
O que está sendo desenvolvido pelo desenvolvimento front-end
No processo de desenvolvimento de front-end, você pode ter pensado sobre esta questão: O que exatamente o desenvolvimento de front-end está desenvolvendo? Em minha opinião, a essência do desenvolvimento front-end é permitir que as visualizações da web respondam corretamente aos eventos relacionados. Existem três palavras-chave nesta frase: "Visualização da Web", "Respondendo corretamente" e "Eventos relacionados".
"Eventos relacionados" podem incluir cliques na página, slides do mouse, temporizadores, solicitações do servidor, etc. "Resposta correta" significa que temos que modificar alguns estados de acordo com eventos relacionados, e "visualização da web" é o aspecto mais importante de nossa desenvolvimento final. A parte familiar.
De acordo com este ponto de vista, podemos dar a fórmula visão = função de resposta (evento):
Exibir = reaçãoFn (evento)
No desenvolvimento de front-end, os eventos que precisam ser processados podem ser classificados nos três tipos a seguir:
- O usuário executa ações de página, como clique, movimento do mouse e outros eventos.
- O servidor remoto interage com os dados locais, como fetch, websocket.
- Eventos assíncronos locais, como setTimeout, setInterval async_event.

Desta forma, nossa fórmula pode ser derivada como:
Exibir = reaçãoFn (UserEvent | Timer | API remota)
Processamento de duas lógicas no aplicativo
Para entender melhor a relação entre essa fórmula e o desenvolvimento de front-end, tomamos um site de notícias como exemplo, que tem os três requisitos a seguir:
- Clique em Atualizar: Clique no botão para atualizar os dados.
- Verificar atualização: Atualizar automaticamente quando a caixa de seleção estiver marcada, caso contrário, pare a atualização automática.
- Atualização suspensa: atualize os dados quando o usuário puxar para baixo da parte superior da tela.
Se analisados da perspectiva do front-end, esses três requisitos correspondem a:
- Clique para atualizar: clique -> buscar
- Verifique a atualização: alterar -> (setInterval + clearInterval) -> buscar
- Puxe para baixo para atualizar: (touchstart + touchmove + touchend) -> buscar news_app

1 MVVM
No modo MVVM, a função de resposta (reaçãoFn) correspondente ao acima será executada entre o Model e o ViewModel ou entre o View e o ViewModel, e o evento (Event) será processado entre o View e o ViewModel.

O MVVM pode abstrair a camada de visualização e a camada de dados muito bem, mas a função de resposta (reaçãoFn) estará espalhada em diferentes processos de conversão, o que tornará difícil rastrear com precisão o processo de atribuição e coleta de dados. Além disso, como o processamento de eventos está intimamente relacionado à visualização neste modelo, é difícil reutilizar a lógica do processamento de eventos entre View e ViewModel.
2 Redux
No modelo mais simples de Redux, a combinação de vários eventos (Evento) corresponderá a uma Ação, e a função redutora pode ser considerada diretamente como correspondendo à função de resposta (reaçãoFn) mencionada acima.

Mas no Redux:
- Estado só pode ser usado para descrever estados intermediários, não processos intermediários.
- A relação entre Ação e Evento não é individual, o que torna difícil para o Estado rastrear a origem real da mudança.
3 Programação reativa e RxJS
A programação reativa é definida na Wikipedia:
Na computação, a programação reativa ou programação reativa (inglês: programação reativa) é um paradigma de programação declarativo orientado para o fluxo de dados e a propagação de mudanças. Isso significa que fluxos de dados estáticos ou dinâmicos podem ser facilmente expressos em linguagens de programação e o modelo de cálculo relevante propagará automaticamente os valores alterados por meio do fluxo de dados.
Reconsidere o uso do usuário do processo de aplicativo na dimensão do fluxo de dados:
- Clique no botão -> acionar evento de atualização -> enviar solicitação -> visualização de atualização
- Verifique a atualização automática
- Tela de toque de dedo
- Intervalo de atualização automática -> evento de atualização de gatilho -> solicitação de envio -> visualização de atualização
- Deslize o dedo na tela
- Intervalo de atualização automática -> evento de atualização de gatilho -> solicitação de envio -> visualização de atualização
- Pare de deslizar o dedo na tela -> acione um evento de atualização suspenso -> enviar solicitação -> visualização de atualização
- Intervalo de atualização automática -> evento de atualização de gatilho -> solicitação de envio -> visualização de atualização
- Desative a atualização automática
Representado pelo diagrama de mármores:

Dividindo a lógica da figura acima, você obterá as três etapas de uso da programação reativa para desenvolver o aplicativo de notícias atual:
- Defina o fluxo de dados de origem
- Combinar / transformar fluxos de dados
- Consumir o fluxo de dados e atualizar a visualização
Vamos descrevê-los em detalhes separadamente.
Defina o fluxo de dados de origem
Usando RxJS, podemos definir facilmente vários fluxos de dados de eventos.
1) Operação de clique
Envolve o fluxo de dados do clique.
click$ = fromEvent<MouseEvent>(document.querySelector('button'), 'click');2) Verifique a operação
Envolve o fluxo de dados de mudança.
change$ = fromEvent(document.querySelector('input'), 'change');3) Operação de puxar
Envolve três fluxos de dados: touchstart, touchmove e touchend.
touchstart$ = fromEvent<TouchEvent>(document, 'touchstart');
touchend$ = fromEvent<TouchEvent>(document, 'touchend');
touchmove$ = fromEvent<TouchEvent>(document, 'touchmove');4) Atualização regular
interval$ = interval(5000);5) Solicitação do servidor
fetch$ = fromFetch('https://randomapi.azurewebsites.net/api/users');Combinar / transformar fluxos de dados
1) Clique para atualizar o fluxo do evento
Ao clicar para atualizar, esperamos que vários cliques em um curto período de tempo só sejam acionados da última vez, o que pode ser feito por meio do operador debounceTime do RxJS.

clickRefresh$ = this.click$.pipe(debounceTime(300));2) Atualizar automaticamente o stream
Use o switchMap de RxJS para cooperar com o intervalo $ fluxo de dados definido anteriormente.

autoRefresh$ = change$.pipe(
switchMap(enabled => (enabled ? interval$ : EMPTY))
);3) Puxe para baixo para atualizar o fluxo
Combine os fluxos de dados touchstart $ touchmove $ e touchend $ previamente definidos.

pullRefresh$ = touchstart$.pipe(
switchMap(touchStartEvent =>
touchmove$.pipe(
map(touchMoveEvent => touchMoveEvent.touches[0].pageY - touchStartEvent.touches[0].pageY),
takeUntil(touchend$)
)
),
filter(position => position >= 300),
take(1),
repeat()
);Finalmente, mesclamos o clickRefresh $ autoRefresh $ definido com pullRefresh $ por meio da função de mesclagem para obter o fluxo de dados de atualização.

refresh$ = merge(clickRefresh$, autoRefresh$, pullRefresh$));Consumir o fluxo de dados e atualizar a visualização
O fluxo de dados de atualização é nivelado diretamente por meio de switchMap para o fetch $ definido na primeira etapa, e obtemos o fluxo de dados de exibição.
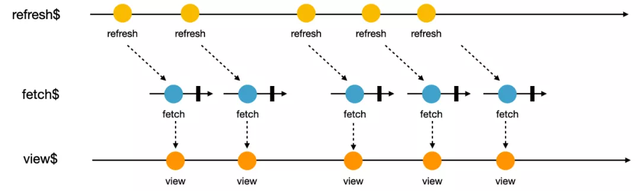
O fluxo de visualização pode ser mapeado diretamente para a visualização por meio do canal assíncrono direto na estrutura Angular:
<div *ngFor="let user of view$ | async">
</div>Em outras estruturas, você pode obter os dados reais no fluxo de dados por meio de assinatura e, em seguida, atualizar a visualização.
Até agora, utilizamos a programação reativa para completar o aplicativo de notícias atual.O código de exemplo [1] é desenvolvido pela Angular com no máximo 160 linhas.
Vamos resumir a correspondência entre os três processos experimentados ao desenvolver aplicativos front-end usando ideias de programação reativas e as fórmulas da primeira seção:
View = reactionFn(UserEvent | Timer | Remote API)1) Descreva o fluxo de dados de origem
Correspondendo ao evento UserEvent | Timer | API remota, as funções correspondentes em RxJS são:
- UserEvent: fromEvent
- Horas: intervalo, horas
- API remota: fromFetch, webSocket
2) Fluxo de dados de conversão combinada
Correspondendo à função de resposta (reaçãoFn), a parte correspondente do método em RxJS é:
- COMBINANDO: merge, combineLatest, zip
- MAPEAMENTO: mapa
- FILTRAGEM: filtro
- REDUZINDO: reduzir, máximo, contar, verificar
- TAKING: take, takeWhile
- SKIPPING: skip, skipWhile, takeLast, last
- TIME: delay, debounceTime, throttleTime
3) Visualização da atualização do fluxo de dados de consumo
Correspondendo a View, pode ser usado em RxJS e Angular:
- se inscrever
- tubo assíncrono
Quais são as vantagens da programação reativa sobre MVVM ou Redux?
- Descreva o evento em si, não o processo de cálculo ou estado intermediário.
- Fornece uma maneira de combinar e transformar fluxos de dados, o que também significa que temos uma maneira de reutilizar dados que mudam continuamente.
- Como todos os fluxos de dados são obtidos por combinação e conversão camada por camada, isso também significa que podemos rastrear com precisão a origem dos eventos e das alterações de dados.
Se desfocarmos a linha do tempo do gráfico RxJS Marbles e adicionarmos a seção vertical sempre que a visualização for atualizada, encontraremos duas coisas interessantes:

- Action é uma simplificação de EventStream.
- Estado é a correspondência de Fluxo em um determinado momento.
Não é à toa que podemos ter uma frase assim no site oficial do Redux: Se você já usou o RxJS, é provável que não precise mais do Redux.
A questão é: você realmente precisa do Redux se já usa o Rx? Talvez não. Não é difícil reimplementar o Redux no Rx. Alguns dizem que é um método de duas linhas usando o método Rx.scan (). Pode muito bem ser!
Neste ponto, podemos abstrair ainda mais a frase de que a visualização da web pode responder corretamente a eventos relacionados?
Todos os eventos - encontrar -> eventos relacionados - criar -> responder
Os eventos que ocorrem em ordem cronológica são essencialmente fluxos de dados, e a expansão posterior pode se tornar:
Fluxo de dados de origem - Conversão -> Fluxo de dados intermediário - Assinatura -> Fluxo de dados de consumo
Esta é a ideia básica para que a programação reativa funcione perfeitamente no front end. Mas essa ideia é aplicada apenas no desenvolvimento de front-end?
A resposta é não. Essa ideia pode ser aplicada não apenas no desenvolvimento front-end, mas também no desenvolvimento back-end e até mesmo na computação em tempo real.
Três quebram a parede da informação
Os desenvolvedores front-end e back-end são geralmente separados por uma parede de informações chamada API REST. A API REST isola as responsabilidades dos desenvolvedores front-end e back-end e melhora a eficiência do desenvolvimento. Mas também permite que os desenvolvedores front-end e back-end sejam separados por essa parede.Vamos tentar derrubar essa parede de informações e ter um vislumbre da aplicação da mesma ideia na computação em tempo real.
1 Computação em tempo real e Apache Flink
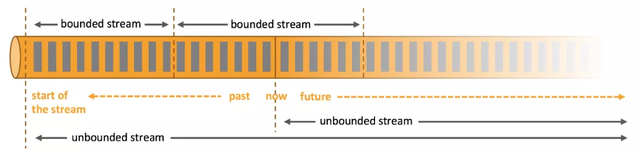
Antes de iniciar a próxima parte, vamos apresentar o Flink. Apache Flink é uma estrutura de processamento de fluxo de código aberto desenvolvida pela Apache Software Foundation para computação com estado em fluxos de dados sem fronteira e com fronteira. Seu modelo de programação de fluxo de dados fornece recursos de processamento de evento único (evento por vez) em conjuntos de dados limitados e ilimitados.
Em aplicações reais, o Flink é geralmente usado para desenvolver os três aplicativos a seguir:
- Aplicativos orientados a eventos Os aplicativos orientados a eventos extraem dados de um ou mais fluxos de eventos e acionam cálculos, atualizações de status ou outras ações externas com base em eventos de entrada. Os cenários incluem alarmes baseados em regras, detecção de anomalias, antifraude e assim por diante.
- Aplicativos de análise de dados As tarefas de análise de dados precisam extrair informações e indicadores valiosos dos dados brutos. Por exemplo, cálculo de turnover duplo onze, monitoramento de qualidade de rede e assim por diante.
- O aplicativo de pipeline de dados (ETL) extrair-transformar-carregar (ETL) é um método comum para conversão de dados e migração entre sistemas de armazenamento. As tarefas ETL geralmente são acionadas periodicamente para copiar dados de um banco de dados transacional para um banco de dados analítico ou data warehouse.
Tomemos o cálculo do giro horário da Double Eleven na plataforma de e-commerce como exemplo para ver se a solução que obtivemos no capítulo anterior ainda pode ser usada.
Neste cenário, primeiro precisamos obter os dados do pedido de compra do usuário e, em seguida, calcular os dados da transação por hora e, em seguida, transferir os dados da transação por hora para o banco de dados e armazená-los em cache pelo Redis e, finalmente, obtê-los por meio da interface e exibi-los no a página.
A lógica de processamento do fluxo de dados neste link é:
Fluxo de dados do pedido do usuário - Conversão -> Fluxo de dados da transação por hora - Assinatura -> Gravar no banco de dados
Conforme descrito no capítulo anterior:
Fluxo de dados de origem - Conversão -> Fluxo de dados intermediário - Assinatura -> Fluxo de dados de consumo
Os pensamentos são exatamente os mesmos.
Se usarmos Marbles para descrever este processo, teremos este resultado. Parece muito simples. Parece que a mesma função pode ser feita usando o operador de janela do RxJS, mas será mesmo assim?

2 complexidade oculta
A computação em tempo real é muito mais complexa do que a programação reativa no front end. Aqui estão alguns exemplos:
Fora de serviço
No processo de desenvolvimento de front-end, também encontraremos a situação de eventos fora de ordem.O caso mais clássico é iniciar uma solicitação primeiro e, em seguida, receber uma resposta, que pode ser representada pelo seguinte diagrama de Marbles. Há muitas maneiras de lidar com essa situação no front-end, vamos ignorá-la aqui.

O que queremos apresentar hoje é a desordem de tempo enfrentada pelo processamento de dados. No desenvolvimento front-end, temos uma premissa muito importante, que reduz muito a complexidade do desenvolvimento de aplicativos front-end, ou seja: o tempo de ocorrência e o tempo de processamento dos eventos de front-end são os mesmos.
Imagine se o usuário realizar ações de página, como clicar, mover o mouse e outros eventos se tornarem eventos assíncronos e o tempo de resposta for desconhecido, então a complexidade de todo o desenvolvimento do front-end será.
No entanto, o tempo de ocorrência de um evento é diferente do tempo de processamento, que é um pré-requisito importante no campo da computação em tempo real. Ainda vamos tomar o cálculo da rotatividade horária como exemplo: Depois que o fluxo de dados original é transmitido camada por camada, a ordem dos dados no nó de computação provavelmente estará fora de ordem.

Se ainda dividirmos a janela pelo tempo de chegada dos dados, o resultado final do cálculo produzirá um erro:

Para que o resultado do cálculo da janela da janela2 seja correto, precisamos aguardar a chegada do evento tardio e realizar o cálculo, mas dessa forma nos deparamos com um dilema:
- Espere indefinidamente: o evento atrasado pode ser perdido durante a transmissão e nunca haverá saída de dados na janela2.
- O tempo de espera é muito curto: o evento atrasado ainda não chegou e o resultado do cálculo está errado.
Flink introduziu o mecanismo de marca d'água para resolver esse problema, que define quando não se deve mais esperar pelo evento atrasado, essencialmente fornecendo um meio-termo entre a precisão do cálculo em tempo real e o desempenho em tempo real.
Há uma analogia vívida sobre Marca d'água: Ao ir para a escola, o professor fecha a porta da classe e diz: "Os alunos que chegarem após este ponto são considerados atrasados e todos serão punidos." Em Flink, a marca d'água atua como o professor fechando a porta.

Contrapressão de dados
Ao usar RxJS em um navegador, gostaria de saber se você considerou tal situação: quando o observável é gerado mais rápido do que o operador ou observador, uma grande quantidade de dados não consumidos será armazenada em cache na memória. Essa situação é chamada de pressão de retorno. Felizmente, a geração de pressão de retorno de dados no front end só fará com que a memória do navegador fique muito ocupada e não haverá consequências mais sérias.
Mas, na computação em tempo real, o que deve ser feito quando a velocidade de geração de dados é maior do que a capacidade de processamento dos nós intermediários ou excede a capacidade de consumo dos dados downstream?

Para muitos aplicativos de streaming, a perda de dados é inaceitável. Para garantir isso, Flink projetou esse mecanismo:
- Em uma situação ideal, armazene os dados em um canal persistente.
- Quando a velocidade de geração de dados é maior do que a capacidade de processamento do nó intermediário, ou excede a capacidade de consumo de dados downstream, o receptor mais lento reduzirá imediatamente a velocidade do transmissor após o efeito de buffering da fila se exaurir. Uma analogia mais vívida é que quando a taxa de fluxo do fluxo de dados diminui, todo o oleoduto é "pressionado de volta" da pia à fonte de água, e a fonte de água é estrangulada para ajustar a velocidade à parte mais lenta para atingir um equilíbrio Estado.

Checkpoint
No campo da computação em tempo real, pode haver bilhões de dados processados a cada segundo, e o processamento desses dados não pode ser feito de forma independente por uma única máquina. Na verdade, no Flink, a lógica de cálculo do operador será executada por diferentes subtarefas em diferentes gerenciadores de tarefas. Neste momento, nos deparamos com outro problema. Quando uma máquina tem um problema, como a lógica geral de cálculo e o estado devem ser tratados? Certifique-se da correção do resultado final do cálculo?
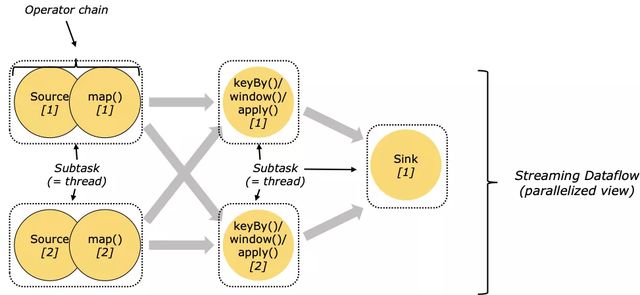
O Flink introduz um mecanismo de ponto de verificação para garantir que o status e a posição de cálculo do trabalho possam ser restaurados.O ponto de verificação faz com que o estado de Flink tenha boa tolerância a falhas. Flink usa uma variante do algoritmo Chandy-Lamport, que é chamado instantâneo de barreira assíncrona.
Quando o ponto de verificação é iniciado, ele fará com que todas as fontes registrem seus deslocamentos e insira as barreiras de ponto de verificação numeradas em seu fluxo. Essas barreiras marcarão a parte do fluxo antes e depois de cada ponto de verificação à medida que passam por cada operador.
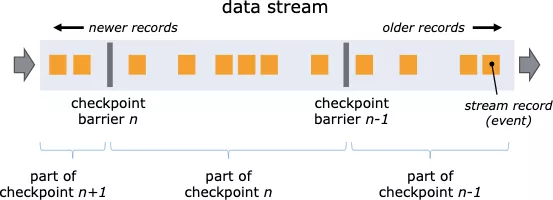
Quando ocorre um erro, o Flink pode restaurar o estado de acordo com o estado armazenado no ponto de verificação para garantir a exatidão do resultado final.
ponta do iceberg
Devido a limitações de espaço, a parte apresentada hoje só pode ser a ponta do iceberg, mas
Fluxo de dados de origem - Conversão -> Fluxo de dados intermediário - Assinatura -> Fluxo de dados de consumo
O modelo é universal em programação reativa e computação em tempo real. Espero que este artigo possa lhe dar mais ideias sobre a ideia de fluxo de dados.
Este artigo é o conteúdo original do Alibaba Cloud e não pode ser reproduzido sem permissão