
1. O que é computação gráfica
O gráfico de dados modela um conjunto de objetos (vértices) e seus relacionamentos (arestas), que podem representar intuitiva e naturalmente vários objetos de entidade no mundo real e seus relacionamentos. No cenário de big data, redes sociais, dados de transações, gráficos de conhecimento, redes de transporte e comunicação, cadeias de suprimentos e planejamento de logística são todos exemplos típicos de modelagem de gráficos. A Figura 1 mostra os dados gráficos do Alibaba no cenário de e-commerce, que possui vários tipos de vértices (consumidores, vendedores, itens e dispositivos) e arestas (representando a relação de compra, visualização, comentário, etc.). Além disso, cada vértice também está associado a informações valiosas de atributos.
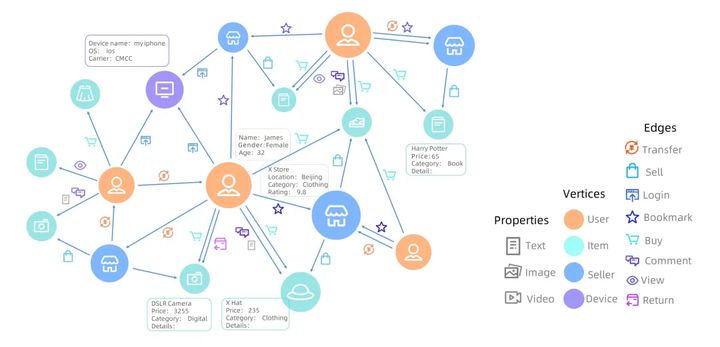
Figura 1: exemplo de dados de gráfico de cena de comércio eletrônico do Alibaba
Esses dados gráficos em cenas reais geralmente contêm bilhões de vértices e trilhões de arestas. Além da grande escala, a velocidade de atualização contínua deste gráfico também é muito rápida e pode haver quase um milhão de atualizações por segundo. Com o crescimento contínuo da escala de aplicação de dados gráficos nos últimos anos, a exploração das relações internas de dados gráficos e a computação em dados gráficos tem recebido cada vez mais atenção. De acordo com os diferentes objetivos da computação gráfica, ela pode ser dividida aproximadamente em três tipos de tarefas: consulta interativa, análise de gráfico e aprendizado de máquina baseado em gráfico.
1 consulta interativa de gráficos
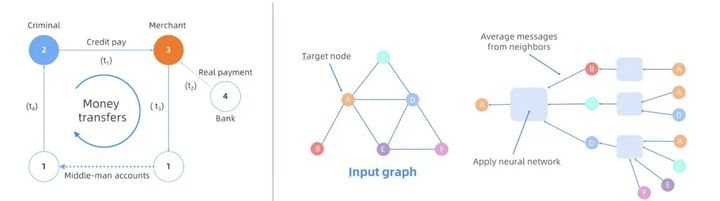
Figura 2: À esquerda, um exemplo de antifraude financeira; à direita, um exemplo de aprendizado.
Na aplicação da computação gráfica, a empresa geralmente precisa visualizar os dados do gráfico de uma forma exploratória para localizar alguns problemas no tempo e analisar algumas informações em profundidade. O modelo gráfico (simplificado) na Figura 2 (à esquerda) pode ser usado para finanças detecção antifraude (dinheiro ilegal fora do cartão de crédito). Ao usar identificadores falsos, os "criminosos" podem obter crédito de curto prazo dos bancos (Vertex 4). Ele tenta sacar a moeda com a ajuda do comerciante (vértice 3) com uma compra falsa (borda 2-> 3). Uma vez que o pagamento (borda 4-> 3) é recebido do banco (vértice 4), o comerciante retorna o dinheiro (via bordas 3-> 1 e 1-> 2) para o "criminoso" por meio de várias contas em seu nome. Este padrão eventualmente forma um loop fechado no gráfico (2-> 3-> 1 ...-> 2). Em um cenário real, a escala online de dados gráficos pode incluir bilhões de vértices (por exemplo, usuários) e centenas de bilhões a trilhões de arestas (por exemplo, transações de pagamento), e todo o processo de fraude pode envolver muitas entidades. cadeia de transações de várias restrições requer uma análise interativa em tempo real complexa para ser bem identificada.
2 Análise de gráfico
A pesquisa sobre análise e cálculo de gráfico vem acontecendo há décadas, e muitos algoritmos de análise de gráfico foram produzidos. Os algoritmos de análise de gráfico típicos incluem algoritmos de gráfico clássicos (por exemplo, PageRank, caminho mais curto e fluxo máximo), algoritmos de detecção de comunidade (por exemplo, clique máximo, cálculo de fluxo conjunto, Louvain e propagação de tag), algoritmos de mineração de gráfico (por exemplo, padrão de conjunto frequente correspondência entre mineração e gráficos). Devido à diversidade de algoritmos de análise de gráfico e à complexidade da computação distribuída, os algoritmos de análise de gráfico distribuído geralmente precisam seguir um determinado modelo de programação. O modelo de programação atual é uma espécie de modelo central "Think-like-vertex", modelo baseado em matriz e modelo baseado em subgrafo, etc. Sob esses modelos, vários sistemas de análise de gráfico surgiram, como Apache Giraph, Pregel, PowerGraph, Spark GraphX, GRAPE, etc.
3 Aprendizado de máquina baseado em gráficos
As tecnologias clássicas de Graph Embedding, como Node2Vec e LINE, têm sido amplamente utilizadas em vários cenários de aprendizado de máquina. A rede neural de grafos (GNN) proposta nos últimos anos combina a estrutura e as informações de atributos do grafo com os recursos do aprendizado profundo. GNN pode aprender representações de baixa dimensão para qualquer estrutura de gráfico no gráfico (por exemplo, vértices, arestas ou o gráfico inteiro), e as representações geradas podem ser classificadas, predição de link, agrupamento, etc. por muitas máquinas relacionadas a gráficos downstream tarefas de aprendizagem. Foi comprovado que as técnicas de aprendizado de gráficos têm um desempenho convincente em muitas tarefas relacionadas a gráficos. Diferente das tarefas de aprendizado de máquina tradicionais, as tarefas de aprendizado de gráfico envolvem gráficos e operações relacionadas à rede neural (consulte a Figura 2 à direita). Cada vértice no gráfico usa operações relacionadas ao gráfico para selecionar seus vizinhos e combinar as características de seus vizinhos Convergir com neural operações de rede.
Computação de duas imagens: a pedra angular da próxima geração de inteligência artificial
Não apenas o Alibaba, os dados gráficos e a tecnologia de computação têm sido pontos importantes na academia e na indústria nos últimos anos. Em particular, nos últimos dez anos, o desempenho dos sistemas de computação gráfica aumentou de 10 a 100 vezes, e o sistema ainda está se tornando cada vez mais eficiente, o que torna possível acelerar as tarefas de IA e big data por meio da computação gráfica. Na verdade, porque os gráficos podem expressar vários tipos complexos de dados com muita naturalidade e podem fornecer abstrações para modelos comuns de aprendizado de máquina. Em comparação com tensores densos, os gráficos podem fornecer uma semântica mais rica e funções de otimização mais abrangentes. Além disso, os gráficos são uma expressão natural de dados esparsos de alta dimensão, e mais e mais estudos em redes convolucionais de grafos (GCN) e redes neurais de grafos (GNN) provaram que a computação de grafos é um suplemento eficaz para o aprendizado de máquina e os resultados pode ser explicado. Sexo, raciocínio profundo, causalidade, etc. terão um papel cada vez mais importante.
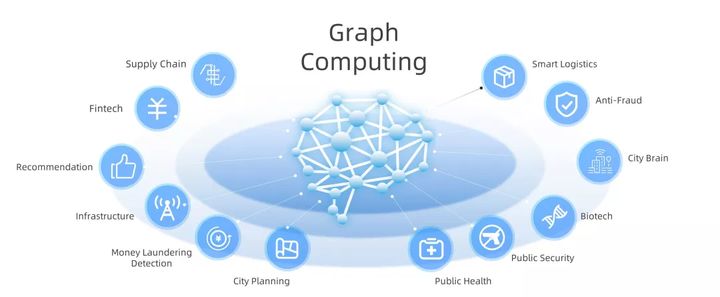
Figura 3: a computação gráfica tem amplas perspectivas de aplicação em vários campos da IA
É previsível que a computação gráfica terá um papel importante em várias aplicações de inteligência artificial de próxima geração, incluindo antifraude, logística inteligente, cérebro urbano, bioinformática, segurança pública, saúde pública, planejamento urbano, combate à lavagem de dinheiro, infraestrutura, Sistema de recomendação, tecnologia financeira e cadeia de suprimentos e outros campos.
Status de cálculo de três imagens
Após esses anos de desenvolvimento, surgiram muitos sistemas e ferramentas para várias necessidades de cálculo de gráficos. Por exemplo, em termos de consulta interativa, existem bancos de dados gráficos, como Neo4j, ArangoDB e OrientDB, bem como sistemas e serviços distribuídos, como JanusGraph, Amazon Neptune e Azure Cosmos DB; em termos de análise gráfica, existem sistemas como Pregel, Apache Giraph, Spark GraphX e PowerGraph; há DGL, geometria pytorch etc. no aprendizado de mapas. No entanto, em face de dados gráficos ricos e cenários gráficos diversificados, o uso eficaz da computação gráfica para aprimorar os efeitos de negócios ainda enfrenta enormes desafios:
- Os cenários de cálculo de gráfico na vida real são diversos e geralmente muito complexos, envolvendo vários tipos de cálculos de gráfico. Os sistemas existentes são projetados principalmente para tipos específicos de tarefas de computação gráfica. Portanto, os usuários devem decompor tarefas complexas em vários trabalhos envolvendo muitos sistemas. Muitos overheads adicionais, como integração, IO, conversão de formato, rede e armazenamento, podem ser gerados entre os sistemas.
- É difícil desenvolver aplicativos para cálculos gráficos em grande escala. Para desenvolver aplicativos de computação gráfica, os usuários geralmente usam ferramentas simples e fáceis de usar (como NetworkX e TinkerPop em Python) para começar com dados gráficos de pequena escala em uma única máquina. No entanto, para usuários comuns, é extremamente difícil estender sua solução autônoma a um ambiente paralelo para processar gráficos em grande escala. Os sistemas distribuídos existentes para gráficos de grande escala geralmente seguem diferentes modelos de programação e não possuem a rica biblioteca de algoritmos / plug-ins prontos para uso em bibliotecas autônomas (como NetworkX). Isso torna o limite para a computação de gráfico distribuído muito alto.
- A escala e a eficiência do processamento de imagens grandes ainda são limitadas. Por exemplo, devido à alta complexidade do modo de viagem, o sistema de consulta de gráfico interativo existente não pode executar consultas Gremlin em paralelo. Para sistemas de análise de gráfico, o modelo de programação centrado no ponto tradicional torna as técnicas de otimização existentes em nível de gráfico não mais disponíveis. Além disso, muitos sistemas existentes basicamente não são otimizados no nível do compilador.
Vamos dar uma olhada nas limitações do sistema existente por meio de um exemplo específico.
1 Exemplo: previsão de classificação de papel
O conjunto de dados ogbn-mag é um conjunto de dados do Microsoft Academic. Existem quatro tipos de pontos nos dados, que representam artigos, autores, instituições e campos de pesquisa. Entre esses pontos, há quatro lados que representam relações: o autor "escreveu" o artigo e o artigo "citou" outro. Para artigos, o autor "pertence" a uma instituição, e o artigo "pertence" a um campo de pesquisa. Esses dados podem ser modelados naturalmente com gráficos.
Um usuário espera realizar uma tarefa de classificação nos "artigos" publicados em 2014-2020 neste gráfico e espera ser capaz de basear o artigo nos atributos estruturais do gráfico de dados, suas próprias características de tópico e o grau de reunião, como kcore e contagem de triângulos. Os parâmetros de medição de, categorizá-los e prever a categoria de assunto do artigo. Na verdade, esta é uma tarefa muito comum e significativa.Esta previsão pode ajudar os pesquisadores a descobrir melhor o potencial de cooperação e pontos de acesso de pesquisa no campo, considerando a relação de citação do artigo e o tema do artigo.
Vamos dividir esta tarefa de cálculo: Primeiro, precisamos filtrar o papel e seus pontos e bordas relacionados de acordo com o ano e, em seguida, precisamos calcular o kcore, contagem de triângulos e outros cálculos de imagem completa neste gráfico e, finalmente, combinar esses dois parâmetros e os recursos originais no mapa são reunidos em uma estrutura de aprendizado de máquina para treinamento de classificação e previsão. Descobrimos que os sistemas atuais existentes não podem resolver este problema de ponta a ponta. Só podemos operar organizando vários sistemas em um pipeline:
Figura 4: Fluxo de trabalho composto por vários sistemas para classificação e previsão de papel
Esta tarefa parece estar resolvida.Na verdade, existem muitos problemas ocultos por trás do esquema de pipeline. Por exemplo, vários sistemas são independentes e separados uns dos outros, e dados intermediários são frequentemente colocados para transferir dados entre sistemas; o programa de análise de gráfico não é uma linguagem declarativa e não há paradigma fixo; a escala do gráfico afeta o eficiência da estrutura de aprendizado de máquina e assim por diante. Esses são os problemas que costumamos encontrar em cenários de computação gráfica do mundo real. Em resumo, eles podem ser resumidos nos três pontos a seguir:
- O problema de cálculo do gráfico é muito complicado, o modo de cálculo é diverso e a solução é fragmentada.
- O aprendizado do cálculo de gráficos é difícil, caro e tem um limite alto.
- A escala do gráfico e a quantidade de dados são grandes, o cálculo é complicado e a eficiência é baixa.
A fim de resolver os problemas acima, projetamos e desenvolvemos um sistema de computação gráfica de código aberto completo: GraphScope.
O que é GraphScope
GraphScope é uma plataforma de computação gráfica completa desenvolvida e de código aberto pelo Intelligent Computing Laboratory da Alibaba Dharma Academy. Baseando-se nos enormes dados e cenários ricos de Ali, e na pesquisa de alto nível da Dharma Academy, a GraphScope está empenhada em fornecer soluções completas e eficientes para os desafios mencionados acima na produção real de cálculos de mapas.
GraphScope fornece um cliente Python, que pode conectar facilmente fluxos de trabalho upstream e downstream. Ele tem as características de um único ponto, desenvolvimento conveniente e desempenho extremo. Ele tem um gerenciamento de memória cruzado eficiente, oferece suporte à otimização de compilação distribuída Gremlin pela primeira vez na indústria e oferece suporte à paralelização automática de algoritmos e processamento incremental automático de atualizações dinâmicas de gráficos, fornecendo o melhor desempenho em cenários de nível empresarial. Nos aplicativos internos e externos do Alibaba, GraphScope provou alcançar um novo valor de negócios importante em várias áreas-chave da Internet (como controle de risco, recomendações de comércio eletrônico, publicidade, segurança de rede, gráficos de conhecimento, etc.).
GraphScope reúne uma série de resultados de pesquisa acadêmica da Dharma Academy. Sua tecnologia principal ganhou o prêmio de melhor artigo do SIGMOD2017, o prêmio de melhor apresentação VLDB2017, o prêmio de nomeação de melhor artigo VLDB2020 e o prêmio SAIL da competição mundial de inovação em inteligência artificial. O artigo sobre o mecanismo de consulta interativo do GraphScope também foi aceito pela NSDI 2021 e será publicado em breve. Existem mais de uma dúzia de resultados de pesquisa em torno do GraphScope publicados nas principais conferências acadêmicas ou periódicos da área, como TODS, SIGMOD, VLDB, KDD, etc.
1 Introdução à arquitetura
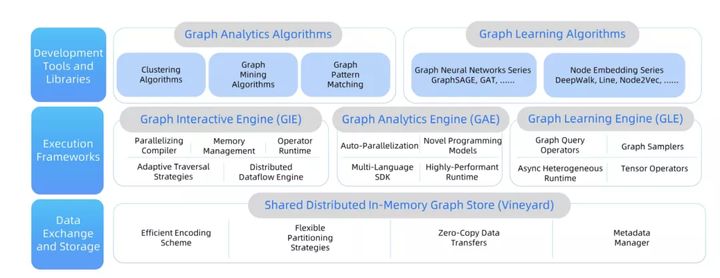
Figura 5: diagrama da arquitetura do sistema GraphScope
A camada inferior do GraphScope é uma vinha de sistema de gerenciamento de dados de memória distribuída [1]. Vineyard também é um projeto de código aberto nosso. Ele fornece uma interface IO eficiente e rica responsável por interagir com o sistema de arquivos de nível inferior. Ele fornece abstração de dados eficiente e de alto nível (incluindo, mas não se limitando a gráficos, tensor, vetor, etc.), oferece suporte para Gerenciar partições de dados, metadados, etc., e fornece leitura de dados de cópia nula nativa para aplicativos de nível superior. É este ponto que suporta a capacidade one-stop do GraphScope: entre motores cruzados, os dados gráficos existem no vinhedo na forma de partições e são gerenciados uniformemente pelo vinhedo.
No meio está a camada de mecanismo, que é composta de mecanismo de consulta interativo GIE, mecanismo de análise de gráfico GAE e mecanismo de aprendizado de gráfico GLE, que apresentaremos em detalhes nos capítulos subsequentes.
A camada superior é composta por ferramentas de desenvolvimento e bibliotecas de algoritmos. GraphScope fornece uma variedade de algoritmos de análise comumente usados, incluindo cálculos de conectividade, descoberta da comunidade e PageRank, centralidade e outros cálculos numéricos. O pacote de algoritmos continuará a ser expandido no futuro e fornecerá compatibilidade com a biblioteca de algoritmos NetworkX no super gráficos em grande escala. Habilidades de análise. Além disso, ele também fornece um pacote de algoritmo de aprendizagem de gráfico rico, suporte integrado para GraphSage, DeepWalk, LINE, Node2Vec e outros algoritmos.
2 Resolva o problema: previsão de classificação de papel
Com GraphScope, uma plataforma de computação completa, podemos resolver os problemas do exemplo anterior de uma forma mais simples.
GraphScope fornece um cliente Python, permitindo que cientistas de dados concluam todas as tarefas relacionadas a cálculos de gráficos em um ambiente com o qual estão familiarizados. Depois de abrir o Python, primeiro precisamos estabelecer uma sessão GraphScope.
import graphscope
from graphscope.dataset.ogbn_mag import load_ogbn_mag
sess = graphscope.sesson()
g = load_ogbn_mag(sess, "/testingdata/ogbn_mag/")No código acima, criamos uma sessão GraphScope e carregamos os dados do gráfico.
GraphScope é projetado para nativos da nuvem. Atrás de uma sessão corresponde a um conjunto de recursos k8s. A sessão é responsável pela aplicação e gerenciamento de todos os recursos nesta sessão. Especificamente, atrás da linha de código do usuário, a sessão primeiro solicita um pod do coordenador de back-end. O coordenador é responsável por toda a comunicação com o cliente Python. Após concluir sua inicialização, ele puxará um conjunto de pods de mecanismo. Cada pod neste grupo de pods tem uma instância de vinha, que juntos formam uma camada de gerenciamento de memória distribuída; ao mesmo tempo, cada pod tem três motores, GIE, GAE e GLE, e seus estados de início e parada são determinados pelo coordenador no acompanhamento sob demanda. Quando este grupo de pods é puxado e estabelece uma conexão estável com o Coordenador e conclui a verificação de integridade, o Coordenador retornará ao cliente para informar ao usuário que a sessão foi puxada com sucesso e os recursos estão prontos para iniciar o upload de imagens ou cálculos.
interactive = sess.gremlin(g)
# count the number of papers two authors (with id 2 and 4307) have co-authored
papers = interactive.execute("g.V().has('author', 'id', 2).out('writes').where(__.in('writes').has('id', 4307)).count()").one()Primeiro, configuramos um objeto de consulta interativo interativo no gráfico g. Este objeto obtém um conjunto de mecanismo de consulta interativo GIE no pod de mecanismo. O seguinte é uma declaração de consulta Gremlin padrão: O usuário deseja visualizar os artigos colaborativos de dois autores específicos nestes dados. Este extrato Gremlin será enviado ao motor GIE para desmontagem e execução.
O mecanismo GIE é composto de componentes principais, como compilador paralelo, gerenciamento de memória e agendamento, tempo de execução do operador, estratégia de viagem adaptável e mecanismo de fluxo de dados distribuído. Depois de receber a instrução de consulta interativa, a instrução será primeiro dividida pelo Compiler e compilada em vários operadores de operação. Esses operadores são então acionados e executados em um modelo de fluxo de dados distribuído. Nesse processo, cada nó de computação que contém dados de partição executa uma cópia do fluxo de dados, processa os dados na partição em paralelo e, no processo, a troca de dados é realizada em -demanda no sistema, para que as consultas Gremlin possam ser executadas em paralelo.
Na complexa gramática de Gremlin, a estratégia de viagens é muito importante e afeta o paralelismo da consulta, sua escolha afeta diretamente a ocupação dos recursos e o desempenho da consulta. Simplesmente confiar no BFS ou DFS não pode atender à demanda na realidade. A estratégia de viagem ideal geralmente precisa ser ajustada dinamicamente e selecionada com base em dados e consultas específicas. O motor GIE fornece uma configuração de estratégia de viagem adaptável, e seleciona a estratégia de viagem de acordo com os dados de consulta, modelos de Op e Custo desmontados, a fim de atingir a eficiência de execução do operador.
# extract a subgraph of publication within a time range
sub_graph = interactive.subgraph("g.V().has('year', inside(2014, 2020)).outE('cites')")
# project the projected graph to simple graph.
simple_g = sub_graph.project_to_simple(v_label="paper", e_label="cites")
ret1 = graphscope.k_core(simple_g, k=5)
ret2 = graphscope.triangles(simple_g)
# add the results as new columns to the citation graph
sub_graph = sub_graph.add_column(ret1, {"kcore": "r"})
sub_graph = sub_graph.add_column(ret2, {"tc": "r"})Depois de passar por uma série de consultas interativas para visualização de um único ponto, o usuário começa a realizar tarefas de análise de gráfico por meio das instruções acima.
Primeiro, ele usa um operador de subgráfico para extrair um subgráfico da imagem original de acordo com as condições do filtro. Por trás desse operador, o mecanismo interativo GIE executa uma consulta e, em seguida, grava o gráfico de resultado no vinhedo.
Em seguida, o usuário extrai os pontos cujo rótulo é o papel e as arestas cuja relação é citada neste novo gráfico, produz um gráfico isomórfico e chama o algoritmo K-core embutido do GAE e conta com triângulos nele. A Triangles fez cálculos analíticos em toda a imagem. Depois que os resultados são produzidos, esses dois resultados são adicionados de volta à imagem original como atributos nos pontos. Aqui, com a ajuda do gerenciamento de metadados do vinhedo e abstração de dados de alto nível, o novo sub_grafo é gerado pela transformação de uma nova coluna na imagem original, e não há necessidade de reconstruir todos os dados de toda a imagem.
O núcleo do mecanismo GAE herda o sistema GRAPE que ganhou o prêmio de melhor artigo SIGMOD2017 [2]. É composto por tempo de execução de alto desempenho, componentes de paralelização automática, SDK de suporte a vários idiomas e outros componentes. O exemplo acima usa o próprio algoritmo do GAE. Além disso, o GAE também permite que os usuários escrevam seus próprios algoritmos de forma simples e plug and play neles. Os usuários escrevem algoritmos com base no modelo PIE de programação de subgráficos ou reutilizam algoritmos de gráficos existentes sem considerar os detalhes distribuídos.O GAE fará a paralelização automática, o que reduz muito o limite alto para usuários de computação de gráfico distribuído. No momento, o GAE oferece suporte aos usuários para escrever sua própria lógica de algoritmo em C ++, Python (Java será compatível no futuro) e outras linguagens, plug and play em um ambiente distribuído. O tempo de execução de alto desempenho do GAE é baseado em MPI, com otimização muito detalhada de comunicação, organização de dados e recursos de hardware para atingir o desempenho máximo.
# define the features for learning
paper_features = []
for i in range(128):
paper_features.append("feat_" + str(i))
paper_features.append("kcore")
paper_features.append("tc")
# launch a learning engine.
lg = sess.learning(sub_graph, nodes=[("paper", paper_features)],
edges=[("paper", "cites", "paper")],
gen_labels=[
("train", "paper", 100, (1, 75)),
("val", "paper", 100, (75, 85)),
("test", "paper", 100, (85, 100))
])A seguir, começamos a usar o mecanismo de aprendizado de gráficos para classificar artigos. Primeiro, configuramos o recurso 128-dimensional do nó de papel nos dados e os dois atributos de kcore e triângulos que calculamos na etapa anterior como o recurso de treinamento. Em seguida, puxamos o mecanismo de aprendizado de gráfico GIE da sessão. Ao puxar o gráfico lg no GIE, configuramos os dados do gráfico, atributos de recursos, especificamos o tipo de borda e dividimos o conjunto de pontos em um conjunto de treinamento, um conjunto de validação e um conjunto de teste.
from graphscope.learning.examples import GCN
from graphscope.learning.graphlearn.python.model.tf.trainer import LocalTFTrainer
from graphscope.learning.graphlearn.python.model.tf.optimizer import get_tf_optimizer
# supervised GCN.
def train_and_test(config, graph):
def model_fn():
return GCN(graph, config["class_num"], ...)
trainer = LocalTFTrainer(model_fn,
epoch=config["epoch"]...)
trainer.train_and_evaluate()
config = {...}
train_and_test(config, lg)Em seguida, usamos o código acima para selecionar o modelo e fazer algumas configurações de parâmetros relacionados ao treinamento, e é muito conveniente usar o GLE para iniciar a tarefa de classificação de imagens.
O motor GLE consiste em duas partes, gráfico e tensor, que são compostas por vários operadores. A parte gráfica envolve a conexão de dados gráficos e aprendizado profundo, como iteração em lote, amostragem e amostragem negativa, e oferece suporte a gráficos isomórficos e gráficos heterogêneos. A parte do Tensor é composta por vários operadores de aprendizado profundo. No módulo de cálculo, a tarefa de aprendizado de gráfico é desmontada em operadores, e os operadores são executados de maneira distribuída durante o tempo de execução. Para otimizar ainda mais o desempenho da amostragem, o GLE armazenará em cache vizinhos remotos, pontos acessados com frequência, índices de atributos, etc. para agilizar a busca de vértices e seus atributos em cada partição. O GLE usa um mecanismo de execução assíncrona que oferece suporte a hardware heterogêneo, o que permite que o GLE sobreponha efetivamente um grande número de operações simultâneas, como E / S, amostragem e cálculos de tensores. GLE abstrai hardware de computação heterogêneo em pools de recursos (por exemplo, pool de thread de CPU e pool de fluxo de GPU) e coopera no agendamento de tarefas simultâneas de granulação fina.
Cinco performances
GraphScope não só resolve o problema de cálculo de gráfico em uma única facilidade de uso, mas também atinge o máximo em desempenho, atendendo às necessidades de nível empresarial. Usamos LDBC Benchmark para avaliar e comparar o desempenho do GraphScope.
Conforme mostrado na Figura 6, no teste de consulta interativa LDBC SNB Benchmark, GraphScope implantado em um único nó é mais do que uma ordem de magnitude mais rápido do que o sistema de código aberto JanusGraph; em implantação distribuída, a consulta interativa de GraphScope pode basicamente atingir linearidade. Escalabilidade acelerada .
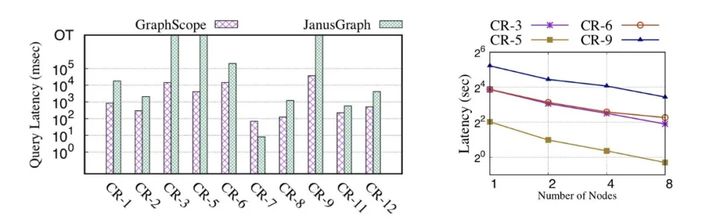
Figura 6: Desempenho de consulta interativa do GraphScope
No teste de análise de gráfico LDBC GraphAnalytics Benchmark, GraphScope compara com PowerGraph e outros sistemas mais recentes e assume a liderança em quase todas as combinações de algoritmos e conjuntos de dados. Em alguns algoritmos e conjuntos de dados, em comparação com outras plataformas, há cinco vezes a vantagem de desempenho no mínimo. Os dados parciais são mostrados na figura abaixo.
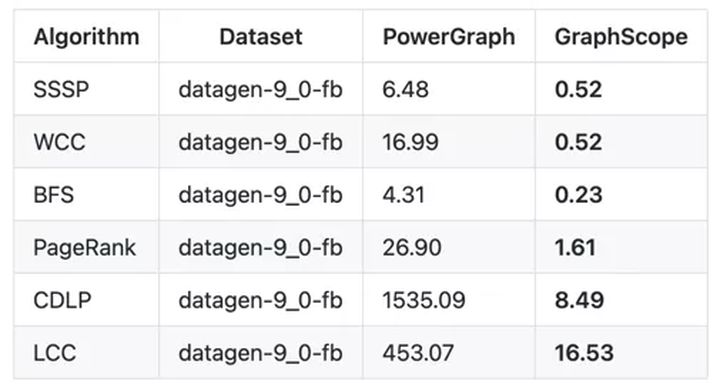
Figura 7: Desempenho da análise gráfica GraphScope
Para a configuração do experimento, reprodução e comparação completa de desempenho, consulte desempenho de consulta interativa [3] e desempenho de análise de gráfico [4].
Seis abraçam o código aberto
O white paper e o código do GraphScope foram abertos em http://github.com/alibaba/graphscope[5 ] e o projeto está em conformidade com a Licença Apache 2.0. Bem-vindo a todos para começar, experimentar e participar de cálculos gráficos. Você também é bem-vindo para contribuir com código para construir o melhor sistema de computação gráfica do setor. Nosso objetivo é atualizar continuamente o projeto e melhorar continuamente a integridade da função e a estabilidade do sistema. Você também pode seguir o site http://graphscope.io para acompanhar o status mais recente do projeto.
Este artigo é o conteúdo original do Alibaba Cloud e não pode ser reproduzido sem permissão.