contente
Preparação do ambiente de simulação
Visão geral
A otimização de desempenho sempre foi o foco da otimização de serviços de back-end , mas as falhas de desempenho online não ocorrem com frequência, ou são limitadas por produtos de negócios, não há como ter problemas de desempenho, incluindo o próprio autor. Não há muitos problemas de desempenho , portanto, para reservar conhecimento com antecedência, e você não terá pressa quando surgirem problemas. Neste artigo, simularemos várias falhas comuns de desempenho Java para aprender a analisá-las e localizá -las .
Olá a todos, deixe-me apresentar-me primeiro. Estou no código. Você pode me chamar de irmão Code. Eu também sou o aluno mais comum que se formou em um curso de graduação comum. Acredito que a maioria dos programadores ou aqueles que querem trabalhar em a indústria de programadores sou filho de uma família comum, então também confio em meus próprios esforços, desde a graduação para ingressar em uma empresa tradicional, até a mudança de emprego sem falhas, e agora trabalhando em uma empresa gigante na indústria da Internet, espero que através do meu compartilhamento, eu possa ajudar a todos
Preparei 16 colunas técnicas para que todos levem você a aprender juntos
"Combate de sistema distribuído de tráfego de nível de bilhões"
"Battery Factory Interview Must-Ask Series"
"Zero Foundation leva você a aprender a coluna de tutorial java"
"Leve você para aprender a coluna springCloud"
"Leve você para aprender a coluna de código-fonte SpringCloud"
"Leve você para aprender a coluna do sistema distribuído"
"Leve você para aprender coluna nativa da nuvem"
"Leve você para aprender o código-fonte do springboot"
"Leve você para aprender princípios netty e coluna prática"
"Leve você para aprender a coluna Elasticsearch"
"Leve você para aprender a coluna mysql"
"Leve você para aprender a coluna de princípios da JVM"
"Leve você para aprender a coluna de princípios do Redis"
Conhecimento preliminar
Por se tratar de um problema de posicionamento, definitivamente é necessário o uso de ferramentas, primeiro vamos entender quais ferramentas são necessárias para ajudar a localizar o problema.
comando superior
topO comando é um dos comandos mais usados no Linux. Ele pode exibir informações do sistema, como uso de CPU e uso de memória do processo em execução em tempo real. top -Hp pid Você pode visualizar o uso de recursos do sistema de um encadeamento.
comando vmstat
vmstat é uma ferramenta de detecção de memória virtual que especifica os tempos de ciclo e coleta, pode contar o uso de memória, CPU e swap, além de ter uma importante função comum para observar a mudança de contexto do processo. As descrições dos campos são as seguintes:
-
r: O número de processos na fila de execução (quando o número é maior que o número de núcleos de CPU, há threads bloqueados)
-
b: o número de processos aguardando IO
-
swpd: usa o tamanho da memória virtual
-
livre: tamanho de memória física livre
-
buff: O tamanho da memória usada para buffer (buffers de memória e disco rígido)
-
cache: tamanho da memória usada como cache (buffer entre CPU e memória)
-
si: O tamanho escrito da área de troca para a memória por segundo, transferido do disco para a memória
-
então: O tamanho da memória gravada na área de troca por segundo, transferido da memória para o disco
-
bi: número de blocos lidos por segundo
-
bo: blocos escritos por segundo
-
in: Interrupções por segundo, incluindo interrupções do relógio.
-
cs: Trocas de contexto por segundo.
-
us: porcentagem do tempo de execução do processo do usuário (tempo do usuário)
-
sy: Porcentagem do tempo de execução do processo do sistema do kernel (tempo do sistema)
-
wa: porcentagem de tempo de espera de E/S
-
id: porcentagem de tempo ocioso
comando pidstat
O pidstat é um componente do Sysstat e também é uma poderosa ferramenta de monitoramento de desempenho, top e vmstat ambos os comandos monitoram o uso de memória, CPU e E/S do processo, e o comando pidstat pode detectar o nível de thread. pidstatOs campos de troca de thread de comando são descritos a seguir:
-
UID : O ID do usuário real da tarefa monitorada.
-
TGID: ID do grupo de threads.
-
TID: ID da linha.
-
cswch/s: O número de vezes de alternância de contexto ativa, aqui é a alternância de threads devido ao bloqueio de recursos, como espera de bloqueio e assim por diante.
-
nvcswch/s: O número de comutação de contexto passiva, aqui se refere aos threads de comutação de agendamento da CPU.
comando jstack
jstack é um comando de ferramenta JDK. É uma ferramenta de análise de pilha de encadeamentos. A função mais comumente usada é usar o jstack pid comando para visualizar as informações de pilha do encadeamento, e é frequentemente usado para eliminar deadlocks.
comando jstat
Ele pode detectar a operação em tempo real de programas Java, incluindo informações de memória heap e informações de coleta de lixo, e geralmente o usamos para visualizar a coleta de lixo do programa. Os comandos comumente usados são jstat -gc pid. Os campos de informações são descritos a seguir:
-
SOC: A capacidade do To Survivor na geração jovem (em KB);
-
S1C: A capacidade do From Survivor na geração jovem (unidade: KB);
-
S0U: O espaço atualmente usado por To Survivor na geração jovem (unidade: KB);
-
S1U: O espaço atualmente usado pelo From Survivor na geração jovem (unidade: KB);
-
EC: A capacidade do Éden na geração jovem (em KB);
-
UE: O espaço atualmente utilizado pelo Eden na geração jovem (em KB);
-
OC: a capacidade da velhice (em KB);
-
OU: O espaço atualmente utilizado na velhice (unidade: KB);
-
MC: a capacidade do metaespaço (em KB);
-
MU: O espaço atualmente usado do metaespaço (unidade: KB);
-
YGC: O número de gcs na geração jovem desde a inicialização do aplicativo até a amostragem;
-
YGCT: O(s) tempo(s) utilizado(s) pelo gc na geração jovem desde a inicialização do aplicativo até o tempo de amostragem;
-
FGC: O número de gcs na velhice (Full Gc) desde a inicialização do aplicativo até o tempo de amostragem;
-
FGCT: O(s) tempo(s) desde a inicialização do aplicativo até o gc de geração antiga (Full Gc) durante a amostragem;
-
GCT: O(s) tempo(s) total(is) gasto(s) pelo gc desde a inicialização do aplicativo até a amostragem.
comando jmap
jmap também é um comando de ferramenta JDK que pode visualizar as informações de inicialização da memória heap e o uso da memória heap, e também pode gerar um arquivo de despejo para análise detalhada. Exibir comando de status da memória heap jmap -heap pid.
ferramenta de memória mat
A ferramenta MAT (Memory Analyzer Tool) é um plug-in do eclipse (o MAT também pode ser usado sozinho), ao analisar o arquivo dump com memória grande, você pode ver intuitivamente o tamanho da memória e o número de instâncias de classe ocupadas por cada objeto no espaço de heap, relacionamento de referência de objeto, use consulta de objeto OQL e pode descobrir facilmente as informações relevantes do objeto GC Roots.
Existe também uma ideia de plug-in, que é o JProfiler .
Leitura relacionada: "Início rápido e práticas recomendadas para a ferramenta de diagnóstico de desempenho JProfiler"
Preparação do ambiente de simulação
O ambiente básico jdk1.8, usando o framework SpringBoot para escrever várias interfaces para acionar a cena de simulação, a primeira é simular a situação completa da CPU
CPU está cheia
É relativamente simples simular a CPU cheia, basta escrever um cálculo de loop infinito para consumir a CPU.
/**
* 模拟CPU占满
*/
@GetMapping("/cpu/loop")
public void testCPULoop() throws InterruptedException {
System.out.println("请求cpu死循环");
Thread.currentThread().setName("loop-thread-cpu");
int num = 0;
while (true) {
num++;
if (num == Integer.MAX_VALUE) {
System.out.println("reset");
}
num = 0;
}
}Copiar para a área de transferênciaErrorCopiedSolicite o teste de endereço de interface curl localhost:8080/cpu/loope descubra que a CPU sobe imediatamente para 100%
 Em
Em
top -Hp 32805 Visualize a situação do thread Java executando
 Em
Em
Execute printf '%x' 32826 para obter o id do thread em hexadecimal para dumpconsulta de informações e o resultado é 803a. Por fim, executamos jstack 32805 |grep -A 20 803apara visualizar as dumpinformações detalhadas.
 Em
Em
As dumpinformações aqui localizam diretamente o método do problema e a linha de código, que localiza o problema de CPU cheia.
vazamento de memória
A simulação de vazamentos de memória é realizada com a ajuda de objetos ThreadLocal. ThreadLocal é uma variável privada de thread que pode ser vinculada a uma thread e existe durante todo o ciclo de vida da thread. No entanto, devido à particularidade de ThreadLocal, ThreadLocal é implementado com base em ThreadLocalMap e a entrada de ThreadLocalMap herdam WeakReference, e a chave de entrada é o encapsulamento de WeakReference. Em outras palavras, a chave é uma referência fraca e a referência fraca será reciclada após o próximo GC. operações após o conjunto, porque o GC limpará a chave, no entanto, como o encadeamento ainda está ativo, o valor nunca será reciclado e, eventualmente, ocorrerá um vazamento de memória.
/**
* 模拟内存泄漏
*/
@GetMapping(value = "/memory/leak")
public String leak() {
System.out.println("模拟内存泄漏");
ThreadLocal<Byte[]> localVariable = new ThreadLocal<Byte[]>();
localVariable.set(new Byte[4096 * 1024]);// 为线程添加变量
return "ok";
}Copiar para a área de transferênciaErrorCopiedAdicionamos um limite de tamanho de memória heap à inicialização e definimos um instantâneo de pilha e registramos a saída quando a memória estoura.
java -jar -Xms500m -Xmx500m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heaplog.log analysis-demo-0.0.1-SNAPSHOT.jarCopiar para a área de transferênciaErrorCopiedApós a inicialização ser bem-sucedida, executamos o ciclo 100 vezes for i in {1..500}; do curl localhost:8080/memory/leak;donee o sistema retornou 500 erros antes que a execução fosse concluída. Ocorreu a seguinte exceção ao visualizar o log do sistema:
java.lang.OutOfMemoryError: Java heap spaceCopiar para a área de transferênciaErrorCopiedUsamos o jstat -gc pid comando para ver a situação do GC do programa.
 Em
Em
Obviamente, a memória estourou e a memória heap não liberou a memória disponível após 45 Gcs completos, o que significa que os objetos na memória heap atual estão todos vivos, referenciados por GC Roots e não podem ser reciclados. Qual é o motivo do estouro de memória? Devo apenas aumentar a memória? Se for um estouro de memória comum, pode ser suficiente expandir a memória, mas se for um vazamento de memória, a memória expandida ficará cheia em pouco tempo, portanto, também precisamos determinar se é um vazamento de memória. Salvamos o arquivo de despejo de heap antes e, desta vez, usamos nossa ferramenta MAT para analisá-lo. Importe a seleção Leak Suspects Reportde ferramentas e a ferramenta listará diretamente o relatório de problemas para você.
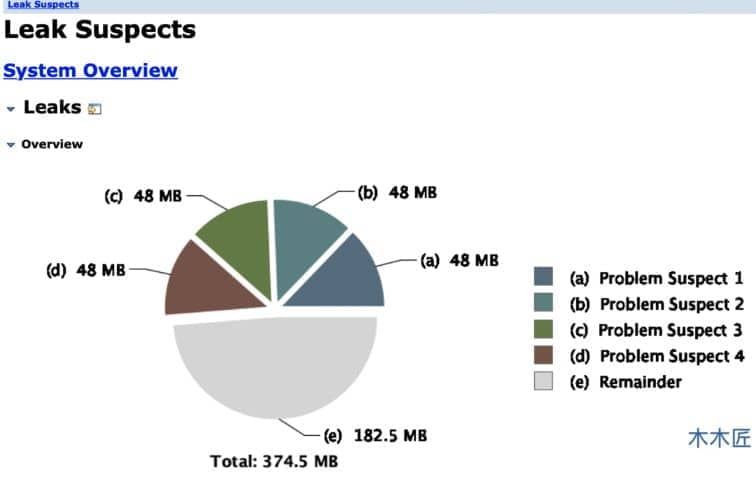 Em
Em
Existem 4 vazamentos de memória suspeitos listados aqui, clicamos em um deles para ver os detalhes.
 Em
Em
Foi apontado aqui que a memória está quase 50M ocupada pela thread, e o objeto ocupado é ThreadLocal. Se você quiser analisá-lo manualmente em detalhes, clique Histogrampara ver quem está ocupando o maior objeto e, em seguida, analise sua relação de referência para determinar quem causou o estouro de memória.
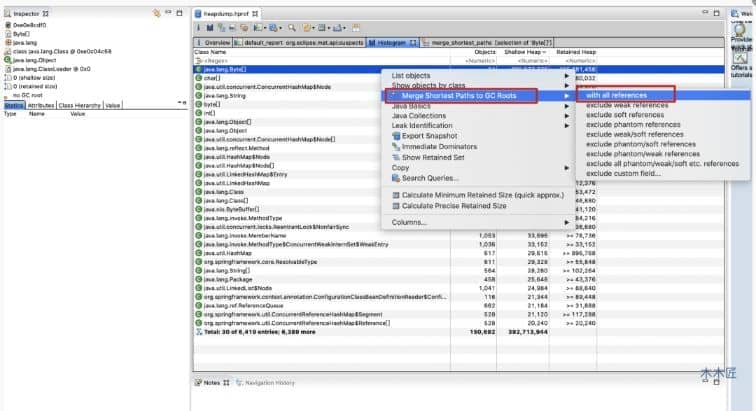 Em
Em
A figura acima mostra que o objeto que ocupa a maior memória é um array Byte, vejamos se ele é referenciado pelo GC Root e não foi reciclado. De acordo com o guia de operação na caixa vermelha acima, o resultado é o seguinte:
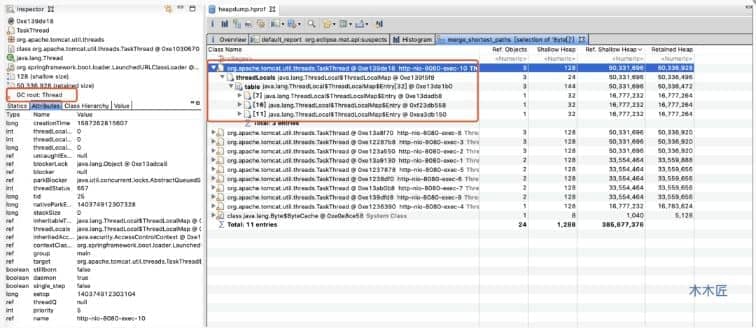 Em
Em
Descobrimos que o array Byte é referenciado pelo objeto thread. Também está indicado na figura que a Raiz GC do objeto array Byte é um thread, portanto não será reciclado. Expanda as informações detalhadas para ver que a memória final objeto ocupado é ThreadLocal. objeto ocupado. Isso também é consistente com os resultados que a ferramenta MAT analisa automaticamente para nós.
impasse
O deadlock levará ao esgotamento dos recursos da thread e ocupará a memória. O desempenho é que o uso da memória aumenta, e a CPU não necessariamente aumentará (dependendo do cenário). Se for uma nova thread direta, fará com que a memória da JVM ser esgotado e relatar o erro de que o encadeamento não pode ser criado. , o que também reflete os benefícios de usar pools de encadeamentos.
ExecutorService service = new ThreadPoolExecutor(4, 10,
0, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1024),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
/**
* 模拟死锁
*/
@GetMapping("/cpu/test")
public String testCPU() throws InterruptedException {
System.out.println("请求cpu");
Object lock1 = new Object();
Object lock2 = new Object();
service.submit(new DeadLockThread(lock1, lock2), "deadLookThread-" + new Random().nextInt());
service.submit(new DeadLockThread(lock2, lock1), "deadLookThread-" + new Random().nextInt());
return "ok";
}
public class DeadLockThread implements Runnable {
private Object lock1;
private Object lock2;
public DeadLockThread1(Object lock1, Object lock2) {
this.lock1 = lock1;
this.lock2 = lock2;
}
@Override
public void run() {
synchronized (lock2) {
System.out.println(Thread.currentThread().getName()+"get lock2 and wait lock1");
try {
TimeUnit.MILLISECONDS.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
System.out.println(Thread.currentThread().getName()+"get lock1 and lock2 ");
}
}
}
}Copiar para a área de transferênciaErrorCopiedSolicitamos ciclicamente a interface 2.000 vezes e descobrimos que ocorreu um erro de log no sistema depois de um tempo e o pool de threads e a fila estavam cheios. Como escolhi a estratégia de rejeitar quando a fila está cheia, o sistema lança uma exceção diretamente .
java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@2760298 rejected from java.util.concurrent.ThreadPoolExecutor@7ea7cd51[Running, pool size = 10, active threads = 10, queued tasks = 1024, completed tasks = 846]Copiar para a área de transferênciaErrorCopiedps -ef|grep javaEncontre o pid do processo Java através do comando, e execute jstack pid as informações da pilha de threads Java. Existem 5 deadlocks encontrados aqui. Listamos apenas um deles. Obviamente, o thread pool-1-thread-2bloqueia o bloqueio de 0x00000000f8387d88espera 0x00000000f8387d98e o thread pool-1-thread-1bloqueia o 0x00000000f8387d98bloqueio de espera 0x00000000f8387d88. Ocorreu um impasse.
Java stack information for the threads listed above:
===================================================
"pool-1-thread-2":
at top.luozhou.analysisdemo.controller.DeadLockThread2.run(DeadLockThread.java:30)
- waiting to lock <0x00000000f8387d98> (a java.lang.Object)
- locked <0x00000000f8387d88> (a java.lang.Object)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"pool-1-thread-1":
at top.luozhou.analysisdemo.controller.DeadLockThread1.run(DeadLockThread.java:30)
- waiting to lock <0x00000000f8387d88> (a java.lang.Object)
- locked <0x00000000f8387d98> (a java.lang.Object)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Found 5 deadlocks.Copiar para a área de transferênciaErrorCopiedTroca frequente de thread
A alternância de contexto faz com que muito tempo de CPU seja desperdiçado ao salvar e restaurar registros, pilhas de kernel e memória virtual, resultando em degradação geral do desempenho do sistema. Ao notar uma queda significativa no desempenho do sistema, considere se ocorreu um grande número de trocas de contexto de thread.
@GetMapping(value = "/thread/swap")
public String theadSwap(int num) {
System.out.println("模拟线程切换");
for (int i = 0; i < num; i++) {
new Thread(new ThreadSwap1(new AtomicInteger(0)),"thread-swap"+i).start();
}
return "ok";
}
public class ThreadSwap1 implements Runnable {
private AtomicInteger integer;
public ThreadSwap1(AtomicInteger integer) {
this.integer = integer;
}
@Override
public void run() {
while (true) {
integer.addAndGet(1);
Thread.yield(); //让出CPU资源
}
}
}Copiar para a área de transferênciaErrorCopiedAqui eu crio vários threads para realizar a operação básica atômica +1 e, em seguida, desisto dos recursos da CPU. Em teoria, a CPU agendará outros threads. Solicitamos que a interface crie 100 threads para ver como funciona curl localhost:8080/thread/swap?num=100. Após a solicitação da interface ser bem-sucedida, nós a executamos vmstat 1 10, o que significa que ela é impressa a cada 1 segundo, 10 vezes, e os resultados da coleta de troca de thread são os seguintes:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
101 0 128000 878384 908 468684 0 0 0 0 4071 8110498 14 86 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4065 8312463 15 85 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4107 8207718 14 87 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4083 8410174 14 86 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4083 8264377 14 86 0 0 0
100 0 128000 878384 908 468688 0 0 0 108 4182 8346826 14 86 0 0 0Copiar para a área de transferênciaErrorCopiedAqui nos concentramos em 4 indicadores, r, cs, us, sy.
r=100 , indicando que o número de processos em espera é 100 e o encadeamento está bloqueado.
cs=mais de 8 milhões , indicando que há mais de 8 milhões de alternâncias de contexto por segundo, o que é um número bastante grande.
us=14 , indicando que o modo de usuário ocupa 14% da fatia de tempo da CPU para processar a lógica.
sy=86 , indicando que o estado do kernel ocupa 86% da CPU, o que obviamente está fazendo a troca de contexto.
Através do topcomando e top -Hp pidverificando a situação da CPU do processo e da thread, descobrimos que a CPU do processo Java está cheia, mas o uso da CPU da thread é muito médio, e não há situação em que uma thread esteja cheia da CPU.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
87093 root 20 0 4194788 299056 13252 S 399.7 16.1 65:34.67 javaCopiar para a área de transferênciaErrorCopied PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
87189 root 20 0 4194788 299056 13252 R 4.7 16.1 0:41.11 java
87129 root 20 0 4194788 299056 13252 R 4.3 16.1 0:41.14 java
87130 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.51 java
87133 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.59 java
87134 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.95 javaCopiar para a área de transferênciaErrorCopiedCombinado com o acima, a CPU do modo de usuário usa apenas 14% e a CPU do modo kernel ocupa 86% Pode-se basicamente julgar que a troca de contexto de thread do programa Java causa problemas de desempenho.
Usamos o pidstatcomando para ver os dados de troca de thread dentro do processo Java, executar pidstat -p 87093 -w 1 10e coletar os dados da seguinte forma:
11:04:30 PM UID TGID TID cswch/s nvcswch/s Command
11:04:30 PM 0 - 87128 0.00 16.07 |__java
11:04:30 PM 0 - 87129 0.00 15.60 |__java
11:04:30 PM 0 - 87130 0.00 15.54 |__java
11:04:30 PM 0 - 87131 0.00 15.60 |__java
11:04:30 PM 0 - 87132 0.00 15.43 |__java
11:04:30 PM 0 - 87133 0.00 16.02 |__java
11:04:30 PM 0 - 87134 0.00 15.66 |__java
11:04:30 PM 0 - 87135 0.00 15.23 |__java
11:04:30 PM 0 - 87136 0.00 15.33 |__java
11:04:30 PM 0 - 87137 0.00 16.04 |__javaCopiar para a área de transferênciaErrorCopiedDe acordo com as informações coletadas acima, sabemos que as threads Java alternam cerca de 15 vezes por segundo. Em circunstâncias normais, deve ser um único dígito ou um decimal. Combinando essas informações, podemos concluir que muitos threads Java são abertos, resultando em trocas frequentes de contexto, o que afeta o desempenho geral.
Por que a troca de contexto do sistema é superior a 8 milhões por segundo, enquanto uma certa troca de thread no processo Java é apenas cerca de 15 vezes?
A comutação de contexto do sistema é dividida em três situações:
1. Multitarefa: Em um ambiente multitarefa, um processo é trocado da CPU para executar outro processo, e a troca de contexto ocorre aqui.
2. Interromper o processamento: Quando ocorre uma interrupção, o hardware muda o contexto. no comando vmstat éin
3. Comutação de modo de usuário e kernel: Quando o sistema operacional precisa alternar entre o modo de usuário e o modo de kernel, a alternância de contexto é necessária, como chamadas de função do sistema.
O Linux mantém uma fila de prontos para cada CPU, ordena os processos ativos de acordo com a prioridade e o tempo de espera da CPU, e então seleciona o processo que mais precisa de CPU, ou seja, o processo com maior prioridade e maior tempo de espera para execução da CPU . Ou seja, no comando vmstat r.
Então, quando o processo será agendado para ser executado na CPU?
- Após o processo ser executado e finalizado, a CPU que ele usava antes será liberada, e então um novo processo será retirado da fila de prontos para execução
- Para garantir que todos os processos possam ser agendados de forma justa, o tempo de CPU é dividido em fatias de tempo, que são alocadas para cada processo por vez. Quando uma fatia de tempo de processo se esgota, ela é suspensa pelo sistema e alterna para outros processos aguardando a execução da CPU.
- Quando os recursos do sistema forem insuficientes, o processo só poderá ser executado após a satisfação dos recursos, neste momento o processo também será suspenso e o sistema agendará a execução de outros processos.
- Quando o processo é suspenso ativamente por meio da função sleep, ele também é reprogramado.
- Quando um processo com maior prioridade estiver em execução, para garantir a execução do processo de alta prioridade, o processo atual será suspenso e executado pelo processo de alta prioridade.
- Quando ocorre uma interrupção de hardware, o processo na CPU será suspenso pela interrupção e, em vez disso, executará a rotina de serviço de interrupção no kernel.
Combinado com nossa análise de conteúdo anterior, a fila de prontos bloqueados é de cerca de 100, e nossa CPU possui apenas 4 núcleos, a mudança de contexto causada por essa parte do motivo pode ser bastante alta, além do número de interrupções ser de cerca de 4.000 e chamadas de funções do sistema , etc. , não é surpreendente que a mudança de contexto de todo o sistema seja de 8 milhões. A troca de threads dentro do Java é de apenas 15 vezes, pois a thread é usada Thread.yield()para abrir mão de recursos da CPU, mas a CPU pode continuar agendando a thread. comutação não é muito alto.grande motivo.
Resumir
Este artigo simula cenários comuns de problemas de desempenho e analisa como localizar CPU100%, vazamentos de memória, deadlocks e problemas frequentes de troca de thread. Para analisar problemas, precisamos fazer duas coisas bem, primeiro, dominar os princípios básicos e, segundo, usar boas ferramentas. Este artigo também lista ferramentas e comandos comuns para analisar problemas, esperando ajudá-lo a resolver problemas. Claro, o ambiente online real pode ser muito complexo, não tão simples quanto o ambiente simulado, mas o princípio é o mesmo e o desempenho do problema é semelhante. acredito que problemas on-line complexos também podem ser resolvidos sem problemas.
Todos devem se lembrar de curtir, se inscrever e seguir
Impedir que seja encontrado na próxima vez
Seu apoio é a força motriz para eu continuar a criar! ! !