Análise Exploratória de Dados (EDA)
A Análise Exploratória de Dados (EDA) refere-se a um método de análise de dados que explora a estrutura e as leis dos dados, desenhando, tabulando, ajustando equações, calculando valores de recursos etc. nos dados existentes, com o menor número possível de suposições anteriores. O método foi proposto pelo estatístico americano JK Tukey na década de 1970.
Os métodos tradicionais de análise estatística geralmente assumem que os dados estão em conformidade com um modelo estatístico e depois estimam alguns parâmetros e estatísticas do modelo com base nas amostras de dados para entender as características dos dados, mas, na prática, muitas vezes existem muitos dados que não atendem ao modelo estatístico assumido. Distribuição, o que leva a resultados de análise de dados insatisfatórios. O EDA é um método de análise mais alinhado com a situação real, com ênfase em permitir que os dados "falem". Com o EDA, podemos observar a estrutura e as características dos dados de maneira mais verdadeira e direta.
Após o surgimento da EDA, o processo de análise de dados é dividido em duas etapas: a fase de exploração e a fase de verificação . A fase de exploração se concentra em descobrir os padrões ou modelos contidos nos dados e a fase de verificação na avaliação dos padrões ou modelos descobertos Muitos algoritmos de aprendizado de máquina (divididos em etapas de treinamento e teste) seguem essa idéia.
No trabalho de análise de dados, usando estatísticas, é possível observar como os dados são organizados com precisão de maneira mais profunda e detalhada e determinar o método de análise de dados com base nessa estrutura organizacional para obter mais informações.
Base estatística de análise de dados

Estatísticas de recursos
Técnicas estatísticas frequentemente usadas no estudo de conjuntos de dados, incluindo desvio, variância, média aritmética, mediana, modo, faixa, porcentagem etc.
As estatísticas frequentemente usadas na medição de tendência centralizada são: média, mediana, modo etc.
As estatísticas frequentemente usadas na medição de tendência descentralizada são: faixa, desvio padrão, coeficiente de variação, faixa interquartil, etc.
É muito fácil entender as estatísticas dos recursos e implementar no código. Por favor, veja o diagrama da caixa abaixo:

Uma caixa no gráfico da caixa contém cinco valores: borda superior (observação máxima ou valor máximo da amostra), quartil superior (Q3), mediana (Q2), quartil inferior (Q1) e Borda (observação mínima ou amostra mínima). Além disso, fora da caixa também é possível usar pontos circulares para indicar valores discrepantes.O seguinte é um diagrama esquemático dos componentes do diagrama da caixa:
Na figura acima, a linha preta grossa no meio indica a mediana (Q2) dos dados. A mediana é usada para a média porque é mais robusta para os valores extremos. O quartil inferior é essencialmente 25%, ou seja, 25% dos dados são inferiores a esse valor. O quartil superior é de 75%, ou seja, 75% dos dados são inferiores a esse valor. As bordas superior e inferior representam as extremidades superior e inferior do intervalo de dados.
Exemplo: Um caso da análise da qualidade do vinho tinto

Vamos dar uma olhada nos resultados numéricos correspondentes na figura acima:
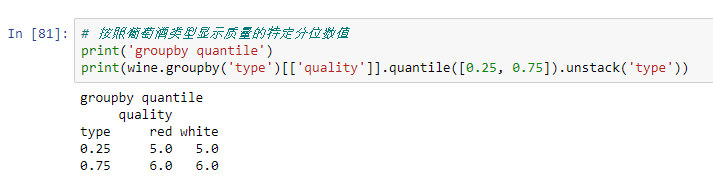
Os gráficos de caixa ilustram bem o papel dos recursos estatísticos básicos:
- Quando o gráfico da caixa é muito curto, significa que muitos pontos de dados são semelhantes, porque muitos valores são distribuídos em um pequeno intervalo;
- Quando o gráfico da caixa é alto, significa que a maioria dos pontos de dados difere bastante, porque esses valores são amplamente distribuídos;
- Se a mediana estiver próxima ao fundo, a maioria dos dados terá valores mais baixos. Se a mediana estiver mais próxima do topo, a maioria dos dados terá valores mais altos. Basicamente, se a linha mediana não estiver no meio da caixa, isso indica dados distorcidos;
- Se as linhas nos lados superior e inferior da caixa forem longas, os dados apresentarão um alto desvio e variação padrão, o que significa que esses valores estão dispersos e variam muito. Se houver uma linha longa em um lado da caixa e não uma longa no outro lado, os dados poderão mudar bastante em uma direção.
Distribuição de probabilidade
Probabilidade pode ser definida como a probabilidade de ocorrência de alguns eventos, expressa em porcentagem. No campo da ciência de dados, isso geralmente é quantificado no intervalo de 0 a 1, onde 0 significa que a determinação de eventos não ocorrerá e 1 significa que a determinação de eventos ocorrerá. Então, a distribuição de probabilidade é uma função que representa a probabilidade de ocorrência de todos os valores possíveis.
Por favor, veja a imagem abaixo:
Distribuições de probabilidade comuns, distribuição uniforme (em cima), distribuição normal (em meio), distribuição de Poisson (em baixo):
A distribuição uniforme é a distribuição de probabilidade mais básica. Ele tem um valor que aparece apenas dentro de um determinado intervalo e tudo o que está fora desse intervalo é 0. Também podemos pensar nisso como uma variável com duas categorias: 0 ou outro valor. As variáveis categóricas podem ter vários valores diferentes de 0, mas ainda podemos visualizá-las como múltiplas funções uniformemente distribuídas.
A distribuição normal, geralmente também chamada de distribuição gaussiana, é definida por sua média e desvio padrão. O valor médio é distribuído em posições espacialmente variáveis, e o desvio padrão controla seu spread. A principal diferença em relação a outros métodos de distribuição é que o desvio padrão é o mesmo em todas as direções. Portanto, através da distribuição gaussiana, sabemos o valor médio do conjunto de dados e a distribuição de difusão dos dados, ou seja, ela se estende por uma faixa relativamente ampla ou concentra-se principalmente em torno de alguns valores.
A distribuição de Poisson é semelhante à distribuição normal, mas há uma taxa de inclinação. Como a distribuição normal, a distribuição de Poisson tem difusão relativamente uniforme em todas as direções quando o valor da assimetria é baixo. No entanto, quando o valor da assimetria é muito grande, a dispersão dos nossos dados em diferentes direções será diferente. Em uma direção, o grau de difusão de dados é muito alto, enquanto na outra direção, o grau de difusão é muito baixo.
Se você encontrar uma distribuição gaussiana, sabemos que existem muitos algoritmos.Por padrão, a distribuição gaussiana será executada muito bem, portanto esses algoritmos devem ser encontrados primeiro. Se for uma distribuição de Poisson, devemos ter um cuidado especial ao escolher um algoritmo que seja muito robusto às mudanças na expansão espacial.
Redução de dimensionalidade
O termo redução de dimensionalidade pode ser entendido intuitivamente, o que significa reduzir a dimensão de um conjunto de dados. Na ciência de dados, esse é o número de variáveis características. Por favor, veja a imagem abaixo:
O cubo na figura acima representa nosso conjunto de dados, que possui 3 dimensões e um total de 1000 pontos. Com o poder de computação atual, é fácil calcular 1000 pontos, mas se você tiver uma escala maior, terá problemas. No entanto, observando nossos dados apenas de uma perspectiva bidimensional, como na lateral do cubo, pode-se observar que é fácil dividir todas as cores.
Através da redução de dimensão, exibimos dados 3D no plano 2D, o que reduz efetivamente o número de pontos que precisamos calcular para 100, o que economiza bastante a quantidade de cálculo.
Outra maneira é reduzir a dimensionalidade através da poda de recursos. Usando esse método, excluímos quaisquer recursos que vemos que não são importantes para a análise.
Por exemplo, depois de estudar o conjunto de dados, podemos descobrir que 7 dos 10 recursos têm uma alta correlação com a saída, enquanto os outros 3 têm uma correlação muito baixa. Bem, esses três recursos de baixa correlação podem não valer a pena ser calculados: podemos apenas removê-los da análise sem afetar o resultado.
A técnica estatística mais comum usada para a redução da dimensionalidade é a PCA, que cria essencialmente uma representação vetorial de recursos, indicando sua importância para o resultado, ou seja, correlação. O PCA pode ser usado para executar os métodos de redução de duas dimensionalidades acima.
Sobrefitting e underfitting
Sobreajuste e sub-adequação são técnicas usadas para problemas de classificação. Por exemplo, temos 2000 amostras em uma categoria, mas apenas 200 amostras na segunda categoria. Isso deixará de lado muitas técnicas de aprendizado de máquina que tentamos e usamos para modelar os dados e fazer previsões. Em seguida, o sobreajuste e a falta de adequação podem lidar com essa situação.
Por favor, veja a imagem abaixo:
Nos lados esquerdo e direito da figura acima, a classificação azul tem mais amostras do que a laranja. Nesse caso, temos duas opções de pré-processamento que podem ajudar o modelo de aprendizado de máquina a ser treinado.
Underfitting significa que apenas selecionaremos alguns dados da classificação de muitas amostras e usaremos o máximo possível de amostras de classificação. Essa escolha deve ser manter a distribuição de probabilidade da classificação. Apenas usamos menos amostragem para tornar o conjunto de dados mais equilibrado.
Sobreajuste significa que vamos criar uma cópia da classificação minoritária para ter o mesmo tamanho de amostra que a classificação majoritária. Serão feitas cópias para manter a distribuição de algumas categorias. Apenas tornamos o conjunto de dados mais equilibrado sem obter mais dados.
Estatísticas bayesianas
Para entender completamente por que, quando usamos as estatísticas bayesianas, precisamos primeiro entender onde as estatísticas de frequência falham. Quando a maioria das pessoas ouve a palavra "probabilidade", a estatística de frequência é o primeiro tipo de estatística que vem à mente. Isso envolve a aplicação de alguma teoria matemática para analisar a probabilidade de um evento.Para deixar claro, os únicos dados que calculamos são dados anteriores.

Suponha que eu lhe dei um dado e perguntei qual a chance de rolar 6 pontos, a maioria das pessoas diria que é um sexto.
Mas e se alguém lhe der um dado específico que sempre pode rolar 6 pontos? Porque a análise de frequência considera apenas os dados anteriores e os fatores dos dados trapaceiros não são levados em consideração.
As estatísticas bayesianas levam isso em consideração.Podemos usar a regra de Bayes para ilustrar:
A probabilidade P (H) na equação é basicamente nossa análise de frequência, dados os dados anteriores sobre a probabilidade do evento. P (E | H) na equação é chamado de possibilidade.De acordo com as informações obtidas pela análise de frequência, é essencialmente a probabilidade de o fenômeno estar correto.
Por exemplo, se você quiser rolar os dados 10.000 vezes e todos os primeiros 1000 lançamentos fizeram 6 pontos, você estará muito confiante de que os dados trapacearam. Se a análise de frequência for muito boa, teremos muita certeza de determinar se 6 pontos estão corretos. Ao mesmo tempo, se a trapaça de dados for verdadeira, ou não com base em sua própria análise prévia de probabilidade e frequência, também consideraremos os fatores da trapaça.
Como você pode ver na equação, as estatísticas bayesianas levam em consideração todos os fatores. Quando achar que os dados anteriores não representam bem os dados e resultados futuros, use métodos estatísticos bayesianos.
