Source丨AI Park
Editar 丨 Gokushi Platform
Leitura guiada
Com a ajuda do algoritmo de rede neural convolucional e da estrutura U-Net, a falha de soldagem do plano de aço pode ser detectada com precisão e sua gravidade pode ser avaliada. Este artigo apresenta o método de detecção e apresenta os resultados de três amostras.
Autor: Soham Malakar
Compilação: ronghuaiyang
Links originais:
https://medium.com/@malakar_soham/detecting-welding-defects-in-steel-plates-using-computer-vision-algorithms-98b1fb0da5e9

1. Introdução
Defeitos de solda podem ser definidos como irregularidades, descontinuidades, imperfeições ou inconsistências na superfície da solda. Defeitos em juntas soldadas podem levar a peças e conjuntos sucateados, reparos caros, desempenho significativamente reduzido em condições operacionais e, em casos extremos, falhas catastróficas que resultam em perda de propriedade e vida útil.
Além disso, devido aos defeitos do próprio processo de soldagem e às características do próprio metal, sempre haverá certos defeitos no processo de soldagem. Avaliar a qualidade da solda é importante porque as juntas soldadas são frequentemente o local de iniciação de trincas devido a defeitos geométricos metalúrgicos inerentes, não uniformidade de propriedades mecânicas e presença de tensões residuais.
Na prática, é quase impossível obter uma solda perfeita e, na maioria dos casos, não é necessário fornecer as funções de serviço necessárias. No entanto, a detecção precoce e o isolamento são sempre preferíveis a um acidente.
Usando nosso algoritmo, podemos detectar facilmente imagens de falhas de soldagem e medir com precisão a gravidade de cada falha . Isso ajudará ainda mais no reconhecimento de imagem mais rápido e evitará situações indesejáveis.
Os resultados mostram que o uso do algoritmo de rede neural convolucional e da estrutura U-Net pode melhorar muito a eficiência do processamento. Os resultados foram 98,3% precisos ao final do trabalho .
2 Conhecimento preliminar
Noções básicas de aprendizado de máquina
A ideia básica da rede neural convolucional
Entenda as operações de convolução, pool máximo e upsampling
Entenda a filosofia arquitetônica da U-Net
Compreensão básica de conexões de salto em blocos residuais (opcional)
Conhecimento de manipulação de ConvNets usando bibliotecas Python, TensorFlow e Keras (opcional)
3 Segmentação de imagem
A segmentação é a divisão de uma imagem em regiões distintas que contêm pixels com propriedades semelhantes. Para serem significativas e úteis para análise e interpretação de imagens, as regiões devem ter fortes associações com objetos delineados ou características de interesse.
O sucesso da análise de imagens depende da confiabilidade da segmentação, mas a segmentação precisa de imagens é muitas vezes um problema muito desafiador.
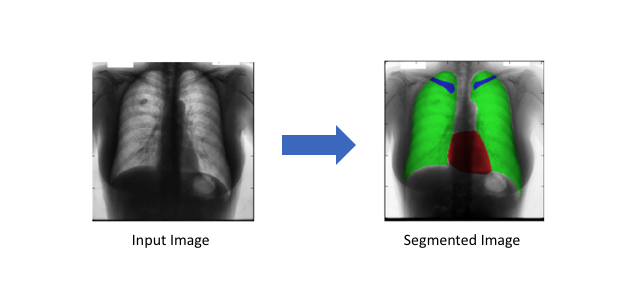
Radiografia de tórax segmentada, coração (vermelho), pulmões (verde) e clavícula (azul)
4 momentos de imagem
Um momento de imagem é uma certa média ponderada de intensidades de pixel de imagem. Momentos de imagem são usados para descrever o objeto segmentado.
Propriedades simples de imagens descobertas por momentos de imagem incluem:
Área (ou intensidade total)
Centro de gravidade
Informações sobre direções
5 Entenda os dados
dataset contém dois diretórios. As imagens originais são armazenadas no diretório 'images' e as imagens segmentadas são armazenadas no diretório 'labels'.
Vamos visualizar os dados:

imagem original de 'imagem'

imagem binária de 'rótulos'
Essas imagens do diretório "labels" são imagens binárias ou rótulos de verdade. Esta é a previsão que nosso modelo deve fazer dada a imagem original. Em uma imagem binária, os pixels têm um valor "alto" ou um valor "baixo". Áreas brancas ou valores "altos" indicam áreas defeituosas, e áreas pretas ou valores "baixos" indicam ausência de defeitos.
6 Métodos usados
A arquitetura que usamos para este problema é a U-Net. Passaremos por três etapas para detectar falhas e medir a gravidade dessas imagens de solda:
Segmentação de imagem
Use cores para indicar a gravidade
Use momentos de imagem para medir a gravidade
Treine o modelo
Abaixo está a arquitetura U-Net que usamos para o modelo:
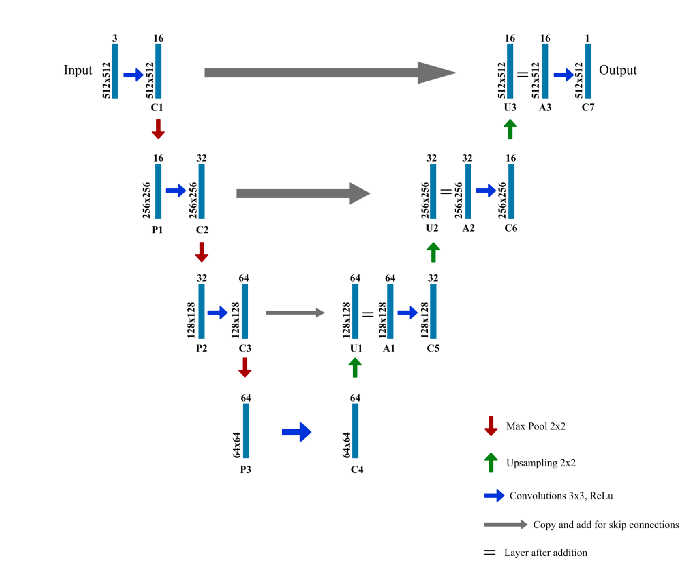
Estrutura U-Net usada
Pontos a observar:
Cada caixa azul corresponde a um mapa de recursos multicanal
O número de canais é indicado na parte superior da caixa
A dimensão (x,y) é exibida na borda inferior esquerda da caixa
As setas indicam ações diferentes
O nome da camada está abaixo da camada
C1 C2...C7 são as camadas de saída após a operação de convolução
P1, P2, P3 são as camadas de saída da operação de pooling máximo
U1, U2, U3 são as camadas de saída da operação de upsampling
A1, A2, A3 são conexões de salto
À esquerda está o caminho de encolhimento, aplicando convolução regular e operações de agrupamento máximo
O tamanho da imagem diminui gradualmente, enquanto a profundidade aumenta gradualmente
À direita está o caminho de desenrolamento, onde são aplicadas as operações de convolução transposta (upamostragem) e convolução regular
No caminho de expansão, o tamanho da imagem aumenta gradualmente e a profundidade diminui gradualmente
Para obter localizações mais precisas, em cada etapa do caminho de expansão, usamos conexões de salto para concatenar a saída da camada convolucional transposta com o mesmo mapa de recursos de nível do codificador: A1 = U1 + C3 A2 = U2 + C2 A3 = U3 + C1
Após cada conexão, aplicamos a convolução regular novamente para que o modelo possa aprender a montar uma saída mais precisa.
import numpy as np
import cv2
import os
import random
import tensorflow as tf
h,w = 512,512
def create_model():
inputs = tf.keras.layers.Input(shape=(h,w,3))
conv1 = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(inputs)
pool1 = tf.keras.layers.MaxPool2D()(conv1)
conv2 = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(pool1)
pool2 = tf.keras.layers.MaxPool2D()(conv2)
conv3 = tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same')(pool2)
pool3 = tf.keras.layers.MaxPool2D()(conv3)
conv4 = tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same')(pool3)
upsm5 = tf.keras.layers.UpSampling2D()(conv4)
upad5 = tf.keras.layers.Add()([conv3,upsm5])
conv5 = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(upad5)
upsm6 = tf.keras.layers.UpSampling2D()(conv5)
upad6 = tf.keras.layers.Add()([conv2,upsm6])
conv6 = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(upad6)
upsm7 = tf.keras.layers.UpSampling2D()(conv6)
upad7 = tf.keras.layers.Add()([conv1,upsm7])
conv7 = tf.keras.layers.Conv2D(1,(3,3),activation='relu',padding='same')(upad7)
model = tf.keras.models.Model(inputs=inputs, outputs=conv7)
return model
images = []
labels = []
files = os.listdir('./dataset/images/')
random.shuffle(files)
for f in files:
img = cv2.imread('./dataset/images/' + f)
parts = f.split('_')
label_name = './dataset/labels/' + 'W0002_' + parts[1]
label = cv2.imread(label_name,2)
img = cv2.resize(img,(w,h))
label = cv2.resize(label,(w,h))
images.append(img)
labels.append(label)
images = np.array(images)
labels = np.array(labels)
labels = np.reshape(labels,
(labels.shape[0],labels.shape[1],labels.shape[2],1))
print(images.shape)
print(labels.shape)
images = images/255
labels = labels/255
model = tf.keras.models.load_model('my_model')
#model = create_model() # uncomment this to create a new model
print(model.summary())
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=['accuracy'])
model.fit(images,labels,epochs=100,batch_size=10)
model.evaluate(images,labels)
model.save('my_model')O modelo é compilado com o otimizador Adam e, como existem apenas duas categorias de defeitos e nenhum defeito, usamos uma função de perda de entropia cruzada binária.
Usamos 100 épocas (o número de vezes que o modelo é executado em todas as entradas) com um tamanho de lote de 10.
Observe que o ajuste desses hiperparâmetros tem muito espaço para melhorar ainda mais o desempenho do modelo.
modelo de teste
Como o tamanho de entrada do modelo é 512x512x3, redimensionamos a entrada para esse tamanho. Em seguida, normalizamos a imagem e a dividimos por 255, o que torna o cálculo mais rápido.
Esta imagem é alimentada no modelo para prever a saída binária. Para amplificar a intensidade do pixel, a saída binária é multiplicada por 1000.
A imagem é então convertida em um inteiro de 16 bits para facilitar a manipulação da imagem. Os defeitos são então detectados com algoritmos que marcam visualmente a gravidade dos defeitos por gradação de cores e atribuindo pesos aos pixels defeituosos de acordo com sua gravidade. Os momentos da imagem são então calculados nesta imagem considerando os pixels ponderados.
Por fim, converta a imagem de volta para um inteiro de 8 bits e exiba o grau de cor e o valor de gravidade da imagem de saída.
import numpy as np
import cv2
from google.colab.patches import cv2_imshow
import os
import random
import tensorflow as tf
h,w = 512,512
num_cases = 10
images = []
labels = []
files = os.listdir('./dataset/images/')
random.shuffle(files)
model = tf.keras.models.load_model('my_model')
lowSevere = 1
midSevere = 2
highSevere = 4
for f in files[0:num_cases]:
test_img = cv2.imread('./dataset/images/' + f)
resized_img = cv2.resize(test_img,(w,h))
resized_img = resized_img/255
cropped_img = np.reshape(resized_img,
(1,resized_img.shape[0],resized_img.shape[1],resized_img.shape[2]))
test_out = model.predict(cropped_img)
test_out = test_out[0,:,:,0]*1000
test_out = np.clip(test_out,0,255)
resized_test_out = cv2.resize(test_out,(test_img.shape[1],test_img.shape[0]))
resized_test_out = resized_test_out.astype(np.uint16)
test_img = test_img.astype(np.uint16)
grey = cv2.cvtColor(test_img, cv2.COLOR_BGR2GRAY)
for i in range(test_img.shape[0]):
for j in range(test_img.shape[1]):
if(grey[i,j]>150 & resized_test_out[i,j]>40):
test_img[i,j,1]=test_img[i,j,1] + resized_test_out[i,j]
resized_test_out[i,j] = lowSevere
elif(grey[i,j]<100 & resized_test_out[i,j]>40):
test_img[i,j,2]=test_img[i,j,2] + resized_test_out[i,j]
resized_test_out[i,j] = highSevere
elif(resized_test_out[i,j]>40):
test_img[i,j,0]=test_img[i,j,0] + resized_test_out[i,j]
resized_test_out[i,j] = midSevere
else:
resized_test_out[i,j] = 0
M = cv2.moments(resized_test_out)
maxMomentArea = resized_test_out.shape[1]*resized_test_out.shape[0]*highSevere
print("0th Moment = " , (M["m00"]*100/maxMomentArea), "%")
test_img = np.clip(test_img,0,255)
test_img = test_img.astype(np.uint8)
cv2_imshow(test_img)
cv2.waitKey(0)7 resultados
A métrica visual que usamos para detectar a gravidade é a cor.
Na imagem, as cores:
Verde indica áreas com defeitos graves.
Azul representa áreas com defeitos mais graves.
As áreas vermelhas indicam os defeitos mais graves.
O momento de ordem 0 é exibido como uma porcentagem na imagem de saída como uma medida de gravidade empírica.
Abaixo estão três amostras aleatórias mostrando a entrada original, a verdade do terreno e a saída gerada pelo nosso modelo.
Amostra 1::

A imagem originária

Imagem binária (Ground Truth)

Saída de previsão com gravidade
Amostra 2:

A imagem originária

Imagem binária (Ground Truth)

Saída de previsão com gravidade
Amostra 3:

A imagem originária

Imagem binária (Ground Truth)

Este artigo é apenas para compartilhamento acadêmico, caso haja alguma infração, entre em contato para deletar o artigo.
Download e estudo de produtos secos
Resposta dos bastidores: Curso da Universidade Autônoma de Barcelona , você pode baixar o material didático de alta qualidade 3D Vison acumulado por universidades estrangeiras por vários anos
Resposta em segundo plano: livros de visão computacional , você pode baixar o pdf de livros clássicos no campo da visão 3D
Resposta dos bastidores: cursos de visão 3D, você pode aprender excelentes cursos na área de visão 3D
Cursos de qualidade visual 3D recomendados:
1. Tecnologia de fusão de dados multissensor para condução autônoma
2. Uma rota de aprendizado completa para detecção de alvos em nuvem de pontos 3D no campo da direção autônoma! (Single-modal + multi-modal/data + code)
3. Compreender completamente a reconstrução visual 3D: análise de princípio, explicação de código e otimização e melhoria
4. O primeiro curso doméstico de processamento de nuvem de pontos para combate em nível industrial
5. Visão a laser -IMU-GPS fusão algoritmo SLAM classificação
e
explicação
de código Princípio do algoritmo chave SLAM a laser interno e externo, código e combate real (cartógrafo + LOAM + LIO-SAM)
11. A implantação real de modelos de aprendizado profundo na condução autônoma
12. Modelo e calibração da câmera (monocular + binocular + olho de peixe)
13. Pesado! Quadcopters: Algoritmos e Prática
14. ROS2 da entrada ao domínio: teoria e prática
Pesado! Workshop de Visão Computacional - O Grupo de Intercâmbio de Aprendizagem foi estabelecido
Digitalize o código para adicionar um assistente do WeChat e você pode se inscrever para participar do grupo de intercâmbio 3D Vision Workshop - Academic Paper Writing and Submission WeChat, que visa trocar assuntos de redação e submissão, como principais conferências, principais periódicos, SCI e EI.
Ao mesmo tempo , você também pode se inscrever para participar do nosso grupo de troca de direção de subdivisão. Atualmente, há principalmente aprendizado de código-fonte da série ORB-SLAM, visão 3D , CV e aprendizado profundo , SLAM , reconstrução 3D , pós-processamento de nuvem de pontos , condução automática, introdução de CV, medição 3D, VR/AR, reconhecimento facial 3D, imagens médicas, detecção de defeitos, reidentificação de pedestres, rastreamento de alvos, aterrissagem visual de produtos, competição visual, reconhecimento de placas, seleção de hardware, estimativa de profundidade, intercâmbios acadêmicos , trocas de procura de emprego e outros grupos WeChat, por favor, digitalize a seguinte conta WeChat mais grupo, observações: "direção de pesquisa + escola/empresa + apelido", por exemplo: "visão 3D + Shanghai Jiaotong University + Jingjing". Por favor, observe de acordo com o formato, caso contrário não será aprovado. Depois que a adição for bem-sucedida, o grupo relevante do WeChat será convidado de acordo com a direção da pesquisa. Entre em contato para envios originais .

▲ Pressione e segure para adicionar o grupo WeChat ou contribuir

▲ Pressione e segure para seguir a conta oficial
Visão 3D da entrada ao planeta do conhecimento proficiente : cursos em vídeo para o campo da visão 3D (série de reconstrução 3D , série de nuvem de pontos 3D, série de luz estruturada , calibração olho-mão, calibração de câmera , laser/visão SLAM, condução automática, etc. ) , resumo dos pontos de conhecimento , rota de entrada e aprendizado avançado, o compartilhamento de papel mais recente e respostas a perguntas para cultivo aprofundado e orientação técnica de engenheiros de algoritmos de várias grandes fábricas. Ao mesmo tempo, a Planet cooperará com empresas conhecidas para liberar trabalhos de desenvolvimento de algoritmos relacionados à visão 3D e informações de encaixe de projetos, criando uma área de encontro para fãs obstinados que integra tecnologia e emprego. conhecimento para criar um mundo de IA melhor. Planet Entrance:
Aprenda a tecnologia principal da visão 3D, digitalize e visualize a introdução, reembolso incondicional em 3 dias

Existem materiais tutoriais de alta qualidade no círculo, que podem responder a perguntas e ajudá-lo a resolver problemas de forma eficiente
Eu acho útil, por favor dê um like e assista