Endereço da tese: https://www.aclweb.org/anthology/P19-1482/
Autor: Chen Wu, Xuancheng Ren, Fuli Luo, Xu Sun
Organização: Universidade de Tsinghua, Universidade de Pequim
Questões de pesquisa:
O foco está na transferência de estilo do texto. O método mainstream atual ainda usa um método de ponta a ponta semelhante à tradução, mas o próprio sistema de ponta a ponta tem alguns problemas, como não ser interpretável, e é difícil encontrar um equilíbrio entre estilo e conteúdo. Este artigo propõe um método baseado em sequência baseado no aprendizado por reforço, que inclui duas partes, uma é um agente de alto nível que propõe uma posição de operação e a outra é um agente de baixo nível que propõe modificar uma sentença de acordo com um agente de alto nível.
A transferência de estilo de texto concentra-se principalmente na fluência, polaridade do estilo e preservação do conteúdo. Para fluência, use a função de recompensa do modelo de linguagem; para polaridade de estilo, introduza recompensas de confiança de classificação e tarefas auxiliares de classificação; para preservação de conteúdo, use o método de reconstrução.
O método de reconstrução vem do CycleGAN, considerando o tipo de texto discreto, aqui usamos a operação da sequência para simular.
Métodos de pesquisa:
Estrutura de opções:
A abordagem geral deste artigo é baseada na estrutura de opções do HRL (Hierarchical Reinforced Learning). Primeiro, introduza o quadro de opções, um quadro de seleção consiste em dois níveis:
A camada inferior é uma política secundária (observação ambiental, ação de saída, continuada até o término)
O nível superior é a política acima das opções (observações ambientais, sub-política de saída, continuada até o término)
Uma opção feita pela camada superior inclui duas partes, uma é a estratégia de ação e a outra é a função de terminação. Quando a função de finalização retornar 0, a próxima etapa será controlada pela opção atual; quando a função de finalização retornar 1, a tarefa da opção será temporariamente concluída e o controle retornado à estratégia de nível superior.
Agente avançado: ponteiro
O objetivo do agente de alto nível é propor a localização da operação, que é alcançada aqui por meio de uma rede de ponteiros. As definições relevantes são as seguintes:
Opção: Dada uma frase x = {x_1, ..., x_t}, o espaço de escolha é O = {1, ..., t}. Se o comprimento da sentença mudar, o intervalo de t também mudará.
Estado: Representação de sentença obtida pelo codificador Bi-LSTM.
Política: Um processo softmax, como mostrado abaixo.
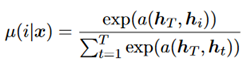
Agente de baixo nível: operação
A operação é predefinida e inclui os 7 tipos a seguir.

Ação: Dada uma sentença e uma posição de operação, o agente de baixo nível seleciona uma operação da tabela e gera uma palavra, se for necessária.
Estado: O mesmo é o código de sentença obtido através do Bi-LSTM.
Condição de término: no quadro de opções original, a condição de término é aprendida, mas aqui a condição de término é fixa, o objetivo é tornar o treinamento mais estável.
Estratégia de seleção de operação: na fase de treinamento, escolha uma operação unificada, como substituição. Também para tornar o treinamento mais estável, a estratégia na fase de inferência é apresentada abaixo.
Estratégia de geração de palavras: gere palavras pela seguinte fórmula.

Aqui h também é estado.
Método de treinamento:
O primeiro é uma ilustração do método de treinamento.
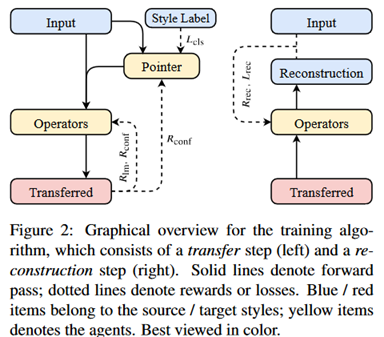
Como mencionado acima, o objetivo do treinamento é principalmente simular os três aspectos de fluência, polaridade de estilo e retenção de conteúdo, que são apresentados separadamente abaixo.
Fluência: use recompensas do modelo de linguagem. Como mostrado abaixo.
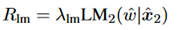
Este artigo calcula a probabilidade calculando a média do LSTM para frente e para trás.
Polaridade do estilo:
Confiança na classificação: use a função de confiança na classificação da seguinte maneira:

Ao mesmo tempo, uma tarefa auxiliar é definida. No HRL, agentes avançados geralmente enfrentam o problema de grande variação de gradiente. Para estabilizar o treinamento, uma tarefa auxiliar é definida aqui, que é estender o agente avançado a um classificador baseado em atenção, como mostrado abaixo.
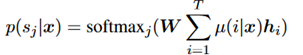
Retenção de conteúdo:
Perda de reconstrução:
Considere uma operação M, opere na i-ésima posição, de acordo com a operação definida, encontre a possível operação M 'e a possível posição i', as regras específicas são mostradas na tabela a seguir.

Em seguida, use (M ', i') para definir a perda de reconstrução da seguinte maneira:
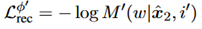
Recompensa por refatoração: a definição é dada da seguinte forma:
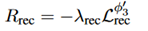
Seu objetivo é principalmente incentivar o mapeamento individual, ou seja, impedir que muitas palavras sejam mapeadas para palavras boas e ruins.
Processo de treinamento:
Em agentes avançados, apenas as recompensas das tarefas de classificação introduzidas são usadas em vez das recompensas do modelo de linguagem. O autor explicou que a recompensa do modelo de idioma é mais local e aumentará bastante a variação da recompensa.
Em agentes de baixo nível, todas as recompensas externas e internas são usadas. Essa é a função de recompensa das três partes acima mencionadas.
Estágio de inferência:
Opção de sobreposição: na inferência, você encontrará o problema de que a operação anterior afeta a operação da próxima etapa.Aqui o autor a implementa através da opção de máscara (a opção aqui também é a posição), especificamente insira, exclua, pule o texto Usado durante a operação.
Condição de término: se o operador for determinado como o tipo de destino, ele será encerrado. Mas essas peças altamente estilizadas podem levar à rescisão prematura. Portanto, o autor aqui mascara as palavras no quadro de operações.
Estratégia de seleção do operador: enumere todos os operadores, pontue por modelo de idioma e selecione aquele com a pontuação mais alta.
Parte experimental:
Existem dois conjuntos de dados, ou seja, Yelp e Amazon
Existem três indicadores de avaliação, um é o classificador de amostra (usando TextCNN), BLEU e pontuação humana
Os resultados experimentais são os seguintes:

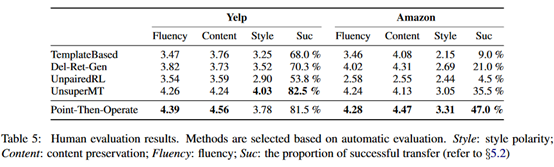
Pode-se observar que a melhoria no BLEU é mais óbvia, mas a precisão da classificação não é muito alta.
Avaliação:
A transferência de estilo no campo de texto ainda não está em uso, em parte devido à falta de dados.O treinamento de ponta a ponta requer uma grande quantidade de texto alinhado, e o efeito da tradução ainda é muito pior. Se a analogia dos seres humanos para executar esta tarefa, primeiro entender o texto e depois reescrever a frase, ainda não é possível para a tecnologia atual.
A partir dos resultados experimentais, os resultados experimentais neste artigo não são muito bons. A precisão da classificação não é tão boa quanto em alguns sistemas anteriores, embora haja uma melhoria relativamente óbvia no BLEU. Mas o problema aqui é que a maior parte do trabalho anterior nessa tarefa é mais sobre o sucesso da transferência de estilos, ou seja, a precisão da classificação, BLEU não é um indicador muito importante. Embora os resultados de seus modelos sejam melhores na avaliação humana, a avaliação humana é mais subjetiva.
Para transferência de estilos, o método mainstream atual é RL + deep learning. Este artigo foi desenvolvido com base na estrutura de opções do HRL e, em seguida, apresenta algumas medidas de melhoria para alguns problemas encontrados no processo de treinamento, e há poucas inovações teóricas.