Análise em Python: análise da qualidade do vinho tinto (exploração de dados)
Conjunto de dados: winemag-data_first150k.csv
Primeiro importe os dados
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.formula.api import ols, glm# 将数据集读入到pandas数据框中
wine = pd.read_csv('C:\\Machine-Learning-with-Python-master\\data\\winemag-data_first150k.csv', sep=',', header=0)
wine.columns = wine.columns.str.replace(' ', '_')
print(wine.head())

Exibir informações de linha e coluna do conjunto de dados
#查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(wine.shape[0],wine.shape[1])) wine.columns
Explique os seguintes significados:
| Nome da coluna | Significado |
| país | País de onde o vinho vem |
| descrição | Descreva o sabor, cheiro, aparência, sensação, etc. do vinho |
| designação | Vinhedos dentro da vinícola, as uvas vêm da vinha |
| pontos | O Wine Enthusiast classifica os vinhos de 1 a 100 (embora eles digam que só comentam sobre vinhos com pontuação> = 80) |
| preço | O custo de uma garrafa de vinho |
| província | Origem do vinho |
| region_1 | Origem do vinho |
| region_2 | Origem do vinho |
| variedade | Tipos de uvas usadas para fazer vinho |
| adega | Vinícola produzindo vinho |
Exibir registros no conjunto de dados

Verifique o valor nulo das informações da coluna no conjunto de dados

Estatísticas descritivas de cada coluna

Siga as estatísticas descritivas dos preços
wine['province'].value_counts().head(10).plot.bar()
Pode-se ver pela figura acima que a produção da Califórnia é muito maior do que a de outras províncias do mundo.Podemos perguntar: qual a porcentagem de vinho da Califórnia responsável pelo vinho total? Esse gráfico de barras indica o valor absoluto, mas é mais útil saber a proporção relativa .

Pela foto acima, podemos ver que o vinho produzido na Califórnia é responsável por quase um terço das avaliações da revista de vinhos.
O gráfico de colunas é muito flexível: a altura pode representar qualquer coisa, desde que seja um número. Cada coluna pode representar qualquer coisa, desde que seja uma categoria.
A classificação de província intermediária no exemplo acima é um dado classificado (sem tamanho inerente ou ordem alta e baixa), e há dados classificados são dados classificados, que têm um grau de ordem em relação ao tipo de dados fixos, como os seguintes No exemplo, o número de avaliações com classificações diferentes para vinho.

Como você pode ver na figura acima, a pontuação total de cada vinho está entre 80 e 100 pontos. Existem 20 categorias de subvalor, e o histograma pode mostrar exatamente esses valores. E se a pontuação for de 0 a 100? Receio que não possamos exibir totalmente a situação de cada categoria.Neste momento, precisamos usar um gráfico de linhas.

Usar gráfico de áreas
Quando apenas uma variável é plotada, a diferença entre o gráfico de áreas e o gráfico de linhas é principalmente visualizada. Nesse caso, eles podem ser usados de forma intercambiável.

Cada amostra possui um índice de qualidade que varia de 1 a 10 e os resultados de vários testes físicos e químicos

O histograma é desenhado com uma série de retângulos de igual largura e altura desigual.A largura indica o intervalo dos dados e a altura indica a frequência ou frequência.
Ver distribuição do preço do vinho


Pela imagem acima, os preços são distribuídos principalmente de 0 a 200. Devido ao alto desvio de preço, a faixa de preço é muito grande e não há problema.
len(wine[wine['price'] > 200])/len(wine) 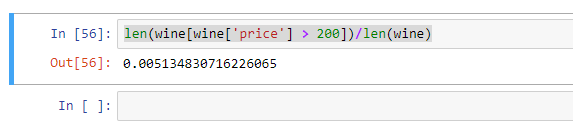
Através do cálculo, verificou-se que a proporção de preços acima de 200 é de apenas 0,005, o que pode ser ignorado.Lidar com o desvio de dados e reexaminar a distribuição da quantidade de preços quando o preço <200







Essa imagem parece muito comum, não há título no gráfico e o tamanho do rótulo no eixo x também é um pouco pequeno. Vamos modificá-lo abaixo.
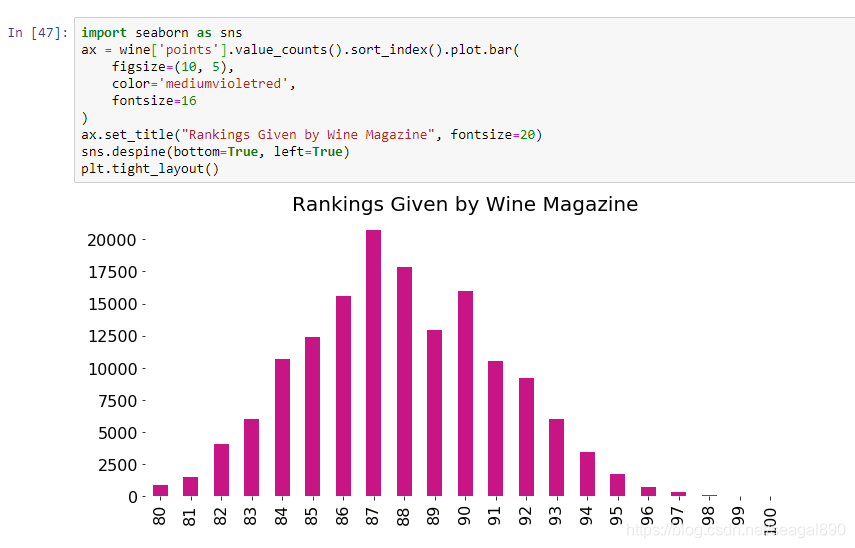
Após o ajuste, fica mais claro do que quando começamos e pode transmitir melhor os resultados da análise ao leitor.Os parâmetros são explicados um a um abaixo.
1. O tamanho do gráfico, utilizando figsize (largura, altura) de parâmetro figsize=(10, 5)
2. modificar a cor, os parâmetros de cor color='mediumvioletred'valores da ponta de ligação do papel, ver Tabela
3. Definições tamanho texto guia, utilizando o parâmetro tamanhodefonte fontsize=16
4. Conjunto o título e tamanho plot.bar(title='xxx')
, mas o tamanho do texto do título é fornecido, Os pandas não deram parâmetros de configuração. Na parte inferior, a ferramenta de visualização de dados do panda é baseada no matplotlib, que pode ser alcançado com a ajuda da função set_title do matplotlib
ax = xxx.plot.bar()
ax.set_title('title', fontsize=20)A variável ax é um objeto AxesSubplot.
5. Remova a borda preta do sns.despine(bottom=True, left=True)
gráfico.Aqui apresentamos uma nova biblioteca marítima, que será introduzida especificamente mais tarde.
6. O gráfico é exibido completamente, às vezes o rótulo do gráfico fica oculto.Verifique plt.tight_layout()apenas o rótulo do eixo, o rótulo da escala e a parte do título.
7. Os gráficos com caracteres chineses precisam ser definidos com fontes, que não são usadas neste artigo e são explicadas separadamente
import matplotlib
font = {
'family': 'SimHei'
}
matplotlib.rc('font', **font)Um gráfico de dispersão é um gráfico no qual uma variável é a abcissa e a outra variável é a ordenada, e a forma de distribuição da dispersão (pontos de coordenadas) reflete o relacionamento das variáveis.
Vamos dar uma olhada na relação entre preços e classificações de vinhos:

Vendo todos os pontos da imagem, dificilmente você pode ver a relação entre preços e classificações de vinhos. Como o gráfico de dispersão não consegue lidar efetivamente com os pontos mapeados na mesma posição, para representar melhor o relacionamento entre os dois, precisamos amostrar os dados e extrair 100 pontos para exibir novamente:

Como você pode ver na foto acima, os vinhos com preços mais altos receberão classificações mais altas quando revisados. Isso mostra que o gráfico de dispersão é mais eficaz para conjuntos de dados e variáveis relativamente pequenos com um grande número de valores exclusivos.
Para lidar com gráficos de cobertura causados por pontos de dados repetidos, além de dados de amostragem, você também pode usar o Hexplot.
O gráfico hexagonal agrega os pontos no espaço em hexágonos e depois colore esses hexágonos com base nos valores dentro do hexágono.
wine[wine['price'] < 100].plot.hexbin(x='price', y='points', gridsize=15)
No caso de preço de teste <200, verifica-se que os gráficos estão concentrados na faixa de preço de 0 a 100 (a imagem não é mostrada aqui), portanto a condição do filtro é ajustada para o preço <100.
Pela imagem acima, vendo as informações que não são informadas pelo gráfico de dispersão, podemos ver que o preço dos vinhos revisados na revista de vinhos está concentrado em cerca de 87,5 pontos, cerca de 20 dólares americanos.
Um gráfico empilhado é um tipo de gráfico que coloca as variáveis uma em cima da outra.
Recordando o gráfico de barras univariado no artigo anterior, aqui você pode simplesmente usar um parâmetro empilhado para obter a superposição de várias barras.
O texto original é para introduzir um novo conjunto de dados Aqui, realizamos o seguinte processamento nos dados de origem para obter o número de vezes que diferentes pontuações de avaliação dos cinco principais vinhos:
#top5酒厂
winery = wine['winery'].value_counts().head(5)
wine_counts = pd.DataFrame({'points': range(80, 101)})
for name in winery.index:
winery_grouped = wine[wine['winery'] == name]
points_series = winery_grouped['points'].value_counts().sort_index()
df = pd.DataFrame({'points': points_series.index, name: list(points_series)})
wine_counts = wine_counts.merge(df, on='points',how='left').fillna(0)
wine_counts.set_index('points', inplace=True)
wine_counts.plot.bar(stacked=True)
Os gráficos de barras empilhadas têm as vantagens e desvantagens dos gráficos de barras univariados. Eles são mais adequados para classificar dados ou uma pequena quantidade de dados de seqüenciamento.
Outro exemplo simples é o gráfico de áreas empilhadas.
wine_counts.plot.area()
Como o gráfico de área univariada, a área multivariável é adequada para exibir dados fixos ou dados de intervalo.
O gráfico empilhado é visualmente muito bonito. Mas eles têm duas limitações principais.
Primeira limitação: A segunda variável do gráfico empilhado deve ser uma variável com um número muito limitado de valores possíveis. 8 às vezes é referido como o limite superior recomendado. Existem muitos campos do conjunto de dados que não atendem a esse critério e requerem processamento adicional de dados.
A segunda limitação: baixa legibilidade e dificuldade em distinguir valores específicos. Por exemplo, olhando a foto acima, você pode me dizer qual vinho tem uma pontuação mais alta quando a pontuação é 87,5: Testarossa (laranja), williams (azul) ou DFJ (verde)? Isso é realmente difícil Fala!
Gráfico de linhas bivariadas
wine_counts.plot.line()
Este método usa gráficos de linhas para compensar a legibilidade dos gráficos empilhados. Neste gráfico, podemos facilmente responder à pergunta no exemplo anterior: quando a pontuação é 87,5, qual vinho tem uma pontuação mais alta? Podemos ver que o Columbia Crest é o mais alto.
