**************************************************** ** *
Codificar palavras não é fácil. Além de colecionar, não esqueça de me dar um like!
**************************************************** ** *
---------Começar
Por favor, vá para outro post do blog sobre a parte de teste da rede swinUnet
Código oficial: https://github.com/HuCaoFighting/Swin-Unet
Objetivo: Treinar Swin-Unet para segmentar regiões pulmonares
Localização oficial do conjunto de dados (não pode ser baixado): https://www.kaggle.com/datasets/nikhilpandey360/chest-xray-masks-and-labels
Conjunto de dados de download gratuito de CSDN
Perceba o efeito:
inserir imagem original
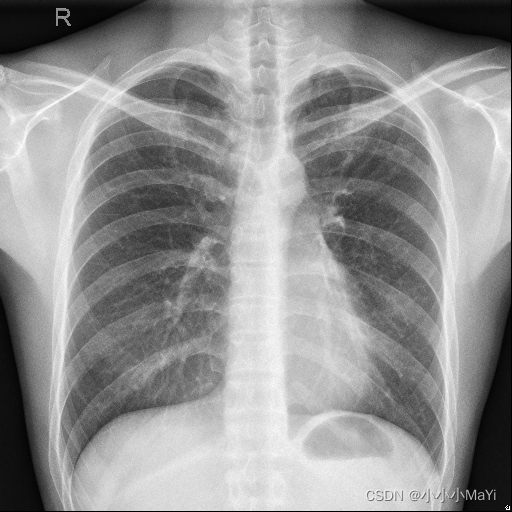
rótulo de saída
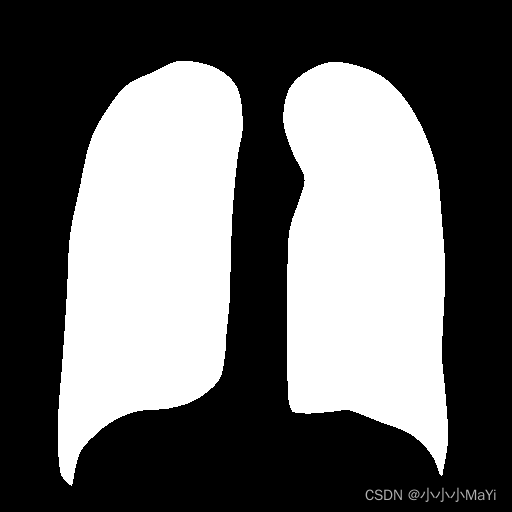
Neste artigo, apenas 345 imagens de todo o conjunto de dados são usadas para concluir toda a tarefa de segmentação!
1. Baixe o código oficial e descompacte-o
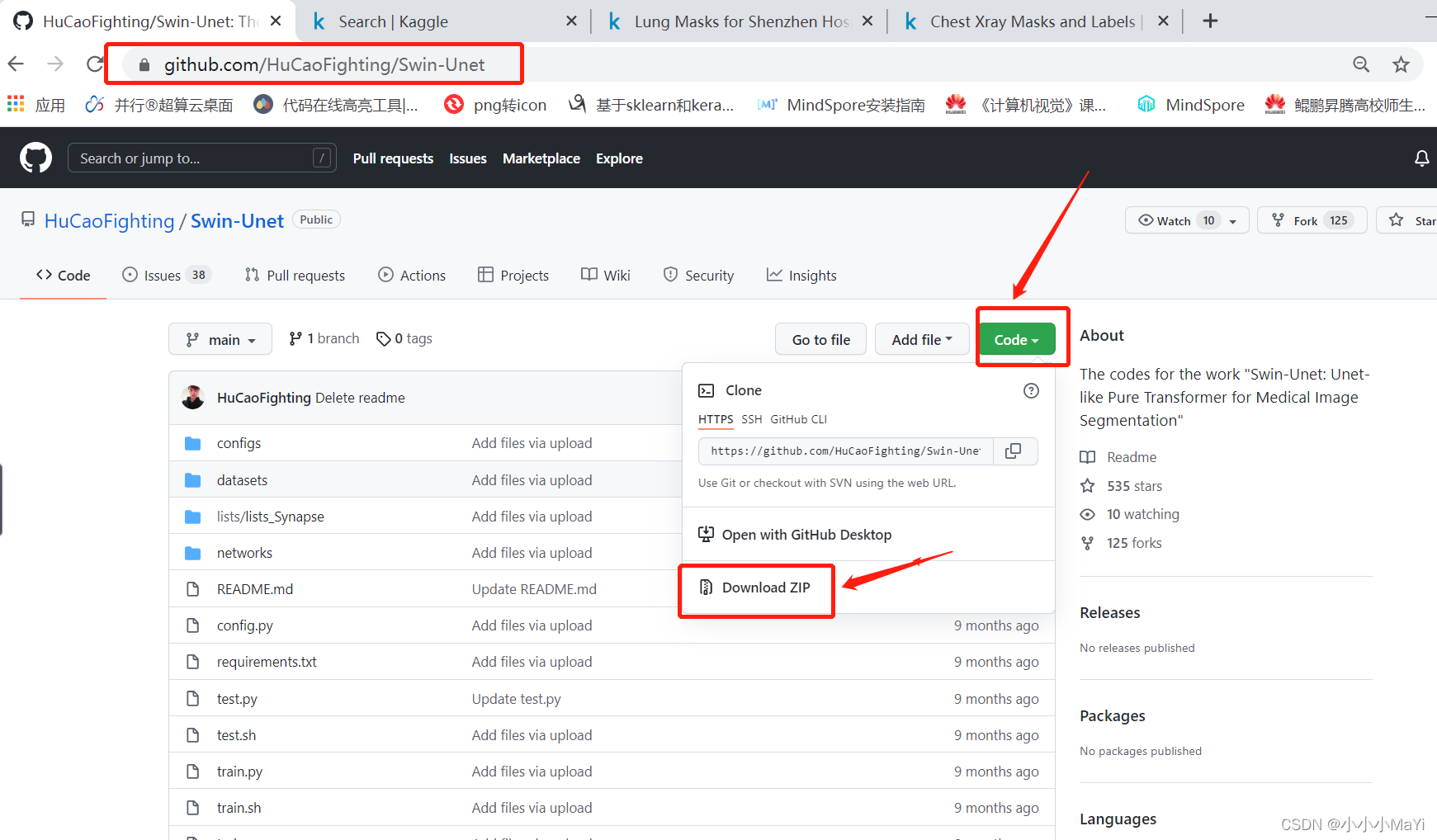
Pasta descompactada:
2. Baixe o conjunto de dados e descompacte-o
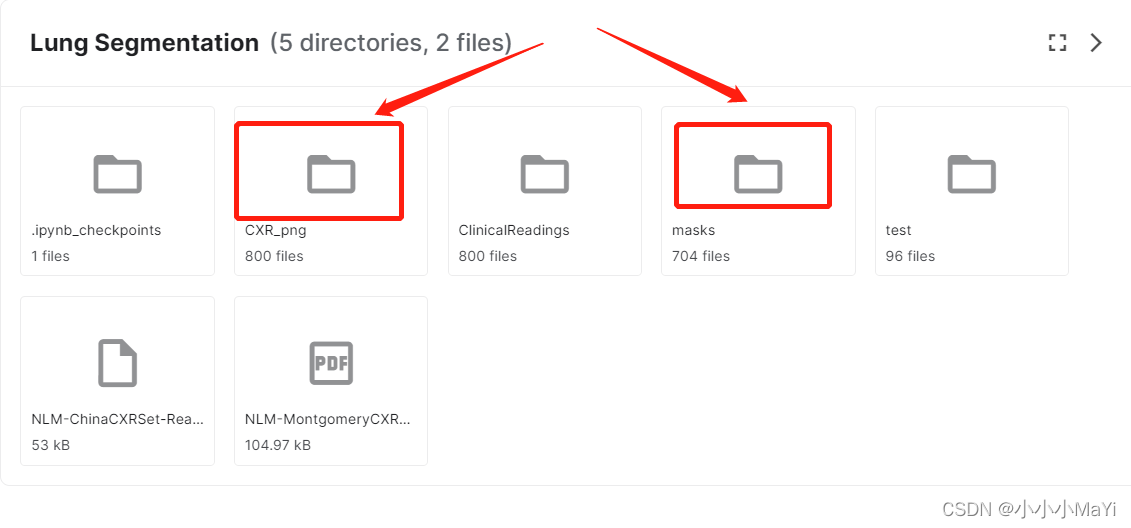
Só precisamos usar as duas pastas a seguir: uma para imagens e outra para rótulos. São 800 fotos no arquivo original e apenas 704 rótulos. Algumas imgs não têm rótulos. Você precisa prestar atenção ao fazer arquivos npz.
Aqui estão as 345 imagens e máscaras correspondentes usadas neste artigo
rótulos para tarefas de segmentação,
3. Gere o arquivo .npz
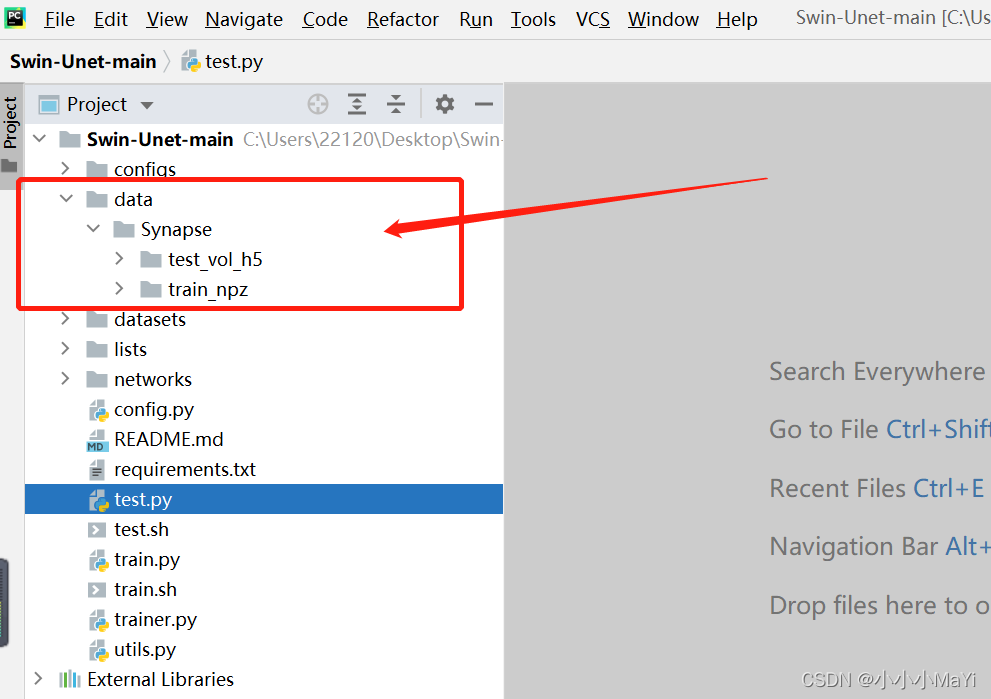
pycharm abre o arquivo de projeto, configura o interpretador python e cria o diretório de dados
No diretório de dados, train_npz é usado para armazenar os arquivos npz usados para treinamento e test_vol_h5 é usado para armazenar os arquivos npz usados para teste. Este é o nome oficial e você pode alterar menos o código.
Converta imagens e rótulos em arquivos .npz
Mantenha a imagem e o rótulo originais no mesmo diretório

Código de conversão: (modifique o caminho de acordo com a localização de seus próprios dados), se houver apenas duas categorias de plano de fundo + destino, este código pode ser usado diretamente, se for dividido em três ou mais categorias, o código deve ser baseado em Ajuste seus dados de imagem. Após o ajuste, certifique-se de que na matriz de rótulos do código a seguir, o fundo seja representado por 0 pixels, o alvo seja representado por 1, 2, 3, 4... pixels respectivamente, e um valor de pixel representa uma categoria. Por exemplo (0: background, 1: class 1, 2: class 2, 3: class 3...).
def npz():
#原图像路径
path = r'G:\dataset\Segmentation\LungSegmentation\npz\images\*.png'
#项目中存放训练所用的npz文件路径
path2 = r'G:\dataset\Unet\TransUnet-ori\data\Synapse\train_npz\\'
for i,img_path in enumerate(glob.glob(path)):
#读入图像
image = cv2.imread(img_path)
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
#读入标签
label_path = img_path.replace('images','labels')
label = cv2.imread(label_path,flags=0)
#将非目标像素设置为0
label[label!=255]=0
#将目标像素设置为1
label[label==255]=1
#保存npz
np.savez(path2+str(i),image=image,label=label)
print('------------',i)
# 加载npz文件
# data = np.load(r'G:\dataset\Unet\Swin-Unet-ori\data\Synapse\train_npz\0.npz', allow_pickle=True)
# image, label = data['image'], data['label']
print('ok')
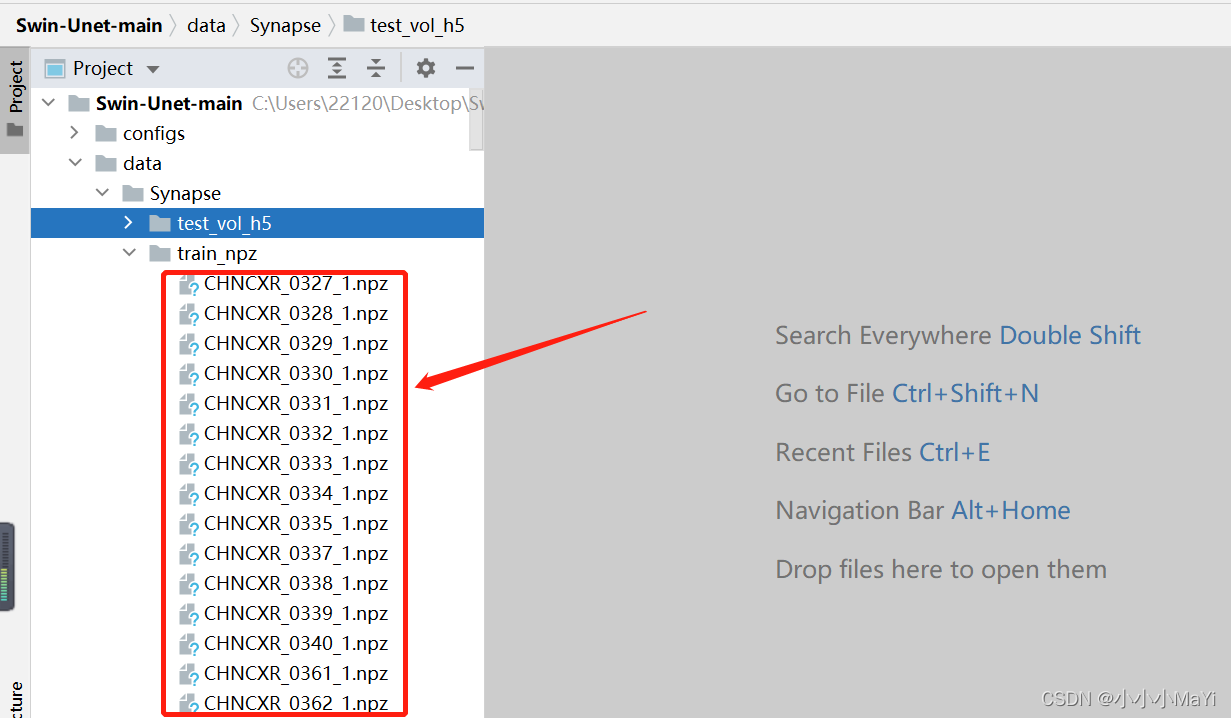
Gere dados de imagem de treinamento e teste como arquivos npz em train_npz e test_vol_h5, respectivamente
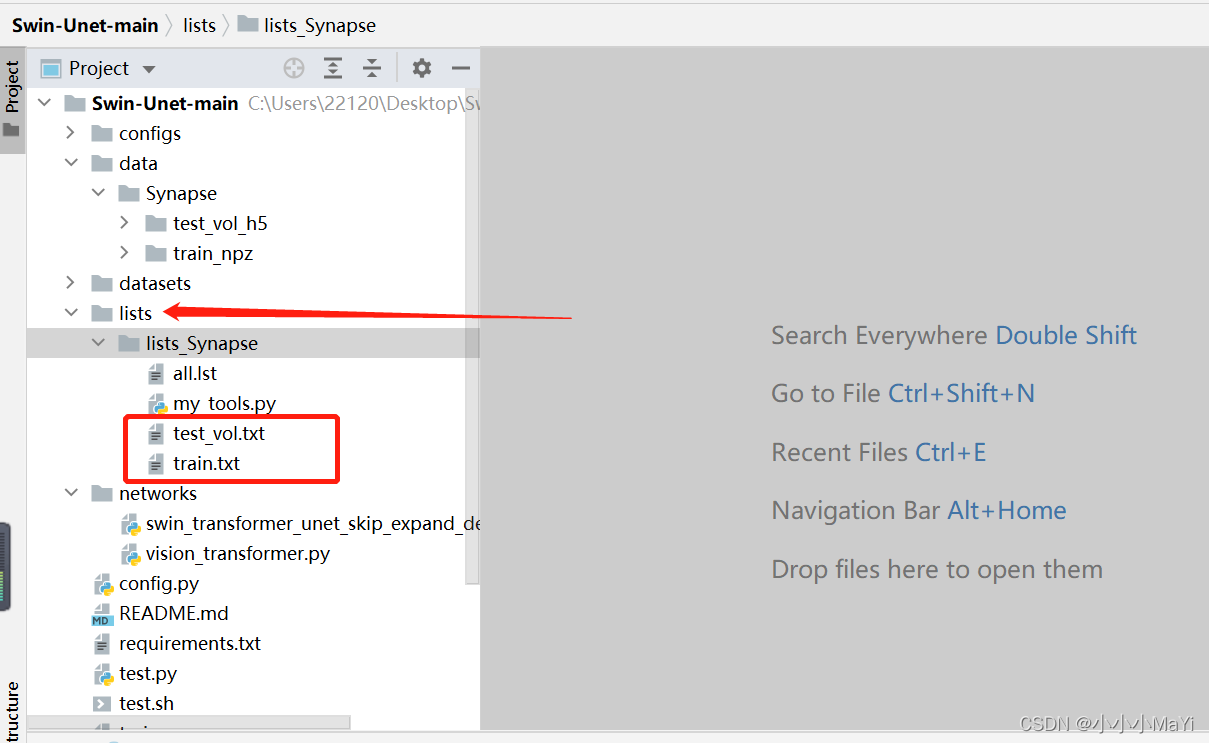
Gerar arquivo txt correspondente ao arquivo npz
O conteúdo do arquivo txt é o nome dos dados da imagem lidos durante o treinamento e teste do modelo. Ignore o arquivo my_tools.py.
O código para gerar o arquivo txt gera os arquivos train.txt e test_vol.txt de acordo com os arquivos npz de treinamento e teste, respectivamente.
def write_name():
#npz文件路径
files = glob.glob(r'C:\Users\22120\Desktop\Swin-Unet-main\data\Synapse\test_vol_h5\*.npz')
#txt文件路径
f = open(r'C:\Users\22120\Desktop\Swin-Unet-main\lists\lists_Synapse\test_vol.txt','w')
for i in files:
name = i.split('\\')[-1]
name = name[:-4]+'\n'
f.write(name)
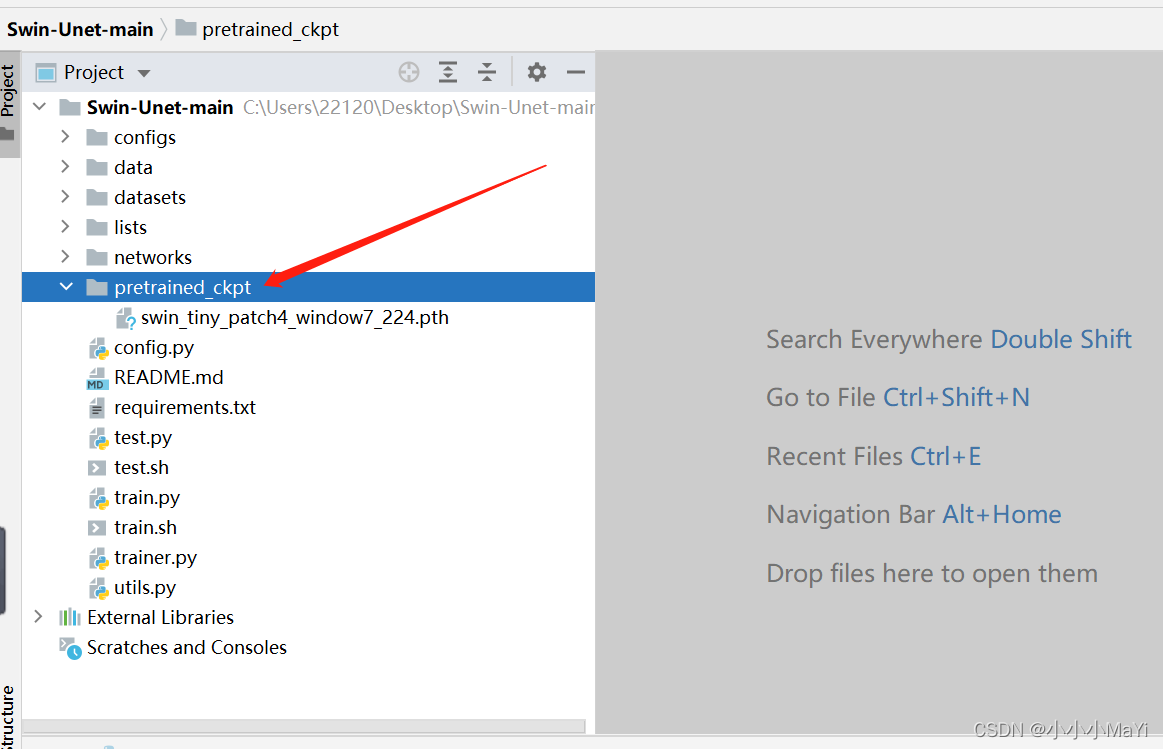
4. Baixe pesos pré-treinados
csdn download gratuito (recomendado)
Após o download dos pesos, coloque-os na pasta pretrained_ckpt do projeto. O oficial fornece apenas pesos de modelo com um tamanho de entrada de 224.
5. Modifique parte do código
Quando seus dados de imagem são de canal único, você pode definitivamente treinar normalmente depois de modificá-los de acordo com o que está escrito no texto. Para imagens de entrada com três canais e acima, modifique-as de acordo com o conteúdo escrito no texto. Se ainda houver algum problema, você pode comentar ou me enviar uma mensagem privada e vamos resolvê-lo juntos.
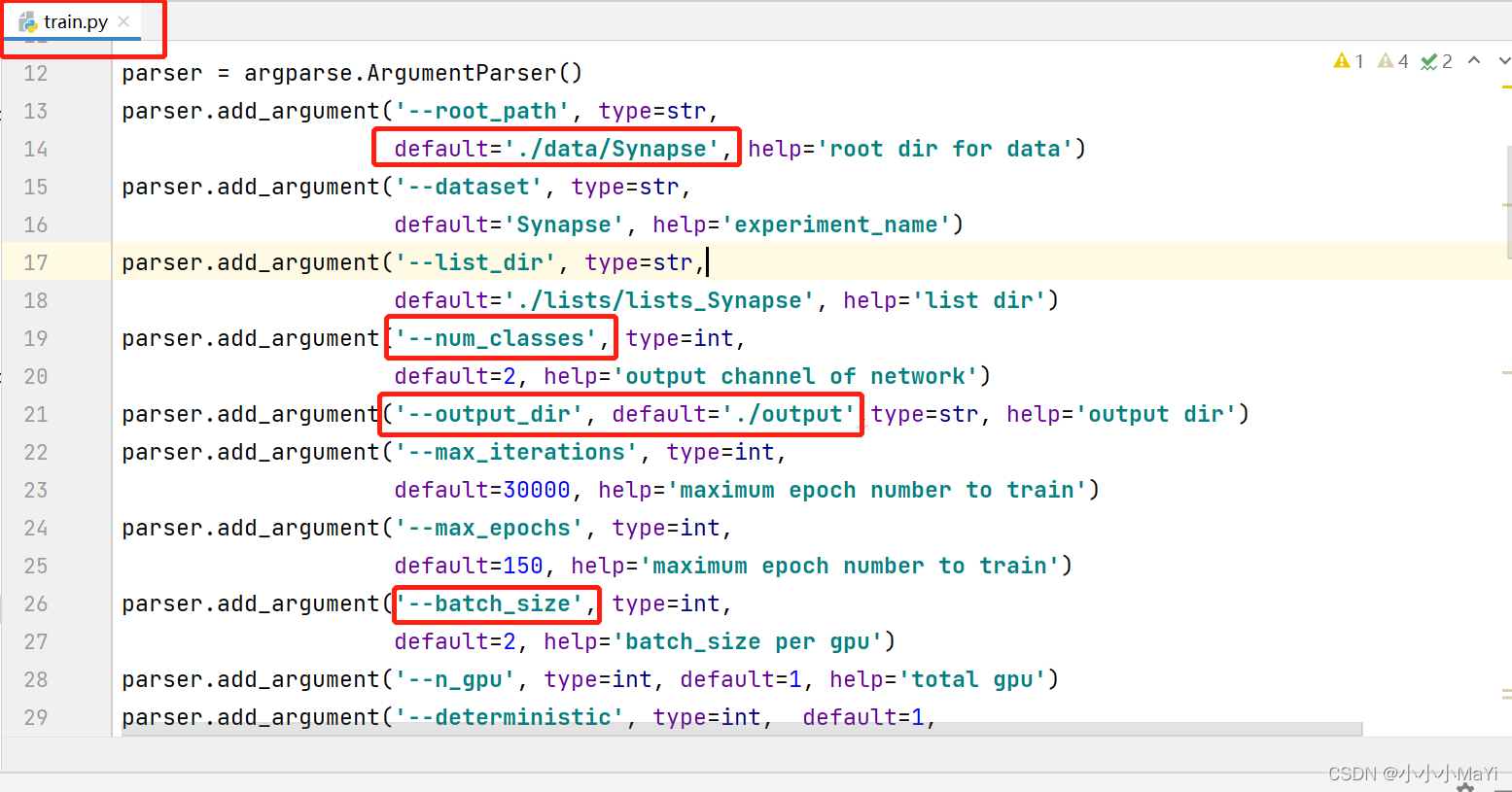
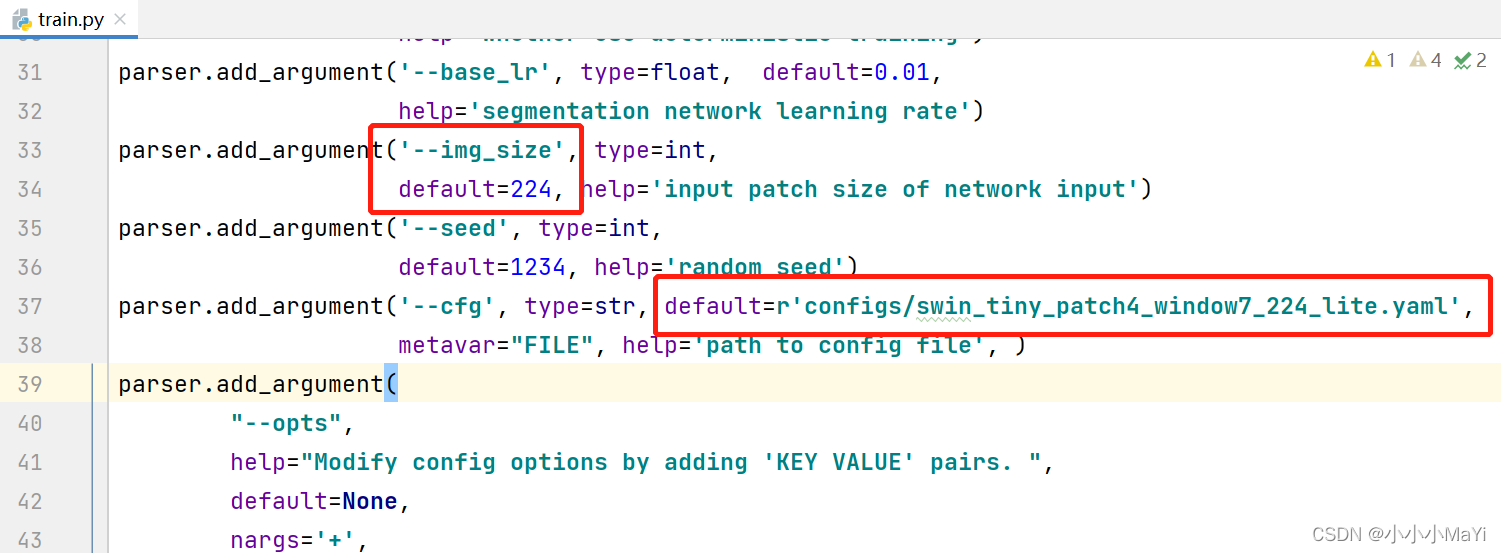
5.1 Modificar train.py
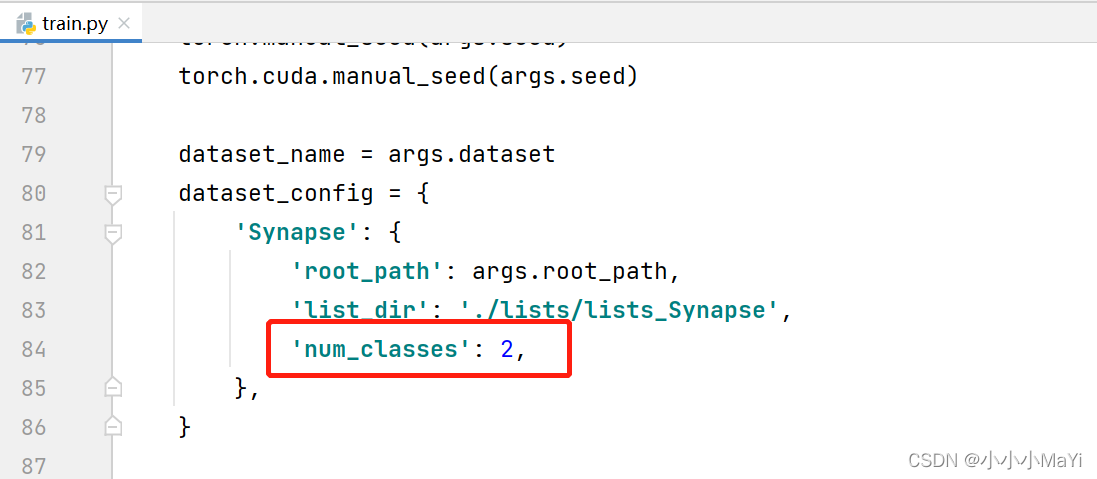
Modifique os parâmetros gerais, o caminho do arquivo de configuração e observe que num_classes é igual ao plano de fundo + o número de categorias de destino previstas. Por não haver muitas modificações, por favor me perdoe por não colocar o código modificado, você pode consultar a marca na figura para modificá-lo.
output_dir: o caminho onde os logs de treinamento e os pesos de saída são salvos
root_path: o diretório raiz onde o conjunto de dados está armazenado
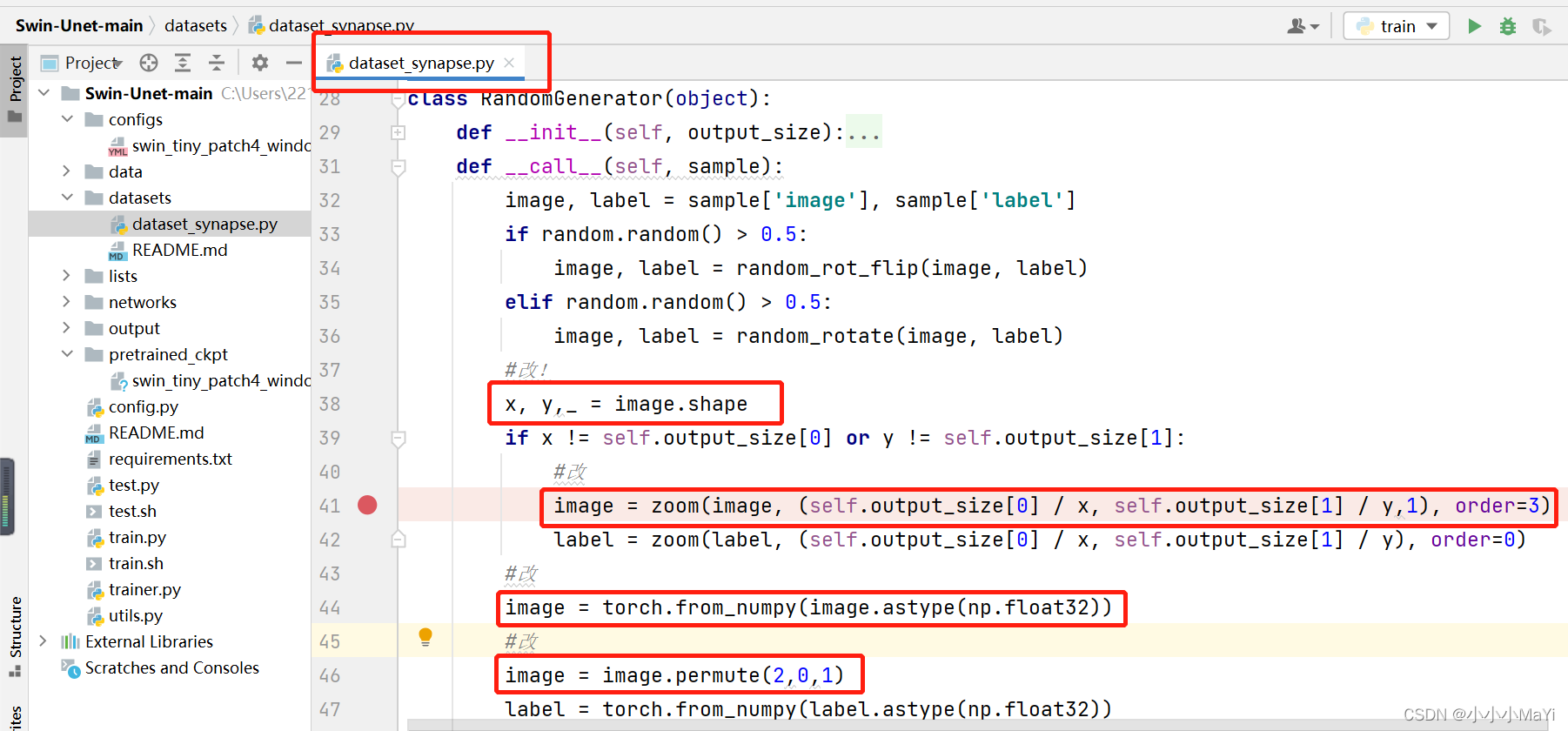
5.2 Modificar dataset_synapse.py
O formato do arquivo npz gerado por mim é diferente do formato oficial do arquivo npz, foi ajustado aqui, e é completamente o mesmo após o ajuste.
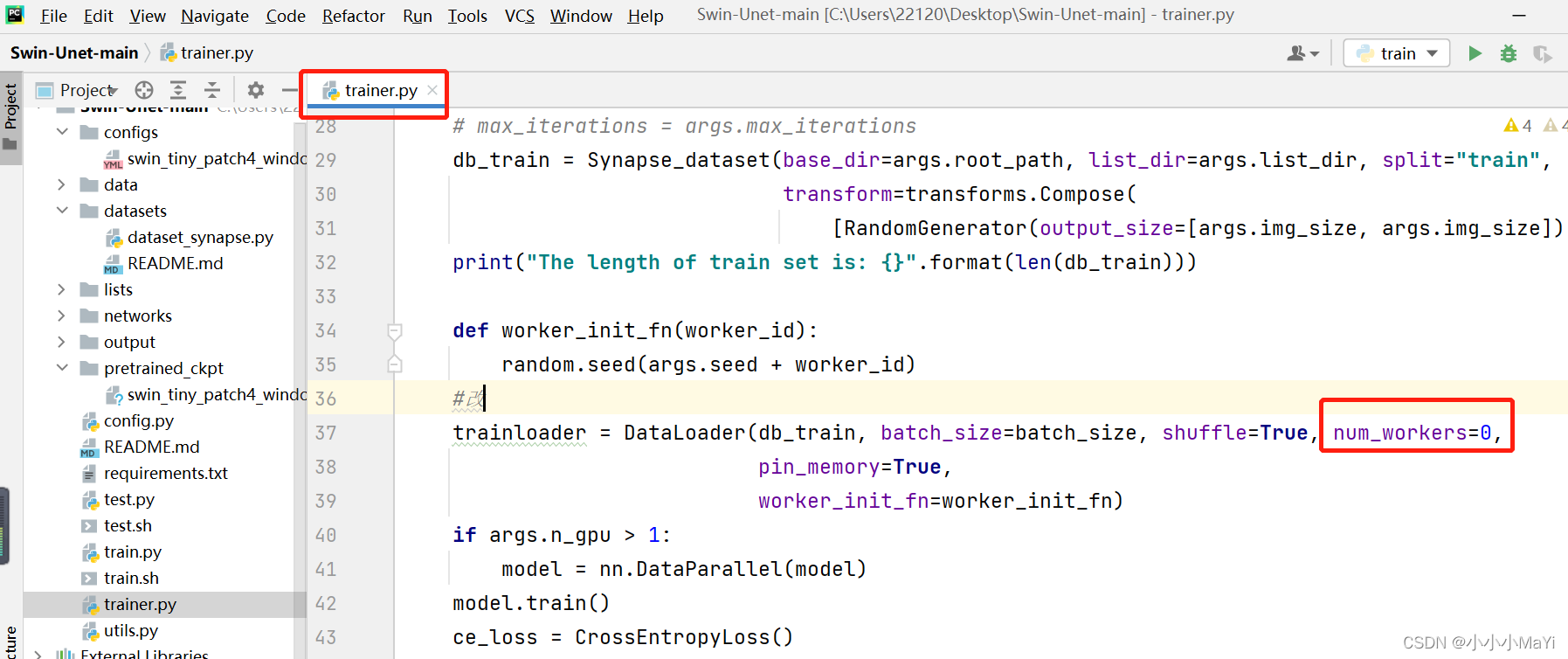
5.3. Modifique o arquivo trainer.py
Defina num_workers=0 na função DataLoader no arquivo trainer.py
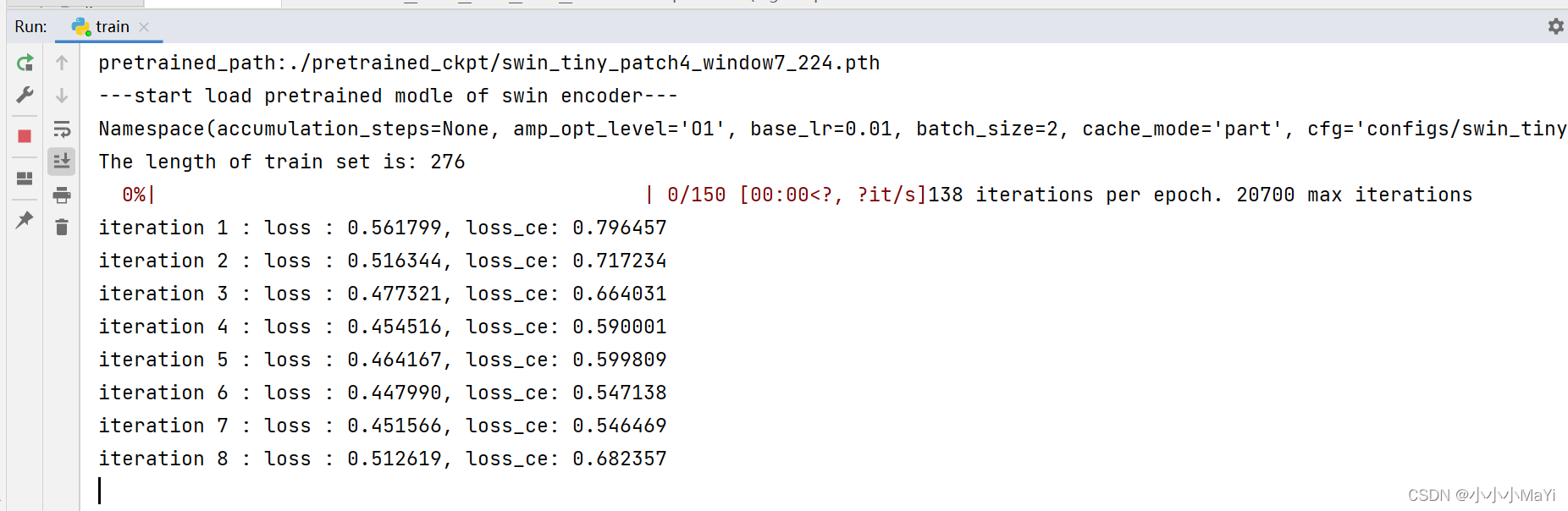
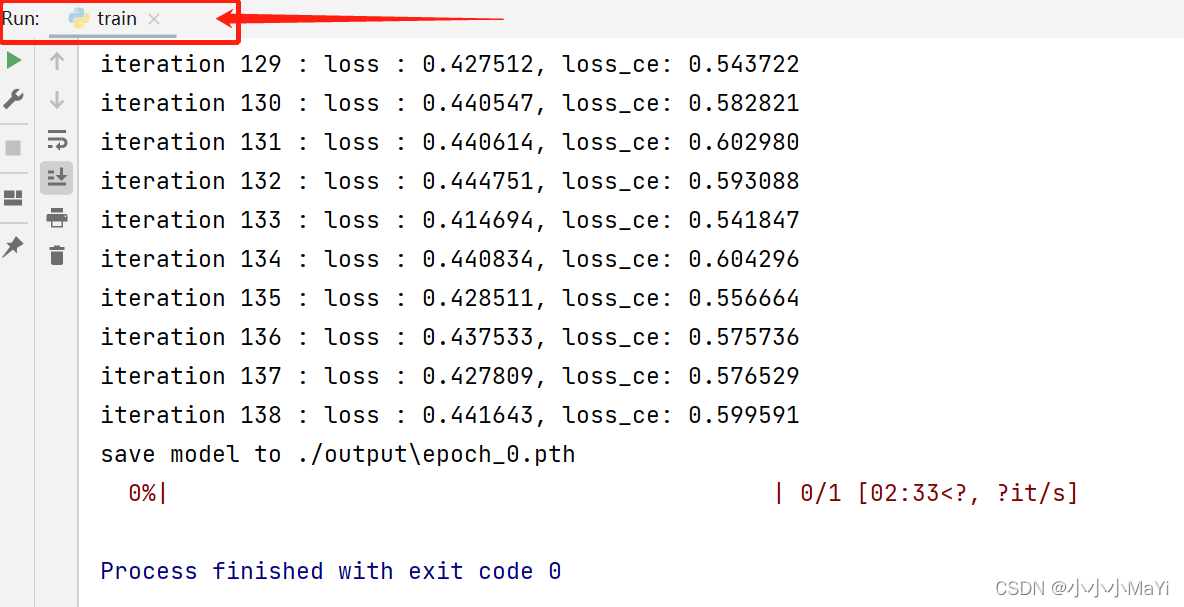
Até agora, todos os códigos foram modificados e o arquivo train.py é executado. Se o console tiver a seguinte saída, ele será executado com sucesso!
Após o treinamento, a pasta de saída no arquivo de projeto armazena o log de saída de treinamento e os pesos do modelo.