Redundância
No texto significativo do alfabeto inglês, o valor estimado da informação média (entropia de cada caractere) transportada por cada caractere é igual a 1,5 bits.
Na lingüística, no inglês real, a entropia média de informação realizada por cada letra em inglês é 4,7 (log26, como obtê-la não é descrita em detalhes aqui).
Então, nas senhas em inglês, a redundância de cada caractere é 3.
3. As evidências empíricas mostram que, para qualquer substituição simples em mensagens significativas, um analista de criptografia qualificado pode restaurar texto simples com apenas 25 caracteres de texto cifrado.
Distância única da solução
A distância da solução exclusiva é a quantidade mínima de texto cifrado (número de caracteres) exigido por um adversário que não está limitado pelo cálculo para recuperar uma chave de criptografia exclusiva.
Sob o modelo de cifra aleatória, o valor esperado da distância única da solução de uma cifra é N = H (K) / D, em que H (K) é a entropia do espaço da chave (por exemplo, 64 bits têm 2 26 chaves de probabilidade iguais), D é a redundância de texto sem formatação (bits / caracteres).
Sob o modelo de cifra aleatória, a distância única da solução de uma cifra transposta simples com o período t pode ser estimada, assumindo a redundância de texto simples D = 3,2 bits / caractere
Nesse caso, H (K) / D = lg (t!) / 3,2 bits / caractere, quando t = 12, o valor estimado da distância exclusiva da solução é de 9 caracteres. Se for o código de César, y = 26, e o H (K) final for 28, o que não é muito diferente do valor empírico acima.
经验证据显示,对于有意义消息上的任意简单替代 ,一位熟练的密码分析者只需25个密文字符就能恢复明文。
Estatísticas de idioma

É fácil entender que, se a frequência de caracteres na tabela de senhas não mudar após a criptografia simples, é muito fácil decifrar.
Há uma seção de texto cifrado na senha de substituição de uma letra: você
UZQSOVUOHXMOPVGPOZPEVSGZWSZOPFPESXUDBMETS XAIZVUEPHZHMDZSHZOWSFPAPPDTSVPQUZWYMXUZUH SXEPYEPOPDZSZUFPOMBZWPFUPZHMDJUDTMOHMQ
pode usar a figura anterior para análise, continuar análises e testes semelhantes e obter o texto sem formatação completo, além de espaços da seguinte forma: Isso
it was disclosed yesterday that several informal but direct contact have been made with political representative of the viet cong in moscow
pode ser alcançado por um programa.
Índice de polimerização
O índice de coincidência (IC) é uma medida da frequência relativa de alfabetos em amostras de texto cifrado.Por determinar o período t, torna-se mais fácil analisar cifras com vários alfabetos.
(Use IC para estimar vários períodos do alfabeto) Liste o valor esperado de IC para o período t = 1,2,3 ... e compare-o com a tabela obtida de um texto cifrado específico para obter uma estimativa aproximada do período de cifra.
A fórmula
para calcular o valor esperado de IC: para uma cifra substituta com vários alfabetos com o período t, o valor esperado do índice de coincidência de uma sequência de texto cifrado de comprimento L é E (IC), em que n é o número de caracteres do alfabeto. k r = 1 / n, k p é dado na tabela a seguir: p em
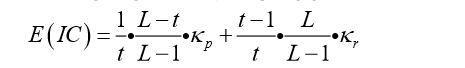
k p refere-se a uma distribuição de frequência de texto sem formatação e k r é uma distribuição de caracteres aleatórios. Para o alfabeto romano, n = 26 significa k r = 0,03846; para o alfabeto cirílico russo, n = 30.
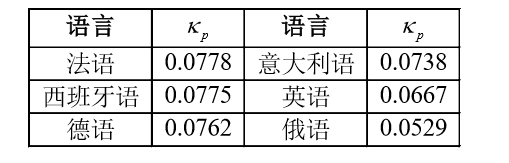
Sobre K P : set texto cifrado alfabeto (A 0 , A . 1 , A 2 ... A n-- 1. ), P I é um personagem texto cifrado aleatória aleatoriamente selecionado A I probabilidade desconhecida.
Rugosidade é o desvio dos caracteres do texto cifrado da distribuição de frequência uniforme: o
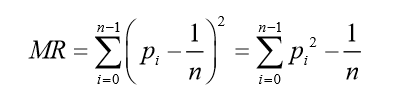
valor máximo é definido como MR max , onde, quando p i é a frequência do texto sem formatação, corresponde a Σp i 2 .
