A memória principal (RAM) é um recurso muito importante e a memória deve ser tratada com cuidado. Embora a taxa de crescimento da maioria da memória seja muito mais rápida do que a do IBM 7094, o crescimento do tamanho do programa é muito mais rápido do que o crescimento da memória. Como diz a lei de Parkinson: não importa o quão grande seja a memória, a taxa de crescimento do tamanho do programa é muito mais rápida do que a taxa de crescimento da capacidade da memória. Vamos explorar como o sistema operacional cria memória e os gerencia.
Após anos de discussão, as pessoas propuseram uma hierarquia de memória. A seguir está a classificação do sistema hierárquico
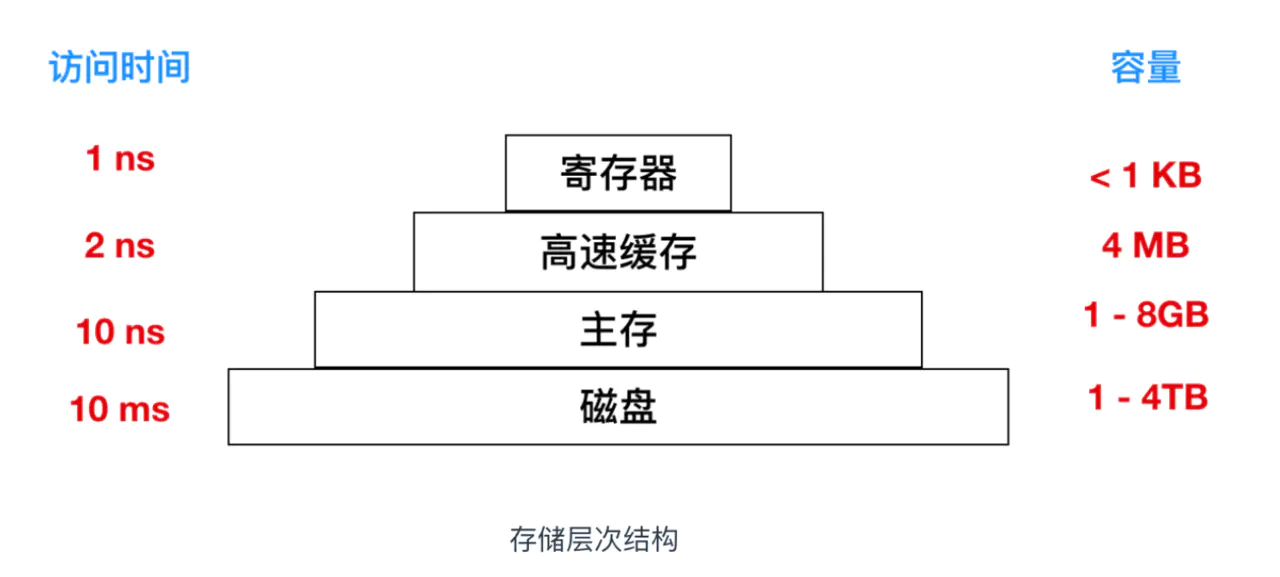
A memória de nível superior tem a velocidade mais alta, mas a menor capacidade, e o custo é muito alto.Quanto menor a estrutura hierárquica, mais lenta a eficiência de acesso e maior a capacidade, mas mais barato é o custo.
A parte do sistema operacional que gerencia a hierarquia da memória é chamada de gerenciador de memória. Sua principal função é gerenciar a memória de maneira eficaz, registrar qual memória está em uso, alocar memória quando o processo precisar dela e recuperar memória quando o processo for concluído .
Abaixo, discutiremos diferentes modelos de gerenciamento de memória, do simples ao complexo.Como o nível mais baixo de cache é gerenciado por hardware, discutiremos principalmente o modelo de memória principal e como gerenciar a memória principal.
Sem abstração de memória
A abstração de memória mais simples é nenhum armazenamento. Os primeiros computadores mainframe (antes da década de 1960), pequenos computadores (antes da década de 1970) e computadores pessoais (antes da década de 1980) não tinham abstração de memória. Cada programa acessa diretamente a memória física. Quando um programa executa o seguinte comando:
MOV REGISTER1, 1000O computador moverá o conteúdo da memória física na posição 1000 para REGISTER1. Portanto, o modelo de memória apresentado ao programador naquele momento era a memória física.O endereço da memória parte de 0 até o valor máximo do endereço da memória, e cada endereço contém uma unidade de 8 bits.
Portanto, o computador, neste caso, não pode ter dois aplicativos na memória ao mesmo tempo. Se o primeiro programa gravar um valor neste local do endereço de memória 2000, esse valor substituirá o valor do segundo programa naquele local.Portanto, executar dois aplicativos ao mesmo tempo não funcionará. O programa irá travar imediatamente.
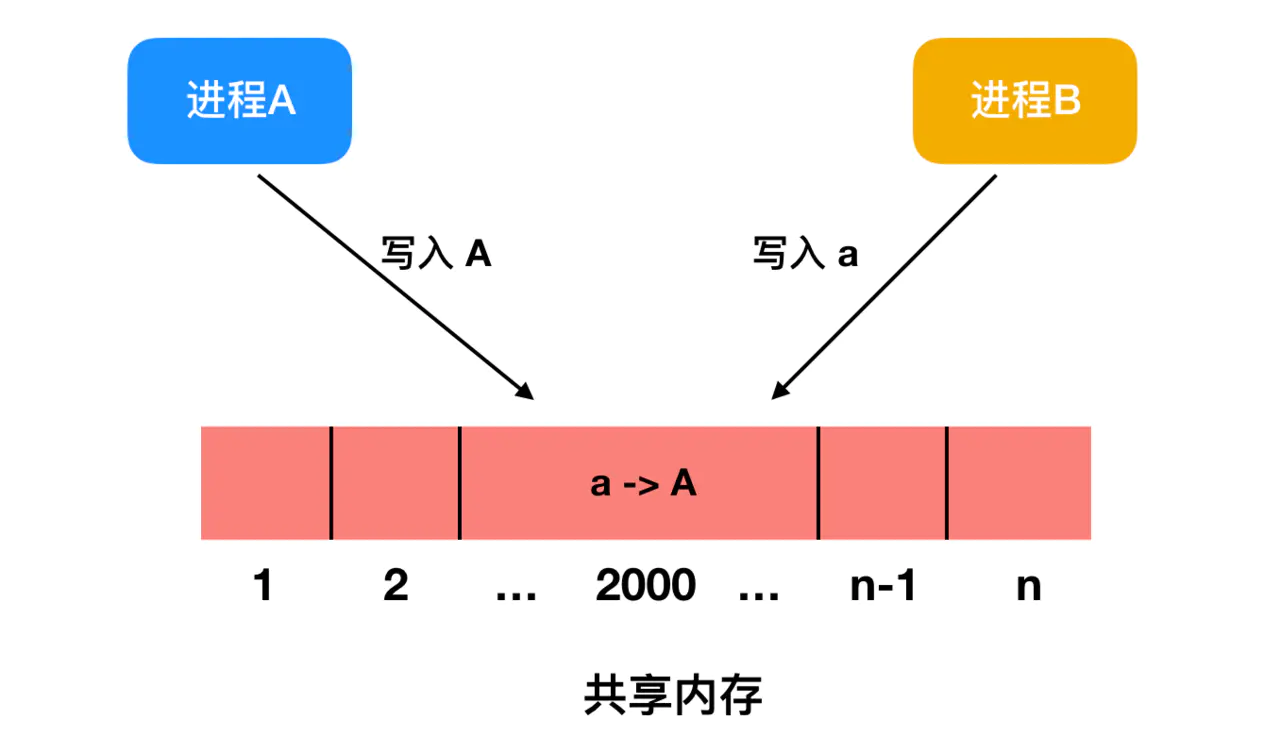
Mas mesmo que o modelo de memória seja físico, ainda existem algumas opções. Três variantes são mostradas abaixo
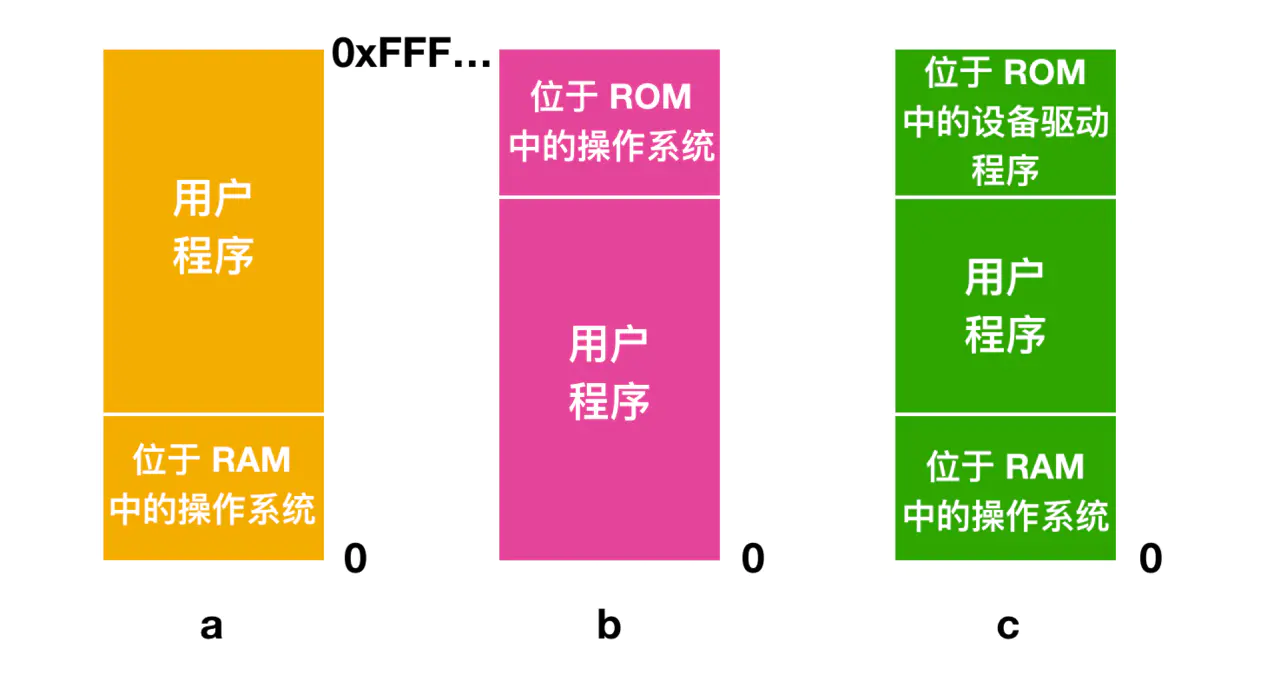
Na Figura a, o sistema operacional está localizado na parte inferior da RAM (memória de acesso aleatório) ou na parte superior da ROM (memória somente leitura) como na Figura b; enquanto na Figura c, o driver do dispositivo está localizado na ROM superior, e O sistema operacional está localizado na RAM na parte inferior. O modelo da Figura a foi usado anteriormente em mainframes e minicomputadores, mas raramente é usado agora; o modelo da Figura b é geralmente usado em computadores portáteis ou sistemas embarcados. O terceiro modelo foi usado nos primeiros computadores pessoais. Uma parte do sistema ROM torna-se o BIOS (Basic Input Output System). A desvantagem dos modelos aec é que erros no programa do usuário podem danificar o sistema operacional e causar consequências catastróficas.
Quando o sistema é organizado dessa forma, geralmente apenas um thread está em execução por vez. Depois que o usuário digita um comando, o sistema operacional copia o programa necessário do disco para a memória e o executa; quando o processo termina, o sistema operacional exibe um prompt no terminal do usuário e aguarda um novo comando. Depois de receber o novo comando, ele carrega o novo programa na memória e sobrescreve o programa anterior.
Uma maneira de atingir o paralelismo em um sistema sem abstração de memória é usar a programação multithread. Uma vez que vários threads no mesmo processo compartilham a mesma imagem de memória internamente, o paralelismo não é um problema.
Execute vários programas
No entanto, mesmo sem abstração de memória, é possível executar vários programas simultaneamente. O sistema operacional só precisa salvar todo o conteúdo da memória atual em um arquivo de disco e, em seguida, ler o programa na memória. Enquanto houver apenas um programa de cada vez, não haverá conflitos.
Com a ajuda de hardware especial adicional, vários programas podem ser executados em paralelo, mesmo se não houver função de troca. É assim que o modelo inicial do IBM 360 foi resolvido
System / 360 é um grande computador que marcou época, lançado pela IBM em 7 de abril de 1964. Esta série é o primeiro computador compatível com conjunto de instruções do mundo.

No IBM 360, a memória é dividida em blocos de área de 2 KB e cada área recebe uma chave de proteção de 4 bits, que é armazenada em um registro especial da CPU. Uma máquina com 1 MB de memória só precisa de 512 desses registradores de 4 bits, com uma capacidade total de 256 bytes (isso contará). Há um código de 4 bits em PSW (Program Status Word). Se um processo em execução acessa uma memória com uma chave diferente de seu código PSW, o hardware 360 vai encontrar essa situação porque apenas o sistema operacional pode modificar a chave de proteção, o que pode impedir a interferência entre processos, processos do usuário e sistemas operacionais.
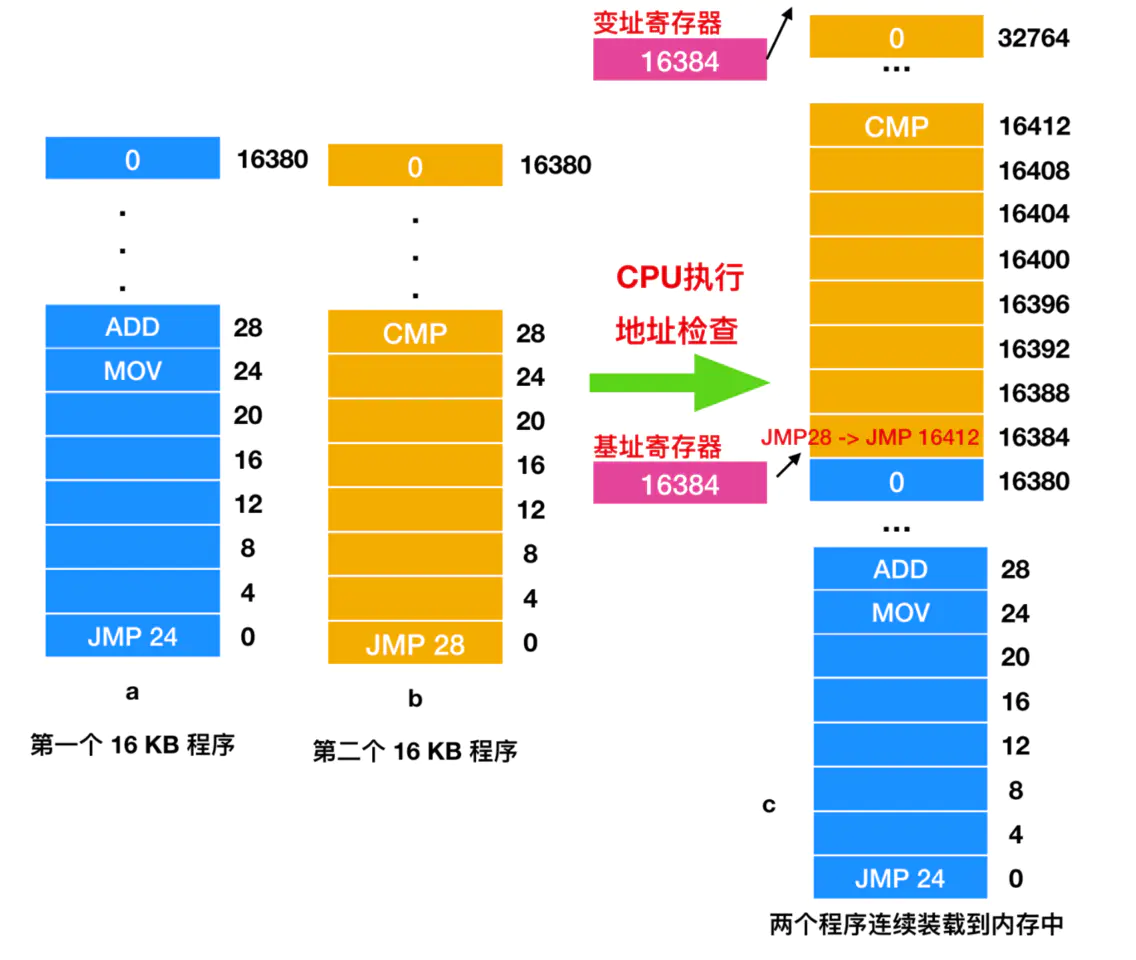
Essa solução tem uma falha. Conforme mostrado abaixo, suponha que haja dois programas, cada um com um tamanho de 16 KB
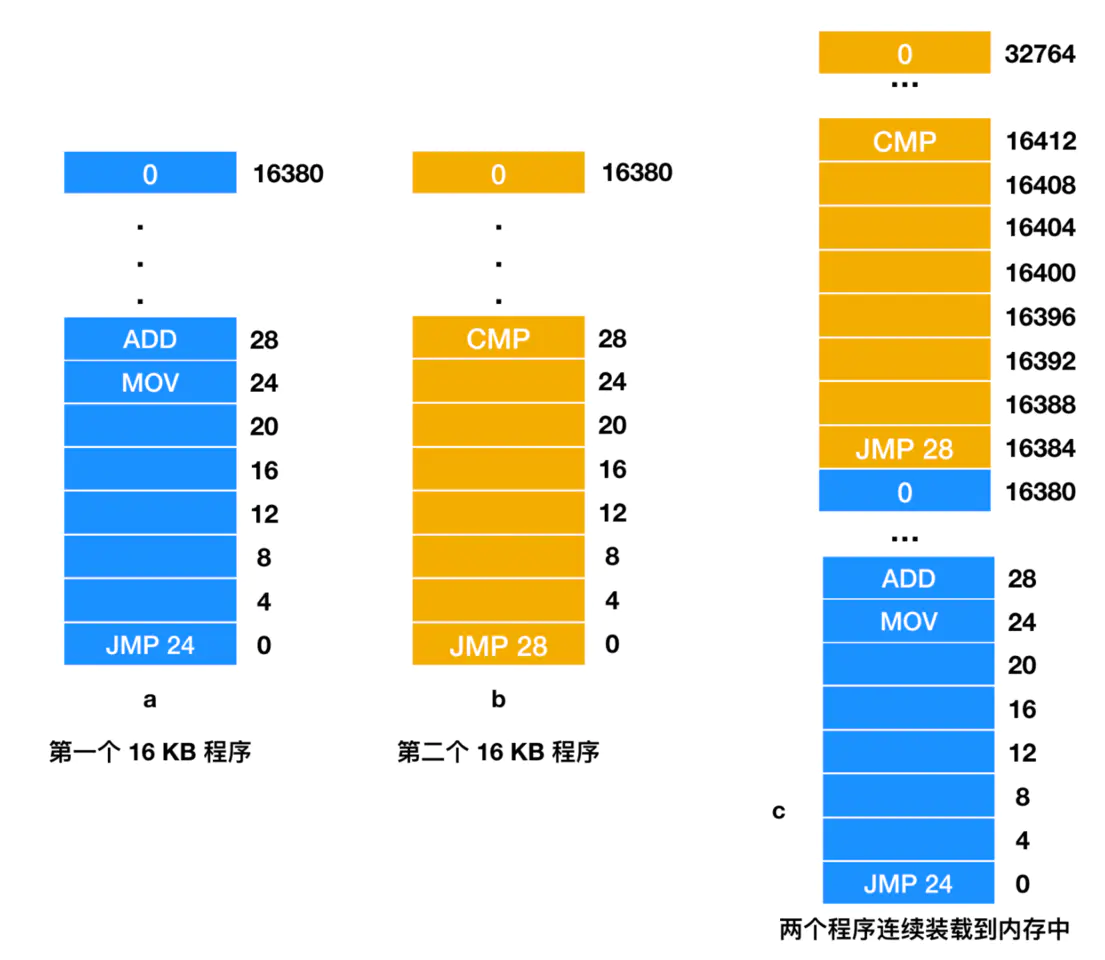
Pode ser visto na figura que este é o processo de carregamento de dois programas diferentes de 16 KB. O programa a vai primeiro pular para o endereço 24, onde é uma instrução MOV, mas o programa b vai primeiro pular para o endereço 28, o endereço 28 é uma linha Instrução CMP. Esta é uma situação em que dois programas são carregados na memória um após o outro. Se os dois programas são carregados na memória ao mesmo tempo e começam a execução a partir do endereço 0, o estado da memória é mostrado na Figura c acima. O programa é carregado e começa a ser executado. Um programa é executado a partir do endereço 0 primeiro, executa a instrução JMP 24 e, em seguida, executa as seguintes instruções em sequência (muitas instruções não são mostradas). Depois de um período de tempo, o primeiro programa é executado e, em seguida, o segundo programa é executado. A primeira instrução do segundo programa é 28. Esta instrução fará com que o programa salte para o ADD do primeiro programa em vez da instrução de salto CMP definida previamente. Devido ao acesso incorreto ao endereço de memória, este programa Ele pode travar em 1 segundo.
O principal problema com a execução simultânea dos dois programas acima é que ambos fazem referência a endereços físicos absolutos. Não é isso que queremos ver. O que queremos é que cada programa faça referência a um endereço local privado. Quando o segundo programa é carregado na memória, o IBM 360 usa uma técnica chamada relocação estática para modificá-lo. Seu fluxo de trabalho é o seguinte: Quando um programa é carregado no endereço 16384, a constante 16384 é adicionada a cada endereço do programa (então JMP 28 se tornará JMP 16412). Embora esse mecanismo seja viável sem erros, não é uma solução geral e diminuirá a velocidade de carregamento. Mais recentemente, ele requer informações adicionais em todos os programas executáveis para indicar quais contêm endereços (relocáveis) e quais não contêm endereços (relocáveis). Afinal, o JMP 28 na Figura b acima pode ser redirecionado (modificado), e algo como MOV REGISTER1,28 moverá o número 28 para o REGISTER sem redirecionamento. Portanto, o carregador precisa de uma certa habilidade para distinguir entre endereços e constantes.
Uma abstração de memória: espaço de endereço
Expor a memória física a um processo tem várias desvantagens principais: O primeiro problema é que, se os programas do usuário podem lidar com cada byte de memória, eles podem facilmente danificar o sistema operacional e pará-lo (a menos que Use o modo de bloqueio e chave IBM 360 ou hardware especial para proteção). Esse problema existe mesmo quando há apenas um processo do usuário em execução.
O segundo ponto é que é muito difícil para este modelo executar vários programas (se houver apenas uma CPU, é a execução sequencial). Em um computador pessoal, muitos aplicativos são normalmente abertos, como métodos de entrada, e-mails e navegadores. , Esses processos terão um processo em execução em momentos diferentes, e outros aplicativos podem ser ativados com o mouse. É difícil conseguir sem memória física no sistema.
O conceito de espaço de endereço
Se você deseja fazer vários aplicativos rodarem na memória ao mesmo tempo, você deve resolver dois problemas: proteção e realocação. Vamos ver como o IBM 360 resolve: A primeira solução é marcar o bloco de memória com uma chave de proteção e comparar a chave do processo de execução com a chave de cada palavra armazenada extraída. Este método pode resolver apenas o primeiro problema, mas ainda não pode resolver o problema de vários processos em execução na memória ao mesmo tempo.
A melhor maneira é criar uma abstração de memória: o espaço de endereço. Assim como o conceito de processo cria uma CPU abstrata para executar programas, o espaço de endereço também cria uma memória abstrata para os programas usarem. O espaço de endereço é o conjunto de endereços que um processo pode usar para endereçar a memória. Cada processo tem seu próprio espaço de endereço, independente do espaço de endereço de outros processos, mas alguns processos podem desejar compartilhar o espaço de endereço.
Registro de base e registro de índice
A maneira mais fácil é usar a realocação dinâmica (realocação dinâmica), que é mapear o espaço de endereço de cada processo para uma área diferente da memória física de forma simples. O método clássico usado do CDC 6600 (o mais antigo supercomputador do mundo) ao Intel 8088 (o núcleo do IBM PC original) é configurar cada CPU com dois registros de hardware especiais, geralmente chamados de registro básico e índice Registrar (registro de limite). Quando o registro de base e o registro de índice são usados, o programa será carregado em um local de espaço contínuo na memória e não há necessidade de realocar durante o carregamento. Quando um processo está em execução, o endereço físico inicial do programa é carregado no registrador de endereço base e o comprimento do programa é carregado no registrador de índice. Na figura c acima, quando um programa está em execução, os valores dos registros de base e índice carregados nesses registros de hardware são 0 e 16384, respectivamente. Quando o segundo programa é executado, esses valores são 16384 e 32768, respectivamente. Se o terceiro programa de 16 KB for carregado diretamente no endereço do segundo programa e executado, o valor do registrador de base e do registrador de índice será 32768 e 16384 neste momento. Então podemos resumir
- Registro de endereço de base: a posição inicial da memória de dados
- Registro de índice: armazena a duração do programa de aplicação.
Sempre que um processo faz referência à memória para obter instruções ou ler ou escrever palavras de dados, o hardware da CPU adiciona automaticamente o valor do endereço de base ao endereço gerado pelo processo e o envia para o barramento de memória. Ao mesmo tempo, ele verifica se o endereço fornecido pelo programa é igual ou maior que o valor do registrador de índice. Se o endereço fornecido pelo programa exceder a faixa do registrador de índice, ocorrerá um erro e o acesso será abortado. Desta forma, após executar a instrução JMP 28 na Figura c acima, o hardware irá interpretá-la como JMP 16412, para que o programa possa pular para a instrução CMP, o processo é o seguinte
Usar o registrador de base e o registrador de índice é uma ótima maneira de fornecer espaço de endereço privado para cada processo, porque cada endereço de memória será adicionado ao conteúdo do registrador de base antes de ser enviado para a memória. Em muitos sistemas reais, o registro de base e o registro de índice serão protegidos de uma certa maneira, de forma que apenas o sistema operacional pode modificá-los. O CDC 6600 fornece proteção para esses registros, mas o Intel 8088 não, nem mesmo indexa os registros. No entanto, o Intel 8088 fornece muitos registradores de endereço de base para que o código do programa e os dados possam ser realocados independentemente, mas não oferece proteção para referências de memória fora do intervalo.
Assim, você pode conhecer as desvantagens de usar o registrador base e o registrador de índice, sempre que a memória for acessada, as operações ADD e CMP serão realizadas. A comparação pode ser realizada muito rapidamente, mas a adição será relativamente lenta. A menos que um circuito de adição especial seja usado, a adição será mais lenta devido ao tempo de propagação do transporte.
Tecnologia de troca
Se a memória física do computador for grande o suficiente para acomodar todos os processos, a solução mencionada anteriormente é mais ou menos viável. Mas, na verdade, a capacidade total de RAM exigida por todos os processos é muito maior do que a capacidade da memória. Nos sistemas Windows, OS X ou Linux, depois que o computador conclui a inicialização (inicialização), cerca de 50-100 processos são iniciados. Por exemplo, quando um aplicativo do Windows é instalado, ele geralmente emite um comando para que, quando o sistema subsequente for iniciado, ele inicie um processo que não faz nada exceto verificar se há atualizações para o aplicativo. Um aplicativo simples pode ocupar de 5 a 10 MB de memória. Outros processos em segundo plano verificam o e-mail, as conexões de rede e muitas outras tarefas semelhantes. Tudo isso acontecerá antes de o primeiro usuário iniciar. Hoje, aplicativos de usuário importantes como o Photoshop exigem apenas 500 MB para iniciar, mas uma vez que começam a processar dados, eles exigem muitos GB para processar. Do ponto de vista dos resultados, manter todos os processos na memória o tempo todo requer muita memória e não pode ser feito se não houver memória suficiente.
Portanto, diante do problema de memória insuficiente acima, dois métodos são propostos: o método mais simples é a tecnologia de troca, que consiste em transferir um processo completamente para a memória, depois executá-lo na memória por um período de tempo e depois colocá-lo De volta ao disco. Os processos ociosos são armazenados no disco, portanto, esses processos não ocuparão muita memória quando não estiverem em execução. Outra estratégia é chamada de memória virtual (memória virtual), a tecnologia de memória virtual pode permitir que parte do aplicativo seja executado na memória. Vamos primeiro discutir o intercâmbio
Processo de troca
O seguinte é um processo de troca
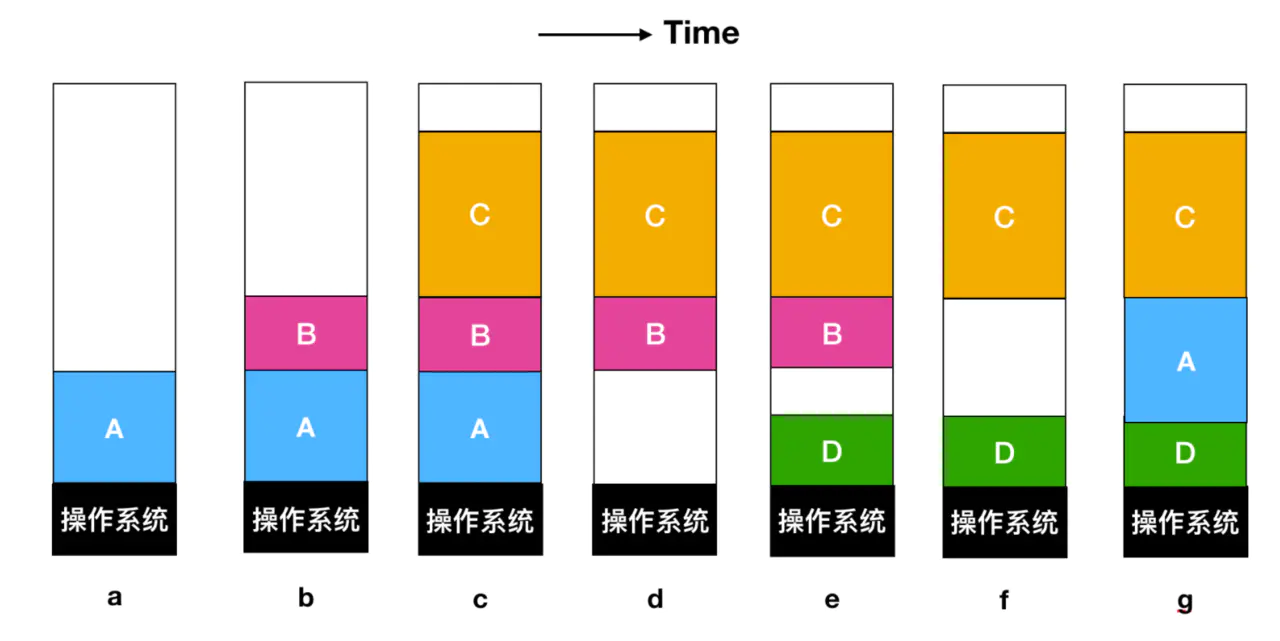
No início, apenas o processo A estava na memória e, em seguida, o processo B e o processo C foram criados ou trocados do disco para a memória.Em seguida, na Figura d, A foi trocado da memória para o disco e, finalmente, A voltou. Como o processo A na Figura g agora atingiu um local diferente, ele precisa ser realocado durante o processo de carregamento ou executado pelo software durante a troca do programa ou pelo hardware durante a execução do programa. O registro de base e o registro de índice são adequados para esta situação.
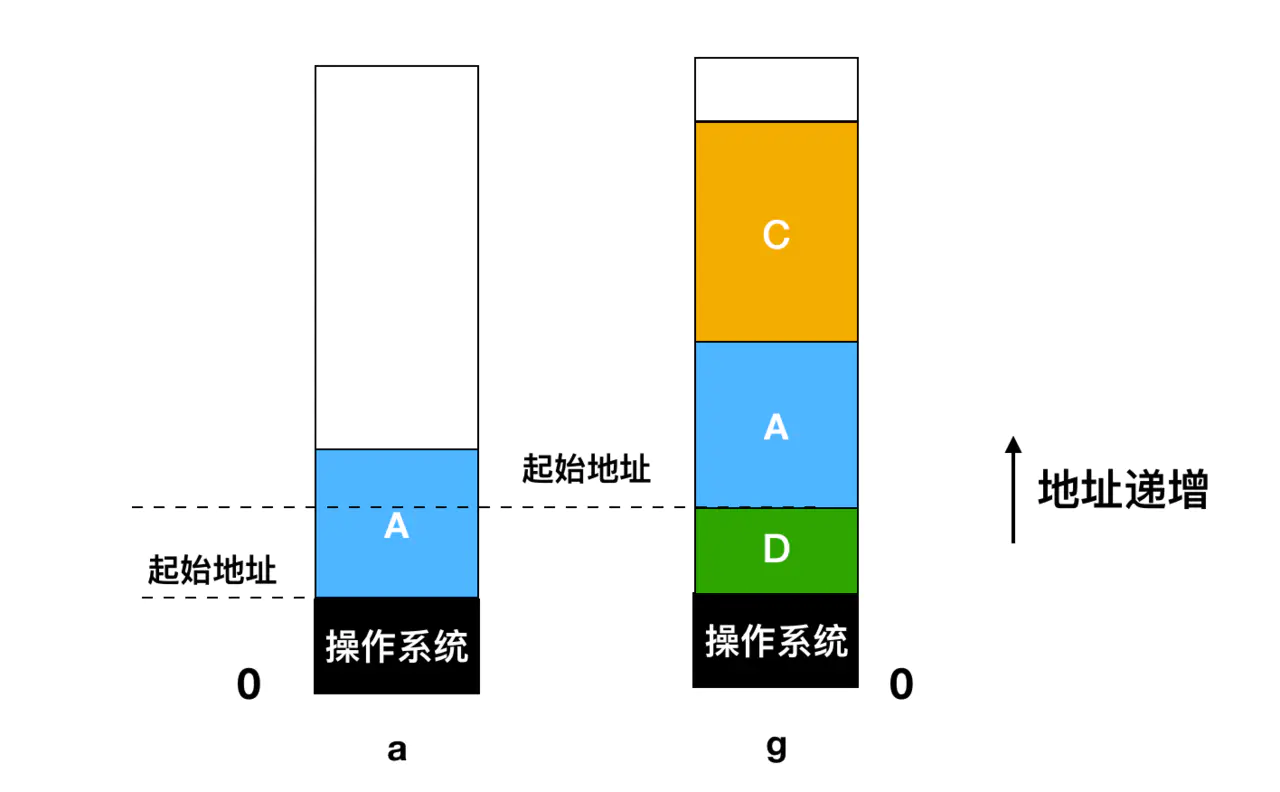
A troca cria vários buracos na memória, e a memória moverá todas as áreas livres para baixo o máximo possível e as mesclará em uma grande área livre. Essa tecnologia é chamada de compactação de memória (compactação de memória). Mas essa técnica geralmente não é usada porque consome muito tempo da CPU. Por exemplo, se você copiar 8 bytes a cada 8 ns em uma máquina com 16 GB de memória, levará cerca de 16 segundos para reduzir toda a memória.
Um problema que vale a pena observar é a quantidade de memória que deve ser alocada para um processo quando ele é criado ou trocado para a memória. Se o tamanho do processo for fixo depois de criado e não mudar, a estratégia de alocação é relativamente simples: o sistema operacional alocará exatamente o tamanho de que precisa.
Mas se o segmento de dados do processo puder crescer automaticamente, por exemplo, alocando dinamicamente a memória no heap, definitivamente ocorrerão problemas. Aqui está outra menção do que é um segmento de dados. Do nível lógico, o sistema operacional divide os dados em diferentes segmentos (diferentes áreas) para armazenar:
- Segmento de código (codesegment / textegment):
Também conhecido como segmento de texto, um espaço de memória usado para armazenar instruções e executar código
O tamanho deste espaço é determinado antes da execução do código
O espaço de memória geralmente é somente leitura e o código de algumas arquiteturas também pode ser gravável
No segmento de código, também pode haver algumas variáveis constantes somente leitura, como constantes de string.
- Segmento de dados (segmento de dados):
Leia e escreva
Armazenar variáveis globais inicializadas e variáveis estáticas inicializadas
O tempo de vida dos dados no segmento de dados é contínuo com o programa (continuado com o processo): contínuo com o processo: o processo existe quando é criado e desaparece quando o processo morre
- bss 段 (bsssegment):
Leia e escreva
Armazene variáveis globais não inicializadas e variáveis estáticas não inicializadas
O tempo de vida dos dados no segmento bss é contínuo com o processo
Os dados no segmento bss geralmente são padronizados para 0
- rodata 段 :
Dados somente leitura, como a string de formato na instrução printf e a tabela de salto da instrução switch. Ou seja, a área constante. Por exemplo, const int ival = 10 no escopo global, ival é armazenado na seção .rodata; outro exemplo é a string de formato na instrução de printf ("Hello world% d \ n", c); no escopo local da função " Hello world% d \ n "também está armazenado na seção .rodata.
- Pilha:
Leia e escreva
Armazena variáveis locais (variáveis não estáticas) em funções ou códigos
O tempo de vida da pilha continua com o bloco de código.O espaço é alocado para você quando o bloco de código é executado e o espaço é automaticamente recuperado quando o bloco de código termina.
- Pilha:
Leia e escreva
Armazenado é o espaço malloc / realloc alocado dinamicamente durante a operação do programa
A vida útil do heap continua com o processo, de malloc / realloc para free
Abaixo está o resultado depois de compilarmos com Borland C ++
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS endsA definição de segmento (segmento) é usada para distinguir ou dividir o escopo do significado. A diretiva de segmento da linguagem assembly indica o início da definição do segmento, e a diretiva termina indica o fim da definição do segmento. A definição do segmento é um espaço de memória contínua
Portanto, existem três maneiras de lidar com a área de memória que cresce automaticamente
- Se um processo for adjacente à área livre, a área livre pode ser alocada ao processo para seu crescimento.
- Se o processo for adjacente a outro processo, há duas maneiras de lidar com ele: mover o processo que precisa crescer para uma área livre grande o suficiente na memória ou trocar um ou mais processos, que se tornaram um spawn Uma grande área livre.
- Se um processo não puder crescer na memória e a área de troca no disco também estiver cheia, então o processo tem apenas algum espaço livre suspenso (ou o processo pode ser encerrado)
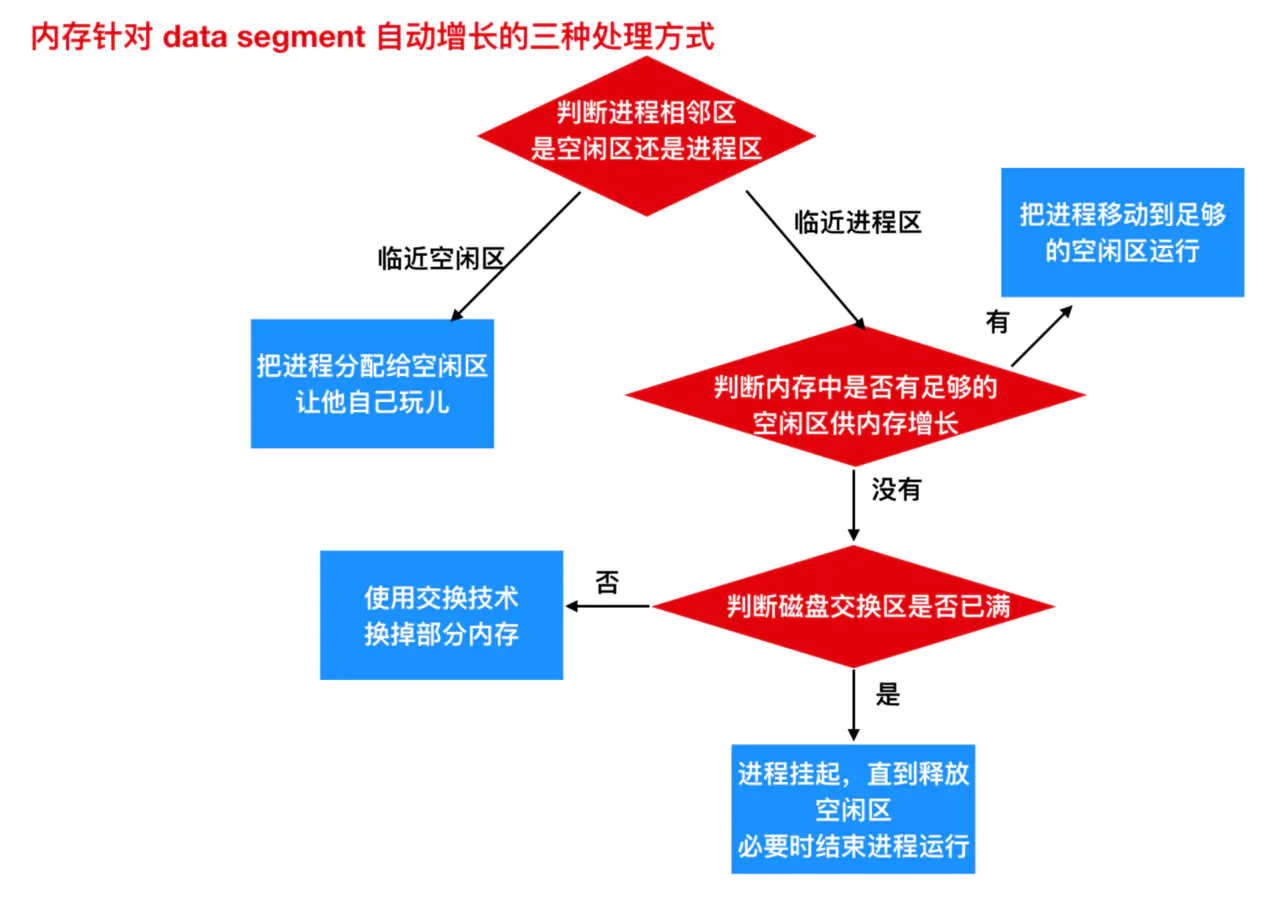
O método acima é apenas para um único ou um pequeno número de processos que precisam crescer. Se a maioria dos processos precisar crescer em tempo de execução, a fim de reduzir a sobrecarga de troca e movimentação de processos causada por área de memória insuficiente, um método disponível Sim, aloque alguma memória extra para ele ao trocar ou mover um processo. No entanto, quando o processo é trocado para o disco, apenas a memória realmente usada deve ser trocada. Também é um desperdício trocar a memória extra. A seguir está uma configuração de memória que aloca espaço de crescimento para dois processos.
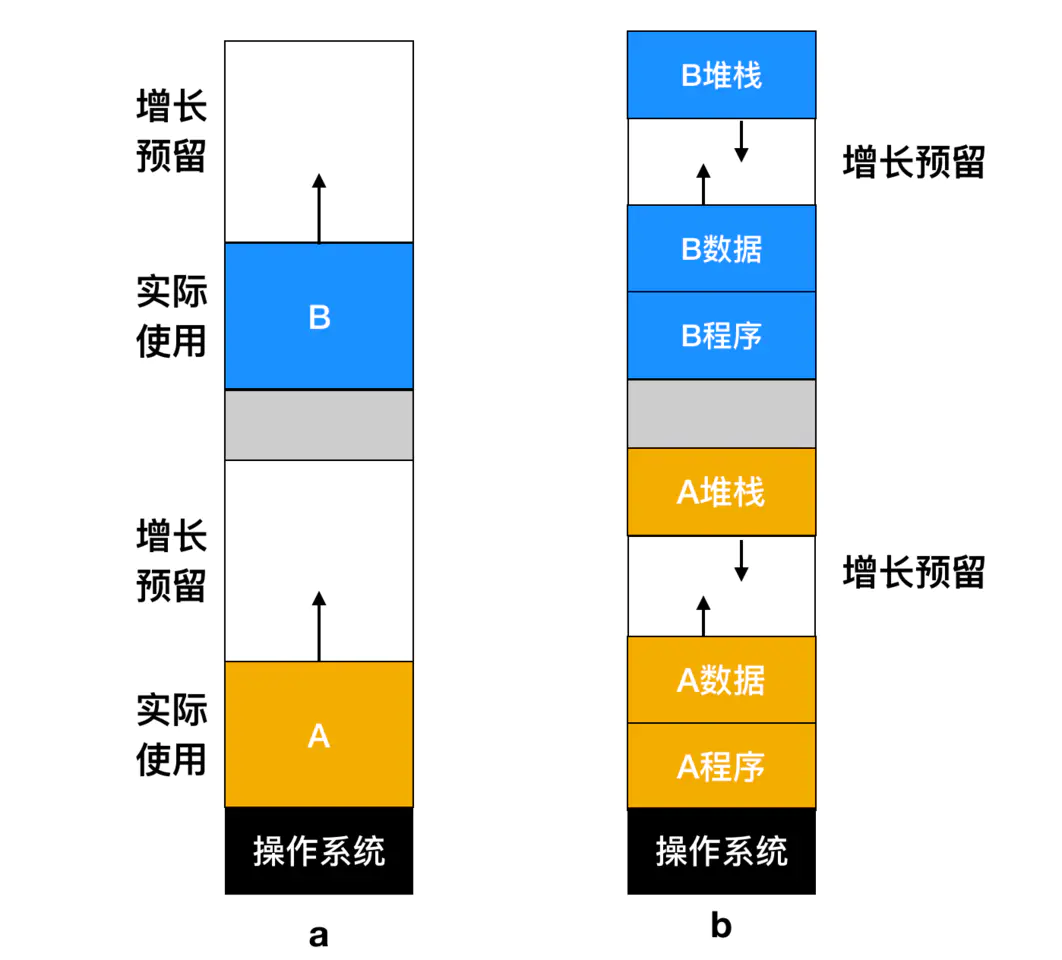
Se o processo tem dois segmentos que podem crescer, por exemplo, um segmento de dados (segmento de dados) usado como um heap (variável global) para alocação dinâmica de variáveis e liberação, e um segmento de pilha (segmento de pilha) armazenando variáveis locais e endereços de retorno , Conforme mostrado na Figura b. Na figura, você pode ver que o segmento da pilha do processo mostrado cresce para baixo no topo da memória ocupada pelo processo e, em seguida, o segmento de dados imediatamente após o segmento do programa cresce para cima. Quando a área de memória reservada para crescimento não é suficiente, o método de processamento é igual ao fluxograma acima (três métodos de processamento para crescimento automático do segmento de dados).
Gerenciamento de memória livre
Quando a memória é alocada dinamicamente, o sistema operacional deve gerenciá-la. De um modo geral, existem duas maneiras de monitorar o uso de memória
- Bitmap
- Listas gratuitas
Vamos explorar essas duas maneiras de usar
Gerenciamento de armazenamento usando bitmaps
Ao usar o método de bitmap, a memória pode ser dividida em unidades de alocação tão pequenas quanto algumas palavras ou tão grandes quanto vários kilobytes. Cada unidade de alocação corresponde a um bit no bitmap, 0 significa livre, 1 significa ocupado (ou vice-versa). Uma área de memória e seu bitmap correspondente são os seguintes
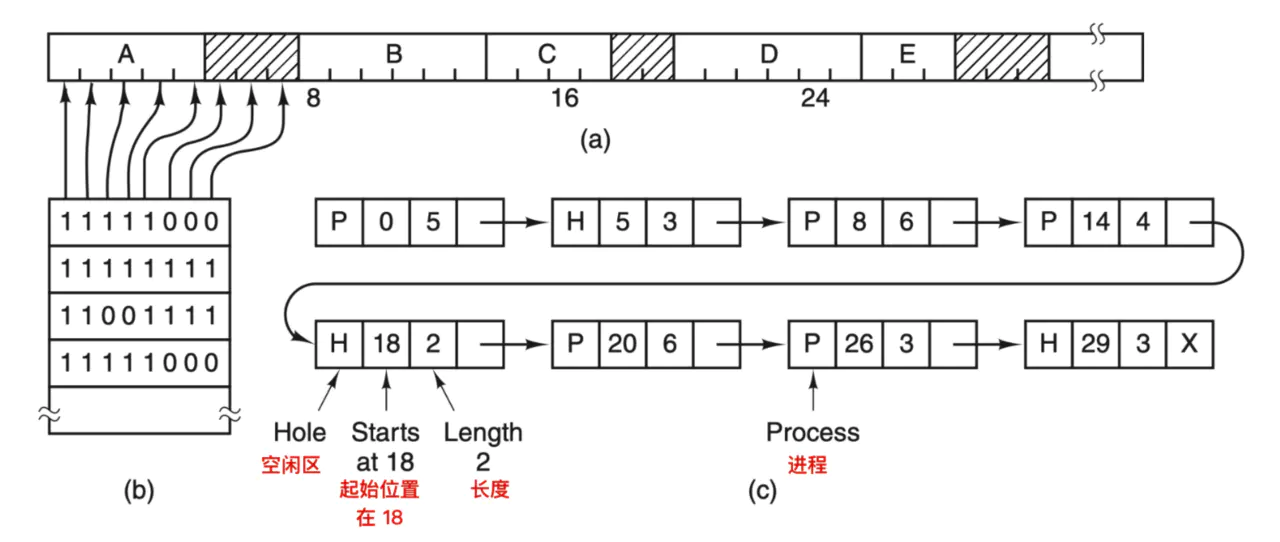
A Figura a mostra uma seção de memória com 5 processos e 3 áreas livres, a escala é a unidade de alocação de memória, e a área sombreada representa livre (indicada por 0 no bitmap); Figura b representa o bitmap correspondente; Figura c representa-o com uma lista vinculada A mesma informação
O tamanho da unidade de alocação é um fator de design importante. Quanto menor a unidade de alocação, maior o bitmap. No entanto, mesmo se houver apenas uma unidade de alocação de 4 bytes, a memória de 32 bits só precisa de 1 bit no bitmap. A memória de 32n bits requer bitmaps de n bits, portanto, 1 bitmap ocupa apenas 1/32 da memória . Se você escolher uma célula de memória maior, o bitmap deve ser menor. Se o tamanho do processo não for um múltiplo inteiro da unidade de alocação, muita memória será desperdiçada na última unidade de alocação.
Os bitmaps fornecem uma maneira fácil de rastrear o uso da memória em uma memória de tamanho fixo, porque o tamanho do bitmap depende do tamanho da memória e da unidade de alocação . Um problema com este método é que quando é decidido colocar um processo com k unidades de alocação na memória, o gerenciador de memória deve pesquisar o bitmap e encontrar k bits 0 consecutivos no bitmap. corda. É uma operação muito demorada localizar sequências 0 consecutivas de um comprimento especificado no bitmap, o que é uma desvantagem do bitmap. (Pode ser simplesmente entendido como descobrir uma longa lista de elementos de array livres em um array caótico)
Use listas vinculadas para gerenciamento
Outra forma de registrar o uso da memória é manter uma lista vinculada de segmentos de memória alocados e segmentos de memória livres.O segmento conterá o processo ou a área livre dos dois processos. A figura c acima pode ser usada para representar o uso da memória . Cada item na lista vinculada pode representar uma área livre (H) ou a marca inicial do processo (P), o comprimento e a posição do próximo item da lista vinculada.
Neste exemplo, a lista de segmentos (lista de segmentos) é classificada por endereço. A vantagem dessa abordagem é que é simples atualizar a lista quando o processo termina ou é trocado. Um processo de término geralmente tem dois vizinhos (exceto na parte superior e inferior da memória). Adjacentes podem ser processos ou áreas livres. Existem quatro combinações deles.
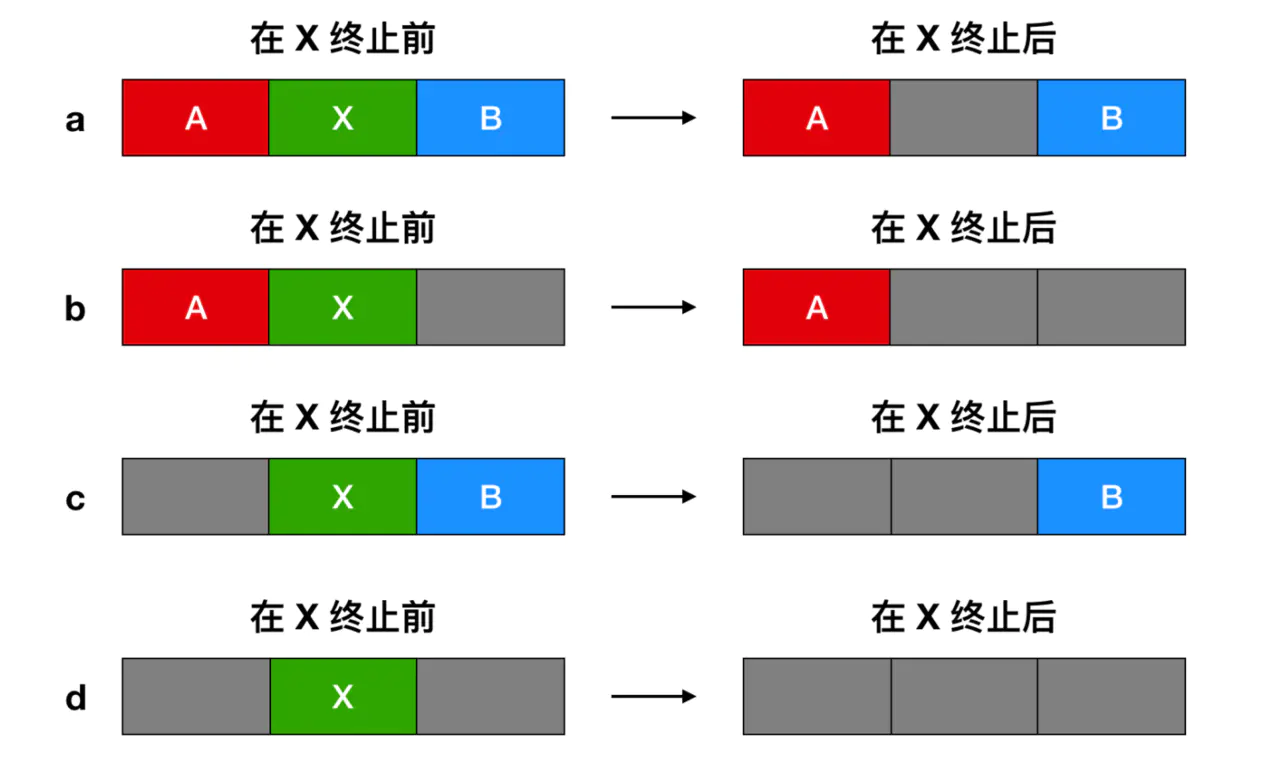
Ao armazenar processos e áreas livres na lista ligada por ordem de endereço, existem vários algoritmos que podem alocar memória para o processo criado (ou o processo trocado do disco). Em primeiro lugar, assumimos que o gerenciador de memória sabe quanta memória deve ser alocada.O algoritmo mais simples é usar o primeiro ajuste. O gerenciador de memória fará a varredura ao longo da lista de segmentos até encontrar uma área livre suficientemente grande. A menos que o tamanho da área livre seja igual ao tamanho do espaço a ser alocado, a área livre é dividida em duas partes, uma para o processo e outra para gerar uma nova área livre. O primeiro algoritmo de adaptação é um algoritmo muito rápido porque pesquisa a lista encadeada tanto quanto possível.
Uma pequena variante do primeiro ajuste é o próximo ajuste. Funciona da mesma forma que a primeira correspondência, a única diferença é que a próxima adaptação gravará a localização atual sempre que for encontrada uma área livre adequada, de modo que da próxima vez que a área livre for pesquisada, comece de onde terminou da última vez. Pesquise em vez de pesquisar desde o início sempre como o primeiro algoritmo de correspondência. Bays (1997) provou que o desempenho do próximo algoritmo é ligeiramente inferior ao do primeiro algoritmo de correspondência.
Outro algoritmo bem conhecido e amplamente utilizado é o mais adequado. O melhor ajuste pesquisará toda a lista vinculada do início ao fim para encontrar a menor área livre que possa acomodar o processo. O algoritmo de melhor ajuste tentará encontrar a área livre mais próxima da necessidade real para melhor corresponder à solicitação e à área livre disponível, em vez de dividir uma grande área livre que pode ser usada posteriormente. Por exemplo, agora precisamos de um bloco de tamanho 2, então o primeiro algoritmo de correspondência irá alocar este bloco na área livre na posição 5, e o algoritmo de melhor ajuste irá alocar o bloco na área livre na posição 18, como segue
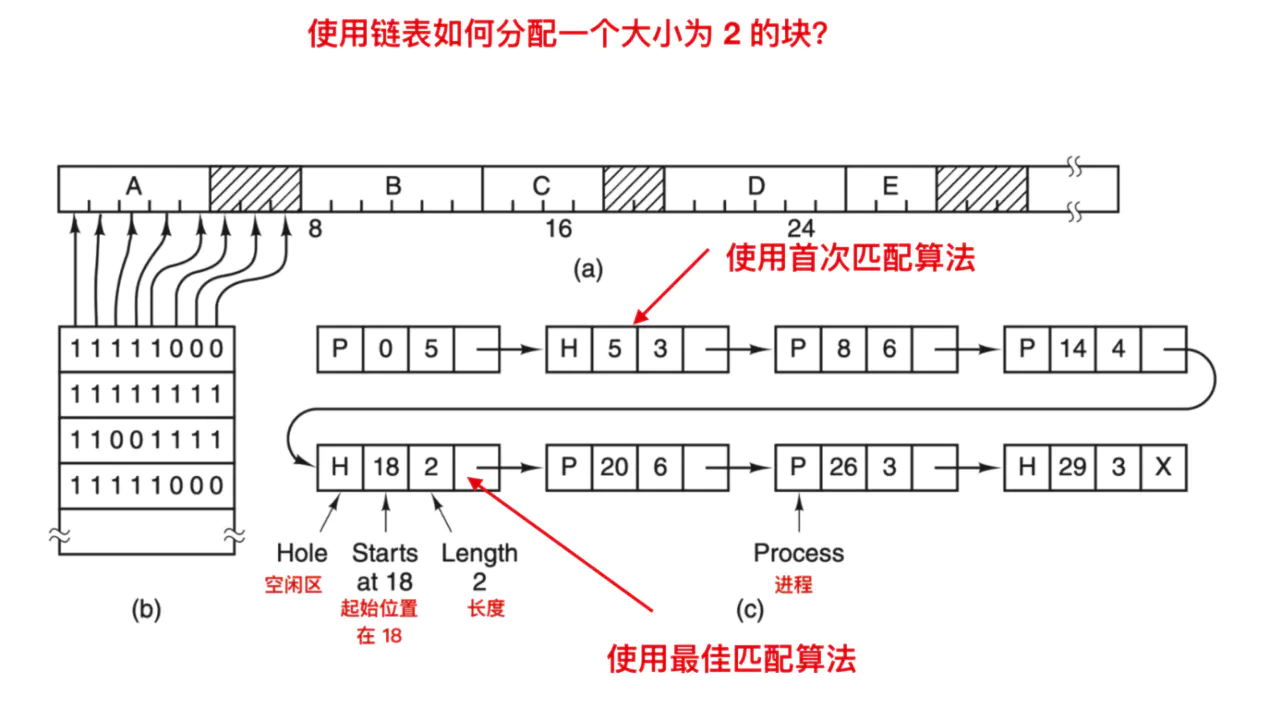
Então, qual é o desempenho do algoritmo de melhor ajuste? O melhor ajuste percorrerá toda a lista vinculada, portanto, o desempenho do algoritmo de melhor ajuste é pior do que o algoritmo de primeira correspondência. Mas o que é inesperado é que o melhor algoritmo de correspondência desperdiça mais memória do que o primeiro e o próximo algoritmo de correspondência, porque ele irá gerar muitos pequenos buffers inúteis, e a área livre gerada pelo primeiro algoritmo de correspondência será maior.
A área livre de melhor ajuste será dividida em muitos buffers muito pequenos. Para evitar esse problema, considere usar o algoritmo de pior ajuste. Ou seja, a maior área de memória é sempre alocada (então agora você entende porque o algoritmo de melhor ajuste divide muitos buffers pequenos), de modo que a área livre recém-alocada seja maior para que possa continuar a ser usada. O programa de simulação mostra que o algoritmo de pior ajuste também não é uma boa ideia.
Se listas vinculadas separadas forem mantidas para processos e ociosos, a velocidade desses quatro algoritmos pode ser melhorada. Dessa forma, o objetivo desses quatro algoritmos é verificar a área livre ao invés do processo. No entanto, um preço inevitável desse aumento na velocidade de alocação é o aumento da complexidade e a velocidade de liberação de memória mais lenta, porque um segmento recuperado deve ser excluído da lista de processos e inserido na área de lista livre.
Se o processo e a área livre usam listas encadeadas diferentes, a lista encadeada de área livre pode ser ordenada de acordo com o tamanho, de modo a melhorar a velocidade do algoritmo de adaptação ideal. Ao usar o algoritmo de melhor ajuste para pesquisar a lista de áreas livres organizadas de pequenas a grandes, desde que uma área livre adequada seja encontrada, essa área livre é a menor área livre que pode acomodar o trabalho, portanto, é a melhor correspondência. Como a lista vinculada de área livre é organizada como uma lista vinculada individual, nenhuma pesquisa adicional é necessária. Quando a lista vinculada de área livre é classificada por tamanho, o primeiro algoritmo de adaptação é tão rápido quanto o melhor algoritmo de adaptação, e o próximo algoritmo de adaptação não tem sentido aqui.
Outro algoritmo de alocação é o algoritmo de ajuste rápido, que mantém uma lista vinculada separada para áreas livres de tamanhos comumente usados. Por exemplo, há uma tabela com n itens. O primeiro item da tabela é um ponteiro para a lista vinculada de área livre com um tamanho de 4 KB, o segundo item é um ponteiro para a lista vinculada de área livre com um tamanho de 8 KB e o terceiro item é Ponteiro para o cabeçalho da lista vinculada de área livre com tamanho de 12 KB e assim por diante. Por exemplo, uma área livre como 21 KB pode ser colocada em uma lista vinculada de 20 KB ou pode ser colocada em uma lista vinculada de áreas livres com um tamanho de armazenamento especial.
O algoritmo de correspondência rápida também é muito rápido para encontrar uma área livre para uma determinada venda em consignação, mas tem a mesma desvantagem de todas as soluções que classificam a área livre por tamanho, ou seja, quando um processo é encerrado ou trocado, ele o procura. O processo de blocos adjacentes e verificar se eles podem ser mesclados consome muito tempo. Sem a fusão, a memória se dividirá rapidamente em pequenas áreas livres que um grande número de processos não pode usar.
Autor: Programador cxuan
link: https: //juejin.im/post/6844904072496037901
Fonte: Nuggets