na pasta VOCData correspondente

arquivo 2..txt para arquivo .xml
Crie um arquivo txt_to_xml.py na pasta VOCData , copie e cole o seguinte código, preste atenção no caminho e na categoria a ser modificada
import os
import xml.etree.ElementTree as ET
from PIL import Image
import numpy as np
# 图片文件夹,后面的/不能省
img_path = 'D:/python_work/yolov5/VOCData/images/'
# txt文件夹,后面的/不能省
labels_path = 'D:/python_work/yolov5/VOCData/labels/'
# xml存放的文件夹,后面的/不能省
annotations_path = 'D:/python_work/yolov5/VOCData/Annotations/'
labels = os.listdir(labels_path)
# 类别
classes = ["GHP","APC"] #类别名
# 图片的高度、宽度、深度
sh = sw = sd = 0
def write_xml(imgname, sw, sh, sd, filepath, labeldicts):
'''
imgname: 没有扩展名的图片名称
'''
# 创建Annotation根节点
root = ET.Element('Annotation')
# 创建filename子节点,无扩展名
ET.SubElement(root, 'filename').text = str(imgname)
# 创建size子节点
sizes = ET.SubElement(root,'size')
ET.SubElement(sizes, 'width').text = str(sw)
ET.SubElement(sizes, 'height').text = str(sh)
ET.SubElement(sizes, 'depth').text = str(sd)
for labeldict in labeldicts:
objects = ET.SubElement(root, 'object')
ET.SubElement(objects, 'name').text = labeldict['name']
ET.SubElement(objects, 'pose').text = 'Unspecified'
ET.SubElement(objects, 'truncated').text = '0'
ET.SubElement(objects, 'difficult').text = '0'
bndbox = ET.SubElement(objects,'bndbox')
ET.SubElement(bndbox, 'xmin').text = str(int(labeldict['xmin']))
ET.SubElement(bndbox, 'ymin').text = str(int(labeldict['ymin']))
ET.SubElement(bndbox, 'xmax').text = str(int(labeldict['xmax']))
ET.SubElement(bndbox, 'ymax').text = str(int(labeldict['ymax']))
tree = ET.ElementTree(root)
tree.write(filepath, encoding='utf-8')
for label in labels:
with open(labels_path + label, 'r') as f:
img_id = os.path.splitext(label)[0]
contents = f.readlines()
labeldicts = []
for content in contents:
# !!!这里要看你的图片格式了,我这里是png,注意修改
img = np.array(Image.open(img_path + label.strip('.txt') + '.jpg'))
# 图片的高度和宽度
sh, sw, sd = img.shape[0], img.shape[1], img.shape[2]
content = content.strip('\n').split()
x = float(content[1])*sw
y = float(content[2])*sh
w = float(content[3])*sw
h = float(content[4])*sh
# 坐标的转换,x_center y_center width height -> xmin ymin xmax ymax
new_dict = {'name': classes[int(content[0])],
'difficult': '0',
'xmin': x+1-w/2,
'ymin': y+1-h/2,
'xmax': x+1+w/2,
'ymax': y+1+h/2
}
labeldicts.append(new_dict)
write_xml(img_id, sw, sh, sd, annotations_path + label.strip('.txt') + '.xml', labeldicts)
#[转载链接](https://zhuanlan.zhihu.com/p/383660741)O arquivo .xml gerado será armazenado na pasta VOCData\Annotations
3. Crie um programa no diretório VOCData split_train_val.py e execute-o
nenhuma modificação
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()Após a execução, o conjunto de teste, conjunto de treinamento, conjunto de verificação de treinamento e conjunto de verificação serão gerados em VOCData\ImagesSets\Main
4. Converta o formato xml para o formato yolo_txt
Crie o programa text_to_yolo.py no diretório VOCData e execute-o
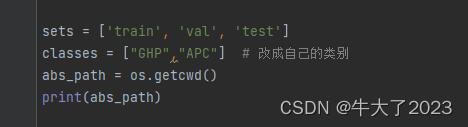
Altere a parte das classes no início para sua própria categoria
Depois disso, o caminho também deve ser alterado para o seu próprio, preste atenção se o sufixo da penúltima linha é .png ou .jpg
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["GHP","APC"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('D:/python_work/yolov5/VOCData/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/python_work/yolov5/VOCData/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:/python_work/yolov5/VOCData/labels/'):
os.makedirs('D:/python_work/yolov5/VOCData/labels/')
image_ids = open('D:/python_work/yolov5/VOCData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('D:/python_work/yolov5/VOCData/dataSet_path/'):
os.makedirs('D:/python_work/yolov5/VOCData/dataSet_path/')
list_file = open('dataSet_path/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('D:/python_work/yolov5/VOCData/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
Entre eles, os rótulos são arquivos de anotações de diferentes imagens. Cada imagem corresponde a um arquivo txt, e cada linha do arquivo contém as informações de um alvo, incluindo classe, x_center, y_center, largura, formato de altura, que é o formato yolo_txt.
A pasta dataSet_path contém arquivos txt de três conjuntos de dados. Os arquivos txt, como train.txt, são os caminhos absolutos dos locais das imagens divididas. Por exemplo, train.txt contém os caminhos absolutos de todas as imagens do conjunto de treinamento.
5. Configure os arquivos de teste
Aqui não encontrei o conjunto de teste sozinho (preguiçoso), encontrei diretamente 100 linhas do train.txt e coloquei no test.txt como um arquivo de teste

6. Arquivo de configuração
Crie um novo arquivo myvoc.yaml (você pode personalizar o nome) na pasta de dados no diretório yolov5 e abra-o com o Bloco de Notas.
O conteúdo é: o caminho do conjunto de treinamento, conjunto de validação e conjunto de teste (train.txt, val.txt e test.txt) ( pode ser alterado para um caminho relativo )
e o número da categoria e o nome da categoria do destino.

3. Agrupamento para obter um quadro a priori
1. Gerar arquivo de âncoras
Crie dois programas kmeans.py e clauculate_anchors.py no diretório VOCData
Não há necessidade de executar kmeans.py, basta executar clauculate_anchors.py.
O programa kmeans.py é o seguinte: Este não precisa ser executado ou alterado, e caso seja reportado algum erro verifique o conteúdo da décima terceira linha.
import numpy as np
def iou(box, clusters):
"""
Calculates the Intersection over Union (IoU) between a box and k clusters.
:param box: tuple or array, shifted to the origin (i. e. width and height)
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: numpy array of shape (k, 0) where k is the number of clusters
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area") # 如果报这个错,可以把这行改成pass即可
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = intersection / (box_area + cluster_area - intersection)
return iou_
def avg_iou(boxes, clusters):
"""
Calculates the average Intersection over Union (IoU) between a numpy array of boxes and k clusters.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: average IoU as a single float
"""
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])])
def translate_boxes(boxes):
"""
Translates all the boxes to the origin.
:param boxes: numpy array of shape (r, 4)
:return: numpy array of shape (r, 2)
"""
new_boxes = boxes.copy()
for row in range(new_boxes.shape[0]):
new_boxes[row][2] = np.abs(new_boxes[row][2] - new_boxes[row][0])
new_boxes[row][3] = np.abs(new_boxes[row][3] - new_boxes[row][1])
return np.delete(new_boxes, [0, 1], axis=1)
def kmeans(boxes, k, dist=np.median):
"""
Calculates k-means clustering with the Intersection over Union (IoU) metric.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param k: number of clusters
:param dist: distance function
:return: numpy array of shape (k, 2)
"""
rows = boxes.shape[0]
distances = np.empty((rows, k))
last_clusters = np.zeros((rows,))
np.random.seed()
# the Forgy method will fail if the whole array contains the same rows
clusters = boxes[np.random.choice(rows, k, replace=False)]
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters)
nearest_clusters = np.argmin(distances, axis=1)
if (last_clusters == nearest_clusters).all():
break
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters
return clusters
if __name__ == '__main__':
a = np.array([[1, 2, 3, 4], [5, 7, 6, 8]])
print(translate_boxes(a))Execute: clauculate_anchors.py
Arquivos que chamarão o agrupamento kmeans.py para gerar novas âncoras
O procedimento é o seguinte:
É necessário alterar o caminho do arquivo das linhas 9 e 13 e o nome da categoria do rótulo da linha 16
# -*- coding: utf-8 -*-
# 根据标签文件求先验框
import os
import numpy as np
import xml.etree.cElementTree as et
from kmeans import kmeans, avg_iou
FILE_ROOT = "D:/python_work/yolov5/VOCData/" # 根路径
ANNOTATION_ROOT = "Annotations" # 数据集标签文件夹路径
ANNOTATION_PATH = FILE_ROOT + ANNOTATION_ROOT
ANCHORS_TXT_PATH = "D:/python_work/yolov5/VOCData/anchors.txt" # anchors文件保存位置
CLUSTERS = 9
CLASS_NAMES = ['GHP','APC'] # 类别名称
def load_data(anno_dir, class_names):
xml_names = os.listdir(anno_dir)
boxes = []
for xml_name in xml_names:
xml_pth = os.path.join(anno_dir, xml_name)
tree = et.parse(xml_pth)
width = float(tree.findtext("./size/width"))
height = float(tree.findtext("./size/height"))
for obj in tree.findall("./object"):
cls_name = obj.findtext("name")
if cls_name in class_names:
xmin = float(obj.findtext("bndbox/xmin")) / width
ymin = float(obj.findtext("bndbox/ymin")) / height
xmax = float(obj.findtext("bndbox/xmax")) / width
ymax = float(obj.findtext("bndbox/ymax")) / height
box = [xmax - xmin, ymax - ymin]
boxes.append(box)
else:
continue
return np.array(boxes)
if __name__ == '__main__':
anchors_txt = open(ANCHORS_TXT_PATH, "w")
train_boxes = load_data(ANNOTATION_PATH, CLASS_NAMES)
count = 1
best_accuracy = 0
best_anchors = []
best_ratios = []
for i in range(10): ##### 可以修改,不要太大,否则时间很长
anchors_tmp = []
clusters = kmeans(train_boxes, k=CLUSTERS)
idx = clusters[:, 0].argsort()
clusters = clusters[idx]
# print(clusters)
for j in range(CLUSTERS):
anchor = [round(clusters[j][0] * 640, 2), round(clusters[j][1] * 640, 2)]
anchors_tmp.append(anchor)
print(f"Anchors:{anchor}")
temp_accuracy = avg_iou(train_boxes, clusters) * 100
print("Train_Accuracy:{:.2f}%".format(temp_accuracy))
ratios = np.around(clusters[:, 0] / clusters[:, 1], decimals=2).tolist()
ratios.sort()
print("Ratios:{}".format(ratios))
print(20 * "*" + " {} ".format(count) + 20 * "*")
count += 1
if temp_accuracy > best_accuracy:
best_accuracy = temp_accuracy
best_anchors = anchors_tmp
best_ratios = ratios
anchors_txt.write("Best Accuracy = " + str(round(best_accuracy, 2)) + '%' + "\r\n")
anchors_txt.write("Best Anchors = " + str(best_anchors) + "\r\n")
anchors_txt.write("Best Ratios = " + str(best_ratios))
anchors_txt.close()Execute para gerar o arquivo de âncoras. Se o arquivo gerado estiver vazio, basta executá-lo novamente.
A segunda linha de Best Anchors precisa ser usada posteriormente. (Este é o valor das âncoras obtidas manualmente)
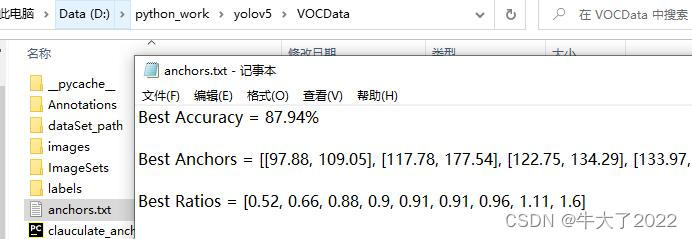
2. Modifique o arquivo de configuração do modelo
Selecione um modelo, a pasta do modelo no diretório yolov5 é o arquivo de configuração do modelo, existem versões n, s, m, l, x, que aumentam gradualmente (conforme a arquitetura aumenta, o tempo de treinamento também aumenta gradualmente).
Aqui, escolha yolov5s.yaml para abrir com o bloco de notas
Altere principalmente dois parâmetros:
Altere nc : de volta ao seu próprio número de categorias de etiquetas (a imagem não foi alterada e a imagem abriu yolov5m por engano...)
Modifique as âncoras , de acordo com as melhores âncoras em âncoras.txt, você precisa arredondar para cima (arredondamento, para cima, para baixo).
Mantenha o formato das âncoras em yaml inalterado, um a um em ordem, como o seis emoldurado e a primeira linha de âncoras 6 (18 deve ser alterado)
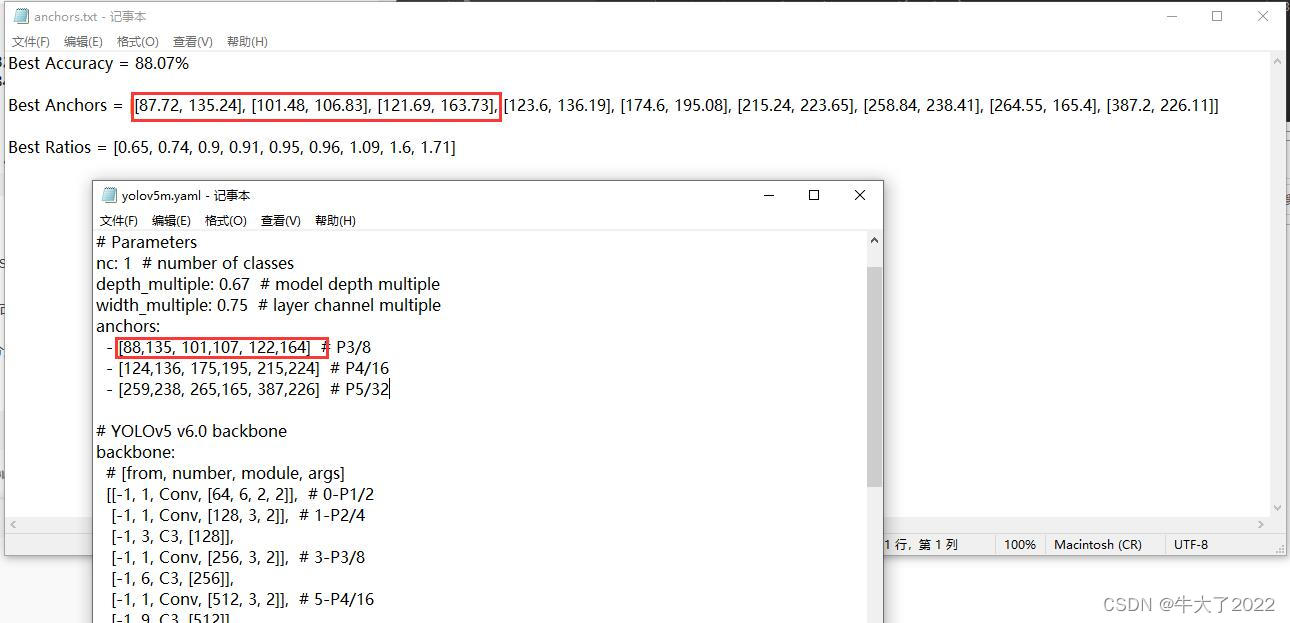
4. Treinamento modelo
1. Comece a treinar
Abra o terminal anaconda, selecione o arquivo yolov5 e ative o ambiente correspondente (meu nome é yolov5)

Em seguida, insira o seguinte comando de treinamento: (Como o conjunto de dados é quase 3w, minha pequena placa gráfica não consegue terminar a execução, mesmo que esteja fumando. Para demonstrar o significado do treinamento por 20 rodadas, o treinamento normal deve ser de pelo menos 50 rodadas)
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 22 --batch-size 8 --img 640 --device 0
Explicação do parâmetro:
–weights weights/yolov5s.pt : Talvez você precise mudar o caminho. Eu coloquei todos os arquivos pt do yolov5 no diretório de pesos, você pode não ter, você precisa mudar o caminho.
--epoch 22: treinar por 22 rodadas
–batch-size 8: atualização de peso após o treinamento 8 imagens
--device cpu: usa CPU para treinamento. //Aqui o dispositivo 0 é o treinamento da gpu
2. Processo de treinamento
22 rodadas levaram mais de 3 horas...
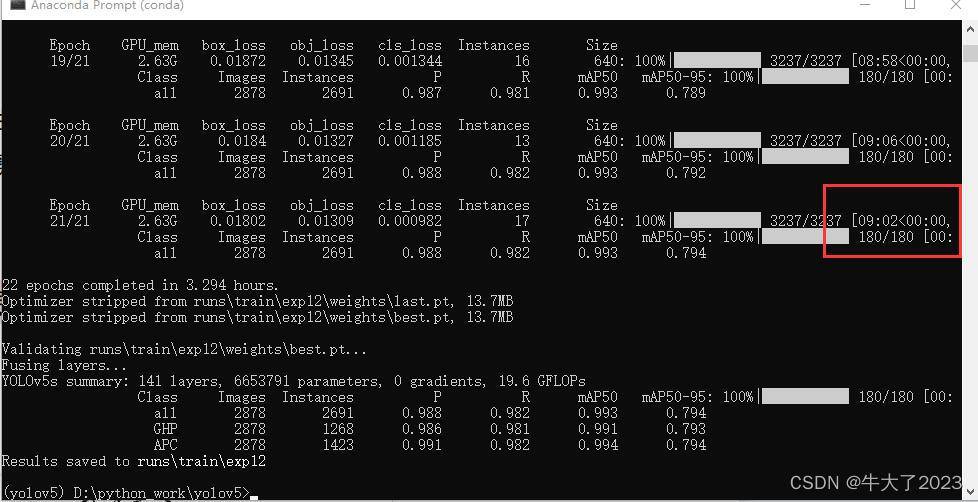
O modelo treinado será salvo em runs/train/weights/expxx no diretório yolov5.
5. Arquivo de teste
Diferente de procurar fotos e vídeos para ver o efeito no passado, desta vez chama o conjunto de teste e retorna dados relevantes
1. Chame o teste val.py
Entre também no console do anaconda
(yolov5) D:\python_work\yolov5>python val.py --weights runs/train/exp12/weights/best.pt --data data/myvoc.yaml --img-size 640 --iou-thres 0.5 -- conf-thres 0.4 --batch-size 8 --task test
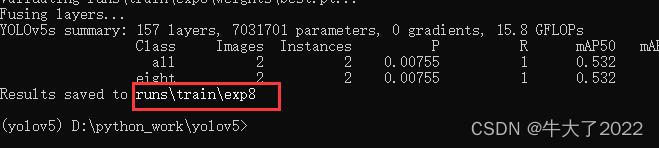
O arquivo de teste será gerado no seguinte caminho
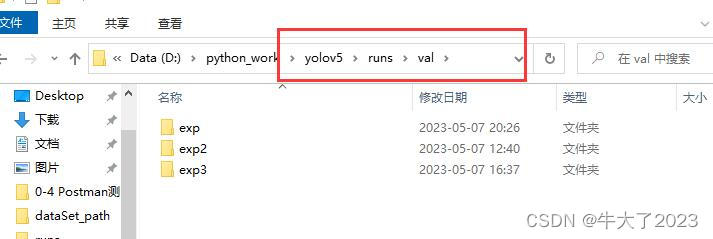
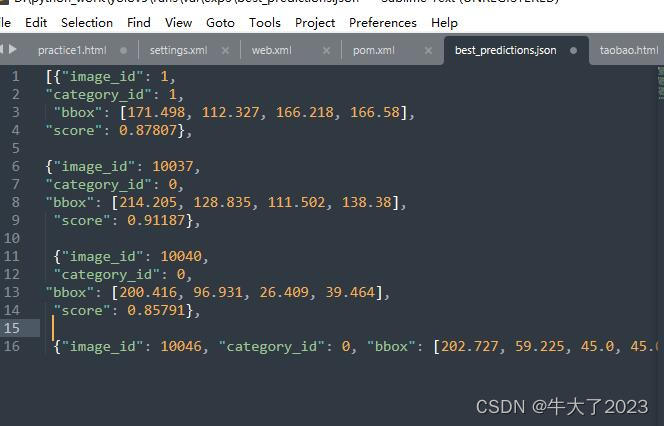
Esses dados serão gerados, dados json previstos, F1, P, PR, R, etc.

2. Teste a taxa de quadros do vídeo
Encontre o arquivo detect.py no diretório principal do yolov5 e abra-o.
Modifique principalmente os pesos e a fonte: (cerca de 218 linhas) vídeo de teste, os resultados do teste estarão em yolov5\runs\detect\exp…
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp12/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='sytest1.mp4', help='source') #file/dir/URL/glob/screen/0(webcam) 
Por fim, use a seguinte função para verificar a taxa de quadros (mas sinto que esse método não é rigoroso, corrija-me)
import cv2
cap = cv2.VideoCapture('result1.mp4')
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 获取帧率
fps = cap.get(cv2.CAP_PROP_FPS)
print(fps)
# 释放视频
cap.release()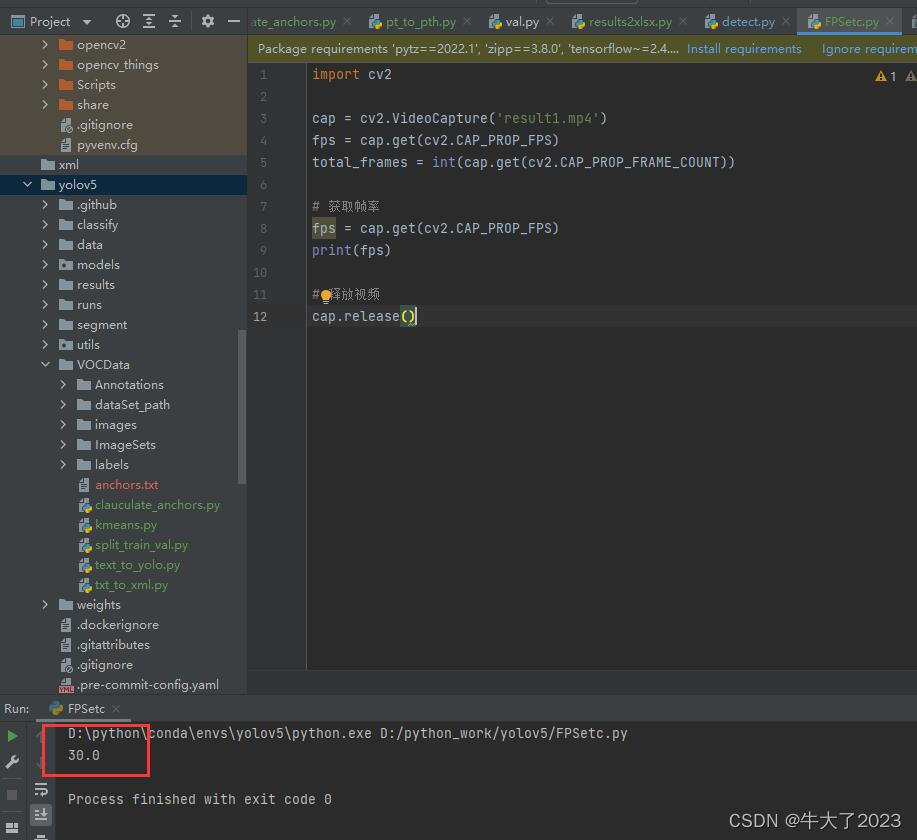
6. Outros
1. Arquivo de peso .pt para .pth
import torch
# 将pt文件转换为pth文件
pt_file_path = 'D:/python_work/yolov5/runs/train/exp12/weights/last.pt'
pth_file_path = 'D:/python_work/yolov5/runs/train/exp12/weights/last.pth'
model_weights = torch.load(pt_file_path)
torch.save(model_weights, pth_file_path)2. Formato do arquivo.xml para .json
import os
import json
import xml.etree.ElementTree as ET
# 指定包含所有.xml文件的文件夹路径
xml_folder = "data/test/labels"
# 定义解析XML文件的函数
def parse_xml(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
# 从XML文件中获取需要的信息,存储在字典中
filename = root.find("filename").text
width = int(root.find("size/width").text)
height = int(root.find("size/height").text)
object_list = []
for obj in root.findall("object"):
name = obj.find("name").text
xmin = int(obj.find("bndbox/xmin").text)
ymin = int(obj.find("bndbox/ymin").text)
xmax = int(obj.find("bndbox/xmax").text)
ymax = int(obj.find("bndbox/ymax").text)
obj_dict = {
"name": name,
"xmin": xmin,
"ymin": ymin,
"xmax": xmax,
"ymax": ymax
}
object_list.append(obj_dict)
# 返回字典
return {
"filename": filename,
"width": width,
"height": height,
"objects": object_list
}
# 解析所有.xml文件并将结果存储在列表中
annotation_list = []
for xml_file in os.listdir(xml_folder):
if xml_file.endswith(".xml"):
xml_path = os.path.join(xml_folder, xml_file)
annotation = parse_xml(xml_path)
annotation_list.append(annotation)
# 将列表写入.json文件中
json_path = "data/test/output.json"
with open(json_path, "w") as f:
json.dump(annotation_list, f)