Os usuários deste artigo registram a experiência de aprendizado do Huangpu College e adicionam algum conteúdo.
Curso 2: Dez linhas de código para concluir com eficiência o POC de aprendizado profundo.O orador principal é o Departamento de Plataforma Tecnológica de Aprendizagem Profunda do Baidu: Professor Chen Zeyu.
Como estou na direção do CV, o conteúdo será ajustado na direção do CV e exibido.
O curso possui principalmente os três aspectos a seguir:
- O processo básico do POC de aprendizagem profunda
- Verificação rápida de ferramentas práticas de aplicação de modelos de pré-treinamento
- Detecção de uma chave de modelos universais
- Dez linhas de código para completar a classificação de texto industrial
- Ajuste automático do AutoDL Finetuner
1. O processo básico do POC de aprendizagem profunda
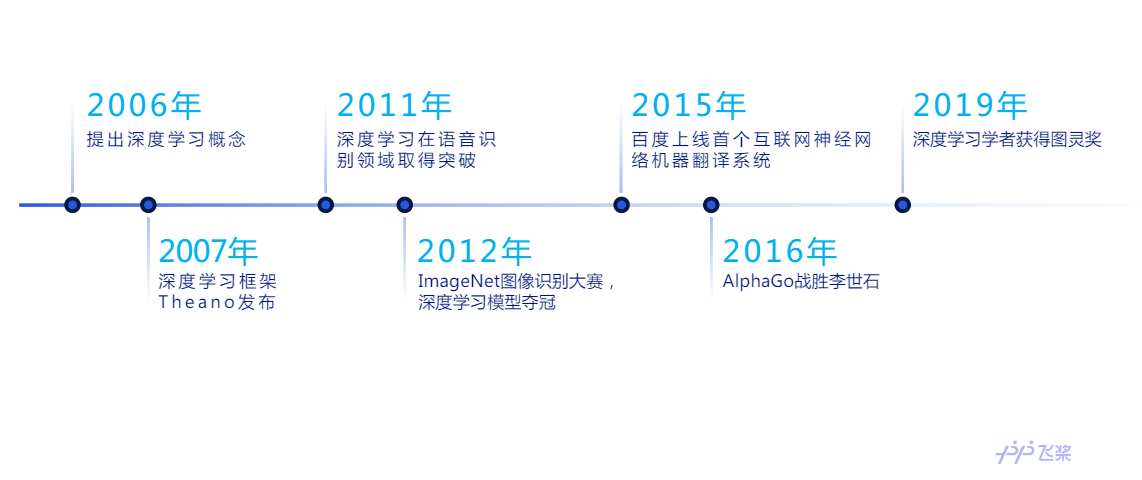
1.1 História de desenvolvimento da aprendizagem profunda
Em 2006, um artigo publicado pelo professor Geoffrey Hinton, da Universidade de Toronto, este ano, fez dois pontos importantes: (1) modelos de redes neurais multicamadas têm fortes recursos de aprendizado de recursos, e os dados que os modelos de aprendizado profundo podem aprender são mais essenciais As características de (2) Para que a rede neural profunda obtenha a solução ideal global, você pode usar o método de treinamento camada a camada para resolver. Desde então, o aprendizado profundo se desenvolveu rapidamente. Em 2007, o framework de aprendizado profundo Theano foi lançado para otimizar o cálculo de matrizes multidimensionais. Em 2011, o aprendizado profundo fez um avanço no campo do reconhecimento de fala. Em 2012, Krizhevsky e colaboradores aplicaram a rede neural convolucional ao concurso de reconhecimento de imagens ImageNet pela primeira vez e conquistaram uma grande vitória. Posteriormente, a aprendizagem profunda foi desenvolvida em vários campos, como processamento de linguagem natural e reconhecimento de imagem. Em 2016, o AlphaGo, com base no aprendizado por reforço profundo, derrotou Li Shishi, brilhando brilhantemente, e a tecnologia de inteligência artificial representada pelo aprendizado profundo foi amplamente discutida entre o público em geral. Em 2019, três pais de aprendizado profundo: Geoffrey Hinton, Yann LeCun e Yoshua Bengio ganharam juntos o Prêmio Turing.
1.2 Sucesso e limitações da aprendizagem profunda
A Bíblia no mundo do aprendizado profundo, o livro de flores "Deep Learning" também mencionou que o sucesso do aprendizado profundo tem os dois motivos a seguir:
(1) A crescente quantidade de dados: "São necessárias algumas habilidades para obter um bom desempenho de um algoritmo de aprendizado profundo. Felizmente, à medida que os dados de treinamento aumentam, as habilidades necessárias estão diminuindo . " Com o rápido aumento na quantidade de dados, os algoritmos de aprendizado profundo direcionados pelo big data atingiram ou até superaram os níveis humanos em algumas tarefas complexas.
(2) Aumento da escala do modelo sob o grande poder da computação: mais e mais recursos computacionais podem permitir a execução de modelos maiores.O professor Hinton e muitos estudiosos do conexionismo mencionaram que o modelo é maior e a capacidade de aprendizado de recursos é mais forte ( Obviamente, não é que quanto maior o modelo, melhor).
Por esse motivo, o efeito do aprendizado profundo é limitado em amostras pequenas e com baixo poder de computação, e o limiar de design de modelos grandes é relativamente alto.
1.3 A direção de exploração da tecnologia de aprendizado profundo
Aprendizagem multitarefa: como transferência de aprendizado com base em modelos pré-treinados. De fato, em muitas ocasiões (especialmente em cenários industriais e médicos), o número de dados, especialmente amostras negativas, é muito pequeno, e a tecnologia de aprendizado de transferência baseada em modelos pré-treinados pode desempenhar um papel mais crítico. Quando li os documentos relacionados à "Inteligência Artificial de Nova Geração", emitidos pelo Ministério da Ciência e Tecnologia, muitos projetos mencionaram habilidades de pesquisa que transferem tecnologia, o que mostra a importância.
Aprendizado auto-supervisionado: O aprendizado auto-supervisionado é um tipo de aprendizado não supervisionado, mas também para resolver pequenos problemas de amostra. As amostras de treinamento necessárias para o aprendizado profundo exigem rotulagem manual, mas o custo da rotulagem é muito grande. A "anotação" do aprendizado auto-supervisionado geralmente vem dos próprios dados, como deduzir alguns quadros no vídeo, cobrir uma determinada parte da imagem e deixar o modelo confiar nas informações ao seu redor para prever as partes ausentes, aprendendo as características dos dados.
1.4 O processo básico do POC de aprendizagem profunda
O POC, ou seja, Prova de Conceito, o papel do POC é testar a verificação do programa na fase inicial do projeto.
O POC de aprendizado profundo é usado para determinar se o projeto pode ser concluído usando a tecnologia de aprendizado profundo.O processo básico é mostrado na figura a seguir:

(1) Requisitos definidos: Primeiro, é necessário esclarecer os requisitos da tarefa e, em seguida, determinar se os indicadores técnicos do cliente podem estar relacionados ao efeito do modelo de aprendizado profundo.
(2) Otimização de dados: Usando a tecnologia de aprendizado profundo para criar um projeto, uma grande proporção de experiência deve ser colocada na coleta, anotação e limpeza de dados. A qualidade do conjunto de dados está diretamente relacionada ao limite superior da tarefa.
(3) Seleção de modelo: determine se a cena da tarefa do cliente pode ser resolvida com modelos pré-treinados prontos, como detecção humana, classificação geral, etc. Encontrar um modelo pré-treinado adequado pode resolver metade do problema; combinando ambiente e desempenho de implantação Exigir seleção de modelos, como requisitos de batida, requisitos de precisão, questões de custo, etc.; determinar se é necessário combinar tecnologias visuais tradicionais, como segmentação de imagem, detecção de borda, etc.; se vários modelos precisam ser combinados, como classificação + segmentação, etc. .
(4) Treinamento de assistente: o treinamento de assistente envolve aprimoramento de dados, assistente de rede e assistente de parâmetro de treinamento, etc. Agora, existem algumas estratégias automatizadas de otimização de hiperparâmetros.
(5) Implantação do modelo: Ao implantar, você precisa considerar a potência e o custo dos equipamentos de computação de borda e geralmente precisa compactar o modelo (consulte a primeira lição para obter detalhes). É necessário considerar se é implantação do lado do servidor, terminal móvel, equipamento incorporado, implantação de chip ASIC, implantação orientada a serviços, etc.
1.5 Modelo básico no campo de visão
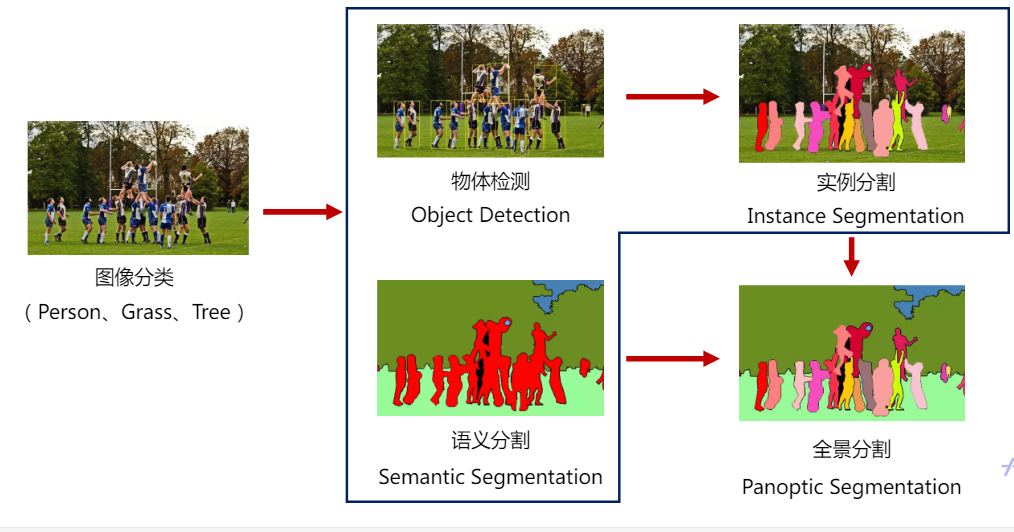
Existem muitos modelos típicos no campo de visão, que podem ser divididos em tarefas de classificação de imagens, detecção de alvos e segmentação de acordo com diferentes tarefas. A tarefa de classificação é mais fácil de entender, que é explicar o problema de "Sim" ou "Não". A tarefa de detecção de destino precisa resolver o problema "o que é onde", não apenas para determinar o que é, mas também para localizar sua localização. As três tarefas de segmentação são resolver o tipo de cada pixel, de acordo com as diferentes necessidades de segmentação semântica, segmentação de instância e segmentação panorâmica.
Geralmente, quando é necessária uma detecção refinada, é necessária uma segmentação semântica ou segmentação de instância. Só precisa saber "o que é onde", você pode usar a detecção de alvo.
1.4 Seleção do modelo visual de pré-treinamento
Agora, seja CV ou PNL, entrou gradualmente na era do pré-treinamento.
A figura a seguir mostra a precisão de vários modelos. A complexidade do cálculo Top-1 VS, o tamanho do círculo indica a sobrecarga da memória.
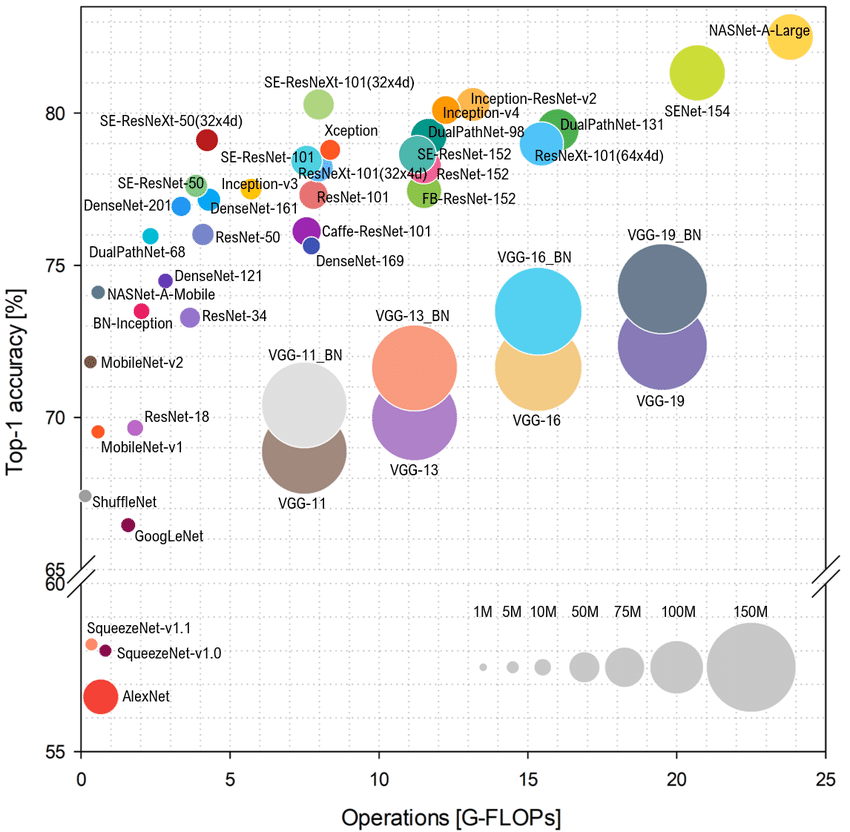
Em termos de tarefas de classificação, geralmente prestamos mais atenção a esses modelos no lado esquerdo da figura a seguir: a precisão é relativamente alta, o modelo é relativamente pequeno e a sobrecarga do poder de computação não é grande, o que pode alcançar um bom desempenho em implantações com poder de computação limitado. Ao executar tarefas de inspeção, você deve prestar atenção ao estágio único ou dois estágios. No entanto, em tarefas reais, é dada mais atenção à multi-escala. Como existem muitos pequenos alvos detectados, o desempenho em várias escalas será maior. O mainstream da tarefa de segmentação é a estrutura Encoder-Decoder, e a estrutura de backbone de baixo nível precisa de atenção.
No geral, precisamos prestar atenção a três aspectos:
(1) Consideração abrangente da precisão, desempenho de previsão e sobrecarga de memória
(2) No futuro, há uma tendência para projetar modelos com base nas características do hardware
(3) tecnologia AutoML
2. Verificação rápida de ferramentas práticas de aplicação de modelos de pré-treinamento
2.1 Detecção de uma chave do modelo geral
O PaddleHub é uma ferramenta de aprendizado de gerenciamento e transferência de modelos de pré-treinamento para remos voadores, que inclui um modelo de pré-treinamento para vários cenários e várias tarefas. Ao adotar o modelo de pré-treinamento de alta qualidade + Ajuste fino, você pode concluir rapidamente o processo, desde o aprendizado da migração até a implantação.
O link é: https://github.com/PaddlePaddle/PaddleHub/
Um modelo pré-treinado de alta qualidade requer uma combinação de quatro fatores: algoritmo + poder de computação + dados + conhecimento especializado para ser concluído. A arquitetura do PaddleHub é mostrada na figura abaixo: O modelo de pré-treinamento é muito rico, cobrindo uma variedade de tarefas, como classificação e detecção de imagens.

Uma característica do PaddleHub é que todos os modelos são gerenciados como pacotes Python, o que é muito conveniente e fácil de usar.
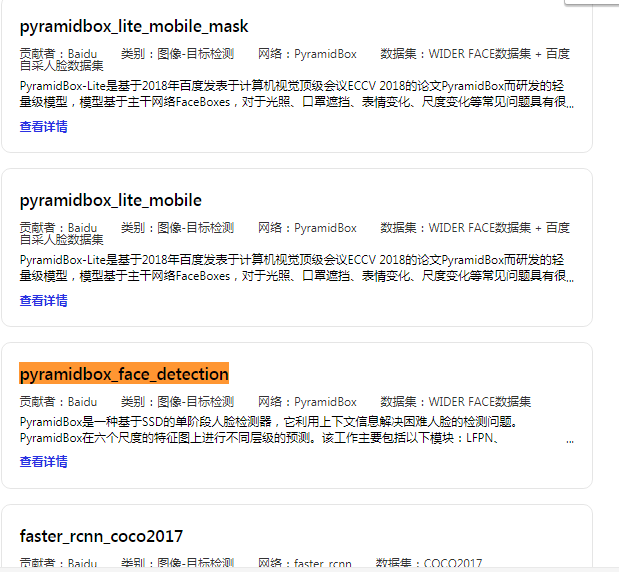
Como mostra a figura abaixo, existem muitos modelos pré-treinados no PaddleHub. Para reconhecimento de rosto mencionado na lição anterior, você pode chamar pyramidbox_face_detection no PaddleHub:
Apenas algumas linhas de código são necessárias para obter o reconhecimento facial:
importar paddlehub como
módulo do hub = hub.Module (nome = "pyramidbox_face_detection")
input_dict = {"image": ["PATH / TO / IMAGE"]}
resultados = module.face_detection (data = input_dict)
Existem muitos exemplos semelhantes, cobrindo vários conteúdos em vários campos, como imagens, textos, vídeos, etc. A cobertura é muito abrangente, portanto não os listarei um por um.
2.1 Dez linhas de código para completar a classificação do texto industrial
O curso apresenta como usar o PaddleHub e a API de ajuste fino para concluir uma classificação de texto industrial com uma pequena quantidade de código.
O modelo de pré-treinamento mais o método de ajuste fino geralmente requerem uma pequena quantidade de dados do usuário e um modelo de pré-treinamento em super-escala.O modelo de pré-treinamento em grande escala usado aqui é o ERNIE .
O código e as observações são as seguintes:
importar paddlehub como hub # Carregar o conjunto de dados da análise de sentimentos em chinês ChnSentiCorp conjunto de dados = hub.dataset.ChnSentiCorp ()
# Faça o download e carregue o modelo ERNIE, que pode ser pesquisado no site oficial do PaddleHub ernie = hub.Module (nome = "ernie")
# trainable = True Os parâmetros que representam o modelo pré-treinado podem ser treinados como entradas, saídas, programa = ernie.context (trainable = True)
# pré-processamento de dados, defina o comprimento máximo da sequência reader = hub.reader.ClassifyReader (
conjunto de dados = conjunto de dados, max_seq_len = 128, vocab_path = ernie.get_vocab_path ())
# Configurar tensor feed_list = [entradas ["input_ids"]. nome, entradas ["position_ids"]. nome, entradas ["segment_ids"]. nome, entradas ["input_mask"]. name]
# configuration Estratégia de otimização, Adam otimizador, estratégia de redução da taxa de aprendizado = hub.AdamWeightDecayStrategy (learning_rate = 5e-5)
# configure parâmetros de treinamento config = hub.RunConfig (num_epoch = 3, estratégia = estratégia) # Criar tarefa de tarefa de aprendizado de migração = hub.TextClassifierTask ( data_reader = reader, feature = outputs ["pooled_output"]], feed_list = feed_list, num_classes = dataset.num_labels, config = config ) # Inicie o ajuste fino, avalie, salve e visualize automaticamente task.finetune_and_eval ()
Se você estiver interessado em transferir aprendizado para tarefas como detecção de alvo e detecção de rosto, o Baidu também oferece tutoriais gratuitos para aprender:
https://aistudio.baidu.com/aistudio/course/introduce/1070
Três, ajuste automático do AutoML Finetuner
3.1 Estratégia de ajuste do modelo
Em seu curso de aprendizado profundo, o professor Wu Enda, da Universidade de Stanford, dividiu as estratégias de ajuste do modelo em duas categorias de uma maneira muito visual: estratégia de panda e estratégia de caviar. (Porque uma criança tem poucas, mas é mantida com cuidado, embora não se pergunte, mas é melhor nascer ...)
A chamada estratégia de panda conta com especialistas que estão muito familiarizados com o modelo e ajustam cuidadosamente um modelo mais importante para que possa ser otimizado um pouco todos os dias. A estratégia do caviar é treinar vários conjuntos de modelos em paralelo, configurar aleatoriamente vários conjuntos de hiperparâmetros, deixar o modelo rodar sozinho e, em seguida, identificar qual conjunto de hiperparâmetros tem o melhor efeito.

O ajuste do modelo é um problema de otimização da caixa preta Durante o processo de ajuste, apenas a entrada e a saída do modelo são vistas, mas as informações de gradiente no processo de ajuste não são visíveis. Portanto, a chave para a otimização é como encontrar um conjunto de hiperparâmetros o menor número de vezes possível para otimizar o efeito do modelo, o que envolve o problema da pesquisa de superparâmetros.
3.2 Pesquisa por hiperparâmetro
Existem duas estratégias para a pesquisa de hiperparâmetros: pesquisa em grade (pesquisa em grade) e pesquisa aleatória (pesquisa aleatória).
Como significado da superfície, a pesquisa em grade refere-se à distribuição uniforme de hiperparâmetros por uma certa regra de combinação: a pesquisa aleatória consiste em polvilhar diretamente grupos de parâmetros aleatoriamente no espaço de configuração de parâmetros para ver qual grupo é melhor.

Na indústria, a pesquisa aleatória geralmente obtém melhores resultados. Isso ocorre porque alguns dos hiperparâmetros dos modelos de aprendizado profundo são muito importantes (como a taxa de aprendizado) e alguns não são tão importantes. Portanto, não é necessário conceder as mesmas oportunidades de pesquisa para hiperparâmetros importantes e hiperparâmetros sem importância. Por exemplo, no lado esquerdo da imagem acima: importante e sem importância oferecem três oportunidades de pesquisa. A pesquisa aleatória pode tornar os hiperparâmetros importantes e as oportunidades de pesquisa mais intensivas e obter melhores resultados.
Além desses dois algoritmos automatizados de ajuste de parâmetros, existem algoritmos genéticos, otimização de enxame de partículas, otimização bayesiana e assim por diante. No entanto, os dois primeiros algoritmos de otimização exigem mais pontos de amostra iniciais e a eficiência da otimização é média. O relativamente mais usado na indústria é a otimização bayesiana.
A comparação de diferentes estratégias de otimização de caixa preta é mostrada na tabela a seguir:
| Estratégia Panda | Pesquisa em grade | Pesquisa aleatória | Otimização bayesiana | |
| Vantagem | Pode obter melhores configurações de super parâmetros | Implementação simples e pesquisa paralela | Espaço de pesquisa amigável, pesquisa paralela | Alta eficiência de pesquisa e robustez forte |
| Desvantagens | Demorado, trabalhoso e dispendioso | Desastre de alta dimensão do espaço de pesquisa | A pesquisa de hiperparâmetros é independente uma da outra | Necessidade de otimização sequencial e baixo paralelismo |
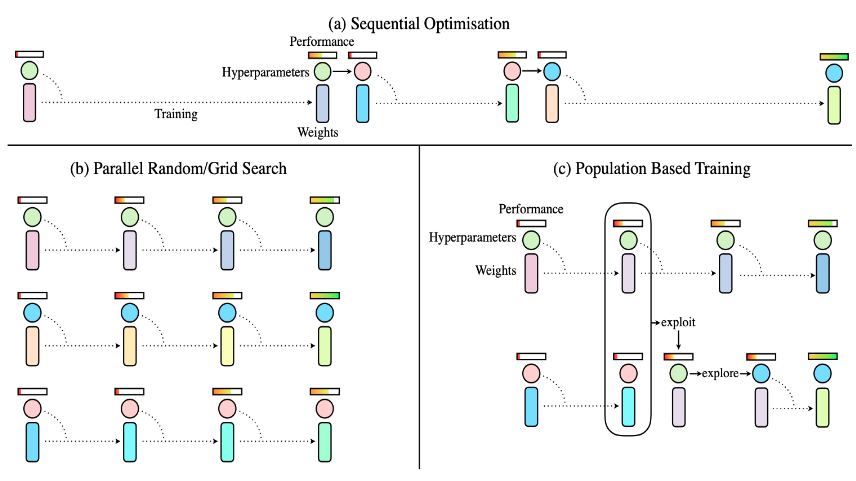
Em 2017, foi proposto o Treinamento Baseado em População (PBT) .A barra superior na figura abaixo representa o desempenho da rede, o círculo do meio representa hiperparâmetros e os parâmetros do modelo de código de barras abaixo.
A (a) estratégia na figura é uma estratégia de otimização "serial": primeiro defina um hiperparâmetro, após o treinamento para ver o efeito do modelo e, em seguida, para avaliar quais hiperparâmetros precisam ser ajustados. Geralmente, esse tipo de estratégia é adotado para o ajuste manual de parâmetros.O custo é muito alto e a eficiência é relativamente baixa.
A estratégia (b) na figura adota uma estratégia de otimização paralela: com o apoio de grande poder computacional, vários conjuntos de hiperparâmetros são configurados para treinar ao mesmo tempo e depois ver qual conjunto tem o melhor efeito. Embora esse método seja mais eficiente, os resultados entre os grupos não são comunicados entre si e todos são feitos separadamente.
A estratégia (c) na figura é PBT: No processo de otimização paralela, é avaliado qual modelo do grupo de superparâmetros é melhor e, com base nesse grupo de superparâmetros mais eficazes, adicione algumas perturbações aleatórias Em seguida, compartilhe seus super parâmetros com pequenas alterações em outros grupos para fortalecer a comunicação entre os grupos.
3.4 Pesquisa automática por hiperparâmetro do AutoDL Finetuner
A ferramenta de pesquisa de hiperparâmetros AutoDL Finetune no PaddleHub fornece dois algoritmos de otimização: HAZero e PSHE2 . A idéia central do HAZero é lidar com a dependência e o dimensionamento entre variáveis, ajustando a matriz de covariância na distribuição normal. O PSHE2 usa o sistema dinâmico hamiltoniano para procurar o ponto mais baixo de "energia potencial" no espaço de parâmetros, que é a combinação ideal de hiperparâmetros.
Para avaliar a eficácia dos superparâmetros pesquisados, o AutoDL Finetuner fornece duas estratégias de avaliação de superparâmetros:
Trilha completa: dado um conjunto de superparâmetros, use esse conjunto de superparâmetros para iniciar um novo modelo de ajuste fino desde o início e avalie esse modelo no conjunto de validação;
Baseado em população: dado um conjunto de super parâmetros, se esse conjunto de super parâmetros for a primeira combinação de super parâmetros experimentados, faça o ajuste fino de um novo modelo desde o início; caso contrário, com base nos melhores modelos que foram salvos nas rodadas anteriores, o atual Continue ajustando e avaliando com a combinação de hiperparâmetros.
4. Resumo
Resuma o conteúdo do PaddleHub:
(1) rica e excelente biblioteca de modelos de pré-treinamento, cobrindo tanto o processamento de linguagem natural quanto a visão computacional;
(2) O modelo é um software, aprendizado de transferência conveniente e fácil de usar, apenas algumas linhas de código podem obter aprendizado de transferência
(3) Forneça algoritmos automatizados de pesquisa por hiperparâmetro e algoritmos de avaliação para otimizar modelos e reduzir o limite de treinamento.