Há poucos dias, um pequeno parceiro nos leitores perguntou: Depois que o processo foi criado, como entrei na função principal que escrevi?
Hoje esse artigo vai falar sobre esse assunto.
Defina primeiro o escopo da discussão deste problema: Linguagem C / C ++
Este artigo discute principalmente a criação e inicialização de processos e threads no nível do sistema operacional , e como linguagens como Python e Java baseadas em interpretadores e máquinas virtuais podem entrar na execução da função principal. O caminho por trás disso é mais longo. (Incluindo o processo de execução interna do intérprete e da máquina virtual), tenho a oportunidade de discutir isso mais tarde. Portanto, aqui nos concentramos em como a função principal das linguagens nativas, como C / C ++, é inserida.

Este artigo irá descrever o processo detalhado nas duas plataformas principais de Linux e Windows .
Processo de criação
A primeira etapa é criar um processo.
No Linux, precisamos iniciar um novo processo, que geralmente é implementado por meio da série de funções fork + exec . O primeiro "bifurca" o processo atual em um processo filho gêmeo, e o último é responsável por substituir o arquivo de execução deste processo filho para executar o filho O novo arquivo de programa do processo.
As séries de funções fork e exec aqui são funções API fornecidas pelo sistema operacional ao programa de aplicativo. Elas eventualmente entrarão no kernel do sistema operacional por meio de chamadas de sistema e concluirão a criação de um processo por meio do mecanismo de gerenciamento de processo no kernel.
O kernel do sistema operacional será responsável pela criação do processo, e existem principalmente as seguintes tarefas a serem realizadas:
Crie uma estrutura de dados usada para descrever o processo no kernel, task_struct no Linux
Crie o diretório da página e a tabela da página do novo processo para construir o espaço de endereço de memória do novo processo
No kernel Linux, devido a razões históricas, o kernel Linux inicial não tinha o conceito de thread , mas usava task: task_struct para descrever a instância de execução de um programa: process .
No kernel, uma tarefa corresponde a uma task_struct , ou seja, um processo, e a unidade de agendamento do kernel também é uma task_struct .
Mais tarde, o conceito de multithreading surgiu. Para oferecer suporte à tecnologia de multithreading no kernel do Linux, task_struct realmente representa um thread, e um processo é descrito combinando vários task_structs em um grupo (através do campo group id dentro da estrutura) . Portanto, os threads no Linux também são chamados de processos leves .
Uma importante missão da bifurcação de chamada de sistema é criar a estrutura task_struct do novo processo.Depois que a criação for concluída, o processo terá a unidade de programação. Posteriormente, você pode participar do agendamento e ter a oportunidade de ser executado.
Carregar arquivo executável
Depois que o processo é criado com sucesso por fork , o processo filho e o processo pai neste momento são equivalentes a uma célula em mitose, e os dois processos são "quase" idênticos.
Para que o processo filho execute um novo programa, a série exec de funções também é necessária no processo filho para substituir o programa executável do processo.
A série de funções exec também é o encapsulamento de chamadas de sistema. Ao chamá-las, elas entrarão no kernel sys_execve para realizar trabalho real.
Existem muitos detalhes deste trabalho, e uma das tarefas importantes é carregar o arquivo executável no espaço do processo e analisá-lo para extrair o endereço de entrada do arquivo executável .
Utilizamos o código escrito em linguagens de alto nível como C e C ++, e finalmente o arquivo executável será compilado pelo compilador.No Linux, ele está no formato ELF.No Windows, é chamado de arquivo PE .
Independentemente de se tratar de um arquivo ELF ou PE, em seus respectivos cabeçalhos de arquivo, fica registrado o endereço de entrada da instrução do arquivo executável, que indica onde o programa deve ser executado.
De onde vem esse ponto de entrada? É nossa função principal ? Aqui está um ponto-chave para resolver o problema anterior: como o processo chegou a esse endereço de entrada depois que o processo foi criado?
Não importa no Windows ou Linux, os threads de aplicativos muitas vezes vão e voltam entre o espaço do usuário e o espaço do kernel. Isso pode ocorrer nas seguintes situações:
Chamada de sistema
Interromper
anormal
Ao retornar do kernel, como o thread sabe de onde veio e para onde retornar ao espaço do aplicativo para continuar a execução?
A resposta é que, ao entrar no espaço do kernel, o encadeamento salvará automaticamente o contexto (na verdade, o conteúdo de alguns registros, como o registro de instrução EIP) na pilha do encadeamento, registrará de onde veio e esperará até que ele retorne do kernel e, em seguida, da pilha Carregue essas informações e retorne ao local original para continuar a execução.
Conforme mencionado anteriormente, o processo filho entra no kernel por meio da chamada de sistema sys_execve . Após a análise do arquivo executável ser concluída posteriormente, o endereço de entrada do arquivo ELF é obtido e as informações de contexto originalmente salvas na pilha serão modificadas para alterar o EIP Aponte para o endereço de entrada do arquivo ELF. Desta forma, quando a chamada de sistema sys_execve terminar, após retornar ao espaço do usuário, você pode ir diretamente para a nova entrada do programa e começar a executar o código.
Portanto, um recurso muito importante é: A série de funções exec não retornará em circunstâncias normais. Uma vez inserida, o fluxo de execução mudará para a nova entrada do arquivo executável após a missão ser concluída .
Outra coisa a ser mencionada é que além dos arquivos ELF, o Linux também oferece suporte a arquivos executáveis em outros formatos, como MS-DOS e COFF.
Além de arquivos binários executáveis, scripts de shell também são suportados. Neste caso, o programa interpretador de scripts será usado como ponto de entrada para iniciar
Da entrada ELF para a função principal
O acima explica como um novo processo é executado para o endereço de entrada do arquivo executável.
Ao mesmo tempo, há uma pergunta: qual é o endereço de entrada? É nossa função principal?
Aqui está um programa C simples que produzirá o clássico hello world após a execução:
#include <stdio.h>
int main() {
printf("hello, world!\n");
return 0;
}
Após a compilação com gcc, um arquivo executável ELF é gerado. Através da instrução readelf pode-se realizar a análise do arquivo ELF. Aqui você pode ver que o endereço de entrada do arquivo ELF é 0x400430:

Em seguida, usamos o artefato de desmontagem, o IDA abriu e analisou esse arquivo, e ver qual função está localizada na entrada de 0x400430?
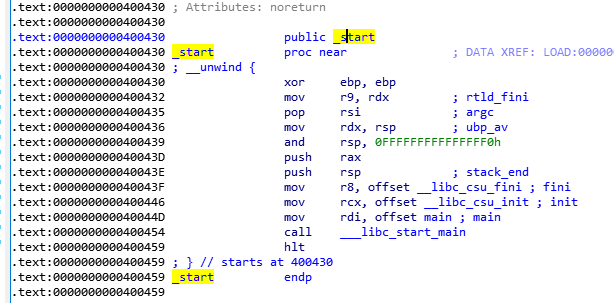
Como você pode ver, o ponto de entrada é uma função chamada _start , não nossa função principal.
No final de _start, a função __libc_start_main é chamada e esta função está localizada em libc.so.
Você pode estar se perguntando, de onde vem essa função? Não a usamos em nosso código?
Na verdade, antes de entrar na função principal, há outro trabalho importante a ser feito, que é: a inicialização da biblioteca runtime C / C ++ . O __libc_start_main acima está fazendo este trabalho.
Ao compilar com o GCC, o compilador completará automaticamente o link da biblioteca de tempo de execução, encapsulará nossa função principal e a chamará.
glibc é open source, podemos encontrar o arquivo libc-start.c deste projeto no GitHub, e dar uma olhada na verdadeira face de __libc_start_main.Nossa função principal é chamada por ele.

Processo completo
Neste ponto, classificamos o processo desde o processo de criação de uma bifurcação até a conclusão da substituição de arquivos executáveis por meio da série exec de funções, até a entrada do arquivo ELF no processo de execução e até o processo completo de nossa função principal.

Algumas diferenças no Windows
A seguir, apresentamos resumidamente algumas diferenças nesse processo no Windows.
A primeira etapa é criar um processo. O sistema Windows mescla as duas etapas de fork + exec em uma etapa. As funções da série CreateProcess são usadas em uma etapa e o caminho do arquivo executável do processo filho é especificado em seus parâmetros.
Diferente da fronteira fuzzy entre processo e thread no Linux, no sistema operacional Windows, o kernel tem uma definição clara do conceito de processo e thread, o processo é representado pela estrutura EPROCESS , e o thread é representado pela estrutura ETHREAD .
Portanto, no Windows, após o trabalho relacionado ao processo estar pronto, é necessário criar uma unidade de execução separada participando do agendamento do kernel, que é o primeiro thread do processo: o thread principal . Obviamente, este trabalho também está encapsulado na série de funções CreateProcess .
Depois que o thread principal do novo processo é criado, ele começa a participar do agendamento do sistema. Onde o thread principal começa a execução? O kernel é claramente especificado quando é criado: nt! KiThreadStartup , esta é uma função do kernel, e a thread começa a ser executada a partir daqui.
Depois que o thread é iniciado a partir daqui, o mecanismo APC é chamado por meio do processo assíncrono do Windows para executar o APC inserido antecipadamente e, em seguida, o fluxo de execução é introduzido na camada de aplicativo para realizar o trabalho de inicialização do aplicativo de processo do Windows, como o carregamento de alguns arquivos DLL principais (Kernel32.dll) , Ntdll.dll) e assim por diante.
Em seguida, por meio do mecanismo APC novamente, vá para o ponto de entrada do arquivo executável.
O mecanismo por trás disso é semelhante ao do Linux. Também não há acesso direto à função principal. Em vez disso, a biblioteca de tempo de execução C / C ++ precisa ser inicializada primeiro e, em seguida, a função de tempo de execução é encerrada antes de finalmente chegar à nossa função principal .
A seguir está o processo completo, desde o processo de criação até nossa função principal no Windows (imagem grande de alta definição: https://bbs.pediy.com/upload/attach/201604/501306_qz5f5hi1n3107kt.png):

Agora você sabe como ir do início do processo à sua função principal, passo a passo? Se você tiver dúvidas e quebra-cabeças, deixe uma mensagem para troca.
Artigos TOP5 anteriores
Eu sou Redis, e o irmão mais velho do MySQL estava muito triste comigo!
Quase perdi meu emprego devido a uma solicitação de vários domínios
É isso aí! A CPU continua pedindo que algo aconteça em breve!
Qual tabela de hash é mais forte? Várias das principais linguagens de programação estão lutando!