Diretório de artigos
1. Introdução
No artigo anterior do MyBatis Quick Start, usamos o método de desenvolvimento nativo do MyBatis para operar o banco de dados, o que resolveu os problemas de codificação rígida e operação incômoda quando o JDBC opera o banco de dados. Na verdade, em projetos Java, usamos o método de desenvolvimento do agente Mapper com mais frequência.
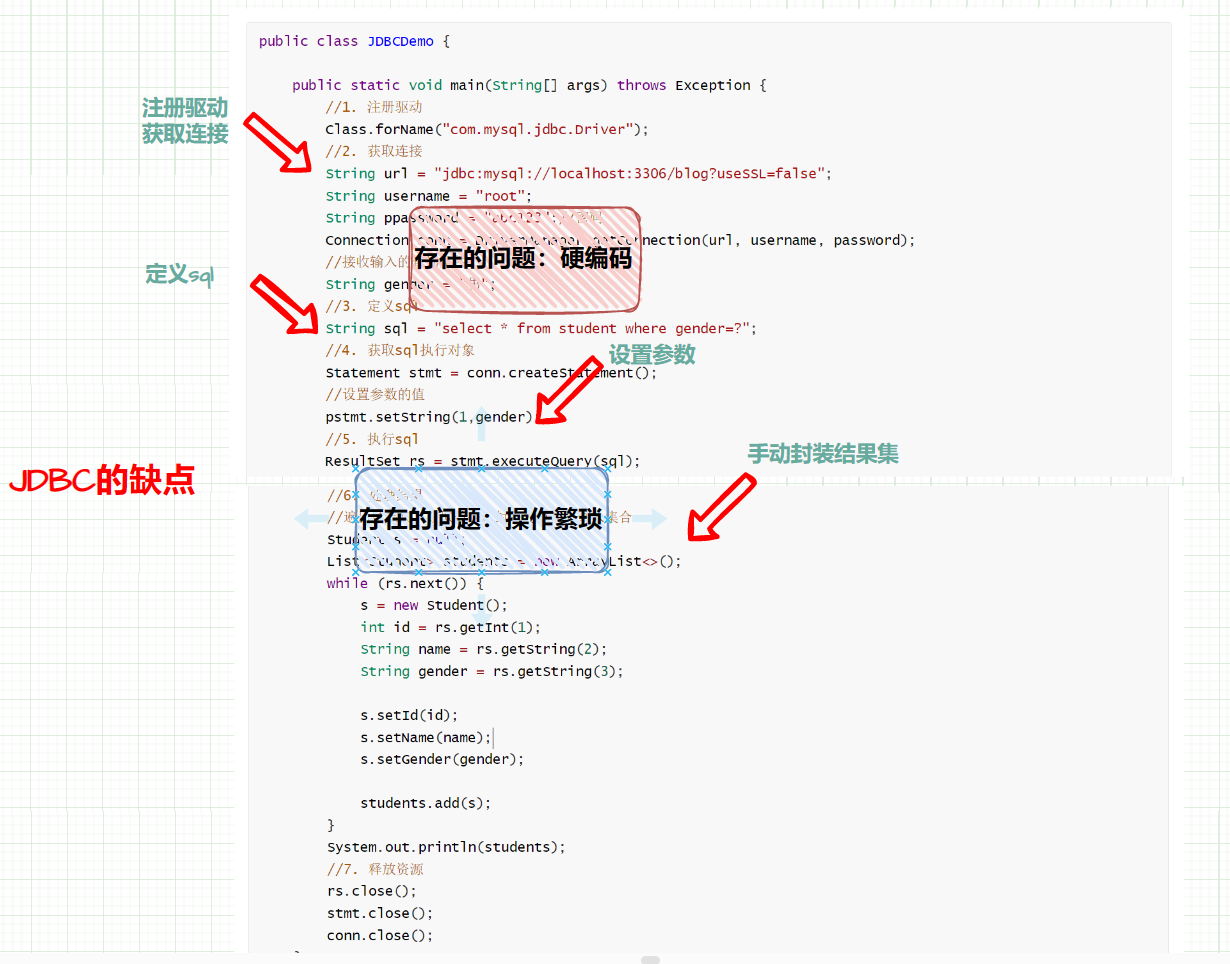
Qual é a diferença entre os dois métodos?
Ao usar o método básico para operar o banco de dados, usamos o método nativo selectList de sqlSession para executar a instrução sql e processar o objeto do conjunto de resultados. Exemplo:
List<Student> students = sqlSession.selectList("test.selectAll"); //参数是一个字符串,该字符串必须是映射配置文件的 namespace.id
O parâmetro deste método deve ser o arquivo de configuração de mapeamento sql name.id, e é passado para este método na forma de uma string, então há um problema de codificação aqui, e a forma de usar id aqui não é um design conveniente, porque ao codificar, também é necessário encontrar o id no arquivo de configuração de mapeamento correspondente, então o método de desenvolvimento do proxy Mapper aparece para resolver esse problema.
Ao usar o método de desenvolvimento do proxy Mapper para operar o banco de dados, obtenha um objeto proxy Mapper especificando a interface Mapper por meio do objeto de classe SqlSession, use o objeto proxy para chamar o método na interface Mapper correspondente e esse método corresponde ao id no arquivo de configuração de mapeamento, para localizar o sql e executá-lo e, finalmente, processar o objeto do conjunto de resultados. Exemplo:
//3. 执行sql
//3.1 获取StudentMapper接口的代理对象
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
List<Student> students = studentMapper.selectAll();
Em geral, o método proxy Mapper tem as duas vantagens a seguir:
- Resolvido o problema de hardcoding no modo nativo
- SQL pós-execução simplificado
2. Desenvolvimento do agente mapeador
Não é difícil ver pelos exemplos acima que o método de uso do proxy Mapper tem mais vantagens: em primeiro lugar, não depende do valor literal da string, o que é mais conveniente e seguro. Em segundo lugar, se o seu IDE tiver a função de preenchimento automático de código, ele poderá ajudá-lo a selecionar rapidamente a instrução sql do arquivo de mapeamento sem depender do id correspondente.
Para usar o método de desenvolvimento do proxy Mapper, as seguintes etapas devem ser executadas:
- Defina a interface Mapper com o mesmo nome do arquivo de configuração de mapeamento sql e evite que a interface Mapper e o arquivo de configuração de mapeamento sql estejam no mesmo diretório
- Defina o atributo namespace do arquivo de mapeamento sql para o nome totalmente qualificado da interface Mapper
- Defina o método na interface Mapper, o nome do método é o id da instrução sql no arquivo de mapeamento sql e mantenha o mesmo tipo de parâmetro e tipo de valor de retorno
O caso a seguir usa um caso para entender o processo de desenvolvimento do agente Mapper. O caso ainda está usando a consulta de informações do aluno no capítulo Introdução, encapsulando-o como um objeto e armazenando-o em uma coleção.
primeiro passo :
org.chengzi.mapperCrie StudentMapper no pacote , exemplo:
public interface StudentMapper {
List<Student> selectAll();
Student selectById(int id);
}
Crie um org / chengzi / mapperdiretório e crie um arquivo de configuração StudentMapper.xml nesse diretório de arquivo. Isso garante que a interface do Mapper e o arquivo de configuração de mapeamento sql estejam no mesmo diretório de arquivo.
Etapa 2 : Defina o atributo namespace do arquivo de mapeamento sql para ser consistente com o nome totalmente qualificado da interface Mapper. Exemplo:
<!--
namespace:名称空间。必须是对应接口的全限定名
-->
<mapper namespace="org.chengzi.mapper.StudentMapper">
<select id="selectAll" resultType="org.chengzi.pojo.User">
select *
from student;
</select>
</mapper>
Etapa 3 : Carregue o arquivo de configuração de mapeamento sql no arquivo de configuração principal do MyBatis, exemplo:
<mappers>
<!--加载sql映射文件-->
<mapper resource="org/chengzi/mapper/StudentMapper.xml"/>
</mappers>
Nota: as próximas duas etapas usam
/como separador de caminho de arquivo
Depois de concluir as três etapas acima, podemos escrever o código de teste para operar o banco de dados e concluir as operações relacionadas. Exemplo:
public class MyBatisDemo2 {
public static void main(String[] args) throws IOException {
//1. 加载mybatis的核心配置文件,获取 SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象,用它来执行sql
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 执行sql
//3.1 获取StudentMapper接口的代理对象
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
List<Student> students = studentMapper.selectAll();
System.out.println(students);
//4. 释放资源
sqlSession.close();
}
}
resultado da operação:
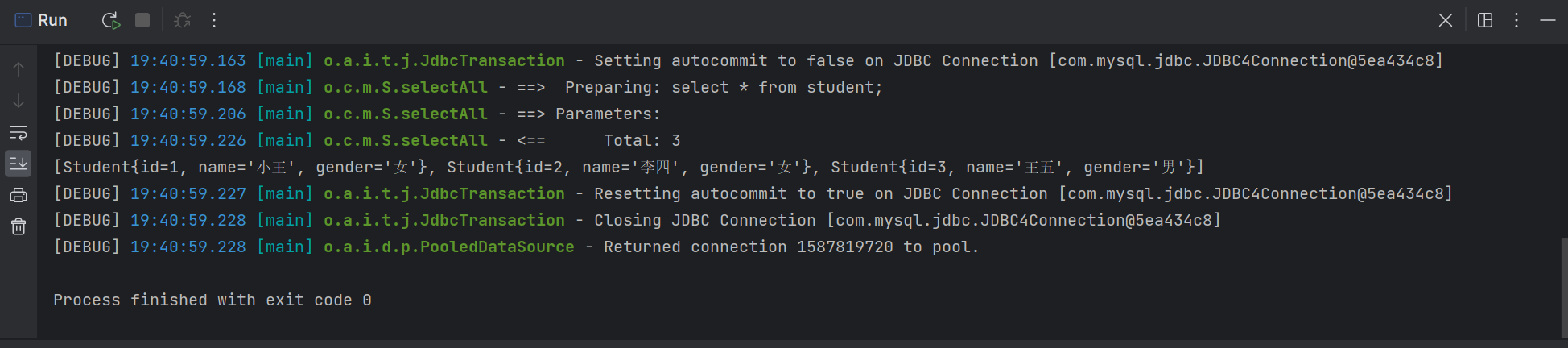
Diferente do método básico do MyBatis, aqui obtemos o objeto proxy da interface StudentMapper por meio do método correspondente ao objeto sqlSession, usamos o objeto proxy para executar a instrução sql e encapsulamos o objeto conjunto de resultados. O processo de retorno do objeto proxy é feito internamente pelo MyBatis.
Dicas: Ao carregar o arquivo de configuração de mapeamento sql no arquivo de configuração principal MyBatis, se o número de arquivos de configuração de mapeamento sql for grande, esta etapa também é problemática. MyBatis também fornece uma solução para este problema.
Se o nome da interface do Mapper for o mesmo do arquivo de mapeamento sql e eles estiverem no mesmo diretório, você pode usar a verificação de pacote para simplificar o carregamento do arquivo de mapeamento sql. Você só precisa modificar a parte do carregamento do arquivo de configuração de mapeamento sql no arquivo de configuração principal para:
<mappers>
<!--加载sql映射文件-->
<!-- <mapper resource="org/chengzi/mapper/UserMapper.xml"/>-->
<!--Mapper代理方式-->
<package name="org.chengzi.mapper"/>
</mappers>
3. Análise do processo
Ao usar o desenvolvimento de proxy Mapper, obtemos o objeto de classe SqlSession por meio do método openSession() da classe SqlSessionFactory e, em seguida, obtemos o objeto de proxy Mapper da interface Mapper especificada por meio do objeto de classe SqlSession.
Ao obter o objeto proxy Mapper, podemos encontrar a interface Mapper correspondente e, no mesmo diretório, podemos encontrar o arquivo de mapeamento sql correspondente com o mesmo nome da interface. Use o objeto proxy para chamar o método na interface Mapper correspondente. Este método corresponde ao atributo id no arquivo de configuração de mapeamento sql. Por meio do atributo id, você pode encontrar a instrução sql correspondente e, em seguida, executar a instrução sql e encapsular o objeto do conjunto de resultados.
Por exemplo, no caso acima, o studentMapperobjeto proxy executa o método selectAll() e retorna um objeto List. Na verdade, a camada inferior ainda executa a seguinte instrução:
List<User> users = sqlSession.selectList("test.selectAll");
4. Resumo
Desenvolvido na forma nativa do MyBatis, alguns processos dependem de valores constantes de cadeia de caracteres e há problemas embutidos no código.Ao mesmo tempo, usar espaço de comando e identificador exclusivo SQL como parâmetros para executar SQL é problemático ao escrever código. A forma de usar o proxy Mapper tem mais vantagens: Em primeiro lugar, não depende do valor literal da string, o que será mais conveniente e seguro. Em segundo lugar, se o seu IDE tiver a função de preenchimento automático de código, ele poderá ajudá-lo a selecionar rapidamente a instrução sql do arquivo de mapeamento sem depender do id correspondente.