1. Detecção de alteração por sensoriamento remoto usando modelos probabilísticos de difusão de redução de ruído código
de papel 22-6
Motivação: Há menos imagens de treinamento anotadas disponíveis para modelos de CD de treinamento, e deve-se prestar atenção para extrair o máximo de informações possível dos milhões de imagens de sensoriamento remoto disponíveis gratuitamente, sem rótulos e sem curadoria para melhorar a precisão e a robustez do CD.
Os métodos atuais de pré-treinamento requerem conjuntos de dados de classificação de cena aérea para pré-treinamento supervisionado ou imagens multitemporais emparelhadas para pré-treinamento auto-supervisionado, o que limita sua capacidade de utilizar informações de milhões de imagens de sensoriamento remoto não rotuladas prontamente disponíveis.
Introdução: Uma nova abordagem é proposta para incorporar milhões de imagens de sensoriamento remoto não rotuladas adquiridas através de diferentes programas de observação da Terra no processo de treinamento por meio de modelos probabilísticos de difusão de redução de ruído.
Os modelos de difusão são treinados em milhões de imagens de sensoriamento remoto disponíveis no mercado para aprender a semântica-chave das imagens aéreas e, em seguida, os recursos multiescala do decodificador de difusão são usados como entrada para treinar um classificador de CD com disponibilidade limitada de nível de pixel rótulos.
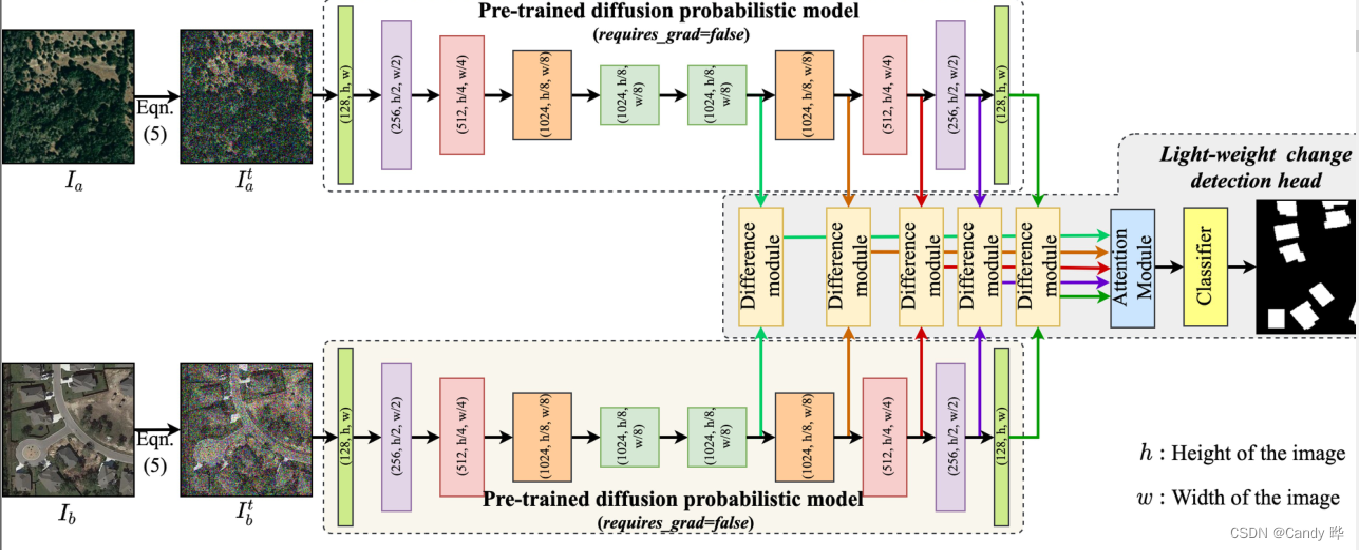
Uma vez que o modelo de difusão pode obter uma melhor semântica dada a imagem extraída, ele também é capaz de extrair a representação hierárquica de recursos da imagem de entrada. O artigo utiliza a semântica multi-escala (ou seja, representação de recursos profundos) do modelo de difusão como entrada, seguido por um módulo de atenção canal-espacial e, em seguida, um classificador convolucional para obter o mapa de previsão de mudança final.
Ao contrário de outras arquiteturas de aprendizado profundo, também é possível obter versões aprimoradas de diferentes representações de recursos variando a quantidade de ruído adicionada à entrada, treinando ainda mais um modelo de CD generalizado robusto sob rótulos de variação limitada em nível de pixel.
2. IDET: Transformadores aprimorados por diferenças iterativas para detecção de alterações de alta qualidade, código
de papel 2022-7
Motivação: A maioria dos trabalhos existentes concentra-se em projetar arquiteturas de rede avançadas para mapear as diferenças de recursos para o gráfico de alteração final, ignorando o impacto da qualidade da diferença de recursos.
Introdução: Este artigo estuda CD de diferentes perspectivas, como otimizar diferenças de recursos para destacar mudanças e suprimir regiões invariantes.

O IDET projeta três transformadores, dois transformadores são usados para extrair as informações remotas de duas imagens e o terceiro transformador usa a saída dos dois primeiros transformadores para guiar iterativamente o aprimoramento das diferenças de recursos.
A fim de alcançar um refinamento mais eficaz, uma detecção de mudança baseada em idet multiescala é proposta, usando UNet para extrair recursos convolucionais multiescala para refinamento de diferenças de recursos múltiplos e uma estratégia de fusão grossa-fina para combinar todas as diferenças de recursos refinadas .
3. A transição é um processo: Redes de detecção de alterações de par para vídeo para imagens de sensoriamento remoto de resolução muito
alta
Motivações: 1) a modelagem temporal é incompleta, 2) o acoplamento espaço-temporal torna difícil para a rede focar em um aspecto de cada vez.
Introdução: Propomos uma abordagem mais explícita e complexa para modelagem temporal e, consequentemente, construímos uma estrutura para detecção de alterações em vídeo (P2V-CD).
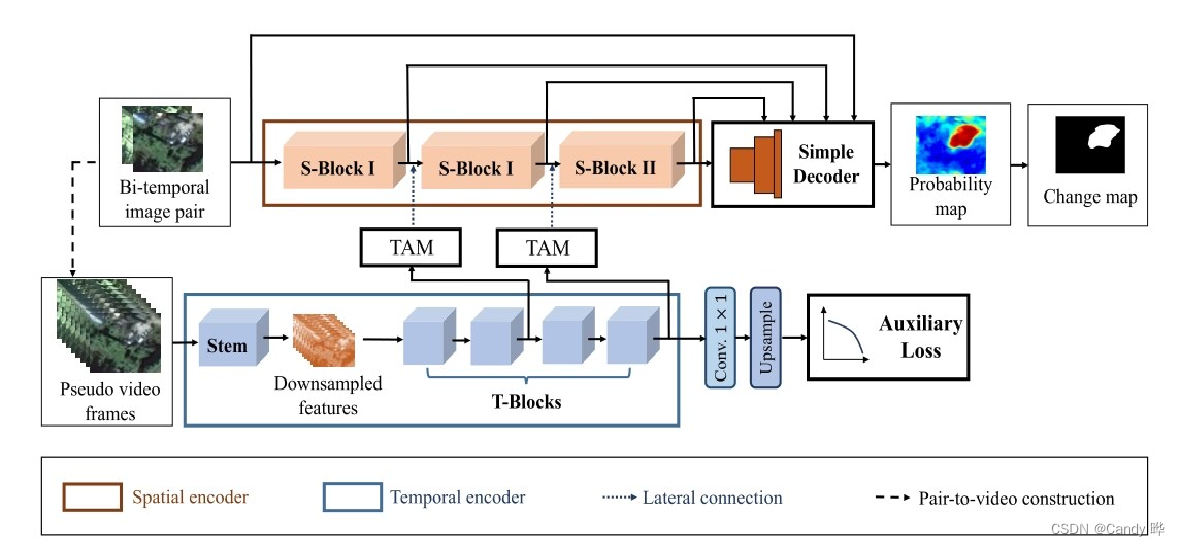
Inspirados pelo fato de que o reconhecimento de vídeo é dividido em quadros e que o fluxo óptico pode ser manipulado tanto no tempo quanto no espaço, interpretamos o CD como um problema de compreensão de vídeo. De acordo com o par de imagens de entrada, um vídeo de pseudo-transição carregando informações temporais ricas é construído como a entrada do codificador temporal.
Em termos de espaço, uma costura de imagens bitemporais é usada como entrada para construir um codificador espacial com uma sequência de blocos espaciais (s-blocks) para capturar o contexto espacial que ajuda a localizar regiões de mudança.
Em termos de tempo, uma sequência de pseudo-frames de vídeo é construída para obter uma visão mais granular dos dados temporais. Em seguida, atribua um codificador temporal que consiste em uma haste e quatro blocos temporais (blocos t) para extrair informações temporais sobre mudanças.
No backbone, o vídeo construído é reduzido espacialmente para reduzir a informação espacial para que o codificador temporal possa se concentrar mais na dimensão temporal. A saída do quarto bloco t é profundamente supervisionada para aumentar a capacidade discriminativa de recursos temporais.
4. TINYCD A (Not So) Deep Learning Model for Change Detection
paper code 2022-7
Motivação: os modelos existentes de detecção de alterações baseados em aprendizado profundo são muito complexos e volumosos para serem aplicados a cenários industriais e aplicativos de ponta.
Introdução: Um novo modelo, o TinyCD, é proposto e demonstrado ser leve e eficaz, capaz de alcançar desempenho comparável ou até melhor do que o estado da arte com 13-150 vezes menos parâmetros.

Use PW-MLP (gerador de máscara em nível de pixel) para processar essas informações e gerar uma pontuação como atenção espaço-temporal. projetado para produzir um tensor de máscara Mk ∈ RH×W.
Ignorar conexões Ao multiplicar a máscara Mk, reponderamos cada pixel para mitigar informações enganosas do upsampling.
5. Uma rede siamesa baseada em transformador para detecção de mudanças
Código de papel IGARSS 2022-7
Motivação: A pesquisa de CD mais recente se concentra principalmente no aumento do campo receptivo de modelos de CD, e as redes Transformer têm campos receptivos efetivos relativamente maiores do que as ConvNets profundas.
Introdução: Este método unifica um codificador de transformador estruturado hierarquicamente com um decodificador de percepção multicamada (MLP) em uma arquitetura de rede Siamese para renderizar com eficiência os detalhes de longo alcance em multiescala necessários para um CD preciso.

6. Rede Totalmente Transformadora para Detecção de Mudança de Imagens de Sensoriamento Remoto Código de papel
ACCV 2022-12
Motivação: Devido à capacidade de representação limitada das características visuais extraídas, os métodos atuais geralmente obtêm apenas regiões CD incompletas e limites irregulares de CD. Esses métodos existentes não oferecem desempenho total para a capacidade do transformador no aprendizado de recursos de vários níveis.
1) À medida que a resolução das imagens de sensoriamento remoto aumenta, a rica informação semântica contida nas imagens de alta resolução não é totalmente utilizada.
2) Muitas vezes faltam informações de contorno em imagens complexas de sensoriamento remoto.
3) A informação temporal contida nas imagens bifásicas de sensoriamento remoto não foi totalmente utilizada.
Introdução: Neste artigo, propomos uma nova estrutura de aprendizado de CD para imagens de sensoriamento remoto, Total Variation Network (FTN), que melhora a extração de recursos de uma perspectiva global e combina recursos visuais de vários níveis de maneira piramidal.
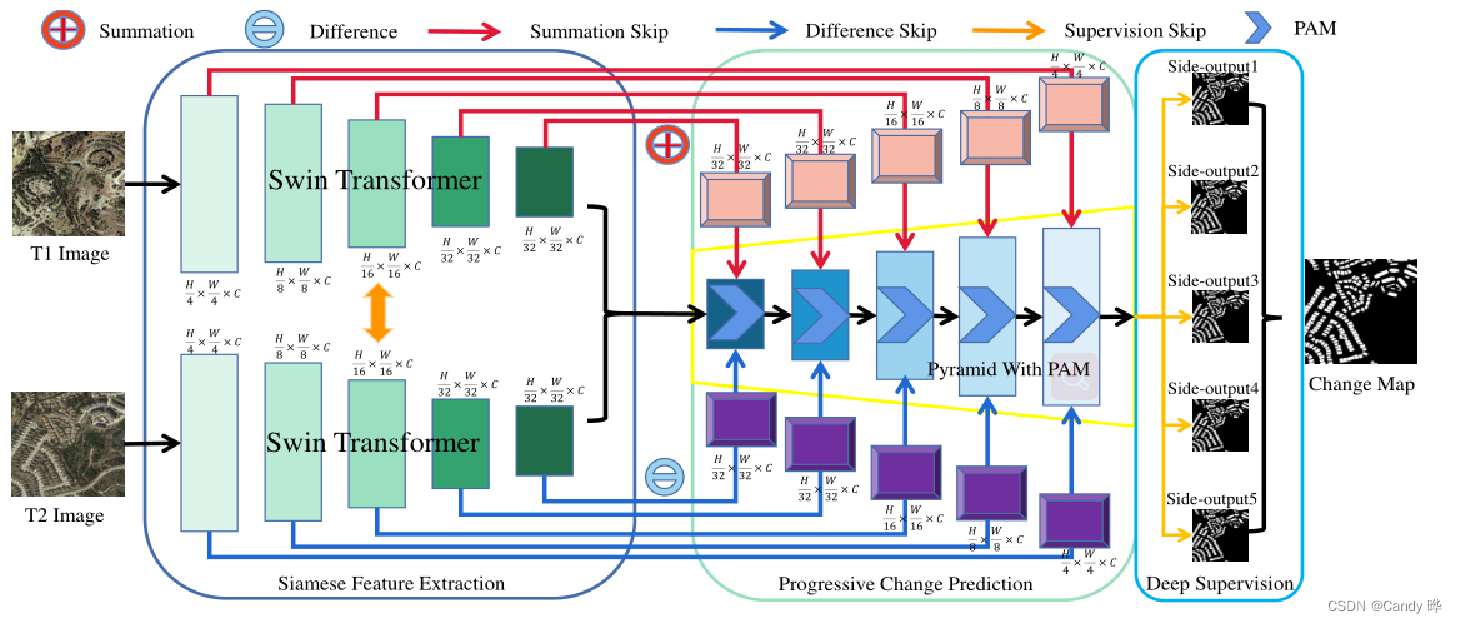
A estrutura consiste em três partes principais, ou seja, Siamese Feature Extraction (SFE), Deep Feature Enhancement (DFE) e Progressive Change Prediction (PCP).
1) O SFE usa imagens bifásicas de sensoriamento remoto como entrada e primeiro extrai recursos visuais de vários níveis por meio de dois transformadores Swin compartilhados.
Em cada estágio do Swin Transformer original, a resolução do recurso é reduzida pela metade enquanto a dimensão do canal é dobrada. Mais especificamente, a resolução do recurso é reduzida de (H/4) × (W/4) para (H/32) × (W/32) e o tamanho do canal é aumentado de C para 8C. Além disso, para reduzir a quantidade de computação, reduzimos uniformemente a dimensão do canal para C.
Os recursos de alto nível capturam mais informações semânticas globais, enquanto os recursos de baixo nível retêm mais informações detalhadas locais. Ambos ajudam a detectar regiões de mudança.
Ele pode ajudar a aprender recursos de nível global mais discriminativos e obter regiões CD completas.
Para explorar informações de nível global, introduzimos um bloco Swin Transformer adicional para ampliar o campo receptivo de mapas de recursos.
2) Utilize recursos visuais de vários níveis para gerar recursos de soma e recursos de diferença e use informações temporais para destacar regiões em mudança.
3) Ao integrar os recursos acima, uma estrutura piramidal enxertada com Módulo de Atenção Progressiva (PAM) é introduzida para melhorar a capacidade de representação de recursos por meio do canal de atenção para a predição final do CD.
4) Para treinar melhor a estrutura, aproveitamos o aprendizado supervisionado profundo com várias funções de perda com reconhecimento de limite.
7. SARAS-Net Scale and Relation Aware Siamese Network for Change Detection
2022-12 paper code
Motivação: Modelos de Aprendizagem Profunda Esses métodos ignoram informações espaciais e mudanças de escala entre os objetos, resultando em limites borrados ou errados e desempenho inferior. Além disso, as informações de interação entre duas imagens diferentes são ignoradas.
Introdução: Propomos uma rede siamesa que opera em duas imagens de entrada antes e depois da subtração de recursos para detectar regiões de mudança e obter desempenho de ponta em conjuntos de dados de sensoriamento remoto.
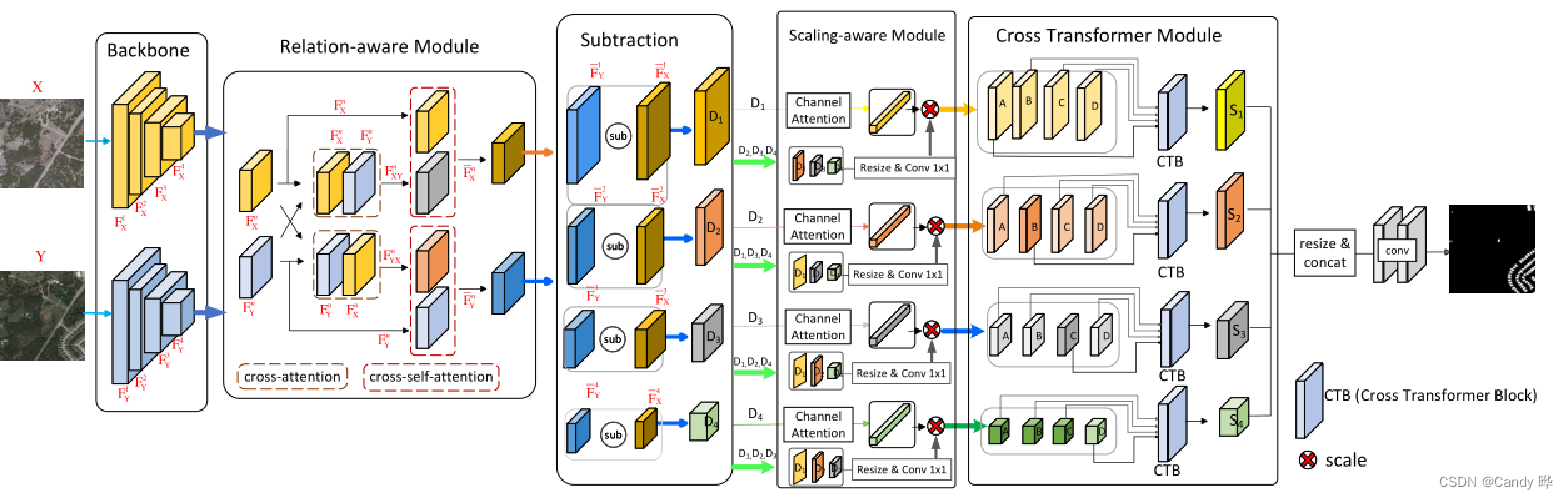
A rede realiza duas operações antes e depois da subtração de recursos, usando um módulo com reconhecimento de relação antes da subtração e um módulo com reconhecimento de escala e um módulo transformador cruzado após a subtração.
1) A rede de backbone resnet extrai os recursos da camada N separadamente.
2) O módulo de reconhecimento de relacionamento realiza operações de atenção cruzada e auto-atenção nas feições extraídas de cada camada, com o objetivo de melhorar a relação interativa entre os mapas de feições extraídos de duas imagens de entrada e melhorar a capacidade de mudança de reconhecimento de feições detecção.
3) Subtração de recursos.
4) Após a subtração de recursos, um módulo de atenção com reconhecimento de escala calcula a atenção em escala cruzada no mapa de subtração para lidar com as mudanças de cena causadas por objetos de vários tamanhos.
O módulo de reconhecimento de escala não apenas calcula a atenção em mapas de recursos da mesma escala, mas também em outras escalas para resolver o problema de reconhecimento de escala na detecção de mudanças.
5) Por fim, o módulo cross-transformer incorpora recursos de vários níveis, com o objetivo de prestar mais atenção às informações espaciais e separar facilmente o primeiro plano e o segundo plano, reduzindo assim os falsos positivos.