1Como o ACID funciona no mecanismo MySQL InnoDB?
** 1 (Atomicidade) Atomicidade **: Uma transação é a menor unidade de execução e a divisão não é permitida. A atomicidade garante que as ações sejam todas concluídas ou completamente ineficazes;
2 (consistência) consistência : antes e depois da transação ser executada, os dados permanecem consistentes;
3 (isolamento) isolamento : ao acessar simultaneamente o banco de dados, uma transação não sofre interferência outras transações.
4 (Durabilidade) durabilidade : após a confirmação de uma transação. As alterações nos dados do banco de dados são persistentes, mesmo se o banco de dados falhar.
1 pool de buffer
O Buffer Pool contém o mapeamento de algumas páginas de dados no disco . Ao ler dados do banco de dados, os dados serão lidos primeiro do Buffer Pool. Se não estiverem no Buffer Pool, serão lidos do disco e colocados no Buffer Pool. Quando os dados são gravados no banco de dados, eles primeiro são gravados no Buffer Pool; a atualização dos dados no Buffer Pool será periodicamente descarregada no disco (um processo conhecido como brush dirty ).
2Log Buffer
Quando você faz alterações nas tabelas InnoDB no MySQL, essas alterações são primeiro armazenadas no buffer de log do InnoDB ( a memória do Buffer de log ) e, em seguida, gravam frequentemente referido no log de redo ( logs de redo ) dos arquivos de log do InnoDB.
3D Buffer de Gravação Dupla (Buffer de DoubleWrite)
Buffer de gravação dupla é o buffer do arquivo físico no espaço de tabela compartilhado. Seu tamanho é de 2 MB. É um espaço de 2 MB dividido em dois.
Quando a operação de página suja começa, a operação de página suja ** 'backup' ** é executada. Os dados da página suja são gravados no buffer de gravação dupla.
O buffer de gravação dupla (IO sequencial) é gravado no arquivo de disco (espaço de tabela compartilhado) para a operação de página suja.
4 Desfazer Log
Undo Log registra o log lógico . Ele registra a versão alterada ea situação de cada um dos dados durante a transação .
Na arquitetura de disco Innodb, padrões Undo Entrar para o buffer do arquivo físico do espaço de tabela compartilhada. A
transação é interrompida de forma anormal ou ativamente (Rollback Durante o processo de rollback **, o Innodb realiza rollback de desfazer dados com base no Undo Log para garantir que os dados retornem ao início da transação. **
5Redo Log
Refazer log geralmente se refere ao log físico , que registra a modificação física da página de dados, mas não grava o registro da linha. (Ou seja, ele registra apenas as alterações a serem feitas e não registra a conclusão das alterações)
Quando o banco de dados estiver inativo e reiniciado, o conteúdo do log de redo será restaurado no banco de dados .
1 atomicidade
Assuntos do Innodb de garantia de atomicidade, incluindo o mecanismo de reversão para enviar mecanismos de transação e transações . No mecanismo de reversão do mecanismo Innodb da transação está contando com o log de reversão (Undo Log) para reverter os dados para garantir que os dados voltem ao início do status da transação .
将修改后的数据存入缓冲池(Buffer Pool)中,等待刷脏。
在Log Buffer中写入重做日志(Redo Log),并将日志状态设置为Prepare。
返回MySQL服务层,记录BinLog日志。
将Log Buffer中的日志文件状态设为Commit,并等待日志文件存入盘中。
2 Portanto, diferentes níveis de isolamento, como o isolamento é alcançado e por que coisas diferentes não podem interferir umas nas outras? A resposta está bloqueada e MVCC .
Transaction Implementation Mode-MVCC
1 O que é MVCC?
MVCC é o controlador de simultaneidade multi-versão do mysql, isto é, o controlador de simultaneidade multi- versão.O motor innodb do mysql suporta MVVC . MVCC é atingir o isolamento da transação, através do número da versão, para evitar a competição entre os mesmos dados em transações diferentes, você pode considerá-lo como um bloqueio otimista com base em vários números de versão . Obviamente, esse bloqueio otimista só tem efeito no nível de transação de RR (leitura repetida) e RC (confirmação de leitura) . Acredita-se que o maior benefício do MVCC seja familiar: ler sem travar, sem conflito entre ler e escrever . Em aplicativos OLTP com mais leituras e menos gravações, é muito importante que as leituras e gravações não entrem em conflito, o que aumenta muito o desempenho simultâneo do sistema .
2 Mecanismo de implementação do MVCC O
InnoDB adiciona dois campos ocultos em cada linha de dados , um número de versão para criação de registro e um número de versão para exclusão de registro.
No controle de simultaneidade multi-versão, a fim de garantir que as operações de dados sejam realizadas em um processo multi-threaded, um mecanismo para garantir o isolamento da transação, reduzir a pressão da concorrência de bloqueio e garantir uma quantidade maior de simultaneidade. Cada vez que uma transação é aberta, um número de versão da transação é gerado e os dados manipulados geram uma nova linha de dados (temporária) , mas é invisível para outras transações antes do envio . Para atualizações de dados (incluindo adições, exclusões e alterações)) Se a operação for bem-sucedida, o número da versão será atualizado para a linha de dados. A transação foi enviada com sucesso, e o novo número da versão será atualizado para esta linha de dados. Isso garante que os dados de cada operação de transação não afetem uns aos outros Não há problema de bloqueio.
CRUD
SELECT sob 3MVCC : operação de seleção
quando o nível de isolamento é READ REPETIVEL , cada linha de dados no InnoDB garante que atenda a duas condições:
1. O InnoDB deve encontrar a versão de criação de uma linha, que deve ser pelo menos tão antiga quanto a transação versão (também Ou seja, seu número de versão não é maior que o número da versão da transação) . Isso garante que essa linha de dados exista, não importa antes do início da transação, ou quando a transação é criada, ou quando a linha de dados é modificada.
2. A versão excluída desta linha de dados deve ser indefinida ou maior que a versão da transação . Isso pode garantir que essa linha de dados não seja excluída antes do início da transação.
INSERT:
InnoDB registra o número da versão atual do sistema para esta nova linha .
DELETE:
InnoDB define o número da versão do sistema atual como o ID de exclusão desta linha.
ATUALIZAÇÃO: o
InnoDB gravará uma nova cópia desta linha de dados, a versão desta cópia é o número da versão atual do sistema. Ele também gravará este número de versão na versão excluída da linha antiga.
Mecanismo de bloqueio
https://blog.csdn.net/zs18753479279/article/details/114622776
3 resistência
Pode haver três cenários no processo de mecanismo de confirmação baseado em transação.
1 A liberação de dados é normal . Tudo é normalmente enviado para o
registro do ciclo de Redo Log. Os dados são colocados com sucesso. A persistência pode ser garantida.
2 Acidentes do sistema no processo de liberação de dados Fenômeno de causar quebras de página (limpeza parcial suja com êxito)
Em vista da situação de fratura de página, o mecanismo de gravação dupla é usado para garantir a recuperação dos dados de fratura de página.
3 Não há fenômeno de fratura de página nos dados e não há sucesso
flushing. O MySQL pode executar a persistência de dados por meio do Redo Log .
4 consistência
Do nível do banco de dados, o banco de dados garante consistência por meio de atomicidade, isolamento e durabilidade
2 A implementação subjacente do tipo de dados Redis
A estrutura de dados subjacente do Redis tem os seguintes tipos de dados: 1 string dinâmica simples 2 lista vinculada 3 dicionário 4 tabela de salto 5 conjunto de inteiros 6 lista compactada
1 string dinâmica simples
O Redis cria um tipo abstrato chamado ** Simple Dynamic String (SDS) ** e usa SDS como a representação de string padrão do Redis . No Redis, as strings C são usadas apenas como strings literais em locais onde não há necessidade de modificar os valores das strings (como impressão de logs). Quando o Redis precisa de um valor de string que pode ser modificado, o Redis usa SDS para representar a string
O SDS também é usado como um buffer : o buffer AOF no módulo AOF e o buffer de entrada no estado do cliente são todos implementados pelo SDS
2 Lista vinculada [edifício da lista] A
lista vinculada fornece recursos eficientes de reorganização de nós , bem como métodos de acesso de nó sequencial , e o comprimento da lista vinculada pode ser ajustado de forma flexível adicionando e excluindo nós
Uma das implementações subjacentes das chaves de lista é uma lista vinculada. Quando uma chave de lista contém um número relativamente grande de elementos ou os elementos contidos na lista são strings relativamente longas, o Redis usará a lista vinculada como a implementação subjacente da chave de lista
Além disso, funções como publicar e assinar , consulta lenta e monitorar também usam listas vinculadas. O próprio servidor Redis também usa listas vinculadas para armazenar as informações de status de vários clientes e usa listas vinculadas para criar buffers de saída do cliente ; servidor redis mantém Um dicionário (k, v), as chaves do dicionário são canais! O valor do dicionário é uma lista vinculada na qual todos os clientes que se inscrevem neste canal são salvos.
3 Dicionário [chave hash]
Dicionário (mapeamento) é uma estrutura de dados abstrata usada para armazenar pares de valores-chave . Os
bancos de dados Redis são implementados usando dicionários como camada inferior.
O dicionário também é uma das implementações subjacentes da chave hash. Quando uma chave hash contém mais comparações de valor-chave ou os elementos no par de valor-chave são strings relativamente longas, o Redis usará o dicionário como a chave hash. implementação subjacente
4 Tabela de salto [conjunto ordenado] A
tabela de salto é uma estrutura de dados ordenada . Ela mantém vários ponteiros para outros nós em cada nó para atingir o objetivo de acesso rápido aos nós. O
Redis só usa saltos em dois lugares. Tabela, uma é para implementar uma tabela ordenada conjunto de chaves , e o outro deve ser usado como uma estrutura de dados interna no nó do cluster
5 Conjunto de inteiros [chave de coleção]
Conjunto de inteiros é uma das implementações subjacentes da chave de conjunto . Quando um conjunto contém apenas elementos de valor inteiro e o número de elementos neste conjunto é pequeno, o Redis usará o conjunto de inteiros como a implementação subjacente de a chave definida
6 Lista compactada [criação de lista, chave de hash]
Lista compactada é uma das implementações subjacentes da criação de lista e chave de hash .
Quando uma chave de lista contém apenas um pequeno número de itens de lista e cada item de lista é um pequeno valor inteiro ou uma string com um comprimento relativamente curto, o Redis usará uma lista compactada como a implementação subjacente da chave de lista .
Quando uma chave hash contém apenas um pequeno número de pares de valor-chave e a chave e o valor de cada par de valor-chave é um pequeno valor inteiro ou uma string com um comprimento relativamente curto, o Redis usará uma lista compactada como o implementação de baixo nível de chave de hash
3 Estrutura de dados subjacente ReentrantLock
Reetrantlock é um bloqueio de exclusão mútua que pode obter repetidamente um bloqueio . Seu bloqueio e desbloqueio precisam ser executados manualmente e também pode ser bloqueado várias vezes . Ao mesmo tempo, também pode especificar se é implementado por um bloqueio justo ou um bloqueio injusto .
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
Pode-se ver a partir do método de construção que o reentrantlock é implementado por fair lock e injusto lock, e fair lock e injusto lock herdam o método de template e os princípios subjacentes de AQS (AbstractQueuedSynchronizer).
1AbstractQueuedSynchronizer (AQS)
A ideia central do AQS é que, se o recurso compartilhado solicitado estiver ocioso, o thread que está solicitando o recurso é definido como um thread de trabalho válido e o recurso compartilhado é definido como um estado bloqueado. Se o recurso compartilhado solicitado estiver ocupado, será necessário um mecanismo de bloqueio e espera de thread e alocação de bloqueio quando ativado.Este mecanismo AQS é implementado com bloqueio de fila CLH , ou seja, threads que não podem obter bloqueios temporariamente são adicionados à fila.
A fila CLH (Craig, Landin e Hagersten) é uma fila virtual bidirecional (uma fila virtual bidirecional significa que não há instância de fila, apenas o relacionamento entre os nós). O AQS encapsula cada thread solicitando recursos compartilhados em um nó de uma fila de bloqueio CLH para realizar a alocação de bloqueio.
O AQS usa uma variável de membro int para representar o status de sincronização e conclui o trabalho de enfileiramento do thread de recursos por meio da fila FIFO embutida **. AQS usa CAS para realizar operações atômicas no estado de sincronização para modificar seu valor. **
//节点元素node的构成:
volatile Node prev; //指向前一个结点的指针
volatile Node next; //指向后一个结点的指针
volatile Thread thread; //当前结点代表的线程
volatile int waitStatus; //等待状态
//AQS其他的数据结构
private volatile int state;//Reentratlock中表示锁被同一个线程重入的次数
private transient Thread exclusiveOwnerThread;//标识锁是由哪个线程拥有
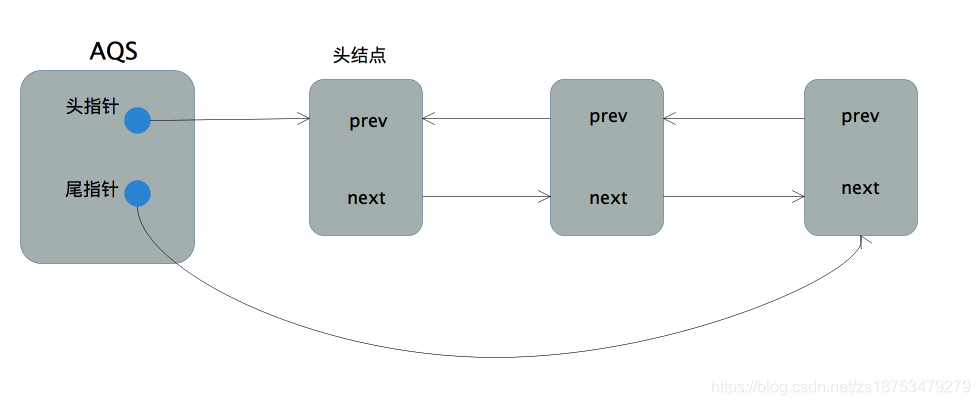
O nó principal do ponteiro principal aqui representa o encadeamento que atualmente adquire o bloqueio e os nós a seguir representam o encadeamento que deseja adquirir o bloqueio . Esta é uma fila de sincronização first-in-first-out . O thread que não conseguir obter o bloqueio construirá seu próprio nó e o anexará ao final da fila e se bloqueará. Quando o thread libera o bloqueio, ele também tente despertar o thread bloqueado no nó subsequente.
2Nonfairlock NonfairSync
static final class NonfairSync extends Sync
Herdar Sync e implementar os métodos lock e tryAcquire. O
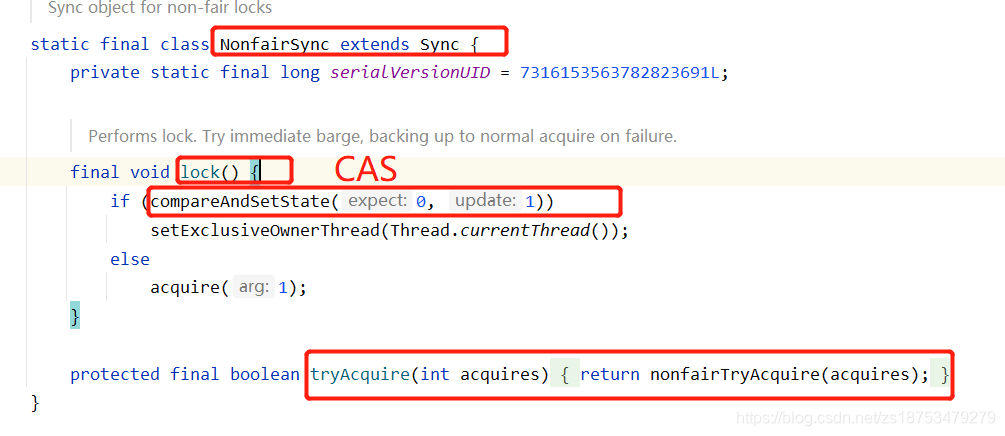 método lock é usar cas para atualizar o estado e o thread de retenção atual por padrão. Se o estado em AQS for 0, ou seja, a fila está vazia, defina o estado e o tópico atual. Se não for bem-sucedido, entre na fila.
método lock é usar cas para atualizar o estado e o thread de retenção atual por padrão. Se o estado em AQS for 0, ou seja, a fila está vazia, defina o estado e o tópico atual. Se não for bem-sucedido, entre na fila.
4 A diferença entre TCP / Http
1 conexão TCP
O telefone móvel pode usar a função de rede porque a camada inferior do telefone móvel implementa o protocolo TCP / IP, que permite que o terminal móvel estabeleça uma conexão TCP por meio da rede sem fio. O protocolo TCP pode fornecer uma interface para a rede da camada superior, de modo que a transmissão de dados da rede da camada superior seja estabelecida na rede "indiferenciada".
Estabelecer uma conexão TCP requer um "handshake de três vias":
o primeiro handshake: o cliente envia um pacote syn (syn = j) para o servidor e entra no estado SYN_SEND, aguardando a confirmação do servidor; o
segundo handshake: o servidor recebe o pacote syn, deve confirmar o SYN do cliente (ack = j + 1), e ao mesmo tempo enviar um pacote SYN (syn = k), ou seja, pacote SYN + ACK, neste momento o servidor entra no estado SYN_RECV ; o
terceiro handshake: o cliente recebe o pacote SYN + ACK do servidor, envia um pacote de confirmação ACK (ack = k + 1) para o servidor, esse pacote é enviado, o cliente e o servidor entram no estado ESTABLISHED e concluem os três- forma de aperto de mão.
Conexão 2HTTP
O protocolo HTTP, ou Hypertext Transfer Protocol (Hypertext Transfer Protocol), é a base da rede da Web e um dos protocolos mais usados para redes de telefonia móvel.O protocolo HTTP é um aplicativo criado sobre o protocolo TCP .
O recurso mais notável da conexão HTTP é que cada solicitação enviada pelo cliente exige que o servidor envie uma resposta e, após o término da solicitação, a conexão é ativamente liberada. O processo desde o estabelecimento de uma conexão até o fechamento de uma conexão é denominado "uma conexão".
1) Em HTTP 1.0, cada solicitação do cliente requer uma conexão separada para ser estabelecida.Após o processamento desta solicitação, a conexão é automaticamente liberada.
2) No HTTP 1.1, várias solicitações podem ser processadas em uma conexão e várias solicitações podem ser sobrepostas, e não há necessidade de esperar que uma solicitação termine antes de enviar a próxima.
Uma vez que o HTTP irá liberar ativamente a conexão após cada solicitação, a conexão HTTP é uma espécie de "conexão curta" . Para manter o programa cliente online, é necessário iniciar continuamente as solicitações de conexão ao servidor. A prática usual é não precisar obter nenhum dado imediatamente, o cliente também continua enviando uma solicitação de "manter a conexão" ao servidor em intervalos regulares, e o servidor responde ao cliente após receber a solicitação, indicando que conhece o cliente . Online ". Se o servidor deixar de receber a solicitação do cliente por um longo tempo, o cliente é considerado "offline", se o cliente deixar de receber a resposta do servidor por um longo tempo, a rede é considerada desconectada.
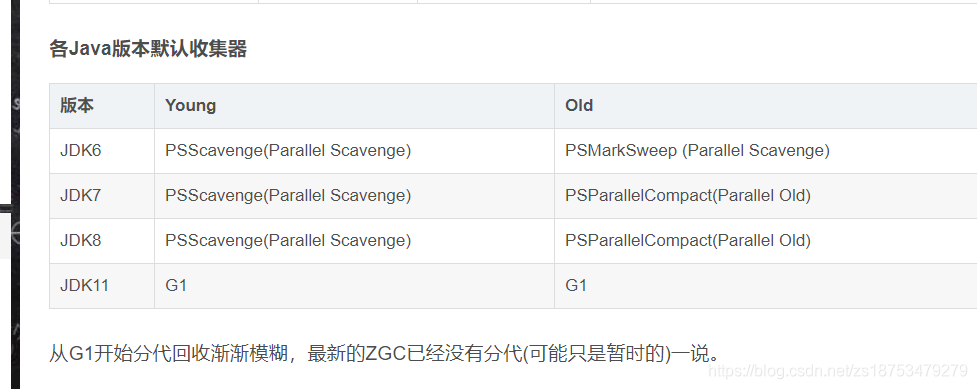
Coletor de lixo padrão JDK8 em 5JVM
UseParallelGC 即 Parallel Scavenge + Parallel Old