Converter o jupyter para pdf é muito simples. Nada mais é do que instalar o pandoc, depois instalar o programa MikTex.exe, definir a variável de ambiente MikTexPATH, abrir o jupyter e clicar em converter. Uma janela aparecerá pedindo para você instalar o pacote de macro e, em seguida, verifique a instalação silenciosa em segundo plano. Em seguida, reinicie o jupyter e converta o pdf. No entanto, não há suporte de caracteres da Microsoft para janelas adicionadas por padrão (ou seja, o conjunto de caracteres não pode ser reconhecido pelo programa MikTex), ou seja, o chinês em jupyter não pode ser convertido para pdf.
Você tem que emitir um comando para convertê-lo todas as vezes? ? ? Não, existe um método definitivo abaixo.
1. Localize o contexto do Anaconda3\Lib\site-packages\nbconvert\templates\latexcaminho. No caso de ambiente virtual, insira o caminho do ambiente virtual primeiro. No Anaconda, geralmente é Anaconda3\envs\虚拟环境名称+ Lib\site-packages\nbconvert\templates\latex
2. código de entrada base.tplx para resolver o problema chinês: o
arquivo base.tplx é inserido após ((* blocos de pacotes *)):
\usepackage{
fontspec, xunicode, xltxtra}
\setmainfont{
Microsoft YaHei}
\usepackage{
ctex}
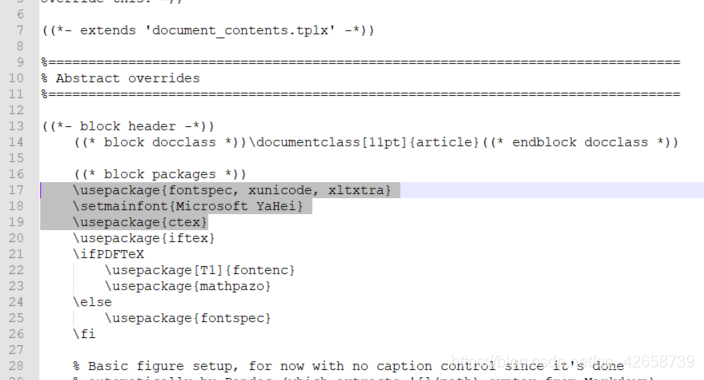
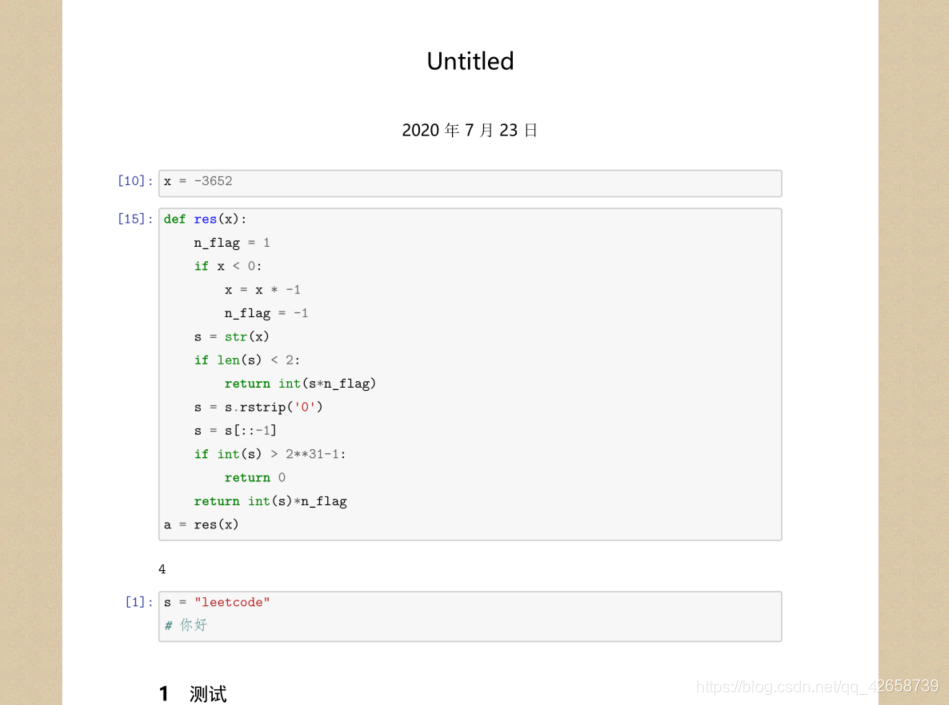
Depois de adicionar, a saída normal do PDF chinês: A
figura a seguir é meu rascunho anterior do Likou, com duas frases em chinês, e a saída normal é PDF:
Além disso: instale o plug-in Jupyter:
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
pip install jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user
jupyter nbextension enable codefolding/main