índice
Flume-custom interceptor, custom Source para ler dados do MySQL, custom Sink
Instalação da calha
- Baixe o Flume do site oficial: http://flume.apache.org/download.html
- - :Tar -zxvf apache-flume-1.9.0-bin.tar.gz
- Renomeie o diretório: mv apache-flume-1.9.0-bin flume-1.9.0
- Renomeie flume-env.sh.template no diretório conf: mv flume-env.sh.template flume-env.sh
- Modifique flume-env.sh:

- Modifique / etc / profile:
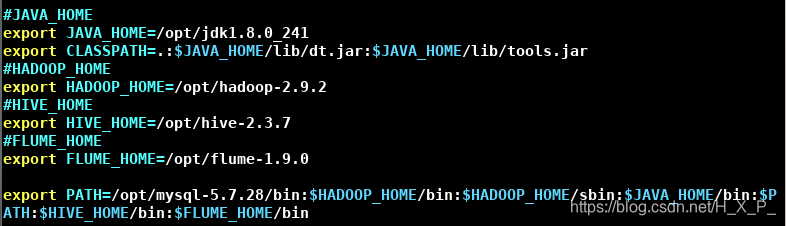
- fonte / etc / perfil

Caso 1: porta de escuta
Os parâmetros exigidos pelo arquivo de configuração podem ser visualizados no site oficial e as opções em negrito são obrigatórias.

análise de caso
- Envie dados para a porta 44444 da máquina através da ferramenta netcat
- O Flume monitora a porta 44444 da máquina e lê os dados por meio da fonte
- Flume grava os dados adquiridos no console por meio do coletor
Etapas do caso
-
Instale o netcat em cada host: yum install -y nc
-
Verifique se a porta 44444 está ocupada: netstat -tunlp | grep 44444
-
Uso do Netcat: insira nc -lk 44444 como o servidor e nc host 44444 como o cliente, que podem se comunicar entre si

-
Crie o arquivo de configuração do Flume Agent netcat-flume-logger.conf :
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1O arquivo de configuração possui 5 partes, separadas por linhas em branco
- Nomeie os componentes do Agente . a1 é o nome do agente, r1 é o nome da fonte, c1 é o nome do canal e k1 é o nome do coletor. Observe que as palavras estão no plural , indicando que pode haver vários componentes.
- Configure a fonte . O tipo de origem de r1 é netcat , o host de escuta é localhost e o número da porta de escuta é 44444.
- Configure o coletor . O tipo de k1 é logger , que é enviado para o console.
- Configure o canal . O tipo de canal c1 é a memória , a capacidade do buffer é de 1000 eventos (Flume usa Event como unidade de transmissão) e a capacidade de transação é de 100 eventos (dados transmitidos de uma vez).
- Vincule três componentes . Como pode haver várias fontes, canais e sumidouros, eles precisam ser vinculados. INFO refere-se a INFO e mensagens acima. Observe o grande número de canais. Uma fonte pode ser vinculada a vários canais, um canal pode ser vinculado a vários coletores e um coletor só pode ser vinculado a um canal .
-
Inicie o Flume, neste momento Flume como o servidor. conf é o diretório conf sob o diretório Flume, conf-file é um arquivo de configuração escrito por você e name é o nome do Agente.
bin/flume-ng agent --conf conf --conf-file netcat-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console 或者 bin/flume-ng agent --c conf --f netcat-flume-logger.conf --n a1 -Dflume.root.logger=INFO,console -
Inicie um novo terminal e digite nc localhost 44444 e digite a string


-
Ctrl + c para fechar. Você pode usar kill, mas não use kill -9. Kill -9 não executará o programa de gancho (trabalho de acabamento).
Caso 2: monitoramento de arquivos locais
análise de caso
- Flume monitora alterações de arquivos locais
- Alterar arquivos em tempo hábil através do crontab
- Flume envia dados para o console
Etapas do caso
-
Crie um arquivo vazio no diretório Flume: toque em date.txt
-
Crie o arquivo de configuração do Flume Agent exec-flume-logger.conf , o tipo de origem é exec , o tipo de coletor é logger e o comando é tail:
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/flume-1.9.0/date.txt # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
Iniciar Flume
bin/flume-ng agent -c conf -f exec-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console -
Inicie um novo terminal, digite crontab -e , edite a tarefa cronometrada, modifique o arquivo a cada minuto e salve

-
O efeito final é o seguinte:
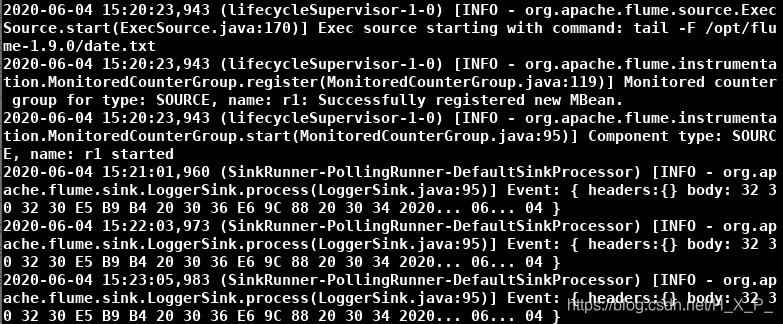
-
Digite crontab -r para excluir a tarefa de tempo do usuário atual
Caso 3: monitorar arquivos locais e fazer upload de HDFS
análise de caso
- Flume monitora arquivos de log do Hive
- Inicie o Hive e gere registros
- Flume grava os dados adquiridos no HDFS
Etapas do caso
-
Como os dados precisam ser carregados no HDFS, os pacotes jar relacionados ao Hadoop precisam ser preparados. O pacote jar pode ser encontrado no diretório share / hadoop no diretório de instalação do Hadoop .

-
Copie esses pacotes jar para o diretório lib sob o diretório Flume. Quando o Flume iniciar, os pacotes jar sob lib serão carregados na memória: mv tempjar / * /opt/flume-1.9.0/lib
-
Inicie o HDFS e o Yarn: start-dfs.sh , start-yarn.sh
-
Crie o arquivo de configuração do Flume Agent exec-flume-hdfs.conf , o tipo de origem é exec e o tipo de coletor é hdfs . Observação: para todas as sequências de escape relacionadas ao tempo, deve haver uma chave de "carimbo de data / hora" no cabeçalho do evento (a menos que hdfs.useLocalTimeStamp seja definido como verdadeiro, este método usará TimestampInterceptor para adicionar automaticamente o carimbo de data / hora).
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/hive-2.3.7/log/hive.log # Describe the sink a1.sinks.k1.type = hdfs # 创建文件的路径 a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y%m%d/%H # 上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs # 是否按照时间滚动文件夹 # 下面3个参数一起配置 a1.sinks.k1.hdfs.round = true # 多久创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 # 定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour # 是否使用本地时间戳(必须配置) a1.sinks.k1.hdfs.useLocalTimeStamp = true # 积累多少个Event才flush到HDFS一次(单位为事件) a1.sinks.k1.hdfs.batchSize = 100 # 设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream # 多久滚动生成一个新的文件(单位为秒) # 这个参数只是实验用,实际开发需要调大点 # 下面3个参数一起配置 a1.sinks.k1.hdfs.rollInterval = 30 # 设置每个文件的滚动大小(略小于文件块大小128M) a1.sinks.k1.hdfs.rollSize = 134217700 # 文件的滚动与Event数量无关(0则不按照该值) a1.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
Iniciar Flume
bin/flume-ng agent -c conf -f exec-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console -
Inicie um novo terminal, inicie o hive e execute operações de consulta
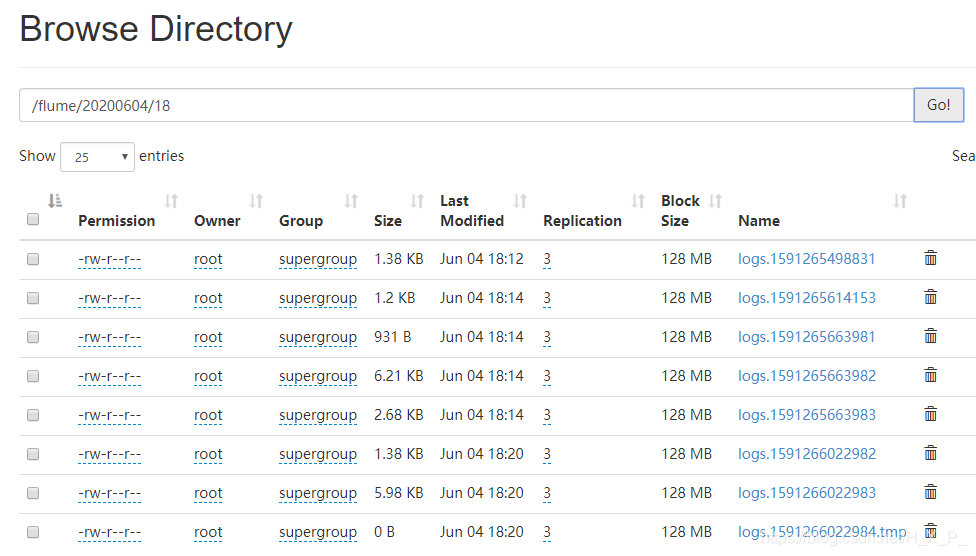
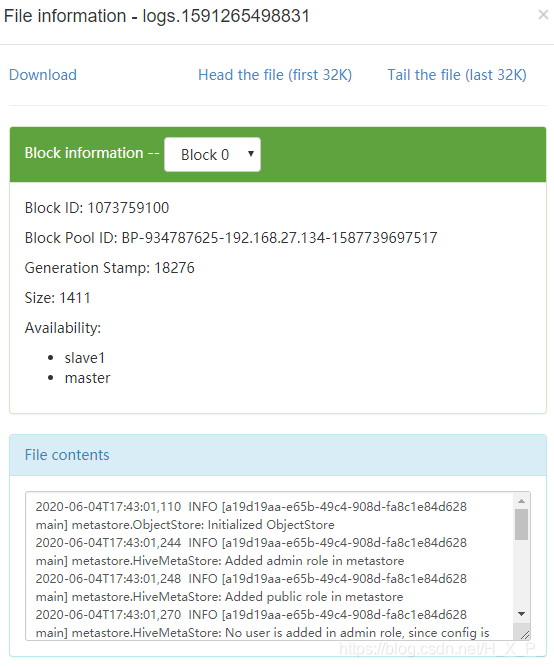
Problema anormal
2020-06-04 17: 53: 52,961 (conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSinks (AbstractConfigurationProvider.java:469)] O coletor k1 foi removido devido a um erro durante a configuração
java.lang.InstantiationException: configurações de coletor e canal incompatíveis definidas. o tamanho do lote do coletor é maior do que a capacidade de transação dos canais. Dissipador: k1, tamanho do lote = 1000, canal c1, capacidade de transação = 100
Motivo : as configurações de canal e coletor não correspondem, o tamanho do lote do coletor é maior do que a capacidade de transação do canal.
Solução : Defina a1.sinks.k1.hdfs.batchSize como menor ou igual a 100
Caso 4: monitoramento de novos arquivos no diretório e upload para HDFS
análise de caso
- O Flume monitora o diretório especificado e a pasta monitorada verifica as alterações de arquivo a cada 500 milissegundos
- Adicionar novos arquivos ao diretório
- Flume grava os dados adquiridos no HDFS. O sufixo local do arquivo carregado é .COMPLETED por padrão . Os arquivos não carregados têm o sufixo .tmp no HDFS .
O Flume usa o método acima para determinar se há um novo arquivo, mas se houver um arquivo com um sufixo .COMPLETED que não foi carregado no diretório, então o Flume não carregará o arquivo.
Ao mesmo tempo, se um arquivo com o sufixo .COMPLETED for modificado , o Flume não carregará o arquivo no HDFS, porque ele tem um sufixo .COMPLETED e o Flume pensa que foi carregado.
Portanto, esse método não pode monitorar dinamicamente os dados alterados.
Etapas do caso
-
Crie um novo diretório: diretório mkdir .
-
Crie o arquivo de configuração do Flume Agent spooldir-flume-hdfs.conf , o tipo de origem é o diretório de spool e o tipo de coletor é hdfs
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = spooldir # 监控的目录 a1.sources.r1.spoolDir = /opt/flume-1.9.0/directory #忽略所有以.tmp 结尾的文件,不上传 a1.sources.r1.ignorePattern = ([^]*\.tmp) # Describe the sink a1.sinks.k1.type = hdfs # 创建文件的路径 a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y%m%d/%H # 上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs # 是否按照时间滚动文件夹 a1.sinks.k1.hdfs.round = true # 多久创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 # 定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour # 是否使用本地时间戳(必须配置) a1.sinks.k1.hdfs.useLocalTimeStamp = true # 积累多少个Event才flush到HDFS一次(单位为事件) a1.sinks.k1.hdfs.batchSize = 100 # 设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream # 多久滚动生成一个新的文件(单位为秒) a1.sinks.k1.hdfs.rollInterval = 30 # 设置每个文件的滚动大小(略小于文件块大小128M) a1.sinks.k1.hdfs.rollSize = 134217700 # 文件的滚动与Event数量无关(0则不按照该值) a1.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
Iniciar Flume
bin/flume-ng agent -c conf -f spooldir-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console -
Crie arquivos no diretório do diretório: data> um.txt , data> dois.txt , data> três.txt

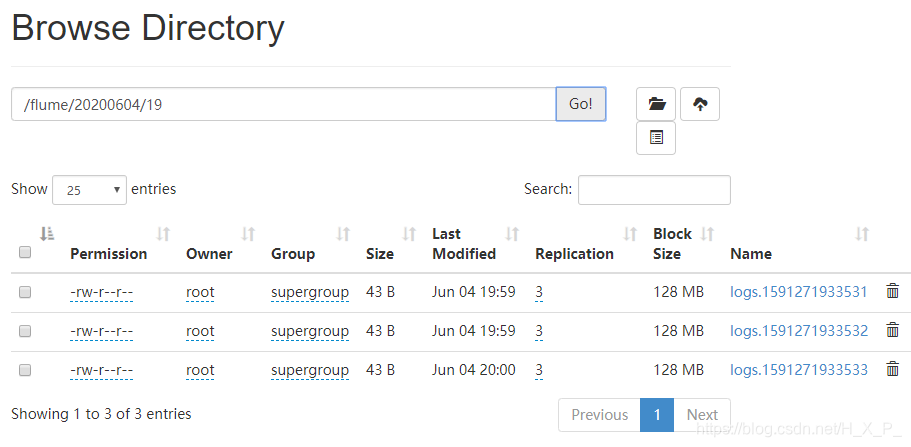
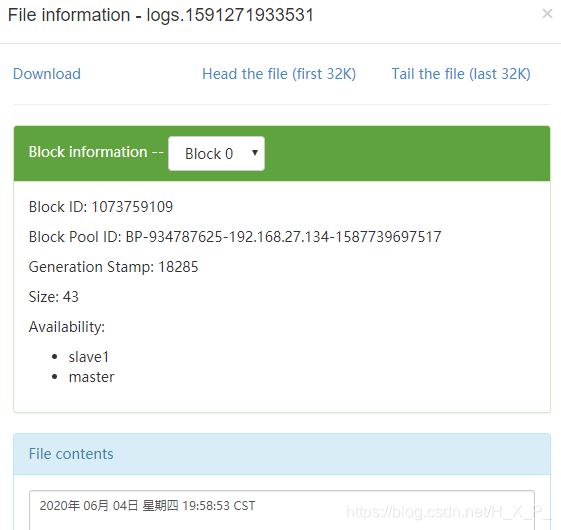
Problema anormal
Se você lançar um arquivo existente no diretório, o Flume relatará um erro. Por exemplo, coloco um one.txt nele, data> um.txt . O Flume relatará um erro de que há um novo arquivo one.txt no diretório do diretório, mas não há sufixo .COMPLETED e há novos arquivos no HDFS. Quando joguei o novo arquivo three.txt no diretório novamente, o novo arquivo não foi renomeado ou carregado, e um arquivo de erro 1B foi carregado.
2020-06-04 20: 22: 32.879 (pool-5-thread-1) [ERROR - org.apache.flume.source.SpoolDirectorySource $ SpoolDirectoryRunnable.run (SpoolDirectorySource.java:296)] FATAL: Fonte do Spool Directory r1: {spoolDir: /opt/flume-1.9.0/directory}: Exceção não detectada no thread SpoolDirectorySource. Reinicie ou reconfigure o Flume para continuar o processamento.
java.lang.IllegalStateException: o nome do arquivo foi reutilizado com arquivos diferentes. Suposições de spool violadas para /opt/flume-1.9.0/directory/one.txt.COMPLETED


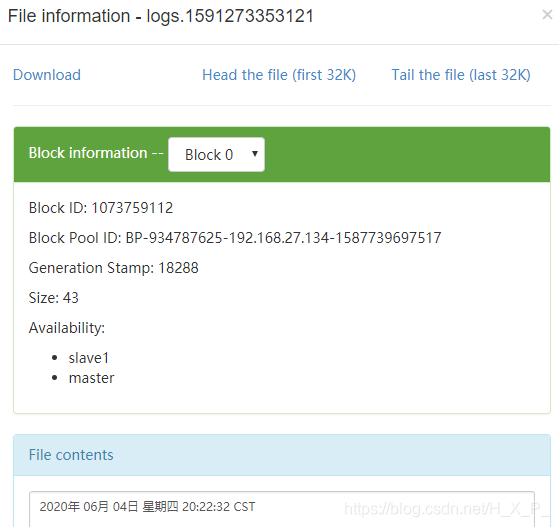

Motivo : o novo arquivo usa um nome de arquivo que já existe no diretório. Flume carregou o arquivo primeiro e depois alterou o nome. Ocorreu um erro ao alterar o nome. O erro persistiu depois disso, e o novo arquivo não pôde ser carregado.
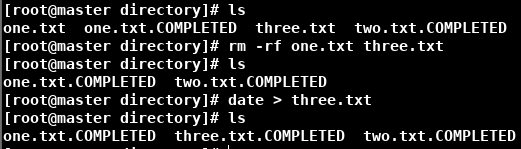
Solução : exclua o arquivo anormal, reinicie o Flume e jogue o arquivo no diretório novamente
Caso 5: monitoramento de arquivos adicionais (upload retomado)
Taildir Source pode não apenas realizar a transmissão recuperável de pontos de interrupção , mas também garantir que os dados não sejam perdidos, e também pode realizar monitoramento em tempo real.
Etapas do caso
-
Crie um novo diretório: arquivo mkdir .
-
Crie dois arquivos no diretório de arquivos: toque em um.txt , toque em dois.txt
-
Crie o arquivo de configuração do Flume Agent taildir-flume-logger.conf , o tipo de origem é taildir e o tipo de coletor é logger
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/file/.*\.txt a1.sources.r1.positionFile = /opt/flume-1.9.0/file/position.json # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
Inicie o Flume.
bin/flume-ng agent -c conf -f taildir-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console -
Inicie um novo terminal, echo A >> one.txt , echo B >> two.txt

-
Ctrl + c para fechar o Flume, digite echo C >> one.txt , echo D >> two.txt , reinicie o Flume

-
Olhando em position.json, você pode descobrir que o arquivo registra a última localização modificada do arquivo, portanto, pode ser retomado com um ponto de interrupção. (Os sistemas Unix / Linux não usam nomes de arquivo internamente, mas usam inodes para identificar arquivos)

Problema anormal
O arquivo de configuração atribui dois arquivos a f1 e, finalmente, one.txt não pode ser monitorado, mas two.txt pode.
a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/file/one.txt
a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/file/two.txt
Isso ocorre porque o segundo substitui o primeiro. Use expressões regulares ou duas variáveis f1, f2.