Clique no cartão abaixo para seguir a conta pública " CVer "
Mercadorias secas pesadas AI/CV, entregues o mais rápido possível
Como um marco importante em 2021, o CLIP atraiu a atenção dos pesquisadores assim que foi lançado. Mas os 400 milhões de dados de imagem-texto e centenas de placas de GPU exigem que os pesquisadores se assustem.
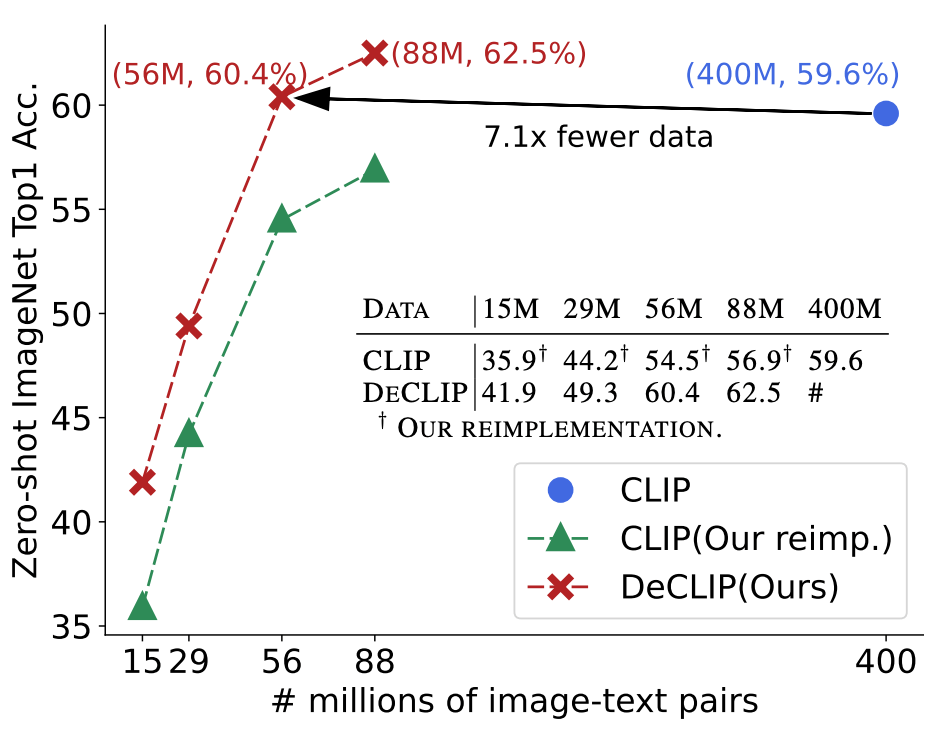
Para resolver o problema de eficiência de dados do treinamento CLIP, a SenseTime lançou o DeCLIP, que foi aceito pelo ICLR 2022. Seu DeCLIP-ResNet50 pode atingir 60,4% de precisão Zero-Shot no ImageNet enquanto usa 7,1 vezes menos dados que o CLIP , que é maior que o CLIP. O CLIP-ResNet50 é 0,8% maior! Além disso, com base no DeCLIP, é proposto um benchmark relacionado ao pré-treinamento do par imagem-texto, que integra os atuais CLIP, SLIP, FILIP e outros trabalhos relacionados. Os dados, códigos, modelos e scripts de treinamento relacionados do DeCLIP e do Benchmark agora são de código aberto, bem-vindo ao uso!
DeCLIP (ICLR 2022):
https://arxiv.org/abs/2110.05208
CLIP-Benchmark:
https://arxiv.org/abs/2203.05796
Código (código aberto): https://github.com/Sense-GVT/DeCLIP
1. Motivação
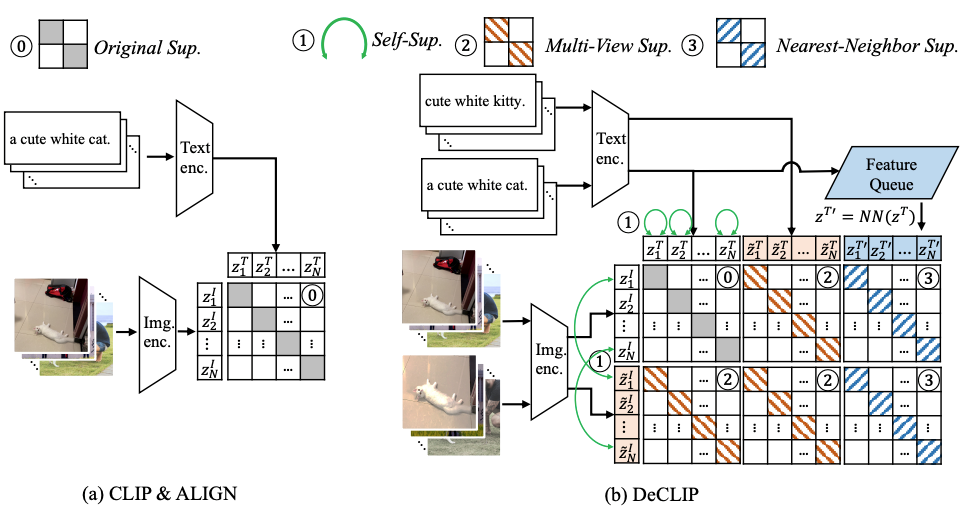
O pré-treinamento de aprendizado de contraste de imagem de linguagem em larga escala alcançou bons resultados em aprendizado zero e tarefas downstream (como CLIP). No entanto, modelos como CLIP requerem 400M de dados para pré-treinamento.A fim de melhorar a eficiência do treinamento e permitir que o modelo alcance bons resultados com menos dados de treinamento, este artigo propõe um eficiente paradigma multimodal de pré-treinamento DeCLIP . Ao contrário do CLIP, que usa apenas a correspondência de pares de texto e imagem como um sinal auto-supervisionado, o DeCLIP usa uma variedade de sinais de supervisão:
Aprendizagem auto-supervisionada dentro de uma modalidade;
Aprendizado supervisionado com várias visualizações em todas as modalidades;
Aprendizado supervisionado pelo vizinho mais próximo.
2. Método
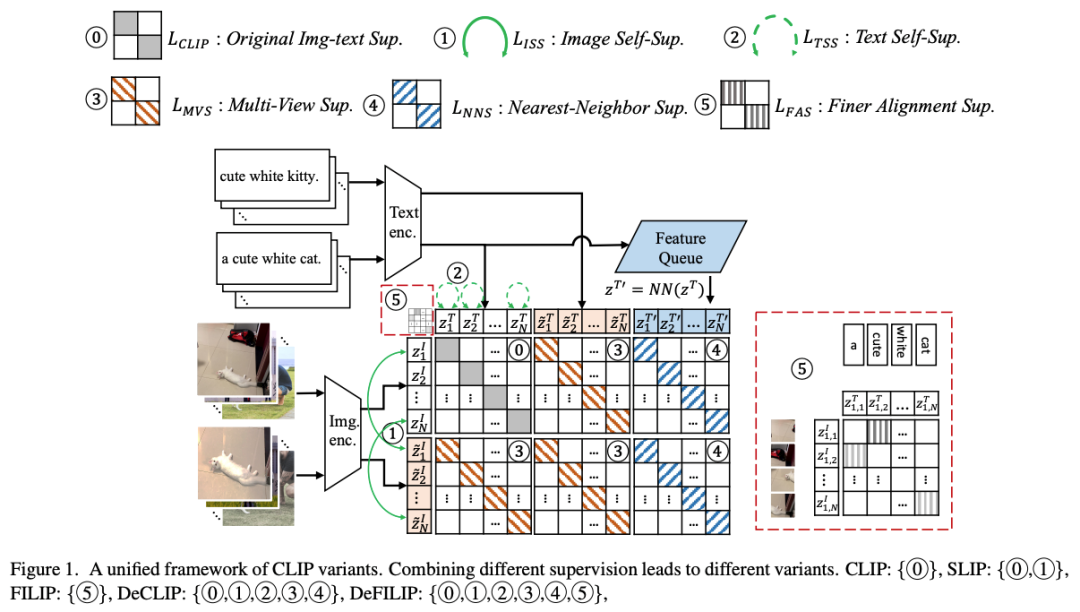
Conforme mostrado na figura abaixo, este artigo propõe um paradigma multimodal de pré-treinamento DeCLIP com maior eficiência de utilização de dados. Use mais informações de supervisão para obter um uso eficiente dos dados.
2.1 Revisão do CLIPE
Primeiro, vamos revisar o CLIP. O CLIP realiza diretamente o aprendizado comparativo entre pares de imagem e texto, usando dois codificadores para codificar informações de imagem e informações de texto, respectivamente. Codificadores de imagem geralmente usam CNN ou VIT, e codificadores de texto geralmente usam transformadores. Depois disso, os embeddings de texto e imagem são mapeados no mesmo espaço, e a ideia de aprendizado contrastivo é usada para encurtar a distância entre os embeddings de imagem-texto correspondentes e os embeddings de distância incomparáveis.
2.2 Auto-Supervisão dentro de cada modalidade (SS)
O aprendizado autossupervisionado é realizado separadamente em cada modalidade, incluindo o aprendizado autossupervisionado de imagens e o aprendizado autossupervisionado de texto.
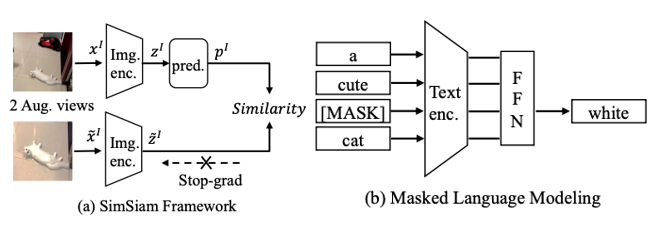
(a) Aprendizagem Auto-Supervisionada de Imagem
Aprendizagem auto-supervisionada em nível de imagem da maneira proposta pelo SimSiam. A imagem é aumentada por dois dados para obter duas visualizações, que são primeiro codificadas por um codificador de imagem com pesos compartilhados e, em seguida, uma das visualizações é aprimorada por um MLP de duas camadas e a semelhança de cosseno é calculada com a saída da outra e retorne o gradiente.
(b) Aprendizagem auto-supervisionada de texto
Aprendizagem auto-supervisionada de texto seguindo o método no BERT. Primeiro selecione aleatoriamente 15% dos tokens em cada sequência, depois substitua esse token (1) 80% de probabilidade por [máscara] (2) 10% de probabilidade por um token aleatório (3) 10% de probabilidade sem modificação. Finalmente, a saída do modelo de linguagem na posição correspondente é usada para prever o token original e otimizada usando uma perda de entropia cruzada.
2.3. Aprendizado de Supervisão Multi-Visualização Multimodal (Supervisão Multi-Visualização, MVS)
O CLIP original usa diretamente a incorporação de imagens e texto para calcular a perda de InfoNCE auto-supervisionada, enquanto o DeCLIP usa o texto e as imagens com aumento de dados para executar quatro vezes o InfoNCE, três vezes mais que o CLIP. Especificamente, para o par imagem-texto original 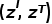 , o DeCLIP realiza aprimoramento de dados na imagem e aprimoramento de dados no
, o DeCLIP realiza aprimoramento de dados na imagem e aprimoramento de dados no 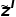 texto
texto 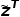 . A
. A 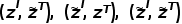 função de perda de InfoNCE calculada tem três supervisões a mais que o CLIP.
função de perda de InfoNCE calculada tem três supervisões a mais que o CLIP.
2.4. Supervisão do Vizinho Mais Próximo (NNS)
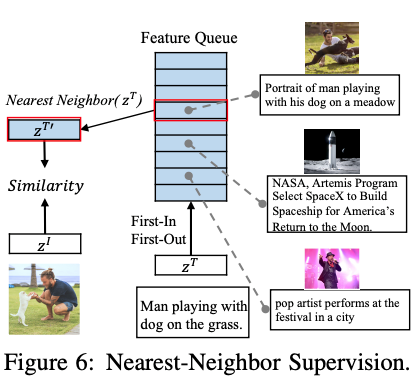
Como as mesmas imagens podem ter descrições de idioma semelhantes, os pares imagem-texto com descrições de idioma semelhantes são selecionados para aprendizado comparativo. Toda a distribuição de dados é simulada mantendo uma fila first-in, first-out (FIFO), selecionando as sentenças mais semelhantes dessa fila como amostras positivas e 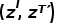 usando a função de perda InfoNCE como a função de perda do vizinho mais próximo entre as seleções.
usando a função de perda InfoNCE como a função de perda do vizinho mais próximo entre as seleções.
Por fim, as três perdas são ponderadas e somadas para se obter a perda final.
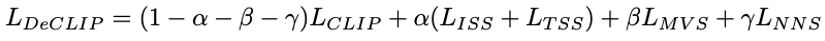
3. Experimentos
3.1. Conjuntos de dados
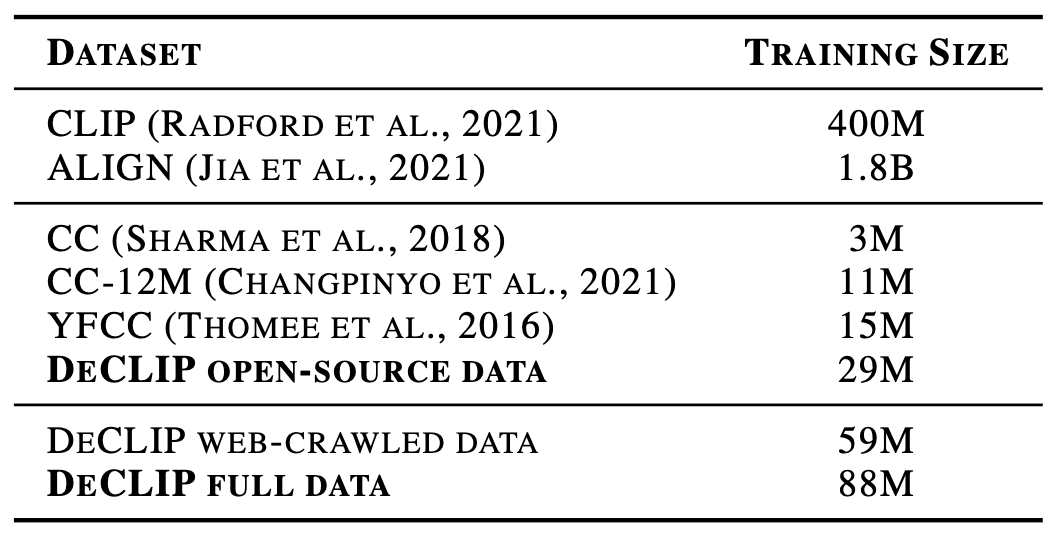
O conjunto de dados DeCLIP contém 29 milhões de código aberto existente e 59 milhões de rastreamento da Internet, um total de 88 milhões de dados.
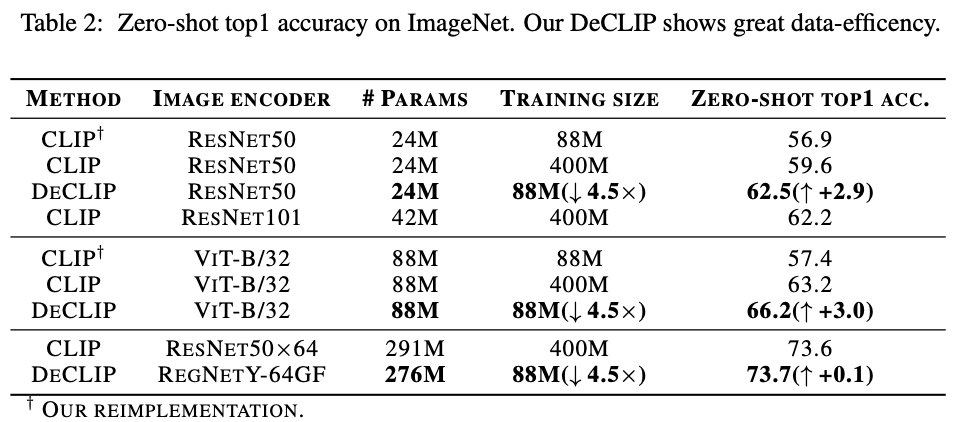
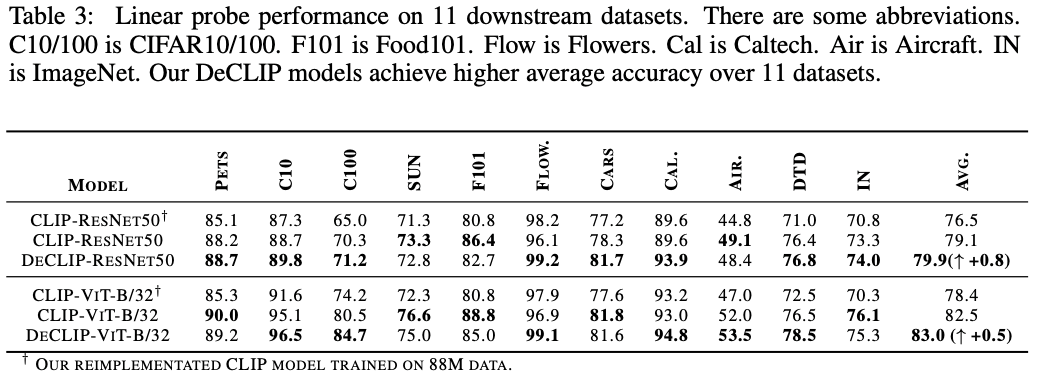
3.2. Precisão de Tiro Zero e Ajuste Fino
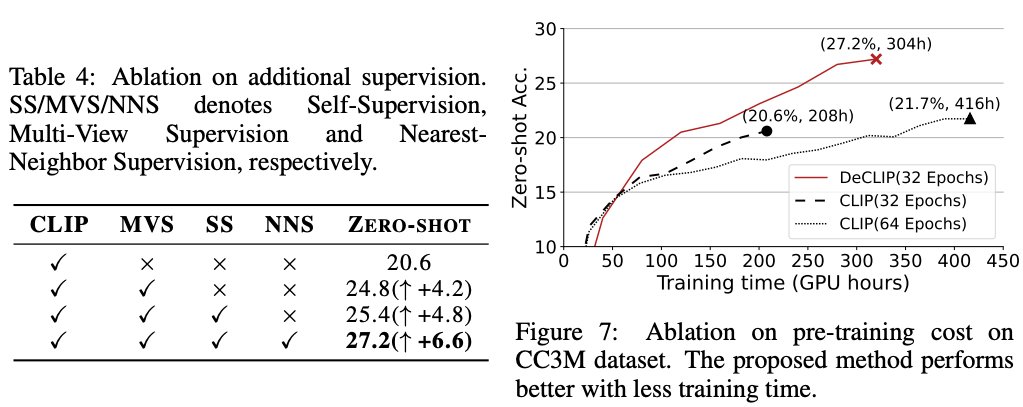
3.3. O efeito de três tipos de supervisão e a comparação da velocidade de treinamento
4. CLIP-Benchmark
Atualmente, os dados e hiperparâmetros baseados nos artigos relacionados da série CLIP são diferentes. Para facilitar o uso da comunidade, este artigo propõe o CLIP-Benchmark com base no DeCLIP, que inclui o YFCC15M-V2 de alta qualidade conjunto de dados e o Documento relacionado existente.Código reproduzido e comparação de resultados (CLIP, SLIP, FILIP, DeCLIP) e um método de treinamento de conjunto DeFILIP. O método específico e o efeito são mostrados na figura a seguir.
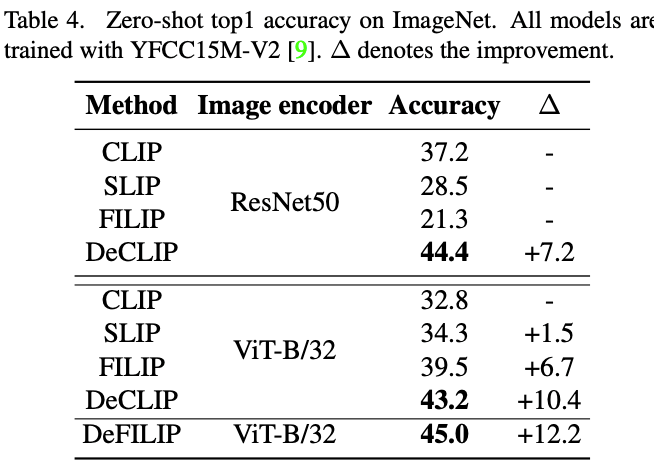
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看