Em 25 de maio de 2022, o PolarDB-X de código aberto do Alibaba Cloud foi atualizado e lançado uma nova versão! O PolarDB-X atende ao sistema central de comércio eletrônico do Alibaba desde 2009 e começou a fornecer serviços comerciais em 2015 e foi oficialmente aberto em outubro de 2021. Esta versão é a primeira grande atualização de versão após o código aberto. Ela lançou a versão 2.1, que fez grandes progressos em estabilidade, integração ecológica e facilidade de uso. Esta versão se alinha com a versão comercial pela primeira vez em termos de recursos do kernel, adicionando X-Paxos, Existem muitos recursos importantes, como particionamento automático, separação de dados quentes e frios de OSS, etc., e continua a iterar na direção da integração ecológica do MySQL e da integração ecológica do K8S.
Clique aqui para assistir ao replay ao vivo da coletiva de imprensa
O PolarDB-X é um sistema de banco de dados distribuído nativo da nuvem projetado para ultra-alta simultaneidade, armazenamento massivo e cenários de consulta complexos. Ele adota a arquitetura de separação de computação de armazenamento e nada compartilhado, suporta expansão horizontal, transações distribuídas, carga mista e outros recursos, e possui as características de nível empresarial, nuvem nativa, alta disponibilidade e alta compatibilidade com o sistema MySQL e a ecologia. O PolarDB-X nasceu originalmente para resolver o gargalo de escalabilidade do banco de dados do sistema de negociação principal "Double Eleven" do Alibaba Tmall e depois cresceu junto com o Alibaba Cloud. É um sistema de banco de dados maduro e estável que foi verificado por uma variedade de cenários de negócios principais .
Novas características:
Este código aberto inclui 5 recursos principais para melhorar de forma abrangente a estabilidade e a compatibilidade ecológica do PolarDB-X .
01. Complemento de recursos de código aberto altamente disponíveis
O algoritmo de consenso distribuído (Consensus Algorithm) é um problema básico no campo da computação distribuída. Sua função mais básica é chegar a um consenso (forte consenso) sobre um (algum) valor entre vários processos, e então resolver o problema. sistemas distribuídos (alta disponibilidade) é um problema.Nos últimos anos, o aumento contínuo de NewSQL e bancos de dados nativos da nuvem tem promovido muito a combinação de bancos de dados relacionais e protocolos de consistência.Tecnologias comuns incluem Paxos e Raft.
Em 1º de abril de 2022, PolarDB-X oficialmente open source X-Paxos, baseado em nós de armazenamento MySQL nativos, fornecendo o protocolo de consenso de três cópias Paxos, que pode alcançar alta disponibilidade e tolerância a desastres de bancos de dados de nível financeiro e atingir RPO = 0 Disponibilidade de nível de produção, que pode atender arquiteturas de recuperação de desastres, como três salas de computadores na mesma cidade e três centros em dois locais.
O protocolo Paxos é muito necessário para a arquitetura orientada à nuvem. A essência da nuvem é virtualização e pool de recursos. A mudança e elasticidade dos nós é uma operação de rotina. Precisamos resolver a capacidade de operação e manutenção transparente orientada ao usuário. De qualquer forma, os dados não podem ser perdidos, não podem estar errados.
02. Atualização da capacidade de expansão horizontal distribuída
PolarDB-X, como uma distribuição nativa baseada em MySQL, além de fornecer recursos de recuperação de desastres de nível financeiro baseados em Paxos RPO=0, o recurso mais importante é a expansão horizontal distribuída, e uma nova versão dos dados foi lançada oficialmente em PolarDB-X versão 2.1.0 Tabela de partição, fornecendo o modo de partição automática.
O banco de dados no modo Auto suporta particionamento automático, ou seja, os dados podem ser distribuídos de forma automática e uniforme no cluster sem especificar uma chave de partição ao criar uma tabela; também suporta particionamento manual de tabelas usando a sintaxe padrão da tabela de partição MySQL. Combinado com a nova versão dos recursos da tabela de partição, novos recursos, como suporte para divisão de hotspot, particionamento TTL (Time To Live) e agendamento de afinidade de localidade, são adicionados, permitindo que você aproveite facilmente a distribuição transparente, o dimensionamento elástico e o gerenciamento de partição de bancos de dados distribuídos. dividendo.
Para obter detalhes, consulte o documento: Banco de dados do modo AUTO .
Com base na nova versão da tabela de partição, é escalável para fornecer recursos de análise térmica distribuída, renderizações de amostra
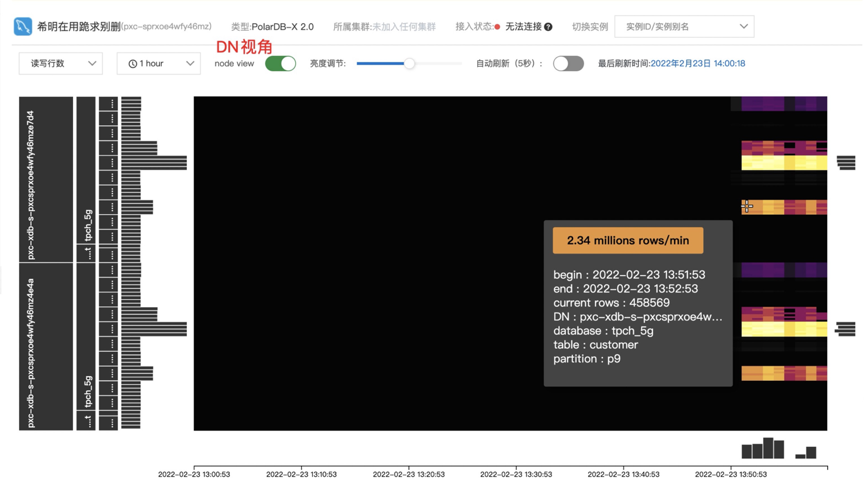
Análise térmica
03. Aceleração da adaptação ecológica do MySQL
Há um componente especial CDC (Change Data Capture) na arquitetura PolarDB-X, que é usado principalmente para fornecer aquisição de log incremental distribuído. Como distribuição nativa do MySQL, o CDC distribuído correspondente também é totalmente compatível com o MySQL Binlog no design. No PolarDB -X 2.1.0, melhoramos ainda mais a adaptação e compatibilidade com o ecossistema CDC existente do MySQL.
Em primeiro lugar, o serviço de log binário do PolarDB-X CDC concluiu a certificação de adaptação com componentes de análise de log binário do MySQL de código aberto, como canal, maxwell, debezium e Flink CDC. Em segundo lugar, o PolarDB-X CDC adiciona um novo serviço de réplica, que é totalmente compatível com os protocolos relacionados ao MySQL Replication. Através do comando MySQL start slave, o PolarDB-X pode ser usado como um banco de dados MySQL standby de código aberto para sincronizar dados em tempo real.

PolarDB-X e Flink CDC
04. Função de implantação leve perfeita
O PolarDB-X Operator é um sistema de controle e gerenciamento de cluster PolarDB-X baseado em Kubernetes que espera fornecer recursos completos de gerenciamento de ciclo de vida em Kubernetes nativos para atender à implantação leve dos usuários. Na versão PolarDB-X 2.1.0, aprimoramos ainda mais alguns recursos de operação e manutenção, como o fornecimento do sistema de monitoramento do Prometheus + Grafana, melhorando a capacidade de aumentar e diminuir nós distribuídos, expandir e contrair, e atualizações de versão.
05. Separação de dados frios e quentes do OSS
TTL (tempo de vida)
Como remover dados frios do armazenamento de linhas do InnoDB? Isso é uma dor de cabeça para muitos desenvolvedores. Se o formulário delete from statement + where condition for usado para excluir dados frios, é muito provável que o número de linhas verificadas seja muito grande e os dados estejam muito dispersos, o que causará o bloqueio da tabela e afetará o acesso de todo o instância de banco de dados; se você particionar de acordo com o tempo com antecedência, descarte as partições antigas uma a uma, e muitas tabelas que não são adequadas para particionamento por tempo ficarão indefesas.
Em resposta a este problema prático relatado pelos usuários, o PolarDB-X apresenta um novo recurso de TTL (time-to-live) para ajudar os usuários a completar a separação de dados quentes e frios. Em vez da manutenção manual, os usuários podem expirar automaticamente os dados especificando antecipadamente a hora de início, o tamanho da partição e o tempo de expiração. Além disso, particionamos de forma transparente cada tabela física na camada de armazenamento inferior e os dados são agregados de acordo com o tempo de atualização mais recente.
Por exemplo, para a tabela de pedidos t_orders, os usuários são particionados por hash pelo ID do pedido. Após a introdução do TTL, cada partição é dividida de forma transparente. A expiração da partição de tempo antigo (a partição 2022-01 na figura) é como arrancar um post-it. A remoção de dados quentes e frios é concluída sem travar a tabela e o particionamento manual.
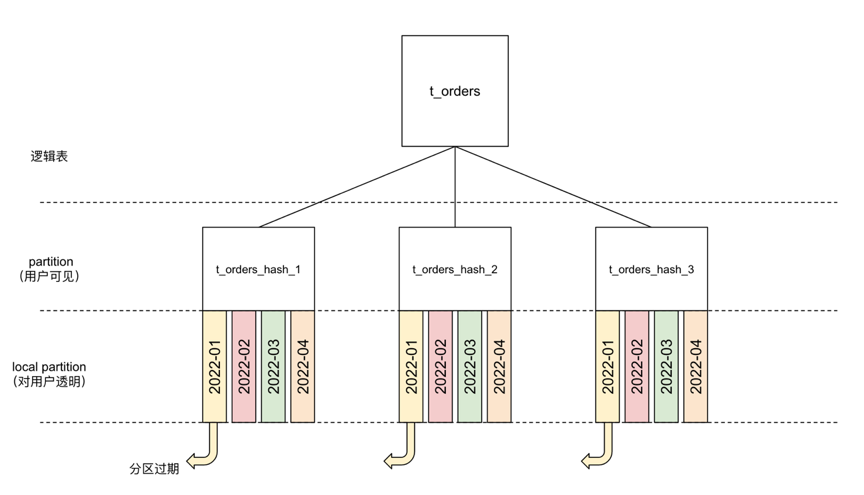
Para o uso específico do TTL, você pode consultar o documento oficial do site: Qual é a função TTL ?
Consulta de alto desempenho
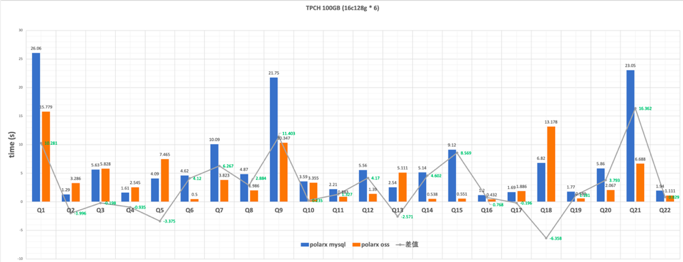
Quando os dados frios são retirados do banco de dados principal e arquivados no serviço de armazenamento OSS, obtemos uma tabela de arquivamento com OSS como portadora de armazenamento. É totalmente compatível com tipos de dados MySQL e diversos métodos de consulta, sob a premissa de baixo custo e alta disponibilidade, pode trazer a mesma experiência da tabela principal. Para atender às necessidades de consulta de diferentes usuários para dados históricos, levamos em consideração consultas analíticas pontuais e complexas no projeto. Realizamos uma avaliação correspondente para isso. Como o PolarDB-X no OSS usa armazenamento em colunas, ele tem vantagens naturais na consulta de relatórios. Portanto, em comparação com o modo de armazenamento de linhas do PolarDB-X no MySQL, os resultados do teste TPC-H foram bastante aprimorados; Sysbench com 100 milhões de linhas de volume de dados O teste de verificação de ponto também mostra que a tabela de arquivamento pode atender aos requisitos de consulta de dados históricos. No processo de realização das funções acima, o projeto mais crítico é o sistema de arquivos, cache multinível, índice multinível e remoção de consulta. Além disso, também inclui seleção de índice de armazenamento de colunas, cálculo vetorizado, aceleração AGG, etc., que apresentaremos em detalhes em artigos subsequentes.
Especificações do teste de desempenho TPC-H :
● CPU: 6 * 16C
● Memória: 6 * 128 GB
● SF = 100 (TPC-H 100 GB)
o tempo total é de cerca de 89s (PolarDB-X no MySQL é de 150s)
Especificações do teste de desempenho do Sysbench
:
● Teste de estresse ECS: 1 * 8C32G
● CN: 6 * 16C128G
● Linhas da tabela do Sysbench: 100 milhões
● Simultaneidade: 100 Os
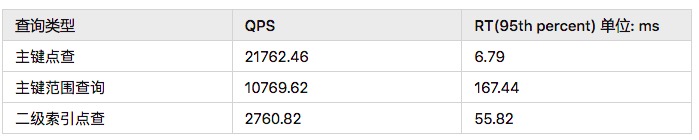
dados do teste de desempenho do Sysbench são os seguintes:
Migração com um clique
Após a conclusão da separação de dados quentes e frios, como arquivar rapidamente os dados no OSS? Com base na sintaxe padrão do MySQL, fornecemos uma maneira muito simples e conveniente, basta executar uma instrução de criação de tabela:
CREATE TABLE [oss_table_name] LIKE [innodb_table_name]
ENGINE = 'OSS' ARCHIVE_MODE = 'TTL'Após a execução, a tabela OSS irá clonar a estrutura da tabela InnoDB, eliminando a necessidade de os usuários projetarem a estrutura da tabela de arquivo; ao mesmo tempo, a tabela de arquivo de dados frios e a tabela de origem são vinculadas, e os dados expirados de a tabela de origem será importada automaticamente para a tabela de arquivo. Depois disso, os usuários podem concluir vários acessos a dados, incluindo verificação de ponto, consulta de intervalo e consulta analítica complexa por meio de SQL, assim como acessar tabelas comuns.
Forçar expiração manualmente
Se você deseja operações de expiração e arquivamento mais flexíveis, as instruções a seguir permitem expirar manualmente os dados e importar os dados expirados para o OSS:
ALTER TABLE [innodb_table_name] EXPIRE LOCAL PARTITION [local_partition_name]Mais recursos por favor clique aqui
Recursos mais detalhados
Adicionado suporte para criação de banco de dados e modo de construção de tabela especificado (novo modo de tabela de partição e modo de subtabela de sub-banco de dados antigo), o padrão é modo de subtabela de sub-banco de dados As
estratégias de particionamento incluem Hash/Range/List, etc.
Adicionado suporte para recursos de remoção dinâmica para tabelas
particionadas , incluindo dobra constante, mesclagem de intervalo e remoção de consulta de prefixo que suportam condições de coluna
de partição , excluindo, dividindo, mesclando e migrando partições
Grupo de tabelas adicionado e outros recursos (incluindo criação, exclusão, alteração de grupos de tabelas, etc.
) use a sintaxe da tabela de partição MySQL e particionada de acordo com estratégias de particionamento, como Hash/Range/List Adicionado
suporte para divisão automática usando a sintaxe da tabela de partição Adicionada nova tabela de partição A divisão automática de GSI carregará chave primária, que pode lidar com problemas de hotspot GSI Adicionado suporte para dimensionamento de instância etc.) Otimizou o comando Check Table para oferecer suporte à verificação de consistência de metadados, como partição da tabela principal, partição da tabela de índice e definição de coluna Adicionado SQL Advisor para suportar tabelas de transmissão recomendadas Adicionado suporte para a função Instant Add Column Adicionado suporte para Explicar Estatísticas pull Obtenha todas as informações que o otimizador precisa para otimização
Otimizou o desempenho das tarefas de verificação de dados em algumas operações em segundo plano DDL para acelerar as operações de alteração GSI/DDL
Adicionado suporte para comandos relacionados a réplicas compatíveis com MySQL
Adicionado suporte para clusters de três nós PAXOS de nó de armazenamento
Adicionados componentes de réplica, Suporta usando PolarDB-X como MySQL Slave para consumir dados através da sintaxe do change master …
Suporta a gravação de dados do tipo Rows_query_event no Binlog global, pré-condição: o parâmetro binlog_rows_query_log_events do nó DN precisa ser definido como On
Adicionado acesso Flink CDC
Novo Adicionado CR PolarDBXMonitor para monitorar PolarDBXCluster
Adicionado Helm Chart polardbx-monitor, incluindo kube-prometheus personalizado e Dashboard predefinido para exibir informações de monitoramento de cluster PolarDB-X
A ferramenta PXD suporta os modos de implantação de cópia única e cópia tripla
Endereço aberto do código-fonte PolarDB-X
Camada de computação: https://github.com/apsaradb/GalaxySQL
Camada de armazenamento: https://github.com/apsaradb/GalaxyEngine
Introdução à comunidade de código aberto PolarDB
A comunidade de código aberto PolarDB é uma plataforma de troca técnica para o PolarDB, um produto de banco de dados de código aberto do Alibaba Cloud. Como um produto de banco de dados de código aberto, é inseparável do suporte de usuários e desenvolvedores. Você pode fazer perguntas, requisitos funcionais, trocar experiências, compartilhar melhores práticas, enviar problemas, contribuir com código etc. para produtos PolarDB na comunidade.
Para permitir que os membros da comunidade se comuniquem de forma mais conveniente e promovam o desenvolvimento da indústria de banco de dados, a comunidade organizará encontros online e offline, organizará atividades de intercâmbio para faculdades e empresas e organizará competições técnicas. Dê as boas-vindas a entusiastas de banco de dados, usuários e desenvolvedores para se juntarem à comunidade.
Site oficial de código aberto PolarDB-X:
https://www.polardbx.com/home
O campo de treinamento de código aberto PolarDB-X agora está se registrando:
https://developer.aliyun.com/trainingcamp/f1b1508330684d6b975b350c285936ca