Guia
Guia do Alimei: Inter-regional, ou seja, o conceito de "dupla vida remota" e "vida múltipla remota". No caso de rápido desenvolvimento de negócios, nossos serviços precisam ser implantados em todas as regiões para atender às necessidades de acesso próximo e recuperação de desastre interregional em várias regiões. Nesse processo, é inevitável que a consistência distribuída interregional esteja envolvida. problema. O problema de atraso de rede causado pela rede interregional, assim como uma série de problemas derivados do atraso da rede, é um grande desafio para o projeto e construção de um sistema de consistência distribuída interregional. A indústria tem muitas soluções para isso Todos esperam resolver o problema de consistência em cenários inter-regionais.

Este artigo compartilha a exploração da equipe Nüwa do Alibaba de sistemas de consistência distribuída em cenários interregionais. Dos três aspectos de "What How Future", apresenta as necessidades e desafios a serem empreendidos em cenários interregionais, sistemas comuns na indústria e Nüwa equipe Pensar nos trade-offs de cenários inter-regionais, bem como desenhar e pensar no desenvolvimento futuro do sistema de consistência inter-regional, para descobrir e resolver mais necessidades e desafios em cenários inter-regionais.
1. Necessidades e desafios inter-regionais
1 demanda
As questões inter-regionais são desafios gerados pelo rápido desenvolvimento dos negócios sob a estratégia de globalização do grupo. Por exemplo, o negócio unitizado da Taobao ou o negócio regionalizado do AliExpress tem um problema inevitável: a consistência da leitura e gravação de dados nas regiões.
Os requisitos principais podem ser resumidos como o seguinte:
- Cenários de negócios interregionais
Sincronização de configuração inter-regional e descoberta de serviço são dois requisitos de negócios comuns para serviços de coordenação consistente inter-regional. A implantação inter-regional pode fornecer recursos de acesso próximo para reduzir atrasos de serviço. De acordo com cenários de negócios específicos, pode ser dividido em redação multirregional ou Cenários únicos simplificados, como gravação regional, leitura de consistência forte ou leitura de consistência eventual. O gerenciamento de sessão entre regiões e bloqueios distribuídos entre regiões com base nisso também precisam fornecer soluções maduras com urgência.
- Expansão de serviços e recursos
Quando a capacidade de serviço de uma determinada sala de computadores em uma região atinge o limite superior e não pode ser expandida, um sistema consistente é necessário para expandir no nível de várias salas de computadores em uma região e ser capaz de se expandir entre as regiões.
Tolerância a desastres entre regiões
Ao encontrar uma falha catastrófica em uma sala de informática ou região, um sistema consistente é necessário para migrar rapidamente as empresas de uma região para outra por meio da implantação de serviço entre regiões para concluir a recuperação e fuga de desastres e alcançar alta disponibilidade.
2 Desafio
Combinando a latência da rede e os requisitos de negócios, podemos resumir os desafios que um sistema de consistência inter-regional precisa resolver:
- Latência: atraso da rede de até dezenas de milissegundos
O principal problema trazido pela implantação multirregional é a alta latência da rede. Veja nossa implantação on-line interregional de clusters interregionais como exemplo. As máquinas no cluster pertencem às quatro regiões de Hangzhou, Shenzhen, Xangai e Pequim. O teste real da sala de informática de Hangzhou O atraso para Xangai é de cerca de 6 ms, e o atraso para Shenzhen e Pequim pode chegar perto de 30 ms. A latência de rede da mesma sala de computadores ou da sala de computadores da mesma região é geralmente em milissegundos. Em contraste, a latência de acesso entre regiões aumentou em uma ordem de magnitude.
- Expansão horizontal: os servidores quorum são limitados em escala
O sistema de consistência distribuída baseado na teoria de Paxos e suas variantes inevitavelmente encontrará o problema Replication Overhead ao expandir os nós. Geralmente, o número de nós em um quorum não é maior que 9, então é impossível simplesmente implantar os nós do sistema de consistência diretamente no vários nós. Nesta região, o sistema precisa ser capaz de se expandir continuamente horizontalmente para atender às necessidades de expansão de serviços e recursos.
- Limite de armazenamento : os dados de armazenamento de um único nó são limitados e a recuperação de failover é lenta
Quer seja MySQL ou um sistema de consistência baseado em Paxos, um único nó manterá e carregará a quantidade total de dados espelhados, que serão limitados pela capacidade de um único cluster. Ao mesmo tempo, durante a recuperação de failover, se a versão dos dados estiver muito atrasada, ela ficará indisponível por um longo tempo para restaurar puxando outros espelhos regionais.
2. Nossa exploração
1 Soluções para a indústria
A indústria tem muitos projetos para sistemas de consistência interregional, principalmente referindo-se ao artigo [1] e algumas implementações de código aberto. Aqui estão algumas mais comuns:
Implantação inter-regional
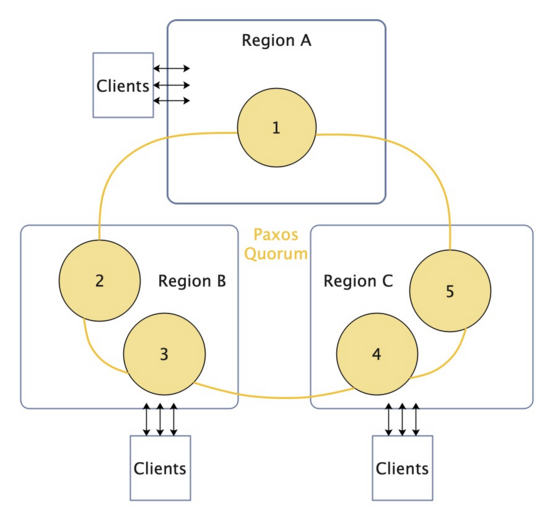
Figura 1 Implantação direta interregional
Implantado diretamente em todas as regiões, as solicitações de leitura leem diretamente os nós de domínio local, com mais rapidez, consistência e disponibilidade garantidas pelo Paxos e não há um único ponto de problema. As deficiências também são óbvias.Você encontrará o problema de expansão de nível mencionado na primeira parte, ou seja, o problema de sobrecarga de replicação será encontrado quando o Quorum se expandir. E conforme o número de nós do Quorum aumenta, sob a latência de rede extremamente alta entre as regiões, leva muito tempo para a maioria chegar a um acordo a cada vez, e a eficiência de gravação é muito baixa.
Implantação em uma única região + função de aluno
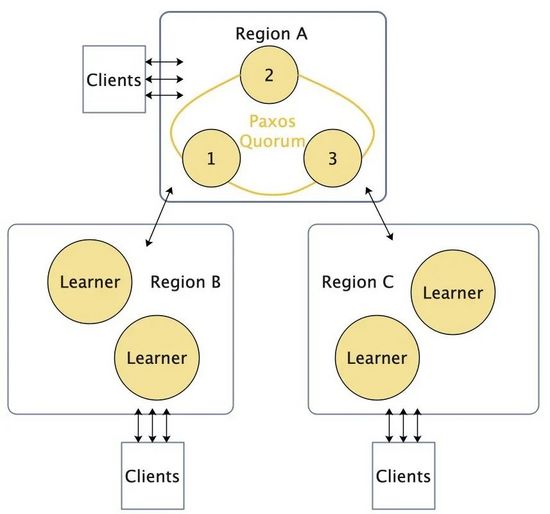
Figura 2 Apresentando a função de aluno
Ao introduzir a função de Aprendiz (como Observador em zk, aprendiz raft [2] do etcd), ou seja, uma função que apenas realiza sincronização de dados sem participar da votação majoritária, a solicitação de gravação é encaminhada para uma determinada região (Região A na Figura 2), para evitar o problema de atraso na votação da implantação direta de vários nós. Esse método pode resolver o problema de expansão horizontal e atraso, mas como as funções que participam da votação são todas implantadas em uma região, quando a sala de informática dessa região passa por um momento catastrófico, o serviço de redação ficará indisponível. Este método é o método de implantação adotado por Otter [3].
Multi-serviço + Partição e implantação em uma única região + Aluno
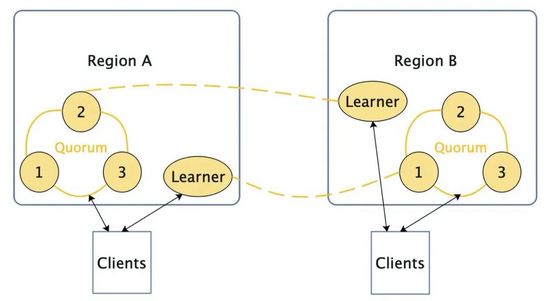
Figura 3 Partição de processamento de vários serviços
Divide os dados em diferentes partições de acordo com as regras, cada região fornece um Quorum para fornecer serviços, diferentes regiões Quorum é responsável por diferentes partições, entre regiões Quorum usa o Learner para sincronizar diferentes pedidos de preenchimento de dados de partição e encaminhamentos, para garantir que problemas em um determinada região afeta apenas a disponibilidade da partição da região. Ao mesmo tempo, haverá problemas de correção neste tipo de esquema, ou seja, a operação não se conforma com o problema de consistência sequencial [4] (ver artigo [1]).
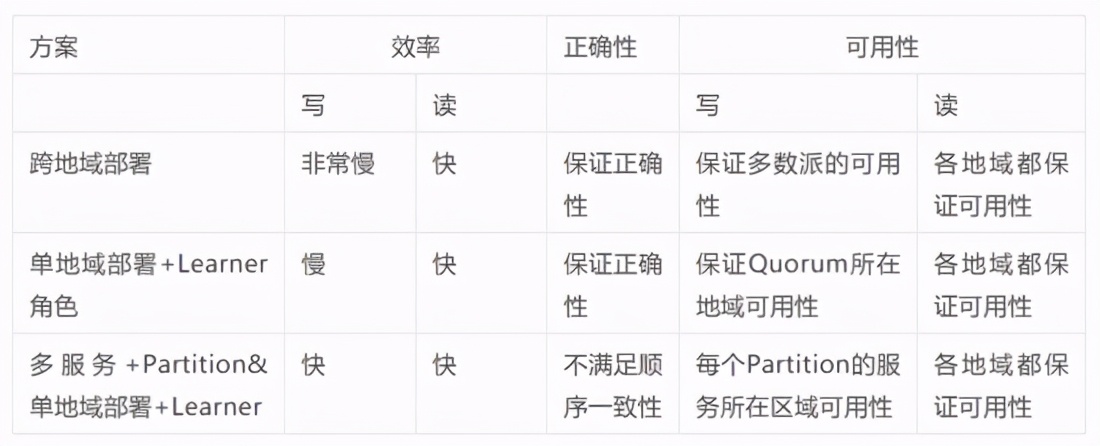
Na implementação real, existem várias soluções de acordo com os cenários de negócios, que serão otimizadas e ponderadas para compensar os defeitos. A solução mais comum na indústria é uma implantação de região única + função de aluno, que garante alta disponibilidade e alta eficiência por meio de várias atividades na mesma cidade e sincronização de dados entre regiões com o aluno. Outras soluções também têm suas próprias soluções de otimização. A implantação entre regiões pode reduzir os problemas de latência e largura de banda, reduzindo a comunicação inter-regional ao chegar a uma resolução, como a replicação de seguidor de TiDB [5]; multi-serviço + partição e implantação de uma única região + Aprendiz: A correção do esquema também pode ser descrita no artigo [1], adicionando uma operação de sincronização antes da leitura, sacrificando parte da disponibilidade de leitura para garantir a consistência.
A conclusão final é a seguinte, e os itens principais serão explicados em detalhes posteriormente:
2 trade-offs entre regiões
Por meio dos requisitos e desafios resumidos na primeira parte e na pesquisa anterior sobre as soluções do sistema de consistência inter-regional da indústria, podemos resumir as principais compensações do sistema de consistência distribuída baseado em Paxos em cenários inter-regionais:
- O acordo de consistência inter-regional de operações de gravação para chegar a uma resolução é muito lento
- Multi-life na região não pode fornecer disponibilidade em condições extremas
- Precisa ter a capacidade de expansão de nível central de um sistema distribuído
Em resposta a esses três problemas, projetamos um sistema de consistência interregional com desacoplamento de espelhamento de log.
3 Desacoplamento de espelhamento de log interregional
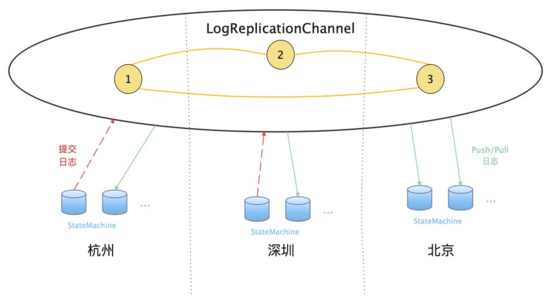
Figura 4 Diagrama esquemático de desacoplamento de espelhamento de log
Conforme mostrado na Figura 3, nosso sistema é dividido em um canal de sincronização de log de back-end e uma máquina de estado completo de front-end - uma arquitetura de desacoplamento de log e espelhamento. O canal de sincronização de log global entre regiões de back-end é responsável por garantir a consistência forte dos logs de solicitação em várias regiões; a máquina de estado completo de front-end é implantada em cada região para processar solicitações de cliente e também é responsável por interagir com o back -end serviço de log para fornecer forte consistência global externamente Serviço de acesso de metadados, a interface pode ser implementada modificando rapidamente a máquina de estado de acordo com os requisitos de negócios.
Sob a arquitetura onde o log global é separado do espelhamento local, além das melhorias de operação e manutenção do sistema e escalabilidade trazidas pelo próprio desacoplamento, também podemos resolver muitos problemas sob a arquitetura desacoplada. A análise a seguir é baseada nisso arquitetura Como resolver os principais problemas nas reflexões anteriores:
Eficiência de escrita
Do ponto de vista do modo de implantação, é semelhante ao método de implantação direta multirregional em vários nós e, em seguida, adicionar a função de Aluno em cada região. É uma combinação de implantação direta em vários nós e a introdução de Aluno, que combina as vantagens e desvantagens dos dois métodos. A maior diferença é que nossos logs e espelhos são desacoplados, o que significa que a parte interregional é uma sincronização de log simples que é leve e eficiente e, como cada região tem apenas um nó, pode economizar largura de banda interregional (semelhante para a replicação do seguidor do TiDB). Ao mesmo tempo, o canal de sincronização de log de back-end também pode realizar a função de vários grupos, dividindo os dados em Partições, e cada grupo consistente é responsável por diferentes Partitons.
Como a maioria das operações de leitura em cenários de negócios estão lendo dados locais, os vários métodos não são muito diferentes, principalmente para a análise de atraso da operação de gravação, o seguinte é a análise de atraso para a operação de gravação (ou leitura de consistência forte):
RTT (Round-Trip Time) pode ser entendido simplesmente como o tempo decorrido desde o envio da solicitação até a resposta do remetente. Devido ao grande atraso da rede inter-regional, o RTT a seguir se refere principalmente ao RTT inter-regional.
(1) Implantar diretamente nas regiões
Para um acordo básico comum, nosso pedido é dividido em duas situações:
- 1 RTT na região onde o líder é visitado (ignorando o menor atraso na região por enquanto)
Client -> Leader ----> Follower ----> Leader -> Client- Visite 2 RTTs na localização do Seguidor
Client -> Follower ----> Leader ----> Follower ----> Leader ----> Follower -> Client(2) Implantação em uma única região + sincronização do aluno
No esquema de ser mais ativo em uma região e aprender a sincronização do aluno entre as regiões, nosso atraso é:
- 0 RTT para domínio local
Client -> Quorum -> Client- 1 RTT entre regiões
Client -> Learner ----> Quorum ----> Learner -> Client(3) Partição multisserviço, implantação de região única + sincronização do aluno (semelhante ao resultado B)
- Grava 0 RTT da partição de domínio local
- Escreva 1 RTT na partição
(4) Arquitetura de desacoplamento de espelho de log (semelhante ao resultado de A)
- Gravar domínio local Partiton 1 RTT
Client ->Frontend -> LogChannel(local) ----> LogChannel (peer) ----> LogChannel (local) -> Frontend -> Client- Grave 2 RTTs nas partições (Paxos two-phase commit / forward leader)
Client ->Frontend -> LogChannel (local) ----> LogChannel (peer) ----> LogChannel (local) ----> LogChannel (peer) ----> LogChannel (local) -> Frontend -> ClientApós a comparação acima, pode-se ver que, enquanto o protocolo de consistência for usado para operações de gravação entre regiões, haverá pelo menos 1 atraso de RTT. Se o Paxos Quorum for implantado apenas em uma única região, ele não pode garantir a disponibilidade em quaisquer casos extremos. Portanto, podemos equilibrar a disponibilidade e a eficiência de gravação de acordo com as necessidades do negócio. A arquitetura de desacoplamento de espelhamento de log pode garantir extrema disponibilidade e exatidão em cenários de implantação multirregional. Claro, a eficiência será um pouco pior do que implantação de região única + aluno. No entanto, a implantação multirregional é mais leve e eficiente do que a implantação multirregional direta, porque a escala do quorum não aumentará devido à expansão horizontal e não afetará a eficiência do voto. A solução com implantação de partição multisserviço não tem vantagens de eficiência, mas tem vantagens em termos de transportabilidade, exatidão e disponibilidade.
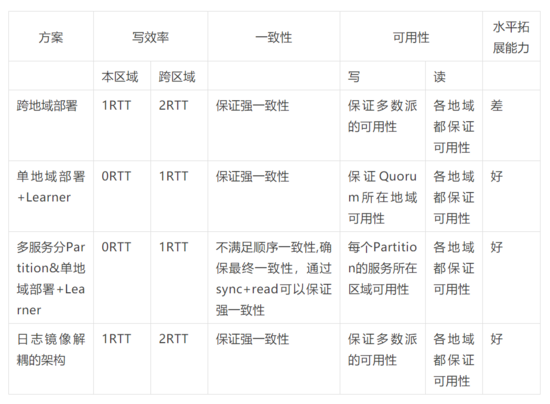
A forte consistência entre a implantação em várias regiões e a implantação em uma única região + Learner é satisfatória. Zookeeper e etcd têm introduções correspondentes, então não vou repeti-las aqui. A solução de Partição e Partição multisserviço não satisfaz a consistência sequencial, principalmente porque multisserviço não pode garantir a ordem de cada commit da operação de gravação, conforme mostrado na figura abaixo:

Figura 5 Consistência da sequência
Pode-se ver que, quando dois clientes modificam xey ao mesmo tempo, no caso de um alto grau de operações de gravação simultâneas, a consistência sequencial não pode ser garantida.
A consistência da sequência significa que as operações de cada cliente podem ser organizadas em uma ordem correta. No exemplo da Figura 4:
set1(x,5) => get1(y)->0 => set2(y,3) => get2(x)->5 ou
set2(y,3) => get2(x)->0 => set2(y,3) => get1(y)->3 Todos estão alinhados com a consistência sequencial.
A consistência da arquitetura de desacoplamento do espelhamento de log pode ser simplesmente entendida como implantação inter-regional + Aprendiz. A operação de gravação tem uma opção de sincronização. Ela retornará sucesso apenas quando o log de back-end for enviado com êxito e o log correspondente for retirado. ele deve ser puxado para o log correspondente à operação de gravação de outros clientes antes desta operação, ele está em conformidade com a consistência sequencial.
- Disponibilidade
A disponibilidade é semelhante à disponibilidade de implantação de vários nós diretos entre regiões. A máquina de estado de front-end pode encaminhar solicitações quando o nó de back-end de uma determinada região está inativo. Também pode fornecer disponibilidade de leitura quando o back-end global serviço de log indisponível. Garantia de alta disponibilidade para leitura e gravação em casos extremos.
Ao mesmo tempo, como a imagem é armazenada na máquina de estado de cada região, quando uma máquina de estado front-end desliga, o cliente pode ser alternado para outros front-ends. Quando o failover é restaurado, os dados também podem ser extraídos diretamente do back-end para restaurar, no caso de muito atraso. Só é necessário puxar espelhos de outros front-ends no domínio local, em vez de sincronizar espelhos entre regiões, o que pode tornar o tempo do front-end extremamente indisponível baixo.
- Habilidade de desenvolvimento de nível
A capacidade de expansão horizontal é a capacidade principal de serviços distribuídos. Entre as várias soluções mencionadas, a capacidade de expansão horizontal para implantação direta interregional é extremamente pobre. Outros métodos que dependem do Aprendiz também resolvem o problema de expansão horizontal, mas o desacoplamento não tem log solução de espelhamento. O design acoplado é simples.
Resuma e compare os principais problemas acima:
Três, mais possibilidades nas regiões
Com o log de back-end e o espelhamento de front-end desacoplados, nossa exploração de cenários interregionais é dividida em duas partes - a sincronização de log de back-end é leve e eficiente e a máquina de estado de front-end é flexível e rica.
- O peso leve se reflete na arquitetura. A pressão de armazenamento de back-end causada apenas pela sincronização de logs no back-end é mínima, e apenas logs incrementais leves são sincronizados.
- Eficiente, conforme refletido no protocolo de consistência de back-end, devido ao seu peso leve, apenas a lógica de votação e eleição precisa ser considerada, e apenas a melhoria da eficiência de sincronização de log é necessária, e os recursos de back-end não são consumidos em outra lógica de negócios.
- A flexibilidade se reflete na arquitetura.O front-end pode personalizar o log de upload, e CAS, transações, etc. podem ser empacotados em logs para análise e processamento pelo front-end.
- A abundância se reflete principalmente na máquina de estado no front end. Como a flexibilidade do log nos deixa com muito espaço para exploração e construção, podemos empacotar uma máquina de estado para lidar com várias transações complexas de acordo com as necessidades.
Existem novos problemas na nova arquitetura. Esta parte explora principalmente como absorver as vantagens dos sistemas existentes e usar a leveza e a flexibilidade do desacoplamento do espelhamento de log para perceber a eficiência e a riqueza dos protocolos de consistência e máquinas de estado em cenários interregionais Haverá também uma reflexão e um plano para o desenvolvimento subsequente do sistema de consistência inter-regional. O objetivo geral é tornar o protocolo de consenso de back-end mais sofisticado e a máquina de estado de front-end maior e mais forte.
1 Protocolo de consenso de back-end eficiente
Com base em nossa discussão anterior sobre a eficiência das operações de gravação, no cenário de gravação dos mesmos dados em várias regiões, o atraso só pode ser controlado em 2RTT. Como no cenário inter-regional, a taxa de atraso está principalmente na comunicação de rede inter-regional, seja um encaminhamento mestre ou um commit de duas fases Paxos não proprietário, o atraso tem 2RTT. No entanto, se você usar um protocolo sem proprietário, como a variante Paxos EPaxos [6], você pode melhorar a eficiência da gravação em cenários interregionais tanto quanto possível. O atraso é dividido em Fast Path e Slow Path. O atraso é 1RTT em Fast Path. O atraso em Slow Path é 2RTT.
Citando uma frase do artigo que apresenta EPaxos:
Se não houver conflito entre os logs de propostas concorrentes, o EPaxos só precisa executar a fase PreAccept para enviar (Fast Path), caso contrário, ele precisa executar a fase Accept para enviar (Slow Path).
Comparado com a operação de partição, se o protocolo de consistência back-end for selecionado como EPaxos, ele pode garantir a disponibilidade em casos extremos e o atraso de 1RTT na maioria dos casos.Esta é a vantagem do protocolo de consistência masterless em cenários interregionais. O principal motivo é que o RTT para encaminhamento da operação líder é omitido. Atualmente, nosso sistema usa a implementação mais básica do Paxos. No cenário de gravação de vários locais, o atraso é teoricamente semelhante ao do protocolo mestre. O desenvolvimento subsequente espera usar o EPaxos para acelerar a eficiência das operações de gravação em cenários interregionais.
Como não há necessidade de implementar várias lógicas de negócios, a eficiência é o maior requisito do protocolo de consistência de back-end. Claro, sua correção e estabilidade também são essenciais. Para a máquina de estado de front-end, existem cenários ricos para projetar e jogar.
Operação CAS
A implementação das operações do CAS nesta arquitetura é muito natural, já que o backend possui apenas um log consistente, toda requisição CAS que tivermos terá naturalmente a ordem de Commit, por exemplo.
Dois clientes gravam o valor da mesma chave ao mesmo tempo:
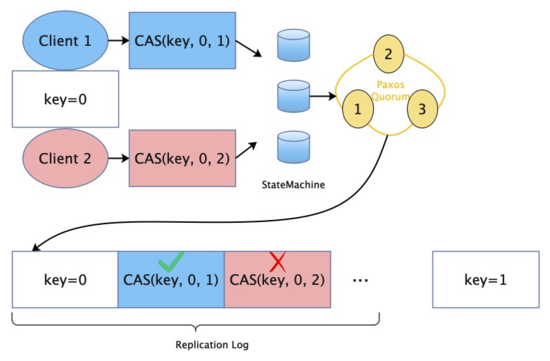
Figura 6 Diagrama esquemático da operação CAS
No início, o valor da chave é 0. Neste momento, o Cliente 1 e o Cliente 2 executam operações CAS na chave simultaneamente. Eles são CAS (chave, 0, 1) e CAS (chave, 0, 2). Quando essas duas operações são submetidas e Após Commit, devido à ordem em que o Quorum de back-end atinge a resolução, o Log de Replicação deve ter uma sequência, então, naturalmente, essas duas operações CAS simultâneas são convertidas para execução sequencial. Quando o Frontend sincroniza com o log dessas duas operações, ele aplicará essas duas operações à máquina de estado local, por sua vez. Naturalmente, CAS (chave, 0, 1) é bem-sucedido, o valor da chave de atualização é 1 e CAS (chave, 0 , 2) Se a atualização falhar, o front end retornará ao cliente correspondente o resultado de se a solicitação CAS foi bem-sucedida ou falhou.
O princípio é transformar uma operação simultânea em um processo serial executado sequencialmente, evitando assim a operação de bloqueio em cenários interregionais. É concebível que se o back-end mantém uma estrutura kv de dados, é necessário adicionar um distribuído interregional bloquear para concluir esta operação é relativamente mais complicado e a eficiência não é garantida. Ao sincronizar apenas o log para transferir cálculos complexos para o Frontend, a máquina de estado do front-end pode ser construída de forma flexível para implementar melhor o CAS ou funções de transação mais complexas (para esta arquitetura, consulte StateSynchronizer [7] de Pravega).
ID global
A ID global é um requisito comum. Os sistemas distribuídos geram uma ID exclusiva. Normalmente usados são UUID, algoritmos de flocos de neve ou soluções baseadas em bancos de dados, redis e zookeeper.
Semelhante a usar a versão de dados znode do zookeeper para gerar o ID global, nesta arquitetura de separação de espelhamento de log, você pode usar a interface CAS para chamar, gerar uma chave como o ID global e executar operações atômicas no ID global a cada vez. Com base no design do CAS acima, não há necessidade de bloquear cenários de simultaneidade entre regiões e o uso é semelhante ao redis para operações atômicas em chaves.
2 Operação do relógio
A função de assinatura é indispensável para serviços de coordenação distribuídos e é o requisito de negócios mais comum. A seguir estão os resultados da pesquisa de zk e etcd:
Atualmente, os sistemas de coordenação distribuída mais maduros do setor que implementam notificações de assinatura incluem ETCD e ZooKeeper. Tomamos esses dois sistemas como exemplos para explicar suas soluções.
ETCD salvará várias versões históricas (MVCC) de dados e indicará as versões novas e antigas aumentando monotonicamente os números das versões. Contanto que o cliente passe na versão histórica que lhe interessa, o servidor pode enviar todos os eventos subsequentes para o cliente.
O Zookeeper não salva várias versões históricas de dados, apenas o estado atual dos dados, o cliente não pode se inscrever na versão histórica dos dados, o cliente só pode se inscrever no evento de mudança após o estado atual, então a inscrição é acompanhada pela leitura Os dados são enviados ao cliente e os eventos subsequentes são enviados. Ao mesmo tempo, para evitar a assinatura de dados antigos e eventos em cenários anormais, como failover, o cliente se recusará a se conectar ao o servidor com os dados mais antigos (isso depende do servidor A solicitação retornará o XID global do servidor atual).
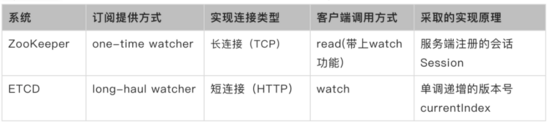
Nos resultados da pesquisa acima, ETCD está mais de acordo com nosso design de interface. Atualmente, ETCDv3 usa multiplexação de link TCP / 2 TCP e o desempenho do relógio é aprimorado. Por ser o mesmo log mais a estrutura da máquina de estado, a função de design se refere principalmente ao ETCD v3 e aprende com suas duas características de como assinar várias chaves e retornar todos os eventos históricos. Para realizar a função de assinatura do etcd, quando sincronizamos a máquina de estado front-end e analisamos o log, se um log for escrito, o armazenamento da máquina de estado da estrutura kv e a máquina de estado watchableStore especialmente fornecida para a interface de observação serão atualizados ao mesmo tempo. A implementação específica pode ser totalmente referenciada etcd, então, de acordo com o número da versão do log, todos os eventos históricos após a versão da assinatura são retornados ao cliente. A assinatura de várias chaves também usa a árvore de segmento de linha como a estrutura de armazenamento de chaves de intervalo do inspetor, que pode implementar notificações do inspetor para chaves de intervalo de observação.
3 Mecanismo de locação
É um grande desafio implementar um mecanismo de concessão eficiente em um sistema sem proprietário. Não há líder em um sistema sem proprietário. Qualquer nó pode manter a concessão. A concessão é distribuída em cada nó. Quando um nó não está disponível, ele precisa ser alternado sem problemas para outros nós. A dificuldade de implementar um mecanismo de Lease eficiente em um sistema sem proprietário é como evitar um grande número de mensagens de manutenção de Lease no protocolo de consistência de back-end conforme o número de Lease aumenta, o que afeta o desempenho do sistema. É melhor fazer mensagens de manutenção de Lease diretamente no front-end. Processamento sem passar pelo back-end. Portanto, nossa ideia é agregar o Lease do cliente e o front-end ao Lease do front-end e o back-end, para que as mensagens de manutenção do Lease possam ser processadas diretamente localmente no front-end.
Quatro, conclusão
Com o avanço da estratégia de globalização, as necessidades inter-regionais se tornarão cada vez mais urgentes, e os verdadeiros pontos problemáticos dos cenários inter-regionais ficarão cada vez mais claros. Espero que nossa pesquisa e exploração inter-regional possam lhe dar uma ideia e referência., Continuaremos a explorar mais possibilidades sob a arquitetura de separação de espelhamento de log interregional.
Espero poder ajudá-lo a aprender sistemas distribuídos até certo ponto, e seus amigos favoritos podem ajudar o LZ a seguir adiante, obrigado! (LZ também fará o possível para compartilhar valiosos materiais de aprendizagem com você!)