índice
1. Configure os arquivos da biblioteca
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
import numpy as np
2. Carregue o conjunto de dados
tensorflow é mais conveniente para carregar conjuntos de dados. A seguir estão os métodos de carregamento online e local:
# 下面一行是在线加载方式
# mnist = tf.keras.datasets.mnist
# 下面两行是加载本地的数据集
datapath = r'E:\Pycharm\project\project_TF\.idea\data\mnist.npz'
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(datapath)
x_train = tf.keras.utils.normalize(x_train, axis=1)
x_test = tf.keras.utils.normalize(x_test, axis=1) #归一化
3. Estabeleça um modelo de rede totalmente conectado
model = tf.keras.Sequential([ # 3 个非线性层的嵌套模型
tf.keras.layers.Flatten(), #将多维数据打平
tf.keras.layers.Dense(784, activation='relu'), # 128也行
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax') # softmax分类
])
# 打印模型
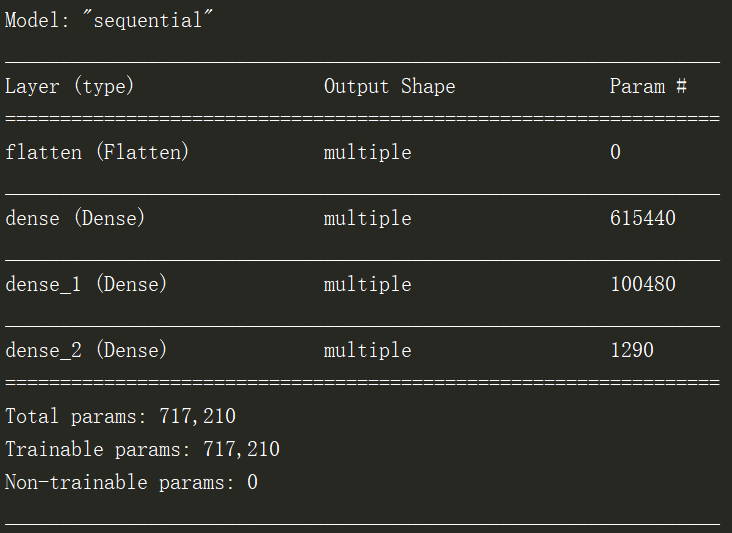
model.build((None,784,1)) # 这里要先build,告诉模型数据输入格式
print(model.summary())
A estrutura da rede impressa é a seguinte:
4. Compilação e treinamento de modelos
model.compile(optimizer='adam', # 优化器
loss='sparse_categorical_crossentropy', # 交叉熵损失函数
metrics=['accuracy']) # 标签
# 训练模型
model.fit(x_train, y_train, epochs=10,verbose=1) # verbose为1表示显示训练过程
5. Teste de modelo
Existem duas maneiras de fornecer precisão. Você pode entender a diferença entre model.evaluate () e model.predict () com base nisso e aprofundar seu entendimento.
O primeiro (recomendado):
#这里是测试模型
val_loss, val_acc = model.evaluate(x_test, y_test) # model.evaluate是输出计算的损失和精确度
print('First test Loss:{:.6f}'.format(val_loss)
O segundo tipo (para aprofundar a compreensão):
#测试模型方式二
acc_correct = 0
predictions = model.predict(x_test) # model.perdict是输出预测结果
for i in range(len(x_test)):
if (np.argmax(predictions[i]) == y_test[i]): # argmax是取最大数的索引,放这里是最可能的预测结果
acc_correct += 1
print('Second test accuracy:{:.6f}'.format(acc_correct*1.0/(len(x_test))))
Nesse ponto, o programa de rede neural totalmente conectado está concluído.
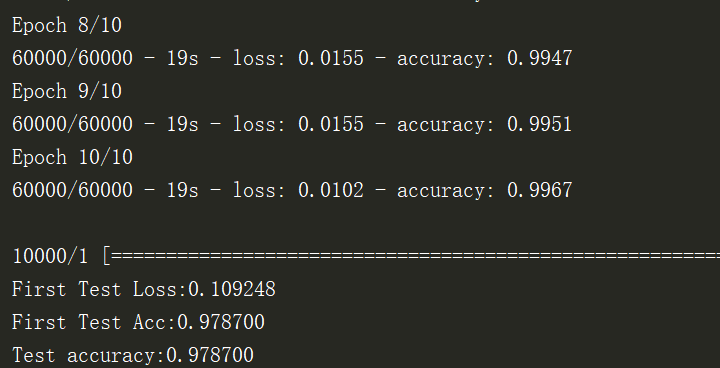
6. Os resultados do programa
A precisão da concentração de treinamento atingiu 0,9967, e a precisão da concentração de teste atingiu 0,9787. O uso de redes neurais convolucionais pode aumentar ainda mais a precisão.
7. Uma pequena exploração do trabalho de np.argmax ()
Como não entendo muito bem o trabalho de argmax (), fiz o seguinte teste e finalmente descobri.
i = 0 #测试集第一张图片
plt.imshow(x_test[i],cmap=plt.cm.binary)
plt.show()
print(np.argmax(predictions[i])) # argmax输出的是最大数的索引,predicts[i]是十个分类的权值
print((predictions[i])) # 比如predicts[0]最大的权值是第八个数,索引为7,故预测的数字为7
O resultado é o seguinte:

plt.show () gera a primeira imagem no conjunto de teste (número 7 manuscrito); a primeira impressão gera 7; a segunda impressão gera o valor de Predictions [0].
Ao observar esses 10 pesos, pode-se ver que o oitavo peso é o maior, chegando a 1; e argmax () é o índice do maior número de saídas, e o índice do oitavo número com o maior peso é 7, portanto, a primeira saída de impressão É 7, ou seja, prevê-se que o número manuscrito da imagem seja 7.
Portanto, podemos entender claramente a função e o uso de argmax.