Este artigo apresenta brevemente o algoritmo e a estrutura de rede desses artigos. Os detalhes podem ser encontrados em meu blog . SRLUT é relativamente novo nesses artigos (2021).
Link original:
RCAN: Super-Resolução de Imagem Usando Redes de Atenção de Canal Residual Muito Profundo
SRLUT: Super-Resolução Prática de Imagem Única Usando Tabela de Consulta [CVPR2021]
ESPCN: Super-Resolução de Imagem e Vídeo Única em Tempo Real Usando uma Sub-Resolução Eficiente Rede Neural Convolucional de Pixel
VESPCN: Super-Resolução de Vídeo em Tempo Real com Redes Espaço-Temporais e Compensação de Movimento
RCAN
RCAN: Super-Resolução de Imagem Usando Redes de Atenção de Canal Residual Muito Profunda
Esta rede de artigo é a mais profunda até agora (referente à época deste artigo).
O objetivo principal do artigo é aprofundar, treinar 非常深的网络, apresentar RIR结构, apresentar 通道注意力机制CA.

Há dois pontos principais neste artigo:
- Por meio de bonecos de nidificação multicamada (três vezes), uma rede muito profunda (mais de 400 camadas) foi treinada e a propostaestrutura RIR。
- O autor acredita que diferentes canais da imagem característica contêm informações de diferentes importâncias, então ele propõeCA do Mecanismo de Atenção do Canal。
O RCAN inclui principalmente quatro partes: extração de recursos rasos , extração de recursos profundos Residual in Residual (RIR) , upsampling e reconstrução .
O foco deste artigo está na parte RIR, e as outras partes são basicamente iguais a EDSR e RDN , então não vou apresentar mais.
A estrutura geral da parte RIR: RIRcom RG como módulo básico, ela é composta por vários grupos residuais RG conectados por um salto em distância LSC . Cada um RGcontém um número de blocos residuais de canal RCAB com conexões de salto curtas SSC . Cada bloco residual de atenção do canal consiste RCABem um bloco residual simples BN e um mecanismo de atenção do canal CA.
-
Primeiro, observe a primeira camada (a camada mais externa):
RIRRG é usado como módulo básico e é composto por G grupo residual RG conectado por uma conexão de salto longo LSC .
As conexões de salto longo (LSC) podem estabilizar o treinamento de redes ultraprofundas, simplificar o fluxo de informações entre RGs e integrar informações rasas e profundas para aprimorar as informações de imagem e reduzir a perda de informações.
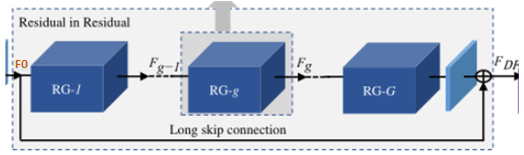
-
A segunda camada: Cada uma
RGcontém um SSC de conexão de salto curto e um bloco residual de canal B RCAB .
Conexão de salto curto (SSC), que pode fundir informações de recursos locais em diferentes níveis.
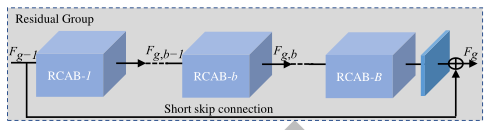
-
Antes de falar sobre a terceira camada, deixe-me apresentar o mecanismo de canal de atenção CA , porque ele é usado na estrutura mais interna.
As informações de recursos contidas em diferentes canais são diferentes, por isso é necessário atribuir pesos diferentes a cada canal, para que a rede possa dar mais atenção a alguns canais que contêm informações importantes, por isso são introduzidas注意力机制.
Use全局平均池化para converter as informações espaciais globais de cada canal em um descritor de canal (uma constante, que na verdade é um valor de peso para cada canal).
Primeiro, os recursos de cada canal são transformados em uma constante por meio de agrupamento global e, em seguida, a convolução 1 ( WD W_DCD)+ReLU+Volume 2( WU W_UCvocê)+sigmóide para obter o valor final do peso s.
A convolução 1 reduz o número de canais para C r \frac{C}{r}rC, A convolução 2 amplifica o número de canais de volta para C. O peso final s é multiplicado pelo recurso original x para obter o recurso após a distribuição do peso.
A CA redistribui de forma adaptativa os pesos dos recursos do canal, concentrando-se nas interdependências entre os canais.

-
Camada 3: Cada bloco residual de atenção do canal consiste
RCABem um bloco residual simples BN e um mecanismo de atenção do canal CA. (Camada mais interna)
O bloco residual comum é composto de camada de convolução + ReLU + convolução, conectada em série com um mecanismo de atenção de canal CA e uma conexão de salto.

Revise a estrutura RCAN: extração de recursos rasos, extração de recursos profundos Residual in Residual ( RIR ), upsampling e reconstrução. RIRCom o RG como módulo básico, ele é composto por vários grupos residuais RG conectados por um LSC de salto longo . Cada um RGcontém um número de blocos residuais de canal RCAB com conexões de salto curtas SSC . Cada bloco residual de atenção do canal consiste RCABem um bloco residual simples BN e um mecanismo de atenção do canal CA.
Resumo: A profundidade da rede proposta neste artigo é muito profunda e geralmente redes muito profundas são difíceis de treinar. O autor aumenta a estabilidade do treinamento da rede e simplifica o fluxo de informações aninhando várias estruturas de blocos e usando conexões de salto longo e curto. Outra característica do artigo é propor um mecanismo de atenção de canal , que atribui diferentes valores de peso a diferentes canais e otimiza o desempenho da rede.
SRLUT
SRLUT: Super resolução prática de imagem única usando tabela de consulta [CVPR2021]
Este artigo é a primeira vez que será 查表法introduzido no campo SR. Os valores de pixel escalados treinados pela rede SR são armazenados na tabela, e a tarefa de reconstrução da imagem pode ser concluída apenas consultando o valor correspondente na tabela durante a fase de teste. A fase de teste pode ser 脱离CNNconectada em rede. Como esse método não requer muitas operações de ponto flutuante, ele pode ser executado muito rapidamente.

A estrutura geral do SR_LUT é: rede de treinamento - tabela de armazenamento - teste (tabela de leitura) (a parte principal é a tabela de armazenamento e a tabela de leitura)
uma imagem é ampliada em r vezes, o que pode ser considerado como cada pixel é ampliado em r vezes . O artigo foi projetado com base nessa ideia, mas a aparência de cada pixel após o zoom é determinada pelos pixels ao redor (campo receptivo).
Rede de treinamento: camadas convolucionais múltiplas convencionais para obter um mapeamento de mapa completo de LR para HR.
Salvar tabela:
- Dado o tamanho do campo receptivo, use o mapeamento previamente treinado para obter o valor do pixel da área correspondente ampliada correspondente ao campo receptivo e armazene-o na tabela de consulta . Por exemplo, dado um campo receptivo 2×2. Então, correspondendo ao tamanho desta área, há um total de 25 5 4 255^42 5 5Arranjos de 4 pixels são possíveis. Em outras palavras, o ambiente ao redor deste pixel deve ser este25 5 4 255^42 5 5Um dos 4 .
每一种像素的排列deve ser armazenado na tabela de pesquisa, de modo que não importa como os pixels sejam organizados no futuro, podemos restaurar a área de pixel reconstruída de acordo com a tabela de pesquisa. Portanto, um total de 25 5 n 255^nprecisa ser armazenado na tabela2 5 5n linhas. nn é o tamanho do campo receptivo especificado. 放大后对应图像区域仅与放大倍数r有关。dada ampliação rrr ,o tamanho da área correspondente após cada aumento de pixel deve ser r × rr × rr×r . O tamanho do campo receptivo é atribuído a cada pixel e é usado para descrever o ambiente ao redor desse pixel. O objeto real ainda é o pixel; portanto, após aumentar o zoom, obtemos r × rr ×rr×tamanho r .- Portanto, a capacidade de armazenamento de toda a tabela de pesquisa é: 25 5 n × r 2 × 8 bit \bm{255^n \times r^2 \times 8bit}2 5 5n×r2×8 bits (cada pixel ocupa 8 bits de memória)
Pesquisa de tabela: expanda cada posição de pixel na imagem para o tamanho do campo receptivo, encontre o valor da área correspondente na tabela de pesquisa e retire-a como um bloco de reconstrução.
O acima é uma rede convencional, mas considerando 25 5 n 255^n2 5 5n linhas, o consumo de memória é muito. Assim, o autor criou uma maneira de proporamostrado-LUTVariante: reduza os valores de 255 pixels para reduzir a memória ocupada pela tabela de consulta. O intervalo de amostragem é 2 4 2^424 , Divida o espaço de entrada em {0, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 255}一共17个采样点. Então25 5 n 255^n2 5 5As n possibilidades são reduzidas a1 7 n 17^n1 7n , reduzindo bastante a capacidade de armazenamento. Mas isso também traz um problema. Se o pixel da imagem de entrada for um ponto sem amostragem (decimal)ao consultar a tabela, se o valor do ponto de amostragem mais próximo for substituído diretamente, a imagem perderá muitos detalhes e o efeito de reconstrução será muito pobre. Portanto, nesta parte, o autor propõe uma variedade de campos receptivos correspondentesalgoritmo de interpolação。
Resumo: A principal vantagem deste artigo é a velocidade , pois a fase de teste é separada da CNN e faz a leitura direta da tabela. Por ser separada da CNN, a rede pode ser utilizada em celulares, e seu desempenho também é bom. Essa ideia também é bastante nova.
ESPCN
ESPCN: Super-Resolução de Imagem e Vídeo Única em Tempo Real Usando uma Rede Neural Convolucional Sub-Pixel Eficiente Este artigo é uma espécie de SISR, mas o mais digno de nosso estudo é a última camada da rede

A camada convolucional de subpixel é Pixel-Shuffle, 上采样método.
A camada convolucional de subpixel é geralmente colocada na última camada da rede sem exigir computação adicional.
Na verdade, a ideia central da camada de convolução de subpixel é a mesma do SRLUT. Ampliar uma imagem r vezes é equivalente a aumentar cada pixel r vezes.
O número de canais de saída no processo de convolução da penúltima camada da rede é r 2 r^2r2 A imagem característica do mesmo tamanho que a imagem originalorganizada periodicamenteatravés da camada convolucional de subpixelpara obterw × r, h × rw × r, h × rc×r ,h×r reconstrói a imagem.
Conforme mostrado na figura, as nove feições circundadas pela elipse vermelha na penúltima camada (fator de ampliação é 3) estão dispostas para formar uma pequena caixa na última camada apontada pela seta, que é a reconstrução dos pixels enquadrados na imagem original através da rede.peça. Esses nove pixels apenas triplicam o comprimento e a largura do pixel original.
Deve-se notar que, embora a camada de convolução de subpixel tenha a palavra convolução, ela não executa operações , mas apenas extrai recursos e simplesmente os organiza .
Resumo: A rede de treinamento neste artigo não é complicada. A essência está na forma de upsampling , que não requer convolução ou mesmo cálculo. O arranjo periódico simples reduz muito a complexidade do cálculo e o efeito também é muito bom. Em muitos experimentos O upsampling baseado em convolução é excedido em Com base neste artigo, o autor continuou a explorar e propôs o seguinte artigo VESPCN, que usa informações de tempo para fazer reconstrução de vídeo.
VESPCN
VESPCN: Super-Resolução de Vídeo em Tempo Real com Redes Espaço-Temporais e Compensação de Movimento O
modelo VESPCN proposto neste artigo consiste em dois aspectos: rede espaço-temporal e mecanismo de compensação de movimento. A chave para o artigo é como fazer bom uso dele 时间信息.

O VESPCN é composto principalmente pela rede Motion-Estimation e pela rede Spatio-Temporal. (Alinhamento + Fusão)
Rede de compensação de movimento: Com base na rede STN, os valores de pixel dos quadros anteriores e subsequentes são previstos.
Rede espacial temporal: A rede Spatio-Temporal é uma rede SR baseada em ESPCN, que usa principalmente camadas sub-pixel convolucionais para upsampling. Além disso, este módulo precisa combinar fusão precoce, fusão lenta ou convolução 3D para adicionar informações de tempo. .
Como a própria rede STN é derivável, o treinamento de toda a rede de compensação de movimento + espaço temporal é um único 端对端treinamento. Toda a rede de compensação de movimento em VESPCN é essencialmente uma rede de alinhamento de tempo em VSR, que é baseada no método Flow-based e pertence ao Image-wise .
Na verdade, não há módulo de compensação de movimento e apenas confiar na rede de espaço temporal pode alcançar um desempenho de reconstrução relativamente bom. No entanto, a compensação de movimento torna o conteúdo dos quadros dianteiro e traseiro mais alinhados, aprimora a correlação e é mais contínuo em tempo .
Estrutura da rede:
Vários quadros de imagens adjacentes são alinhados ao quadro de referência por meio do módulo de compensação de movimento baseado em STN e, em seguida, inseridos na rede de espaço temporal baseada em ESPCN para fundir informações temporais para extrair recursos e, finalmente, usar upsampling de camada convolucional sub-pixel para concluir Reconstrução RS.
Decompô-lo:
- Insira três quadros de imagens, o quadro atual I t LR I_t^{LR}EUtL RComo quadro de referência, dois quadros antes e depois são usados como quadros de suporte, o quadro anterior I t − 1 LR I_{t-1}^{LR}EUt - 1L RE o próximo quadro I t + 1 LR I_{t+1}^{LR}EUt + 1L RRespectivamente com o quadro atual I t LR I_t^{LR}EUtL RFaça uma compensação de movimento para obter duas imagens distorcidas I ' t − 1 LR I'_{t-1}^{LR}eu 't - 1L R和I 't + 1 LR I'_{t+1}^{LR}eu 't + 1L R。
O objetivo deste processo é tornar o quadro anterior I t − 1 LR I_{t-1}^{LR}EUt - 1L RTente transformar para o quadro atual I t LR I_t^{LR}EUtL Rs posição. Claro que o próximo quadro é o mesmo. Este é o alinhamento do qual falei antes . Reduza o deslocamento das três imagens e mantenha-as o mais consistentes possível, para que haja mais correlações de conteúdo e mais continuidade no tempo. Como não é possível alterar o quadro de suporte para ficar exatamente igual ao quadro de referência, ainda haverá uma diferença, mas a diferença torna-se menor, o que pode ser visto como um novo quadro inserido entre as duas imagens , portanto a continuidade de o movimento é bastante aprimorado. O módulo ME na figura é uma variante baseada no STN que adiciona um elemento de tempo.
- Insira as imagens mais semelhantes obtidas após os três warps na rede de espaço temporal para fusão , de fato, combine as três imagens juntas
提取特征e, finalmente, use a camada convolucional de subpixel Pixel-Shuffle para aumentar a resolução e reconstruir a saída da imagem I t SR I_t ^{SR}EUtS R。
Existem três maneiras neste processo de fusão: fusão inicial, fusão lenta e convolução 3D. A fusão inicial mais simples é, na verdade, unir três imagens diretamente na dimensão do tempo e, em seguida, extrair recursos juntos. A parte de fusão realmente se refere a como extrair recursos .
Resumo: A tarefa de reconstrução de vídeo é adicionar informações de tempo com base em SR de imagem única, portanto, como usar as informações de tempo é a chave. Alinhar vários quadros de imagens e fundir vários quadros de imagens são para melhor extração de informações temporais.
Continua~
Por fim, desejo a todos sucesso na pesquisa científica, boa saúde e sucesso em tudo~