Depois de baixar do banco de dados SEER para o banco de dados, uma etapa muito importante é dividir aleatoriamente o banco de dados em um grupo de modelagem e um grupo de verificação. De modo geral, 70% dos dados são usados para modelagem e 30% dos dados são usados para verificação. Como é difícil para nós encontrar dados semelhantes ao banco de dados SEER para verificação externa, só podemos dividir os dados para verificação. O exemplo na figura abaixo, o autor usa a divisão de dados 7: 3.


Hoje, vamos falar sobre como dividir o banco de dados SEER proporcionalmente no conjunto de modelagem e no conjunto de verificação por meio da linguagem R, ou usar nosso câncer de mama passado comumente usado Dados,
primeiro importe os dados
tr1<- sample(nrow(bc),0.7*nrow(bc))##随机无放抽取
bc_train <- bc[tr1,]#70%数据集
bc_test<- bc[-tr1,]#30%数据集

OK, os dados foram selecionados aleatoriamente, basta escrevê-los em um arquivo
write.csv(bc_train,file = "bc_train.csv")
write.csv(bc_test,file = "bc_test.csv")
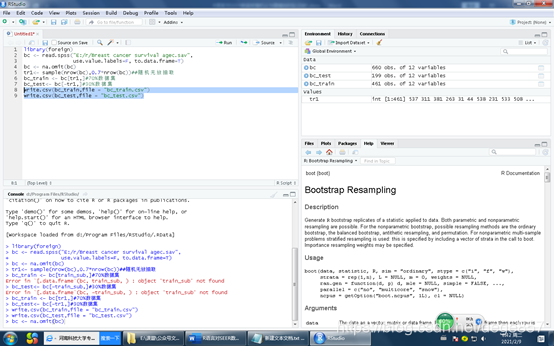
OK, pronto, embora seja muito simples, também é muito prático.
Esta conta oficial fornece um conjunto completo de cursos de mineração para o banco de dados SEER pela SPSS e Stata, com base zero e prática simples, bem-vindo para se inscrever.
Para artigos mais interessantes, preste atenção ao número público: pesquisa científica baseada em zero
