Prefácio
A coleção ordenada SortedSet (zset) pode ser considerada como mantendo um valor de sequência para cada elemento na coleção com base na coleção Set: pontuação, que permite que os elementos na coleção sejam classificados de acordo com a pontuação, por isso é clássica e Cenários práticos como: os candidatos são classificados por pontuação, um determinado jogador é classificado por pontuação, uma determinada classificação de dados na página inicial do site, os comentários mais recentes são classificados por tempo e assim por diante.
O Redis é um banco de dados na memória. Ele também precisa considerar a sobrecarga de memória, garantindo a velocidade de leitura e gravação. Para conjuntos ordenados SortedSet, ele precisa manter um valor de pedido. Para a implementação subjacente de conjuntos ordenados, você pode escolher: matrizes , listas vinculadas, estruturas como árvores balanceadas ou árvores vermelhas e pretas, mas SortedSet não escolheu essas estruturas. O desempenho de inserção e exclusão de elementos na matriz é muito baixo e a consulta da lista vinculada é lenta. Embora a eficiência da consulta da árvore balanceada ou da árvore vermelha e preta seja alta, o desempenho da árvore precisa ser mantido ao inserir e excluir elementos, e a implementação é extremamente complicada.
Portanto, a camada inferior do SortedSet usa um novo tipo de estrutura de dados— 跳跃表
Princípio da lista de pular skiplist
O desempenho da tabela de salto é comparável ao da árvore vermelho-preto e é muito mais simples de implementar do que a árvore vermelho-preto. Então, o que é pular relógio? Antes de entender a lista de atalhos, vamos dar uma olhada na seguinte lista vinculada.
![[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo de link anti-leech. Recomenda-se salvar a imagem e carregá-la diretamente (img-77seSZ0O-1615940744288) (sortedset.assets / 1615907166172.png)]](https://img-blog.csdnimg.cn/20210317082630470.png)
Se quisermos consultar um nó com um valor de 13, para a lista vinculada individualmente acima, preciso percorrer os nós da frente para trás e calcular que o desempenho é muito ruim. Como posso melhorar a velocidade da consulta? Sabemos que mesmo uma lista encadeada ordenada não pode ser alterada para pesquisa binária, a menos que transformemos essa lista encadeada em uma estrutura como uma árvore vermelho-preto, mas a realização de uma árvore vermelho-preto é muito problemática. Então, e se eu tratar essa lista vinculada assim?
![[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo de link anti-leech. Recomenda-se salvar a imagem e carregá-la diretamente (img-HWqiGo40-1615940744291) (sortedset.assets / 1615907457430.png)]](https://img-blog.csdnimg.cn/20210317082645182.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTQ0OTQxNDg=,size_16,color_FFFFFF,t_70)
Eu extraio os elementos do primeiro nível da lista vinculada a cada dois elementos para cima para formar o segundo nível da lista vinculada, como mostrado na figura acima, se eu pesquisar por elementos, primeiro encontrarei 13 no nível superior, e quando eu encontrar 18 Quando for maior que 13, volte para 10, vá para o próximo nível para encontrar e, em seguida, encontre 13. Você conta desta vez que o número de pesquisas é quase a metade da lista anterior unicamente vinculada, o que economiza bastante o tempo de consulta. E se eu subir outra camada?
![[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo de link anti-leech. Recomenda-se salvar a imagem e carregá-la diretamente (img-EOwpcGLF-1615940744294) (sortedset.assets / 1615907763389.png)]](https://img-blog.csdnimg.cn/20210317082724541.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTQ0OTQxNDg=,size_16,color_FFFFFF,t_70)
De acordo com a regra de agora, extraímos mais uma camada. Desta vez, o número de pesquisas foi reduzido novamente? Na verdade, essa estrutura de dados é a estrutura de armazenamento da "tabela de salto". Na verdade, você pode descobrir que seu desempenho de consulta é comparável ao da árvore vermelho-preto, mas é muito mais simples de implementar do que a árvore vermelho-preto.
Implementação de baixo nível SortedSet
A camada inferior do SortedSet usa duas estruturas de armazenamento: lista compactada Ziplist e "tabela de salto". Existem duas configurações no arquivo de configuração do Redis:
- zset-max-ziplist-entries 128: Quando zset usa uma lista compactada, o número máximo de elementos. O valor padrão é 128.
- zset-max-ziplist-value 64: Quando zset usa uma lista compactada, o comprimento máximo da string de cada elemento. O valor padrão é 64.
Quando zset insere o primeiro elemento, ele julgará as duas condições a seguir, se o valor de zset-max-ziplist-entries é igual a 0; zset-max-ziplist-value é menor que o comprimento da string a ser inserida, e o Redis irá satisfazer qualquer condição. A lista de pulos será usada como a implementação inferior, caso contrário, a lista compactada será usada como a implementação inferior. Veja o código-fonte: t_zset.c
void zaddGenericCommand(client *c, int flags) {
...省略...
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();/ *创建跳跃表*/
} else {
zobj = createZsetZiplistObject(); / *创建压缩列表 */
}
dbAdd(c->db,key,zobj);
}
}
Em circunstâncias normais, zset-max-ziplist-entries não serão configuradas para 0 e o comprimento da string do elemento não será muito longo, portanto, ao criar um conjunto ordenado, a implementação subjacente da lista compactada é usada por padrão. Quando um novo elemento é inserido em zset, as duas condições a seguir serão julgadas: o número de elementos em zset é maior que zset_max_ziplist_entries; o comprimento da string do elemento inserido é maior que zset_max_ziplist_value. Quando qualquer condição for atendida, o Redis converterá a implementação subjacente de zset de uma lista compactada em uma lista de atalhos, consulte a função zsetAdd em t_zset.c
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);/* 转跳跃表 */
É importante notar que depois que zset for convertido em uma lista de pulos, mesmo se os elementos forem excluídos gradualmente, ele não será convertido em uma lista compactada novamente.
Estrutura do skiplist
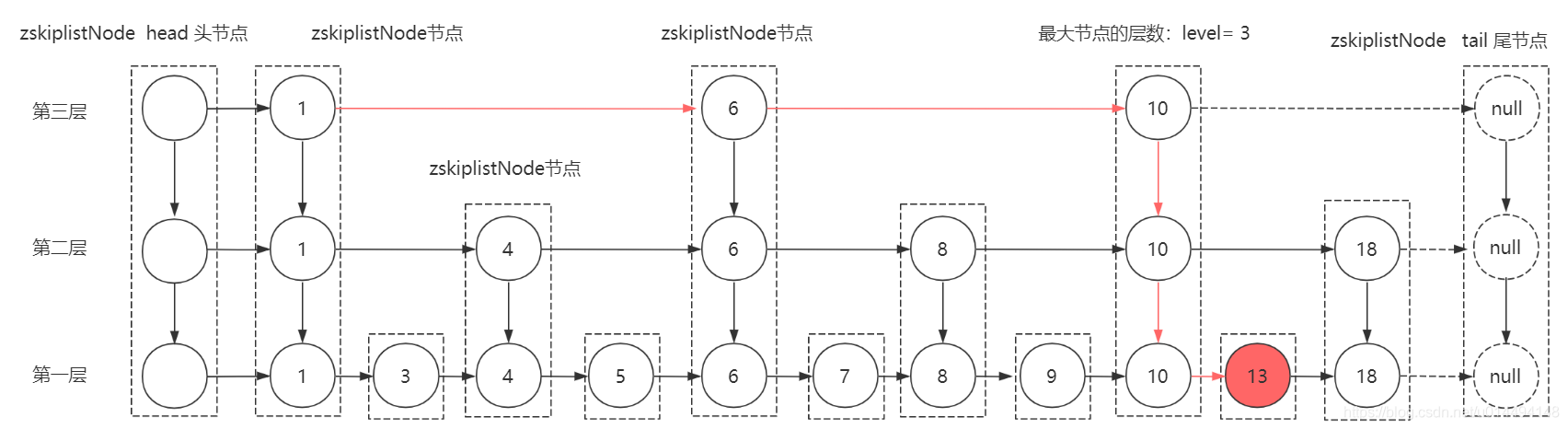
A tabela de salto consiste principalmente em: nó da tabela de salto, nó principal, nó final, número do nó e nível máximo do nó, como segue: Consulte server.h para obter o código-fonte
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//跳表节点 ,头节点 , 尾节点
unsigned long length;//节点数量
int level;//目前表内节点的最大层数
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
Explicação:
- cabeçalho: aponta para o nó principal da tabela de salto, o nó principal é um nó especial da tabela de salto e o número de elementos na matriz de nível é 64. O nó principal não armazena nenhum membro e valores de pontuação no conjunto ordenado, o valor de ele é NULL e o valor de pontuação é 0; ele não está incluído no comprimento total da tabela de salto. Quando o nó principal é inicializado, o encaminhamento de 64 elementos aponta para NULL e o valor do intervalo é todo 0.
- cauda: aponte para o nó final da lista de atalhos
- comprimento: o comprimento da tabela de salto, indicando o número total de nós, exceto o nó principal
- nível: A altura do maior nó na tabela de salto.
A estrutura do zskiplist é mostrada na figura:
estrutura zskiplistNode
//跳表节点
typedef struct zskiplistNode {
sds ele;//用于存储字符串类型的数据
double score;//分值
struct zskiplistNode *backward;//后向指针
struct zskiplistLevel {
//节点所在的层
struct zskiplistNode *forward;//前向指针
unsigned int span;//该层向前跨越的节点数量
} level[]; //节点层结构 数组,每次创建一个跳表节点时,都会随机生成一个[1,32]之间的值作为level数组的大小。
} zskiplistNode;
Explicação:
-
ele: usado para armazenar dados do tipo string
-
backward: ponteiro para trás, ele só pode apontar para o nó anterior na parte inferior do nó atual, o nó principal e o primeiro nó para trás aponta para NULL, que é usado ao percorrer a tabela de salto de trás para frente.
-
pontuação: usado para armazenar a pontuação classificada
-
nível: é uma matriz flexível. O comprimento da matriz de cada nó é diferente. Ao gerar o nó da tabela de salto, um valor de 1 a 64 é gerado aleatoriamente. Quanto maior o valor, menor a probabilidade de ocorrência.
- forward: aponta para o próximo nó nesta camada, e o forward do nó final aponta para NULL.
- span: O número de elementos entre o nó apontado pelo forward e este nó. Quanto maior o valor do intervalo, mais nós serão ignorados
O elemento de cada nó da tabela de salto armazena o valor do membro do conjunto ordenado e a pontuação armazena o valor da pontuação do membro. As pontuações de todos os nós são classificadas de pequeno a grande. Quando as pontuações dos membros do conjunto ordenado são iguais, os nós são classificados na ordem lexicográfica dos membros.
O artigo acabou, espero que ajude você, se gostar, por favor, dê um bom comentário! ! !