Artigo Diretório
1. Processo Linux
1.1 Conceito de processo:
- Do ponto de vista do usuário: um processo é um programa em execução.
- Perspectiva do sistema operacional: o sistema operacional executa um programa e precisa descrever o processo de execução do programa. Essa descrição é descrita por uma estrutura task_struct {}, coletivamente denominada PCB, portanto, para o sistema operacional, o processo é PCB (processo bloco de controle) peça de controle do programa
- As informações de descrição do processo incluem: identificador PID, status do processo, prioridade, contador do programa, dados de contexto, ponteiro de memória, informações de status IO e informações de contabilidade. Todos precisam do sistema operacional para agendamento.
1.2 Status do processo:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
2. função fork ()
2.1 Visão geral:
O processo filho obtido usando a função fork () é uma cópia do processo pai. Ele herda o espaço de endereço de todo o processo do processo pai:
incluindo o contexto do processo (descrição estática de todo o processo das atividades de execução do processo), processo empilhar e abrir arquivos Descritores, configurações de controle de sinal, prioridade de processo, número de grupo de processo, etc. A única coisa única do processo filho é seu número de processo, cronômetro, etc. (apenas uma pequena quantidade de informações).
pid_t fork(void);
Arquivo head:
#include <sys/types.h>
#include <unistd.h>
Características:
- Usado para criar um novo processo a partir de um processo existente, o novo processo é chamado de processo filho e o processo original é chamado de processo pai.
valor de retorno:
- Sucesso: 0 é retornado no processo filho e o ID do processo filho é retornado no processo pai. pid_t é um inteiro sem sinal.
- Falha: retornar -1.
Exemplo de código:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(int argc, char *argv[])
{
pid_t pid;
pid = fork();
if( pid < 0 ){
// 没有创建成功
perror("fork");
}
if(0 == pid){
// 子进程
while(1){
printf("I am son\n");
sleep(1);
}
}
else if(pid > 0){
// 父进程
while(1){
printf("I am father\n");
sleep(1);
}
}
return 0;
}
2.2 Resultados da operação:

2.3 Resumo:
- Através dos resultados da execução, você pode ver que os processos pai e filho fazem uma coisa cada um (cada um imprime uma frase). Aqui, vemos apenas que há apenas um trecho de código. Na verdade,
após fork () , dois espaços de endereço são executados de forma independente, o que é um pouco semelhante a ter dois programas independentes (processos pai e filho) em execução. Deve-se observar que no espaço de endereço do processo filho, o processo filho começa a executar o código após a função fork (). - Depois de fork (), é incerto se o processo pai é executado primeiro ou se o processo filho é executado primeiro. Isso depende do algoritmo de escalonamento usado pelo kernel.
3. Processo de zumbi
Um processo usa fork para criar um processo filho. Se o processo filho sair e o processo pai não chamar wait () ou waitpid () para obter as informações do processo filho, o descritor do processo filho ainda está armazenado no sistema, e isso tipo de processo é chamado de processo zumbi.
Z 进程
3.1 O código simula o processo zumbi:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("输入一遍\n");
pid_t ret = fork();
if(ret > 0)
{
//parent
while(1)
{
printf("I am parent! pid is : %d\n", getpid());
sleep(1);
}
}
else if(ret == 0)
{
/child
int count = 0;
while(count<5)
{
printf("I am child! pid is : %d, ppid: %d\n", getpid(), getppid());
count++;
sleep(2);
}
exit(0);
}
else
{
printf("fork error\n");
}
sleep(1);
return 0;
}
3.2 Exibição dos resultados do processo zumbi:
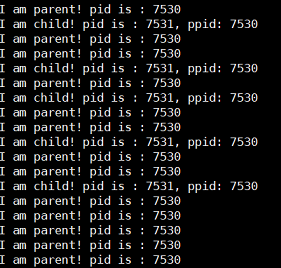
3.3 Danos no processo de zumbi:
O estado de saída do processo filho será sempre mantido, a manutenção do próprio estado de saída requer a manutenção dos dados, que também pertencem às informações básicas do processo e estão armazenados
task_structnele. Ou seja, enquanto o estado Z não sair, o PCB deve sempre manter a informação de saída. Se um processo pai criar muitos processos filho sem reciclagem, isso causará造成内存资源的极大浪费e ocorrerá内存泄露.
4. Processo órfão
Quando o processo pai sai mais cedo, o processo filho é chamado de "processo órfão". Depois que o processo pai sai, o processo filho está no estado Z quando deseja sair. Como nenhum processo recebe suas informações de saída, o processo órfão deve ser adotado e reciclado pelo processo init nº 1 para evitar que o processo filho se torne um processo zumbi.
4.1 O código simula o processo órfão:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
pid_t ret = fork();
if(ret < 0)
{
printf("创建进程失败!\n");
}
else if(ret > 0)
{
int count = 0;
while(count++ < 5)
{
printf("我是父进程(id:%d)\n",getpid());
sleep(2);
}
exit(0);
}
else
{
while(1)
{
printf("我是子进程(id:%d)\n",getpid());
sleep(1);
}
}
sleep(1);
return 0;
}
4.2 Exibição dos resultados do processo órfão:
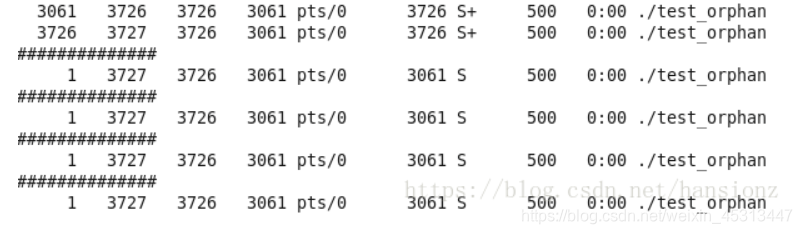
4.3 Resumo:
O SO considera esta situação, quando o processo pai sai e o processo filho ainda está em execução (o processo filho é chamado de processo órfão), ele encontra um pai para ele novamente, como mostrado na figura é o sistema de processo nº 1.
Extensão do processo nº 1 (init):
Criado pelo processo 0, conclui a inicialização do sistema. É o processo ancestral de todos os outros processos do usuário no sistema.
Todos os processos no Linux são criados e executados pelo processo init. Primeiro, o kernel Linux é iniciado, em seguida, o processo init é iniciado no espaço do usuário e, em seguida, outros processos do sistema são iniciados. Depois que a inicialização do sistema for concluída, o init se tornará um daemon para monitorar outros processos no sistema.