fundo
Recentemente, estou me preparando para lançar o produto Cassandra, e meus colegas estão fazendo alguns testes de pressão ECS (8G) de tamanho pequeno. É mais fácil acionar o OOM Killer durante o teste de estresse para matar o processo do Cassandra . O problema é que o heap (Xmx) que configurei para a especificação 8G não é alto (cerca de 6,5g) e deixou espaço suficiente para o sistema. Somente se o uso de memória fora do heap Java exceder as expectativas, levando a um aumento em RES, o OOM pode ser acionado.
Processo de investigação
0. Suspeita-se inicialmente que há um vazamento de DirectBuffer ou um problema com a biblioteca JNI.
1. Rastreando a sobrecarga de memória fora do heap por meio do Google Perftools, como de costume, mas nenhuma exceção óbvia foi encontrada.
2. Então eu olhei para ele com o Java NMT e não encontrei nada de anormal.
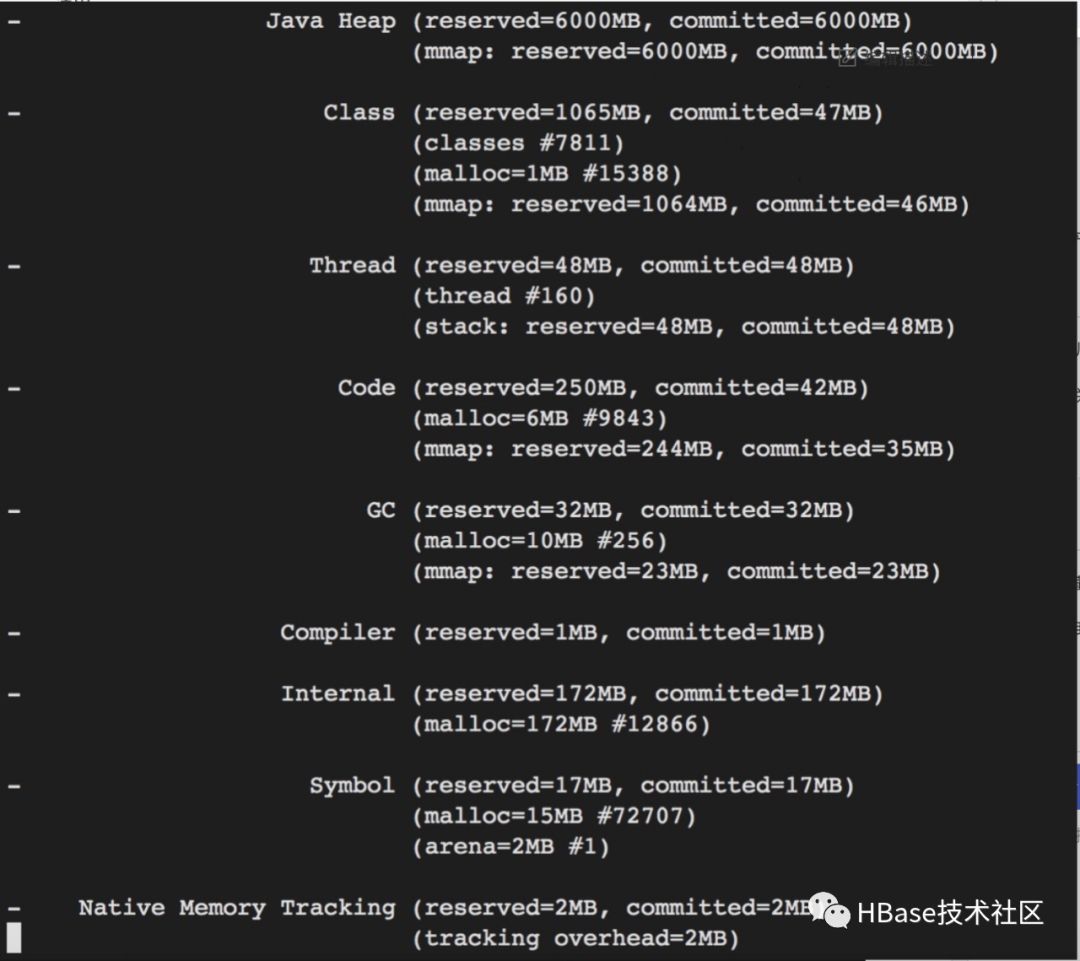
3. A ideia parece ter sido quebrada quando encontrada aqui, pois parece não ter nada a ver com DirectBuffer. Nesse momento, notei que a memória virtual do processo está muito alta, ultrapassando a memória do ECS. Eu suspeito que há algo errado aqui.

4. Verifique a distribuição do espaço de endereço da memória do processo por meio de / proc / pid / smaps e descubra que há um grande número de arquivos mmap. Esses arquivos são arquivos de dados do Cassandra
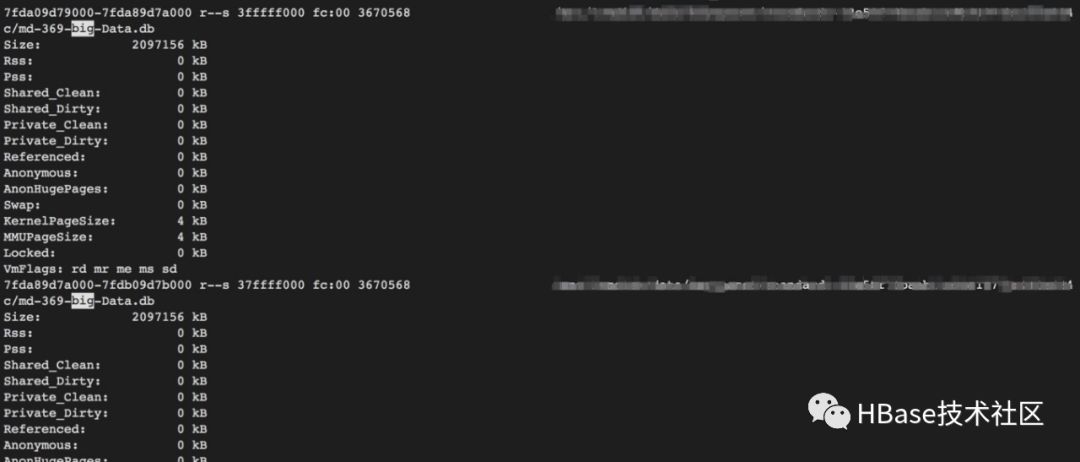
Neste momento, a memória virtual desses arquivos mmap é 2G, mas a memória física é 0 (porque eu reiniciei antes e diminuí a memória para evitar que o processo travasse e afetasse a solução de problemas).
Obviamente, a sobrecarga de memória do mmap não é controlada pelo heap da JVM, ou seja, memória fora do heap. Se os dados do arquivo mmap são carregados do disco para a memória física (aumento de RES), o Java NMT e o Google Perftool não podem percebê-los. Este é o processo de agendamento do kernel.
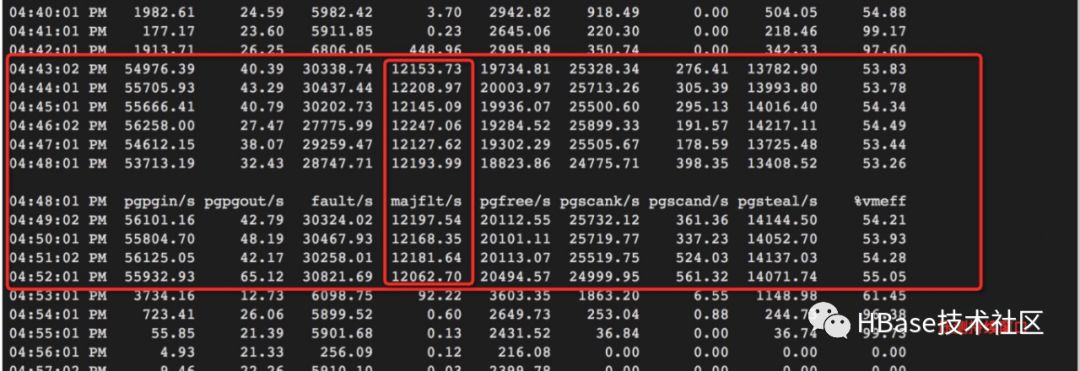
5. Considerando que o problema ocorreu durante o teste de estresse, só preciso ler esses documentos e observar se o RES vai aumentar, quanto e porque aumenta, para poder inferir se o problema está aqui. Use o seguinte comando para simplesmente ler os dados importados anteriormente.
cassandra-stress read duration=10m cl=ONE -rate threads=20 -mode native cql3 user=cassandra password=123 -schema keysp
ace=keyspace5 -node core-36. Pode-se observar que durante o período de teste de estresse (sar -B), a falha de página principal é significativamente aumentada porque os dados são realmente carregados do disco para a memória
Ao mesmo tempo, observou-se que a memória física do arquivo mmap aumentou para 20 MB
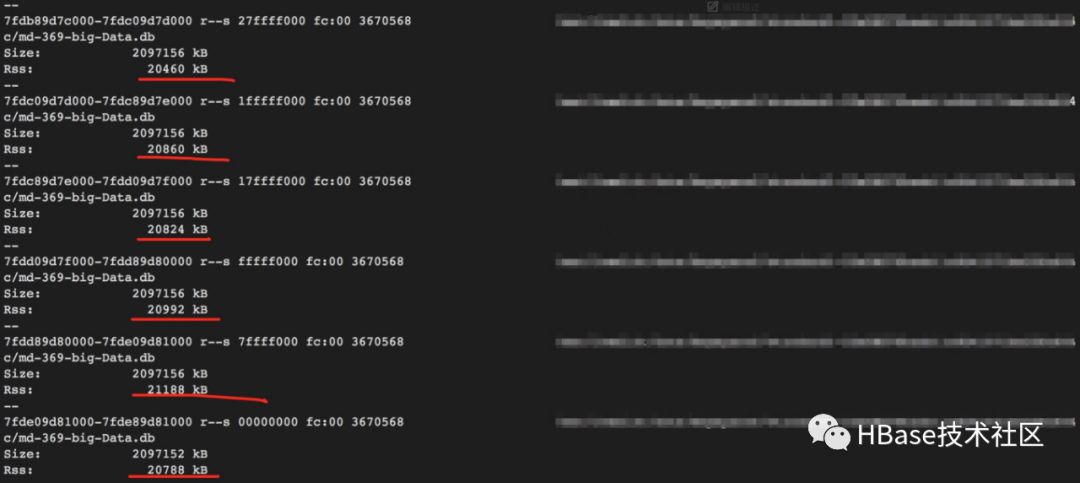
O RES do processo final subiu para cerca de 7,1g, um aumento de cerca de 600M

Se você aumentar a pressão (50 threads), ela aumentará e a memória física de cada arquivo mmap aumentará de 20 MB para 40 MB
7. A causa raiz é se o Cassandra reconhece se o sistema é 64 ou 32 para determinar se deve usar mmap ou não.O ECS é 64, mas na verdade não há muitas memórias ECS pequenas.
Em conclusão
1. A causa do problema é que a sobrecarga de mmap para memória não é levada em consideração e há muitos métodos de ajuste específicos. Você pode reduzir a configuração de heap ou desabilitar o recurso mmap (disk_access_mode = standard) para ECS de tamanho pequeno.
2. Ainda é problemático solucionar problemas de memória off-heap Java. Recomenda-se usar NMT para verificar primeiro, é relativamente simples para usar, basta configurar os parâmetros JVM, você pode ver o status do aplicativo de memória.
