A história começa há muitos anos.
Você já deve ter ouvido a afirmação de que uma única tabela em um banco de dados recomenda no máximo 2kw de dados. Se exceder, o desempenho cairá mais severamente.
Coincidentemente.
Eu também já ouvi falar.
Mas não aceito sua sugestão, apenas carrega 100 milhões de dados em uma única tabela.
Neste momento, depois que os novos estagiários do nosso grupo viram, eles me perguntaram inocentemente: "Não é recomendado que uma única tabela tenha no máximo 20 milhões? Por que essa tabela é 100 milhões e não é dividida em bancos de dados e tabelas ?"
Posso dizer que sou preguiçoso ? Como eu pensei que este relógio poderia subir tão rápido quando eu o projetei. . .
Não posso.
Dizer isso é admitir que sou um câncer na equipe de desenvolvimento , embora seja, mas não posso admitir .
Sinto como se estivesse sentada sobre alfinetes e agulhas, como um espinho nas costas, como uma picada na garganta.
Uma enxurrada de ação começou.
"Eu fiz isso por uma razão"
"Embora esta tabela seja muito grande, você notou que sua consulta é realmente muito rápida"
"Esse 2kw é um valor sugerido, temos que ver de onde veio esse 2kw"
Qual é o número máximo de linhas em uma única tabela em um banco de dados?
Vejamos primeiro o número máximo teórico de linhas em uma única tabela.
O SQL para criar a tabela é escrito assim,
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=100037 DEFAULT CHARSET=utf8;
onde id é a chave primária. A própria chave primária é única, o que significa que o tamanho da chave primária pode limitar o limite superior da tabela.
Se a chave primária for declarada como o inttamanho, ou seja, 32 bits, ela poderá suportar 2^32-1, que é cerca de 2,1 bilhões .
Se for bigint, é 2^64-1, mas esse número é muito grande . Geralmente, o disco não aguenta antes que esse limite seja atingido .
Seja ultrajante.
Se eu declarar a chave primária como tinyint, um byte, 8 bits, max 2^8-1, ou seja 255.
CREATE TABLE `user` (
`id` tinyint(2) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
Se eu quiser inserir um dado com id=256, vai dar erro .
mysql> INSERT INTO `tmp` (`id`, `name`, `age`) VALUES (256, '', 60);
ERROR 1264 (22003): Out of range value for column 'id' at row 1
Ou seja, tinyinta chave primária limita um máximo de 255 dados na tabela.
Além da chave primária, que outros fatores afetarão o número de linhas?
estrutura do índice
A árvore B+ é usada dentro do índice, também é um estoque antigo da Baguwen, e provavelmente todos estão familiarizados com ela.
Para não deixar todo mundo ter muito cansaço de julgar feio, hoje eu tento falar sobre essa coisa por outro ângulo.
estrutura da página
Suponha que tenhamos uma tabela de dados do usuário.
tabela de usuário
onde id é a chave primária exclusiva .
Isso se parece com dados de linha por linha, por conveniência, vamos chamá-los de registro mais tarde .
Esta tabela se parece com uma planilha do Excel. Os dados do Excel são um arquivo xx.excel no disco rígido.
Os dados da tabela de usuário acima são realmente semelhantes no disco rígido e são colocados no arquivo user.ibd . O significado é o arquivo de dados innodb da tabela do usuário, ponto profissional, também chamado de espaço de tabela .
Embora na folha de dados, eles parecem estar um ao lado do outro. Mas, na verdade, em user.ibd eles são divididos em muitas pequenas páginas de dados , cada uma com 16k de tamanho.
Semelhante ao seguinte.
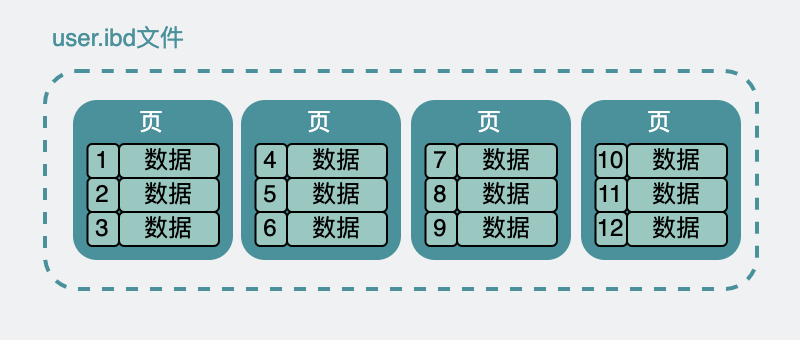
Existem muitas páginas dentro do arquivo ibd
Vamos focar a perspectiva e colocá-la na página.
A página inteira 16knão é grande, mas são tantos registros que não cabem em uma página, então ela será dividida em muitas páginas. E esses 16k não podem ser usados para todos os discos, certo?
Como os registros são divididos em muitas partes e colocados em muitas páginas, para identificar exclusivamente qual é a página, é necessário introduzir o número da página (na verdade, o deslocamento de endereço de um espaço de tabela). Ao mesmo tempo, para associar essas páginas de dados, os ponteiros frontal e traseiro são introduzidos para apontar para as páginas frontal e traseira. Estes são adicionados ao cabeçalho .
A página precisa ser lida e escrita. 16k não é muito pequeno. É possível que o cabo de alimentação seja puxado na metade da escrita. Portanto, para garantir a exatidão da página de dados, também é introduzido um código de verificação . Isso é adicionado ao rodapé .
O espaço restante é usado para colocar nossos registros. E se o número de linhas no registro for muito grande, não é muito eficiente percorrer uma a uma ao entrar na página, então um diretório de páginas é gerado para esses dados , e os detalhes específicos da implementação não são importantes. Apenas saiba que ele pode mudar a eficiência da busca de O(n) para O(lgn) por meio de busca binária .
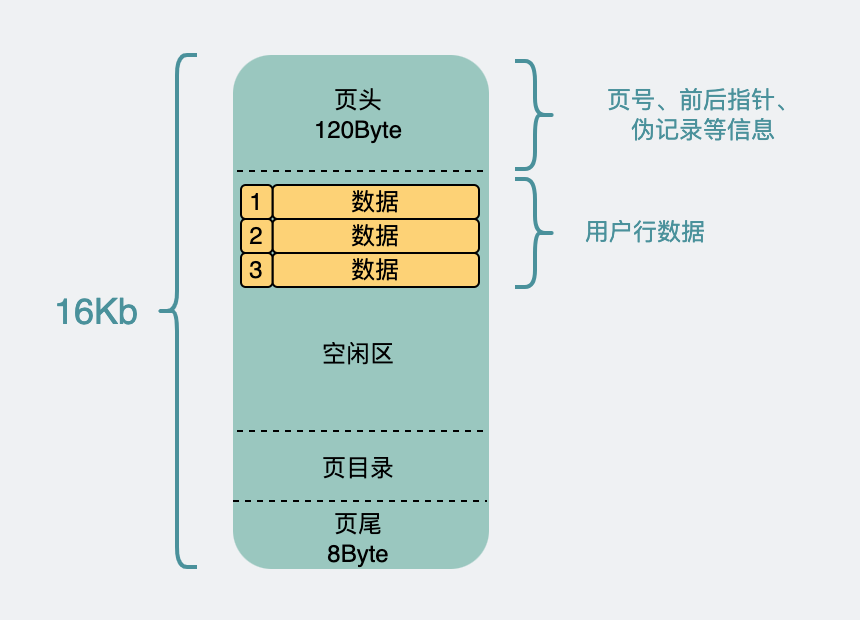
estrutura da página
Da página ao índice
Se quisermos verificar um registro, podemos pescar todas as páginas no tablespace e, em seguida, pescar os registros nele um por um para determinar se estamos procurando por ele.
Quando o número de linhas é pequeno, esta operação não é um problema.
Quanto maior o número de linhas, mais lento o desempenho , portanto, para acelerar a pesquisa, podemos selecionar o registro com o menor id de chave primária em cada página de dados , e precisamos apenas do id da chave primária e do número da página do página onde estão localizados . Forme um novo registro e coloque-o em uma página de dados recém-gerada. Essa nova página de dados não é diferente da estrutura da página anterior, e o tamanho ainda é 16k.
Mas para distingui-lo da página de dados anterior. As informações do nível da página (nível da página) são adicionadas à página de dados , começando em 0 e contando para cima. Portanto, existe um conceito de níveis superior e inferior entre as páginas , como o seguinte.
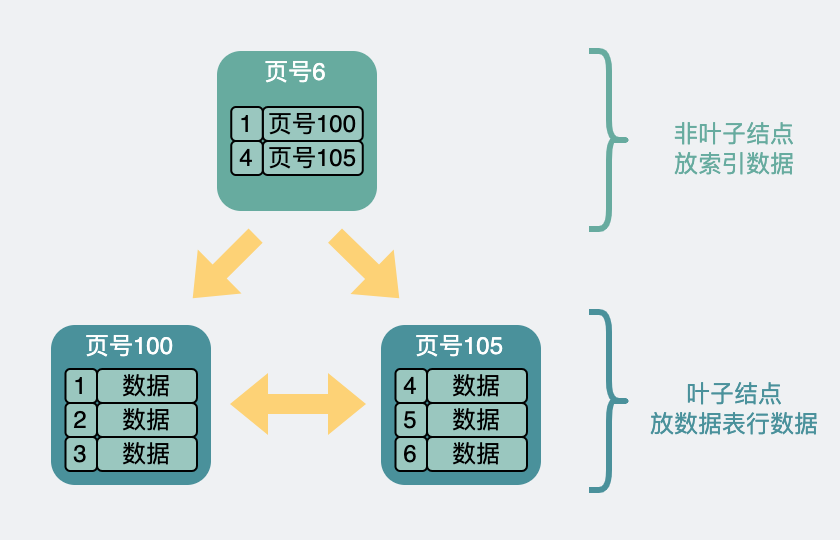
Estrutura de árvore B+ de dois níveis
De repente, parece uma árvore de cabeça para baixo entre as páginas. Ou seja, costumamos dizer índice de árvore B+ .
Na camada inferior, o nível de página é 0 , que é o chamado nó folha , e os demais são chamados nós não folha .
A imagem acima mostra uma árvore de duas camadas . Se houver mais dados, também podemos construir uma camada através de um método semelhante. É uma árvore de três andares .
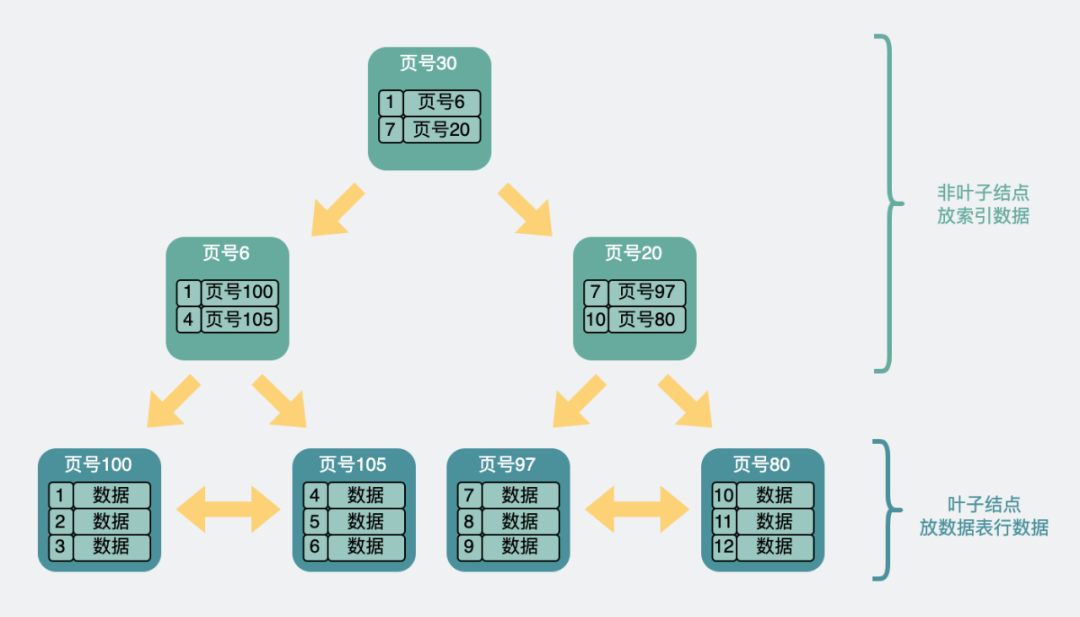
Estrutura de árvore B+ de três camadas
Agora podemos acelerar a consulta por meio de uma árvore B+. por exemplo.
Digamos que queremos encontrar os dados da linha 5. Ele começará com os registros na página superior. O registro contém o ID da chave primária e o número da página (endereço da página) . Observe a seta amarela na figura abaixo, o id mínimo à esquerda é 1 e o id mínimo à direita é 7. Se os dados com id=5 existirem, eles devem estar na seta para a esquerda. Então siga o endereço da página do registro para a 6号página de dados, e então julgue que id=5>4, então deve estar na página de dados à direita, então carregue a 105号página de dados. Encontre a linha de dados com id=5 na página de dados e complete a consulta.
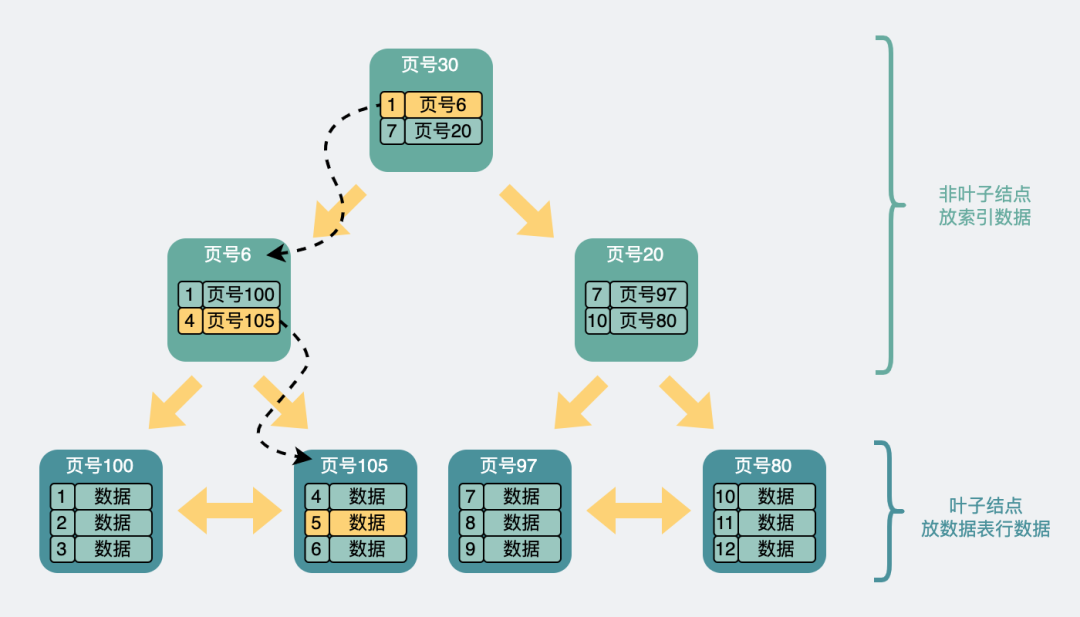
Processo de consulta em árvore B+
Outra coisa a notar é que os números de página das páginas acima não são consecutivos e não estão necessariamente próximos uns dos outros no disco.
Nesse processo, três páginas são consultadas.Se essas três páginas estiverem todas no disco (não carregadas na memória antecipadamente), serão necessárias até três consultas de E/S de disco antes que possam ser carregadas na memória.
O número de registros carregados pela árvore B+
A partir da estrutura acima, pode-se ver que os dados do registro são colocados no nó folha de último nível da árvore B+ . Os dados de índice usados para acelerar a consulta são colocados no nó não .
Isso quer dizer
Para a mesma página de 16k, cada parte de dados no nó não folha aponta para uma nova página e a nova página tem duas possibilidades.
-
Se for o nó folha de último nível, haverá linhas de dados de registro nele.
-
Se for um nó não folha, o loop continuará apontando para novas páginas de dados.
Suposição
-
O número de ponteiros para outras páginas de memória no nó não folha é
x -
O número de registros que podem ser acomodados em um nó folha é
y -
O número de níveis da árvore B+ é
z
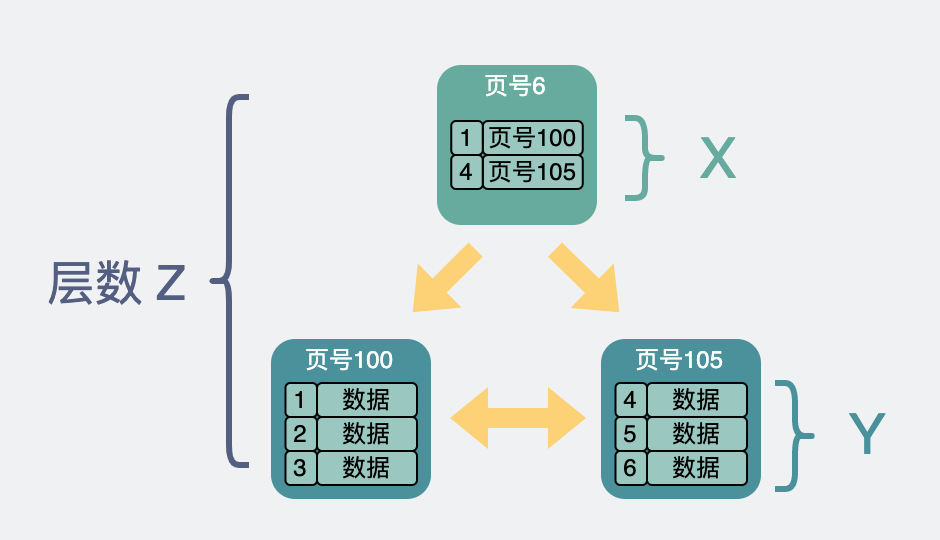
Como calcular o número total de linhas
Então a quantidade total de dados de linha nesta árvore B+ é igual a (x ^ (z-1)) * y.
como calcular x
Vamos voltar e examinar a estrutura da página de dados.
estrutura da página
Nos nós não folha, os dados relacionados à consulta de índice são colocados principalmente, e a chave primária e o número de página apontador são colocados.
A chave primária é assumida como bigint(8Byte), e o número da página é chamado no código-fonte FIL_PAGE_OFFSET(4Byte), então uma parte dos dados no nó não folha é 12Byteesquerda e direita.
A página de dados inteira 16k, a parte dos dados no início e no final da página é aproximadamente somada 128Byte, mais a estimativa bruta do diretório da página 1k. Os 15k restantes divididos por 12Byte, são iguais a 1280, ou seja, podem apontar para x=1280 páginas .
A árvore binária que costumamos dizer se refere a um nó que pode irradiar dois novos nós. Um nó em uma árvore m-ária pode apontar para m novos nós. Essa operação de apontar para um novo nó é chamada de fanout .
A árvore B+ acima, que pode apontar para 1280 novos nós, é tão assustadora que pode-se dizer que o fan-out é muito alto .
cálculo y
A estrutura de dados dos nós folha e nós não-folha é a mesma, então também é assumido que o resto 15kbpode ser reproduzido.
Os dados reais da linha são colocados no nó folha. Suponha uma linha de dados 1kb, para que y=15 linhas possam ser colocadas em uma página .
contagem total de linhas
De volta a (x ^ (z-1)) * y esta fórmula.
conhecido x=1280, y=15.
Assumindo que a árvore B+ tem dois níveis , que z=2. é(1280 ^ (2-1)) * 15 ≈ 2w
Assumindo que a árvore B+ tem três níveis , que z=3. é(1280 ^ (3-1)) * 15 ≈ 2.5kw
**Esse 2,5kw é a origem do número máximo recomendado de linhas para uma única tabela que costumamos dizer que é 2kw. **Afinal, adicione outra camada e os dados são um pouco escandalosos. A página de dados de três camadas corresponde a um máximo de três E/S de disco, o que também é razoável.
É lento quando o número de linhas excede 100 milhões?
O acima pressupõe que uma única linha de dados usa 1kb, portanto, uma página de dados pode conter 15 linhas de dados.
Se eu não puder usar tanto para uma única linha de dados, por exemplo, use apenas 250byte. Em seguida, uma única página de dados pode conter 60 linhas de dados.
Também é uma árvore B+ de três níveis e o número de linhas suportadas por uma única tabela é (1280 ^ (3-1)) * 60 ≈ 1个亿.
Veja meus 100 milhões de dados, que na verdade são uma árvore B+ de três camadas.Para encontrar uma linha de dados nessa árvore B+, são necessários até três E/S de disco. Então não é lento.
Esta é uma boa explicação para o início do artigo, porque eu tenho uma única tabela de 100 milhões, mas o desempenho da consulta não é um grande problema.
O número de registros transportados pela árvore B
Agora que já falamos sobre isso aqui, vamos falar um pouco mais ao longo deste tópico.
Todos nós sabemos que os índices do MySQL agora são todos árvores B+, e existe um tipo de árvore, que é muito parecida com a árvore B+, chamada de árvore B, também chamada de árvore B.
A maior diferença entre ela e a árvore B+ é que a árvore B+ só coloca os dados da linha da tabela de dados no nó folha de último nível, enquanto a árvore B os coloca nos nós folha e não folha.
Portanto, a estrutura da árvore B é semelhante a esta
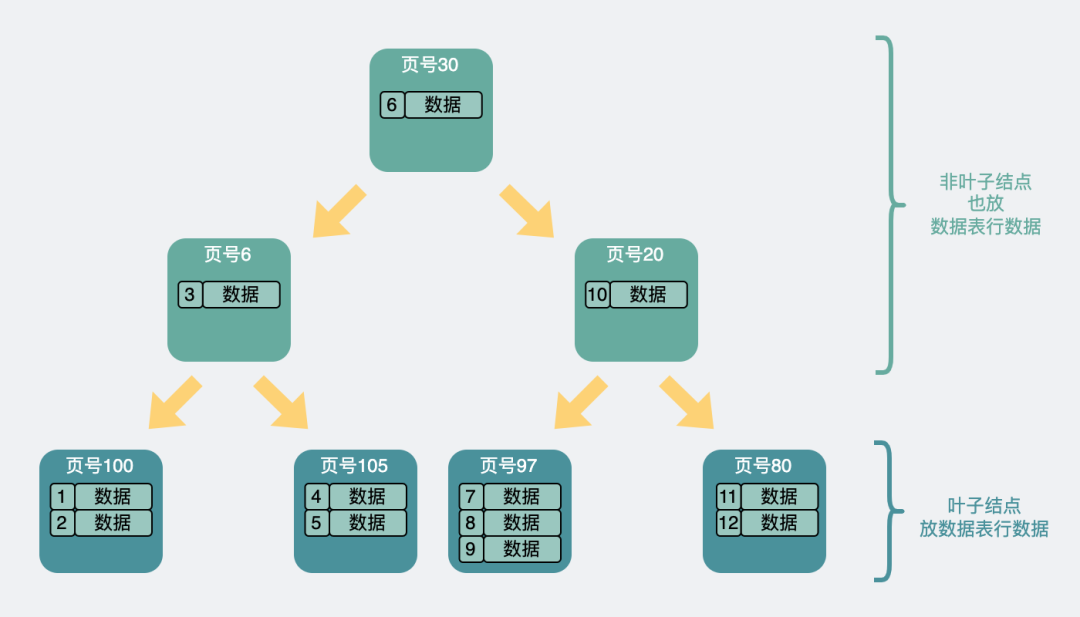
Estrutura de árvore B
A árvore B armazena todos os dados de linha em nós não folha. Assumindo que cada página de dados ainda tem 16kb, cada página fica com 15kb e uma linha de dados da tabela de dados ainda ocupa 1kb, mesmo que os vários ponteiros de página não sejam considerados, Apenas 15 dados podem ser colocados. O fanout da página de dados é significativamente reduzido.
A fórmula para calcular o número total de linhas que podem ser transportadas também se torna uma série proporcional .
15 + 15^2 +15^3 + ... + 15^z
Entre eles, z também significa o número de camadas.
É necessário poder colocar 2kwdados à esquerda e à direita z>=6. Ou seja, a árvore precisa ter 6 camadas, e 6 páginas são acessadas por vez. Supondo que essas 6 páginas não sejam consecutivas, para consultar um dos dados, o pior caso requer 6 IOs de disco .
No mesmo caso, a árvore B+ coloca cerca de 2kw de dados, e uma verificação é no máximo 3 vezes de E/S de disco.
Quanto mais E/S de disco, mais lento ele é, e a diferença de desempenho entre os dois é um pouco maior.
Por esta razão, as árvores B+ são mais adequadas para índices mysql do que as árvores B.
Resumir
-
As páginas de dados dos nós folha e não folha da árvore B+ são 16k, e a estrutura de dados é a mesma. A diferença é que os nós folha colocam os dados reais da linha, enquanto os nós não folha colocam a chave primária e o endereço da próxima página.
-
A árvore B+ geralmente tem duas a três camadas. Devido ao seu alto fan-out, três camadas podem suportar dados de mais de 2kw, e uma consulta pode executar até 1 a 3 IOs de disco por vez, e o desempenho também é bom .
-
Para armazenar a mesma quantidade de dados, a árvore B tem um nível mais alto que a árvore B+, portanto, há mais IOs de disco, portanto, a árvore B+ é mais adequada para se tornar um índice do MySQL.
-
A estrutura do índice não afeta o número máximo de linhas em uma única tabela e 2kw é apenas um valor recomendado. Exceder esse valor pode levar a um nível de árvore B+ mais alto e afetar o desempenho da consulta.
-
O máximo de tabela única também é limitado pelo tamanho da chave primária e pelo tamanho do disco.
Referências
"Kernel MYSQL: INNODB Storage Engine Volume 1"
Finalmente
Embora eu tenha colocado 100 milhões de dados em uma única tabela, a premissa dessa operação é que eu sei muito bem que isso não afetará muito o desempenho.
Essa onda de explicações é impecável e impecável.
Neste ponto, até eu estava convencido por mim mesmo. Presumivelmente, os estagiários também.
Porra, esse maldito câncer é na verdade um pouco "inteligente".

Recentemente, o volume de leitura das atualizações originais diminuiu constantemente e, depois de pensar nisso, joguei e me virei à noite.
Eu tenho um pedido imaturo.

Já faz muito tempo desde que deixei Guangdong, e ninguém me chamou de Pretty Boy por muito tempo.
Você pode me chamar de menino bonito na área de comentários ?
Pode um desejo meu tão gentil e simples ser realizado?
Se você realmente não consegue falar, pode me ajudar a clicar em gostei e assistir no canto inferior direito ?
Pare de falar, vamos engasgar no oceano do conhecimento juntos
Clique no cartão de visita abaixo para seguir a conta oficial: [Xiaobai debug]

Depuração Xiaobai
Prometa-me, depois de prestar atenção, aprender bem as técnicas, não apenas colecionar meus emojis. .
31 conteúdo original
Sem público
Não está satisfeito em falar merda na área de mensagens?
Adicione-me, montamos um grupo de remar e se gabar. No grupo, você pode conversar sobre temas interessantes com colegas ou entrevistadores que você pode encontrar na próxima vez que mudar de emprego. Simplesmente super! abrir! Coração!