Hoje compartilharei com vocês o terceiro projeto de competição Kaggle, New-York-City-Taxi-Fare-Prediction. A característica deste projeto é que o conjunto de dados fornecido a nós é relativamente grande, 5,3 G, e a quantidade total de dados é 5400 W linhas. No entanto, quando estamos fazendo este projeto, não precisamos de tantos dados. Vamos dar uma olhada neste projeto juntos.
Parte 1. Importação de dados e análise preliminar
Primeiro importe nosso conjunto de dados. Devido à grande quantidade de dados, importamos apenas as primeiras 500 W linhas de dados para modelagem.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train = pd.read_csv('train.csv',nrows=5000000)
test = pd.read_csv('test.csv')
test_ids = test['key']
train.head()

Pode-se ver que nossa quantidade de recursos de dados desta vez ainda é relativamente pequena, embora a quantidade total de dados seja grande, existem apenas 8 recursos.
train.info()

chave: índice
fare_amount: preço
pickup_datetime: horário
em que o táxi recebeu o passageiro pickup_longitude: longitude
na partida
pickup_latitude: latitude na partida dropoff_longitude: longitude
na chegada dropoff_latitude: latitude na chegada
passageira_count: número de passageiros
train.describe()

Os dados dentro do círculo vermelho são discrepantes: preços negativos, o número mínimo de passageiros é 0 e o número máximo de passageiros é 208.
Os dados traçados pela linha horizontal são intrigantes: que tipo de viagem terá um custo de aluguel de 1270?
Parte 2. Análise de dados
Primeiro observe a distribuição das características de preço:
train.fare_amount.hist(bins=100,figsize = (16,8))
plt.xlabel("Fare Amount")
plt.ylabel("Frequency")

train[train.fare_amount <100 ].fare_amount.hist(bins=100, figsize = (16,8))
plt.xlabel("Fare Amount")
plt.ylabel("Frequency")

train[train.fare_amount >=100 ].fare_amount.hist(bins=100, figsize = (16,8))
plt.xlabel("Fare Amount")
plt.ylabel("Frequency")

train[train.fare_amount <100].shape
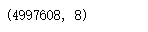
train[train.fare_amount >=100].shape

A partir do código e do diagrama acima, podemos obter várias conclusões:
1. A distribuição dos preços está principalmente dentro de 100, uma pequena parte está acima de 100
e os preços dentro de 100 estão principalmente concentrados entre 0 e 20, 3
e fora de 100 . A maioria dos preços está concentrada em torno de 200, e alguns preços relativamente altos podem ser discrepantes ou podem ser preços para o aeroporto.
A seguir, observe a distribuição do número de passageiros:
train.passenger_count.hist(bins=100,figsize = (16,8))
plt.xlabel("passenger_count")
plt.ylabel("Frequency")

train[train.passenger_count<10].passenger_count.hist(bins=10,figsize = (16,8))
plt.xlabel("passenger_count")
plt.ylabel("Frequency")

train[train.passenger_count<7].passenger_count.hist(bins=10,figsize = (16,8))
plt.xlabel("passenger_count")
plt.ylabel("Frequency")

train[train.passenger_count>7].passenger_count.hist(bins=10,figsize = (16,8))
plt.xlabel("passenger_count")
plt.ylabel("Frequency")

train[train.passenger_count >7]

train[train.passenger_count ==0].shape

plt.figure(figsize= (16,8))
sns.boxplot(x = train[train.passenger_count< 7].passenger_count, y = train.fare_amount)

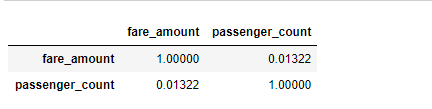
train[train.passenger_count <7][['fare_amount','passenger_count']].corr()
A partir do código e do gráfico acima, podemos tirar várias conclusões:
1. A distribuição do número de pessoas está principalmente dentro de 7, uma pequena parte está fora
de 7. 2. Nos dados com o número de pessoas fora de 7, a maioria das coordenadas de dados está faltando e o número de pessoas é 208
3. Existem 17.602 dados de que o número de passageiros é 0, pode ser um táxi que transporta mercadorias, ou pode haver dados ausentes.
4. No gráfico de caixa, pode-se ver que o preço médio dos táxis com menos de 7 é próximo a
5. Use a interface .corr () para verificar se a correlação entre passage_count e fare_amount não é alta, apenas 0,013
Parte 3. Processamento de dados
1. Processamento de valor nulo
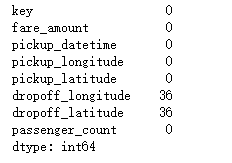
train.isnull().sum()#找出空值
train = train.dropna(how='any', axis=0)
36 valores ausentes são insignificantes para nosso volume de dados de 500 W, então eu escolho remover diretamente os valores ausentes
test = pd.read_csv('test.csv')
test_ids = test['key']
test.head()
test.isnull().sum()

Faça o mesmo para o conjunto de teste, mas o conjunto de teste não tem valores ausentes
2. Manuseio de outlier
train = train[train.fare_amount>=0]
Remova os dados com preços negativos
3. Engenharia de recursos
① Encurtar o escopo do conjunto de treinamento Como a quantidade de dados no conjunto de treinamento é relativamente grande, podemos reduzir o conjunto de treinamento de
acordo com o intervalo de coordenadas do conjunto de teste.
print(min(test.pickup_longitude.min(),test.dropoff_longitude.min()))
print(max(test.pickup_longitude.max(),test.dropoff_longitude.max()))
print(min(test.pickup_latitude.min(),test.dropoff_latitude.min()))
print(max(test.pickup_latitude.max(),test.dropoff_latitude.max()))
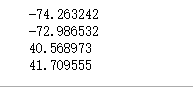
Obtenha -74,2 a -73 como o intervalo de seleção de longitude e 40,5 a 41,8 como o intervalo de seleção de latitude
def select_train(df, fw):
return (df.pickup_longitude >= fw[0]) & (df.pickup_longitude <= fw[1]) & \
(df.pickup_latitude >= fw[2]) & (df.pickup_latitude <= fw[3]) & \
(df.dropoff_longitude >= fw[0]) & (df.dropoff_longitude <= fw[1]) & \
(df.dropoff_latitude >= fw[2]) & (df.dropoff_latitude <= fw[3])
fw = (-74.2, -73, 40.5, 41.8)
train = train[select_train(train, fw)]
Use select_train para reduzir os dados do conjunto de treinamento
②Construindo novos recursos de tempo. Os
recursos de tempo originais não são adequados para uso direto. Considerando que os táxis podem aumentar os preços em diferentes períodos, anos e meses, precisamos extrair novos anos e meses dos recursos de tempo originais. , Dia e hora são novos recursos para nosso modelo.
def deal_time_features(df):
df['pickup_datetime'] = df['pickup_datetime'].str.slice(0, 16)
df['pickup_datetime'] = pd.to_datetime(df['pickup_datetime'], utc=True, format='%Y-%m-%d %H:%M')
df['hour'] = df.pickup_datetime.dt.hour
df['month'] = df.pickup_datetime.dt.month
df["year"] = df.pickup_datetime.dt.year
df["weekday"] = df.pickup_datetime.dt.weekday
return df
train = deal_time_features(train)
test = deal_time_features(test)
train.head()

O recurso de tempo processado consiste em hora, mês, ano e dia da semana
③Construir novos recursos de distância
diretamente usando coordenadas de latitude e longitude não é propício para a operação de nosso modelo, usamos fórmulas de conversão para converter coordenadas de latitude e longitude em distância
def distance(x1, y1, x2, y2):
p = 0.017453292519943295
a = 0.5 - np.cos((x2 - x1) * p)/2 + np.cos(x1 * p) * np.cos(x2 * p) * (1 - np.cos((y2 - y1) * p)) / 2
dis = 0.6213712 * 12742 * np.arcsin(np.sqrt(a))
return dis
train['distance_miles'] = distance(train.pickup_latitude,train.pickup_longitude,train.dropoff_latitude,train.dropoff_longitude)
test['distance_miles'] = distance(test.pickup_latitude, test.pickup_longitude,test.dropoff_latitude,test.dropoff_longitude)
train.head()

train[(train['distance_miles']==0)&(train['fare_amount']==0)]

Depois de construir o recurso de distância, descobriremos que existem mais 15 dados inúteis, cuja distância e preço são ambos 0, que podem ser excluídos
train = train.drop(index= train[(train['distance_miles']==0)&(train['fare_amount']==0)].index, axis=0)
④ Processamento especial
1. Exclua os dados com fare_amount menor que 2,5, porque a tarifa inicial dos táxis em Nova York é 2,5
train = train.drop(index= train[train['fare_amount'] < 2.5].index, axis=0)
2. Remova dados com mais de 7 pessoas
train[train.passenger_count >= 7]

train = train.drop(index= train[train.passenger_count >= 7].index, axis=0)
Parte4. Modelagem de dados
Dê uma olhada na aparência final após o processamento dos dados
train.describe().T

Use a interface .corr para ver como esses novos recursos se relacionam com os preços
train.corr()['fare_amount']

Passos para a modelagem:
df_train = train.drop(columns= ['key','pickup_datetime'], axis= 1).copy()
df_test = test.drop(columns= ['key','pickup_datetime'], axis= 1).copy()
#使用copy后的数据进行建模
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train.drop('fare_amount',axis=1)
,df_train['fare_amount']
,test_size=0.2
,random_state = 42)
#用train_test_split分出训练集和测试集
import xgboost as xgb
params = {
'max_depth': 7,
'gamma' :0,
'eta':0.3,
'subsample': 1,
'colsample_bytree': 0.9,
'objective':'reg:linear',
'eval_metric':'rmse',
'silent': 0
}
def XGBmodel(X_train,X_test,y_train,y_test,params):
matrix_train = xgb.DMatrix(X_train,label=y_train)
matrix_test = xgb.DMatrix(X_test,label=y_test)
model=xgb.train(params=params,
dtrain=matrix_train,
num_boost_round=5000,
early_stopping_rounds=10,
evals=[(matrix_test,'test')])
return model
model = XGBmodel(X_train,X_test,y_train,y_test,params)
#建模
prediction = model.predict(xgb.DMatrix(df_test), ntree_limit = model.best_ntree_limit)
prediction
#数据预测

res = pd.DataFrame()
res['key'] = test_ids
res['fare_amount'] = prediction
res.to_csv('submission.csv', index=False)
#结果保存
Parte 5. Resumo
Minha abordagem é apenas uma maneira relativamente simples de pensar, porque os únicos fatores que consigo pensar sobre os preços dos táxis são os diferentes períodos de tempo e distâncias. Esses dois fatores terão um impacto maior. Se você tiver outras ideias e práticas melhores, deixe uma mensagem na área de discussão para contar ao blogger.
Além disso, existe uma maneira na comunidade kaggle de construir um novo recurso, que representa a distância das coordenadas para três aeroportos locais diferentes. Esse método é usado pelo blogueiro diretamente quando os parâmetros não são ajustados. O resultado é um aumento de 0,03. Acho que a melhoria é Não é muito grande e a função se sobrepõe um pouco à distância, então não usei no final. Poste aqui e compartilhe com todos.
# def transform(data):
# # Distances to nearby airports,
# jfk = (-73.7781, 40.6413)
# ewr = (-74.1745, 40.6895)
# lgr = (-73.8740, 40.7769)
# data['pickup_distance_to_jfk'] = distance(jfk[1], jfk[0],
# data['pickup_latitude'], data['pickup_longitude'])
# data['dropoff_distance_to_jfk'] = distance(jfk[1], jfk[0],
# data['dropoff_latitude'], data['dropoff_longitude'])
# data['pickup_distance_to_ewr'] = distance(ewr[1], ewr[0],
# data['pickup_latitude'], data['pickup_longitude'])
# data['dropoff_distance_to_ewr'] = distance(ewr[1], ewr[0],
# data['dropoff_latitude'], data['dropoff_longitude'])
# data['pickup_distance_to_lgr'] = distance(lgr[1], lgr[0],
# data['pickup_latitude'], data['pickup_longitude'])
# data['dropoff_distance_to_lgr'] = distance(lgr[1], lgr[0],
# data['dropoff_latitude'], data['dropoff_longitude'])
# return data
# train = transform(train)
# test = transform(test)