Prefácio
Na arquitetura de microsserviço, uma solicitação geralmente envolve vários módulos, vários middleware e várias máquinas para concluir a colaboração. Nesta série de solicitações de chamada, algumas são seriais e outras paralelas. Então, como determinar quais aplicativos, módulos, nós e a ordem de chamada são chamados por trás dessa solicitação? Como localizar o problema de desempenho de cada módulo? Este artigo irá revelar a resposta para você.
Este artigo irá explicar os seguintes aspectos
- Princípio e função do sistema de rastreamento distribuído
- Princípio e projeto de arquitetura de SkyWalking
- A prática da nossa empresa na cadeia de chamadas distribuída
Princípio e função do sistema de rastreamento distribuído
Como medir o desempenho de uma interface, geralmente vamos prestar atenção a pelo menos os seguintes três indicadores
- Como você conhece o RT da interface?
- Existe uma resposta anormal?
- Onde está o principal lento?
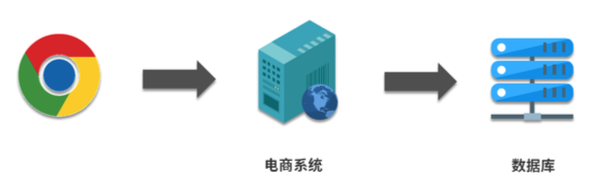
Arquitetura monolítica
No início, quando a empresa estava apenas começando, ela pode adotar a seguinte arquitetura monolítica: Para a arquitetura monolítica, que método devemos usar para calcular os três indicadores acima?
A coisa mais fácil de pensar é, obviamente, usar AOP
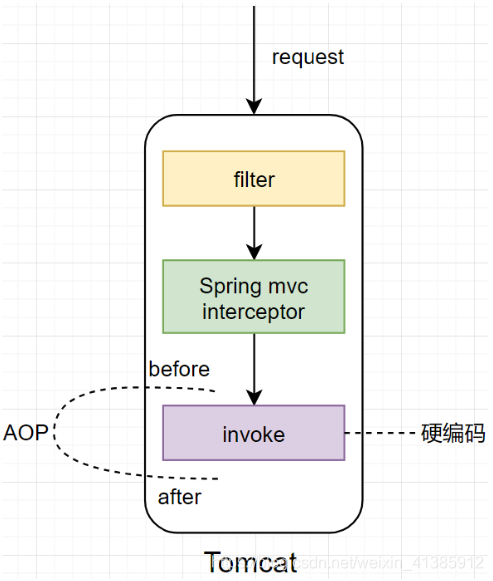
Use AOP para imprimir a hora antes e depois de chamar a lógica de negócios específica para calcular o tempo geral da chamada. Use AOP para capturar a exceção e também saber onde a chamada causou a exceção.
Arquitetura de microsserviço
Na arquitetura monolítica, como todos os serviços e componentes estão em uma máquina, esses indicadores de monitoramento são relativamente fáceis de implementar. No entanto, com o rápido desenvolvimento dos negócios, a arquitetura monolítica se desenvolverá inevitavelmente em direção a uma arquitetura de microsserviço, como segue
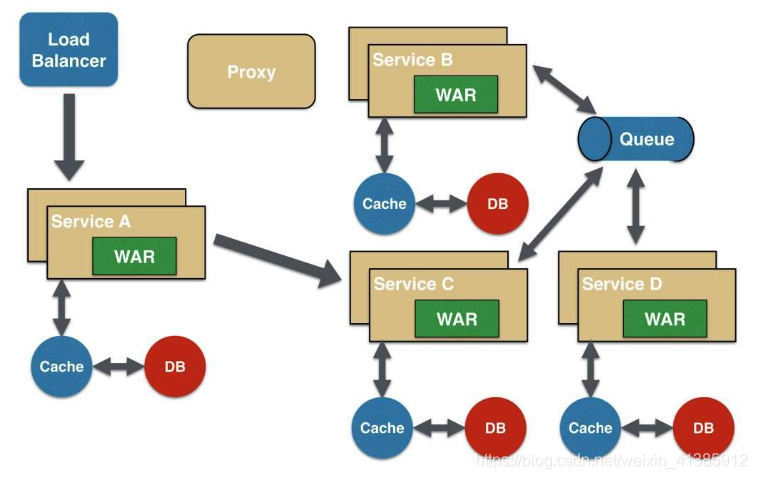
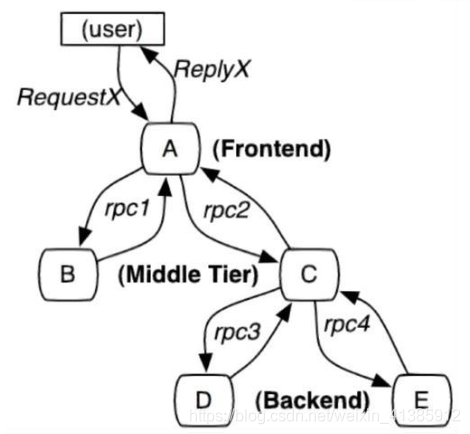
Conforme mostrado na imagem: uma arquitetura de microsserviço um pouco mais complexa
Se alguns usuários relatam que uma página está lenta, sabemos que a cadeia de chamada de solicitação desta página é A -----> C -----> B -----> D, como localizar qual módulo pode estar neste momento O problema causado. Cada serviço Serviço A, B, C, D tem várias máquinas. Como sei em qual máquina uma determinada solicitação chama o serviço?
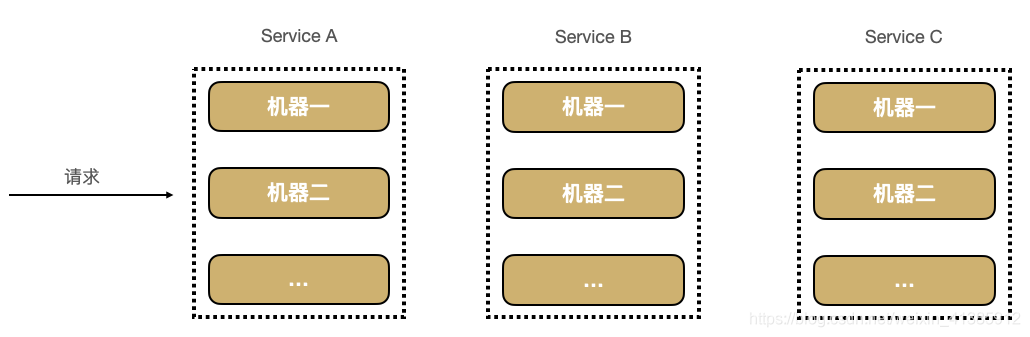
Pode ser visto claramente que devido à incapacidade de localizar com precisão o caminho exato pelo qual cada solicitação passa, existem os seguintes pontos problemáticos na arquitetura de microsserviço
- Dificuldade em solucionar problemas e ciclo longo
- Difícil de reproduzir cenas específicas
- A análise do gargalo de desempenho do sistema é difícil
A cadeia de chamadas distribuída nasceu para resolver os problemas acima, e suas principais funções são as seguintes
- Pega dados automaticamente
- Analise os dados para gerar uma cadeia de chamadas completa : Com uma cadeia de chamadas completa da solicitação, o problema tem uma alta probabilidade de ocorrer
- Visualização de dados: A visualização do desempenho de cada componente pode nos ajudar a localizar o gargalo do sistema e descobrir o problema a tempo
Por meio do sistema de rastreamento distribuído, cada link de solicitação específico das seguintes solicitações pode ser bem localizado, de forma que o rastreamento do link de solicitação possa ser facilmente realizado e o gargalo de desempenho de cada módulo possa ser localizado e analisado.
Cadeia de chamadas distribuída padrão - OpenTracing
Conhecendo o papel das cadeias de chamadas distribuídas, vamos dar uma olhada em como implementar a implementação e os princípios das cadeias de chamadas distribuídas. Em primeiro lugar, a fim de resolver o problema de incompatibilidade de API de diferentes sistemas de rastreamento distribuído, nasceu a especificação OpenTracing. OpenTracing é leve Nível da camada de padronização, ele está localizado entre o aplicativo / biblioteca de classes e o programa de rastreamento ou análise de log.
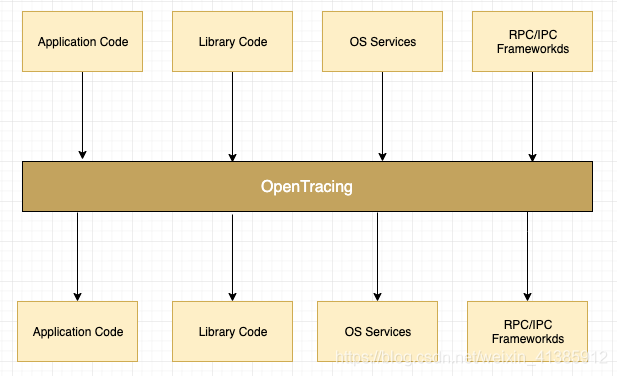
Dessa forma, OpenTracing fornece APIs independentes de plataforma e de fornecedor para que os desenvolvedores possam adicionar facilmente a implementação do sistema de rastreamento.
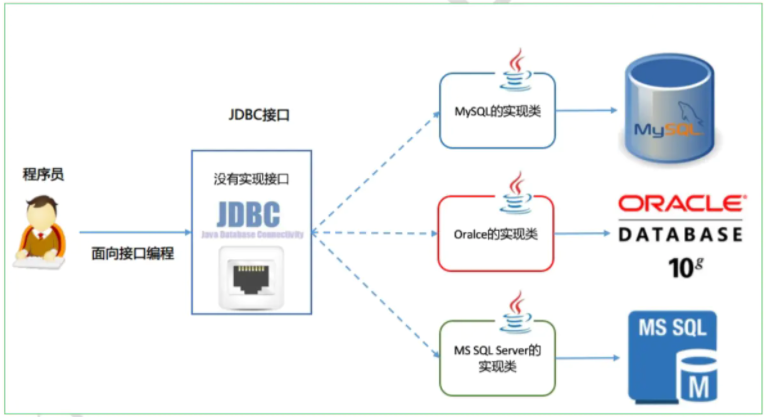
Por falar nisso, você já pensou em uma implementação semelhante em Java? Lembre-se de JDBC, ao fornecer um conjunto de interfaces padrão para vários fornecedores implementarem, os programadores podem enfrentar a programação de interface sem se preocupar com a implementação específica. A interface aqui é na verdade um padrão, por isso é muito importante formular um conjunto de padrões para habilitar componentes conectáveis.
Em seguida, olhamos para o modelo de dados OpenTracing, existem principalmente os três seguintes
- Trace : um link de solicitação completo
- Extensão : chame o processo uma vez (hora de início e hora de término são obrigatórias)
- SpanContext : rastreie informações de contexto global, como traceId
É muito importante entender esses três conceitos. Para que todos possam entender melhor esses três conceitos, fiz um desenho especial
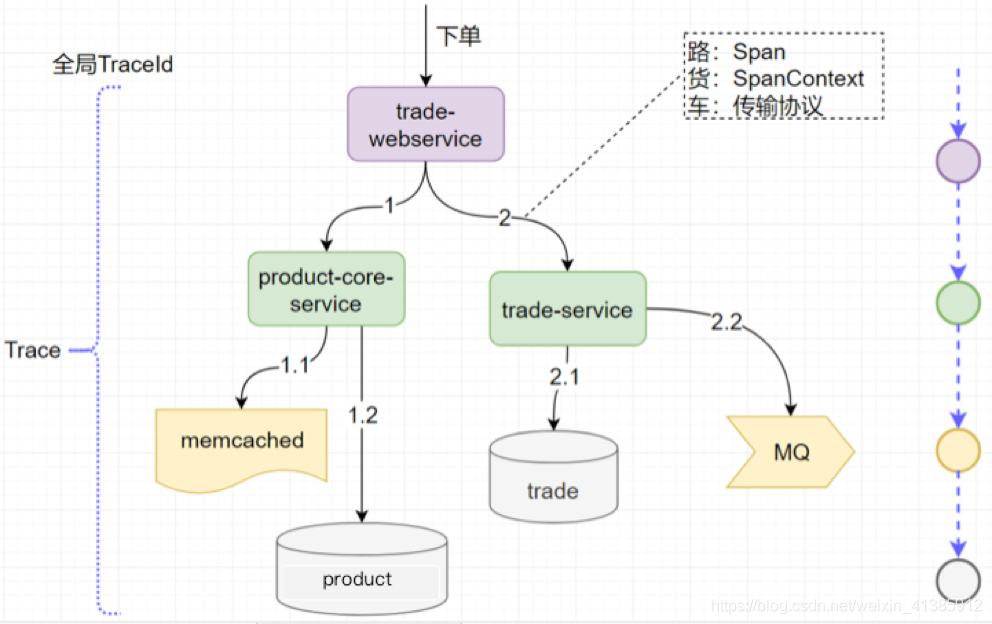
Conforme mostrado na figura, a solicitação completa de um pedido é um rastreamento completo Obviamente, para esta solicitação, deve haver um identificador global para identificar essa solicitação. Cada chamada é chamada de Span, e cada chamada deve ser trazida. O TraceId global, para que o TraceId global possa ser associado a cada chamada. Este TraceId é transmitido através do SpanContext. Como é necessário transmitir, obviamente deve ser chamado de acordo com o protocolo. Conforme mostrado na figura, comparamos o protocolo de transmissão para um carro, SpanContext para mercadorias e Span para estradas. Deve ser melhor entendido.
Depois de entender esses três conceitos, deixe-me ver como o sistema de rastreamento distribuído coleta a cadeia de chamadas de microsserviço no gráfico unificado.
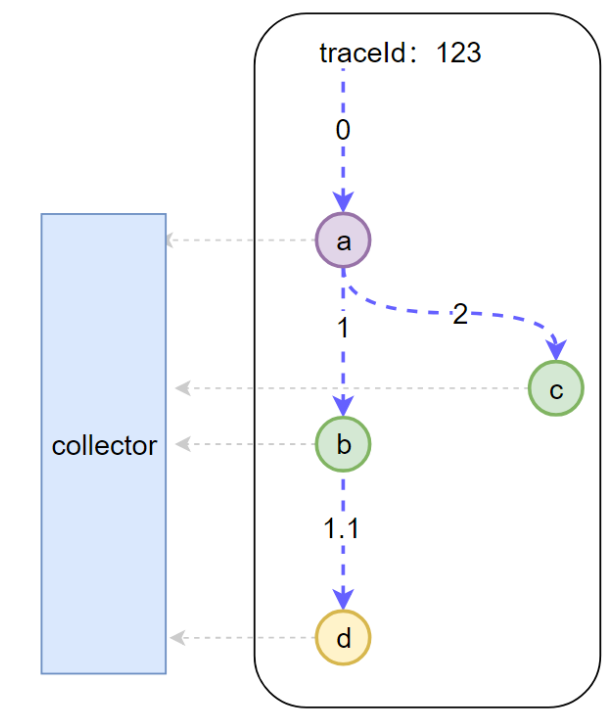
Podemos ver que há um Coletor na camada inferior que tem coletado dados na obscuridade, então quais informações serão coletadas toda vez que o Coletor for chamado.
- Trace_id global: isso é óbvio, de modo que cada sub-chamada pode ser associada à solicitação original
- span_id: 0, 1, 1.1, 2 na figura, para que você possa identificar qual chamada
- parent_span_id: Por exemplo, o span_id de b chamando d é 1.1, então seu parent_span_id é o span_id de a chamando b, que é 1, de modo que as duas chamadas adjacentes podem ser associadas.
Com essas informações, as informações coletadas pelo Coletor para cada chamada são as seguintes

De acordo com essas informações do gráfico, é óbvio que a visão visual da cadeia de chamadas pode ser desenhada da seguinte forma
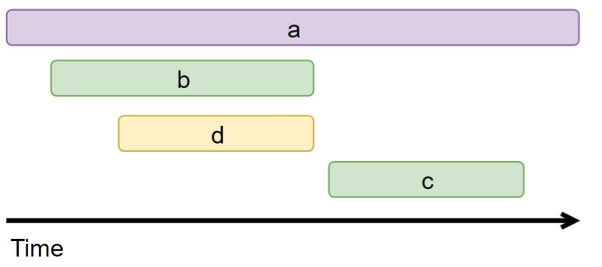
Assim, um sistema completo de rastreamento distribuído é realizado.
A implementação acima parece muito simples, mas existem vários problemas que exigem que pensemos com cuidado
- Como automaticamente dados extensão Coletar: coleta automática, sem invasão do código de negócios
- Como transferir contexto entre processos
- Como garantir a exclusividade global de traceId
- Tantas solicitações afetarão o desempenho?
A seguir, deixe-me ver como SkyWalking resolve os quatro problemas acima
Princípio e projeto de arquitetura de SkyWalking
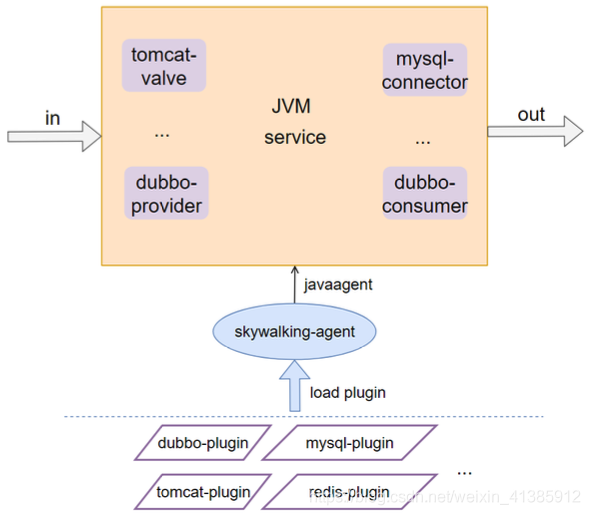
Como coletar dados abrangidos automaticamente
SkyWalking adota a forma de plug-in + javaagent para realizar a coleta automática de dados de span, de modo que possa ser não invasivo ao código , plug-in significa plugável, boa extensibilidade (a seguir apresentará como definir seu próprio plug-in )
Como transferir contexto entre processos
Sabemos que os dados geralmente são divididos em cabeçalho e corpo, assim como http tem cabeçalho e corpo, RocketMQ também tem MessageHeader, Corpo da mensagem, corpo geralmente contém dados de negócios, portanto, não é adequado passar o contexto no corpo, mas deve passar o contexto no cabeçalho, conforme mostrado na figura
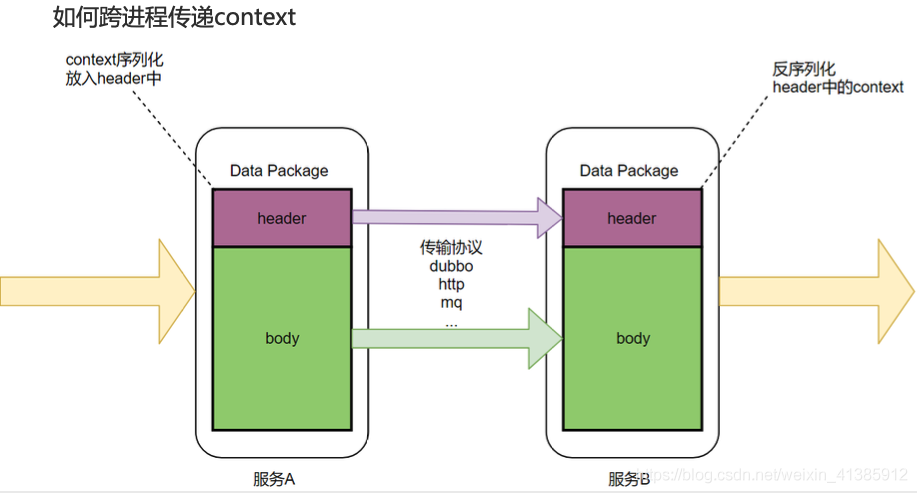
O anexo em dubbo é equivalente ao cabeçalho, então colocamos o contexto no anexo, o que resolve o problema de transferência de contexto.

Dicas: O processo de transferência de contexto aqui é feito no plugin dubbo, e a empresa não sabe. Como este plugin é implementado, analisarei a seguir
Como garantir a exclusividade global de traceId
Para garantir exclusividade global, podemos usar IDs distribuídos ou gerados localmente. Se você usar IDs distribuídos, precisa ter um remetente. Cada vez que você solicitar, deve primeiro solicitar o remetente. Haverá uma sobrecarga de chamada de rede, então SkyWalking acabará Ele usa o método de geração local de ID, usa o famoso algoritmo de fluxo de neve e tem alto desempenho.

Ilustração: id gerado pelo algoritmo do floco de neve
No entanto, o algoritmo do floco de neve tem um problema bem conhecido: o retorno de chamada em tempo , que pode causar a geração de id duplicado. Então, como SkyWalking resolve o problema de retorno de chamada de tempo?
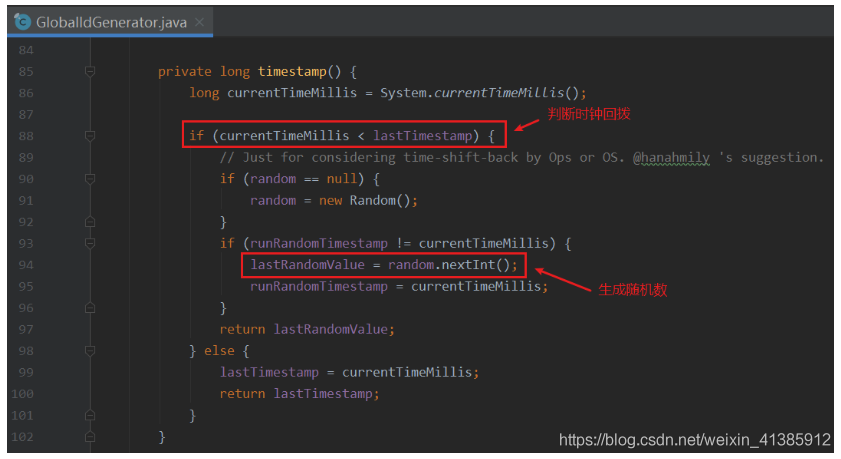
Cada vez que um id é gerado, o horário em que o id foi gerado (lastTimestamp) é registrado. Se o horário atual for menor do que o horário em que o id foi gerado pela última vez (lastTimestamp), significa que ocorreu um retorno de chamada de tempo e um número aleatório será gerado como traceId. Pode haver alunos que desejam ser mais reais aqui, e eles podem sentir que o número aleatório gerado também será o mesmo que o ID global gerado. Seria melhor se você adicionar outra camada de verificação.
Aqui quero falar sobre a escolha do design do sistema. Em primeiro lugar, se a exclusividade do número aleatório gerado for verificada, haverá, sem dúvida, uma camada extra de chamada, haverá uma certa perda de desempenho, mas na verdade, a probabilidade de retorno de chamada em tempo é muito pequena. (Após a ocorrência, o negócio será muito afetado devido à desordem do tempo da máquina, portanto, o ajuste do tempo da máquina deve ser cauteloso), mais a probabilidade dos números aleatórios gerados se sobreporem também é muito pequena e realmente não há necessidade de adicionar um aqui. Verificação de exclusividade global da camada. Para a seleção de soluções técnicas, devemos evitar o over-design.
Com tantas solicitações, toda a coleta afetará o desempenho?
Se você ligar para cada solicitação de coleta, então não há dúvida de que a quantidade de dados será muito grande, mas por sua vez, pense se é realmente necessário coletar para cada solicitação. Na verdade, não é necessário. Podemos definir a frequência de amostragem e apenas amostrar Para parte dos dados, o padrão SkyWalking é amostrar 3 vezes em 3 segundos, e outras solicitações não são amostradas, conforme mostrado na figura
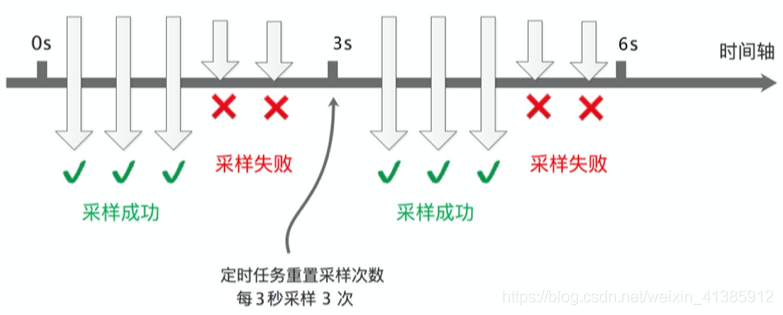
Este tipo de frequência de amostragem é suficiente para analisarmos o desempenho do componente. Que problemas haverá ao amostrar dados com uma frequência de 3 vezes em 3 segundos? Idealmente, cada chamada de serviço ocorre no mesmo ponto no tempo (conforme mostrado na figura abaixo), então é normal amostrar no mesmo ponto no tempo todas as vezes.
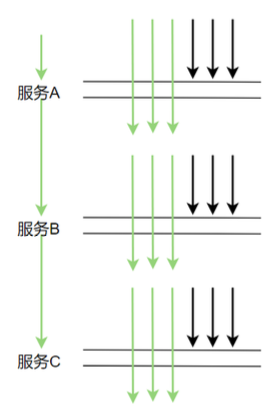
No entanto, na produção, é basicamente impossível que cada chamada de serviço seja chamada ao mesmo tempo, porque há atrasos nas chamadas de rede durante o período, e a situação real da chamada provavelmente será como a figura a seguir
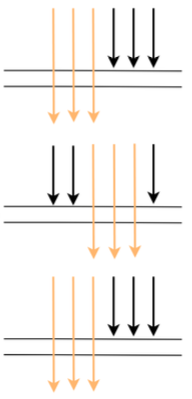
Nesse caso, algumas chamadas serão amostradas no serviço A, mas não nos serviços B e C, e é impossível analisar o desempenho da cadeia de chamadas.Então, como SkyWalking resolve isso?
É resolvido assim: se o upstream transportar Contexto (indicando amostragem upstream), o downstream é forçado a coletar dados. Isso pode garantir a integridade do link.
Infraestrutura do SkyWalking
A estrutura básica do SkyWalking é a seguinte. Pode-se dizer que quase todas as chamadas distribuídas são compostas pelos seguintes componentes
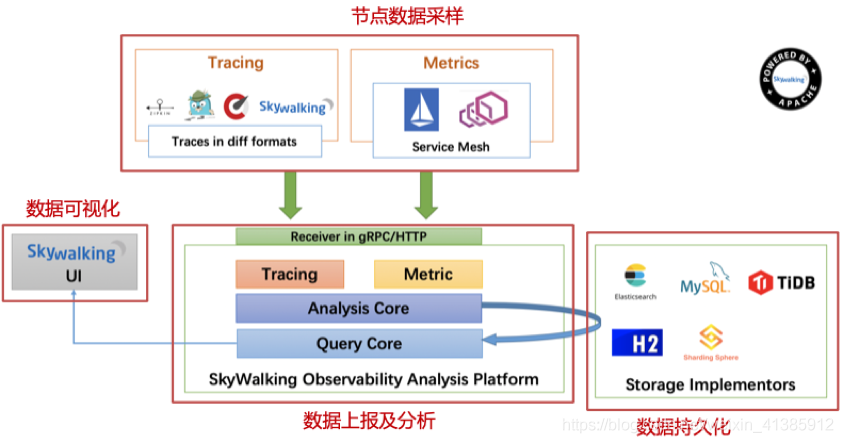
Em primeiro lugar, é claro, a amostragem regular dos dados do nó. Após a amostragem, os dados são relatados regularmente e armazenados na camada de persistência, como ES e MySQL. Com os dados, é natural fazer uma análise visual com base nos dados.
Como funciona o SkyWalking
A seguir, todos estão definitivamente preocupados com o desempenho do SkyWalking, então vamos dar uma olhada nos dados de avaliação oficial
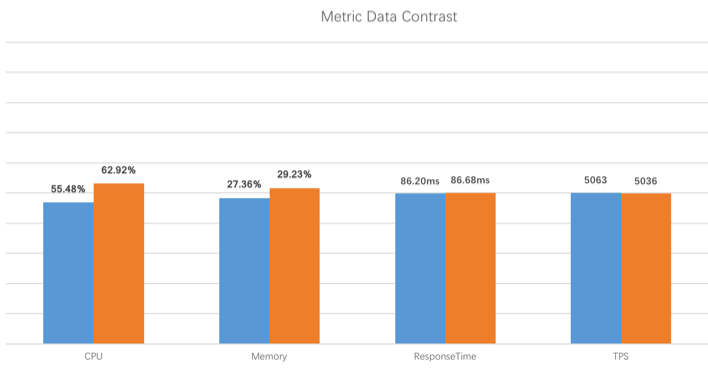
O azul na figura representa o desempenho sem SkyWalking e o laranja representa o desempenho com SkyWalking. Os dados acima são medidos com um TPS de 5000. Pode ser visto que seja CPU, memória ou tempo de resposta, use SkyWalking com A perda de desempenho resultante é quase insignificante.
A seguir, vamos dar uma olhada na comparação entre SkyWalking e Zipkin, Pinpoint, outra ferramenta de rastreamento distribuída bem conhecida na indústria (comparação com uma taxa de amostragem por segundo, 500 threads e 5.000 solicitações no total). Pode-se ver que Zipkin (117ms) e PinPoint (201ms) são muito inferiores ao SkyWalking (22ms) em termos de tempo de resposta crítico !
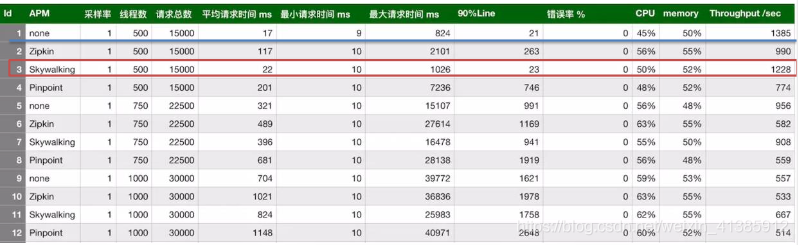
Do índice de perda de desempenho, SkyWalking venceu!
Outra olhada no indicador: como o código é invasivo, requer Zipkin enterrado no ponto de aplicação, forte invasão do código, usando o SkyWalking javaagent + widget de tais modificações formas de bytecode para fazer para Não há intrusão de código . Além do desempenho e intrusividade do código, SkyWaking tem um bom desempenho e também tem as seguintes vantagens
- Suporte a vários idiomas, componentes ricos: atualmente ele oferece suporte a Java, .Net Core, PHP, NodeJS, Golang, linguagens LUA, e os componentes também oferecem suporte a componentes comuns, como dubbo, mysql, e a maioria deles pode atender às nossas necessidades.
- Extensibilidade: Para plug-ins insatisfeitos, podemos escrever um manualmente de acordo com as regras do SkyWalking, e os plug-ins recém-implementados não invadirão o código.
A prática da nossa empresa na cadeia de chamadas distribuída
Estrutura do aplicativo SkyWalking em nossa empresa
Do acima exposto, podemos ver que SkyWalking tem muitas vantagens, então usamos todos os seus componentes? Na verdade, não é. Vamos dar uma olhada em sua arquitetura de aplicativo em nossa empresa.
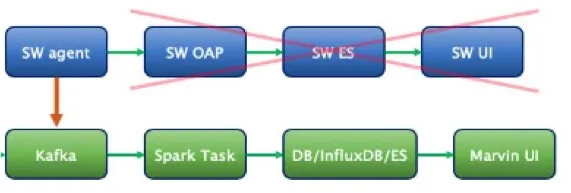
Pode ser visto na figura que usamos apenas o agente do SkyWalking para amostragem e abandonamos os outros três componentes de "relatório e análise de dados", "armazenamento de dados" e "visualização de dados", então por que não usar diretamente todo o conjunto do SkyWalking A solução é porque nosso ecossistema de monitoramento Marvin estava relativamente completo antes de nos conectarmos ao SkyWalking. Se o substituirmos pelo SkyWalking, não será necessário. O Marvin pode atender às nossas necessidades na maioria dos cenários. O custo da substituição do sistema é alto e, em terceiro lugar, é muito caro reconectar os usuários para aprender.
Isso também nos esclarece: é muito importante que qualquer produto aproveite a oportunidade, e o custo de reposição dos produtos subsequentes será alto. Aproveitar a primeira oportunidade significa dominar a mente do usuário. É como o WeChat. Embora a IU seja bem feita, é Whatsapp não pode ser feito em países estrangeiros, porque a primeira oportunidade se foi.
Por outro lado, para a arquitetura, não existe o melhor, apenas o mais adequado. Combinar o cenário de negócios atual para equilibrar a compensação é a essência do design de arquitetura
Que transformações e práticas nossa empresa fez para SkyWalking
Nossa empresa fez principalmente as seguintes transformações e práticas
- O ambiente de pré-lançamento requer amostragem obrigatória devido à depuração
- Obter uma amostragem mais precisa?
- TraceId incorporado no log
- Implementação auto-desenvolvida do plug-in SkyWalking
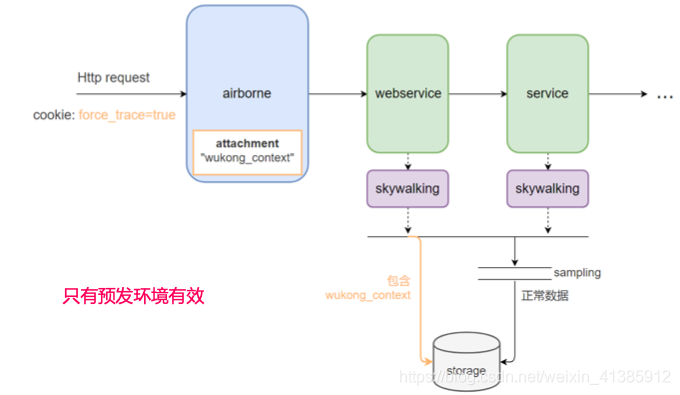
O ambiente de pré-lançamento requer amostragem obrigatória devido à depuração
A partir da análise acima, podemos ver que o Collector está fazendo amostragem regularmente em segundo plano. Não é bom? Por que precisamos implementar a amostragem forçada? Ainda é para solucionar problemas de posicionamento. Às vezes, há problemas online. Esperamos reproduzi-lo no pré-lançamento, esperando ver a cadeia de chamadas completa desta solicitação, por isso é necessário implementar a amostragem forçada no pré-lançamento. Então, modificamos o plug-in dubbo do Skywalking para implementar a amostragem forçada
Trazemos um par de valores-chave como force_flag = true no cookie solicitado para indicar que queremos forçar a amostragem. Depois que o gateway recebe esse cookie, ele trará o par de valores-chave force_flag = true no anexo dubbo, e então O plug-in dubbo do skywalking pode julgar se é uma amostragem forçada com base nisso. Se houver esse valor, significa amostragem forçada. Se não houver tal valor, será feita uma amostragem de tempo normal.
Obter uma amostragem mais precisa?
Hah chamado de amostragem mais refinada. Primeiro, olhe para o método de amostragem padrão de skywalking, ou seja, amostragem unificada
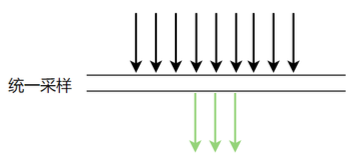
Sabemos que o padrão desse método é 3 vezes antes da amostragem em 3 segundos, e todas as outras solicitações são descartadas. Nesse caso, há um problema. Suponha que haja várias chamadas dubbo, mysql e redis em 3 segundos nesta máquina, mas se nas primeiras três vezes Se forem todas chamadas dubbo, outras chamadas como mysql, redis, etc. não podem ser amostradas, então modificamos o skywalking para obter amostragem de grupo, como segue
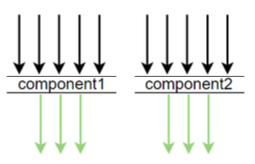
Em outras palavras, 3 amostras de redis, dubbo, mysql, etc. são executadas em 3 segundos, o que evita este problema
Como incorporar traceId no log?
O traceId embutido no log de saída é conveniente para nós solucionarmos problemas, então é muito necessário digitar o traceId. Como embutir o traceId no log? Estamos usando log4j. Aqui, precisamos entender o mecanismo de plug-in log4j. Log4j nos permite personalizar o plug-in para gerar o formato de registro. Primeiro, precisamos definir o formato de registro e incorporar% traceId no formato de registro personalizado como a conta Placeholder, como segue

Em seguida, implementamos um plug-in log4j, como segue
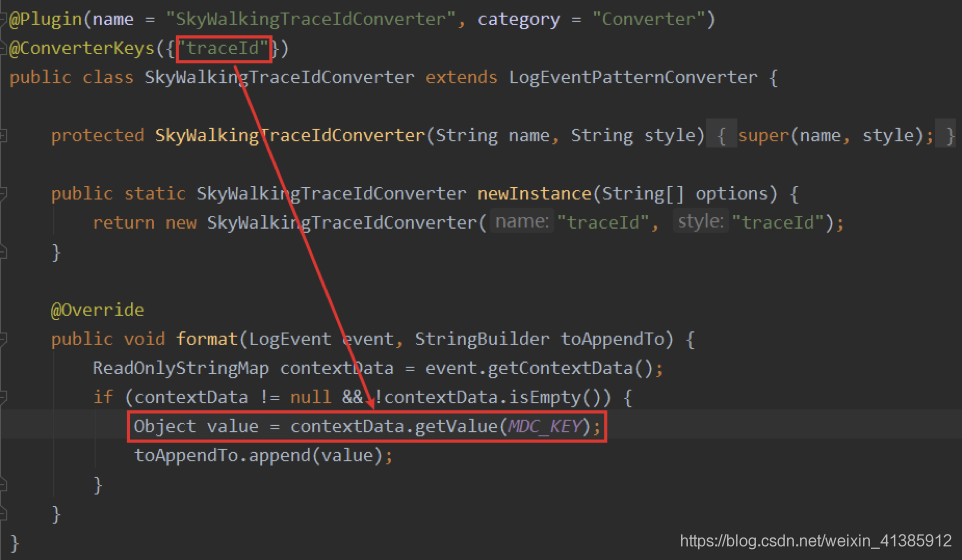
Primeiro, o plug-in log4j precisa definir uma classe que herda a classe LogEventPatternConverter e se declara um plug-in com o plug-in padrão. O marcador a ser substituído é especificado por meio da anotação @ConverterKeys e, em seguida, substituído no método de formato. Solta. Desta forma, o TraceId que desejamos aparecerá no log, como segue

Quais plugins skywalking foram desenvolvidos por nossa empresa
SkyWalking implementou muitos plug-ins, mas não fornece plug-ins memcached e druid, então nós desenvolvemos esses dois plug-ins de acordo com suas especificações
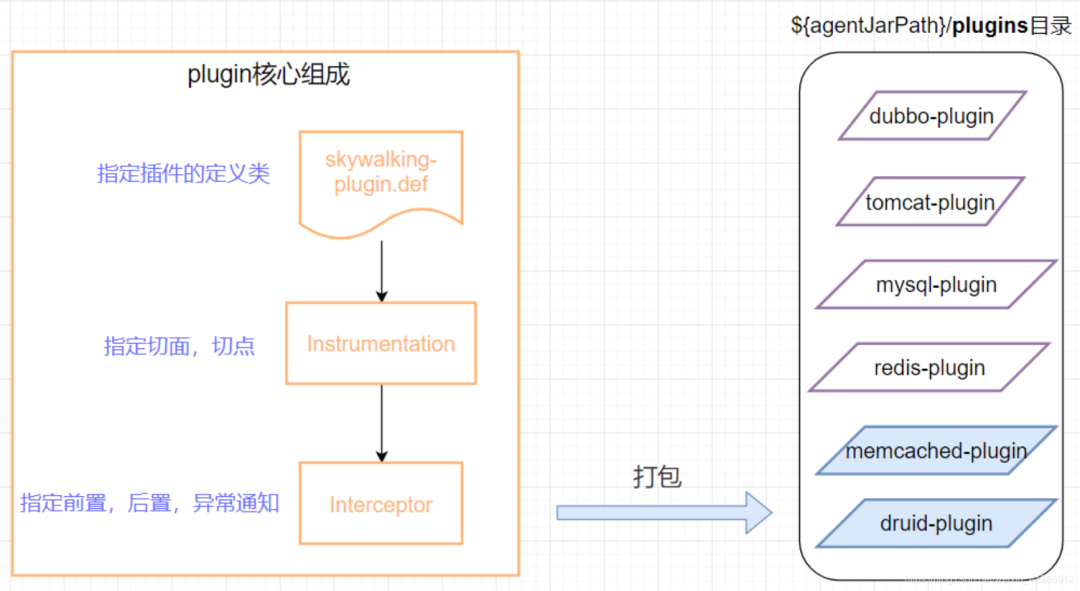
Como implementar o plug-in, você pode ver que ele é composto principalmente de três partes
- Classe de definição de plug-in: especifique a classe de definição do plug-in. Finalmente, o plug-in será empacotado e gerado de acordo com a classe de definição aqui
- Instrumentação: Especifique o aspecto, o ponto de contato, qual método de qual classe deve ser aprimorada
- Interceptor, especifique a etapa 2 É importante escrever lógica aprimorada na frente do método, atrás ou na exceção
Talvez você ainda não entenda depois de ler. Vamos explicar brevemente com o plug-in dubbo. Sabemos que no serviço dubbo, cada solicitação recebe uma mensagem do netty e a envia para o pool de discussão de negócios para processamento, até a chamada real para o final do método de negócios. Depois de mais de uma dúzia de processamento de filtro no meio
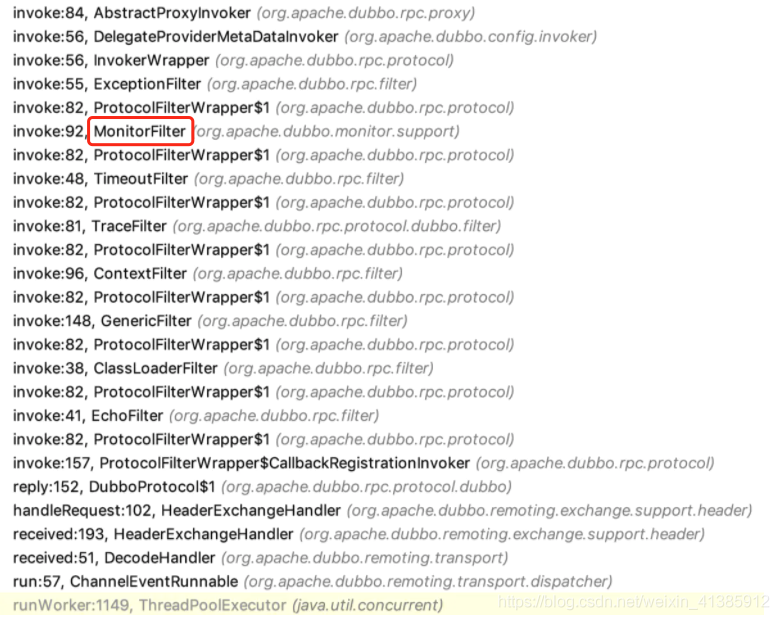
E MonitorFilter pode interceptar todas as solicitações do cliente ou solicitações de processamento do servidor, para que possamos aprimorar o MonitorFilter, antes de chamar o método invoke, injetar o traceId global no anexo de sua invocação, de modo a garantir que a solicitação chegue ao real O traceId global já existe antes da lógica de negócios.
Obviamente, precisamos especificar a classe que queremos aprimorar (MonitorFilter) no plug-in e aprimorar seu método (invocar). Quais melhorias devem ser feitas a este método? Isso é o que o interceptor (Inteceptor) faz, vamos dar uma olhada Instrumentação no plug-in Dubbo (DubboInstrumentation)

Vamos dar uma olhada no que o Inteceptor descrito no código faz. As principais etapas estão listadas abaixo
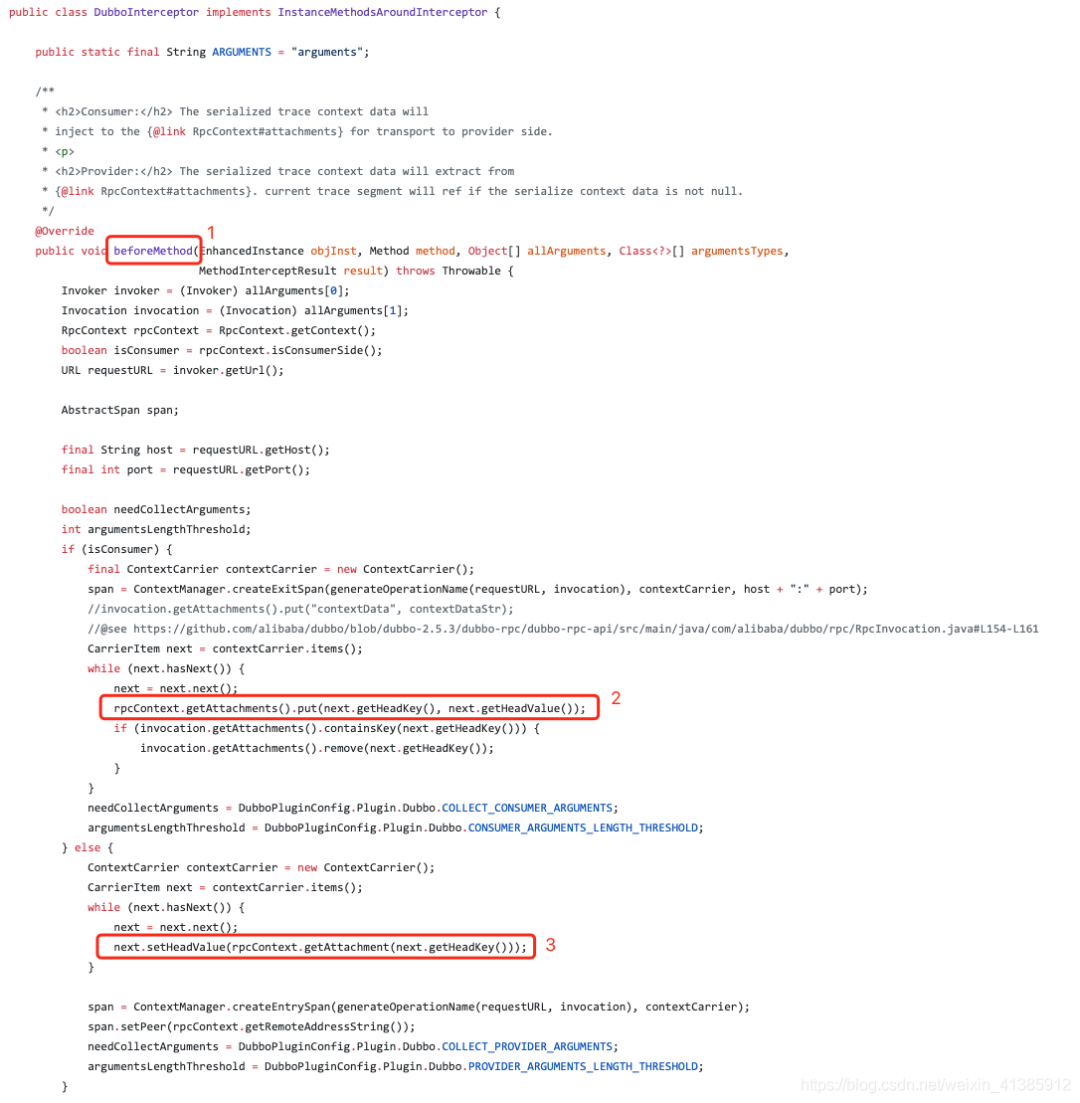
Em primeiro lugar, beforeMethod representa que o método será chamado antes que o método invoke de MonitorFilter seja executado, e o correspondente é afterMethod, que representa a lógica de aprimoramento após a execução do método invoke.
Em segundo lugar, podemos verificar nos pontos 2 e 3 que, quer se trate de um consumidor ou de um fornecedor, o ID global é processado em conformidade, de modo a garantir que o traceid global é garantido quando a camada de negócio real é atingida. Após a definição da Instrumentação e do Interceptor , A última etapa é especificar a classe definida em skywalking.def
// skywalking-plugin.def 文件
dubbo=org.apache.skywalking.apm.plugin.asf.dubbo.DubboInstrumentation
O plug-in empacotado aprimorará o método invoke do monitorFilter e executará operações como injetar traceId global no anexo antes da execução do método invoke.Todos são silenciosos e não intrusivos para o código .
Resumindo
Este artigo apresenta o princípio do sistema de rastreamento distribuído do mais superficial ao mais profundo. Acredito que todos têm uma compreensão mais profunda de sua função e mecanismo de funcionamento. É particularmente importante observar que a introdução de uma determinada técnica deve ser combinada com a arquitetura técnica existente para fazer o melhor Uma escolha razoável, assim como SkyWalking tem quatro módulos. Nossa empresa usa apenas sua função de amostragem de agente. Não existe a melhor tecnologia, apenas a tecnologia mais adequada . Por meio deste artigo, acredito que todos deveriam ter um entendimento mais claro do mecanismo de implementação do SkyWalking. O artigo apenas apresenta a implementação do plug-in SkyWalking, mas é um software de nível industrial, afinal. Para entender sua amplitude e profundidade, você deve ler mais código-fonte.
Mais materiais de estudo de entrevista foram classificados em meu repositório git, e amigos necessitados podem pegá-los: https://gitee.com/biwangsheng/personal.git